

在本指南中,您将看到
- 用于构建人工智能代理的 Google ADK 库是什么?
- 为什么它对 MCP 的本地支持使其与众不同?
- 如何将其与 Bright Data MCP 服务器集成,以构建一个极其强大的人工智能代理
让我们深入了解一下!
什么是 Google ADK?
Google ADK 是Google Agent Development Kit 的缩写,是一个开源 Python 框架,用于构建和部署人工智能代理。虽然它针对 Gemini 和更广泛的 Google 生态系统进行了优化,但仍然与模型和部署无关。
ADK 强调开发者体验,提供工具和数据结构,让您轻松构建强大的多代理系统。它使您能够定义人工智能代理,这些代理可以通过工具和集成进行推理、协作和与世界交互。
Google ADK 的最终目标是让代理开发更像传统的软件开发。这是通过简化代理架构的创建、部署和协调过程来实现的。
谷歌 ADK 的独特之处
与其他人工智能代理创建库相比,Google ADK 的突出之处在于内置了对 MCP(托管连接平台)的支持。如果您对它不熟悉,MCP 是一种标准化方式,用于让人工智能模型与外部工具和数据源(如 API、数据库和文件系统)进行交互。
简单地说,MCP 允许 Google ADK 代理利用任何 MCP 兼容服务器的功能。将其视为即插即用的集成,通过让人工智能代理访问真实世界的数据和操作,使其超越底层 LLM 的限制。
该选项提供了一种结构化、安全和可扩展的方式,将您的代理与外部功能连接起来,而无需您从头开始建立这些连接。当与Bright Data MCP 服务器等功能丰富的 MCP服务器集成时,MCP 集成尤其引人注目。
MCP 服务器通过 Node.js 运行,可无缝连接到Bright Data 的所有强大人工智能数据检索工具。这些工具使您的代理能够与实时网络数据、结构化数据集和抓取功能进行交互。
截至目前,支持的MCP 工具有
| 工具 | 说明 |
|---|---|
search_engine |
从 Google、Bing 或 Yandex 抓取搜索结果。以 markdown 格式(URL、标题、描述)返回 SERP 结果。 |
scrape_as_markdown |
抓取单个网页,并以 Markdown 格式返回提取的内容。即使是受僵尸保护或验证码保护的网页也能正常运行。 |
scrape_as_html |
同上,但返回原始 HTML 内容。 |
session_stats |
提供当前会话期间工具使用情况的摘要。 |
web_data_amazon_product |
使用/dp/URL 检索结构化亚马逊产品数据。由于有缓存,因此比抓取更可靠。 |
web_data_amazon_product_reviews |
使用/dp/URL 检索结构化亚马逊评论数据。缓存且可靠。 |
web_data_linkedin_person_profile |
访问结构化的 LinkedIn 个人资料数据。高速缓存,保证一致性和速度。 |
web_data_linkedin_company_profile |
访问结构化的 LinkedIn 公司数据。缓存版本提高了可靠性。 |
web_data_zoominfo_company_profile |
读取结构化的 ZoomInfo 公司数据。需要有效的 ZoomInfo URL。 |
web_data_instagram_profiles |
结构化 Instagram 个人资料数据。需要有效的 Instagram URL。 |
web_data_instagram_posts |
检索 Instagram 帖子的结构化数据。 |
web_data_instagram_reels |
检索 Instagram 卷轴的结构化数据。 |
web_data_instagram_comments |
以结构化数据形式检索 Instagram 评论。 |
web_data_facebook_posts |
访问 Facebook 帖子的结构化数据。 |
web_data_facebook_marketplace_listings |
从 Facebook Marketplace 检索结构化列表。 |
web_data_facebook_company_reviews |
检索 Facebook 公司评论。需要公司 URL 和评论数量。 |
web_data_x_posts |
从 X(原 Twitter)帖子中检索结构化数据。 |
web_data_zillow_properties_listing |
访问结构化的 Zillow 房源数据。 |
web_data_booking_hotel_listings |
从 Booking.com 检索结构化酒店列表。 |
web_data_youtube_videos |
结构化 YouTube 视频数据。需要有效的视频 URL。 |
scraping_browser_navigate |
将抓取浏览器导航到新的 URL。 |
scraping_browser_go_back |
返回上一页。 |
scraping_browser_go_forward |
在浏览器历史记录中向前浏览。 |
scraping_browser_click |
点击页面上的特定元素。需要使用元素选择器。 |
scraping_browser_links |
读取当前页面上的所有链接及其选择器和文本。 |
scraping_browser_type |
模拟在输入框中输入文本。 |
scraping_browser_wait_for |
等待特定元素变为可见。 |
scraping_browser_screenshot |
给当前页面截图。 |
scraping_browser_get_html |
读取当前页面的 HTML 全文。如果不需要完整页面内容,请谨慎使用。 |
scraping_browser_get_text |
读取当前页面的可见文本内容。 |
如需了解另一种可能的集成方式,请参阅我们关于使用 MCP 服务器进行网络抓取的文章。
注:Bright Data MCP 服务器会定期添加新工具,使其功能日益强大和丰富。
了解如何通过 Google ADK 利用这些工具!
如何将 Google ADK 与 Bright Data MCP 服务器整合
在本教程中,您将学习如何使用 Google ADK 构建一个功能强大的人工智能代理。它将配备由 Bright Data MCP 服务器提供的实时抓取、数据检索和转换功能。
此设置最初由 Meir Kadosh 实现,因此请务必查看他最初的 GitHub 仓库。
具体来说,人工智能代理将能够
- 从搜索引擎检索 URL。
- 从这些网页中抓取文本。
- 使用提取的数据生成基于来源的答案。
注:通过更改代码中的提示,您可以轻松地调整人工智能代理,使其适用于任何其他场景或用例。
请按照以下步骤在 Python 中构建由 Bright Data MCP 驱动的 Google ADK 代理!
先决条件
要学习本教程,您需要
- 本地已安装Python 3.9或更高版本。
- 本地已安装Node.js。
- 基于 UNIX 的系统,如 Linux 或 macOS,或 WSL(Windows Subsystem for Linux)。
注意:Google ADK 与 Bright Data MCP 服务器的集成目前无法在 Windows 上正常运行。尝试运行它可能会引发这部分代码的NotImplementedError 错误:
transport = await self._make_subprocess_transport(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
protocol, popen_args, False, stdin, stdout, stderr,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
bufsize, **kwargs)
^^^^^^^^^^^^^^^^^^
raise NotImplementedError因此,本教程假定您使用的是 Linux、macOS 或 WSL。
您还需要
- Bright Data 账户
- 双子座 API 密钥
本教程将指导您在需要时设置 Gemini 和 Bright Data 证书。因此,现在不用担心它们。
虽然不是必需的,但以下内容将帮助您从本教程中获得最大收益:
- 对多边协商程序运作方式的大致了解。
- 基本了解Google ADK 的工作原理。
- 熟悉 Bright Data MCP 服务器及其可用工具。
- 具有一定的Python 异步编程经验。
步骤 #1:项目设置
打开终端,为你的抓取代理创建一个新文件夹:
mkdir google_adk_mcp_agentgoogle_adk_mcp_agent文件夹将包含 Python 人工智能代理的所有代码。
接下来,导航进入项目文件夹,并在其中创建一个虚拟环境:
cd google_adk_mcp_agent
python3 -m venv .venv在你喜欢的 Python IDE 中打开项目文件夹。我们建议使用带有 Python 扩展的 Visual Studio Code或PyCharm Community Edition。
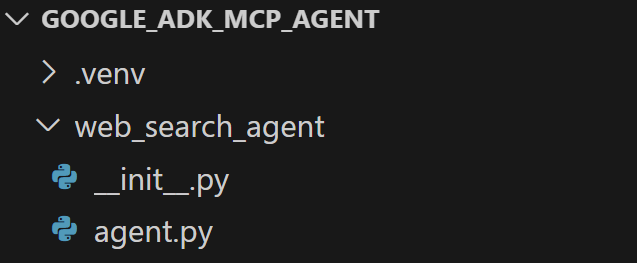
在google_adk_mcp_agent 中创建一个名为web_search_agent 的子文件夹。该子文件夹将包含代理的核心逻辑,并应包括以下两个文件:
- __init__
.py:导出agent.py中的逻辑 agent.py: 包含 Google ADK 代理定义。
现在,用下面一行初始化 __init__.py文件:
from . import agent相反,agent.py将很快与代理人工智能代理逻辑一起定义。
在集成开发环境的终端中,激活虚拟环境。在 Linux 或 macOS 中,执行此命令:
./.venv/bin/activate同样,在 Windows 上,启动
.venv/Scripts/activate一切就绪!现在您有了一个 Python 环境,可以使用 Google ADK 和 Bright Data MCP 服务器构建一个人工智能代理。
步骤 #2:设置环境变量 阅读
您的项目将与 Gemini 和 Bright Data 等第三方服务交互。最好的做法是从环境变量中加载它们,而不是直接在 Python 代码中硬编码 API 密钥和身份验证机密。
为了简化这项工作,我们将使用python-dotenv库。激活虚拟环境后,运行以下命令进行安装:
pip install python-dotenv在agent.py文件中导入该库,并使用load_dotenv() 加载环境变量:
from dotenv import load_dotenv
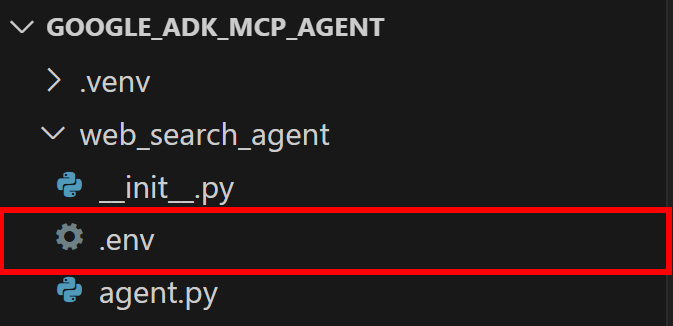
load_dotenv()这样就可以从本地.env文件中读取变量。因此,请在嵌套的代理目录中添加一个.env文件:
现在,您可以通过这行代码在代码中读取环境变量:
env_value = os.getenv("<ENV_NAME>")不要忘记从 Python 标准库中导入os模块:
import os太好了!您现在可以阅读 env 提供的安全集成第三方服务的秘诀了。
步骤 #3:开始使用 Google ADK
在已激活的虚拟环境中,运行以下命令安装Google ADK Python 库:
pip install google-adk然后,打开agent.py,添加以下导入:
from google.adk.agents import Agent, SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StdioServerParameters这些将在下一步整合 Google ADK 时使用。
现在,请记住 Google ADK 需要与人工智能提供商集成。在这里,我们将使用 Gemini- 因为该库已针对 Google 的人工智能模型进行了优化。
如果您尚未获得 API 密钥,请按照 Google 的官方文档进行操作。登录 Google 账户并访问 Google AI Studio。然后导航到“获取 API 密钥“部分,你会看到这个模式:
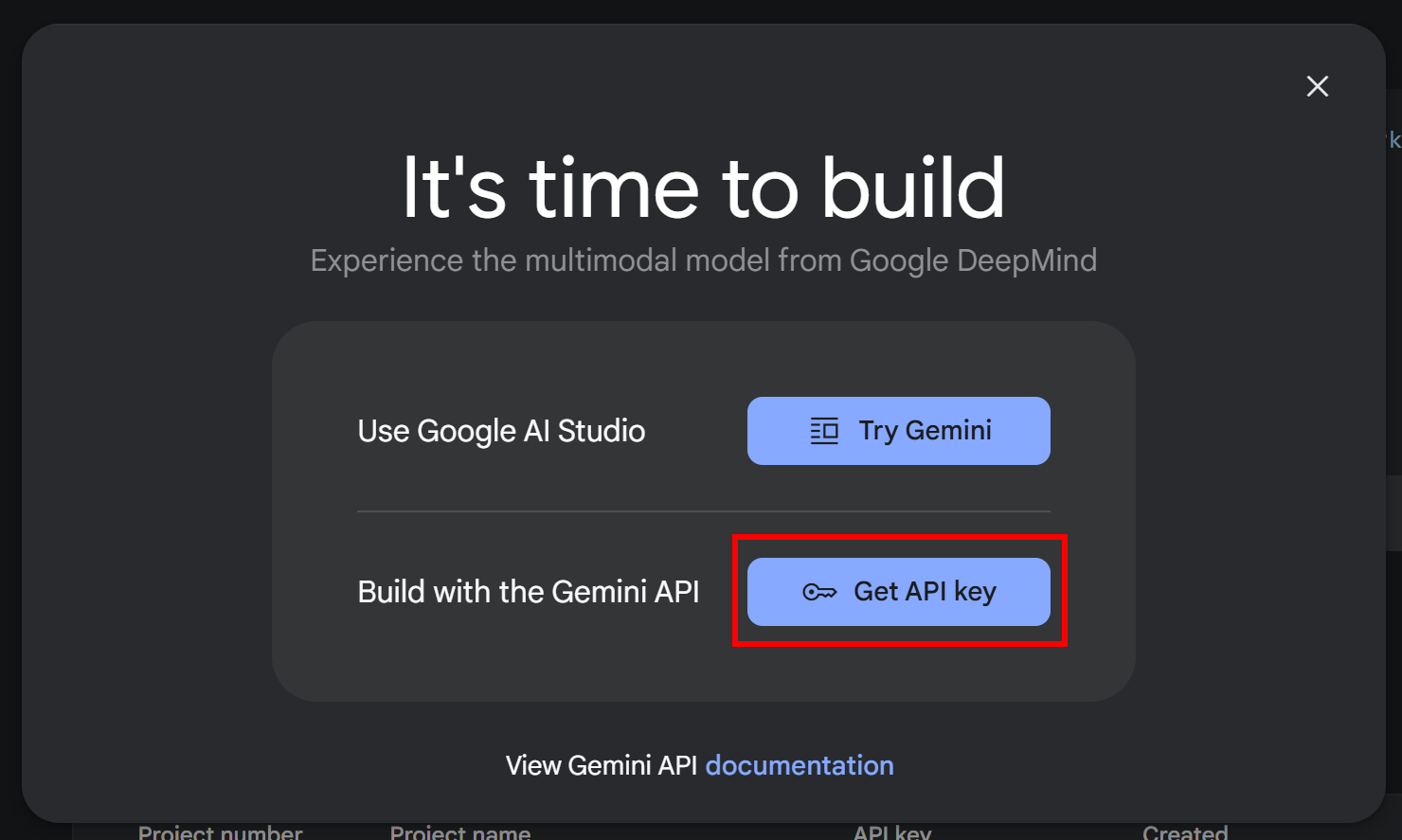
点击 “获取 API 密钥 “按钮。在下一个屏幕中,点击 “创建 API 密钥 “按钮:
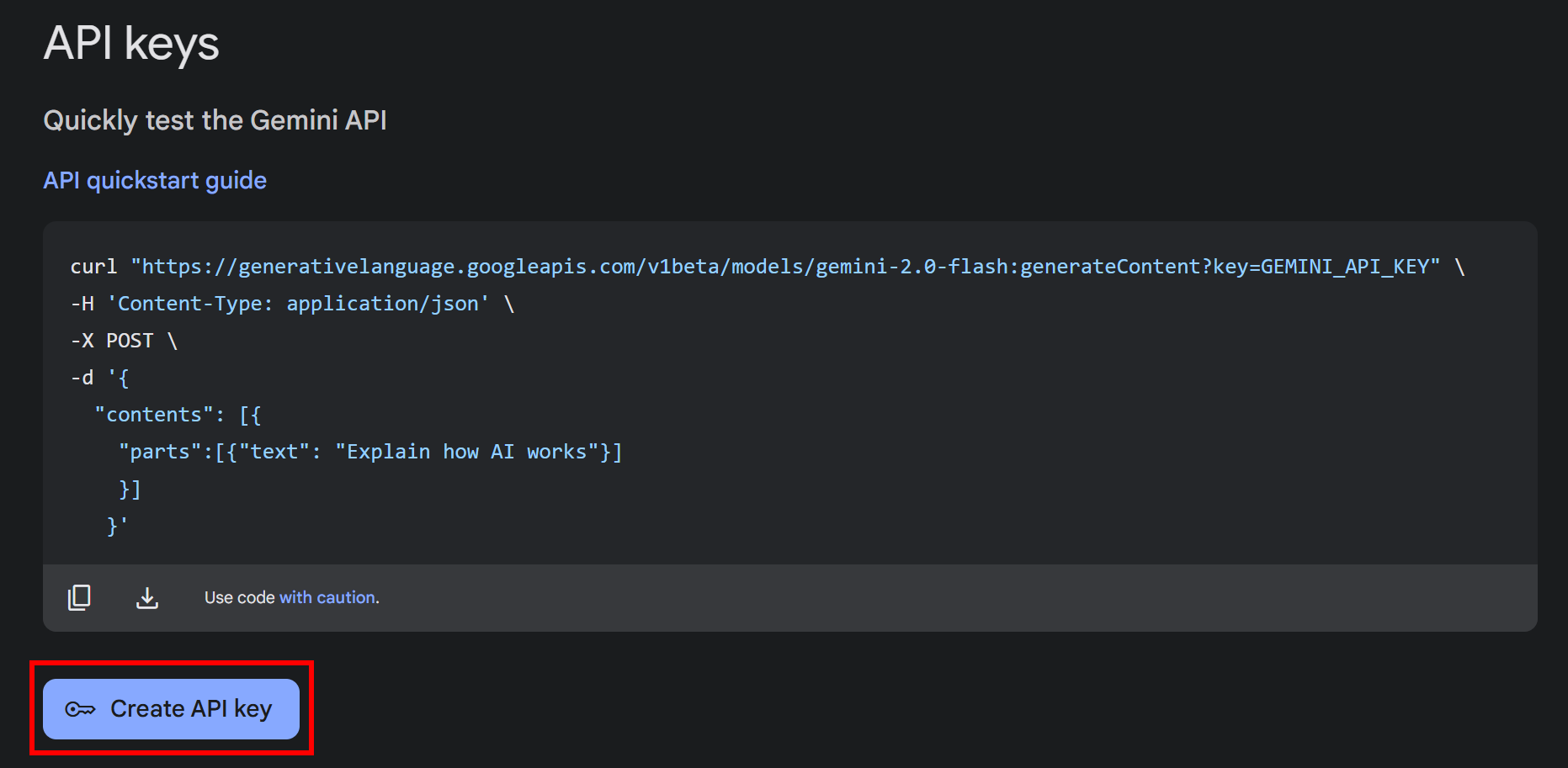
密钥生成后,您将看到模态窗口中显示您的密钥:

复制密钥并将其存放在安全的地方。请注意,使用同一密钥,您可以使用双子座执行网络抓取。
注:本教程使用免费的双子座层级即可。只有当您需要更高的费率限制或不希望您的提示和回复被用于改进 Google 产品时,才需要付费层级。请参阅双子座计费页面。
现在,用以下环境变量初始化.env文件:
GOOGLE_GENAI_USE_VERTEXAI="False"
GOOGLE_API_KEY="<YOUR_GEMINI_API_KEY>"替换为 替换为刚刚生成的实际密钥。由于google-adk库会自动查找GOOGLE_API_KEY环境变量,因此无需在agent.py中添加额外代码。
同样,GOOGLE_GENAI_USE_ VERTEXAI 设置决定 Google ADK 是否应与顶点人工智能集成。将其设置为"False "可直接使用 Gemini API。
太神奇了现在您可以在 Google ADK 中使用双子座了。让我们继续进行集成所需的第三方解决方案的初始设置。
步骤 #4:设置 Bright Data MCP 服务器
如果还没有,请 [创建一个 Bright Data 帐户]()。如果您已有账户,只需登录即可。
接下来,请按照官方说明进行操作:
- 读取您的 Bright Data API 令牌。
- 配置 Web Unlocker 和 Scraping Browser,以便集成 MCP。
您将获得
- 一个 Bright Data API 令牌。
- 一个 Web 解锁器区域(在此,我们假设它的默认名称是
mcp_unlocker)。 - 抓取浏览器验证凭证,格式为:
<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>。
现在,您可以在 Node.js 环境中全局安装Bright Data MCP 服务器:
npm install -g @brightdata/mcp然后,使用@brightdata/mcpnpm 软件包启动 MCP 服务器:
API_TOKEN="<YOUR_BRIGHT_DATA_API_TOKEN>"
BROWSER_AUTH="<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>"
npx -y @brightdata/mcp上述命令设置了所需的环境变量(API_TOKEN和BROWSER_AUTH),并在本地启动了 MCP 服务器。如果一切设置正确,你应该能看到服务器运行成功的输出:
Checking for required zones...
Required zone "mcp_unlocker" already exists
Starting server...太棒了!Bright Data MCP 服务器运行得非常好。
将这些环境变量添加到 Google ADK 项目根目录下的.env文件中:
BRIGHT_DATA_API_TOKEN="<YOUR_BRIGHT_DATA_API_TOKEN>"
BRIGHT_DATA_BROWSER_AUTH="<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>"用实际值替换占位符。
接下来,在代码中读取这些环境:
BRIGHT_DATA_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
BRIGHT_DATA_BROWSER_AUTH = os.getenv("BRIGHT_DATA_BROWSER_AUTH")完美!现在您已经做好了将 Bright Data MCP 服务器与 Google ADK 集成的一切准备。但首先,是时候定义人工智能代理了。
步骤 #5:确定代理
如导言所述,由 MCP 驱动的 Google ADK 代理将充当内容摘要代理。它的主要目标是接收用户的输入,并返回高质量、来源明确的摘要。
具体来说,代理将遵循以下工作流程:
- 解析用户请求并将其拆分为类似 Google 搜索的查询关键词。
- 通过一个子代理处理这些搜索关键词,该子代理完成以下步骤:
- 使用 Bright Data MCP 服务器提供的
search_engine工具, 通过 SERP API 从 Google 搜索结果中获取相关链接。 - 将最相关的 URL 传递给 Scraping Browser,该工具会自动访问这些页面并提取文本内容。
- 从爬取到的内容中提炼并理解核心见解。
- 使用 Bright Data MCP 服务器提供的
- 根据用户的原始查询生成一份 Markdown 格式的报告。该报告使用刚刚获取的内容作为信息来源,并附带进一步阅读的链接。
由于这一过程自然分为三个不同的阶段,因此将顶级人工智能代理分成三个子代理也是合理的:
- 规划器将复杂的主题转换为格式清晰的搜索查询。
- 研究员:执行搜索并从搜索到的网页中提取有意义的信息。
- 出版者:将研究综述为一份文笔优美、结构严谨的文件。
使用以下 Python 代码在 Google ADK 中实现这三个代理:
- 规划师
def create_planner_agent():
return Agent(
name="planner",
model="gemini-2.0-flash",
description="Breaks down user input into focused search queries for research purposes.",
instruction="""
You are a research planning assistant. Your task is to:
1. Analyze the user's input topic or question.
2. Break it down into 3 to 5 focused and diverse search engine-like queries that collectively cover the topic.
3. Return your output as a JSON object in the following format:
{
"queries": ["query1", "query2", "query3"]
}
IMPORTANT:
- The queries should be phrased as if typed into a search engine.
""",
output_key="search_queries"
)- 研究员:
def create_researcher_agent(mcp_tools):
return Agent(
name="researcher",
model="gemini-2.0-flash",
description="Performs web searches and extracts key insights from web pages using the configured tools.",
instruction="""
You are a web research agent. Your task is to:
1. Receive a list of search queries from the planner agent.
2. For each search query, apply the `search_engine` tool to get Google search results.
3. From the global results, select the top 3 most relevant URLs.
4. Pass each URL to the `scraping_browser_navigate` tool.
5. From each page, use the `scraping_browser_get_text` tool to extract the main page content.
6. Analyze the extracted text and summarize the key insights in the following JSON format:
[
{
"url": "https://example.com",
"insights": [
"Main insight one",
"Main insight two"
]
},
...
]
IMPORTANT:
- You are only allowed to use the following tools: `search_engine`, `scraping_browser_navigate`, and `scraping_browser_get_text`.
""",
tools=mcp_tools
)注意:mcp_tools输入参数是一个列表,用于指定代理可以与哪些MCP 工具交互。下一步,您将看到如何使用 Bright Data MCP 服务器提供的工具填充此列表。
- 发布者:
“`python
def create_publisher_agent():
return Agent(
name=”publisher”、
model=”gemini-2.0-flash”、
description=”将研究成果综合成全面、结构合理的最终文档”、
instruction=”””
您是一名写作专家。您的任务是利用抓取器代理提供的结构化研究成果,撰写一份条理清晰、深入浅出的报告。指导原则: - 正确使用类似 Markdown 的结构:标题 (#)、副标题、引言、章节 (##)、小章节 (###) 和结论 (##)。- 使用研究人员代理输出的 URL,整合上下文链接(如需要)。- 保持专业、客观和翔实的语气。- 不仅要重述研究结果--还要综合信息、连接观点,并以连贯的叙述方式呈现。""")
Note that each AI agent prompt corresponds to one specific step in the overall 3-step workflow. In other words, each sub-agent is responsible for a distinct task within the process.
### Step #6: Add the MCP Integration
As mentioned in the previous step, the `reasearch` agent depends on the tools exported by the Bright Data MCP server. Retrieve them with this function:python
async def initialize_mcp_tools():
print(“Connecting to Bright Data MCP…”)
tools, exit_stack = await MCPToolset.from_server(
connection_params=StdioServerParameters(
command=’npx’、
args=[“-y”, “@brightdata/mcp”]、
env={
“API_TOKEN”:bright_data_api_token、
“browser_auth”:bright_data_browser_auth、
}
)
)
print(f “MCP Toolset created successfully with {len(tools)} tools”)
tool_names = [tool.name for tool in tools] 工具名称
print(f “Available tools include:{‘,’.join(tool_names)}”)
print("MCP initialization complete!")
return tools, exit_stack要加载 MCP 工具,Google ADK 提供了MCPToolset.from_server()函数。该方法接受用于启动 MCP 服务器的命令以及任何所需的环境变量。在本例中,代码中配置的命令与步骤 #4 中用于本地测试 MCP 服务器的命令相对应。
⚠️警告:配置 MCP 工具并在代理提示中提及这些工具并不能保证库会实际使用它们。最终还是要由 LLM 来决定是否有必要使用这些工具来完成任务。请记住,Google ADK 中的 MCP 集成仍处于早期阶段,其行为可能并不总是符合预期。
干得漂亮!剩下的工作就是调用这个函数,将生成的工具集成到一个代理中,按顺序运行你的子代理。
步骤 #7:创建根代理
Google ADK 支持多种类型的代理。在这种情况下,您的工作流程遵循明确的步骤顺序,因此根顺序代理是正确的选择。您可以这样定义
async def create_root_agent():
# Load the MCP tools
mcp_tools, exit_stack = await initialize_mcp_tools()
# Define an agent that applies the configured sub-agents sequentially
root_agent = SequentialAgent(
name="web_research_agent",
description="An agent that researches topics on the web and creates comprehensive reports.",
sub_agents=[
create_planner_agent(),
create_researcher_agent(mcp_tools),
create_publisher_agent(),
]
)
return root_agent, exit_stack为了实现这一功能,Google ADK 希望您在agent.py文件中定义一个root_agent变量。请使用
root_agent = create_root_agent()注意:不要担心在这里调用不带await的异步函数。这是 Google ADK 官方文档中推荐的方法。因此,框架将为您处理异步执行。
干得好!Bright Data MCP 服务器和 Google ADK 之间的集成现已完成。
步骤 #8:将所有内容整合在一起
现在,您的agent.py文件应包含
from dotenv import load_dotenv
import os
from google.adk.agents import Agent, SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StdioServerParameters
# Load the environment variables from the .env file
load_dotenv()
# Read the envs for integration with the Bright Data MCP server
BRIGHT_DATA_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
BRIGHT_DATA_BROWSER_AUTH = os.getenv("BRIGHT_DATA_BROWSER_AUTH")
# Define the functions for the creation of the required sub-agents
def create_planner_agent():
return Agent(
name="planner",
model="gemini-2.0-flash",
description="Breaks down user input into focused search queries for research purposes.",
instruction="""
You are a research planning assistant. Your task is to:
1. Analyze the user"s input topic or question.
2. Break it down into 3 to 5 focused and diverse search engine-like queries that collectively cover the topic.
3. Return your output as a JSON object in the following format:
{
"queries": ["query1", "query2", "query3"]
}
IMPORTANT:
- The queries should be phrased as if typed into a search engine.
""",
output_key="search_queries"
)
def create_researcher_agent(mcp_tools):
return Agent(
name="researcher",
model="gemini-2.0-flash",
description="Performs web searches and extracts key insights from web pages using the configured tools.",
instruction="""
You are a web research agent. Your task is to:
1. Receive a list of search queries from the planner agent.
2. For each search query, apply the `search_engine` tool to get Google search results.
3. From the global results, select the top 3 most relevant URLs.
4. Pass each URL to the `scraping_browser_navigate` tool.
5. From each page, use the `scraping_browser_get_text` tool to extract the main page content.
6. Analyze the extracted text and summarize the key insights in the following JSON format:
[
{
"url": "https://example.com",
"insights": [
"Main insight one",
"Main insight two"
]
},
...
]
IMPORTANT:
- You are only allowed to use the following tools: `search_engine`, `scraping_browser_navigate`, and `scraping_browser_get_text`.
""",
tools=mcp_tools
)
def create_publisher_agent():
return Agent(
name="publisher",
model="gemini-2.0-flash",
description="Synthesizes research findings into a comprehensive, well-structured final document.",
instruction="""
You are an expert writer. Your task is to take the structured research output from the scraper agent and craft a clear, insightful, and well-organized report.
GUIDELINES:
- Use proper Markdown-like structure: title (#), subtitle, introduction, chapters (##), subchapters (###), and conclusion (##).
- Integrate contextual links (where needed) using the URLs from the output of the researcher agent.
- Maintain a professional, objective, and informative tone.
- Go beyond restating findings—synthesize the information, connect ideas, and present them as a coherent narrative.
"""
)
# To load the MCP tools exposed by the Bright Data MCP server
async def initialize_mcp_tools():
print("Connecting to Bright Data MCP...")
tools, exit_stack = await MCPToolset.from_server(
connection_params=StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_TOKEN,
"BROWSER_AUTH": BRIGHT_DATA_BROWSER_AUTH,
}
)
)
print(f"MCP Toolset created successfully with {len(tools)} tools")
tool_names = [tool.name for tool in tools]
print(f"Available tools include: {", ".join(tool_names)}")
print("MCP initialization complete!")
return tools, exit_stack
# Define the root agent required by Google ADK to start
async def create_root_agent():
# Load the MCP tools
mcp_tools, exit_stack = await initialize_mcp_tools()
# Define an agent that applies the configured sub-agents sequentially
root_agent = SequentialAgent(
name="web_research_agent",
description="An agent that researches topics on the web and creates comprehensive reports.",
sub_agents=[
create_planner_agent(),
create_researcher_agent(mcp_tools),
create_publisher_agent(),
]
)
return root_agent, exit_stack
# Google ADK will load the root agent in the web UI or CLI
root_agent = create_root_agent()在项目根文件夹中,启用虚拟环境后,在网络用户界面中启动人工智能代理:
adk web以下应用程序将在http://localhost:8000 上启动:
运行第一个请求后,Google ADK 库将尝试访问root_agent变量。这将触发create_root_agent()函数,进而调用initialize_mcp_tools ()。
因此,在终端中,您将看到
Connecting to Bright Data MCP...
Checking for required zones...
Required zone "mcp_unlocker" already exists
Starting server...
MCP Toolset created successfully with 30 tools
Available tools include: search_engine, scrape_as_markdown, scrape_as_html, session_stats, web_data_amazon_product, web_data_amazon_product_reviews, web_data_linkedin_person_profile, web_data_linkedin_company_profile, web_data_zoominfo_company_profile, web_data_instagram_profiles, web_data_instagram_posts, web_data_instagram_reels, web_data_instagram_comments, web_data_facebook_posts, web_data_facebook_marketplace_listings, web_data_facebook_company_reviews, web_data_x_posts, web_data_zillow_properties_listing, web_data_booking_hotel_listings, web_data_youtube_videos, scraping_browser_navigate, scraping_browser_go_back, scraping_browser_go_forward, scraping_browser_links, scraping_browser_click, scraping_browser_type, scraping_browser_wait_for, scraping_browser_screenshot, scraping_browser_get_text, scraping_browser_get_html
MCP initialization complete!可以看到,Google ADK 正确加载了 30 个 Bright Data MCP 工具。
现在,在聊天中输入请求后,人工智能代理会:
- 将用户的请求转换为类似搜索引擎关键词的格式;
- 使用
search_engineMCP 工具执行以下步骤:- 检索与关键词最匹配的页面。
- 从结果中选取与请求最相关的前 3 条记录。
- 使用
scraping_browser_navigate工具访问这些 URL。 - 通过
scraping_browser_get_text提取页面文本内容。 - 将提取到的文本归纳为关键的可操作洞察。
- 基于这些洞察撰写一篇与上下文相关的文章或报告,以回答用户的需求。
请注意,如步骤 #6 所述,Gemini(或任何其他 LLM)有时可能会完全跳过 MCP 工具。即使这些工具已在代码中配置并在子代理提示中明确提及,情况也是如此。具体来说,它可能会直接返回响应或运行子代理,而不使用推荐的 MCP 工具。
为避免这种副作用,请仔细调整您的子代理提示。此外,请记住,Google ADK 中的 MCP 集成仍在不断演进,其行为可能并不总是符合预期。因此,请确保库是最新的。
现在,假设您想知道最近当选的教皇的传记。通常情况下,LLM 会很难处理当前事件查询。但是,有了 Bright Data 的 SERP API 和网络抓取功能,您的人工智能代理就可以毫不费力地获取和汇总实时信息:

好了!任务完成
结论
在这篇博文中,您将了解到如何将 Google ADK 框架与 Bright Data MCP 结合使用,在 Python 中构建一个功能强大的人工智能代理。
如图所示,将功能丰富的 MCP 服务器与 Google ADK 相结合,您就可以创建能够从网络上检索实时数据等的人工智能代理。这只是 Bright Data 的工具和服务如何支持先进的人工智能驱动自动化的一个例子。
探索我们的人工智能代理开发解决方案:
- 自主人工智能代理:使用一套功能强大的应用程序接口,实时搜索、访问任何网站并与之互动。
- 垂直 AI 应用程序:建立可靠的自定义数据管道,从特定行业来源提取网络数据。
- 基础模型:访问符合要求的网络规模数据集,以便进行预训练、评估和微调。
- 多模态人工智能:利用世界上最大的图像、视频和音频资源库,为人工智能进行优化。
- 数据提供商:与值得信赖的提供商建立联系,大规模地获取高质量的人工智能就绪数据集。
- 数据包:获取精心策划、随时可用、结构化、丰富和注释的数据集。
如需了解更多信息,请访问我们的人工智能中心。
创建 Bright Data 帐户,试用我们为人工智能代理开发提供的所有产品和服务!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




