

在几十个 Google 搜索结果之间手动做内容研究既耗时又容易错过分散在多个来源中的关键信息。传统的网页抓取只能得到原始 HTML,缺乏将信息综合为连贯叙事的智能。本指南将教你构建一个 AI 系统,自动抓取 Google SERP 结果,用嵌入向量分析内容,并生成完整的文章或大纲。
你将学到:
- 如何使用 Bright Data 与向量嵌入构建自动化的“研究到文章”流水线
- 如何对抓取内容进行语义分析并识别反复出现的主题
- 如何使用大语言模型生成结构化大纲和完整文章
- 如何创建用于内容生成的交互式 Streamlit 界面
开始吧!
内容创作研究的挑战
内容创作者在为文章、博客或营销材料做选题研究时会面临很多障碍。手动研究往往需要打开几十个浏览器标签页,阅读冗长的文章,并尝试从不同来源综合信息。这一过程易出错、耗时且难以规模化。
使用 BeautifulSoup 或 Scrapy 的传统抓取方法能提供原始 HTML 文本,但缺乏理解内容语境、识别关键主题或在多来源之间综合信息的智能。最终得到的只是非结构化文本集合,仍需大量人工处理。
将 Bright Data 的强大抓取能力与现代 AI 技术(如向量嵌入和大语言模型)结合,可自动化整个“研究到文章”的流水线,将数小时的人工工作转化为几分钟的自动化分析。
我们要构建什么:AI 驱动的内容研究系统
你将创建一个智能内容生成系统,可针对任意关键词自动抓取 Google 搜索结果。系统会从目标网页提取完整内容,利用向量嵌入分析信息以识别主题与洞见,并通过直观的 Streamlit 界面生成结构化文章大纲或完整文章初稿。
前置条件
按以下要求配置你的开发环境:
- Python 3.9 或更高版本
- Bright Data 账户:注册并创建 API 令牌(提供免费试用额度)
- OpenAI API Key:在 OpenAI 控制台创建,用于嵌入和 LLM 访问
- Python 虚拟环境:隔离依赖
- LangChain + 向量嵌入(FAISS):负责内容分析与存储
- Streamlit:提供交互式用户界面,便于使用该工具
环境搭建
创建项目目录并安装依赖。先设置一个干净的虚拟环境以避免与其他 Python 项目冲突。
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenv创建名为 article_generator.py 的新文件,并添加以下导入。这些库用于网页抓取、文本处理、嵌入与用户界面。
import streamlit as st
import os
import json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
load_dotenv()Bright Data 配置
使用环境变量安全地存储你的 API 凭证。创建 .env 文件以保存凭证,将敏感信息与代码分离。
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token_here"
BRIGHT_DATA_ZONE="your_serp_zone_name"
OPENAI_API_KEY="your_openai_api_key_here"你需要:
- Bright Data API 令牌:在 Bright Data 控制台中生成
- SERP 抓取 Zone:创建一个针对 Google SERP 的 Web Scraper Zone
- OpenAI API Key:用于嵌入与 LLM 文本生成
在 article_generator.py 中配置 API 连接。以下类负责与 Bright Data 抓取基础设施的所有通信。
class BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("No MCP tools available")
return {'results': []}
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'search_engine' in tool_name and 'batch' not in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(query=keyword)
elif hasattr(tool, 'run'):
result = tool.run(query=keyword)
elif hasattr(tool, '__call__'):
result = tool(query=keyword)
else:
result = tool.search_engine(query=keyword)
if result:
return self._parse_serp_results(result)
except Exception as method_error:
st.warning(f"Method failed for {tool_name}: {str(method_error)}")
continue
except Exception as tool_error:
st.warning(f"Tool {tool_name} failed: {str(tool_error)}")
continue
st.warning(f"No search_engine tool could process: {keyword}")
return {'results': []}
except Exception as e:
st.error(f"MCP scraping failed: {str(e)}")
return {'results': []}
def _parse_serp_results(self, mcp_result):
"""Parse MCP tool results into expected format."""
if isinstance(mcp_result, dict) and 'results' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
return {'results': mcp_result}
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
else:
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results': parsed}
except:
return {'results': []}
def _parse_html_search_results(self, html_content):
"""Parse HTML search results page to extract search results."""
import re
results = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
links = re.findall(link_pattern, html_content, re.DOTALL)
for link_url, link_text in links:
if (link_url.startswith('http') and
not any(skip in link_url for skip in [
'google.com', 'accounts.google', 'support.google',
'/search?', 'javascript:', '#', 'mailto:'
])):
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title and len(clean_title) > 10:
results.append({
'url': link_url,
'title': clean_title[:200],
'snippet': '',
'position': len(results) + 1
})
if len(results) >= 10:
break
if not results:
specific_pattern = r'[(.*?)]((https?://[^)]+))'
matches = re.findall(specific_pattern, html_content)
for title, url in matches:
if not any(skip in url for skip in ['google.com', '/search?']):
results.append({
'url': url,
'title': title.strip(),
'snippet': '',
'position': len(results) + 1
})
if len(results) >= 10:
break
return {'results': results}构建文章生成器
步骤一:抓取 SERP 与目标页面
系统的基础是全面的数据收集。你需要构建一个抓取器,先提取 Google SERP 结果,再跟进这些链接,从最相关的来源收集完整页面内容。
class ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def extract_serp_urls(self, keyword, max_results=10):
"""Extract URLs from Google SERP results."""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
results_list = serp_data.get('results', [])
for result in results_list:
if 'url' in result and self.is_valid_url(result['url']):
urls.append({
'url': result['url'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
elif 'link' in result and self.is_valid_url(result['link']):
urls.append({
'url': result['link'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
return urls
def is_valid_url(self, url):
"""Filter out non-article URLs like images, PDFs, or social media."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) and
not any(ext in url.lower() for ext in excluded_extensions))
def scrape_page_content(self, url, max_length=10000):
"""Extract clean text content from a webpage using Bright Data MCP tools."""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("No MCP tools available for content scraping")
return ""
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'scrape_as_markdown' in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(url=url)
elif hasattr(tool, 'run'):
result = tool.run(url=url)
elif hasattr(tool, '__call__'):
result = tool(url=url)
else:
result = tool.scrape_as_markdown(url=url)
if result:
content = self._extract_content_from_result(result)
if content:
return self._clean_content(content, max_length)
except Exception as method_error:
st.warning(f"Method failed for {tool_name}: {str(method_error)}")
continue
except Exception as tool_error:
st.warning(f"Tool {tool_name} failed for {url}: {str(tool_error)}")
continue
st.warning(f"No scrape_as_markdown tool could scrape: {url}")
return ""
except Exception as e:
st.warning(f"Failed to scrape {url}: {str(e)}")
return ""
def _extract_content_from_result(self, result):
"""Extract content from MCP tool result."""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['content', 'text', 'body', 'html']:
if key in result and result[key]:
return result[key]
elif isinstance(result, list) and len(result) > 0:
return str(result[0])
return str(result) if result else ""
def _clean_content(self, content, max_length):
"""Clean and format scraped content."""
if isinstance(content, dict):
content = content.get('text', content.get('content', str(content)))
if '<' in content and '>' in content:
import re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
lines = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
return text[:max_length]该抓取器会智能过滤 URL,聚焦文章内容,避免图片、PDF 或社交媒体链接,这些通常无法提供有价值的文本用于分析。
步骤二:向量嵌入与内容分析
将抓取的内容转换为可搜索的向量嵌入,以捕捉语义信息并实现智能内容分析。嵌入过程将文本转化为机器可理解并可比较的数值表示。
class ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", ".", "!", "?", ",", " ", ""]
)
def process_content(self, scraped_data):
"""Convert scraped content into embeddings and analyze themes."""
all_texts = []
metadata = []
for item in scraped_data:
if item['content']:
chunks = self.text_splitter.split_text(item['content'])
for chunk in chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url'],
'title': item['title'],
'position': item['position']
})
if not all_texts:
raise ValueError("No content available for analysis")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, all_texts, metadata
def identify_themes(self, vectorstore, query_terms, k=5):
"""Use semantic search to identify key themes and topics."""
theme_analysis = {}
for term in query_terms:
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = {
'relevant_chunks': len(similar_docs),
'key_passages': [doc.page_content[:200] + "..." for doc in similar_docs[:3]],
'sources': list(set([doc.metadata['url'] for doc in similar_docs]))
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata):
"""Generate statistical summary of scraped content."""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_sources': len(set(meta['url'] for meta in metadata)),
'total_chunks': total_chunks,
'total_words': total_words,
'avg_chunk_length': round(avg_chunk_length, 1)
}分析器将内容分解为语义块,创建一个可搜索的向量数据库,以实现智能主题识别与内容综合。
步骤三:使用 LLM 生成文章或大纲
将分析后的内容转化为结构化输出,使用精心设计的提示,充分利用嵌入分析中的语义洞见。LLM 会基于你的研究数据生成连贯、结构良好的内容。
class ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7,
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""Generate a structured article outline based on research data."""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f"""
Based on comprehensive research about "{keyword}", create a detailed article outline.
Research Summary:
- Analyzed {content_summary['total_sources']} sources
- Processed {content_summary['total_words']} words of content
- Identified key themes and insights
Key Themes Found:
{themes_text}
Create a structured outline with:
1. Compelling headline
2. Introduction hook and overview
3. 4-6 main sections with subsections
4. Conclusion with key takeaways
5. Suggested call-to-action
Format as markdown with clear hierarchy.
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""Generate a complete article draft."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f"""
Write a comprehensive {target_length}-word article about "{keyword}" based on extensive research.
Research Foundation:
{themes_text}
Content Requirements:
- Engaging introduction that hooks readers
- Well-structured body with clear sections
- Include specific insights and data points from research
- Professional, informative tone
- Strong conclusion with actionable takeaways
- SEO-friendly structure with subheadings
Write the complete article in markdown format.
"""
return self.llm(article_prompt)
def _format_themes_for_prompt(self, theme_analysis):
"""Format theme analysis for LLM consumption."""
formatted_themes = []
for theme, data in theme_analysis.items():
theme_info = f"**{theme}**: Found in {data['relevant_chunks']} content sectionsn"
theme_info += f"Key insights: {data['key_passages'][0][:150]}...n"
theme_info += f"Sources: {len(data['sources'])} unique referencesn"
formatted_themes.append(theme_info)
return "n".join(formatted_themes)生成器可产出两种不同的输出格式:用于内容规划的结构化大纲,以及可直接发布的完整文章。两种输出都基于对抓取内容的语义分析。

步骤四:构建 Streamlit 界面
创建直观的界面,引导用户完成内容生成流程,并提供实时反馈与自定义选项。该界面让复杂的 AI 操作对非技术用户也可用。
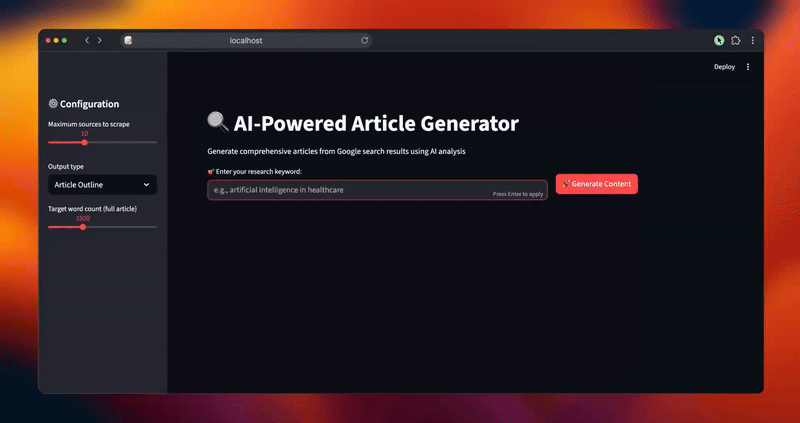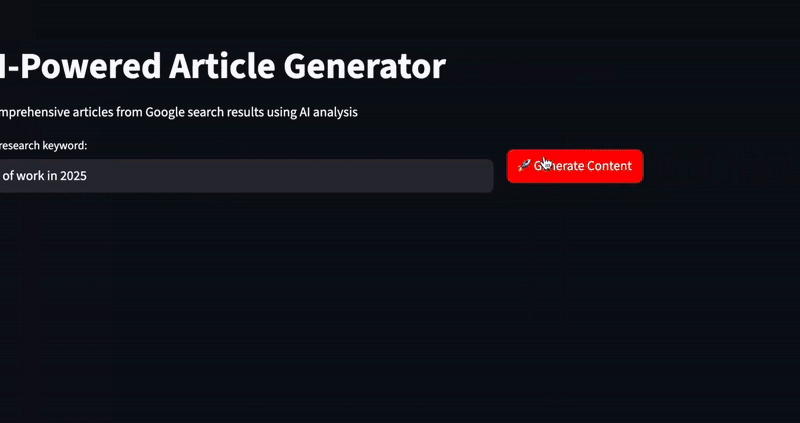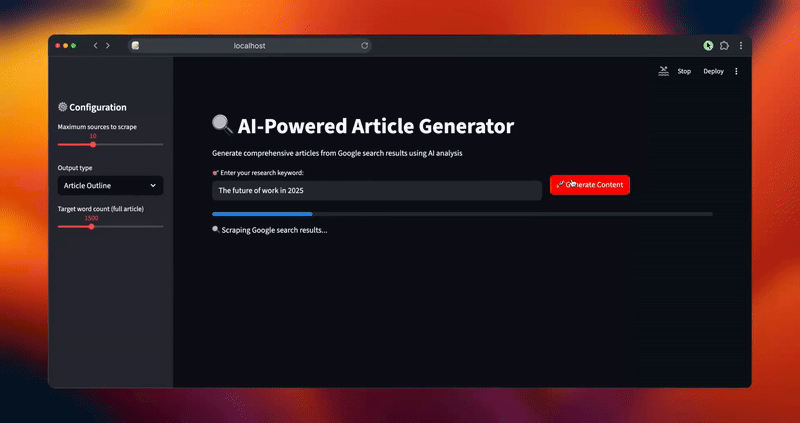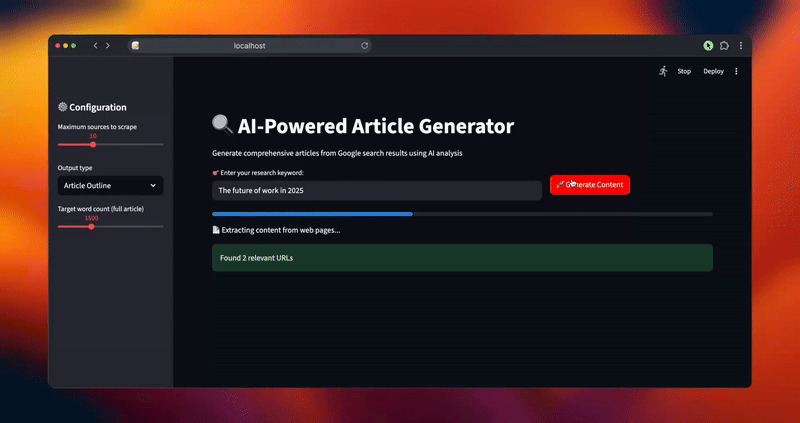
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide")
st.title("🔍 AI-Powered Article Generator")
st.markdown("Generate comprehensive articles from Google search results using AI analysis")
scraper = ContentScraper()
analyzer = ContentAnalyzer()
generator = ArticleGenerator()
st.sidebar.header("⚙️ Configuration")
max_sources = st.sidebar.slider("Maximum sources to scrape", 5, 20, 10)
output_type = st.sidebar.selectbox("Output type", ["Article Outline", "Full Article"])
target_length = st.sidebar.slider("Target word count (full article)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
with col1:
keyword = st.text_input("🎯 Enter your research keyword:", placeholder="e.g., artificial intelligence in healthcare")
with col2:
st.write("")
generate_button = st.button("🚀 Generate Content", type="primary")
if generate_button and keyword:
try:
progress_bar = st.progress(0)
status_text = st.empty()
status_text.text("🔍 Scraping Google search results...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f"Found {len(urls)} relevant URLs")
status_text.text("📄 Extracting content from web pages...")
progress_bar.progress(0.4)
scraped_data = []
for i, url_data in enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url'],
'title': url_data['title'],
'content': content,
'position': url_data['position']
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("🧠 Analyzing content with AI embeddings...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword] + keyword.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ Generating AI-powered content...")
progress_bar.progress(0.9)
if output_type == "Article Outline":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
else:
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
progress_bar.progress(1.0)
status_text.text("✅ Content generation complete!")
st.markdown("---")
st.subheader(f"📊 Research Analysis for '{keyword}'")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Sources Analyzed", content_summary['total_sources'])
with col2:
st.metric("Content Chunks", content_summary['total_chunks'])
with col3:
st.metric("Total Words", content_summary['total_words'])
with col4:
st.metric("Avg Chunk Size", f"{content_summary['avg_chunk_length']} words")
with st.expander("🎯 Key Themes Identified"):
for theme, data in theme_analysis.items():
st.write(f"**{theme}**: {data['relevant_chunks']} relevant sections found")
st.write(f"Sample insight: {data['key_passages'][0][:200]}...")
st.write(f"Sources: {len(data['sources'])} unique references")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Generated {output_type}")
st.markdown(result)
st.download_button(
label="💾 Download Content",
data=result,
file_name=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ Generation failed: {str(e)}")
st.write("Please check your API credentials and try again.")
if __name__ == "__main__":
main()Streamlit 界面提供直观的工作流、实时进度跟踪、可自定义参数,并可立即预览研究分析与生成内容。用户可将结果以 Markdown 格式下载,以便进一步编辑或发布。
运行你的文章生成器
运行应用以开始从网络研究生成内容。在终端中进入你的项目目录:
streamlit run article_generator.py你将看到系统在处理请求时的智能工作流:
- 从 Google SERP 提取全面的搜索结果,并进行相关性过滤
- 带有反机器人保护地抓取目标网页的完整内容
- 使用向量嵌入与主题识别对内容进行语义处理
- 在多来源之间分析重复模式与关键信息
- 生成结构化、流程清晰、格式专业的内容
最后思考
你现在拥有一个完整的文章生成系统,可自动从多个来源收集研究数据,并将其转化为全面的内容。该系统执行语义内容分析,识别跨来源的重复主题,并生成结构化的文章或大纲。
你可以通过调整抓取目标与分析标准,将该框架适配到不同的行业。模块化设计也允许你根据需求演进,添加新的内容平台、嵌入模型或生成模板。
若要构建更高级的工作流,请探索 Bright Data AI 基础设施中用于获取、验证与转换实时网络数据的完整解决方案。
创建一个免费的 Bright Data 账户,开始体验我们的面向 AI 的网页数据解决方案吧!



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





