

Tableau 是领先的数据可视化工具,但它有一个重大限制:它自身无法可靠地从网站拉取实时数据。此前可解决该问题的 Web Data Connector(WDC v2)已在 2023 年被弃用。其最后一个兼容版本(Tableau 2022.4)也已生命周期结束(EOL),使分析师失去了受支持的解决方案。
本指南对比用于网页抓取并将实时数据连接到 Tableau 的6 种方法。同时还提供一个分步教程,演示如何使用 Bright Data Web Scraper API 搭建 API-to-Tableau 的数据管道。
TL;DR
Tableau 不能原生抓取网站,而它的 Web Data Connector(WDC v2)在 2023 年已弃用。你需要外部数据管道。
- WDC v2 已弃用;WDC v3 仅支持 Extract,且构建复杂
- Google Sheets、Excel 和 TabPy 在规模化场景下都有关键限制
- 自建 Python 脚本一开始能跑,但需要持续维护
- 托管式抓取 API 可自动处理代理、CAPTCHA 和数据解析
跟随本文分步教程,搭建一个可运行的 Amazon → Bright Data → Tableau 管道。
为什么 Tableau 需要外部数据管道
现代数据栈需要实时 Web 数据:竞品价格、社交媒体指标、招聘信息、房源列表、金融行情等。但 Tableau 并不是为采集这些数据而设计的。
主要挑战包括:
- 网站持续变化 – 布局调整、反爬虫策略迭代、对 JavaScript 渲染的要求增加
- 规模至关重要 – 每天监控 10,000 个竞品 SKU 需要重试逻辑、限速与失败处理,这不是单页脚本所需的复杂度
- 合规是硬性要求 – GDPR、CCPA 与平台条款要求谨慎的数据采集实践
- 基础设施成本高 – 代理轮换、CAPTCHA 处理、重试逻辑与 IP 管理都是持续的工程挑战
以下方法可以弥补这个缺口。
用于网页抓取并将实时数据连接到 Tableau 的 6 种方法
每种方法在规模、维护成本与可靠性之间的权衡不同。这里按从最不适用到最适合生产的顺序排列。
方法 1:Tableau Web Data Connector v2(已弃用)
它是什么:WDC v2 允许你构建基于 JavaScript 的连接器,将 Web API 数据直接拉入 Tableau。
为什么现在不行了:在 Tableau 2023.1 中被弃用。WDC v2 连接器在当前所有 Tableau 版本中都不再受支持,Tableau 未来版本甚至可能彻底移除。需要迁移到 WDC v3,但 v3 的架构与 v2 本质不同。
关键限制:官方支持已结束。如果你仍在运行 WDC v2 连接器,请尽快迁移,因为它们可能在未来任何一次 Tableau 更新中停止工作。
方法 2:Google Sheets 作为中间层
工作原理:先将数据抓取到 Google Sheets(通过 Apps Script、IMPORTXML、IMPORTDATA 或第三方工具),再将 Tableau 连接到 Sheets 作为实时数据源。
为何使用:免费、无需编码,且 Tableau 可通过其 Google Drive 连接器连接到 Google Sheets。
关键限制:
- Google Sheets 有1,000 万单元格上限 – 大数据集很快触顶
IMPORTXML与IMPORTHTML公式会因网站结构变化而频繁失效- 刷新时机不可靠:Google 会不可预测地限制公式执行
- 不支持 JavaScript 渲染,因此现代单页应用(SPA)会返回空数据(这类站点需要 Scraping Browser)
- Google Sheets API 的速率限制会导致定时刷新时同步失败
结论:适合小型原型,但在更大规模下容易崩。适用于个人仪表盘:少于 10,000 行、且数据变化不频繁的场景。
方法 3:Excel + OneDrive / SharePoint
工作原理:使用 Excel 的 Power Query 或“从 Web 获取数据”功能从 URL 拉取数据并保存到 OneDrive,然后让 Tableau 连接该云端 Excel 文件。
关键限制:
- 需要手动刷新 – Power Query 难以可靠地后台自动刷新
- 不支持 JavaScript 渲染,无法处理 React、Angular 或任何基于 SPA 的站点
- 解析能力有限:复杂 HTML 结构经常导致导入失败
- OneDrive 同步冲突会引发数据一致性问题
- 没有代理轮换,任何稍大的抓取量都会导致 IP 被封
结论:适合从静态网页拉一份单次报表,但并不是数据管道。
方法 4:TabPy(Python + Tableau 扩展)
工作原理:TabPy 是 Tableau 官方的 Python 服务器,可通过 SCRIPT_REAL、SCRIPT_STR 等函数在 Tableau 计算字段中执行 Python 脚本。理论上,可以通过 TabPy 让网页抓取逻辑在 Tableau 内直接运行。
为何使用:Python 有丰富的抓取库,且 TabPy 受 Tableau 官方支持。
关键限制:
- 需要运行 TabPy 服务 – 额外的基础设施需要维护
- 在 Tableau 计算字段里做爬虫抓取属于反模式:慢、不稳定,并会阻塞仪表盘渲染
- 没有代理轮换,你的 TabPy 服务器 IP 在高频目标上会很快被封
- 无 CAPTCHA 处理、无重试逻辑、无 JavaScript 渲染
- 计算字段有执行时间限制,复杂抓取任务会超时
- 调试非常困难,错误通常以模糊的 Tableau 报错呈现
结论:TabPy 非常适合在 Tableau 内运行 ML 模型和统计计算,但不适合做网页抓取。
方法 5:自建 Python 脚本(requests、Scrapy、Selenium)
工作原理:使用 requests、BeautifulSoup、Scrapy 或 Selenium 等库编写自定义 Python 脚本。按计划运行(如 cron 或 Airflow),输出 CSV/JSON 文件,再让 Tableau 连接这些文件。
为何使用:灵活度最高,一切都可控。
关键限制:
- 维护成本高 – 网站会改版、增加反爬虫机制、调整 HTML 结构。你的爬虫可能无预警失败,仪表盘展示的则是过期数据。
- 规模化 IP 封禁 – 若没有 代理网络,目标站会在数小时内封锁你的服务器
- 没有 CAPTCHA 处理 – Cloudflare、reCAPTCHA、hCaptcha 会阻断抓取工具且无内置解决方案(像 Web Unlocker 这类服务可自动处理)
- 基础设施成本 – 你需要服务器、代理订阅、监控和告警
- 合规风险 – 缺少完善基础设施时,可能违反 GDPR、CCPA 或平台条款
- 不易扩展 – 抓取 100 个 URL 与抓取 100,000 个是两回事;适用于前者的架构在后者会彻底失败。
结论:自建方案初期可行,但长期可靠性差。多数团队会从这里起步,并在一开始取得成效,但维护成本会随时间不断增加。
第一个月通常运行良好,但几个月后,你花在修复失效选择器与处理 IP 封禁上的时间,会超过搭建仪表盘的时间。如果你只抓取一两个站点且低频低量,自建脚本可能已足够。
方法 6:Bright Data Web Scraper API(推荐)
工作原理:Bright Data 的 Web Scraper API 覆盖整个数据采集层:代理轮换、CAPTCHA 自动处理、JavaScript 渲染、反爬虫绕过,以及结构化数据输出。你通过 API 触发采集任务,获得干净的 JSON/CSV 数据,再加载进 Tableau。
优势:
| 能力 | Bright Data | 自建脚本 |
|---|---|---|
| 代理网络 | 覆盖 195 个国家/地区的 1.5 亿+ IP | 自行购买(昂贵) |
| 现成抓取器 | 120+ 覆盖主流平台 | 从零开发 |
| CAPTCHA 处理 | 自动 | 不包含 |
| JavaScript 渲染 | 内置 | 需要 Selenium/Playwright |
| 反爬虫绕过 | 自动 | 需要持续手动更新 |
| 可用性 | 99.99% | 取决于你的基础设施 |
| 合规 | GDPR、CCPA、ISO 27001 | 由你负责 |
| 维护 | 极少 – 由 Bright Data 负责更新抓取器 | 持续维护 |
| 规模 | 百万级页面/天 | 受你的服务器限制 |
| 定价 | 低至 $1.50/1K 记录 | 不固定(服务器 + 代理 + 维护) |
结论:你专注于 Tableau 仪表盘;Bright Data 负责数据采集基础设施。
权衡:Bright Data 是付费第三方服务,你会依赖其基础设施与定价模型。若只是低频、低量地抓取一两个站点,自建脚本(方法 5)成本更低且可完全掌控。
你应该选择哪种 Tableau 数据连接方式?
下表按生产管道最关键的能力维度对比 6 种方法。
| 方法 | JS 渲染 | 代理轮换 | CAPTCHA 处理 | 自动刷新 | 规模 | 维护 | 状态 |
|---|---|---|---|---|---|---|---|
| WDC v2 | No | No | No | Yes | 低 | N/A | 已弃用 |
| Google Sheets | No | No | No | 不可靠 | 极低 | 低 | 单元格上限 |
| Excel + OneDrive | No | No | No | 手动 | 极低 | 中 | 手动流程 |
| TabPy | 手动/自建 | No | No | Yes | 低 | 高 | IP 封禁 |
| 自建 Python | 通过 Selenium | 自建 | No | 通过 cron | 中 | 极高 | 规模化会崩 |
| Bright Data API | Yes | Yes(1.5 亿+ IP) | Yes | Yes | 高 | 极少 | 生产可用 |
教程:把网页抓取 API 连接到 Tableau
本教程将搭建一条真实管道:Amazon 商品价格 → Bright Data API → CSV → Tableau 仪表盘,使用 Amazon Scraper API。它覆盖“竞品价格监控”这一用例,这是团队将 Web 数据接入 Tableau 的最常见原因。
架构
管道流程如下:
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ Your Script │────▶│ Bright Data Scraper │────▶ │ CSV/JSON │────▶│ Tableau │
│ (Python/cron) │ │ API │ │ Output │ │ Dashboard │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
Trigger with Handles proxies, Visualize prices,
keywords/URLs CAPTCHAs, rendering ratings, trends先决条件
开始前你需要安装或准备好:
- Python 3.8+
- Bright Data 账号(可免费试用,无需信用卡)
- 来自 Bright Data 控制台的API token(步骤 0 有说明)
- Tableau Desktop(14 天试用)、Tableau Cloud 或 Tableau Public(免费,但仪表盘公开)
准备就绪后,从生成 Bright Data API token 开始。
步骤 0:获取 Bright Data API token
按以下步骤生成 API token:
- 在 brightdata.com/cp 注册或登录
- 进入 Account settings → Users and API keys
- 选择 “Add API key”(API key 区块右上角)
- 设置权限与过期时间,然后选择 Save
- 复制 token
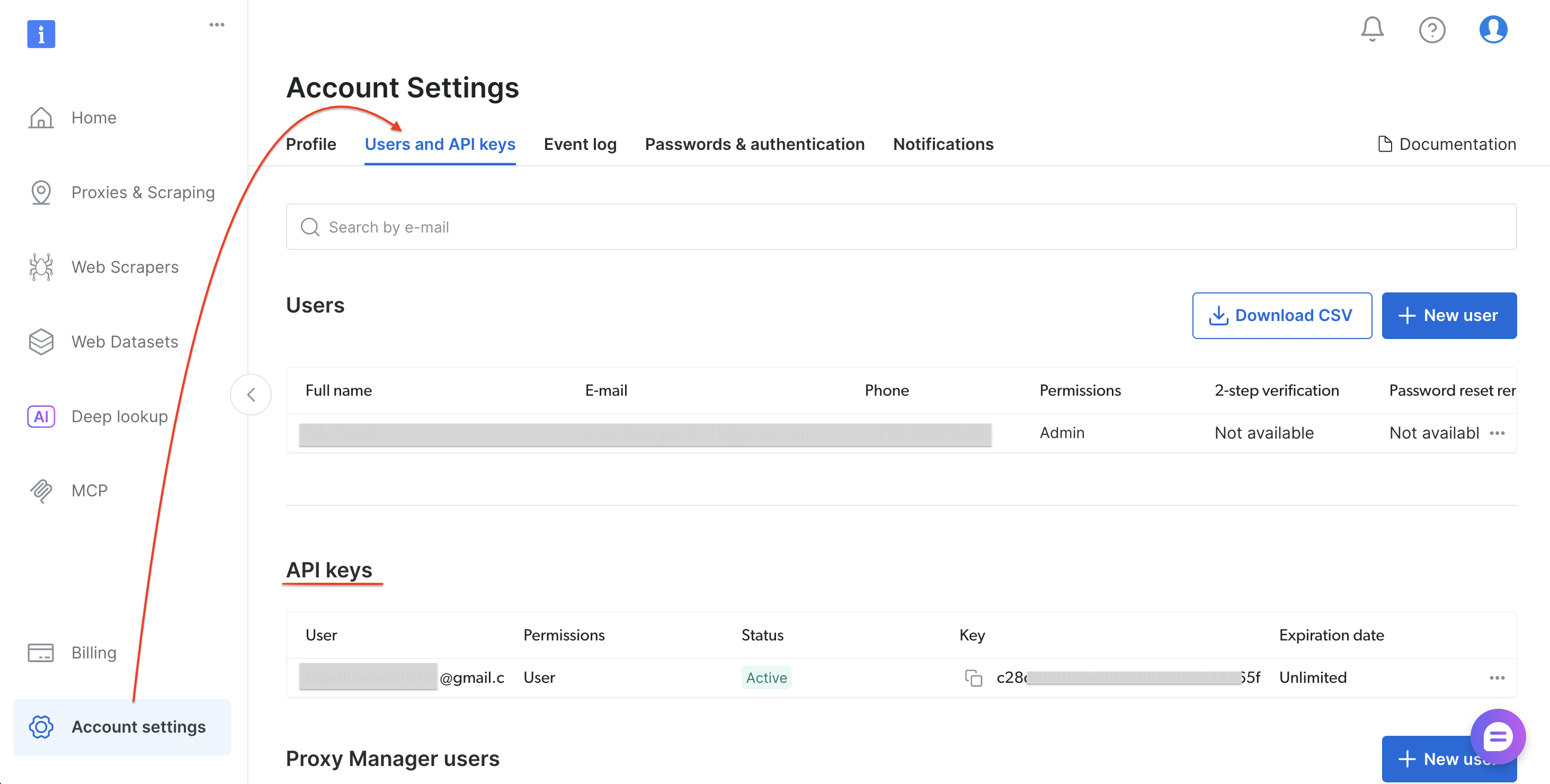
保存好 API token 后,安装 Python 依赖。
步骤 1:安装依赖
安装所需 Python 包:
pip install requests pandas安装好 requests 与 pandas 后,创建管道脚本。
步骤 2:管道脚本
创建文件 bright_data_to_tableau.py:
"""
Bright Data → Tableau Pipeline
Scrapes Amazon product data via Bright Data's Web Scraper API
and outputs a Tableau-ready CSV file.
Usage:
1. Replace YOUR_API_TOKEN with your Bright Data API token
2. Run: python bright_data_to_tableau.py
3. Open the output CSV in Tableau Desktop
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── Configuration ───────────────────────────────────────────────────────────
API_TOKEN = "YOUR_API_TOKEN" # Replace with your Bright Data API token
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Amazon Products Search (by keyword)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # seconds between status checks
POLL_TIMEOUT = 300 # max wait time in seconds
# ─── API Endpoints ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/datasets/v3/trigger"
f"?dataset_id={DATASET_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/datasets/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Trigger a data collection job on Bright Data."""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] Triggering collection for keyword: '{keyword}'...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" Snapshot ID: {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""Poll the snapshot endpoint until data is ready."""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] Waiting for results...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" Ready! Received {len(data)} records.")
return data
elif response.status_code == 202:
print(f" Processing... ({elapsed}s / {POLL_TIMEOUT}s)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
print(f" TIMEOUT: Snapshot not ready after {POLL_TIMEOUT}s.")
print(f" Try increasing POLL_TIMEOUT or check Bright Data dashboard.")
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""Transform raw API data into a clean, Tableau-optimized CSV."""
df = pd.DataFrame(data)
# Map API field names → Tableau-friendly names
column_mapping = {
"title": "Product Name",
"seller_name": "Seller",
"brand": "Brand",
"initial_price": "Original Price",
"final_price": "Current Price",
"currency": "Currency",
"rating": "Rating",
"reviews_count": "Review Count",
"availability": "Availability",
"url": "Product URL",
"asin": "ASIN",
"categories": "Categories",
"delivery": "Delivery Info",
}
# Keep only columns present in the data
available = {k: v for k, v in column_mapping.items() if k in df.columns}
df = df.rename(columns=available)
df = df[list(available.values())]
# Add metadata for Tableau filtering & tracking
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] Saved {len(df)} rows → {output_path}")
return df
def print_summary(df: pd.DataFrame):
"""Print a summary of the scraped data."""
print(f"\n{'─'*50}")
print(f" Summary")
print(f"{'─'*50}")
print(f" Total products : {len(df)}")
if "Current Price" in df.columns:
prices = pd.to_numeric(df["Current Price"], errors="coerce")
print(f" Price range : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" Average price : ${prices.mean():.2f}")
if "Brand" in df.columns:
print(f" Unique brands : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" Avg rating : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}\n")
def run_pipeline(keyword: str):
"""Execute the full pipeline: Trigger → Poll → CSV → Summary."""
print(f"\n{'='*50}")
print(f" Bright Data → Tableau Pipeline")
print(f" Keyword: '{keyword}'")
print(f"{'='*50}\n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# Default keyword — change this or pass as CLI argument
keyword = sys.argv[1] if len(sys.argv) > 1 else "wireless headphones"
run_pipeline(keyword)步骤 3:运行脚本
运行管道脚本:
python bright_data_to_tableau.py预期输出:
==================================================
Bright Data → Tableau Pipeline
Keyword: 'wireless headphones'
==================================================
[1/3] Triggering collection for keyword: 'wireless headphones'...
Snapshot ID: sd_mmlan9p51yycmmkd7d
[2/3] Waiting for results...
Processing... (0s / 300s)
Ready! Received 43 records.
[3/3] Saved 43 rows → amazon_products_tableau.csv
──────────────────────────────────────────────────
Summary
──────────────────────────────────────────────────
Total products : 43
Price range : $0.00 – $169.95
Average price : $45.98
Unique brands : 4
Avg rating : 4.4 / 5.0
──────────────────────────────────────────────────CSV 已准备好。用 Tableau 打开它即可开始构建仪表盘。
步骤 4:连接到 Tableau
将 CSV 导入 Tableau 并校验数据类型:
- 打开 Tableau Desktop、Tableau Cloud 或 Tableau Public
- 连接 CSV:在 Desktop 中选择 Connect → Text File;在 Cloud 中选择 New → Workbook → Files tab 并上传文件
- 确认
Current Price与Rating被识别为数字(Number),而不是字符串 - 选择 Sheet 1 开始搭建
推荐的仪表盘视图:
- 价格分布 – 使用
Current Price的直方图识别市场定位 - 降价分析 – 对比
Original Price与Current Price的并列柱状图识别折扣 - 评分 vs 价格 – 散点图用于寻找高性价比产品
- 品牌对比 – 按
Brand分组的柱状图对比定价与评分
步骤 5:自动化刷新
为保持仪表盘数据实时更新,可用 cron(Linux/Mac)或任务计划程序(Windows)定时运行脚本:
# Run every 6 hours — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.py让 Tableau 展示新数据的刷新方式:
- Tableau Desktop:cron 更新 CSV 后,按 F5(Windows)或 Command+R(Mac)重载;或在 Data 菜单中选择数据源并点 Refresh。Tableau Desktop 不会自动刷新基于文件的数据源,需要手动刷新或重开工作簿。
- Tableau Server:在 Tableau Desktop 中通过 Server → Publish Workbook 发布。在发布对话框中设置 Extract Refresh Schedule(例如每 6 小时,与 cron 对齐)。Tableau Server 会按该计划 自动刷新 Extract。
- Tableau Cloud:浏览器上传的 CSV 无法自动刷新。若要自动刷新,在运行 cron 的机器上安装 Tableau Bridge。Bridge 将本地 CSV 连接到 Tableau Cloud 并支持定时 Extract 刷新。没有 Bridge 的话,每次跑完管道需手动重新上传 CSV。
- Tableau Public:不支持文件型数据源的定时刷新。对于 CSV 管道,每次数据更新都需要重新发布工作簿。
步骤 6:使用任意抓取器(查找 dataset IDs)
本教程使用 Amazon Products Search 数据集(gd_lwdb4vjm1ehb499uxs)。如果要抓取其他网站,只需替换 dataset ID。查找方式如下:
- 登录 Bright Data 控制台
- 在侧边栏选择 Web Scrapers 打开 Web Scrapers Library
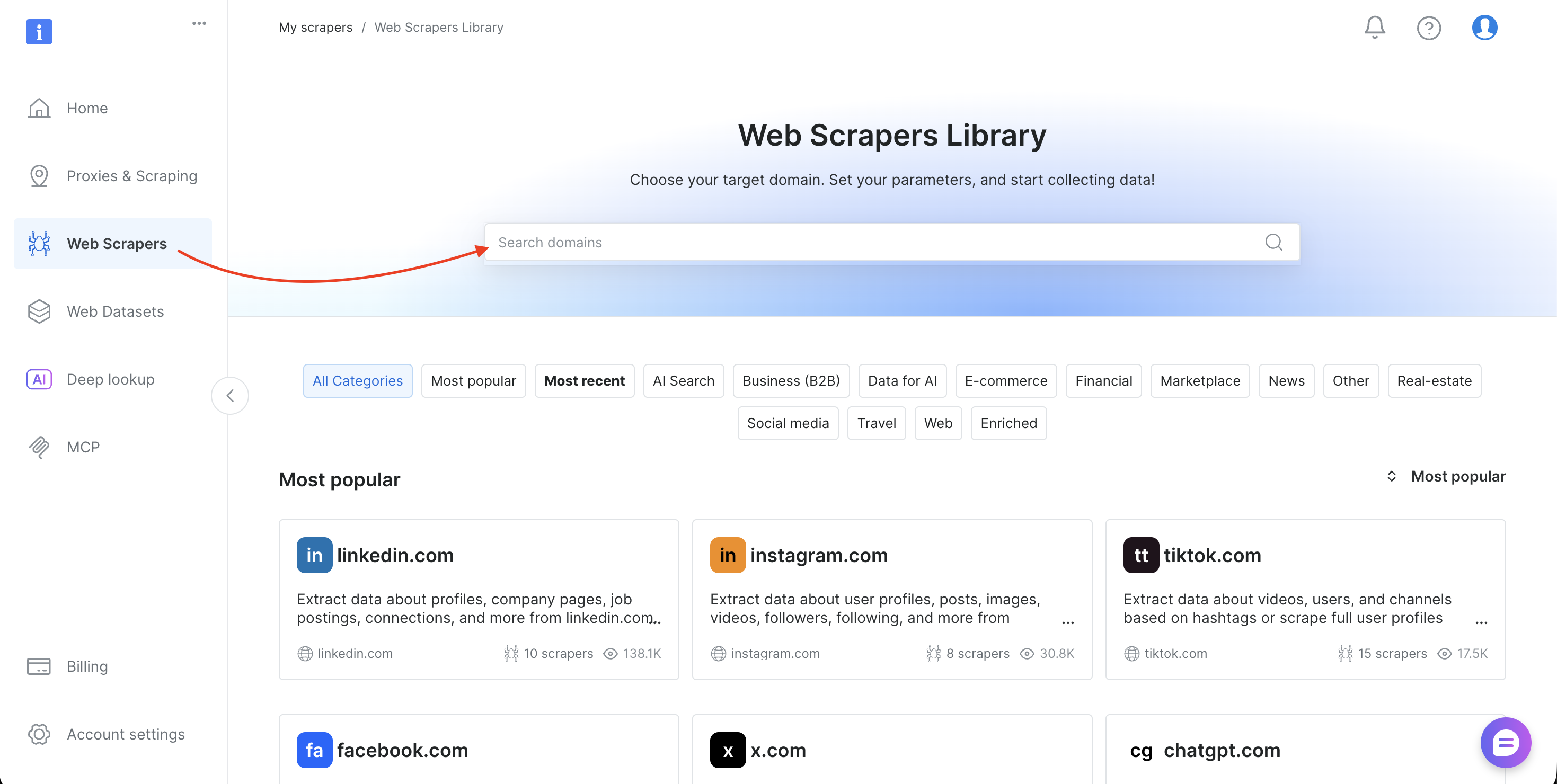
- 搜索目标域名(如 amazon.com、zillow.com 或 linkedin.com)并选择
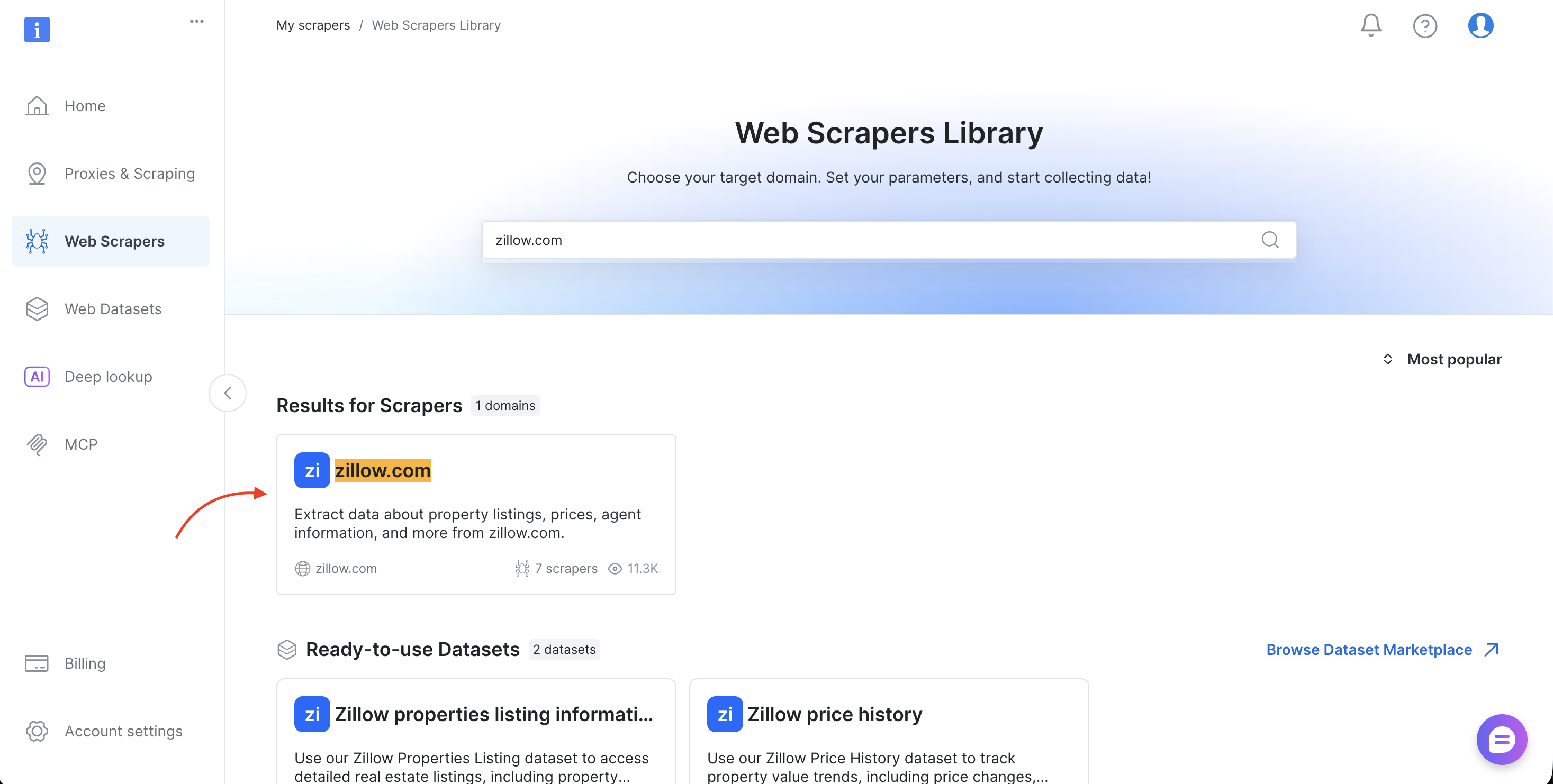
- 选择采集方式(Collect by URL 或 Discover by keyword)
- 从浏览器地址栏复制
dataset_id(例如brightdata.com/cp/scrapers/gd_lfqkr8wm13ixtbd8f5),或从 Code examples 面板复制
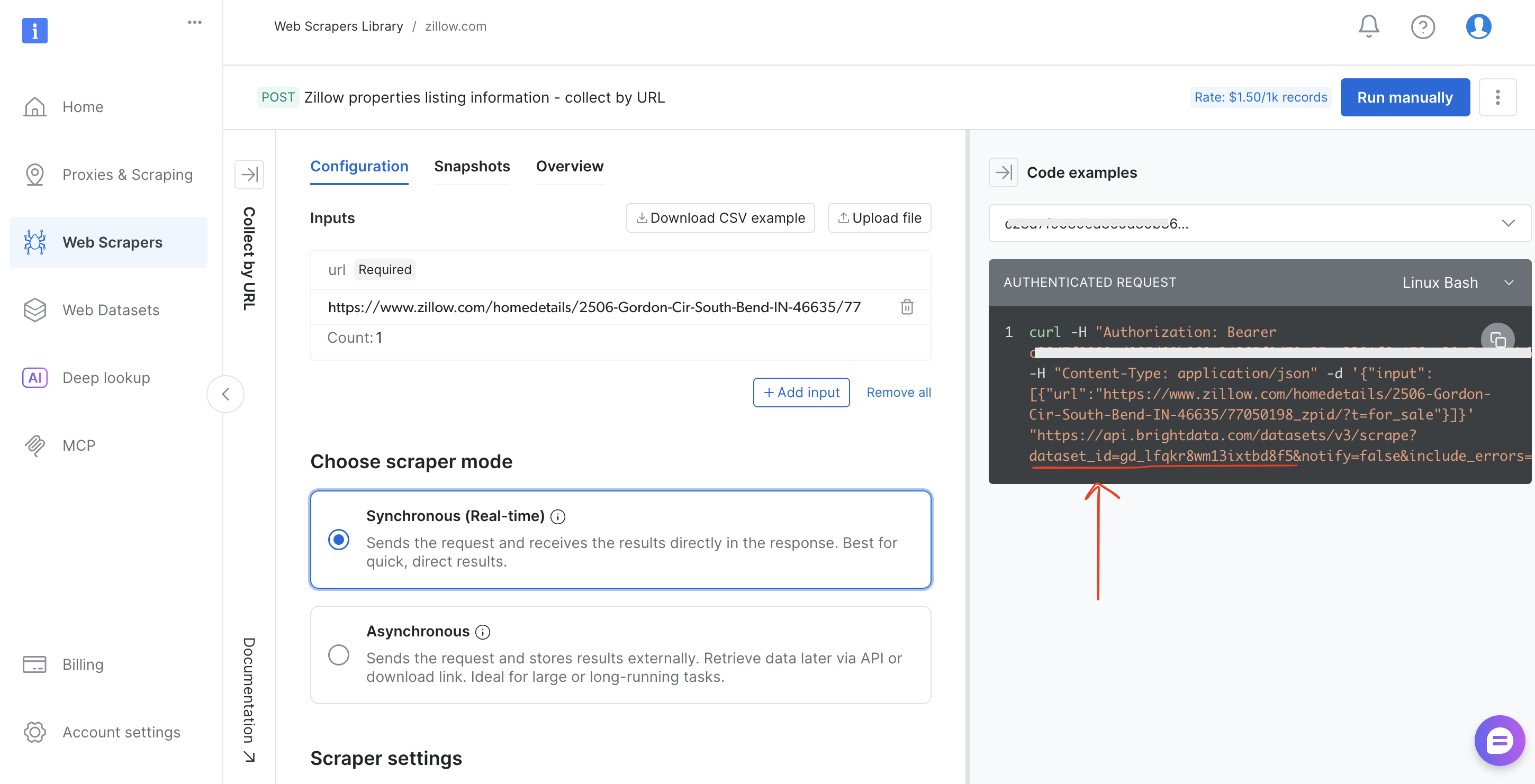
替换脚本中的 DATASET_ID,调整 payload,同样的管道即可用于 Bright Data 120+ 任意抓取器。
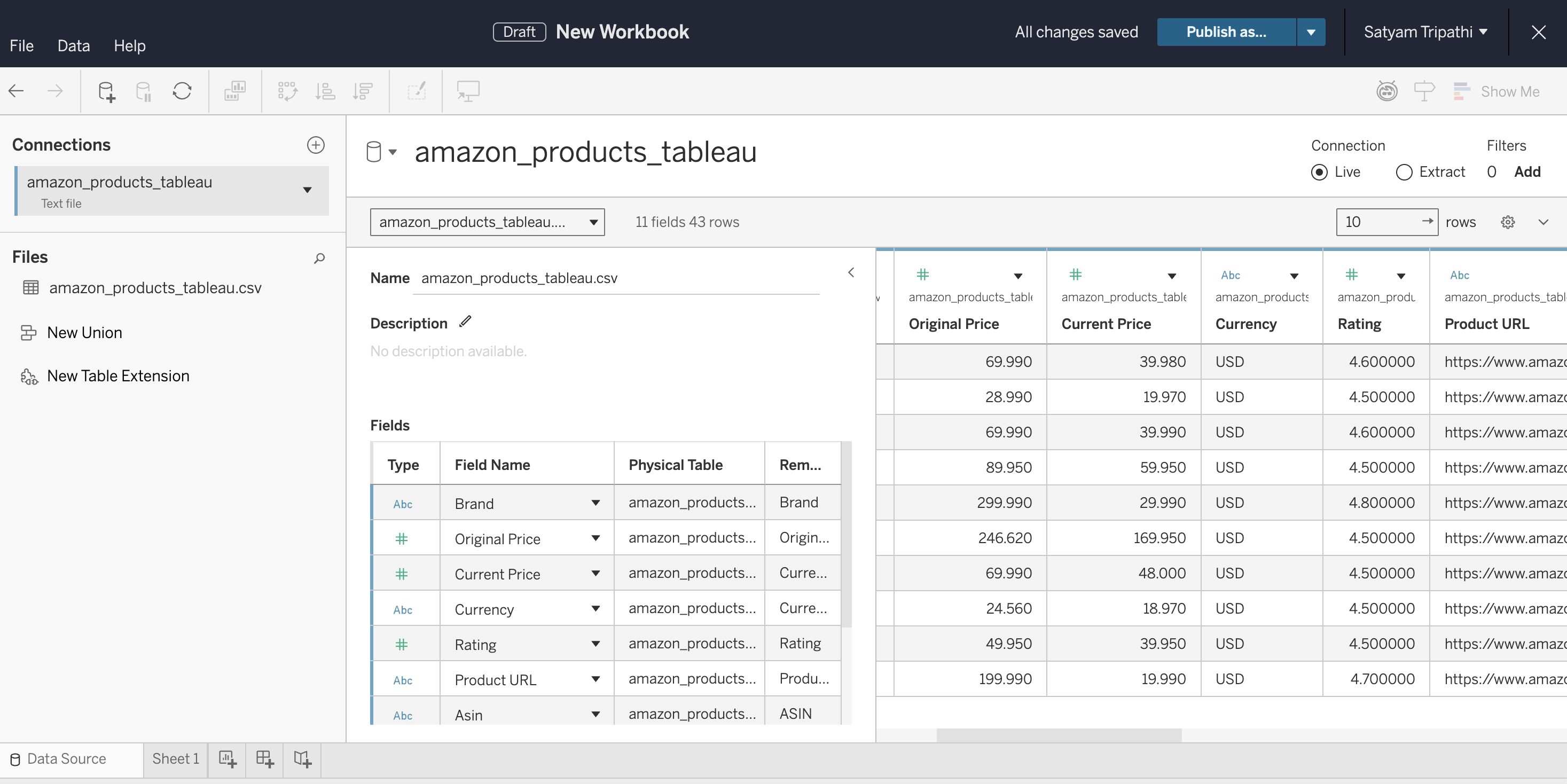
真实结果:抓取数据长什么样
下图展示该管道输出的原始 CSV,也就是 Bright Data API 对关键词 “wireless headphones” 返回的内容:
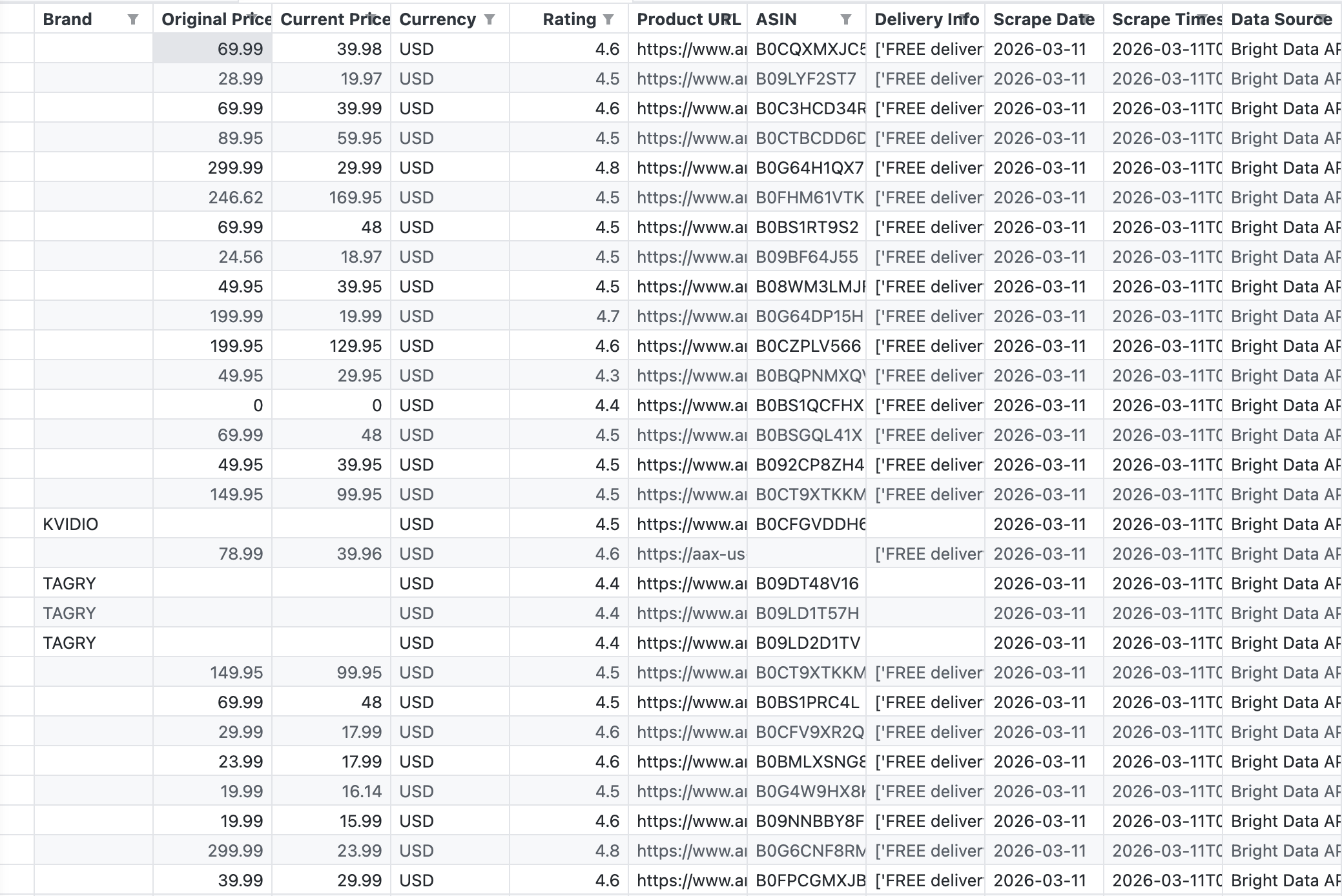
API 返回了 43 条记录,字段包括 Brand、Original Price、Current Price、Rating、ASIN、Product URL 和 Delivery Info。
API 一次调用就返回了43 个商品。数据结构化且可直接用于 Tableau。无需解析 HTML、无需修复失效选择器、无需处理 CAPTCHA。关于 Amazon 抓取方案的更多细节,请参见 如何抓取 Amazon 商品数据。
数据可视化:从 CSV 到洞察
以下四种可视化展示该管道可产出的效果。每个视图都来自脚本生成的同一份 CSV:
商品价格分布
该图表按当前价格从低到高对 31 个商品进行排序(仅包含可从 Amazon URL 解析出名称的商品):
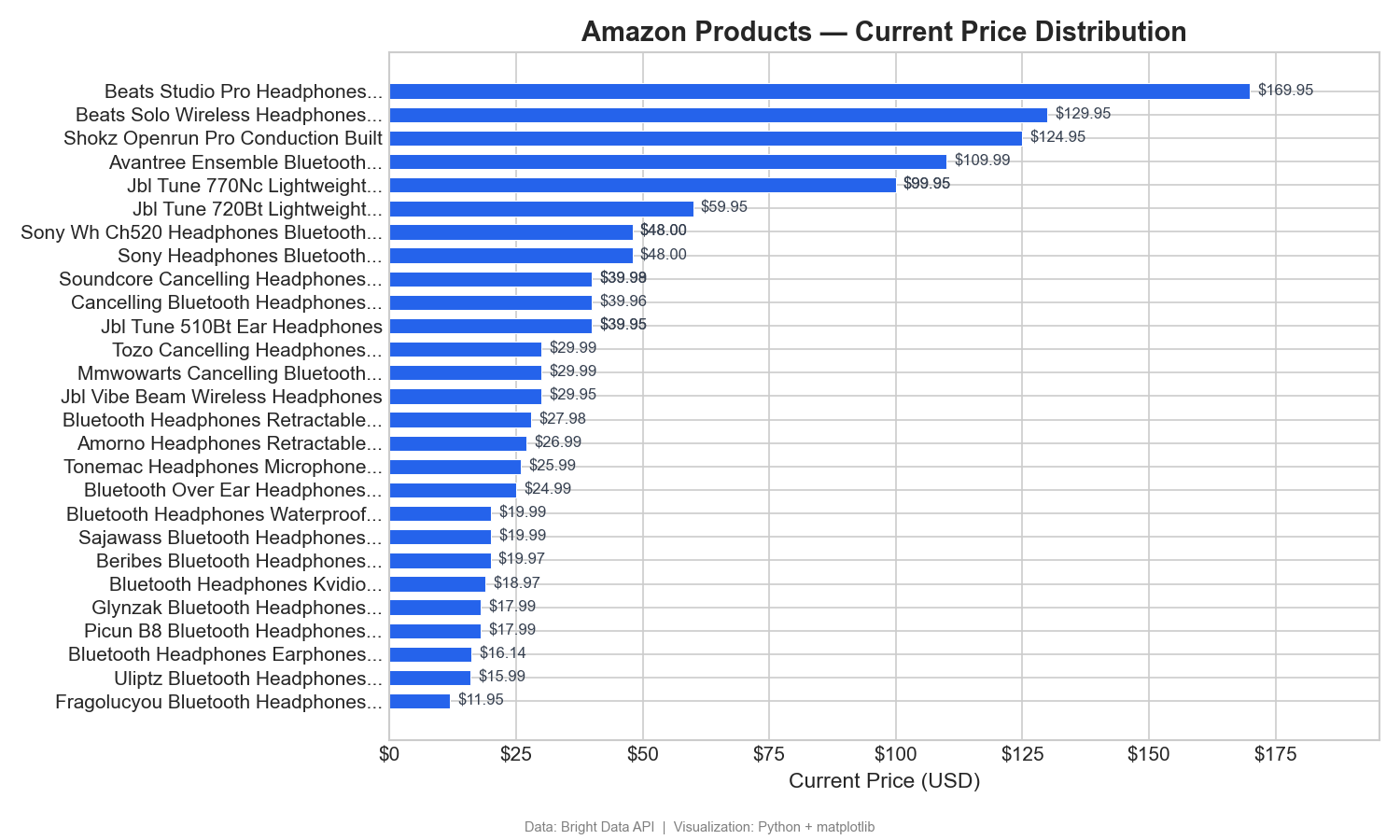
该水平条形图清晰展示价格区间:Beats 处于高端价位($125–$170),而多数无线耳机集中在 $12–$60。Tableau 中可用排序条形图实现:Columns 放 Current Price,Rows 放 Product Name。
降价:原价 vs 现价
该分组柱状图对比折扣最大的前 10 个商品的标价与现价:
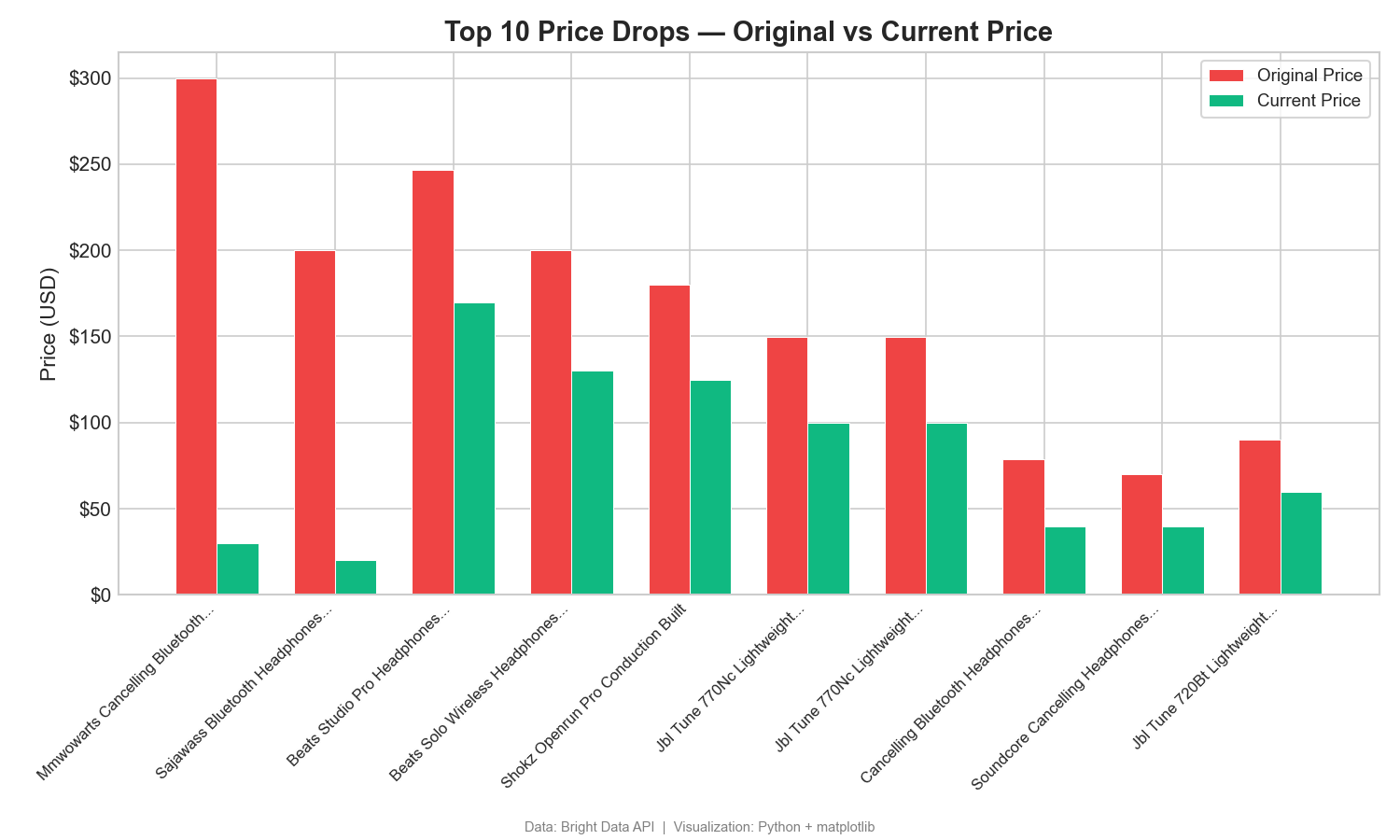
原价与现价之间的差距体现了大幅折扣。其中一个商品从标价 $299.99 降到 $29.99,出现$270 的降幅。这种差距可以揭示促销与定价策略。Tableau 中可用并列柱状图,并将 Measure Names 放到 Color。
评分 vs 价格:寻找高性价比
该散点图将用户评分与价格映射,用于识别高性价比商品:
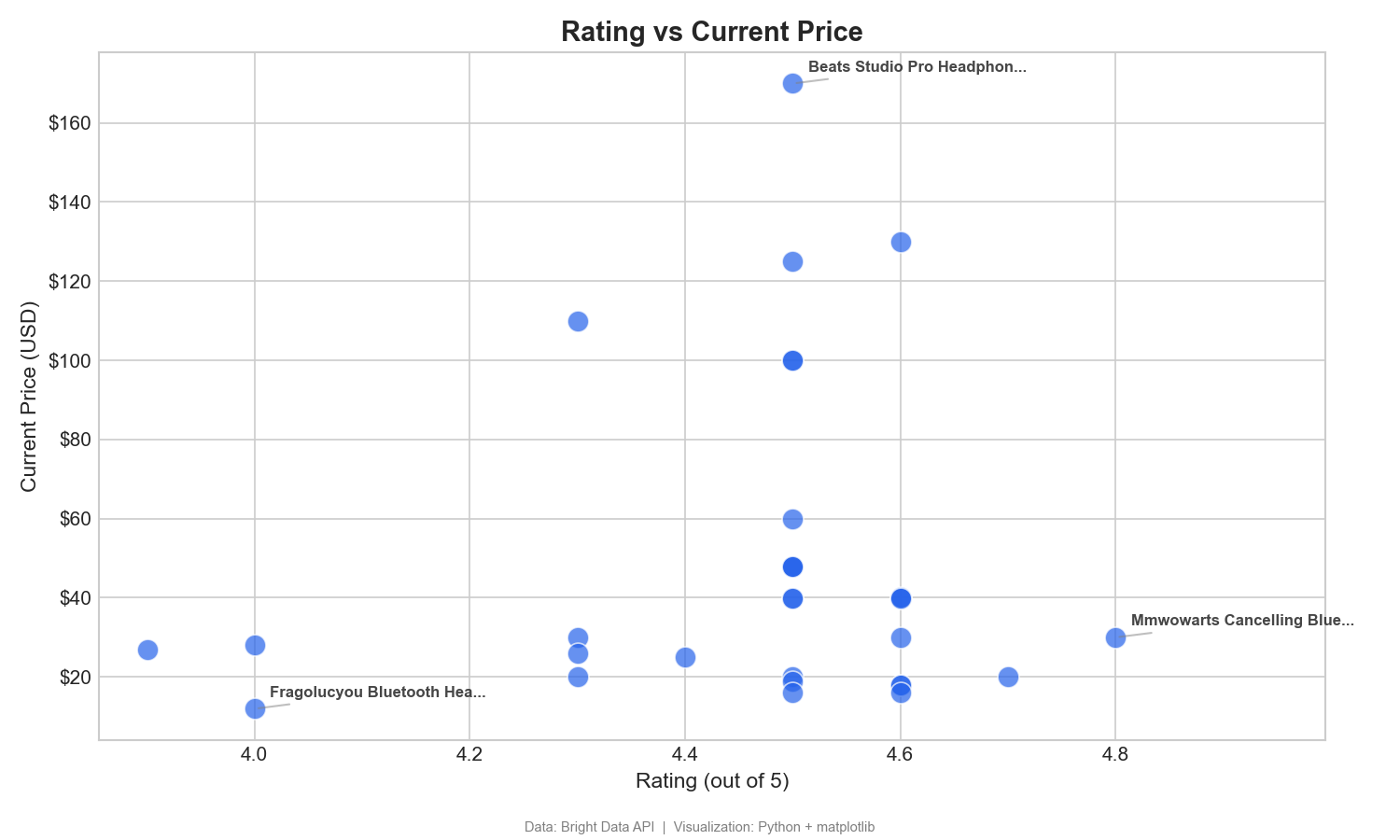
散点图有助于找到高性价比商品——高评分、低价格(右下象限)。例如 MMWOWARTS 耳机价格 $29.99、评分 4.8。Tableau 中把 Rating 拖到 Columns、Current Price 拖到 Rows、Product Name 拖到 Detail。
按价格区间的市场分层
该甜甜圈图按价格区间拆分商品占比:
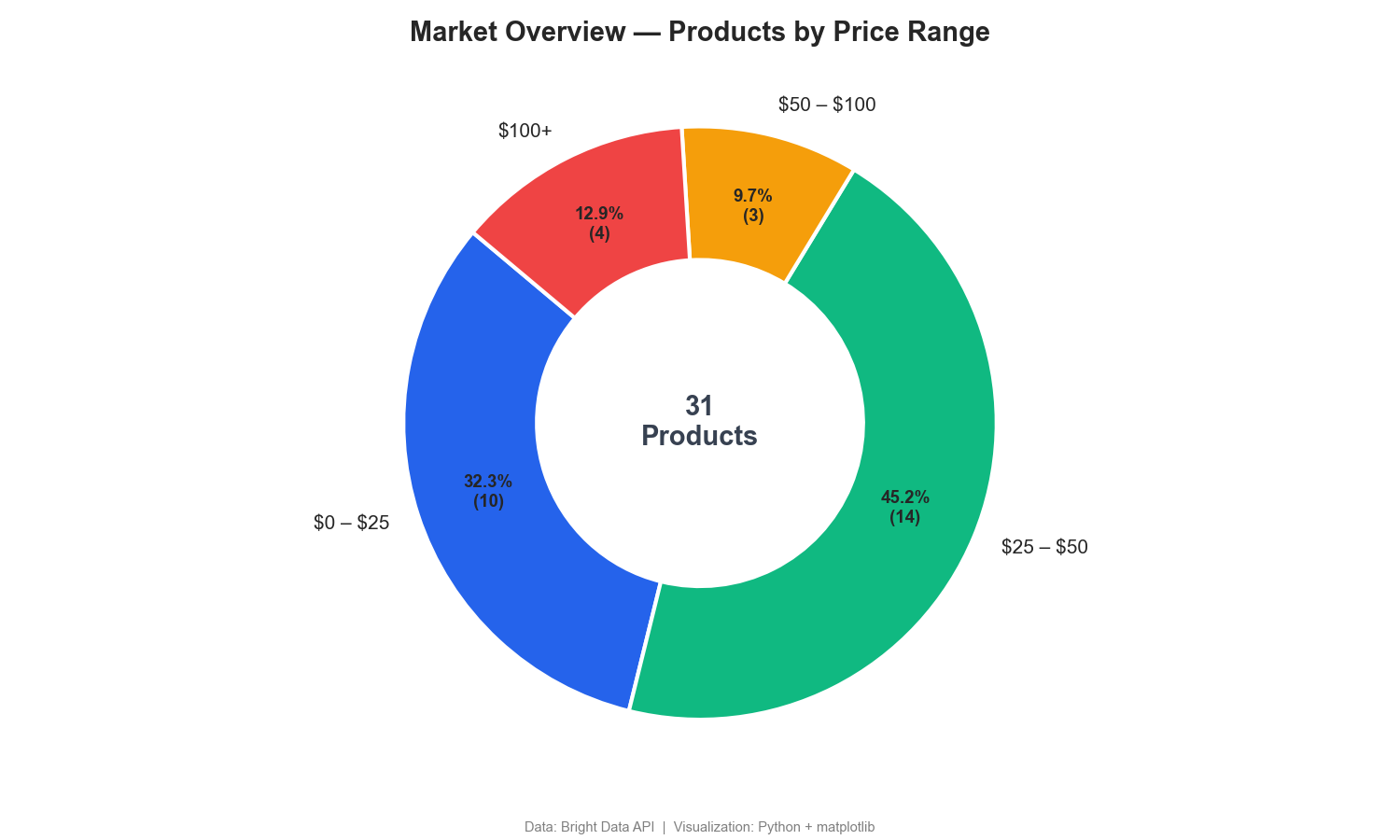
甜甜圈图显示:77% 的无线耳机售价低于 $50,只有 13% 属于 $100+ 的高端段位。竞品价格监控仪表盘通常会包含类似分层。
加分项:使用 Zillow 的房地产管道
同样的管道模式适用于 Bright Data 120+ 任意抓取器。以下示例使用 Zillow Scraper API(GitHub repo)。只需在 bright_data_to_tableau.py 中更新两个变量,其余流程不变:
# Replace the Amazon dataset ID with the Zillow dataset ID
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Zillow Properties然后在 trigger_collection() 中把 payload 改为使用位置 URL,而不是关键词:
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]同样方式运行脚本,轮询与 CSV 导出逻辑无需改动。
Zillow 字段包括:房产地址、价格、卧室数、浴室数、面积、地块面积、建造年份、房产类型、挂牌状态、Zestimate。
Tableau 仪表盘思路:
- 按 ZIP code 的每平方英尺价格热力图
- 挂牌价 vs Zestimate 的差距分析
- 按城市或 ZIP code 的房型分布
- 建造年份 vs 价格散点图,用于寻找翻新机会
关键收益:你学会一次模式,就能应用到任意数据源。Amazon、Zillow、LinkedIn 招聘信息——都可复用同一套 Bright Data 基础设施,将数据输送到 Tableau 仪表盘。
Tableau 中使用实时 Web 数据的 6 大用例
这些是团队将 Web 数据管道接入 Tableau 的最常见原因。
1. 竞品价格监控
跟踪 Amazon、Walmart、Target 或任何 电商平台上的竞品价格。构建 Tableau 仪表盘,展示每日价格波动、历史趋势与市场定价位置。当竞品降到你的最低价以下时设置告警。
使用 Bright Data 120+ 现成抓取器监控多平台、成千上万 SKU。无需自建爬虫工具。
Tableau 视图:价格瀑布图、按 SKU 的时间序列趋势、竞品价格热力图。
2. 社交媒体品牌追踪
从 Instagram、Twitter/X、TikTok 与 LinkedIn 拉取提及量、互动指标、粉丝数和评论数据。构建仪表盘追踪多平台品牌曝光,并衡量活动效果随时间的变化。Scraping Browser 可处理 JS 很重的社交平台,而普通 HTTP 请求无法渲染这些页面。
Tableau 视图:互动率趋势、提及量随时间变化、平台对比柱状图。
3. 就业市场分析
聚合 Indeed、Glassdoor、LinkedIn(GitHub repo)以及细分 招聘网站的职位信息。分析招聘趋势、薪资基准、所需技能以及跨行业与地区的需求变化。HR 团队与招聘人员用这些仪表盘对标薪酬,并在竞争对手之前发现人才市场变化。
Tableau 视图:岗位地理气泡图、薪资分布直方图、技能需求树图(treemap)。
4. 房地产仪表盘
监控 Zillow、Realtor.com、Redfin 与 Airbnb 的房源、价格变化、库存与社区趋势。房地产投资者与分析师会在 Tableau 中构建地理热力图,识别被低估市场并追踪各城市租金收益率趋势。
Tableau 视图:ZIP code 热力图、每平方英尺价格散点图、挂牌量时间序列。
5. 金融数据源
从 Yahoo Finance、Bloomberg 等平台采集股价、财报、分析师评级、内幕交易和金融新闻。量化分析师与投资组合经理使用自动刷新数据的金融仪表盘追踪组合表现与市场信号。
Tableau 视图:K 线风格价格图、业绩超预期柱状图、板块轮动仪表盘。
6. 供应链监控
跟踪全球市场的商品可用性、运输预估、卖家库存与价格。运营团队构建 Tableau 仪表盘,提前发现供应中断(如突然断货或配送时间飙升),避免影响更大范围的供应链环节。
Tableau 视图:可用性状态矩阵、配送时间趋势线、供应商风险评分卡。
以上用例都遵循同一架构:Bright Data API → 结构化数据 → Tableau 仪表盘。变化的只是 dataset ID 和你构建的 Tableau 可视化。
Bright Data API 管道如何工作
教程脚本负责触发与轮询。下面是从 API 调用到 Tableau 仪表盘的全流程。
分步数据流
- 触发:你的 Python 脚本向 Bright Data 的
/trigger端点发送 POST 请求。你可以提供关键词(用于发现)或 URL 列表(用于定向采集)。API 会立即返回snapshot_id。 - 采集:Bright Data 基础设施通过 1.5 亿+ 住宅代理路由请求,自动处理 CAPTCHA,必要时渲染 JavaScript,并对失败请求重试。
- 解析:Bright Data 将原始 HTML 解析为结构化字段。以 Amazon 商品为例,可能包含标题、价格、评分、评论数、卖家信息与库存等——具体字段取决于数据集与搜索类型。
- 快照:采集与解析完成后,Bright Data 将数据保存为 snapshot。脚本轮询
/snapshot,直到状态从202(processing)变为200(ready)。 - 交付:你以 JSON 或 CSV 拉取 snapshot。也可配置交付到 Amazon S3、Google Cloud Storage、Azure Blob、Snowflake、SFTP 或 webhook。自动交付适用于将数据写入数仓的生产管道。
- 转换:你的脚本(或 pandas 等工具)重命名列、筛选字段并格式化为 Tableau 读取友好的数据。在这里可以新增抓取日期、数据来源等元数据列。
- 可视化:Tableau 读取输出文件(或连接到你已写入的数据库)并用最新数据渲染仪表盘。
管道扩展(规模化)
用于生产时,可考虑以下增强:
- 多个关键词:脚本循环处理关键词/品类列表,构建更全面的数据集。
- 写入数据库:用 PostgreSQL 或 MySQL 替代 CSV。Tableau 原生连接两者,历史数据会随时间积累以便做趋势分析。
- 编排:用 Apache Airflow、Prefect 或 cron 按业务频率(每小时/每日/每周)调度运行。
- Webhook 交付:配置 Bright Data 在结果就绪时 POST 到你的服务器,完全跳过轮询。
生产检查清单
在将管道部署到生产定时任务前,请处理这些运维问题:
- 错误处理:用 try/except 包裹 API 调用并加入重试逻辑;将失败记录到日志或监控系统,及时发现数据过期。
- 去重:添加唯一键(如 ASIN + 抓取日期),在导入 Tableau 前去重,避免聚合被重复行扭曲。
- Schema 校验:写 CSV 前先校验 API 响应包含预期字段;网站变化可能在无提示的情况下改变数据结构。
- 监控与告警:为失败运行、空数据集、行数异常下降设置告警(邮件、Slack 或 PagerDuty)。
- 数据备份:按时间戳归档每次 CSV 快照;若某次错误抓取破坏了工作文件,可回滚到上一版本。
为什么用 Bright Data 搭建 Tableau 管道
对于生产级 Tableau 工作流,这些因素很关键:
- 灵活交付:通过 API、webhook、Amazon S3、Google Cloud、Azure 或 SFTP 以 JSON/CSV/NDJSON 获取结果,把数据导入你的 Tableau 数仓。
- 自定义或现成方案:使用 Serverless Functions 创建自定义抓取器,使用 Scraper Studio 创建 AI 驱动与生成式抓取器,或直接使用 现成数据集,无需写代码即可快速获取数据。
- 成本可控:按量付费 $1.50/1,000 条记录起,量大可降至 $0.75/1K。
搭建你的实时 Web 数据管道
可用数据与所需数据之间的差距仍在扩大,尤其当数据位于开放 Web 上且没有 API 或连接器时更是如此。
WDC v2 已弃用且不再受支持。Google Sheets 会触及单元格上限。Excel 需要大量手工操作。TabPy 缺少代理轮换。自建脚本在规模化时会失效。
Bright Data Web Scraper API 提供这些方案缺失的基础设施层。API 提供120+ 现成抓取器、覆盖 195 个国家/地区的 1.5 亿+ 代理、自动 CAPTCHA 处理,以及 Tableau 原生支持的结构化数据输出格式。定价 $1.50/1,000 条记录起,99.99% 可用性,并符合 GDPR、CCPA 与 ISO 27001。
与其搭建数据采集基础设施,不如把精力放在搭建仪表盘上。
常见问题
Tableau WDC 被弃用了吗?
是的。Tableau 的 Web Data Connector v2 已在 2023.1 版本中被官方弃用。最后支持 WDC v2 的 Tableau 2022.4 已生命周期结束。WDC v2 连接器在当前所有 Tableau 版本中均不受支持,并可能在未来更新中被移除。
Tableau WDC 的替代方案是什么?
Tableau 推出了 WDC v3,但它仅支持 Extract,且不受 Tableau Bridge 支持。对于实时 Web 数据,一个可行替代方案是使用抓取 API 管道(Bright Data → CSV/JSON → Tableau)。本文教程会搭建这条管道。
Tableau 能直接连接到网页抓取 API 吗?
不能原生支持。Tableau 主要连接数据库、文件以及特定云服务。要使用抓取 API,你需要一个轻量脚本(Python 或 Node.js)调用 API 并接收数据,然后输出 Tableau 可读取的格式:CSV、JSON 或写入数据库。
如何让我的 Tableau 仪表盘数据保持最新?
使用 cron(Linux/Mac)、任务计划程序(Windows)或 Apache Airflow 等工作流编排器定时运行数据采集脚本。脚本从 Bright Data API 拉取最新数据并覆盖 CSV 文件。Tableau 会在下次刷新周期加载更新后的数据。
将网页数据加载到 Tableau 的成本是多少?
Bright Data Web Scraper API 按量付费 $1.50/1,000 条记录起,量大可降至 $0.75/1K。对于一个典型的竞品监控仪表盘(每天跟踪 5,000 个商品),大约是 $7.50/天 或约 $225/月。
Bright Data 输出哪些 Tableau 可用的数据格式?
Bright Data 通过 API 输出 JSON、CSV 或 NDJSON。对 Tableau 来说,CSV 最直接,Tableau 可原生读取且无需转换。你也可以配置自动交付到 Amazon S3、Google Cloud Storage、Azure Blob、Snowflake、SFTP 或 webhook 以适配生产管道。
我能在 Tableau Public 中使用 Bright Data 吗?
可以。Bright Data 输出标准 CSV,Tableau Public 可原生读取。限制在 Tableau Public 一侧:它不支持文件型数据源的定时刷新。每次数据更新后,你需要重新运行数据采集脚本并重新发布工作簿。



高级 SEO 专家
 6 years experience
6 years experience
Daniel Shashko 是 Bright Data 的高级 SEO/GEO 专家,专注于 B2B 营销、国际 SEO,以及开发 AI 驱动的代理、应用与网页工具。




