

网页抓取正处在转折点。高级反爬虫机制让传统抓取方法频频失效,开发者不得不不断修补脆弱脚本。虽然这些方法依旧可用,但与能提供弹性与可扩展性的现代 AI 原生抓取架构相比,它们的局限显而易见。随着AI 代理市场预计将从 78.4 亿美元增长至 526.2 亿美元(2030 年),智能自治系统将成为未来获取数据的核心。
结合 CrewAI 的自治代理框架与 Bright Data 的强大基础设施,您将获得一套能自主推理、突破反爬虫壁垒的抓取技术栈。本教程将引导您构建一名 AI 驱动的抓取代理,实时稳定地提取数据。
传统抓取的局限性
传统抓取极其脆弱——它依赖于静态CSS 或 XPath 选择器,任何前端微调都可能导致失败。主要难点包括:
- 反爬虫防御。 CAPTCHA、IP 限流与指纹识别会阻挡简单爬虫。
- JavaScript 重度页面。 React、Angular、Vue 等框架在浏览器内生成 DOM,纯 HTTP 调用抓不到主要内容。
- 非结构化 HTML。 不一致的 HTML 与分散的内联数据需要大量解析和后处理。
- 扩展瓶颈。 代理编排、重试及反复打补丁会演变成无止境的运维负担。
CrewAI + Bright Data 如何简化抓取
要构建自治抓取器,需要两大支柱:自适应的“大脑”与强韧的“身体”。
- CrewAI(大脑)。 开源多代理运行时,能创建会规划、推理、协同的 “crew” 以完成端到端抓取任务。
- Bright Data MCP(身体)。 实时数据网关,每个请求都会通过 Bright Data Unlocker 组件——旋转 IP、自动解 CAPTCHA、无头浏览器渲染——一次性返回干净的 HTML 或 JSON。Bright Data 是AI 代理可靠数据的业界标杆。
两者合体,让您的代理能够思考、检索并适应几乎任何网站。
CrewAI 是什么?
CrewAI 是一款编排协作式 AI 代理的开源框架。您可为每个代理定义 角色、目标 与 工具,再把它们组合成 crew 执行多步骤流程。
核心组件:
- Agent。 由 LLM 驱动的工作者,拥有 role、goal 与可选 backstory,为模型提供领域上下文。
- Task。 针对单一代理的可度量工作,并带有 expected_output 作为质量门。
- Tool。 代理可调用的任何功能——HTTP 抓取、数据库查询或 Bright Data MCP 端点。
- Crew。 多个代理与任务的集合,共同达成一个目标。
- Process。 执行计划——sequential、parallel 或 hierarchical——控制任务顺序、委派与重试。
这就像现实团队:专家各司其职,交接结果,并在需要时升级。
什么是 Model Context Protocol (MCP)?
MCP 是一套基于 JSON-RPC 2.0 的开放标准,让 AI 代理通过单一结构化接口调用外部工具与数据源。可把它看作模型的 USB-C 接口——一次插入,连接万千设备。
Bright Data 的 MCP 服务器把标准落地,实现MCP 抓取比传统技术栈更强大、更简单:
- 反爬绕过。 请求经由Web Unlocker 和全球 1.5 亿+住宅 IP 旋转池。
- 动态站点支持。 专用Scraping Browser 渲染 JavaScript,代理能看到完整 DOM。
- 结构化结果。 多数工具直接返回干净 JSON,无需自写解析器。
服务器已发布50+ 现成工具,代理可一键获取商品价格、搜索结果或 DOM 快照。
构建第一个 AI 抓取代理
下面我们将构建一名 CrewAI 代理,从 Amazon 产品页提取数据并返回结构化 JSON。若要抓取其他站点,仅需改动少量代码。
前置条件
- Python 3.11(推荐)。
- Node.js + npm(运行 Bright Data MCP 服务端)。
- Python 虚拟环境(隔离依赖)。
- Bright Data 账号(免费注册并创建 API token)。
- Google Gemini API Key(在 Google AI Studio 生成)。
架构概览
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON Output步骤 1:环境准备与导入
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .env步骤 2:配置 API Key 与 Zone
在项目根目录创建 .env:
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"您需要:
- API token:在 文档中生成。
- Web Unlocker zone:创建 新 zone,若省略则默认创建
mcp_unlocker。 - Browser API zone:创建,仅当需渲染 JS 时使用。
- Google Gemini API Key:已在前置条件中生成。
步骤 3:LLM 配置(Gemini)
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)步骤 4:Bright Data MCP 设置
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)该命令以子进程形式启动 npx @brightdata/mcp,并通过 MCP 暴露 50+ 工具。
步骤 5:代理与任务定义
在这里,我们要为代理设定角色人格,并明确其具体工作内容。高效的 CrewAI 实践遵循 80/20 法则:将 80% 的精力投入到任务设计,20% 用于代理定义。
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)各参数说明:
- role:简短职位名称。
- goal:总体目标,用于判断任务是否完成。
- backstory:领域背景,减少幻觉。
- tools:
BaseTool列表,如 MCP 的search_engine。 - llm:每次循环使用的模型。
- max_iter:代理内部循环上限。
- verbose:是否输出调试信息。
- description:具体行动指令。
- expected_output:期望的严格 JSON 格式答案。
- agent:绑定到某个
Agent实例。
步骤 6:组装 Crew 并执行
此步骤将代理和任务组装成一个 Crew,并启动完整工作流。
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
print(f"n[ERROR] Scraping failed: {str(e)}")步骤 7:运行抓取脚本
在终端执行脚本,您将看到代理的思考、计划与执行过程。

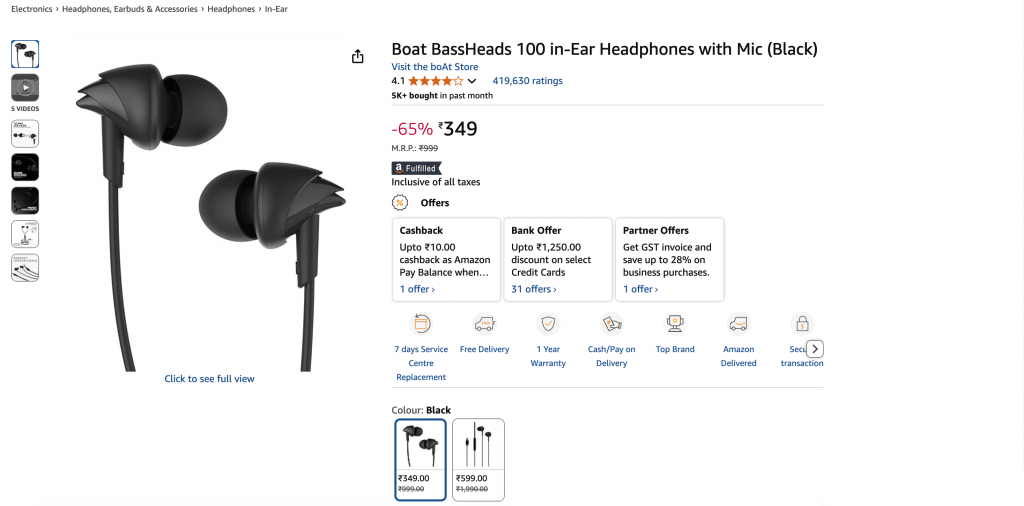
最终输出示例:
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}适配其他目标站点
代理设计的真正优势在于灵活性。想抓取 LinkedIn 帖子?只需更新代理的 role、goal、backstory,再调整任务的 description 与 expected_output,其余代码与基础设施保持不变。
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""输出将会是一个干净的 JSON 对象:
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2026-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}成本优化
Bright Data 的 MCP 采用按量计费模式,因此每增加一次请求都会带来额外费用。通过以下设计可有效控制成本:
- 目标式抓取。 仅请求所需字段,而非整页或整库爬取。
- 缓存。 启用 CrewAI 的工具级缓存(
cache_function),当内容未变时跳过调用,节省时间与额度。 - 高效工具选择。 默认使用 Web Unlocker zone,仅在必须渲染 JavaScript 时才切换 Browser API zone。
- 设置
max_iter。 为每个代理设定合理上限,避免在故障页面无限循环。(也可使用max_rpm进行请求限速。)
遵循这些做法,您的 CrewAI 代理能够保持安全、可靠且具成本效益,可随时在 Bright Data MCP 上投入生产。
接下来可以做什么
随着生态扩展,OpenAI Responses API 与 Google DeepMind Gemini SDK 已原生支持 MCP,确保长期兼容与持续投入。
CrewAI 将推出多模态代理、更丰富调试及企业级 RBAC,而 Bright Data MCP 服务器已暴露 60+ 现成工具,仍在增长。
代理框架与标准化数据访问共同释放了AI 驱动应用的新一波网络智能。MCP 集成 OpenAI Agents SDK 的教程彰显了稳定数据管道的重要性。
归根结底,您构建的并非仅是“爬虫”,而是一套面向未来网络的自适应数据工作流。
需要更大规模? 无需维护爬虫与对抗封锁,直接获取结构化数据:
- Crawl API:整站抓取,规模无限。
- Web Scraper APIs:120+ 域专用端点。
- SERP API:轻松抓取搜索引擎结果。
- Dataset Marketplace:按需获取新鲜验证数据集。
准备打造下一代 AI 应用? 探索 Bright Data 全面的AI 产品套件,看看即时、无阻的网页访问会给您的代理带来怎样的提升。想深入了解,可阅读我们为 Qwen-Agent 和 Google ADK 准备的 MCP 指南。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





