在这篇文章中,你将了解:
- 什么是 Crunchbase 数据、它为何如此重要,以及采集它面临的主要挑战。
- 为什么依靠 Crunchbase 数据供应商可以让你大幅简化整个获取流程。
- 评估此类供应商时需要重点考量的因素。
- 7 大最佳 Crunchbase 数据供应商的完整对比。
下面开始正文!
TL;DR:顶级 Crunchbase 数据供应商快速对比
如果你想先快速了解全局,可以先看下面这张汇总表,对比主要的 Crunchbase 数据供应商:
| 供应商 | 数据广度 | 基础设施 | 正常运行时间 | 历史数据集 | 数据爬取方式 | 合规性 | 按需付费 | 定价 |
|---|---|---|---|---|---|---|---|---|
| Bright Data | 400 万+ 公司档案、融资轮次、投资人、并购、公司特征数据 | 企业级、全托管、高度可扩展 | 99.99% | ✔ | ✔ | GDPR、CCPA、ISO 27001、SOC 2 Type II、CSA STAR | ✔ | 数据集:$2.50/1k 条记录;爬取:$1.50/1k 条记录 |
| Piloterr | 350 万+ 记录:公司、融资轮次、高管、投资人 | 云端 | —(未披露) | ✔ | ✔ | GDPR、CCPA | ❌ | 起价 $3,000,爬虫 API 套餐从 $49/月 起 |
| Bardeen | 组织、投资人、融资轮次、员工、个人档案 | 云端 | —(未披露) | ❌(但可访问之前爬取的数据) | ✔ | GDPR、SOC 2 Type II、CASA Tier 2 & 3 | ❌ | 起价 $50/月 |
| WebAutomation | 300 万+ 公司、融资轮次、团队、关键高管 | 云端 | —(未披露) | ✔ | ✔ | —(未披露) | ❌ | $1/25 行(约 $40/1k 行) |
| HasData | 公司档案、融资轮次、投资人数据 | 云端 | 99.9% | ❌ | ✔ | 保证在欧盟和美国的合法性 | ❌ | 起价 $49/月 |
| Apify | 公司、人物、投资人、融资轮次、收购 | 云端 | —(未披露) | ❌ | ✔ | GDPR、SOC2 | 视具体 Actor 而定 | 视具体 Actor 而定 |
| Rebrowser | 数百万公司、融资轮次、投资人、历史模式 | 可扩展 | —(未披露) | ✔ | ✔ | —(未披露) | ❌ | 定制报价 |
关于 Crunchbase 数据,你需要知道的一切
接下来我们来看看 Crunchbase 数据为何重要、包含哪些内容,以及获取它有多难。在对比 Crunchbase 数据供应商之前,这些背景非常关键。
什么是 Crunchbase 数据?
Crunchbase 是一个专注于私营和上市公司数据与情报的平台。它提供关于融资轮次、投资人、关键人物、并购、市场趋势等方面的洞察。
该平台受到全球 8000 万+ 用户的信任,并拥有超 60,000 名付费客户。其中一半以上是《财富》500 强企业,此外还有数以千计的中小企业。
其 AI 驱动的解决方案可分析数百万家公司,预测趋势与重大业务里程碑,每月输出近 100,000 条预测。
这些数字说明,Crunchbase 被广泛视为全球最值得信赖的私募市场数据来源之一。投资人、分析师和交易撮合者依赖它,通过分析公司动态及前瞻性信号,发现、评估并把握高潜机会。
更具体地说,访问 Crunchbase 数据可以支持如下广泛的场景:
- 识别投资机会,例如满足特定投资或收购标准的初创公司。
- 实时跟踪融资轮次、投资人和交易活动。
- 基于公司增长信号进行B2B 线索生成。
- 监测行业内的竞争对手和新兴玩家。
- 分析市场趋势和行业层面的投资模式。
- 发现关键决策者和公司领导层变动。
- 用结构化的公司与融资数据支撑尽调流程。
Crunchbase 数据的类型
Crunchbase 暴露的数据类型主要包括:
- 组织(Organizations):从初创到大型企业的公司画像数据,包括行业、所在地、规模、运营状态、所有权结构等。可进一步了解最佳公司特征数据供应商。
- 人物(People):创始人、高管和董事会成员的个人档案,用于追踪职业变动和识别关键决策者。
- 财务与融资数据:融资轮次详情、阶段、累计融资额、估值、投资人、并购活动(M&A)、IPO 以及预估营收区间等。
- 投资人(Investors):风投机构、天使投资人及基金的数据,包括投资组合、投资历史、出手频率以及偏好的阶段与行业。
- 并购(Acquisitions):并购交易信息,包括买方、卖方、时间与披露的交易金额。
- 公司关系与网络:公司、投资人、加速器、孵化器以及母子公司之间的关联关系。
- IPO 与股价:包括 IPO 日期、股票代码、初始估值以及历史股价表现等公开市场数据。
- 事件(Events):会议、活动和公司里程碑记录,包括参与情况、公告、产品发布、领导层变更和退出事件。
- 信号与新闻(Signals and news):对领导层变动、裁员、融资活动或增长信号等事件进行告警,用于发现高意向机会。这是一类优质的另类数据。
为什么从 Crunchbase 获取数据如此困难?
Crunchbase 的数据来源于庞大的风投网络,其中包括4000+ 风投项目成员,他们每月提交投资组合更新。具体来说,每月有 60 多万名高管、创业者和投资人更新 100,000+ 个人档案。
随后,平台通过 400+ AI 与机器学习算法、政府文件以及 1000+ 头部新闻媒体的报道,对数据进行每日校验。
部分 Crunchbase 数据可通过官方 API 获取,但价格昂贵且限流为每分钟 200 次调用。而且,这些 API 仅能访问下面 3 个主要数据包:
- Fundamentals data:核心历史和公司特征数据,涵盖里程碑、财务和市场趋势,用于验证与分析。
- Insights data:AI 驱动的分析,揭示市场趋势、新兴增长模式和可执行机会。
- Predictions data:利用 AI 预测融资轮次、并购、退出、裁员和增长情况,帮助预判风险并优先处理高回报机会。
这些 API 的主要限制在于:你并不能完全掌控。Crunchbase 可以随时限制访问、修改端点或更改返回内容。
当你在比较 API 与网页爬取(即自动从公开网页提取数据的技术)时,爬取通常意味着更高的可控性、更强的可扩展性、更低成本以及更长期稳定的可用性。
数据采集、验证与校验是 Crunchbase 业务的核心。因此,该公司对其数据保护极为严格,大部分网页都加上了反爬机制,包括 WAF(Web 应用防火墙):
这也是为什么,从零构建一套高效的自建 Crunchbase 爬虫来抓取这些数据极具挑战性。
为什么需要 Crunchbase 数据供应商?
Crunchbase 数据的价值不言而喻,但想要稳定、规模化地获取却相当复杂。最有效的方式,就是与专业的 Crunchbase 数据供应商合作。
Crunchbase 数据供应商是一类服务,它们负责采集、整理并交付部分或全部类型的 Crunchbase 数据。这些供应商帮助你解决与数据获取相关的技术难题,确保你能够以所需格式稳定地获取信息。
更具体地说,它们通常通过两种主要方式提供 Crunchbase 数据:
- Crunchbase 数据集:预先采集、结构化的历史与定期更新数据集。非常适合大规模研究及训练机器学习和 AI 模型。
- Crunchbase 爬取方案:直接从 Crunchbase 页面抓取最新数据的工具。这类方案更适合线索挖掘、市场监测以及 AI Agent 的实时洞察场景。
为了维持全面的金融数据覆盖,多数机构都会组合使用这两种方式:
- 用数据集获取历史背景、分析和报表。
- 用爬取方案获取实时情报,并支撑自动化工作流和数据流水线。
选择最佳 Crunchbase 数据供应商时要考虑的因素
网上能找到一长串 Crunchbase 数据供应商名单,但它们的信誉与能力差异巨大。要识别最佳选项,应当围绕同一套维度对比各家供应商,例如:
- 数据广度:是否提供公司特征、融资、并购、人物、投资人信息等多类 Crunchbase 数据。
- 基础设施:系统的可扩展性、正常运行时间、成功率和整体可靠性。
- 技术要求:访问并用好这些数据需要哪些技能、软件和技术组件。
- 数据新鲜度:是通过数据集提供静态数据,还是通过爬取方案提供实时更新的数据。
- 合规性:是否遵从 GDPR、CCPA 等隐私与数据安全法规。
- 定价:费用结构、订阅计划和计费模式,以及是否提供免费试用或评估方案。
7 大顶级 Crunchbase 数据供应商
下面是我们基于以上标准精挑细选并排序的 7 大 Crunchbase 数据供应商。
1. Bright Data
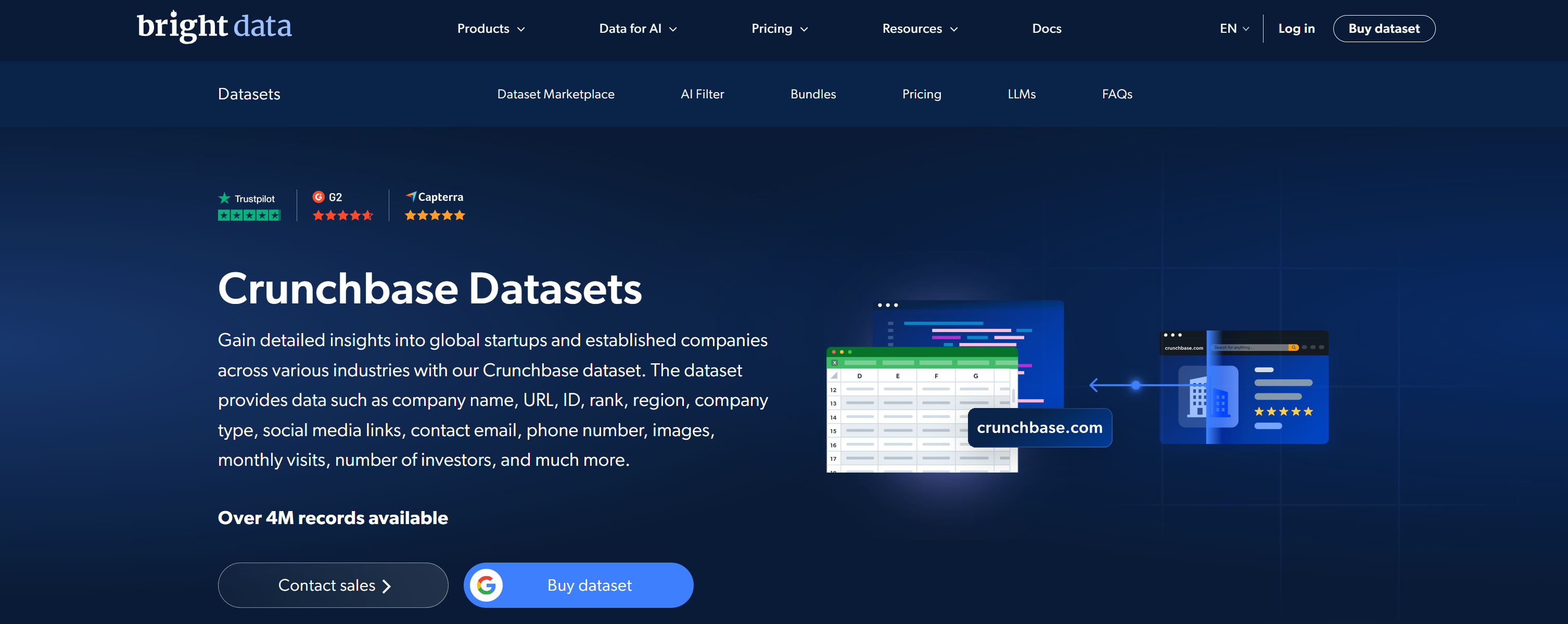
Bright Data 起初是一家代理(Proxy)供应商,如今已经发展为领先的网页爬取和数据解决方案公司。在 Crunchbase 数据供应商中,Bright Data 以企业级、高度可扩展的基础设施脱颖而出,可支撑 AI 集成,并为超 20,000 家客户(包括众多《财富》500 强)提供服务。
Bright Data 提供丰富的Crunchbase 数据集,支持 JSON、CSV 与 Parquet 格式,按记录计费,覆盖 400 万+ 多行业记录。数据干净、已验证、持续更新,并已为大模型(LLM)直接可用做好准备。
这些数据集包含公司名称、URL、ID、排名、区域、公司类型、社交媒体链接、联系方式、月访问量、投资人数量等字段。你还可以通过 Databricks直接访问并查询这些数据。
借助 Bright Data 的Crunchbase Scraper,你也可以按需抓取最新数据,包括公司 ID、规模、类型、员工人数、所在地、成立时间、关注者、投资人、社交媒体账号等。
该爬虫既可通过 API 接入脚本、AI Agent 或数据流水线,也可通过零代码界面供非技术用户使用。
Bright Data 的 Crunchbase 数据解决方案承诺 99.99% 正常运行时间和 99.99% 成功率,背靠 1.5 亿+ 全球代理 IP 和先进的反反爬工具,用于应对验证码和各种反爬机制。
综合来看,这些特性让 Bright Data 成为当下最值得考虑的 Crunchbase 数据供应商之一。
➡️ 最适合:企业级分析、模型数据增强与 AI Agent 集成。
数据广度:
- 可访问 Crunchbase 公司数据,包括公司 ID、名称、规模、类型、员工人数、所在地、成立时间、社交媒体、关注者、投资人以及其它关键公司特征数据。
- 包含历史融资轮次、并购活动及其它业务指标。
基础设施:
- 灵活的 Crunchbase 数据集交付格式(JSON、NDJSON、CSV 等),可选 Gzip 压缩。
- 支持与 AI 应用和 CRM 丰富化流程集成。
- 支持批量爬取请求(每次最高 5000 条 URL)。
- 内置验证码自动识别、IP 自动轮换、User-Agent 轮换以及自定义 Header,降低被封风险。
- 99.99% 正常运行时间。
- 99.99% 成功率。
- 依托1.5 亿+ 覆盖 195 个国家/地区的住宅代理 IP,为企业级业务提供高度稳定性和可扩展性。
- 集成高质量数据验证机制,确保数据结构化、准确且可靠。
- 7×24 全球技术支持和专门的数据团队。
技术要求:
- 数据可直接交付至指定存储(Amazon S3、Google Cloud、Azure、Snowflake、SFTP)。
- 提供零代码爬虫,可通过 Web 平台即插即用。
- 基于 API 的爬虫支持自动化、定时任务和对现有数据流水线的集成。
- 基础用法几乎无需技术背景,高级 API 使用仅需常规 API 集成经验。
数据新鲜度:
- 按需交付,并支持按月、季度或半年进行全自动刷新与调度。
- 通过 Crunchbase Scraper API 实时抓取数据。
合规性:
- 完全符合 GDPR、CCPA 等隐私法规。
- 仅从公开可访问源以合乎道德的方式采集数据。
- 通过 ISO 27001、SOC 2 Type II、CSA STAR Level 1 等多项安全认证。
定价:
- Crunchbase 数据集:每 1000 条记录起价 $2.50。
- 实时爬取数据:每 1000 条记录起价 $1.50。
2. Piloterr
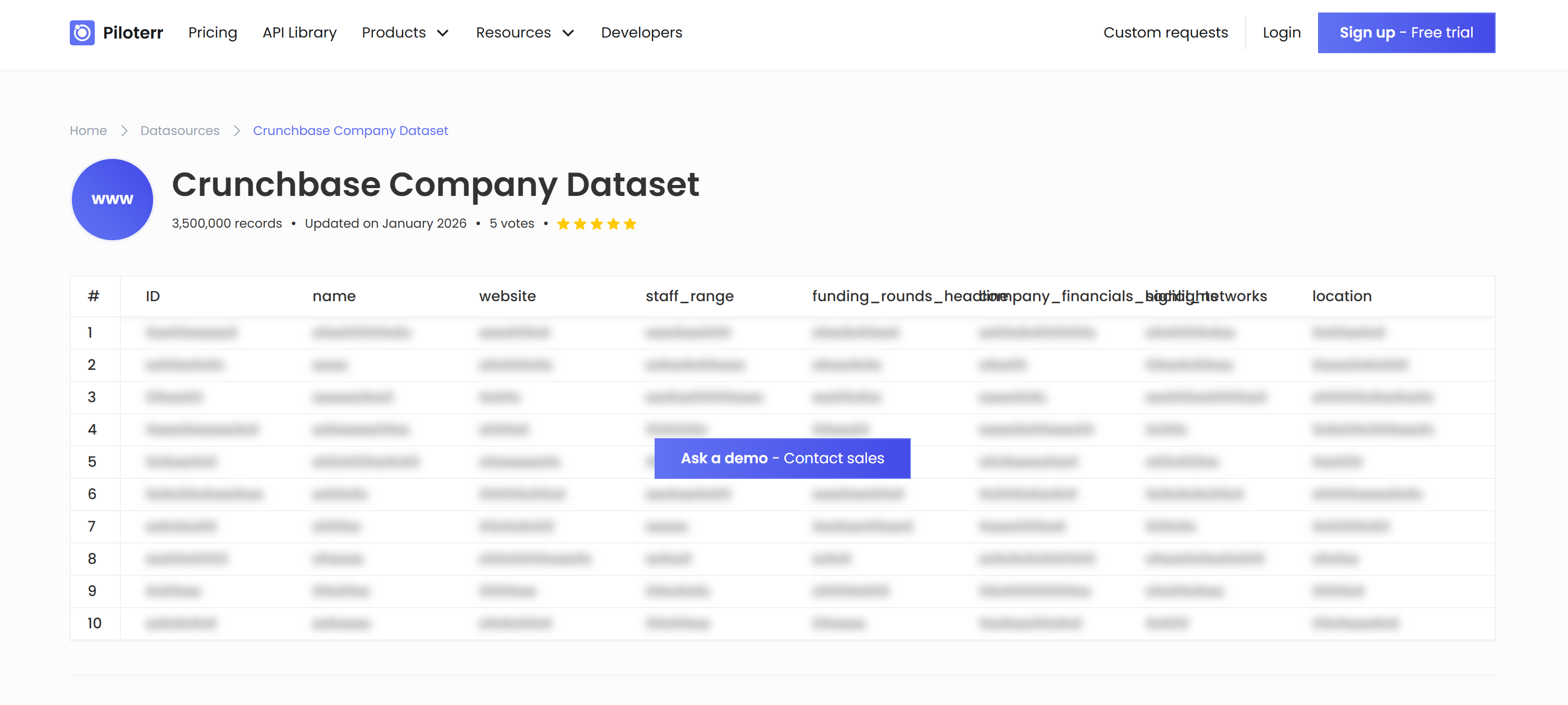
Piloterr 是一款网页爬取与数据抽取平台,提供 API 和预构建爬虫,用于大规模采集结构化数据。在 Crunchbase 场景下,它既提供 API,也提供可直接分析的数据集,覆盖公司、融资轮次、高管和投资人等数据,既支持历史分析也支持持续刷新式数据流水线。
➡️ 最适合:持续、定期的金融数据流水线。
数据广度:
- 超过 350 万条记录。
- 涵盖公司档案、融资轮次、团队详情、关键高管和投资人信息。
基础设施:
- 可即用的数据集,支持 CSV、JSON 等格式。
- 统一数据模式的云端 API,可获取 Crunchbase 融资轮次、人物信息、公司信息、事件与搜索结果数据。
技术要求:
- 访问数据集几乎不需要技术门槛。
- 集成 Piloterr 的云爬虫 API 需要一定技术基础。
数据新鲜度:
- 支持一次性与周期性交付(每日、每周、每月、每季度或自定义)。
- 用户可通过云端爬虫 API 构建自有 Crunchbase 数据流水线。
合规性:
- 符合 GDPR 与 CCPA。
定价:
- Crunchbase 数据集起价 $3,000。
- 免费试用包含 50 个爬虫 API 点数。
- 爬虫 API 计划:
- 面向普通用户:
- Premium:$49/月,18k 点数。
- Premium+:$99/月,40k 点数。
- Startup:$249/月,110k 点数。
- 面向企业:
- Startup+:$499/月,230k 点数。
- Enterprise:$799/月,390k 点数。
- Enterprise+:$999/月,530k 点数。
- Custom:+$2,000/月,自定义点数。
- 面向普通用户:
3. Bardeen
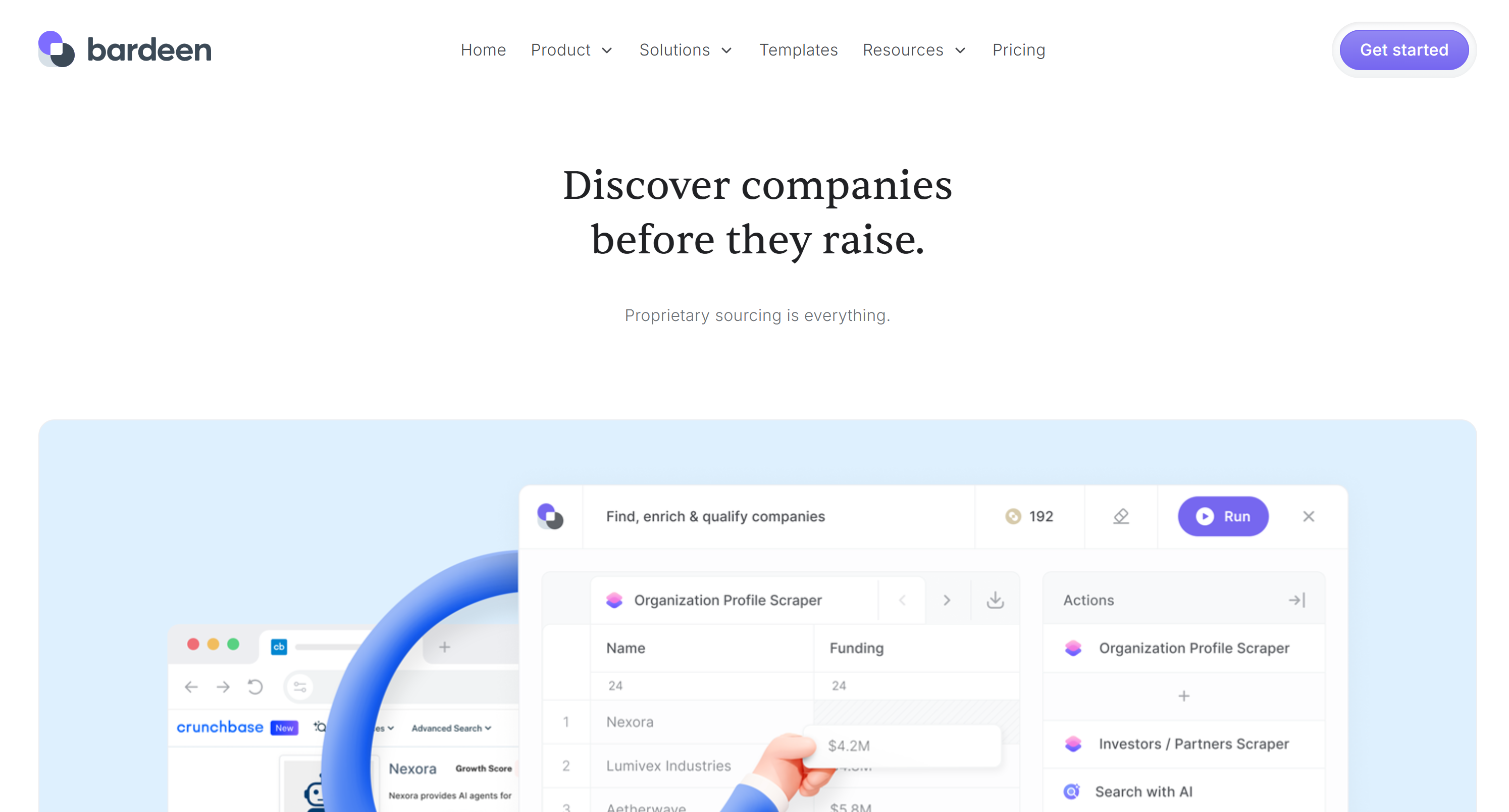
Bardeen 是一款 AI 增强的零代码自动化平台,帮助销售、市场和运营团队自动化浏览器端工作流。它提供现成的 Crunchbase 爬取模板,可按需抽取组织、投资人、融资轮次和人物数据,并在平台内直接进行丰富与分析。
➡️ 最适合:自动化与数据分析。
数据广度:
- Crunchbase 数据包含组织、投资人、融资轮次、员工档案和个人档案等。
基础设施:
- 可扩展平台,支持自动化采集 Crunchbase 及其它来源的数据。
- 内置 AI 洞察、数据丰富功能以及外部集成。
技术要求:
- 预构建爬取模板,技术门槛较低。
- 部分集成流程需要基础技术知识(如 API 使用、对接 Google Sheets、Airtable 或 Notion 等)。
数据新鲜度:
- 通过 Bardeen 的爬取模板即时从 Crunchbase 抽取数据。
- 可对历史爬取数据进行打分、丰富和探索,但不提供直接面向公共用户的通用历史数据集。
合规性:
- 符合 GDPR。
- 通过 SOC 2 Type II 与 CASA 2、3 级认证。
定价:
- 提供 100 点免费额度。
- Premium Plan:$50/月,可访问 Crunchbase 高级模板等功能。
- Enterprise Plan:定制报价。
4. WebAutomation

WebAutomation 是一个云端零代码网页爬虫服务,允许用户通过预构建爬虫和可视化流程抽取网页数据。其 Crunchbase 方案包括云端爬虫与覆盖 300 万+ 公司的数据集,因此也被视为值得信赖的公司数据供应商。
➡️ 最适合:初创公司挖掘与筛选。
数据广度:
- 全球 300 万+ 公司。
- 涵盖公司档案、融资轮次、团队详情和关键高管,覆盖各行业与地区的成熟公司和新创企业。
基础设施:
- 专用的零代码 Crunchbase 公司爬虫,在云端运行。
技术要求:
- 使用零代码爬虫,只需极少技术背景。
- 数据可导出为 CSV、Excel、JSON 等常见格式,便于分析或集成。
数据新鲜度:
- 提供历史公司数据集。
- 通过 Crunchbase 爬虫获取最新数据。
合规性:
- 未披露。
定价:
- 提供样例数据集 + 爬虫免费试用。
- 完整定价需联系销售。
- 爬虫按条计费:$1/25 公司记录(约 $40/1k 条)。
5. HasData
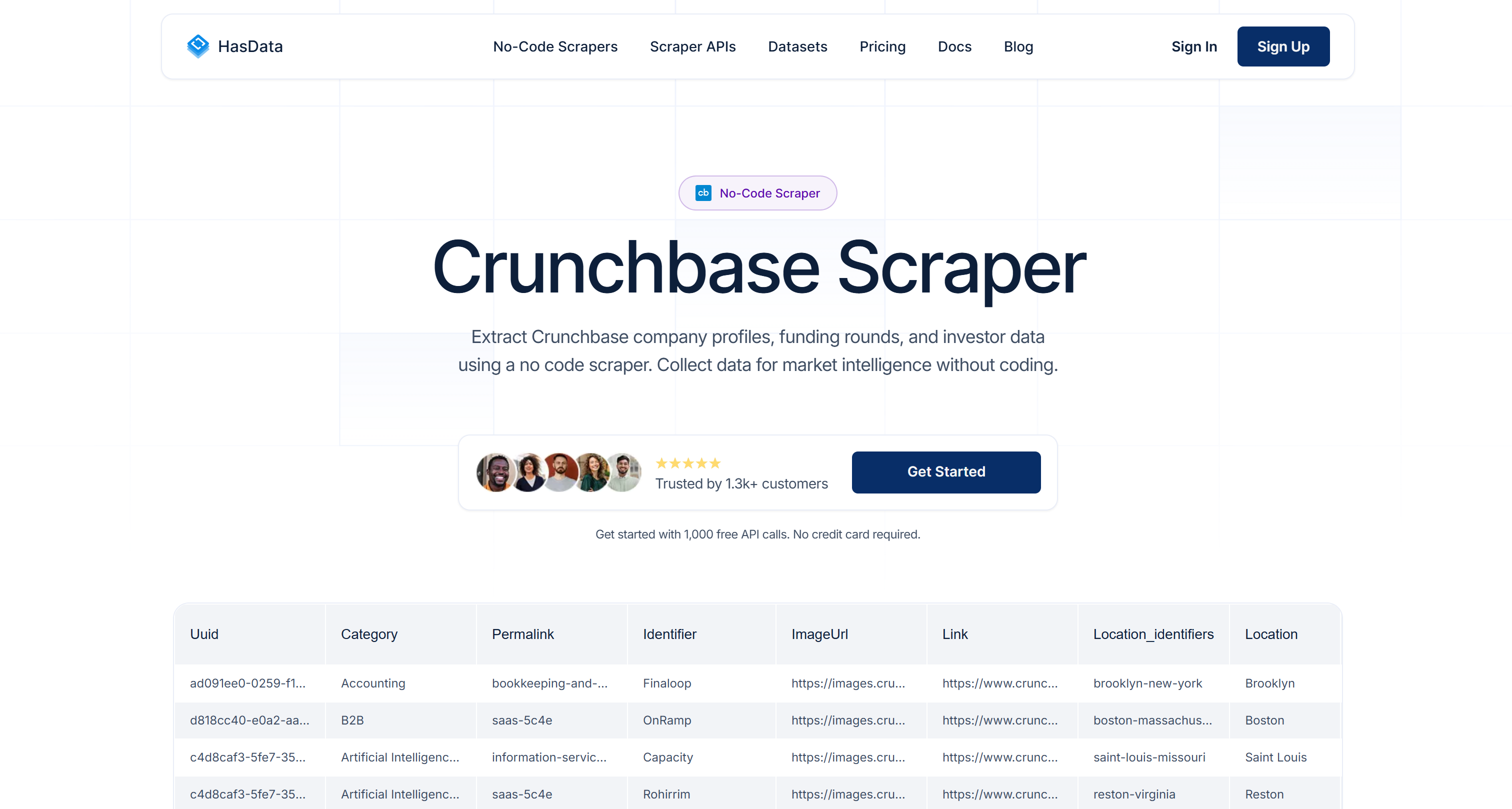
HasData 是一款云端网页爬取平台,提供 API 与零代码工具,用于大规模抽取公开网页数据。作为 Crunchbase 数据供应商,它支持采集公司档案、融资轮次和投资人数据,并通过托管式基础设施、内建代理池与反反爬机制以及多档价格方案来交付。
➡️ 最适合:快速获取公司数据。
数据广度:
- 公司档案、融资轮次与投资人数据。
基础设施:
- 云计算驱动,无需本地部署。
- 支持数百万级请求。
- 代理池管理与反反爬(Cloudflare、DataDome、Akamai 等)。
- 99.9% 正常运行时间。
技术要求:
- 零代码爬取界面,对技术要求较低。
- 通过官方 Python 和 NodeJS SDK 简化 API 接入。
数据新鲜度:
- 实时数据采集。
合规性:
- 承诺在欧盟和美国范围内的合法性。
定价:
- 免费试用包含 1,000 个 API 点数 + 高级套餐 30 天免费试用。
- 付费方案:
- Startup:$49/月,最多 20k 条记录。
- Business:$99/月,最多 100k 条记录。
- Enterprise:$249/月,最多 300k 条记录。
6. Apify
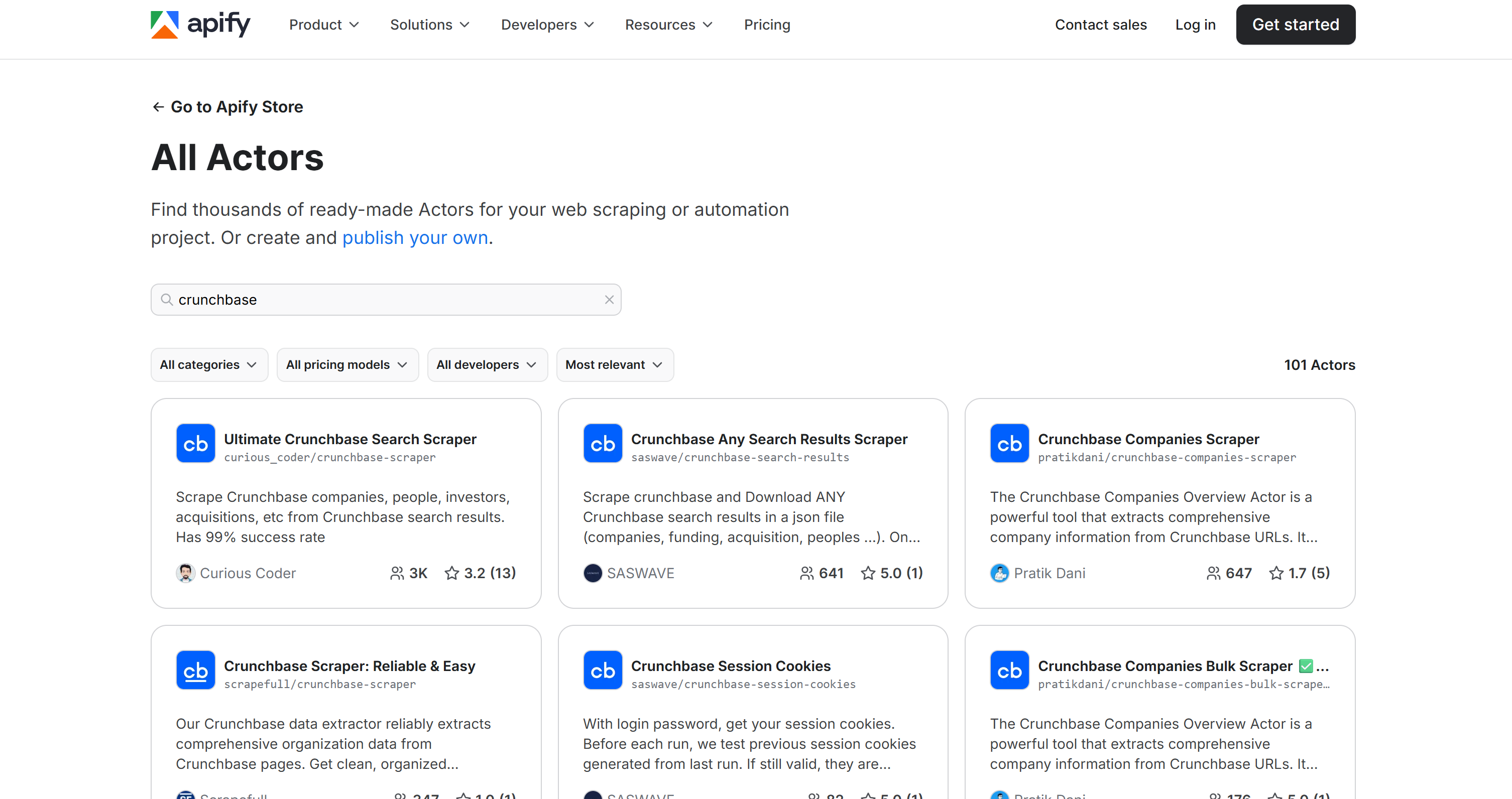
Apify 是一个云端网页爬取与自动化平台,可大规模抽取和处理网页数据。在 Apify 语境中,Actor 是执行特定任务的可运行单元,例如爬取网站或自动化特定工作流。针对 Crunchbase,Apify 提供 100+ 个 Actor,用于采集公司、人物、投资人、融资轮次和收购等不同类型的数据。
➡️ 最适合:定制数据工作流与多源数据集的丰富化。
数据广度:
- 抓取的 Crunchbase 数据覆盖公司、人物、投资人、融资轮次、收购、高管档案等。
基础设施:
- 云端平台,提供数十个可直接使用的 Crunchbase 爬虫。
- 内置反封锁与代理轮换支持。
技术要求:
- 集成 Actor 与构建自定义数据流水线需要技术背景(API 调用、数据处理等)。
- 也可以通过 Apify Web 端零代码界面以最小投入运行爬虫。
数据新鲜度:
- 从 Crunchbase 页面实时抓取数据。
合规性:
- 符合 GDPR。
- 通过 SOC2 认证。
定价:
- 提供免费套餐。
- 具体费用取决于使用的 Crunchbase 爬虫 Actor。
7. Rebrowser
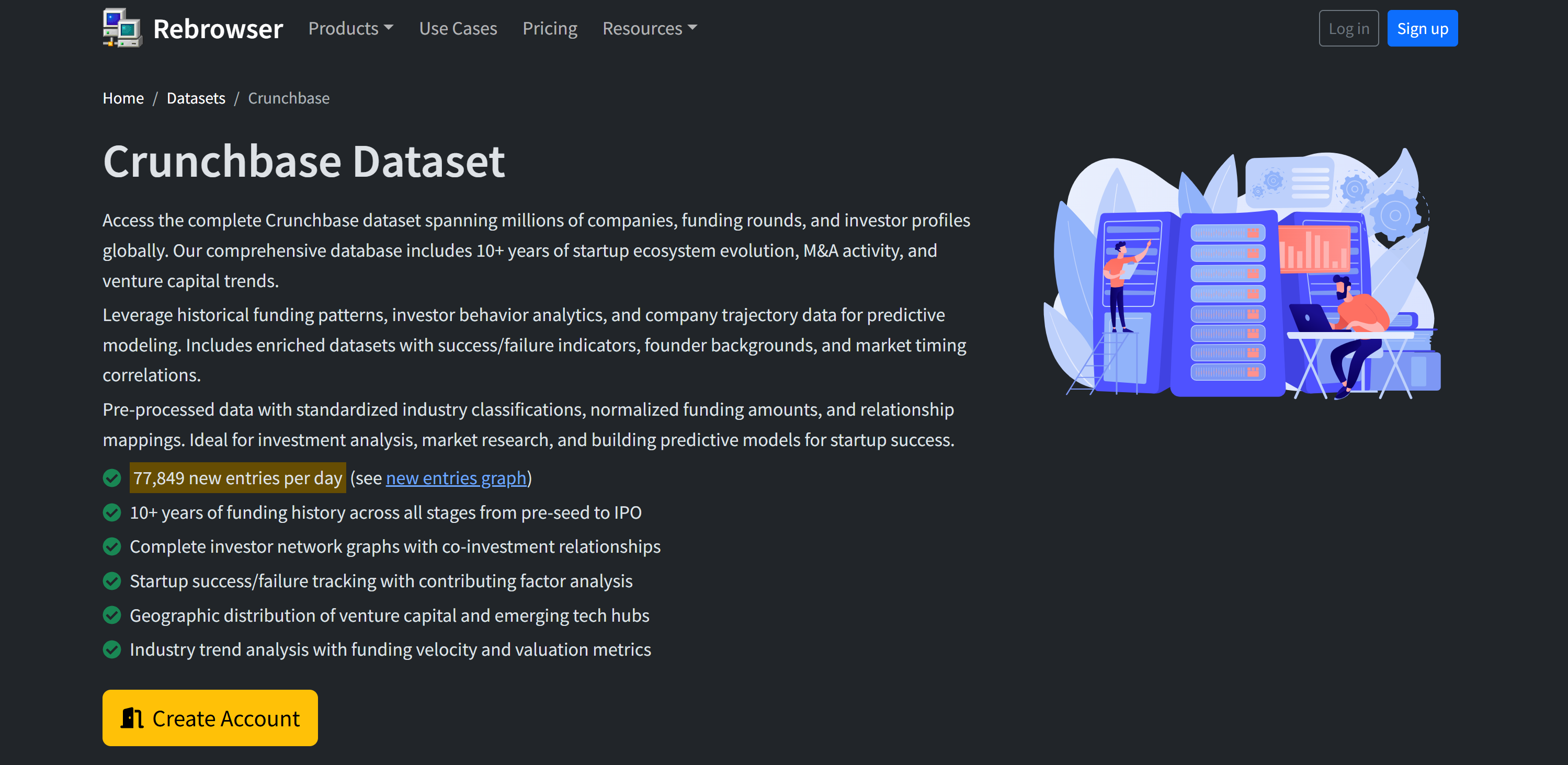
Rebrowser 是一套无头浏览器自动化框架,可模拟真实浏览器环境并规避传统检测手段。它同时也是大规模、难以访问网页数据的数据基础设施供应商。针对 Crunchbase,它提供数据集与爬取方案,覆盖数百万公司、投资人和融资事件,并具备深度历史覆盖。
➡️ 最适合:趋势分析与基于历史数据的 AI 训练。
数据广度:
- 数百万家公司、融资轮次与投资人档案,包括历史融资模式、并购活动以及初创成功/失败指标。
基础设施:
- 可扩展基础设施,内置反反爬机制。
- 数据集条目的准确率达 99.2%。
技术要求:
- 获取数据集几乎无需技术背景,数据交付时已结构化和校验完毕。
- 集成爬虫则需要技术团队进行 API 调用和数据流水线集成。
数据新鲜度:
- 历史数据集覆盖 10 年以上,每日新增约 7.5–8 万条记录。
- 通过 Crunchbase 爬虫方案获取最新数据。
合规性:未披露。
定价:
- 可在 7 天内交付定制数据集样本。
- 完整定价未公开,需要先与其技术团队沟通。
总结
本文介绍了什么是 Crunchbase 数据、它为何具有高价值,以及你在获取过程中需要克服的障碍。我们也阐述了,使用专业的 Crunchbase 数据供应商如何显著简化数据采集流程。
通过这些服务,你可以访问范围广泛的 Crunchbase 信息,包括公司档案、融资轮次、投资人详情等。这些信息既可以通过预构建数据集获取,也可以借助网页爬虫方案按需抓取最新数据。
在众多顶级 Crunchbase 数据供应商中,Bright Data 尤为突出。其基础设施高度稳健,Crunchbase 数据服务也极为完整,包括:
- 包含 400 万+ 条记录的Crunchbase 数据集。
- 用于实时数据提取的专用Crunchbase Scraper。
立即免费注册 Bright Data 账号,亲身体验我们的 Crunchbase 数据解决方案!
常见问题 FAQ
如何获取 Crunchbase 数据?
获取 Crunchbase 数据主要有两种途径:
- 使用预先采集的 Crunchbase 数据集:这些是供应商过去采集或爬取并整理好的结构化数据集,通常包含历史数据,可即拿即用,免去了实时爬取的时间成本。
- 使用 Crunchbase 爬虫:你可以自己开发爬虫,或使用现成的 Crunchbase 爬取服务/API。这种方式可以直接从 Crunchbase 公司页面及其他页面抓取最新信息。
什么是 Crunchbase 数据集?
Crunchbase 数据集是一种包含从 Crunchbase 获取的结构化数据的文件,常见交付格式包括 CSV、JSON、Parquet 或 Excel。通常包含公司档案(名称、规模、地址、行业)、融资轮次与金额、并购记录等信息。
如何构建 Crunchbase 爬虫?
一个 Crunchbase 爬虫脚本一般会遵循如下路线:
- 爬虫自动控制浏览器,访问目标 Crunchbase 页面。
- 使用浏览器自动化工具加载并渲染页面。
- 应用解析逻辑,提取所需的数据点。
- 以你希望的格式(CSV、JSON 等)返回采集到的数据。
注意:大规模爬取 Crunchbase 难度较大,因为会遇到限流、IP 封禁及其他反爬措施。使用托管式的 Crunchbase 爬虫解决方案,可以大大简化这一过程。
如何爬取 Crunchbase 的公司数据?
如果重点是公司数据,可以针对 Crunchbase 的公司详情页进行爬取,并按照上述通用爬取流程执行。为获得最佳效果,建议使用专业的 Crunchbase 爬虫 API,它会自动处理 IP 轮换、验证码以及各类网页爬取难题。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。