

在本教程中,你将学习:
- 什么是 AWS Bedrock AI 代理,以及它能做什么。
- 为何通过 Bright Data 的 SERP API 等 AI 就绪工具为代理提供网页搜索结果能提升准确性与上下文理解。
- 如何在 AWS 控制台中一步步构建集成 SERP API 的 AWS Bedrock 代理。
- 如何使用 AWS CDK 以代码方式实现同样的效果。
我们开始吧!
什么是 AWS Bedrock AI 代理?
在 AWS Bedrock 中,AI 代理是一项利用大语言模型(LLM)将多步任务拆解为逻辑步骤并自动化执行的服务。更具体而言,Amazon Bedrock AI 代理利用基础模型、API 和数据来理解用户请求、收集相关信息并自动完成任务。
AWS Bedrock 代理支持任务连续性的记忆功能、通过 Bedrock Guardrails 提供的内置安全,并可与其他代理协作以处理复杂工作流。得益于 AWS 基础设施,它们是托管的、可扩展且无服务器的,从而简化了构建与部署 AI 驱动应用的流程。
为什么 Amazon Bedrock 中的 AI 代理需要动态网页搜索上下文
LLM 由大规模数据集训练而成,其知识只覆盖到某个时间点。这意味着模型发布时,只能“知道”其训练数据中包含的内容,并会很快过时。
因此,AI 模型缺乏对实时事件与新兴知识的感知,可能产生过时、不正确甚至幻觉的回答,这在 AI 代理中是一个大问题。
可以在RAG(检索增强生成)架构中赋予你的 AI 代理获取最新、可靠信息的能力来克服该限制。核心思路是为代理配备一个可靠的工具,能够执行网页搜索并检索可验证的数据,以支持其推理、扩展知识并最终输出更准确的结果。
一种做法是构建自定义 AWS Lambda 函数来抓取搜索引擎结果页(SERP),并将数据准备为可供 LLM 摄取的形式。然而,这种方式技术门槛较高,需要处理 JavaScript 渲染、验证码(CAPTCHA)以及不断变化的网站结构。此外,它也不易扩展,因为像 Google 这样的搜索引擎可能在少量自动化请求后迅速封禁你的 IP。
更好的解决方案是使用顶级的 SERP 与网页搜索 API,例如Bright Data 的 SERP API。该服务返回搜索引擎数据,并自动处理代理池、解封、数据解析等所有难题。
通过在 AWS Bedrock 中借助 Lambda 函数集成 Bright Data 的 SERP API,你的 AI 代理即可获得网页搜索能力——而无需承担运维负担。下面来看看如何实现!
如何将 Bright Data SERP API 集成到你的 AWS Bedrock AI 代理中以实现搜索上下文化的用例
在这一分步教程中,你将学习如何让 AWS Bedrock AI 代理通过 Bright Data SERP API 从搜索引擎获取实时数据。
集成完成后,代理能够给出更具上下文、更加及时的答案,并附上相关链接以供延伸阅读。整个配置主要在 AWS Bedrock 控制台中可视化完成,仅需少量代码。
按照以下步骤构建一个由 SERP API 赋能的 AWS Bedrock AI 代理!
先决条件
要跟随本教程,你需要:
- 一个有效的AWS 账号(免费试用即可)。
- 已完成 Amazon Bedrock Agents 的前置条件设置。(注意:Amazon Bedrock Agents 目前仅在部分区域可用。请查看最新支持区域列表并确保你使用的是其中之一。)
- 一个带 API Key 的Bright Data 账号。
- 基础的 Python 编程技能。
如果你尚未创建 Bright Data 账号,不用担心。稍后会有引导步骤。
步骤一:创建 AWS Bedrock 代理
要创建 AWS Bedrock AI 代理,登录你的 AWS 账号,搜索并打开Amazon Bedrock 控制台:
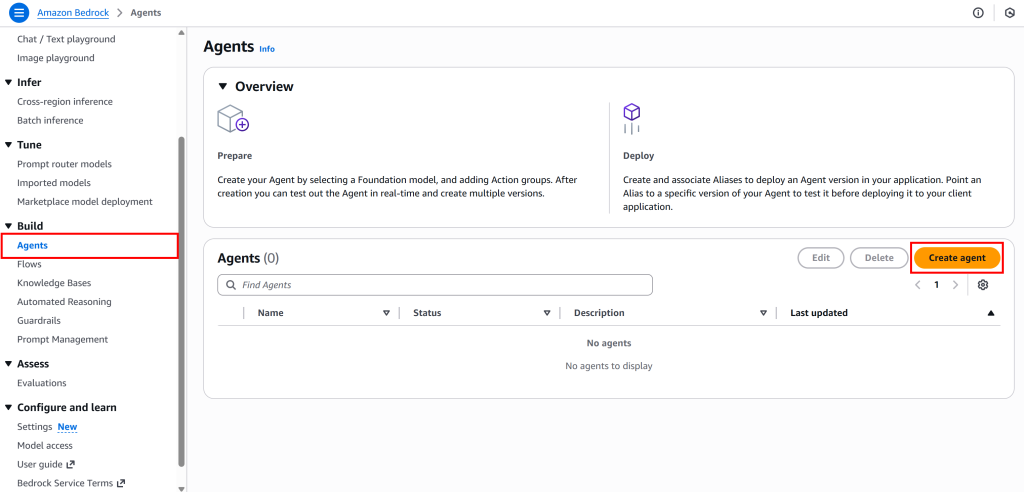
接着,在 Bedrock 控制台左侧菜单选择“Agents”,点击“Create agent”按钮:
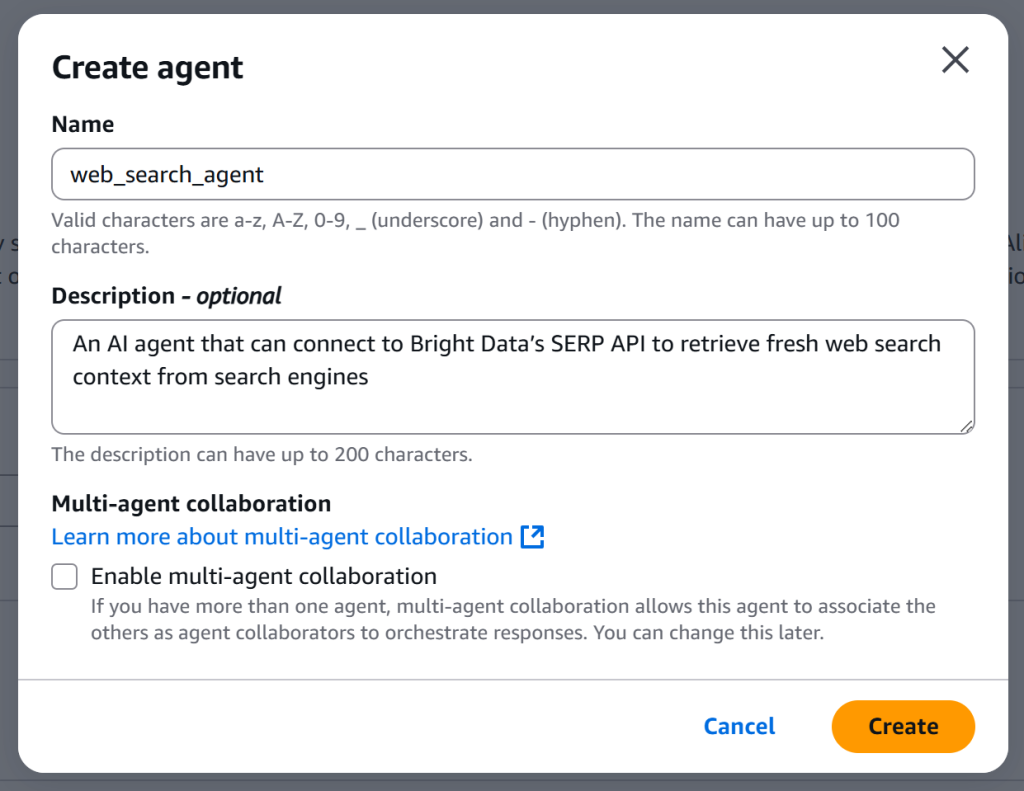
为你的代理命名并添加描述,例如:
- 名称:
web_search_agent - 描述:“一个可连接 Bright Data 的 SERP API,从搜索引擎检索最新网页搜索上下文的 AI 代理。”
重要:如果你计划使用 Amazon 的 LLM,代理名称、函数等必须使用下划线(_)而不是连字符(-)。使用连字符可能导致“Dependency resource: received model timeout/error exception from Bedrock. If this happens, try the request again.”错误。
点击“Create”创建代理,你将被重定向至“Agent builder”页面:
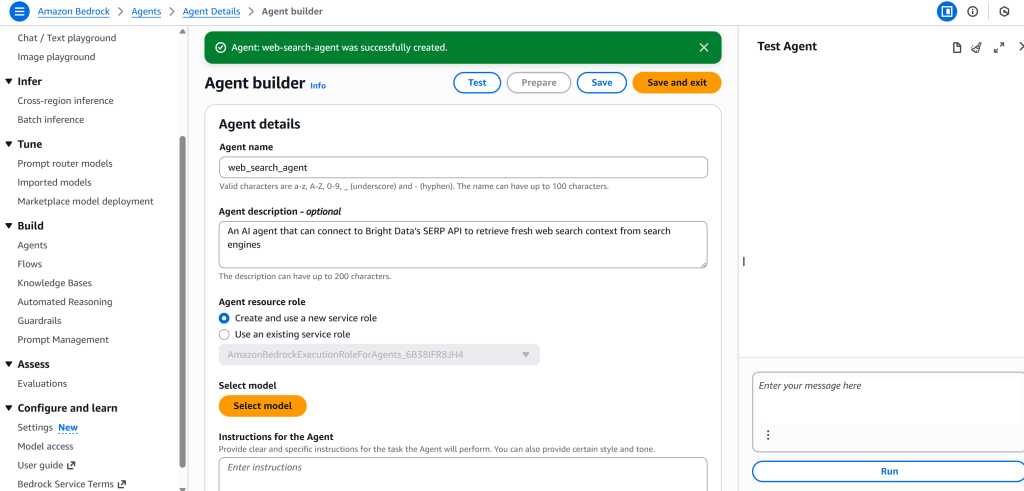
很好!你已成功在 AWS Bedrock 中创建了一个 AI 代理。
步骤二:配置 AI 代理
创建代理后,需要通过配置若干选项来完成设置。
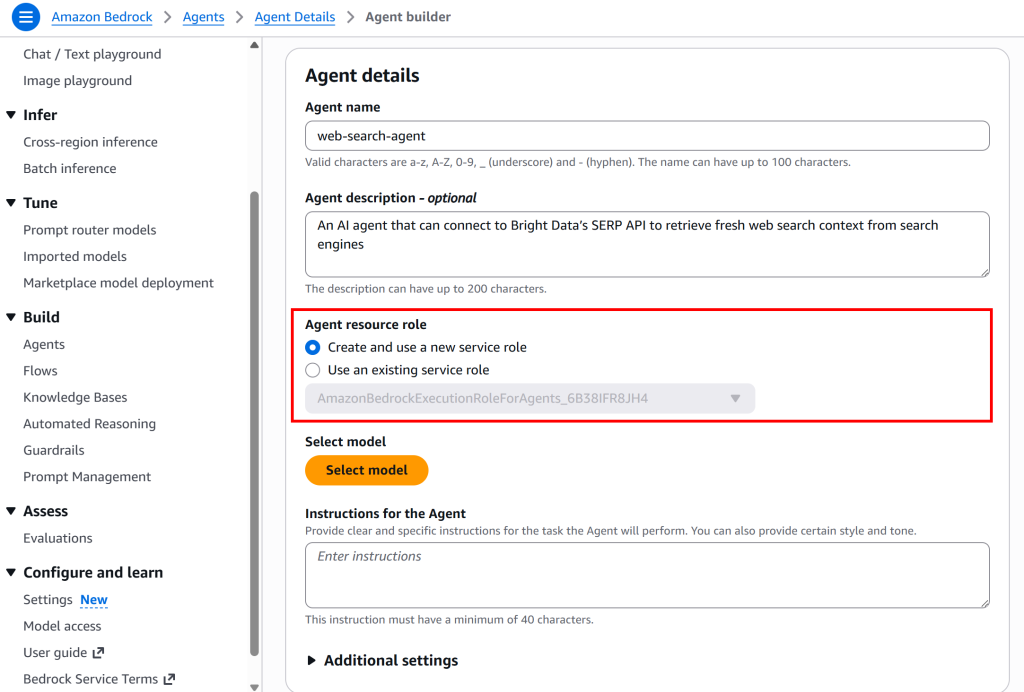
在“Agent resource role”处,保持默认的“Create and use a new service role”。这会自动创建一个代理可承担的AWS 身份与访问管理(IAM)角色:
然后点击“Select model”选择用于驱动代理的 LLM。本示例使用 Amazon 的“Nova Lite”模型(也可选择其他模型):
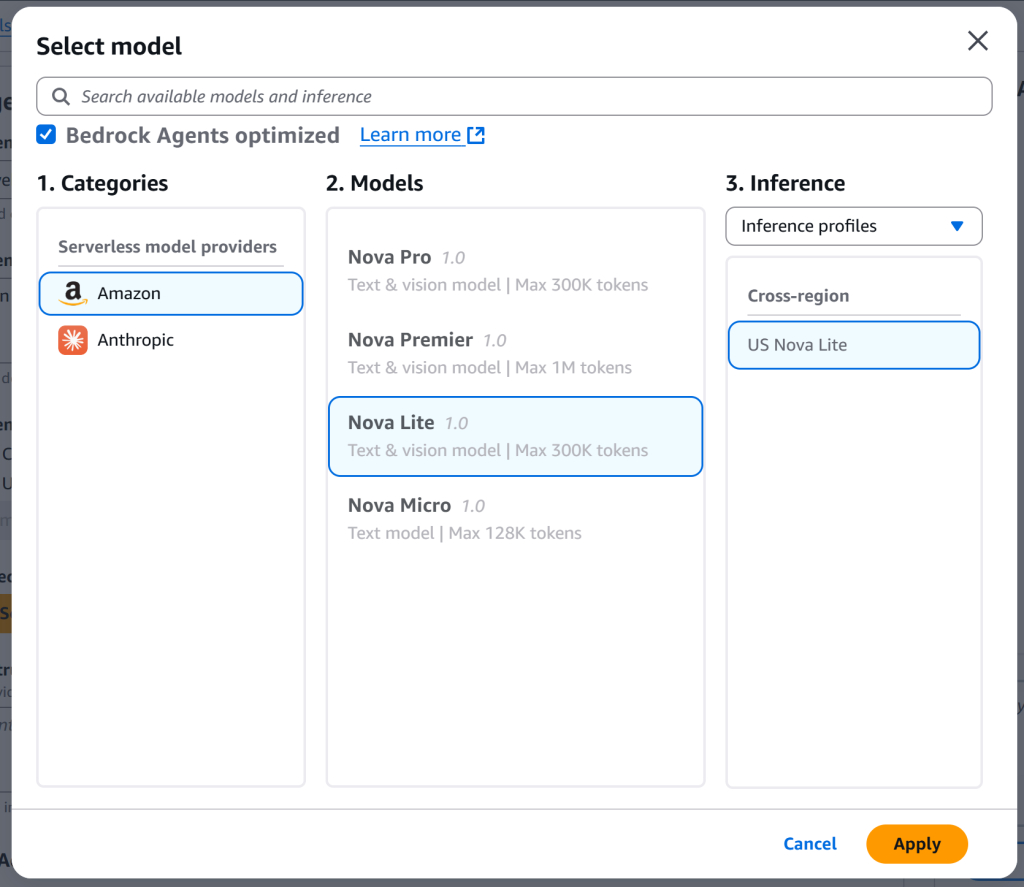
选择完模型后点击“Apply”确认。
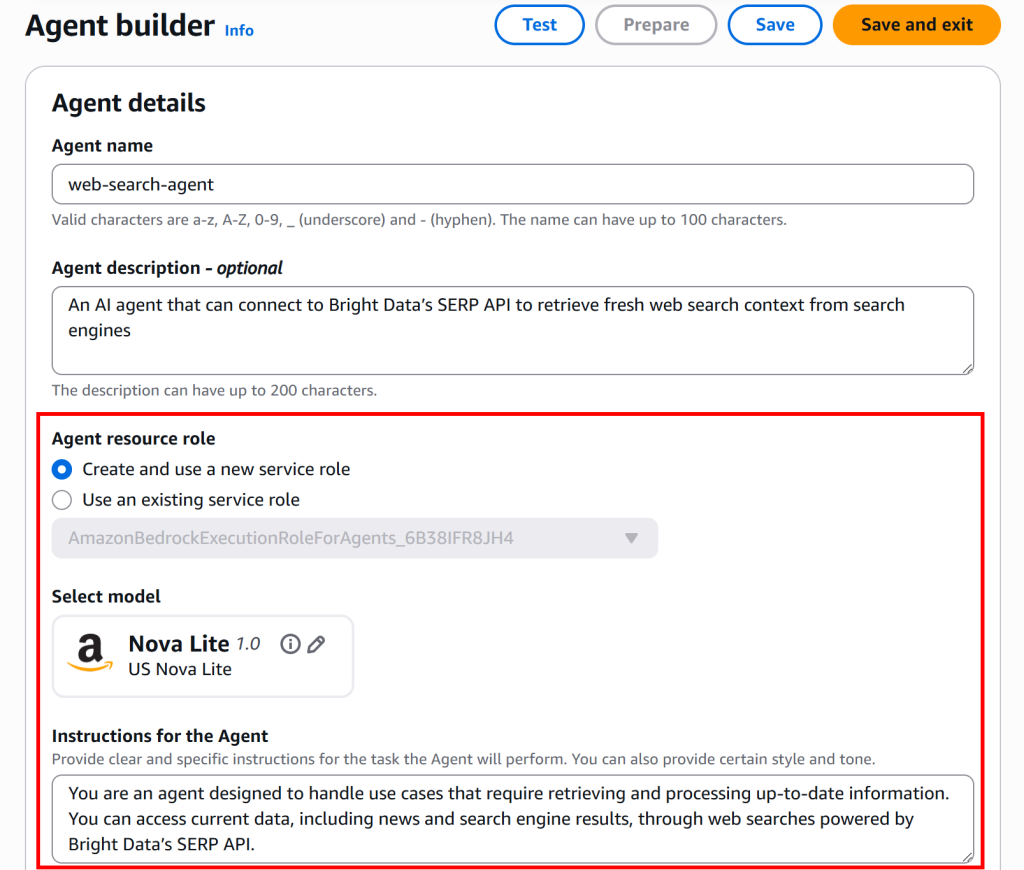
在“Instructions for the Agent”部分,提供明确具体的指令,告诉代理该做什么。对于本网页搜索代理,你可以输入如下内容:
You are an agent designed to handle use cases that require retrieving and processing up-to-date information. You can access current data, including news and search engine results, through web searches powered by Bright Data’s SERP API.完成指令后,最终代理详情应如下所示:
点击顶部栏的“Save”保存所有代理详情,完成代理详情配置。
注意:AWS Bedrock 还提供许多其他配置选项。可根据你的具体用例进行探索与调整。
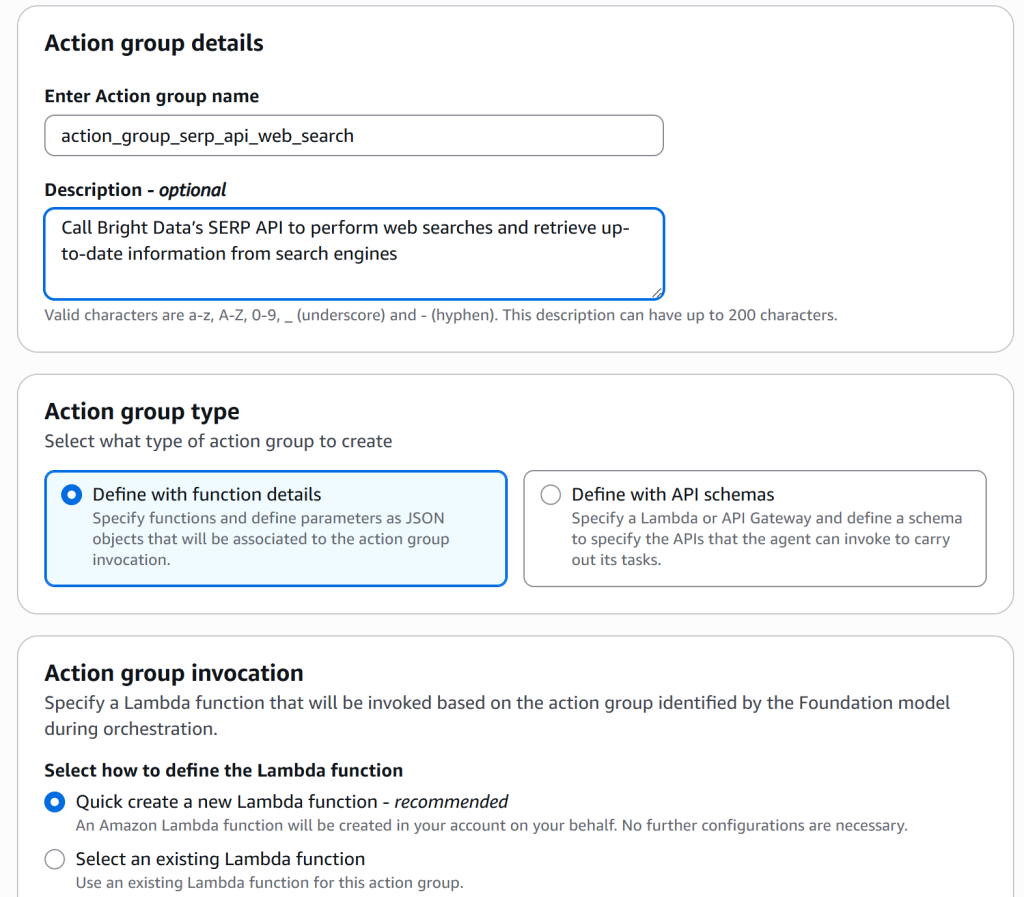
步骤三:添加 SERP API 操作组(Action Group)
操作组允许代理与外部系统或 API 交互以收集信息或执行操作。你需要定义一个操作组来集成 Bright Data 的 SERP API。
在“Agent builder”页面向下滚动至“Action groups”部分,点击“Add”:
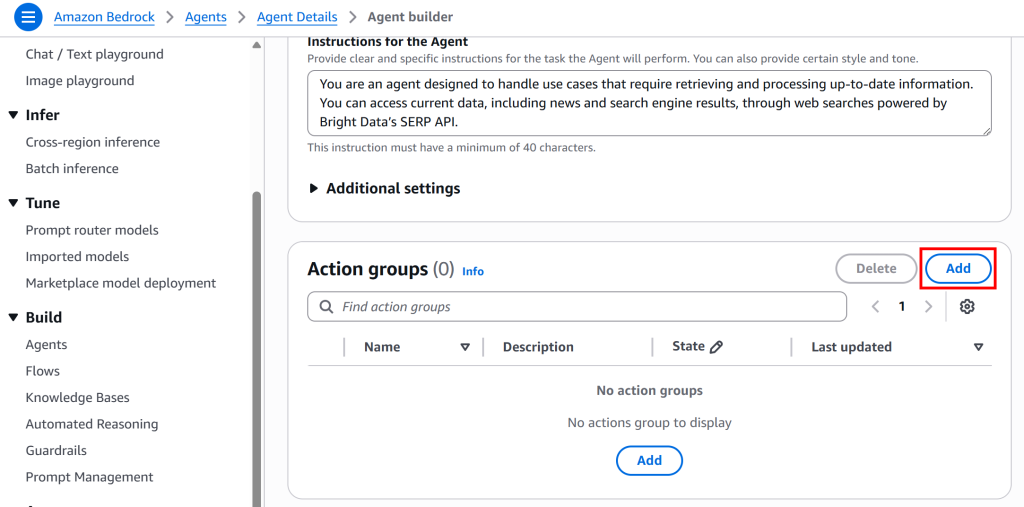
这将打开一个用于定义操作组的表单。按如下填写:
- Enter Action group name:
action_group_web_search(同样使用下划线_,不要用连字符-) - Description:“调用 Bright Data 的 SERP API 执行网页搜索并从搜索引擎检索最新信息。”
- Action group type:选择“Define with function details”。
- Action group invocation:选择“Quick create a new Lambda function”,这会创建一个代理可调用的基础Lambda 函数。该函数将负责调用 Bright Data 的 SERP API 的逻辑。
注意:选择“Quick create a new Lambda function”后,Amazon Bedrock 会为你的代理生成一个 Lambda 函数模板。你可以稍后在 Lambda 控制台中修改此函数(我们会在后续步骤中进行)。
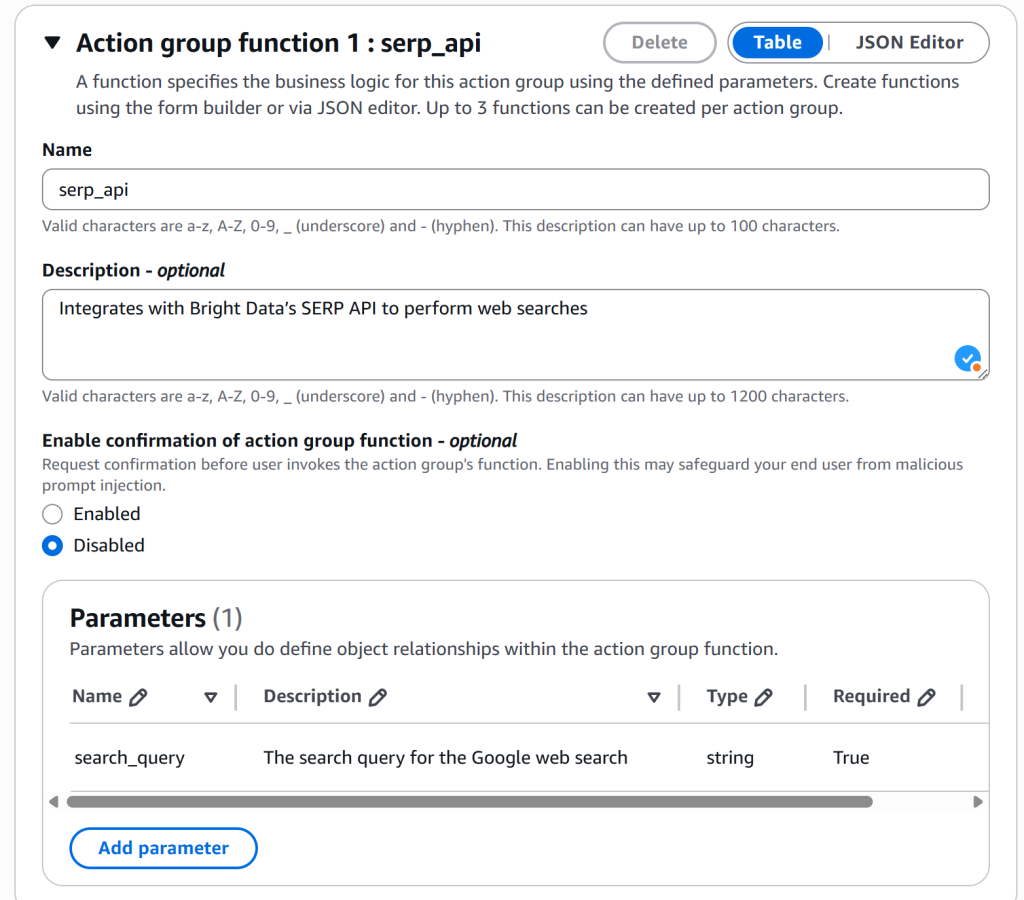
现在配置组内的函数。向下滚动至“Action group function 1: serp_api”部分,按如下填写:
- Name:
serp_api(仍然建议用下划线)。 - Description:“集成 Bright Data 的 SERP API 以执行网页搜索。”
- Parameters:添加一个名为
search_query的字符串参数,并标记为必填。该参数将传入 Lambda 函数,作为 Bright Data SERP API 检索网页搜索上下文的输入。
最后,点击“Create”完成操作组设置:
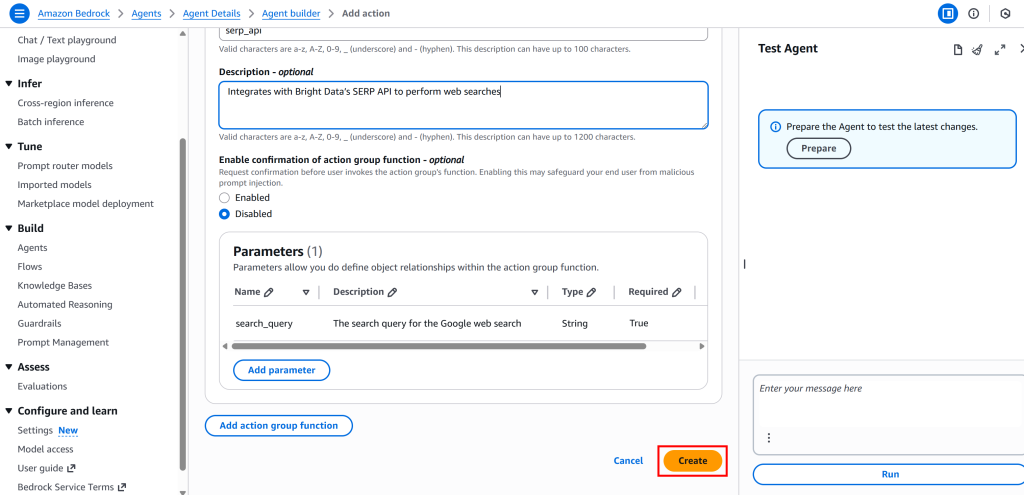
然后点击“Save”保存代理配置。干得好!
步骤四:设置你的 Bright Data 账号
现在需要设置 Bright Data 账号并配置 SERP API 服务。你可以参考官方文档或按照下列步骤进行。
如果你还没有账号,请注册 Bright Data。若已有账号,请登录。登录后前往“Proxies & Scraping”的“My Zones”部分,检查表格中是否有一行“SERP API”:
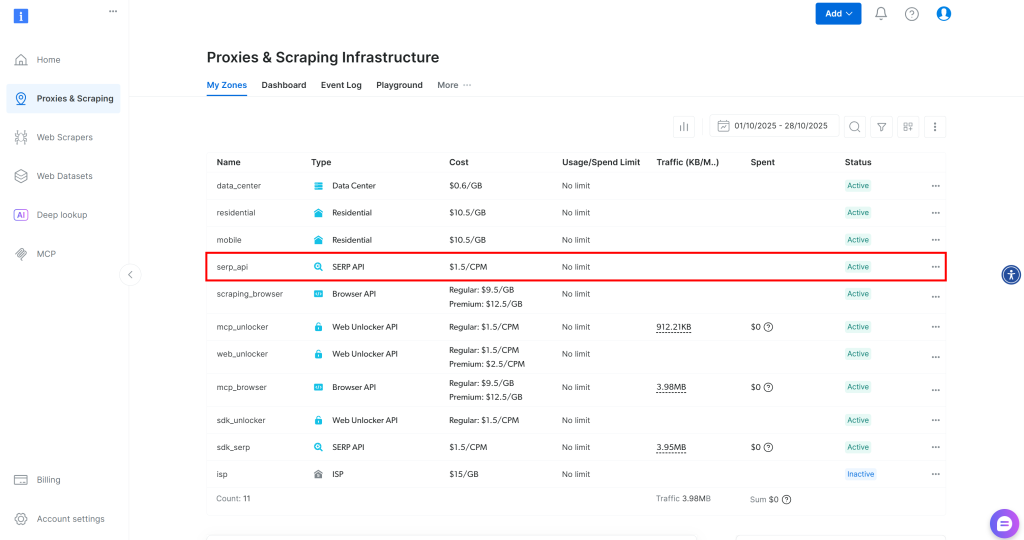
如果没有看到 SERP API 行,说明你尚未配置区域(Zone)。向下滚动并在“SERP API”下点击“Create zone”:
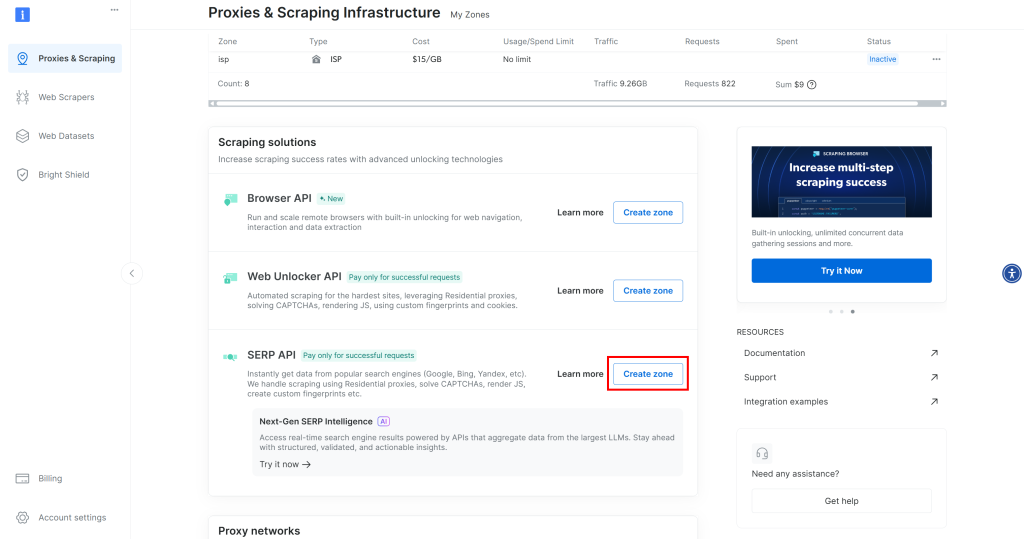
创建一个 SERP API 区域,可命名为 serp_api(或任意你喜欢的名称)。请记录该 SERP API 区域名,稍后通过 API 连接时会用到。
在产品页面,将“Activate”开关切换为启用:
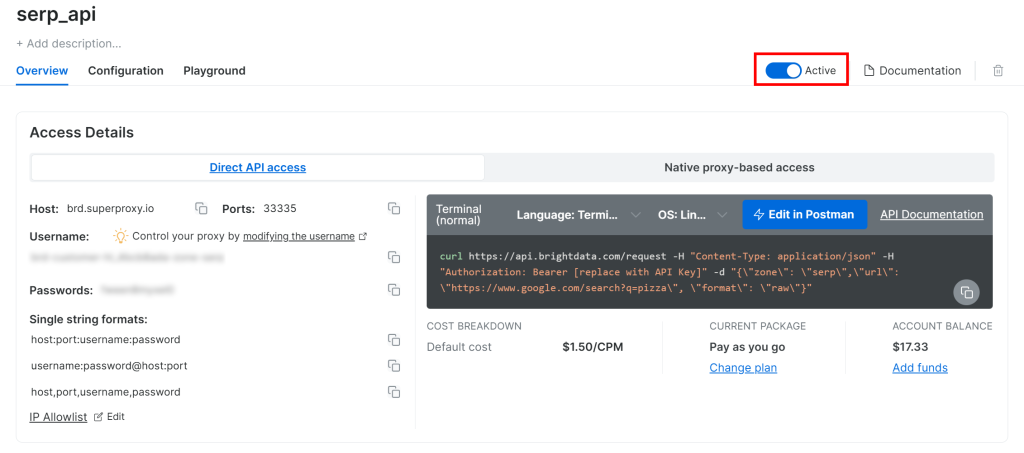
最后,按照官方指南生成你的 Bright Data API Key。请妥善保存,稍后会用到。
就这样!你现在已准备好在 AWS Bedrock AI 代理中使用 Bright Data 的 SERP API。
步骤五:在 AWS 中存储密钥
上一步你获得了敏感信息,如 Bright Data API Key 和 SERP API 区域名。请不要将这些值硬编码在 Lambda 函数代码中,而应将其安全地存储在AWS Secrets Manager中。
在 AWS 搜索栏中搜索“Secrets Manager”并打开该服务:
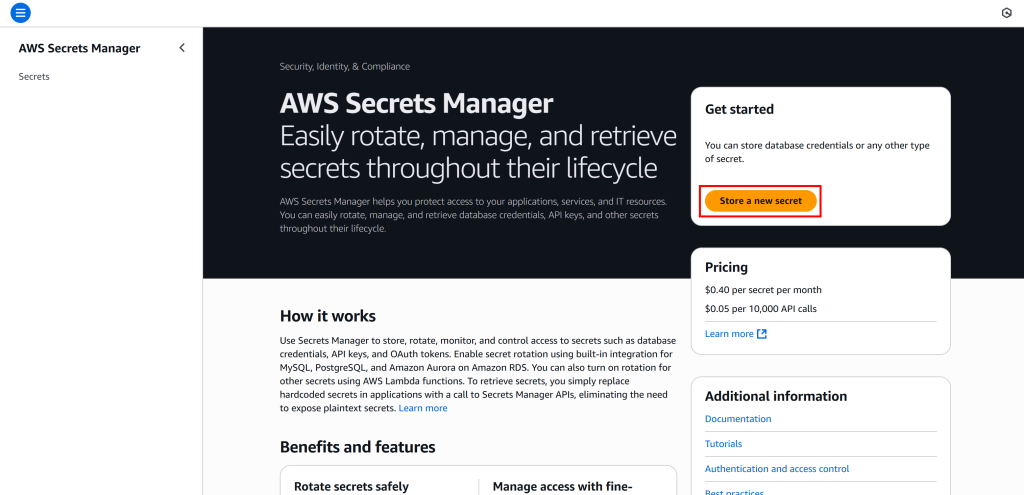
点击“Store a new secret”,选择“Other type of secret”。在“Key/value pairs”部分,添加如下键值对:
BRIGHT_DATA_API_KEY:填写之前获取的 Bright Data API Key。BRIGHT_DATA_SERP_API_ZONE:填写 Bright Data SERP API 区域名(如serp_api)。
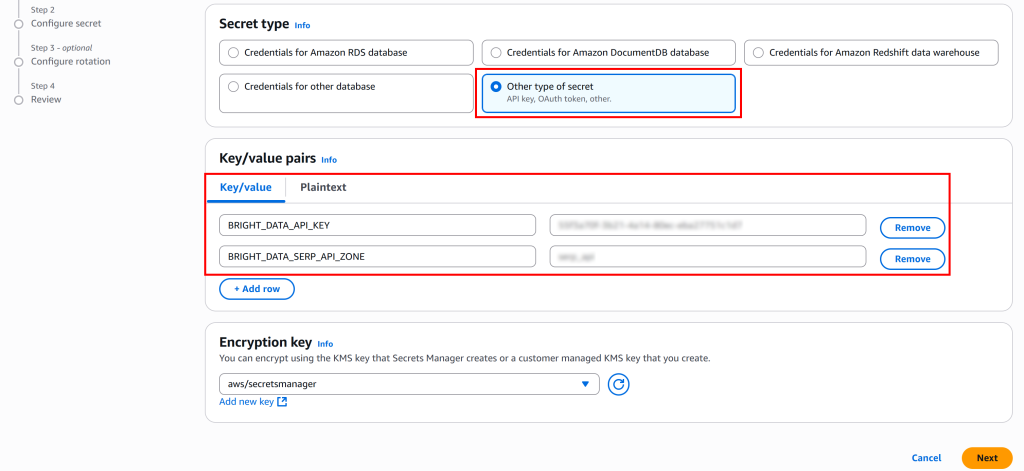
点击“Next”,为该密钥提供一个名称,例如命名为 BRIGHT_DATA:
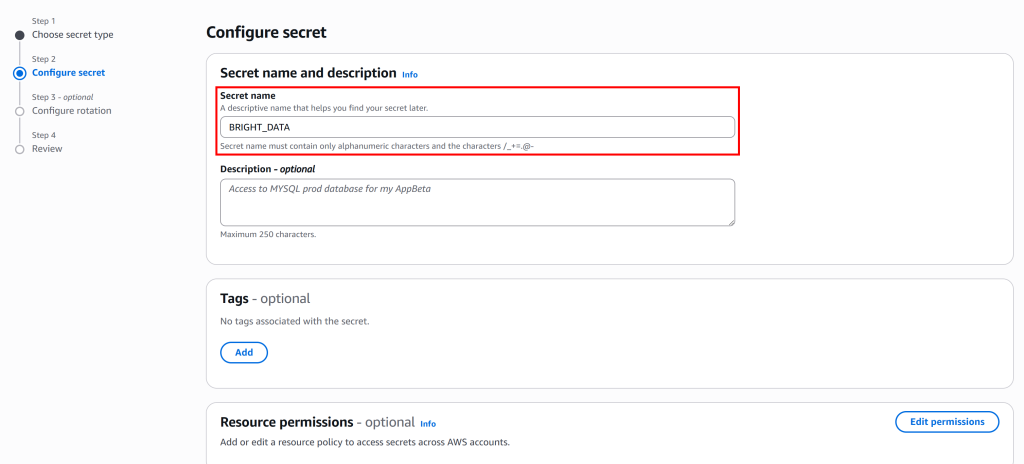
该密钥将存储一个包含 BRIGHT_DATA_API_KEY 与 BRIGHT_DATA_SERP_API_ZONE 字段的 JSON 对象。
继续按向导完成剩余步骤,完成密钥的存储。完成后,密钥看起来如下:

太棒了!接下来你会在 Python Lambda 函数中访问这些密钥,以便安全连接 Bright Data SERP API(我们将在下一步中设置)。
步骤六:创建调用 SERP API 的 Lambda 函数
现在你已具备创建操作组(步骤三)所关联 Lambda 函数的所有基础。该函数将包含调用 Bright Data SERP API 并检索网页搜索数据的 Python 代码。
要创建(或编辑)该 Lambda,请在 AWS 搜索栏中搜索“Lambda”,打开Amazon Lambda 控制台。你会发现步骤三中 AWS Bedrock 已自动创建了一个函数:
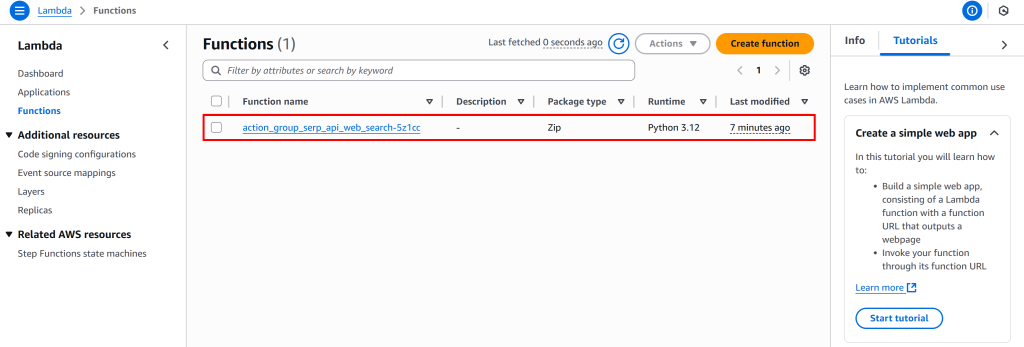
点击名为 action_group_serp_api_web_search_XXXX 的函数进入其概览页:
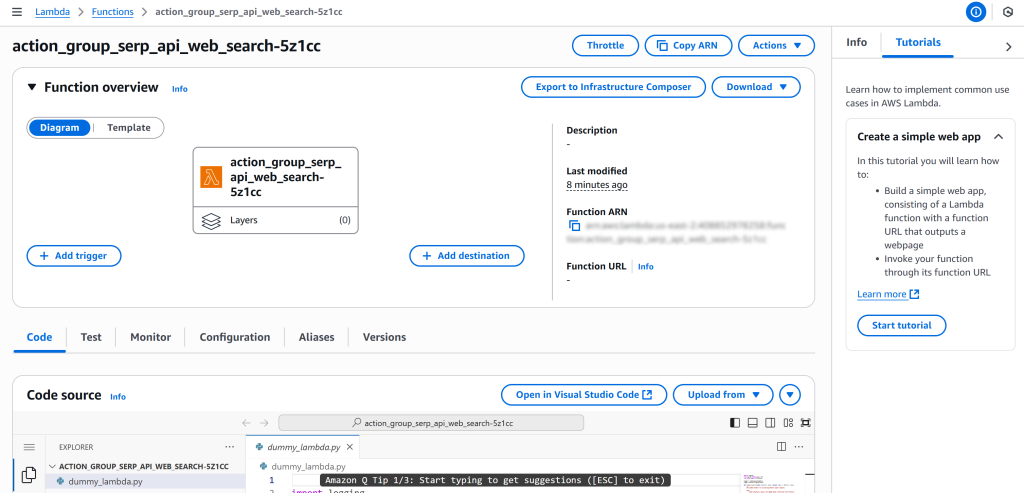
在该页面向下滚动至 Code 选项卡,你会看到内置的 Visual Studio Code 在线编辑器:
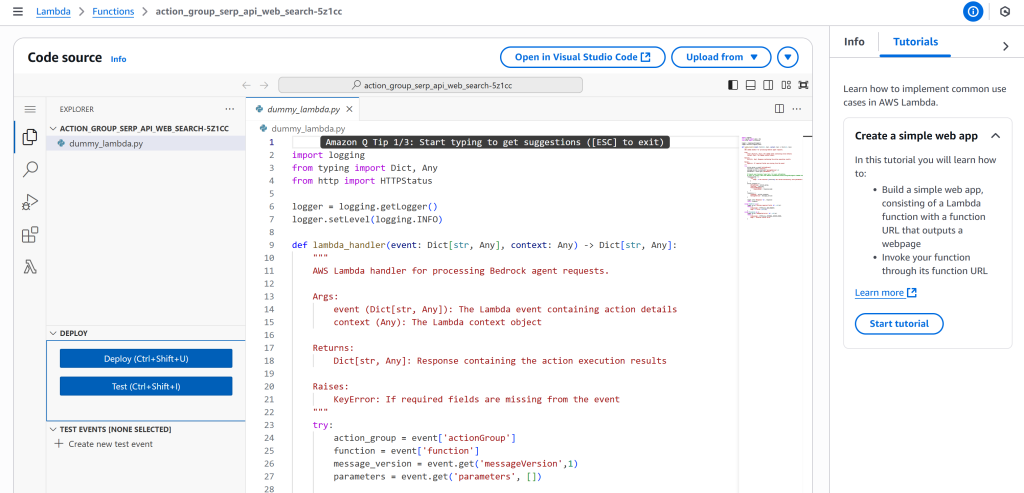
将 dummy_lambda.py 文件内容替换为以下代码:
import json
import logging
import os
import urllib.parse
import urllib.request
import boto3
# ----------------------------
# Logging configuration
# ----------------------------
log_level = os.environ.get("LOG_LEVEL", "INFO").strip().upper()
logging.basicConfig(
format="[%(asctime)s] p%(process)s {%(filename)s:%(lineno)d} %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
logger.setLevel(log_level)
# ----------------------------
# AWS Region from environment
# ----------------------------
AWS_REGION = os.environ.get("AWS_REGION")
if not AWS_REGION:
logger.warning("AWS_REGION environment variable not set; boto3 will use default region")
# ----------------------------
# Retrieve the secret object from AWS Secrets Manager
# ----------------------------
def get_secret_object(key: str) -> str:
"""
Get a secret value from AWS Secrets Manager.
"""
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=AWS_REGION
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=key
)
except Exception as e:
logger.error(f"Could not get secret '{key}' from Secrets Manager: {e}")
raise e
secret = json.loads(get_secret_value_response["SecretString"])
return secret
# Retrieve Bright Data credentials
bright_data_secret = get_secret_object("BRIGHT_DATA")
BRIGHT_DATA_API_KEY = bright_data_secret["BRIGHT_DATA_API_KEY"]
BRIGHT_DATA_SERP_API_ZONE = bright_data_secret["BRIGHT_DATA_SERP_API_ZONE"]
# ----------------------------
# SERP API Web Search
# ----------------------------
def serp_api_web_search(search_query: str) -> str:
"""
Calls Bright Data SERP API to retrieve Google search results.
"""
logger.info(f"Executing Bright Data SERP API search for search_query='{search_query}'")
# Encode the query for URL
encoded_query = urllib.parse.quote(search_query)
# Build the Google URL to scrape the SERP from
search_engine_url = f"https://www.google.com/search?q={encoded_query}"
# Bright Data API request (docs: https://docs.brightdata.com/scraping-automation/serp-api/send-your-first-request)
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": search_engine_url,
"format": "raw",
"data_format": "markdown" # To get the SERP as an AI-ready Markdown document
}
payload = json.dumps(data).encode("utf-8")
request = urllib.request.Request(url, data=payload, headers=headers)
try:
response = urllib.request.urlopen(request)
response_data: str = response.read().decode("utf-8")
logger.debug(f"Response from SERP API: {response_data}")
return response_data
except urllib.error.HTTPError as e:
logger.error(f"Failed to call Bright Data SERP API. HTTP Error {e.code}: {e.reason}")
except urllib.error.URLError as e:
logger.error(f"Failed to call Bright Data SERP API. URL Error: {e.reason}")
return ""
# ----------------------------
# Lambda handler
# ----------------------------
def lambda_handler(event, _):
"""
AWS Lambda handler.
Expects event with actionGroup, function, and optional parameters including search_query.
"""
logger.debug(f"lambda_handler called with event: {event}")
action_group = event.get("actionGroup")
function = event.get("function")
parameters = event.get("parameters", [])
# Extract search_query from parameters
search_query = next(
(param["value"] for param in parameters if param.get("name") == "search_query"),
None,
)
logger.debug(f"Input search query: {search_query}")
serp_page = serp_api_web_search(search_query) if search_query else ""
logger.debug(f"Search query results: {serp_page}")
# Prepare the Lambda response
function_response_body = {"TEXT": {"body": serp_page}}
action_response = {
"actionGroup": action_group,
"function": function,
"functionResponse": {"responseBody": function_response_body},
}
response = {"response": action_response, "messageVersion": event.get("messageVersion")}
logger.debug(f"lambda_handler response: {response}")
return response该代码从 AWS Secrets Manager 中读取 Bright Data API 凭据,使用 Google 搜索查询调用 SERP API,并以 Markdown 文本返回搜索结果。关于如何调用 SERP API 的更多信息,请参考文档。
将上述代码粘贴到在线 IDE 中:
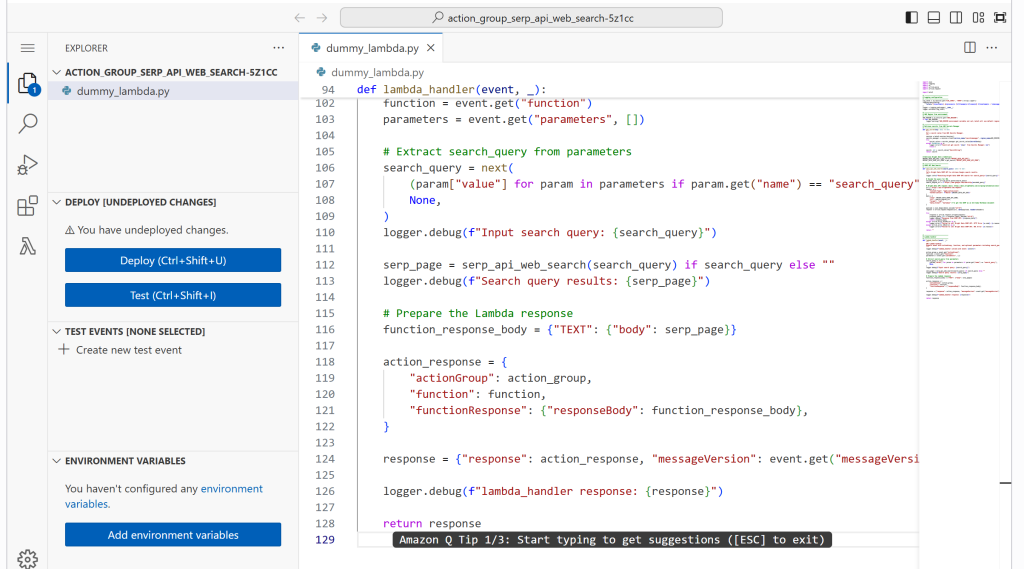
然后点击“Deploy”更新 Lambda 函数:
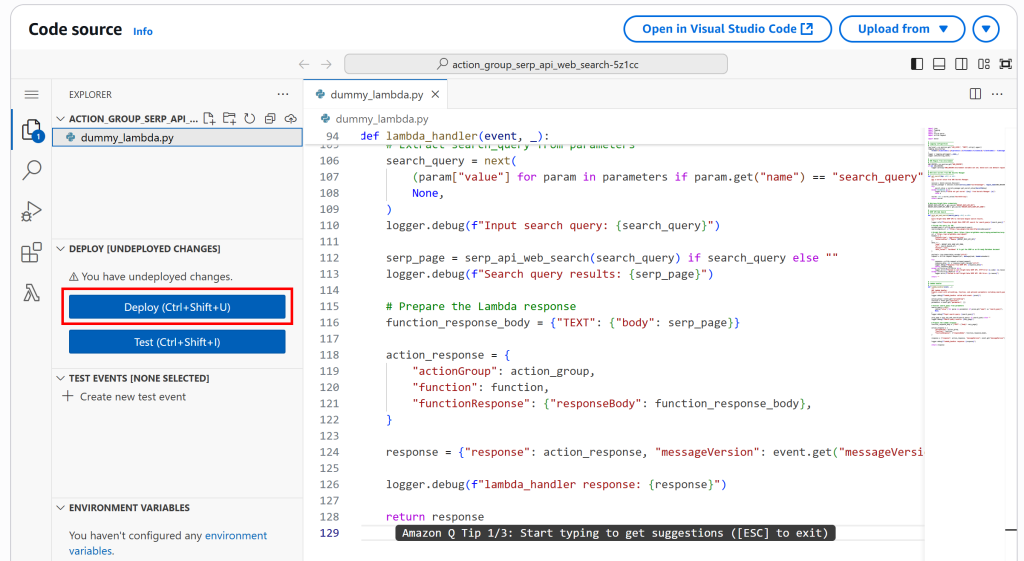
如果一切顺利,你将看到类似“Successfully updated the function action_group_serp_api_web_search_XXXX.”的消息。
注意:该 Lambda 函数已自动配置基于资源的策略,允许 Amazon Bedrock 调用它。由于之前选择了“Quick create a new Lambda function”,因此无需手动修改 IAM 角色。
完美!你用于连接 Bright Data SERP API 的 AWS Lambda 函数已就绪。
步骤七:配置 Lambda 权限
虽然你的 Lambda 函数不需要自定义 IAM 权限即可被调用,但它需要访问存储在 AWS Secrets Manager 中的 API Key。
在 Lambda 函数详情页,进入“Configuration”选项卡,选择“Permissions”:
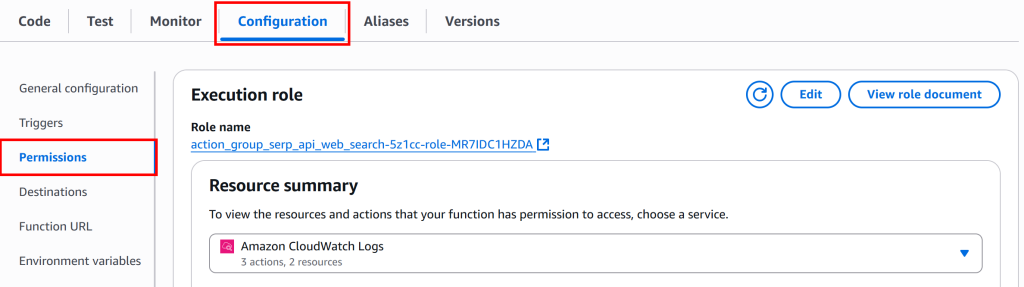
在“Execution role”部分,点击“Role name”链接进入 IAM 控制台:
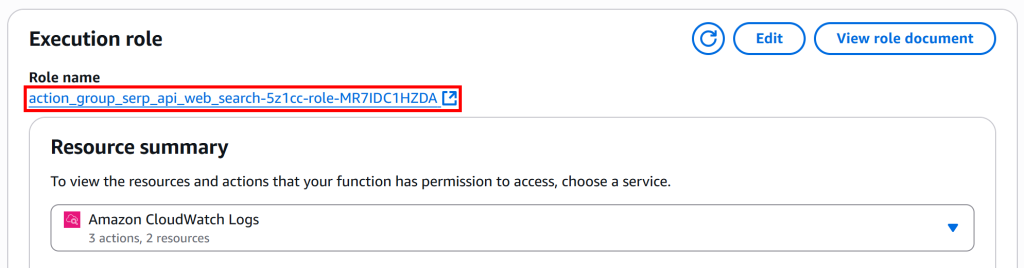
在角色页面中,找到并选择已附加的权限策略:
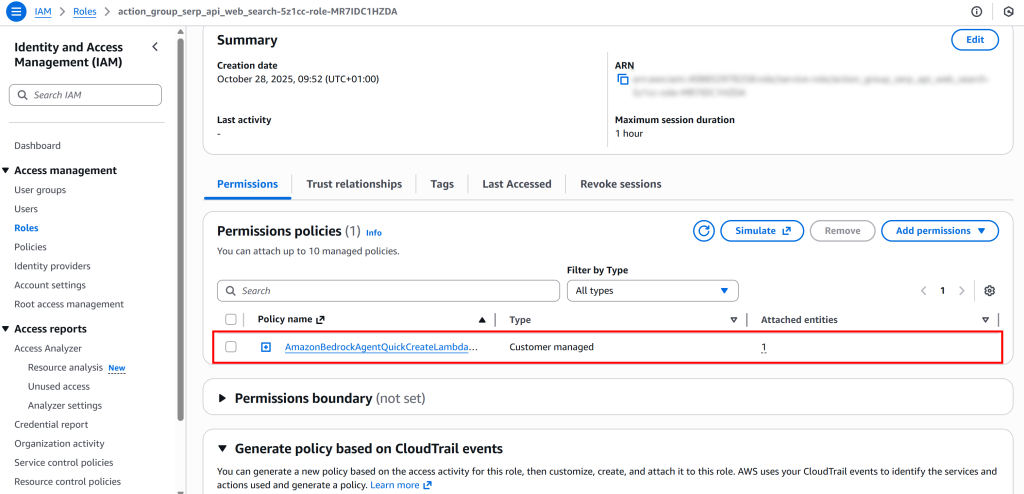
打开“JSON”视图并点击“Edit”以准备更新权限策略:
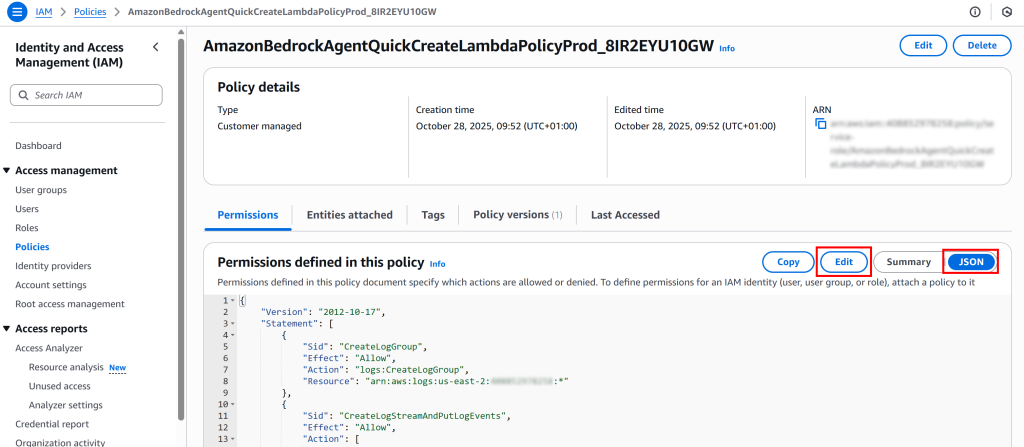
确保 Statement 数组包含如下内容:
{
"Action": "secretsmanager:GetSecretValue",
"Resource": [
"arn:aws:secretsmanager:<YOUR_AWS_REGION>:<YOUR_AWS_ACCOUNT_ID>:secret:BRIGHT_DATA*"
],
"Effect": "Allow",
"Sid": "GetSecretsManagerSecret"
}将 <YOUR_AWS_REGION> 和 <YOUR_AWS_ACCOUNT_ID> 替换为你的实际值。该 JSON 片段将授予 Lambda 函数访问 Secrets Manager 中 BRIGHT_DATA 密钥的权限。
然后点击“Next”,最后“Save changes”。完成后,你应能看到 Lambda 函数已具备 Secrets Manager 访问权限:
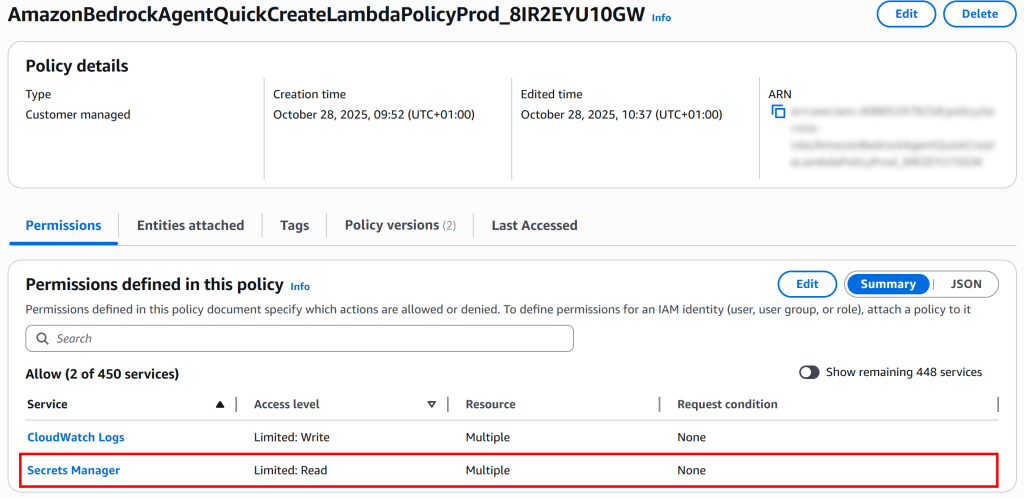
太赞了!你的 Lambda 函数现已正确配置,可由 AWS Bedrock AI 代理调用,并能访问存储在 Secrets Manager 中的 Bright Data 凭据。
步骤八:完成代理配置
返回“Agent builder”部分,最后再点击一次“Save”以应用之前的所有更改:
接着点击“Prepare”,使代理以最新配置进入可测试状态。

你应会看到类似“Agent: web_search_agent was successfully prepared.”的确认信息。
大功告成!你的 Bright Data SERP API 驱动的 AI 代理已完全实现并可投入使用。
步骤九:测试你的 AI 代理
你的 AWS Bedrock AI 代理可以访问 serp_api 组函数,该函数由你在步骤六中定义的 lambda_handler Lambda 实现。简单来说,你的代理可以通过 Bright Data SERP API 在 Google(以及潜在的其他搜索引擎)上执行实时网页搜索,并动态检索与处理最新在线内容。
为了测试此能力,假设你想获取关于飓风 Melissa的最新新闻。尝试向代理发出如下提示:
"Give me the top 3 latest news articles on Hurricane Melissa"请记住:这只是一个示例,你可以测试任何涉及实时网页搜索结果的提示。
在代理的“Test Agent”部分运行该提示,你应会看到类似如下的输出:
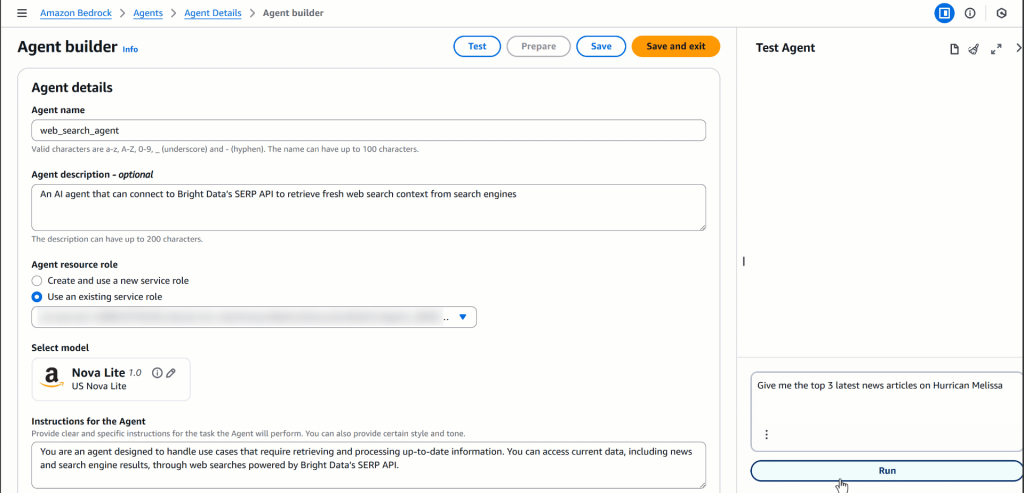
在幕后,代理调用了 SERP API 对应的 Lambda,检索了关于“飓风 Melissa”的最新 Google 搜索结果,并提取了最相关的新闻条目及其链接。这是任何“原生”LLM(包括 Nova Lite)自身无法完成的!
以下是代理生成的具体文本响应(已省略 URL):
Here are the top 3 latest news articles on Hurricane Melissa:
1. Jamaica braces for Hurricane Melissa, strongest storm of 2026 - BBC, 6 hours ago
2. Hurricane Melissa live updates, tracker—Jamaica faces "catastrophic" impact - Newsweek, 7 hours ago
3. Hurricane Melissa bears down on Jamaica and threatens to be the island's strongest recorded storm - AP News, 10 hours ago
Please visit the original sources for the full articles.这些结果并非幻觉!相反,它们与在 Google 上手动搜索“飓风 Melissa”时看到的内容一致(以代理测试当日为准):
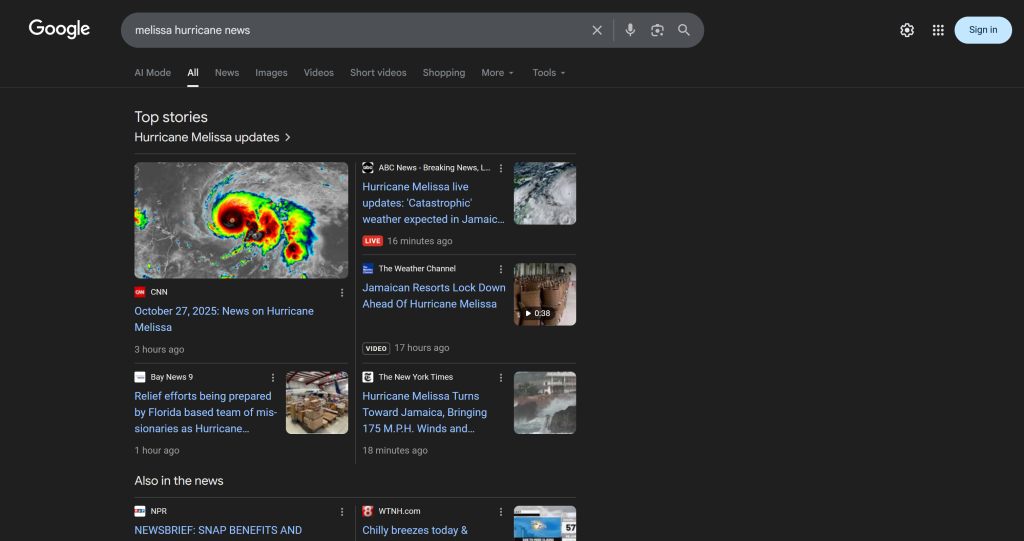
如果你曾尝试过抓取 Google 搜索结果,就会知道由于机器人检测、IP 封禁、JavaScript 渲染以及诸多其他挑战,这有多困难。
Bright Data SERP API 高效解决了这些问题,并支持将抓取到的 SERP 以 AI 优化的 Markdown 格式返回(这对 LLM 摄取尤为有价值)。
要确认代理确实调用了 SERP API 的 Lambda,点击“Show trace”:
在“Trace step 1”部分,向下滚动至组调用日志,可以看到函数调用的输出:
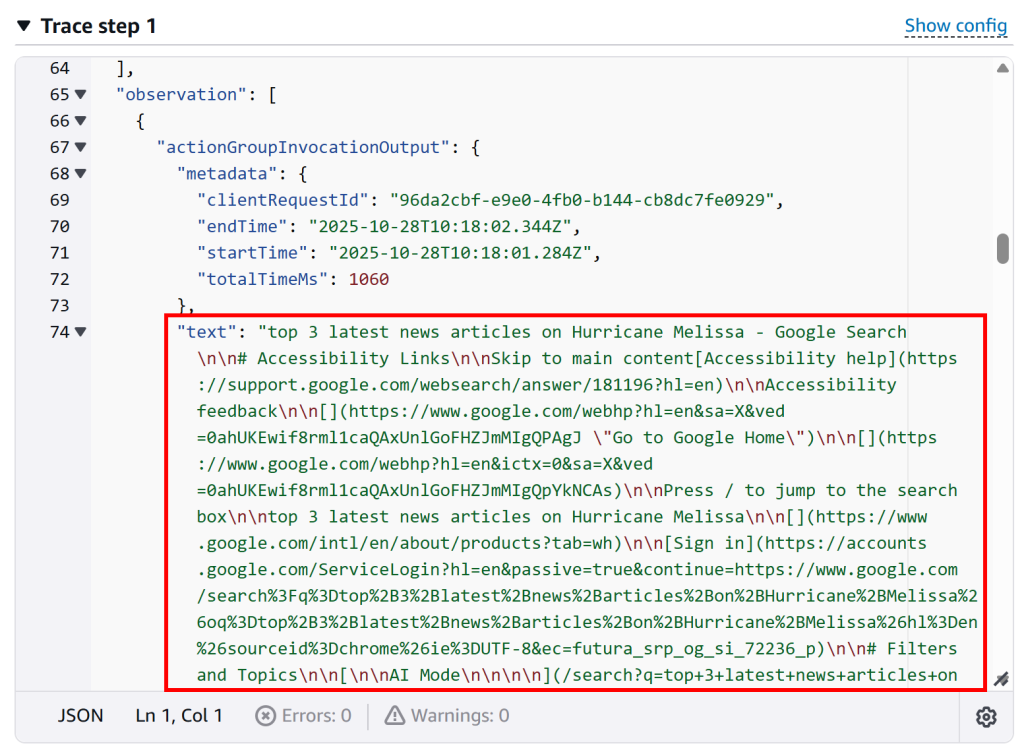
这表明 Lambda 函数执行成功,代理如预期与 SERP API 进行了交互。你也可以在该 Lambda 的AWS CloudWatch 日志中进行核验。
现在让你的代理更进一步吧!尝试与事实核查、品牌监测、市场趋势分析等相关的提示,看看你的代理在不同用例中的表现。
就是这样!你刚刚构建了一个与 Bright Data SERP API 集成的 AWS Bedrock AI 代理,能够按需检索最新、可信且具有上下文的网页搜索数据。
[进阶] 使用 AWS CDK 构建具备网页搜索能力的 Amazon Bedrock 代理
上一节中,你已学习了如何直接通过 Amazon Bedrock 控制台定义并实现一个与 SERP API 集成的 AI 代理。
如果你更偏好代码优先的方式,可以使用AWS Cloud Development Kit(AWS CDK)实现相同结果。该方法遵循相同步骤,只是将一切在本地的 AWS CDK 项目中进行管理。
详细指南可参考AWS 官方博文,并查看支持该教程的GitHub 仓库。这套代码非常容易改造以适配 Bright Data 的 SERP API。
结语
本文展示了如何将 Bright Data 的 SERP API 集成进 AWS Bedrock AI 代理。该工作流非常适合希望在 AWS 中构建更强大、具备上下文感知能力的 AI 代理的用户。
若要打造更高级的 AI 工作流,欢迎探索Bright Data 的 AI 基础设施。你将发现一整套用于检索、验证与转换实时网页数据的工具。
立即注册免费的 Bright Data 账号,开始体验我们为 AI 准备的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




