在本教程中,你将探索:
- 用于客户识别的完整分步工作流。
- 如何使用 Bright Data 的 Filter API 生成专门为你的需求量身定制的 Crunchbase 数据集。
- 如何利用 Bright Data API 和 AI 进行数据丰富与分析,从而处理该数据集以进行客户挖掘。
让我们开始吧!
展示新的客户识别工作流
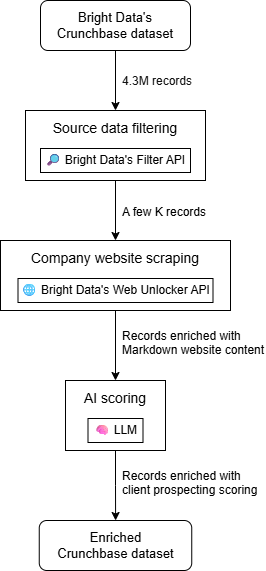
从高层来看,你可以通过三个主要步骤构建一个由 AI 驱动的客户挖掘工作流:
- 源数据筛选:从 Crunchbase 数据集开始,并根据你的独特需求对其进行筛选。
- 公司网站抓取:为数据集中的每家公司检索其主页内容。
- AI 评分:使用 AI 基于其网站内容(以及公司记录中可能的其他字段)评估每家公司,以生成针对你的产品或服务量身定制的客户挖掘评分。
输出将是一个丰富后的数据集,其中每条 Crunchbase 公司记录都包含额外的列,包含客户挖掘评分和其他附加信息。然后,你可以筛选结果数据集或按评分排序,以确定应先联系哪些公司。
了解每一步以及如何实现它们!
1. 源数据筛选
该工作流的理想来源是包含公司信息的数据集。Bright Data 是最佳公司数据提供商,提供覆盖 LinkedIn、Crunchbase、Indeed 等众多平台的丰富数据集。
对于客户挖掘而言,Crunchbase 尤其有价值,因为它具有 CB Rank、Heat Score 等专业字段以及其他指标,可让你快速评估一家公司的行业影响力。
Bright Data 提供一个包含超过 430 万条记录的 Crunchbase 数据集。直接处理如此庞大的数据集会很有挑战性,因此你可以使用 Filter API 将其缩小到符合你特定标准的公司。例如,你可以仅获取处于特定员工规模范围内、当前活跃并且满足其他相关方面的公司。
2. 公司网站抓取
筛选后的 Crunchbase 数据集中的数据字段当然很有趣。然而,仅凭这些字段通常不足以进行准确的客户识别。要真正评估一家公司,分析其网站是最有效的方法之一。这能让你洞察公司做什么,以及它是否可能从你的服务中受益。
以编程方式从每家公司的网站检索内容具有挑战性。这是因为每个站点结构不同,并且可能受到反爬虫措施保护,例如 IP 封禁、地理位置限制、CAPTCHA 等。有些站点还需要 JavaScript 渲染。
为了持续应对这些挑战并以适合 LLM 分析的格式获取网站内容,最佳解决方案是依赖 Bright Data 的 网络解锁器 API。该端点允许你抓取任何网站,无论其保护程度如何。
3. AI 评分
最后,一旦你获得了已筛选的 Crunchbase 数据集,并用每家公司的网页内容对其进行了丰富,就可以将每条记录输入给 AI。提供你的服务/产品描述,并让 AI 评分每家公司是否与你的产品或服务匹配。
通过 Bright Data 的 Filter API 获取专门适配你需求的 Crunchbase 数据集
让我们通过检索源数据来启动由 AI 驱动的客户挖掘工作流。这将是一个筛选后的 Crunchbase 数据集,包含符合与你的挖掘假设相关标准的公司。
这一步确保你只处理重要的数据,与处理更大的数据集相比可节省时间和成本。正如你即将看到的,Bright Data 在这里大放异彩,得益于其高级筛选能力——尤其是通过其 Filter API。
按照以下说明检索你定制的 Crunchbase 数据集!
先决条件
要跟随本节内容,你应具备:
- 一个已设置 API key 的 Bright Data 账户。
- 一个本地 Python 环境,并安装了
requests。 - 对 Bright Data 数据集与快照生成如何工作 的基本理解。
要配置 Bright Data API key,请阅读官方指南。
第 #1 步:筛选 Crunchbase 数据集
先登录你的 Bright Data 账户。在控制面板中,导航到“Web 数据集”页面并选择“数据集 Marketplace”选项卡。在“数据集 Marketplace”页面,搜索“crunchbase”并选择“Crunchbase companies information”数据集: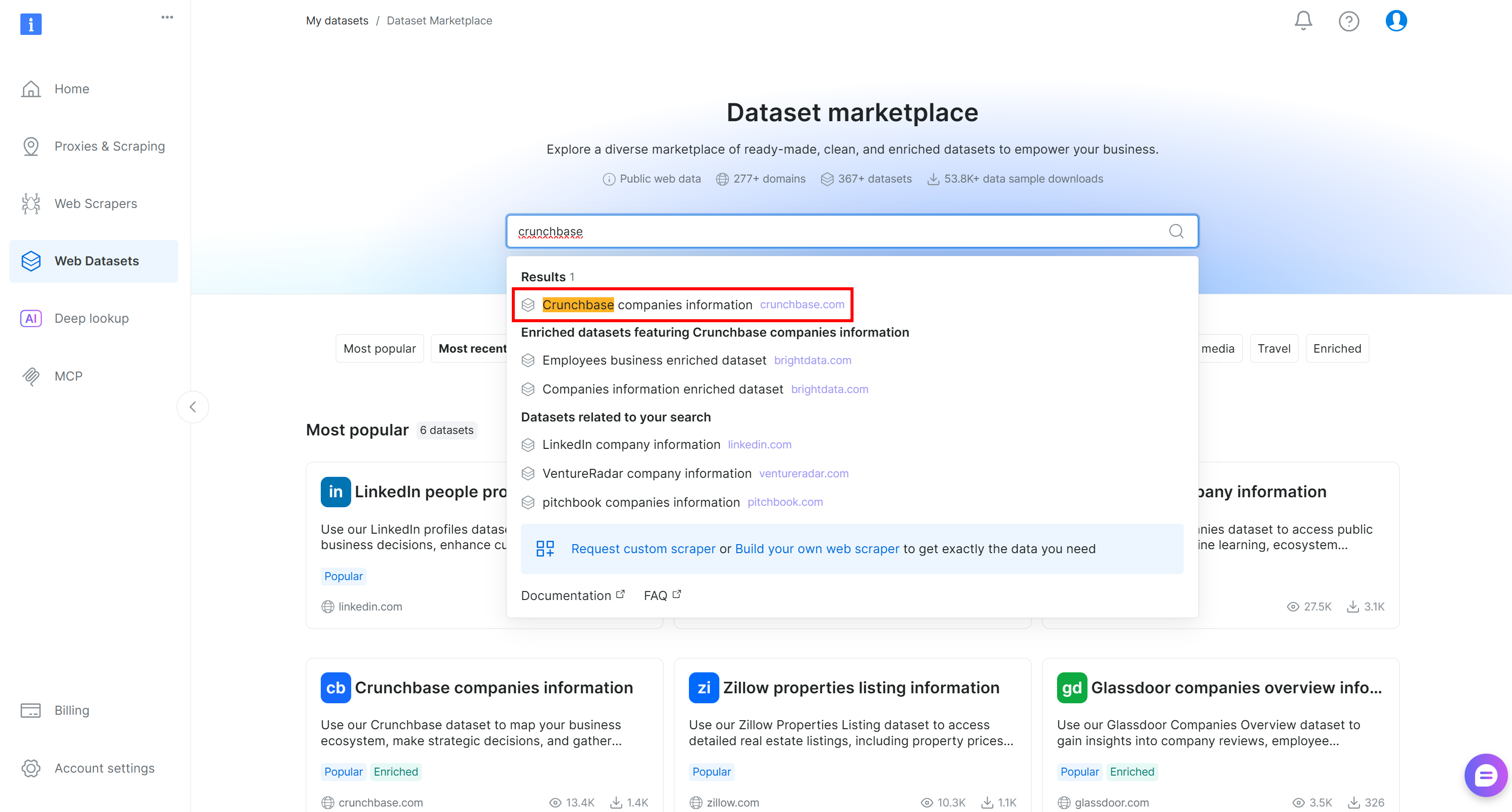
你将被重定向到“Crunchbase companies information”数据集页面。在那里,你可以通过点击左侧的“Filters”按钮,直接在控制面板中应用数据筛选: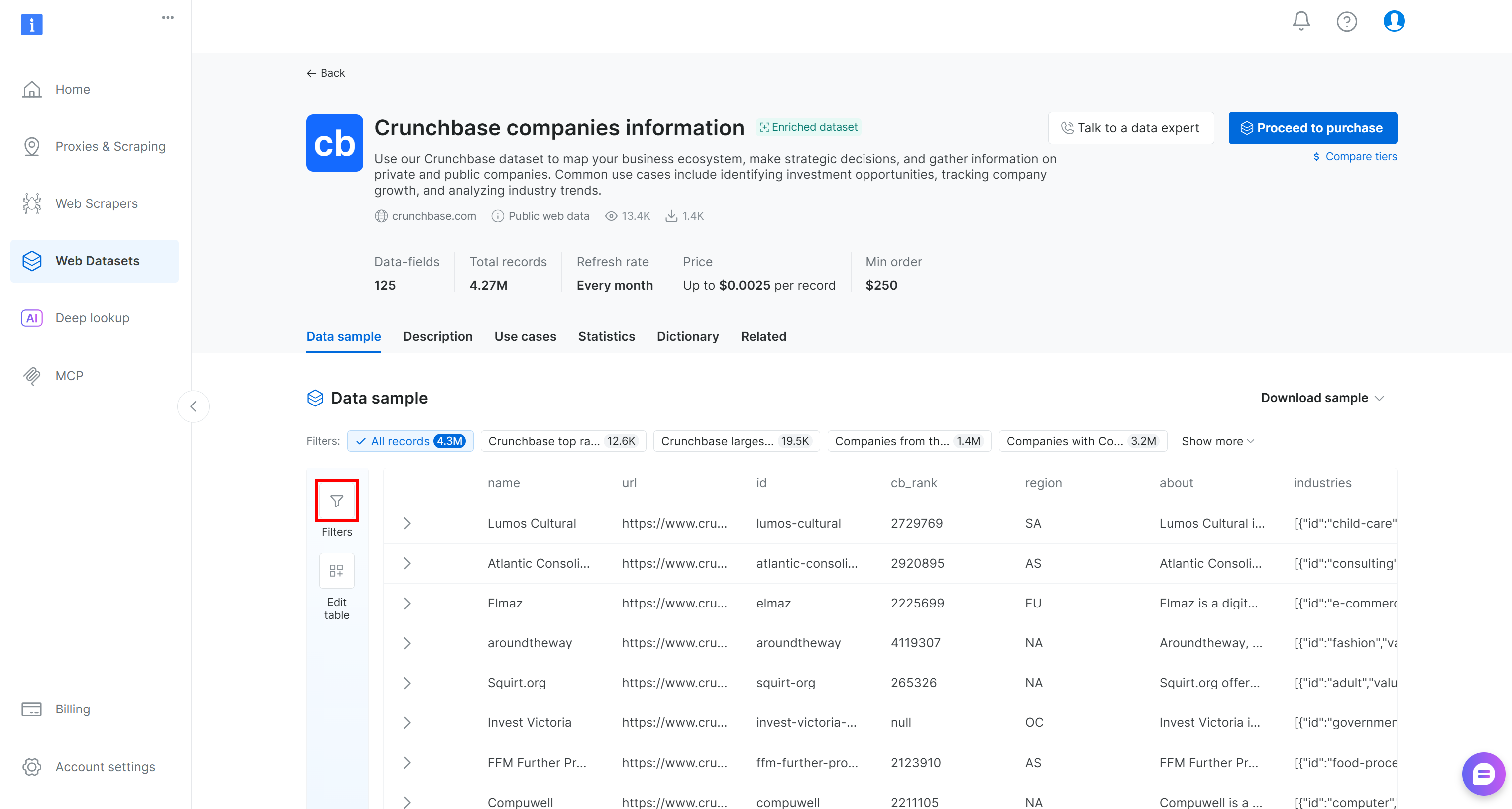
具体来说,你可以为 125+ 个数据字段中的每一个添加一个或多个筛选条件。应用筛选条件可以更轻松地从 430 万条公司条目完整列表中识别潜在优质客户。
例如,假设你想找到满足以下条件的公司:
- 位于北美或欧洲。
- 正在营业。
- 在 AI 行业运营。
- CB Rank 小于或等于 10,000。
- 员工少于 250 人。
website字段已填充。- heat score 小于或等于 60。
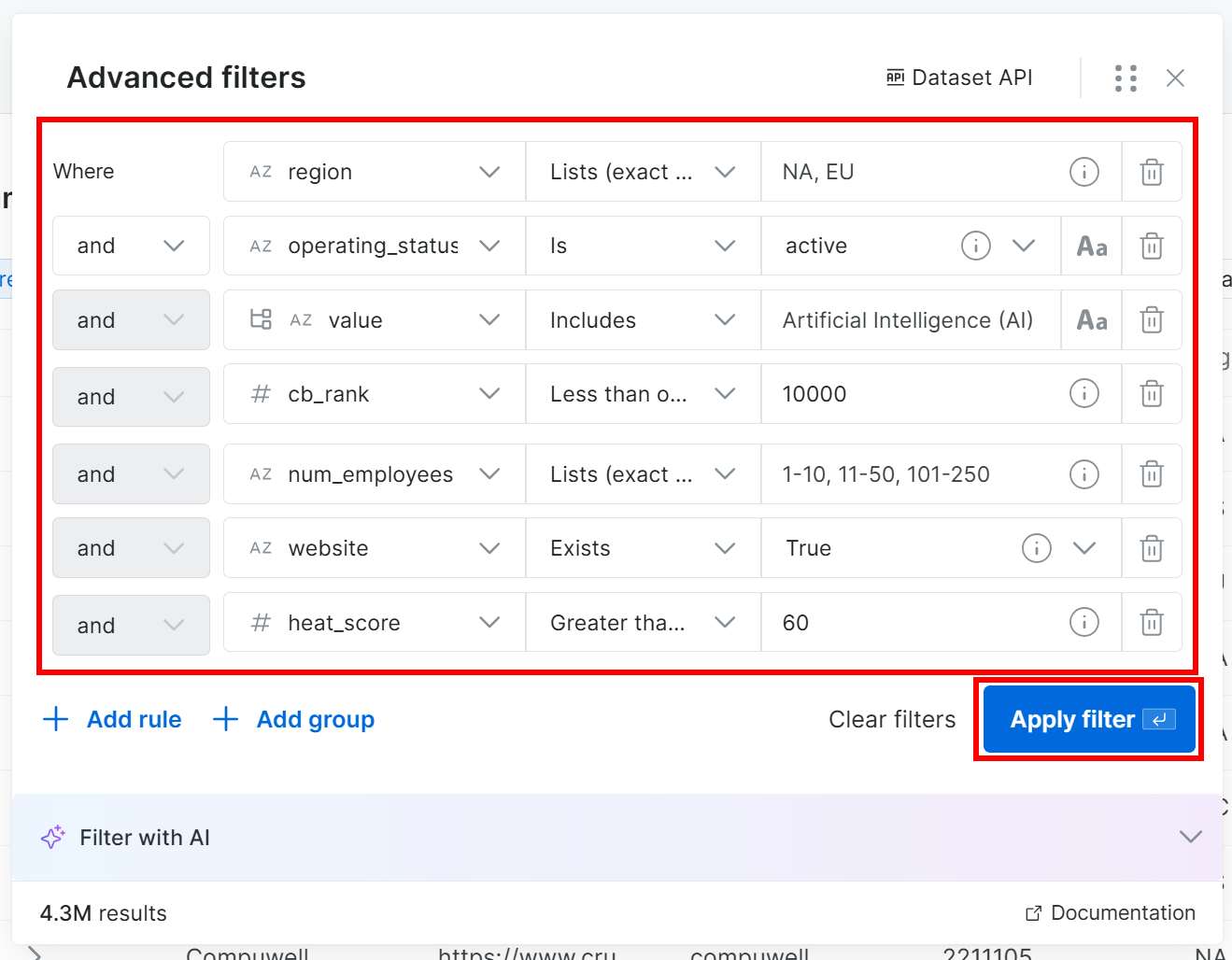
注意:如果你不想手动添加筛选条件,请点击“Filter with AI”按钮,并用自然语言提示描述你想要的数据。
点击“Apply Filter”按钮并耐心等待,因为筛选可能需要一些时间。Bright Data 将显示前 30 条记录的预览,以便你验证筛选条件是否符合预期。
你还会看到筛选后数据集的记录总数:
在此示例中,从 430 万条记录中,你获得了 1.3k 个可用于挖掘的潜在客户。这就是 Bright Data 筛选能力的强大之处,它帮助你从庞大的初始数据集中精确提取所需数据。很酷!
第 #2 步:调用 Filter API
现在,你有两个选项:点击“Proceed to purchase”直接下载数据集,或使用 Filter API 以编程方式生成它。调用 Filter API(属于 Bright Data 的 数据集 API 的一部分)可提供可重复性和更多控制,因此我们将采用该方法。
在筛选条件弹窗中,点击“数据集 API”按钮。这将显示在给定数据集上调用 Filter API 所需的代码,并应用你选择的筛选条件。选择“Python”选项以获取 Python 代码片段: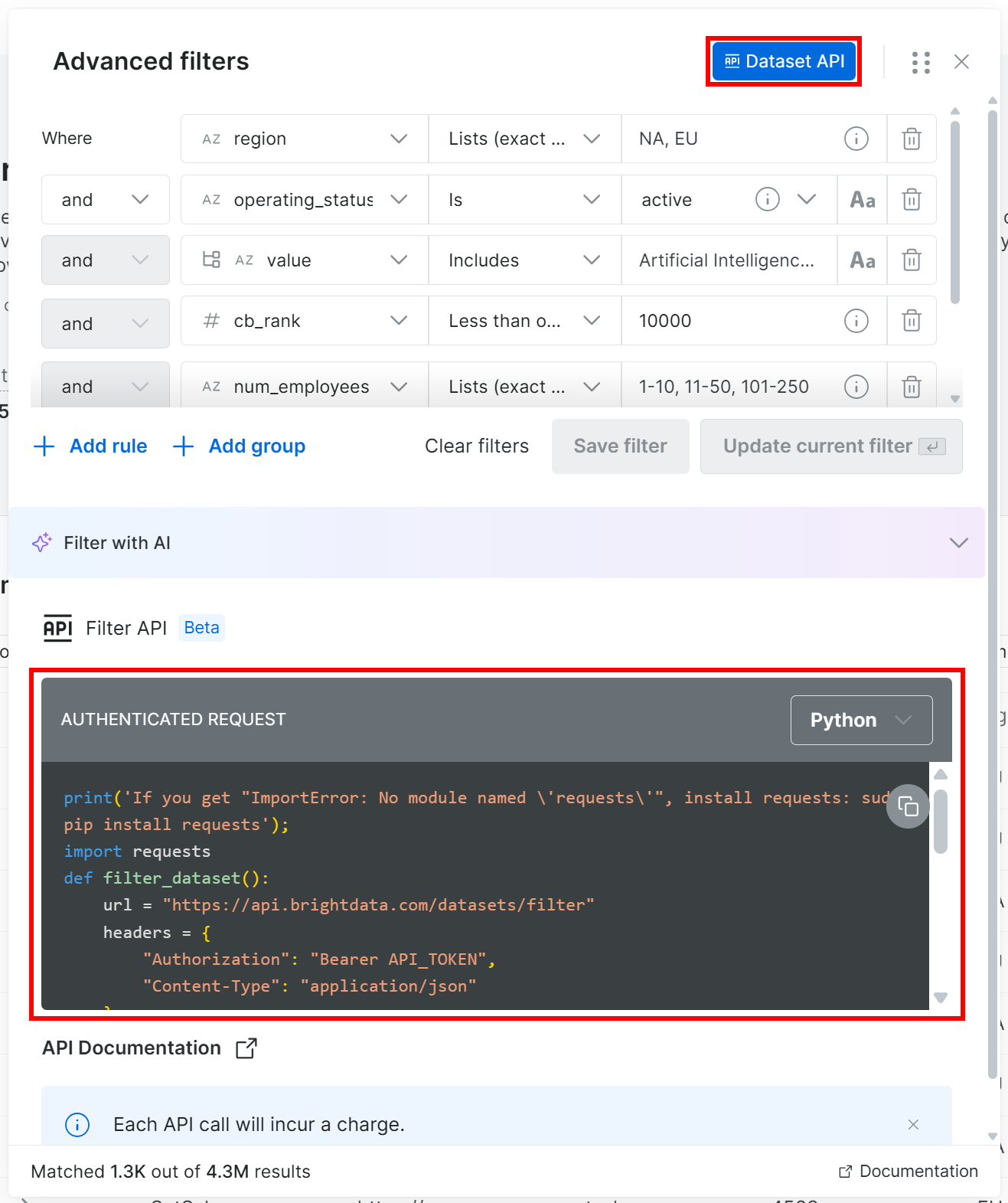
这一次,你将获得一个类似这样的 Python 代码片段:
print('If you get "ImportError: No module named \'requests\'", install requests: sudo pip install requests');
import requests
def filter_dataset():
url = "https://api.brightdata.com/datasets/filter"
headers = {
"Authorization": "Bearer API_TOKEN",
"Content-Type": "application/json"
}
payload = {
"dataset_id": "gd_l1vijqt9jfj7olije",
"filter": {"operator":"and","filters":[{"name":"region","value":["NA","EU"],"operator":"in"},{"name":"operating_status","value":"active","operator":"="},{"name":"industries:value","value":"Artificial Intelligence (AI)","operator":"includes"},{"name":"cb_rank","value":10000,"operator":"<="},{"name":"num_employees","value":["1-10","11-50","101-250"],"operator":"in"},{"name":"website","operator":"is_not_null"},{"name":"heat_score","value":60,"operator":">="}]}
}
response = requests.post(url, headers=headers, json=payload)
if response.ok:
print("Request succeeded:", response.json())
else:
print("Request failed:", response.text)
filter_dataset()将 API_TOKEN 占位符替换为你的 Bright Data API key,将脚本保存到本地,并在你的 Python 环境中运行它。
如果一切正常,你应该会看到:
Request succeeded: {'snapshot_id': 'snap_XXXXXXXXXXXXXXXXXXX'}这意味着生成新数据集快照的任务已开始。
此时,你可以:
- 通过 数据集 API 检查状态并下载它,或
- 从控制面板手动下载它(这就是我们在下一步要做的!)
第 #3 步:检索筛选后的数据
一旦快照生成任务完成,你将收到一封电子邮件,通知你的快照已就绪: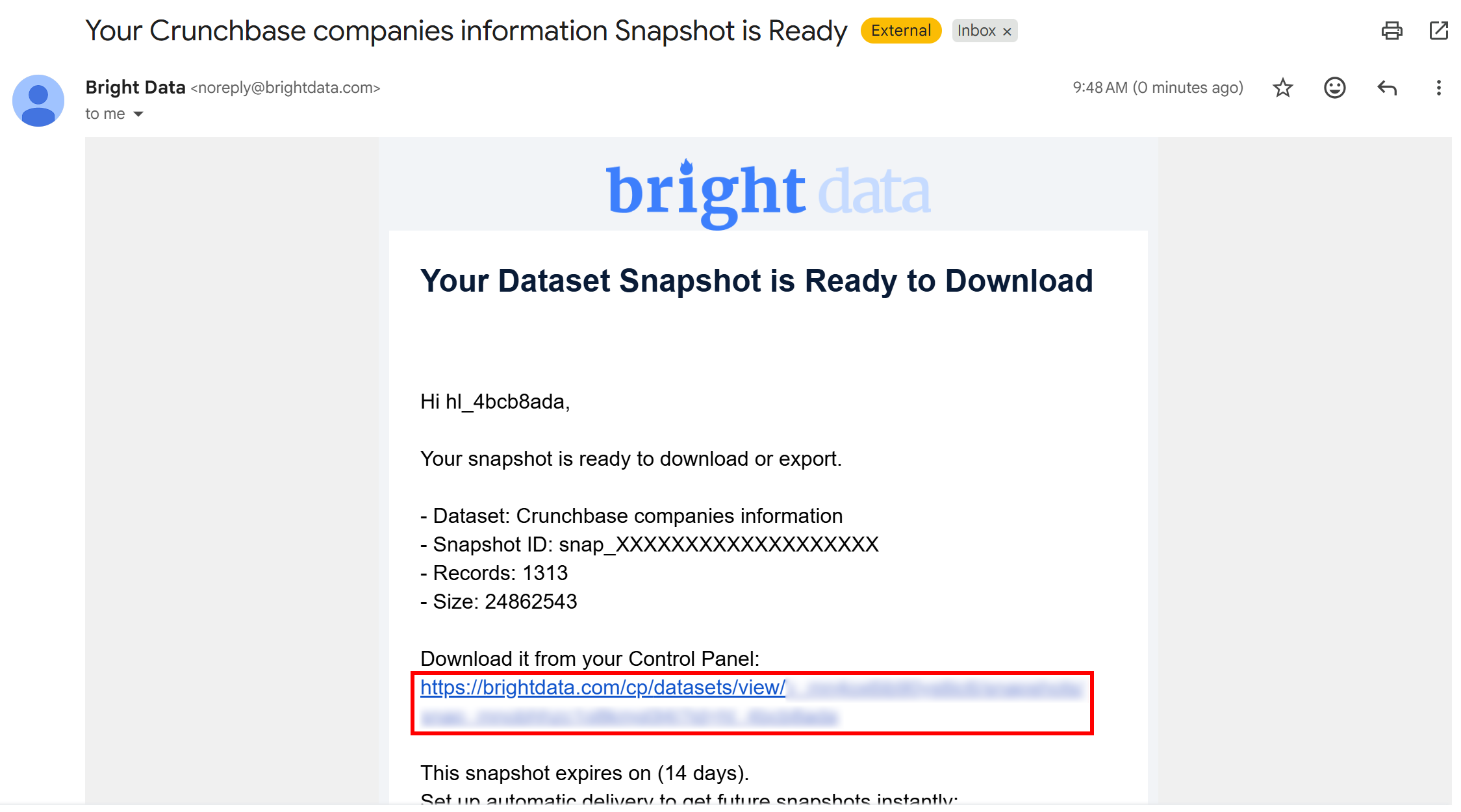
点击邮件中的 URL,你将进入 Bright Data 控制面板中的快照页面: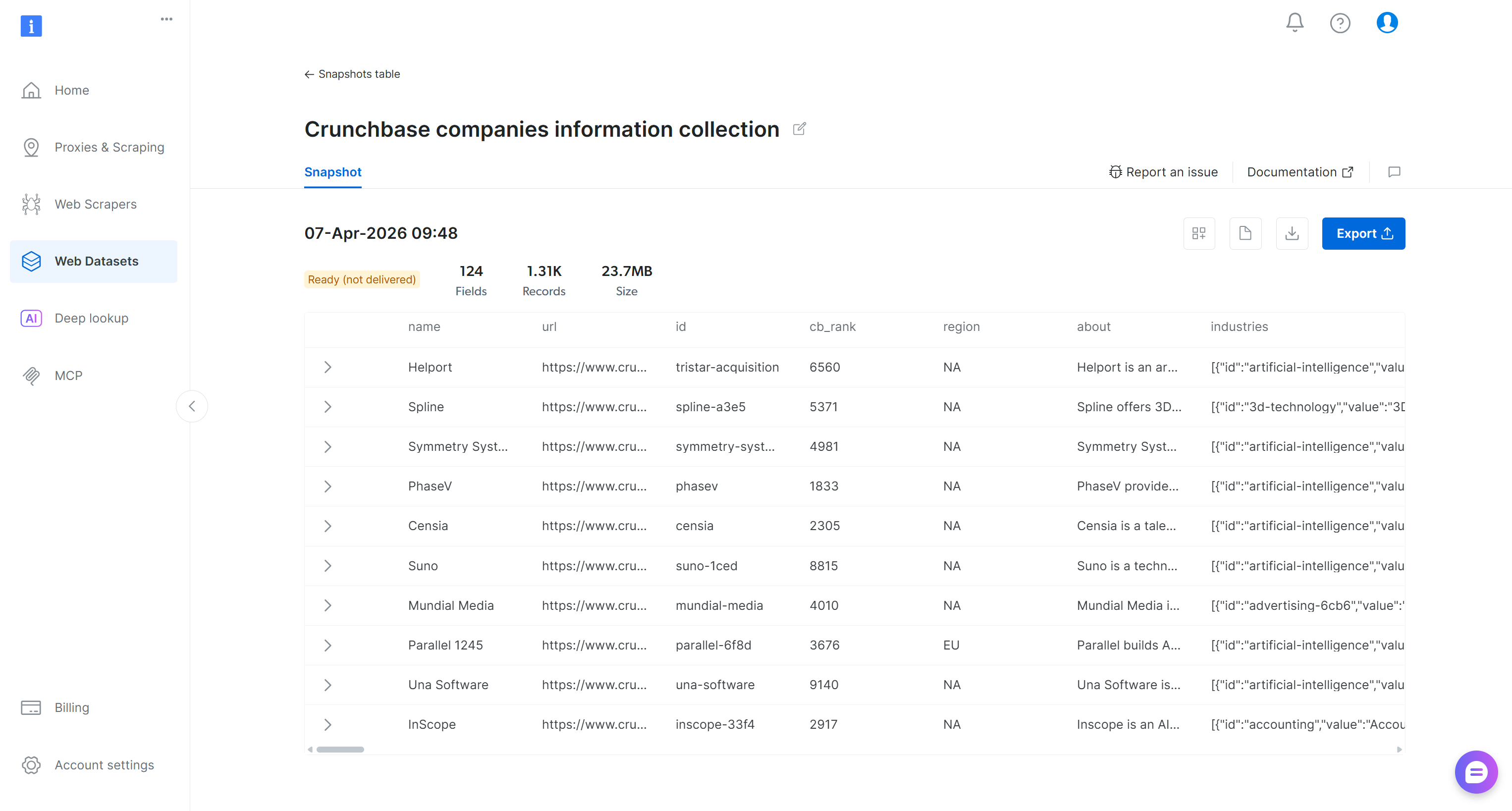
在这里,你可以探索筛选后的数据集、下载它并访问更多详细信息。例如,你可以下载一份包含洞察的报告,例如记录数量和总成本。在这种情况下,报告显示你花费了 $3.29 并检索了 1,313 条记录(记住:定价为每 1,000 条记录 $2.50):

要检索快照,点击“Download”图标并选择“CSV”选项:
你的浏览器将下载一个名为 snap_XXXXXXXXXXXXXXXXXXX.csv 的文件,其中包含筛选后的 Crunchbase 数据。完美!
第 #4 步:探索筛选后的数据集
打开 snap_XXXXXXXXXXXXXXXXXXX.csv 文件,你应该会看到如下内容: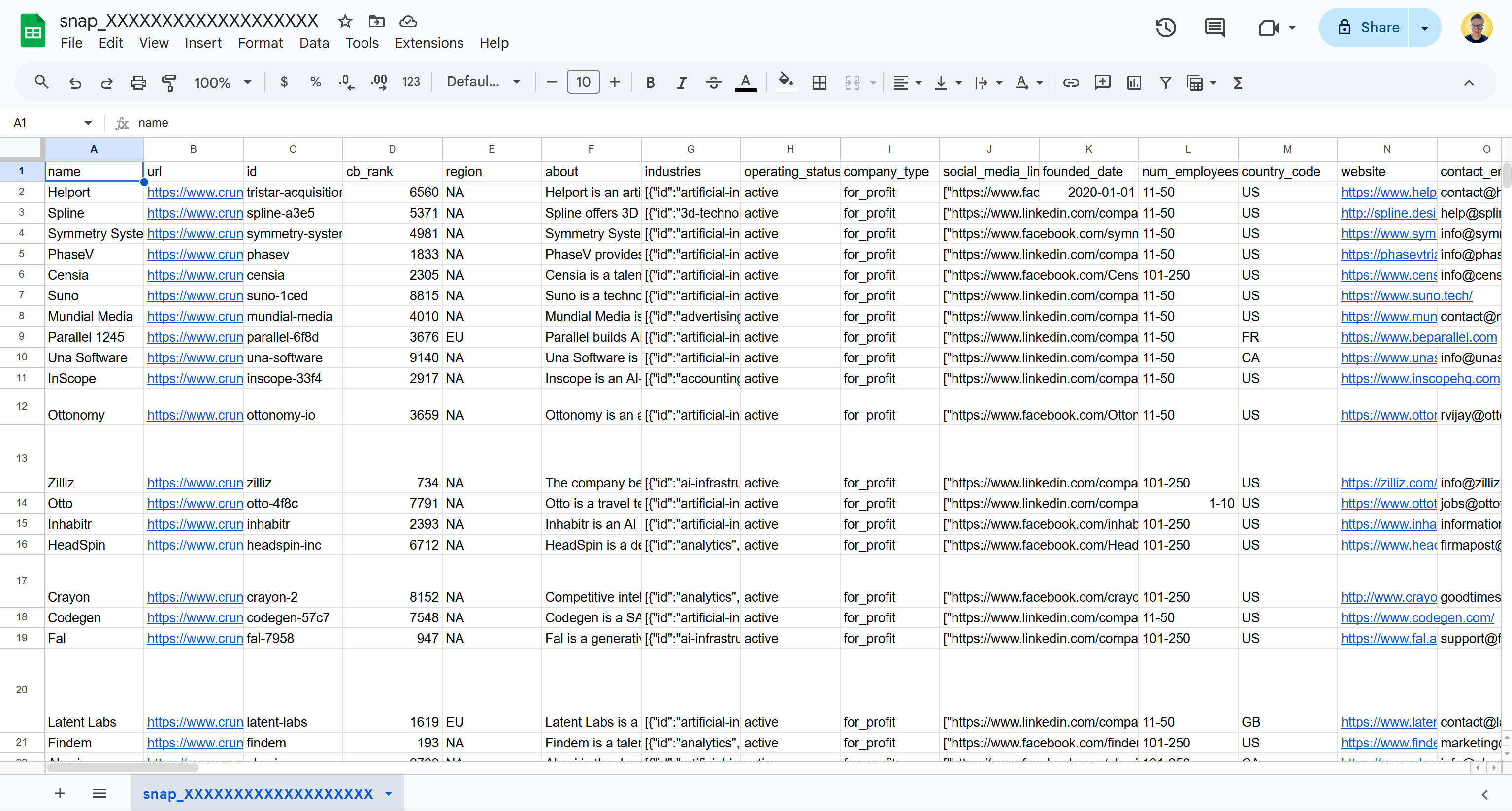
注意下载的数据集包含 1,313 条 Crunchbase 公司条目(每条有 133 列),它们匹配指定的筛选条件。
任务完成!你现在拥有源数据,可以通过 由 AI 驱动的数据转换与丰富 来进行客户挖掘。
注意:在继续之前,请审查数据集,并考虑应用额外的筛选步骤以进一步缩小内容范围,如支持本文的 “Crunchbase Data Analysis for Client Prospecting” Kaggle notebook 中所示。
如何从定制的 Crunchbase 数据集开始使用 AI 挖掘新客户
筛选后的 Crunchbase 数据集将作为数据处理与丰富工作流的来源。对于每一行,该过程将:
- 访问公司的官网,并使用 网络解锁器 API 以 Markdown 格式检索其内容。
- 将公司的内容传递给 AI 模型,请它理解公司做什么,并提供一个评分,指示该公司对你的业务而言作为潜在客户有多合适。
看看如何实现它!
先决条件
要跟随本节内容,请确保你满足之前的先决条件,以及:
- 在你的 Bright Data 账户中已设置一个 网络解锁器 API 区域(例如
web_unlocker)。 - 了解 网络解锁器 API 的工作方式及其支持的功能。
- 一个 OpenAI API key。
要创建 网络解锁器 区域,请阅读 Bright Data 文档中的“Create Your First Unlocker API”指南。下面,我们将假设你的 网络解锁器 区域名为 web_unlocker。
为简单起见并保持本教程简洁,我们将假设你已经准备好了一个本地 Jupyter Notebook 环境。
第 #1 步:将源筛选数据集上传到你的 Notebook
启动 Jupyter Notebook 并创建一个新 notebook(例如命名为 client_prospecting.ipynb)。然后,上传 snap_XXXXXXXXXXXXXXXXXXX.csv 文件:
该文件将作为你由 AI 驱动的客户挖掘工作流的源数据。做得好!
第 #2 步:安装所需的库
在深入数据丰富逻辑之前,先安装该工作流所需的依赖。为此,添加一个包含以下内容的单元格:
!pip install pandas requests pydantic openai这将安装以下库:
pandas:用于加载包含 Crunchbase 数据的源 CSV,并以 DataFrame 形式处理。requests:用于连接 Bright Data 网络解锁器 API 以下载公司主页。pydantic:用于为 OpenAI 任务定义结构化输出。openai:用于与 OpenAI 模型交互,以对给定主页进行客户挖掘排序。
点击“▶”按钮执行该单元格以安装这些库。太棒了!你的 notebook 现在包含了从筛选后的 Crunchbase 数据集开始进行 AI 驱动客户挖掘所需的全部依赖。
第 #3 步:设置初始单元格
为了避免在代码中到处散落导入、密钥和常量,将它们全部放在 notebook 的第一个单元格中,如下所示:
import os
import pandas as pd
import requests
import datetime
import concurrent.futures
from typing import Optional
from pydantic import BaseModel, Field
from openai import OpenAI
# Secrets to connect to third-party services (replace them with the actual values)
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
# Define the required constants
SOURCE_CSV_PATH = "snap_XXXXXXXXXXXXXXXXXXX.csv"
ENRICHED_CSV_PATH = "crunchbase_analyzed_companies.csv"
# Initialize the OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY)请确保:
- 将
<YOUR_BRIGHT_DATA_API_KEY>替换为你的 Bright Data API key。 - 将
<YOUR_OPENAI_API_KEY>替换为你的 OpenAI API key。 - 根据需要更新源文件(
SOURCE_CSV_PATH)和丰富后文件路径(ENRICHED_CSV_PATH)的名称。
请记住,ENRICHED_CSV_PATH 定义了保存丰富后数据的输出文件路径。
太好了!通过此设置,你现在拥有开始所需的全部构建块。
第 #4 步:加载数据集
在一个新单元格中,添加将源数据集加载到 DataFrame 并显示其主要信息的逻辑:
# Load the CSV file containing the filtered Crunchbase dataset
df = pd.read_csv(SOURCE_CSV_PATH, keep_default_na=False)
# Print the basic info about the dataset
df.info()
# Print the first rows
df.head()注意:keep_default_na=False 选项是必需的。否则,包含 "NA" 的 region 列会被 pandas 默认解释为 NaN。
运行该单元格,你应该会看到类似这样的输出: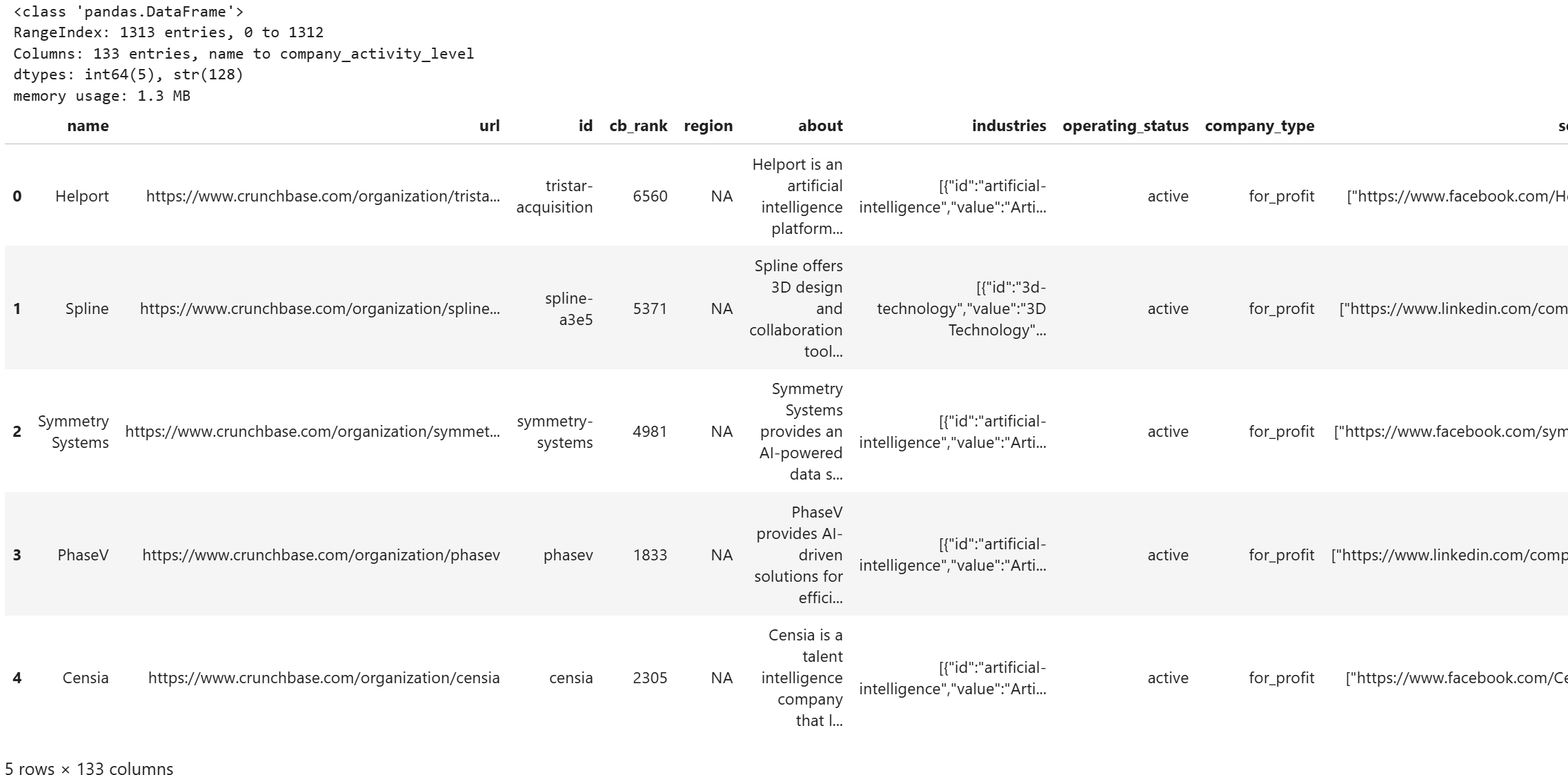
注意 DataFrame 存储了全部 1,313 条条目,每条都有来自筛选后的 Crunchbase 数据集的 133 列。非常好!
第 #5 步:定义网站抓取函数
现在,定义一个函数来调用 网络解锁器 API 并抓取公司网站:
def fetch_website(url, zone = "web_unlocker"):
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": zone,
"url": url,
"format": "raw", # Get the response directly in the body
"data_format": "markdown" # Get the webpage in Markdown format (ideal for LLM ingestion)
}
api_url = "https://api.brightdata.com/request"
try:
response = requests.post(api_url, json=data, headers=headers)
# Raise an error if the response is 4xx/5xx
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching '{url}' via Web Unlocker API: {e}")
return None如果你不熟悉 网络解锁器 API 的工作方式,请参考官方文档。
fetch_website() 函数会在提供的 URL 上调用你的 Bright Data 网络解锁器 API 区域(将 "web_unlocker" 替换为你自己的区域名称)。由于 data_format: "markdown" 参数,响应将是网站的 AI 就绪 Markdown 版本。该数据格式非常适合 LLM 摄取,这正是你很快要做的事情。
该函数将应用于每个公司条目,以用其主页的 Markdown 版本对其进行丰富。看看下一步如何做到这一点!
第 #6 步:并行抓取所有公司主页
网络解锁器 API 与 Bright Data 的任何其他基于 API 的产品一样,由企业级基础设施支撑,拥有超过 4 亿住宅 IP。得益于此,你可以无限并发调用 API,而无需担心速率限制或扩展问题。
由于我们的数据集包含数千家公司,同时抓取多个网站是合理的。以下单元格正是这样做的:
batch_size = 5
total = len(df)
defprocess_row_for_scraping(idx):
url = df.at[idx, "website"]
# Skip the row if the "website" field is missing
if pd.isna(url):
return None
# Retrieve the website homepage in Markdown
markdown = fetch_website(url)
timestamp = datetime.datetime.now(datetime.UTC)
return idx, markdown, timestamp
for start in range(0, total, batch_size):
# Get the current batch
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing Crunchbase records {start} to {end-1}")
# Fetching website homepages in parallel for the batch
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row_for_scraping, batch_indices))
# Update the DataFrame with the results
for r in results:
# Skip
if r is None:
continue
idx, markdown, timestamp = r
df.at[idx, "website_markdown"] = markdown
df.at[idx, "website_markdown_fetching_timestamp"] = timestamp
# Save the updated CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")该片段处理一个 Crunchbase 数据集,以用其网站的 Markdown 版本丰富每个公司条目,为由 AI 驱动的分析做好准备。它以每次 5 行的批次运行,并行抓取网站以加速 I/O 密集型操作。
process_row() 函数处理每家公司:它使用 网络解锁器 API 抓取主页并记录时间戳。跳过缺失的 URL 可确保效率并避免不必要的 API 调用。此外,跟踪时间戳很重要,因为公司的官网可能经常变化。因此,知道上次抓取时间是有益的。
批次通过 线程池 处理,允许多个请求并发运行。每个批次之后,DataFrame 会被更新并保存到磁盘。增量保存至关重要,因为它可以防止进程中断时的数据丢失,并使你能够在无需从头开始的情况下继续。
专业提示:首次运行时,将行数限制为 5 或 10,以在处理完整数据集之前确认工作流按预期工作。
运行后,你将获得如下图所示的输出消息:
在 notebook 目录中将出现一个 crunchbase_analyzed_companies.csv 文件。它将包含所有原始 Crunchbase 数据,以及两个新列:
website_markdown:每家公司主页的 AI 就绪 Markdown 版本。website_markdown_fetching_timestamp:抓取每个页面的确切时间。
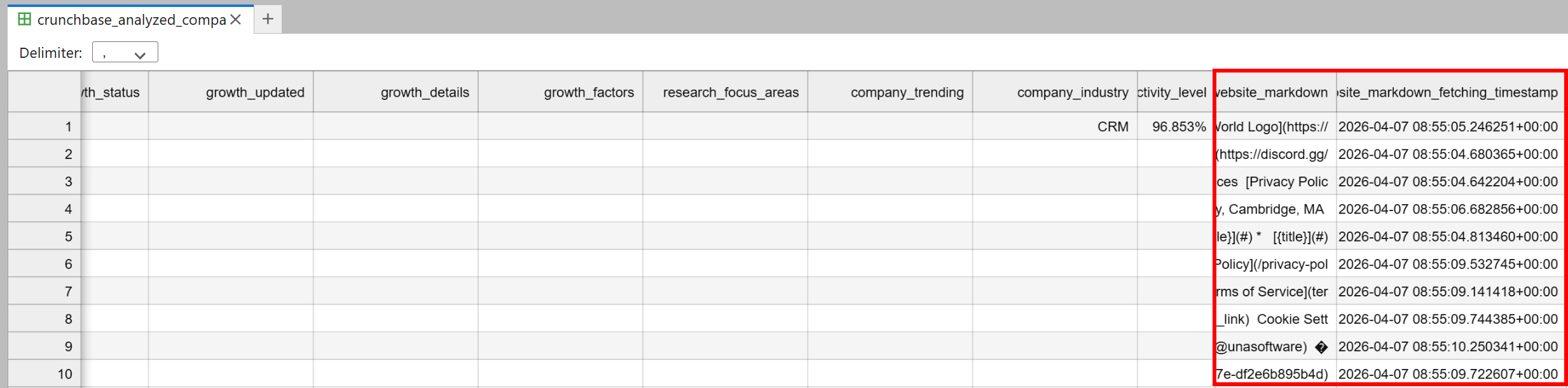
太棒了!该数据集现在已准备好进行由 AI 驱动的分析和客户挖掘。
第 #7 步:指定用于 AI 客户挖掘的函数
下一步是添加一个函数,指示 AI 执行客户挖掘。其思路是描述你的公司做什么,并让 AI 评估每个 Crunchbase 公司条目以生成:
- 一个评分,指示该公司作为潜在客户可能有多强。
- 一条简短评论,解释评分背后的原因(很有用,因为仅凭数字可能无法呈现全貌)。
- 一段基于网站内容的公司核心业务简述(有助于理解它是否匹配)。
注意:以下提示将公司网站作为唯一输入,但你可以传递整个记录以进行更高级、更细致的分析。
使用此单元格实现该过程:
# Define the structured output schema
class AIProspectingResult(BaseModel):
ai_client_prospecting_score: float
ai_client_prospecting_comment: str
ai_core_business: str
def analyze_website(markdown):
# Ask the AI to perform the client prospecting task
system_prompt = (
"You are a business intelligence analyst specialized in identifying potential clients "
"for a cybersecurity firm. We are a specialized cybersecurity firm providing adversarial testing "
"for AI-powered ecosystems. Our mission is to proactively identify vulnerabilities by attempting to 'break' "
"AI models through sophisticated attack simulations. Following our assessment, we deliver a comprehensive "
"Vulnerability & Patch Report, detailing specific weaknesses discovered and providing actionable technical "
"strategies to remediate these risks and fortify the system’s integrity.\n\n"
"Analyze the provided website content and produce a structured JSON with:\n"
"- `ai_client_prospecting_score`: 0-10 float indicating how good a potential client this company could be.\n"
"- `ai_client_prospecting_comment`: short comment (<=30 words) explaining the score.\n"
"- `ai_core_business`: short description (<= 50 words) of what the company does based on the website.\n"
)
user_prompt = f"WEBSITE CONTENT:\n{markdown}"
try:
response = openai_client.responses.parse(
model="gpt-5.4-mini",
input=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
text_format=AIProspectingResult,
)
# Return the parsed result
return response.output_parsed
except Exception as e:
print("Error analyzing website with AI:", e)
return None为确保所选 OpenAI 模型(此处为 GPT-5.4 Mini)以结构化输出进行响应,请调用 responses.parse() 方法。它接受一个 Pydantic 数据模型,并确保生成的响应遵循该格式。有关更多信息,请在我们的使用 ChatGPT 进行网页抓取指南中查看其实际效果。
太好了!下一步是为每条公司记录并行调用该函数。
第 #8 步:并行挖掘所有公司
就像之前一样,添加一个单元格,让 AI 并行处理多个条目:
batch_size = 5
total = len(df)
def process_row(idx):
markdown = df.at[idx, "website_markdown"]
# Skip rows with missing markdown
if pd.isna(markdown):
return None
# Call the AI prospecting function
result = analyze_website(markdown)
if result is None:
return None
return idx, result.ai_client_prospecting_score, result.ai_client_prospecting_comment, result.ai_core_business
for start in range(0, total, batch_size):
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing AI prospecting for records {start} to {end-1}")
# Run AI analysis in parallel
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row, batch_indices))
# Update the DataFrame with the results (if the array is not full of None values)
for r in results:
if r is None:
continue # Skip
idx, score, comment, core_business = r
df.at[idx, "ai_client_prospecting_score"] = score
df.at[idx, "ai_client_prospecting_comment"] = comment
df.at[idx, "ai_core_business"] = core_business
# Save CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")运行它,它将打印如下消息:
很好!Crunchbase 数据集现在已通过 Bright Data 提取与由 AI 驱动的分析进行了丰富,以用于客户挖掘。
是时候探索结果了!
第 #9 步:分析丰富后的数据
在最后一个单元格中,添加用于展示丰富后数据的逻辑:
relevant_columns = [
"name",
"cb_rank",
"region",
"ai_client_prospecting_score",
"ai_client_prospecting_comment",
"ai_core_business"
]
pd.set_option("display.max_columns", None) # Show all columns
pd.set_option("display.max_colwidth", None) # Do not truncate text
# Print only the relevant fields
df[relevant_columns].head(10)结果数据集将包含:
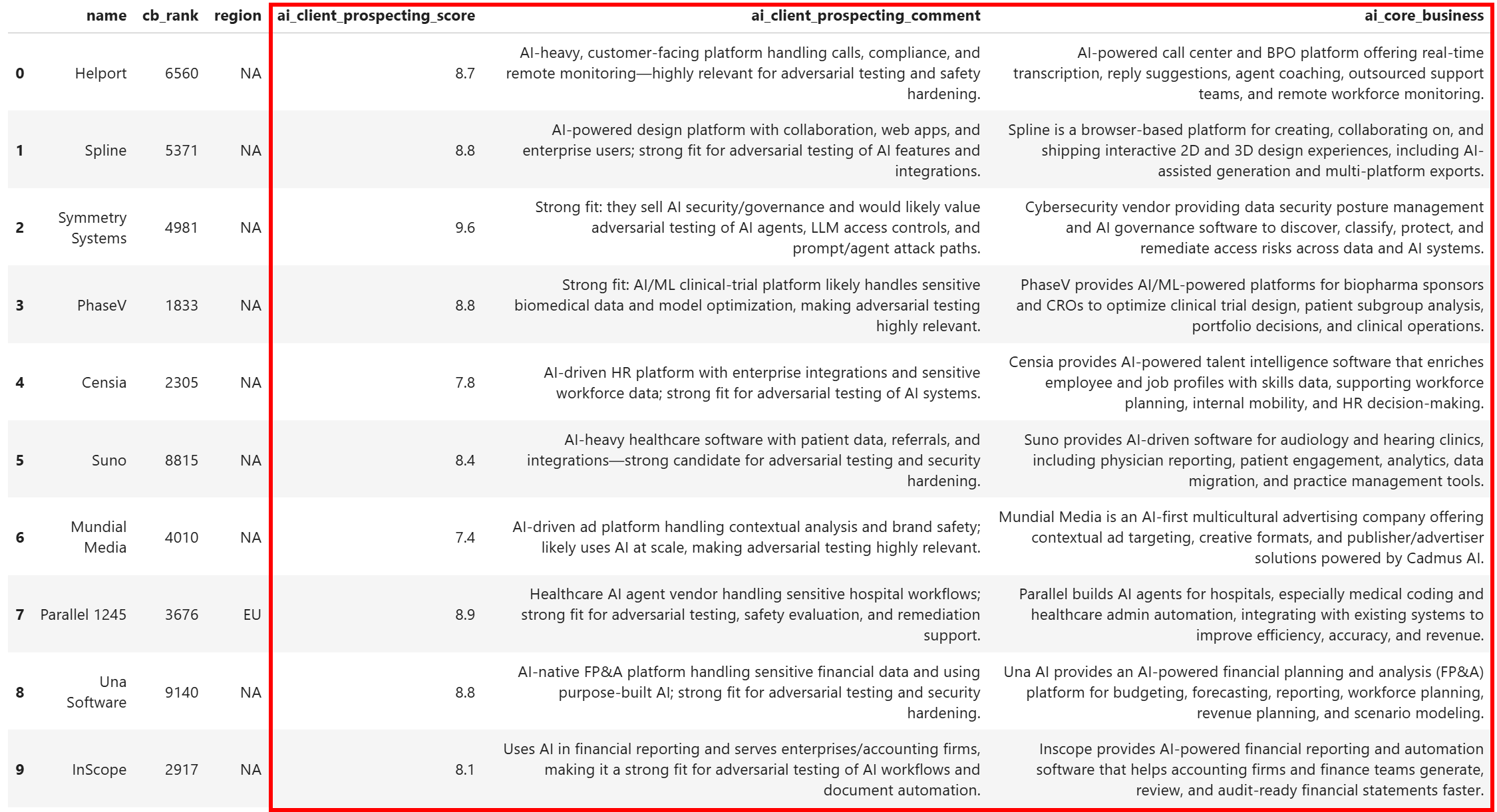
注意每家公司都被丰富了一个清晰的挖掘评分、一条解释评分的简短评论,以及对公司业务的简明描述。若没有以下内容,这是不可能实现的:
- Bright Data 的 Filter API:用于检索一个有针对性、经过筛选的 Crunchbase 数据集。
- 网络解锁器 API:用于可靠地抓取任何公司网站,而不会被拦截。
Et voilà!你现在可以 应用进一步的数据分析 和处理,以仅选择最值得联系的候选对象。
结论
在本文中,你学习了如何利用 Bright Data 的数据集,以及 Bright Data API 和 AI,构建一个完整的、可用于生产的、自动化的客户挖掘工作流。该工作流:
- 从一个包含超过 430 万条记录的 Crunchbase 数据集开始。
- 使用 Bright Data 的 Filter API 以编程方式筛选它,仅包含符合你特定标准的公司。
- 使用 网络解锁器 API 检索每家公司的官网内容。
- 将该内容传递给 AI 进行编程式评分,评估每家公司作为潜在客户有多合适。
结果是一个丰富后的数据集,其中每家公司都有一个评分和一条简短评论,指示是否值得就你的产品或服务联系他们。得益于来自 Bright Data marketplace 的高质量数据、高级筛选能力以及 AI 丰富,寻找新客户从未如此简单!
立即创建一个免费的 Bright Data 账户,并开始试用我们的 AI 就绪网页工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。