

阅读本文,你将学到:
- 什么是数据验证、何时使用、涉及的检查项,以及应使用哪些库来实现。
- 如何通过一个实际的 Python 示例执行数据验证。
- 什么是数据核验、其工作方式、核验检查的示例及最佳方法。
- 如何使用专用 AI 代理实现数据核验。
- 一张对比数据验证与数据核验的总结表。
让我们开始吧!
数据验证:你需要知道的一切
先从第一种方法入手,开启数据验证 vs 数据核验之旅:数据验证。
什么是数据验证,它为何重要?
数据验证是检查数据准确性、质量与完整性的过程。它通常在数据被存储、使用或处理之前执行。其终极目标是保证一致的质量与可信度。
具体而言,此技术会核对数据是否遵循既定规则与标准。它能阻止错误或不完整的信息进入系统、应用、工作流,或继续在数据管道中流转。
数据验证是保持高数据质量的基石。数据验证也在满足 GDPR 与 CCPA 等合规要求以及遵循安全最佳实践方面发挥关键作用。
通过应用数据验证,你可以及早捕获数据中的错误与问题。这有助于在问题在数据生命周期中扩散之前发现它们,从而避免高昂代价与严重后果。
数据验证检查示例
可应用的数据验证检查数不胜数,取决于你的具体需求、字段类型与特定场景。重要的检查包括:
- 数据类型检查:确认写入字段的数据类型正确(例如确保
age字段只接受数字)。 - 格式检查:核对数据是否符合特定模式,如电话号码
(XXX) XXX-XXXX、日期YYYY-MM-DD,或邮箱[email protected]。 - 范围检查:确保数值处于预定义的最小与最大范围内(例如
score字段必须在0到100之间)。 - 必填检查:确认必填字段未被留空或为 null,确保关键信息不缺失。
- 代码检查:校验输入是否来自预定义的可接受值列表(如 ISO 3166 国家代码)。
- 一致性检查:核对同一条目内多个字段或不同条目之间的数据是否逻辑一致(例如下单日期必须早于送达日期)。
- 唯一性检查:防止需要唯一值的字段出现重复记录,如员工 ID 或邮箱地址。
何时执行
经验法则是:数据验证应在数据生命周期中持续进行。同时,越早执行,就越能有效防止错误扩散。这被称为数据质量的“左移”做法。
因此,最主动高效的验证时机是在数据录入点。当场拦截错误可确保劣质数据永不进入你的系统,节省后续清洗的人力与资源。这适用于用户输入的数据(如表单或文件上传)、通过网络爬取的数据、或来自你不完全信任的公共/开源库的数据。
对于用户经由后端 API 提交的数据,实时验证可以立即反馈(例如在 API 响应中直接标记格式不正确的邮箱或不完整的手机号,并返回400 Bad Request 错误)。
不过,并非总能立刻验证数据。例如,在ETL 或 ELT 管道中,验证通常在特定阶段进行:
- 抽取后:检查从源系统拉取的数据在传输过程中是否损坏或丢失。
- 转换后:核对每个转换步骤(如聚合)的输出是否满足预期规则与标准。
即使数据已存储,也应定期复核。因为数据不是静态的,它可能被更新、丰富或二次利用,因此需要持续验证。
如何执行数据验证
数据验证过程包含以下步骤:
- 定义需求:基于业务需求、监管标准与期望,制定清晰的验证规则(例如为数据定义带规则的模式)。
- 采集数据:通过多种来源获取数据,如爬虫、API 或数据库。
- 应用验证:根据定义的规则检查数据的准确性、一致性与完整性。
- 错误处理:按组织策略记录、隔离或修正无效记录。为输入错误数据的用户提供明确反馈。
- 加载数据:数据验证通过且清洗完成后,将其加载至目标系统,如数据仓库。
注意:下一章将通过一个 Python 示例演示上述步骤如何落地。
数据验证常用库
下表列出了一些优秀的开源数据验证库:
| 库 | 编程语言 | GitHub 星标 | 简介 |
|---|---|---|---|
| Pydantic | Python | 25.3k+ | 基于 Python 类型注解的数据验证 |
| Marshmallow | Python | 7.2k+ | 将复杂对象与简单 Python 数据类型相互转换的轻量库 |
| Cerberus | Python | 3.2k+ | 轻量、可扩展的 Python 数据验证库 |
| jsonschema | Python | 4.8k+ | JSON Schema 在 Python 中的实现 |
| Validator.js | JavaScript | 23.6k+ | 字符串校验与清洗库 |
| Joi | JavaScript | 21.2k+ | 功能强大的 JS 数据验证库 |
| Yup | JavaScript | 23.6k+ | 极其简单的对象模式验证 |
| Ajv | JavaScript | 14.4k+ | 最快的 JSON Schema 验证器。支持 JSON Schema draft-04/06/07/2019-09/2020-12 与 JSON Type Definition (RFC8927) |
| FluentValidation | C# (.NET) | 9.5k+ | 流行的 .NET 验证库,用于构建强类型验证规则 |
| validator | Go | 19.1k+ | Go 的结构体与字段验证,支持跨字段、跨结构体、Map、Slice、Array 深入验证 |
如何在 Python 中应用数据验证:分步示例
在本教程中,你将学习如何使用 Pydantic 对 JSON 输入数据进行验证。教程将涵盖构建数据验证流程的主要方面。
场景描述
假设你在抓取一个电商网站的数据。具体而言,目标是该产品页面:
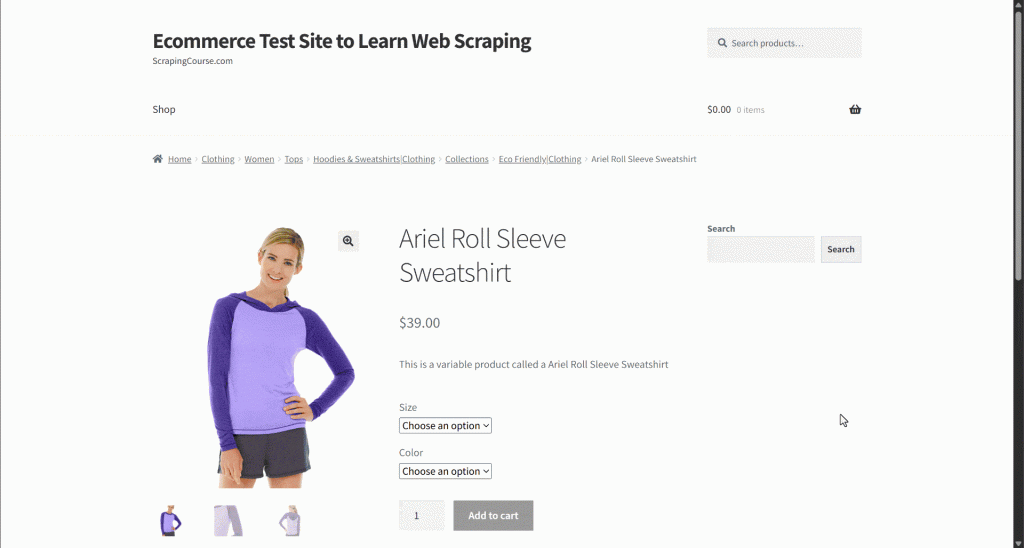
在数据抽取过程中,你将页面内容提供给一个用于简化解析的 LLM。但 LLM 可能不够精确,可能生成臆造、不可靠或不完整的数据。这正是数据验证至关重要的原因。
为简化,假设你已经搭建好 Python 项目与开发环境。
步骤 #1:定义目标模式与规则
先检查目标页面,注意产品页面包含以下字段:
- 产品 URL:产品页面的 URL。
- 产品名称:包含产品名称的字符串。
- 图片:图片 URL 列表。
- 价格:浮点数表示的价格。
- 货币:表示货币的单个字符。
- SKU:包含产品 ID 的字符串。
- 类别:包含一个或多个类别的数组。
- 简介:产品简短描述的文本字段。
- 详细描述:包含完整产品描述及详情的文本字段。
- 附加信息:包含以下内容的对象:
- 尺码选项:可选尺码的字符串数组。
- 颜色选项:可选颜色的字符串数组。
然后,将其表示为一个Pydantic 模型,如下所示:
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options: Optional[List[str]] = None # nullable
color_options: Optional[List[str]] = None # nullable
class Product(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
product_url: HttpUrl # required, must be a valid URL
product_name: str # required
images: Optional[List[HttpUrl]] = None # list of valid URLs, nullable
price: Optional[PositiveFloat] = None # nullable, must be >= 0
currency: Optional[Annotated[str, StringConstraints(min_length=1, max_length=1)]] = None # nullable, single character
sku: str # required
category: Optional[List[str]] = None # nullable
description: Optional[str] = None # nullable
long_description: Optional[str] = None # nullable
additional_information: Optional[AdditionalInformation] = None # nullable
@model_validator(mode="after")
# Custom validation rule to make sure that the price is always associated with a currency
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("currency must be provided if price is set")
return values注意,Product 模型不仅定义了字段及其类型(如 str、HttpUrl 等),还包含验证约束(如货币必须为单个字符)。此外,它包含严格验证规则,以确保价格总是与货币关联,并禁止任何与模型不匹配的额外字段。
步骤 #2:采集数据
假设你通过 AI 网页爬取获取数据,如下列教程之一所示:
- 使用 ChatGPT 的网页爬取:分步教程
- 使用 Gemini 的网页爬取:完整教程
- 使用 Perplexity 的网页爬取:分步指南
- 使用 Claude 的网页爬取:Python 中的 AI 驱动解析
你将得到一个包含抓取数据的 product.json 文件。这里假设 LLM 生成的内容如下:

如你所见,这个输出并不完全匹配 Pydantic 模型。如果在提示词中未明确指定输出结构,或 AI 的温度设置过高,这种情况很常见。
步骤 #3:应用验证规则
从 product.json 文件加载数据:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)然后,使用 Pydantic 进行验证:
try:
# Validate the data through the Pydantic model
product = Product(**product_data)
print("Validation successful!")
except ValidationError as e:
print("Validation failed:")
print(e)运行脚本,你将得到如下错误输出:
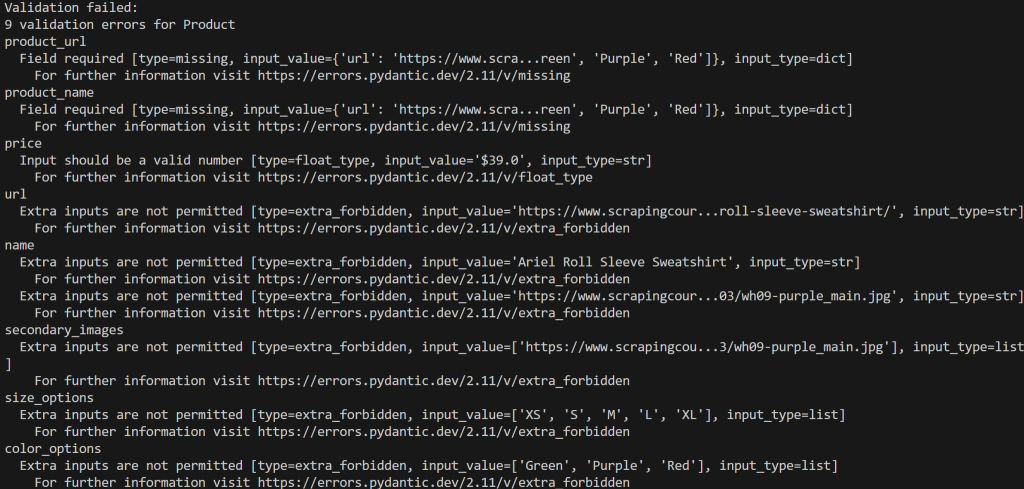
本例中检测到 9 个验证错误,因为输入数据不符合 Product 模型。
步骤 #4:修复错误
目前没有通用流程能自动修复数据以通过验证。每条数据管道或工作流都不同,你可能需要在不同方面介入。
就此例而言,解决方法很简单:在 LLM 提示词中清晰指定期望的输出格式,大多数 LLM(如 OpenAI)都支持该特性。
提示:可在我们的使用 GPT Vision 的可视化网页爬取指南中看到该特性的实战。
否则,如果不支持结构化输出,你也可以在提示词中让 LLM 匹配期望的 Pydantic 模型,将其以 JSON 字符串形式输出:
prompt = f"""
Extract data from the given page content and return it with the following structure:
{Product.model_json_schema()}
CONTENT:
<page content>
"""两种方式下,LLM 的输出都应与期望格式一致。
做出上述修改后,product.json 将包含:
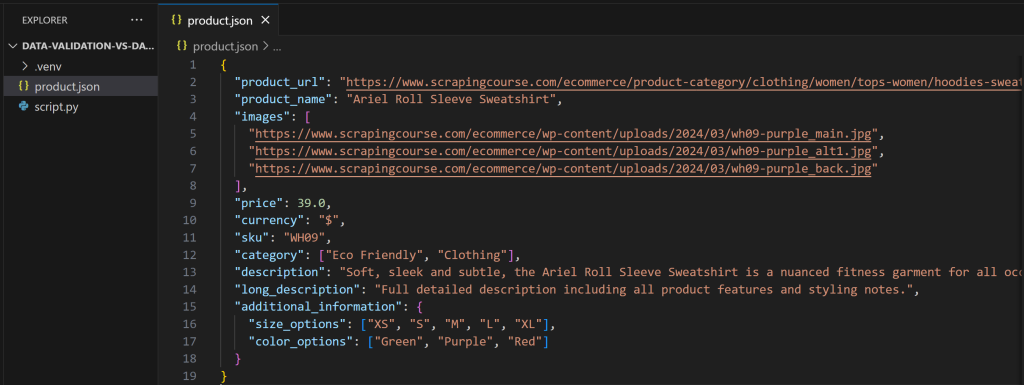
这一次,运行脚本将输出:

太棒了!数据验证已成功通过。验证通过后,你即可继续处理、入库或执行其他操作。
数据核验:要点解析
继续本指南的第二部分:数据核验。
什么是数据核验,它为何重要?
数据核验是检查数据是否准确并反映现实事实的过程。其通过将信息与权威来源进行比对来实现。
与仅检查数据是否满足预定义规则(如邮箱格式正确)的数据验证不同,数据核验旨在确认数据是真实并与现实相符的(如该邮箱确实存在且属于目标人员)。
核验对于强化数据质量至关重要,尤其是在语义层面。毕竟,即使结构良好、看似干净的数据也可能包含错误信息。依赖不准确的数据会导致高昂代价、错误决策、糟糕的客户体验与运营低效。
数据核验检查示例
数据核验颇具挑战,最佳方法高度取决于输入数据与业务领域。常见方法包括:
- 自动核验:使用专业软件、第三方服务或Agent 化 AI 系统,将数据与可信来源交叉比对。
- 校对:人工审阅文档、数据或字段,确保信息精确。可由具备领域知识的人手动执行,也可由 AI 自动执行。
- 双录入:两个独立系统(或自主 AI 代理)就同一主题分别录入数据,然后对比记录并标记差异以便复核或更正。
- 源数据核验:将数据库中的数据与原始来源文件(如患者病历)进行比对,确认一致。
何时执行
当你无法完全信任数据来源时,应进行数据核验。典型例子是使用 AI 生成或丰富数据时,AI 可能生成看似合理但不准确的信息。
另一类场景是数据迁移或整合后的传输与存储。当此类任务完成后,需要确保结果数据仍然准确。数据核验也适用于持续性的数据质量维护。
请记住,数据核验通常在数据验证之后进行。如果数据结构不符合期望格式,则核验没有意义,因为该数据可能完全不可用。只有当数据通过验证后,才应继续进行核验。
数据核验确实比数据验证更复杂,因为你很难像前文那个简单 Python 脚本那样获得确定性的结果。要绝对确定信息是否为真非常困难。
数据核验的主要方法
在处理用户提交内容时,最佳方式是人工核验。例如:
- 邮箱核验:用户注册时输入邮箱后,系统发送带确认链接或验证码的邮件,以确认地址有效且可访问。
- 手机号核验:通过短信或语音电话发送一次性密码(OTP),以确认号码有效、处于活跃状态且归属该用户。
类似地,你可以要求用户提交身份证明或账单以核验身份或地址。这些文件可通过 OCR 系统处理,以验证用户输入与上传文件信息是否一致。尽管该方法仍可能遭遇欺诈,但对提升数据可信度非常有用。
真正的挑战在于获取公共网页数据,这是最大且最非结构化的信息源。在这种情况下,判断信息是否正确很难。通用方法是优先选择可信来源(如文档、官方声明),并在给定输入内容后追溯其来源、在线交叉比对与比较结果。
手动执行这些任务极为耗时,因此如今大量此类任务都通过配备网页搜索与爬取工具的 AI 代理自动化完成。
如何执行数据核验:Python 示例
本节将通过一个分步示例构建用于数据核验的 AI 代理。该代理将:
- 接收一段示例文本作为输入。
- 将信息传递给扩展了网页搜索与爬取工具的 LLM。
- 要求 AI 识别源文本中的主要主题,并在 Google 上搜索相关、可信页面以核验其准确性。
- 抓取这些页面的信息并与源文本进行比较。
- 返回一份报告,指出数据是否准确;若不准确,给出修正建议与佐证来源链接。
若无支持网页数据获取、搜索、交互等能力的 AI 就绪基础设施,上述流程将难以实现——而Bright Data 的 AI 基础设施正提供了这类能力。
为便于集成,我们将使用 Bright Data Web MCP,它提供 60+ 工具。特别是,其免费层包含如下两款工具:
search_engine:以 JSON 或 Markdown 形式获取 Google、Bing 或 Yandex 的搜索结果。scrape_as_markdown:将任意网页抓取为干净的 Markdown,且可绕过机器人检测与验证码。
这两款工具足以驱动数据核验代理并实现目标!
场景描述
假设你在一个 summary.txt 文件中有待核验的输入数据。举例来说,这里包含一段关于第 59 届超级碗(Super Bowl LIX)的简短摘要:

你将使用与 Web MCP 集成的 LangChain 构建数据核验代理。要跟随实践,你需要:
- 本地安装 Python。
- 已搭建的 LangChain 项目。
- 一个用于连接 Web MCP 的Bright Data API Key。
- 一个 OpenAI API Key。
开始之前,请查看我们关于使用 LangChain MCP 适配器与 Bright Data Web MCP 集成的教程。如果你更偏好其他框架或工具,请参考这些指南:
- 使用 CrewAI 与 Bright Data MCP 构建网页爬取代理
- 使用 LlamaIndex 与 Bright Data MCP 构建 CLI 聊天机器人
- 将 Claude Code 集成到 Bright Data Web MCP
- 如何使用 SERP 数据与 GPT-4o 创建 RAG 聊天机器人
构建用于数据核验的 AI 代理
以下展示如何使用 LangChain 与 Bright Data 的 Web MCP 构建数据核验代理:
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Load the input data to verify
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# Initialize the LLM engine
llm = ChatOpenAI(
model="gpt-5-nano",
)
# Configuration to connect to a local Bright Data Web MCP server instance
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Replace with your Bright Data API key
}
)
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the MCP client session
await session.initialize()
# Get the MCP tools
tools = await load_mcp_tools(session)
# Create the ReAct agent
agent = create_react_agent(llm, tools)
# Agent task description
input_prompt = f"""
Given the input content below, perform the following steps:
1. Identify the main topic as a Google-like search query and use it to perform a web search to gather information about it.
2. From the search results, select the top 2/3 authoritative sources (e.g., trusted news sites, journals, official publications).
3. Scrape the content from the selected pages.
4. Compare the scraped information with the input content to determine whether it is accurate.
5. If not accurate, produce a report listing all errors found in the input content, along with the corrected information and links to the supporting sources.
Input content:
{summary_data_to_verify}
"""
# Stream the agent’s response
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())重点关注提示词本身,它是上述脚本中最重要的部分。
执行代理
启动代理后,你会看到它正确识别主要主题为 “Super Bowl LIX”。随后,它将使用 Web MCP 的search_engine 工具执行 Google 搜索:

从 SERP 结果中,它将 ESPN 与 CBS Sports 的文章识别为主要来源,并使用 scrape_as_markdown 工具对其进行抓取:
从三家新闻来源抽取内容后,它会生成如下 Markdown 报告:
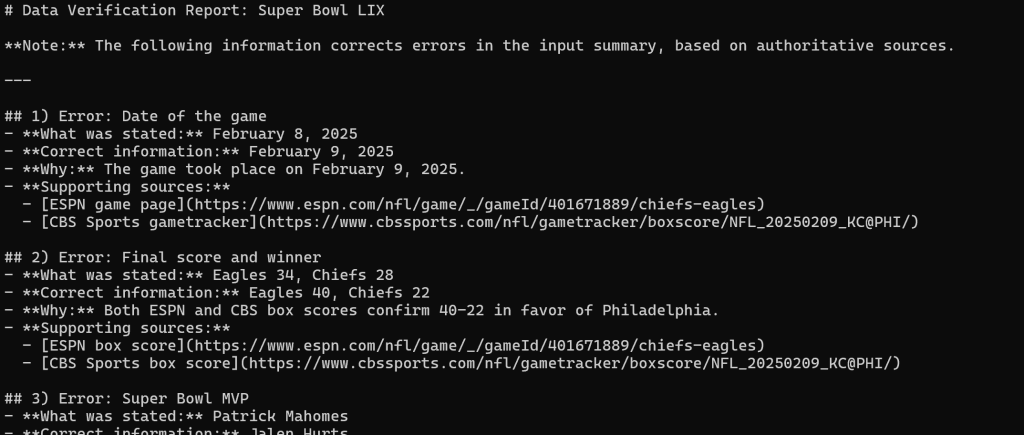
在 Visual Studio Code 中渲染,即可查看最终报告。
可以看出,借助 Web MCP 的网页搜索与抓取能力,LangChain 代理成功识别了原始错误文本中的所有错误。任务完成!
数据验证 vs 数据核验:总结表
通过下表对比两种技术:
| 方面 | 数据验证 | 数据核验 |
|---|---|---|
| 定义 | 在使用或存储前,根据预定义规则与标准检查数据的准确性、质量与完整性。 | 通过与权威来源比对,确认数据准确反映现实事实。 |
| 目的 | 确保数据符合预期格式、类型、范围与规则;阻止劣质数据进入系统。 | 确保数据真实、准确、可信,支撑决策。 |
| 时机 | 在录入点、抽取后、转换后或周期性地执行。 | 在验证之后,或当数据源可靠性存疑时执行;通常在数据收集或传输之后。 |
| 复杂度 | 相对直接;基于既定规则的确定性检查。 | 更复杂;可能涉及不确定性、外部来源与人工审阅;结果可能非确定性。 |
| 示例 | price 必须 ≥ 0 |
核对价格是否与官方商店列表一致 |
最后点评
正如你在本文中所学,数据验证与数据核验处理的是不同但互补的任务。二者都为实现高数据质量做出贡献。同样地,忽视任一项都可能在支撑大多数业务运营的数据驱动流程中引发严重问题。
因此,选择值得信赖、可靠的数据提供商至关重要,该提供商需提供多种方案以确保数据验证,并提供构建高效数据核验系统的工具。
Bright Data 是一个绝佳示例。它提供广泛的产品,包括即用型、已验证的数据集以及完整的、面向 AI 的网页抓取解决方案,以从网络收集准确信息,支持验证与核验工作流。
立即注册免费 Bright Data 账户,探索我们的数据服务!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




