
在这篇博客中,你将了解:
- AI 智能体的定义。
- AI 智能体如何工作,以及其主要组成部分。
- 基于智能与行为划分的 AI 智能体主要类型。
- 构建一个 AI 智能体所需的全部步骤。
- 开发 AI 智能体的最佳技术栈。
- 真实世界的智能体示例。
让我们开始吧!
什么是 AI 智能体?
AI 智能体是一种软件系统,它能够自主完成任务,使用工具并进行决策,以在几乎无需人工干预的情况下(人类在环场景除外)实现既定目标。
为了达到目标,AI 智能体通常会进行规划、推理,并通过编排多步处理流程、利用记忆和集成外部工具(如 API、数据库或第三方解决方案)来不断调整自身行为。
AI 智能体如何工作,以及它由哪些要素构成
AI 智能体通过执行一个面向目标的自主循环来运作,该目标通常较为复杂并包含多步任务。为此,智能体需要感知环境、对其可访问或已检索的信息进行推理、采取行动,并从结果中学习,持续重复这一循环,直到其判断目标已经达成。
与传统 LLM 调用通常只执行单一步任务不同,AI 智能体能够进行多步问题求解,在过程中调整策略并从错误中学习。
AI 智能体的行为取决于多种因素,尤其是其所依赖的概念架构。总体来说,其工作流由感知、推理、行动、学习等阶段构成的循环组成,这些阶段组合在一起,使智能体能够自主追求其目标。
从技术角度看,一个智能体可以被实现得非常简单,比如使用带有基于目标校验退出条件的 while True 循环。例如,Hugging Face 最近在其 Agent 类中采用的就是这种方式。了解更多如何构建 Hugging Face AI 智能体。
AI 智能体的核心组件
一个 AI 智能体通常由若干关键组件构成,它们共同实现自主和自适应行为,主要包括:
- 大语言模型(LLM):通常被视为智能体的“大脑”或“引擎”,负责基础推理与自然语言处理能力,使智能体能够理解用户输入、生成回复并制定计划。需要注意的是,单个智能体可以使用多个 LLM 模块(例如,一个用于推理、一个用于规划、另一个用于目标校验)。此外,AI 模型既可以是远程托管的,也可以是本地部署的。
- 记忆(Memory):对保持上下文与随时间学习至关重要,智能体的记忆通常被划分为两个系统:
- 短期记忆:负责当前任务或会话的即时上下文,存储保持连续性所需的最近信息。多数情况下,它通过内存数据结构或数据库实现,如临时缓存、基于会话的存储,或 Redis 等,因为这里对快速访问和低延迟要求极高。
- 长期记忆:存储事实性知识、过往经验、用户偏好,以及跨多次会话累积的技能。该组件使智能体能够保持连续性,并提供更加个性化、具备上下文感知的响应。常见的长期记忆技术包括用于存储向量嵌入的向量数据库(如 Pinecone、Weaviate、FAISS),以及 SQL/NoSQL 数据库、文档库或知识库(如 MySQL、PostgreSQL、MongoDB 等)。
- 工具(Tools):LLM 的知识有限,也无法独立完成所有任务。AI 智能体通过集成外部工具来扩展自身能力,使底层 LLM 能够与环境和外部世界进行交互(例如访问文件系统、浏览网页,或对接业务基础设施)。这些工具支持智能体执行诸如网页爬取、网站交互、创建文件等具体任务。为管理工具使用,智能体依赖于多种 AI 协议,其中 MCP(Multi-Tool Control Protocol,多工具控制协议)目前最为流行(至少在当前阶段)。
- 执行运行时(Execution Runtime):该编排层负责管理智能体的整体工作流,检查计划是否被遵循,按顺序调度工具调用,并协调所有组件。此外,它还能帮助完成 AI 智能体架构的部署与管理。常见的执行运行时包括 LangChain、LlamaIndex、CrewAI、AutoGen 等。
延伸阅读:
AI 智能体的类型
本节我们将聚焦于不同类型的 AI 智能体。分类依据是其决策水平,以及它们如何与环境交互以达成预期结果。
说明:给 AI 智能体分类的方式有很多,但以下分类是最具参考价值的一种,因为它能够清晰界定智能体的行为方式和决策方式。其他可能的分类包括基于推理范式的方式,例如 ReAct、ReWOO 等。
延伸阅读:
简单反射型智能体(Simple Reflex Agents)
简单反射型智能体是最基础的 AI 智能体类型。它完全依赖当前环境输入以及一组预定义的条件—动作(condition–action)规则来做决策,不维护任何内部状态、既往经验记忆,也不会考虑未来后果,其行为是即时且被动响应式的。
基于模型的反射型智能体(Model-Based Reflex Agents)
基于模型的反射型智能体是对简单反射型智能体的改进。它包含了对外部世界的内部模型,帮助智能体追踪当前状态,并理解过去交互或动作如何影响环境,这意味着它可以在部分可观测环境中运行。
虽然仍然使用条件—动作规则,但其决策基于当前感知和经过推理的内部状态。这种对环境动态的记忆与推理能力,使其决策比简单反射型智能体更为充分和有效。
基于目标的智能体(Goal-Based Agents)
基于目标的智能体具有主动性,并拥有明确的目标或任务。它们通过规划和推理评估不同可能动作,并选择能够使其更接近目标的行动序列。这类 AI 智能体可以预见期望的未来状态,并基于对结果与目标关联性的逻辑评估来做出决策。
基于效用的智能体(Utility-Based Agents)
基于效用的智能体超越了简单的“达成目标”,它们通过效用函数来最大化整体收益或“满意度”。这类智能体对多种可能结果进行评估,并为每个结果分配一个数值化的效用值,从而在存在多目标或权衡(如速度 vs. 安全性)时做出更细致的决策。
学习型智能体(Learning Agents)
学习型智能体会基于来自环境的反馈,不断适应新经验和新数据,从而随时间提升自身表现。它们通过内部的学习组件持续更新行为。实现学习型智能体的一种常见机制是强化学习,智能体通过不断的试错学习哪些动作能够最大化回报。
延伸阅读:
多智能体系统(Multi-Agent Systems)
多智能体系统由多个相互协作的智能体组成,用以处理复杂问题。高层智能体可能聚焦于整体目标,而底层智能体则负责具体子任务。其核心思想是 AI 编排:系统通过整合多个不同类型的智能体来管理跨多领域的复杂任务。其中最流行的多智能体实现库之一是 CrewAI。
延伸阅读:
- 使用 CrewAI 与 Bright Data 构建房地产智能体
- 用 CrewAI 和 Bright Data 构建多源评论情报智能体
- 使用 CrewAI 和 Bright Data 进行 GEO 内容优化
构建 AI 智能体:从构想到部署
下面的步骤展示了如何从零开始,直到让一个 AI 智能体上线。我们逐步来看。
1. 明确目的
从高层思考智能体需要处理哪些任务,以及它应该覆盖哪些场景。智能体通常应在某个特定问题领域内足够专业;不过,有时你也会希望构建能执行多种任务、覆盖多种用例的广义智能体。
无论如何,你都必须清晰地理解构建 AI 智能体背后的目的。你甚至可能会意识到自己并不真正需要一个完整的智能体,简单的 AI 工作流就足够了。
2. 设计智能体工作流
将智能体以可视化的方式表示为节点图,每个节点对应一个组件,如下图所示: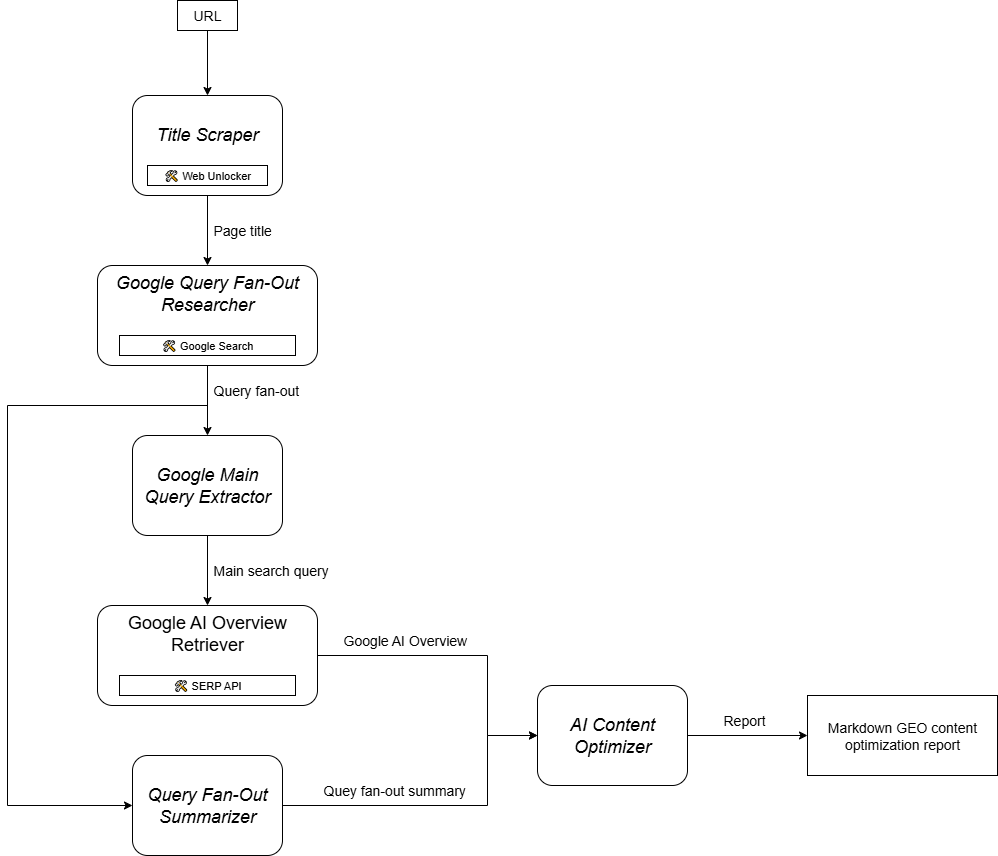
在某些情况下,从“步骤”而非“组件”的角度进行思考更为合适。这个过程有助于你清晰定义工作流,并为每个节点/步骤确定期望的输入和输出。
3. 选择数据源
AI 智能体的能力取决于它能访问的数据与信息。因此,你需要识别并提供 AI 模型达成目标所需的数据,可能包括 API、网页数据、数据集、数据库或其他数据源。请记住,并非所有数据格式都适合 AI ingest,实证基准已经证明了这一点。
在这方面,Bright Data 提供了丰富的 AI 就绪基础设施产品,包括:
- Web Unlocker API:绕过网站的反爬与反机器人保护,支持以 HTML 或 Markdown 格式获取任意网页。
- SERP API:解锁搜索引擎结果,从主流搜索引擎中提取 SERP 数据,用于各类网页搜索场景。
- Web Scraper APIs:预配置 API,可从 100 多个主流网站获取结构化数据,并以 AI 优化的格式返回。
- Browser API:可云端控制的浏览器实例,与 AI 集成后可进行可编程的网页交互,并内置解封能力。
- Crawl API:自动化任意域名内容提取,可将整站内容以 Markdown、文本、HTML 或 JSON 等格式返回。
- 训练数据:来自热门平台的 AI 就绪公开网页数据与多模态数据集,涵盖数十亿条记录。
4. 选择 AI 模型
在 OpenRouter 和 Hugging Face 等平台上,已有数千种 AI 模型。一些是通用模型(如 OpenAI 或 Gemini 系列),另一些则是为细分应用精调(fine-tuned)而成。基于你为智能体设计的可视化工作流和高层架构,为每个需要 LLM 集成的节点选择合适的 AI 模型。
延伸阅读:
- 使用 Unsloth 微调 GPT-OSS:分步指南
- 利用最新网页数据微调 Llama 4 以获得更好效果
- 微调 Gemma 3:基于自定义问答数据集的分步指南
- 如何用 Web Scraper API 和 n8n 微调 GPT-4o
5. 集成工具
LLM 在内容生成方面表现出色,但在其他功能以及其训练数据限制上仍有不足。要扩展智能体能力,你需要识别各个 LLM 节点所需的工具。这些工具可以是自建的(例如调用外部 API),依赖本地任务执行器,或来自现成的 MCP servers 等服务。
说明:Bright Data 的 Web MCP 使 LLM 和 AI 智能体能够高效访问网络,支持其在不被封禁的情况下搜索、提取和浏览在线内容,并内置60 多种工具。同时,它提供免费额度,可零成本使用。
延伸阅读:
- 如何将 Bright Data Web MCP 集成到 smolagents
- 为 LangChain 智能体轻松接入 Bright Data Web MCP
- CrewAI & Bright Data Web MCP:进阶网页爬取指南
- AutoGen AgentChat 集成 Bright Data Web MCP
- 将 Pydantic AI 与 Bright Data Web MCP 集成
- 使用 AWS Strands SDK + Bright Data MCP 构建 AI 智能体
- Bright Data Web MCP 的全部集成
6. 实现逻辑
使用选定的 AI 智能体框架或低/零代码解决方案,将你的设计转化为可运行系统。这包括连接 AI 模型、工具以及其他组件。
实现 AI 智能体可能涉及编写脚本、创建配置文件,以及为各个 LLM 节点定义 Prompt,以指导其完成相应任务。对于多智能体系统,你还可以利用 A2A(Agent-to-Agent)协议进行智能体间通信。
延伸阅读:
- 用 Pica 和 Bright Data 构建 AI 智能体
- 使用 Dify 构建具备数据检索能力的 AI 智能体
- 使用 LlamaIndex 与网页数据构建 AI 智能体
- – 在 xpander.ai 中构建具备爬取能力的 AI 智能体
- 如何用 Hugging Face 与 Bright Data 构建 AI 爬虫
7. 测试与迭代
当智能体可以运行后,使用简单和复杂场景对其进行测试。检查每一步是否产生预期的输入和输出。测试有助于你优化智能体的基础架构,例如识别是否需要更多工具、不同模型或更佳 Prompt。对边界情况进行测试对于确保准确性与可靠性尤其关键。此外,你很可能会遇到各种错误,并意识到需要构建更健壮的错误处理流程。
8. 部署与监控
最后,将智能体部署到云端或本地环境。部署后,使用监控工具跟踪智能体在真实环境中的表现。根据监控反馈持续迭代、优化智能体。请记住,新的模型、工具或能力会不断出现,应持续更新智能体以利用最新的 AI 进展。
延伸阅读:
适合构建 AI 智能体的最佳技术栈
与大多数软件开发场景类似,构建 AI 智能体并不存在唯一的“最佳”技术栈。成功的关键在于为 AI 智能体开发过程中的各个组件(如 AI 服务商、LLM、数据库、Prompt 版本管理工具等)做出合适选择。
在这里,我们将重点关注技术栈中最重要的一环:用于实际构建 AI 智能体的框架或解决方案。
下面是一个包含 15+ 个最流行开源框架的表格,按 GitHub star 数排序:
| AI 智能体框架 | 编程语言 | GitHub Star 数 |
|---|---|---|
| AutoGPT | —(低代码/零代码) | 179k+ |
| Langflow | Python,TypeScript/JavaScript | 134k+ |
| LangChain | Python,JavaScript/TypeScript | 118k+ |
| Dify | —(低代码/零代码) | 117k+ |
| AutoGen | Python,.NET | 51k+ |
| Flowise | —(低代码/零代码) | 46k+ |
| LlamaIndex | Python,JavaScript/TypeScript | 44.9k+ |
| CrewAI | Python | 39.6k+ |
| Agno | Python | 34.5k+ |
| ChatDev | Python | 27.6k+ |
| Semantic Kernel | Python,.NET,Java | 26.5k+ |
| smolagents | Python | 23.5k+ |
| Letta | Python,TypeScript | 18.9k+ |
| OpenAI Agents SDK | Python,TypeScript | 16.8k+ |
| Google Agent Development Kit (ADK) | Python,Java | 13.9k |
| PydanticAI | Python | 13k+ |
说明:Bright Data 已通过 MCP 与上述大多数技术(以及许多其他技术)实现官方集成。查看全部 70+ 集成。
延伸阅读:
AI 智能体示例
现在,你已经清楚了解 AI 智能体是什么、如何工作、由哪些组件构成,以及构建它们所用的工具,最后一步就是看看它们在真实场景中的表现。
为此,我们推荐查看我们的 AI 智能体展示库,其中汇集了一系列基于不同技术构建、覆盖多种用例的 AI 智能体。
延伸阅读:
- TrendScan:一个多源企业情报平台,可自动采集并基于 AI 分析来自 Crunchbase、LinkedIn、Reddit 与 Twitter/X 的公司数据。
- 统一搜索智能体(Unified Search Agent):一个基于 LangGraph 构建的高级多模态搜索智能体,可根据查询意图在 Google 搜索与网页爬取之间智能路由。
- 房地产 AI 智能体系统:一个智能的 Python 系统,利用 AI 智能体、Nebius Qwen LLM 和 Bright Data Web MCP,将房地产房源数据提取为结构化 JSON。
- GEO AI Crew:一个 AI 驱动工具,可通过爬取 URL、分析 H1 标题并生成可执行的 GEO 建议来审计和优化网站内容,基于 CrewAI 实现。
- FactFlux:一个使用 Agno 框架和 Bright Data 工具,对社交媒体帖子进行事实核查的智能多智能体系统。
- AI 旅行规划师:一个利用 n8n 和 Bright Data 实时爬取自动化旅行规划的 AI 智能体。
结论
在本文中,你已经了解了构建 AI 智能体所需的一切。现在,你具备了开发 AI 智能体的基础信息,同时也拥有大量延伸资源,可以在这一热门主题上成为更深入的专家。
无论你的 AI 智能体目标是什么,拥有可靠的网页数据合作伙伴都至关重要。正如本文所强调的,智能体的能力取决于其所拥有的知识,而这又完全取决于它能访问的数据。
这正是 Bright Data 的价值所在——我们提供完整的 AI 解决方案基础设施,以支持广泛的智能体场景与用例。
立即创建 Bright Data 账号,将我们的网页数据工具免费集成到你的 AI 智能体中!
常见问题(FAQ)
AI 智能体 vs. Agentic AI:有什么区别?
AI 智能体可以自主执行完整流程。相比之下,Agentic AI 指的是能够协调多个智能体以完成更复杂目标的高层系统。它能够在无需持续人工输入的情况下进行规划、推理和动态适应。简而言之,AI 智能体负责执行任务,而 Agentic AI 是编排这些任务的智能基础设施。
AI 智能体 vs. AI 工作流:主要区别是什么?
AI 工作流是遵循预定义步骤或逻辑的过程,具有高度可预测性,非常适合结构化、重复性的任务。而 AI 智能体则是具备自主性、使用推理来动态规划、选择工具并在实时中调整行为的非确定性系统,适用于解决路径并不预先确定的开放性问题。
构建 AI 智能体的最佳技术是什么?
Agentic AI 聚焦于自主任务执行,例如规划、工具使用、状态追踪和决策,以完成目标;而生成式 AI(也称 GenAI)则根据提示生成新的内容,如文本、图片、视频或代码。因此,Agentic AI 负责“协调”,而生成式 AI 负责“生成”。你可以在我们的文章《Agentic AI 与生成式 AI 对比》中深入了解。
用于 AI 智能体集成的最佳 MCP Server 有哪些?
部分适用于 AI 智能体的 MCP Server 包括:用于实时网页数据和结构化抽取的 Bright Data Web MCP,用于自动化开发工作流的 GitHub,用于数据库和后端管理的 Supabase,用于浏览器自动化的 Playwright MCP,以及用于知识管理的 Notion。其他值得注意的 server 包括 Atlassian、Serena、Figma 和 Grafana。你可以在我们的文章《最佳 AI 智能体 MCP Servers》中了解所有选项。
什么是 Agentic RAG?
Agentic RAG 是一种进阶形式的 RAG(检索增强生成,Retrieval-Augmented Generation),它通过自主 AI 智能体智能地控制并动态调整检索与响应生成流程。了解如何用 Bright Data 构建 Agentic RAG 系统。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




