

在本指南中,你将学到:
- 为什么当传统解析技术不再适用时,GPT Vision 是数据提取任务的绝佳选择。
- 如何在 Python 中使用 GPT Vision 进行可视化网页爬虫。
- 这种方法的主要限制以及如何规避它。
让我们开始吧!
为何使用 GPT Vision 进行数据爬虫?
GPT Vision 是一种多模态 AI 模型,能够理解文本和图像。这些能力已在最新的 OpenAI 模型中提供。将图像传给 GPT Vision 后,你可以进行可视化数据提取,尤其适用于 传统数据解析失效的场景。
常规数据解析需要编写自定义规则从文档中提取数据(例如使用 CSS 选择器或 XPath 表达式 从 HTML 页面获取数据)。问题在于信息可能以视觉形式嵌入到图片、横幅或复杂的 UI 元素中,这些内容用标准解析技术无法获取。
GPT Vision 可帮助你从这些更难触达的来源中提取数据。两个最常见的用例是:
- 可视化网页爬虫:直接从页面截图中提取网页内容,无需担心页面改版或页面上的视觉元素。
- 基于图像的文档提取:从本地文件的截图或扫描件(如简历、发票、菜单和收据)中提取结构化数据。
如果你需要非可视化的方法,请参考我们的 使用 ChatGPT 进行网页爬虫 指南。
如何用 Python 借助 GPT Vision 从截图中提取数据
在这个循序渐进的部分,你将学会如何构建一个 GPT Vision 网页爬虫脚本。具体而言,爬虫会自动完成以下任务:
- 使用 Playwright 连接到目标网页。
- 对你想要提取数据的特定区域进行截图。
- 将截图传给 GPT Vision,并提示其提取结构化数据。
- 将提取的数据导出为 JSON 文件。
目标页面是 “Books to Scrape” 的一个特定产品页:
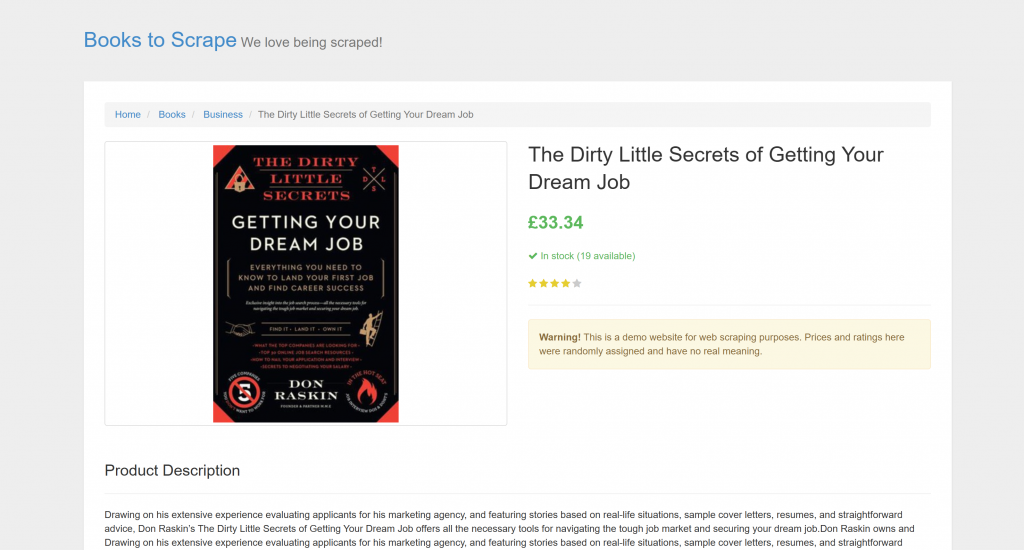
该页面非常适合测试,因为它明确欢迎 自动化爬虫机器人。此外,它包含诸如星级评分组件等视觉元素,这些元素用常规解析方法很难处理。
注意:为了简单起见,并因为 OpenAI 的 Python SDK 被广泛采用,示例代码使用 Python 编写。不过你也可以使用 JavaScript OpenAI SDK 或其他受支持的语言实现相同效果。
按照以下步骤学习如何使用 GPT Vision 爬虫网页数据!
先决条件
在开始之前,请确保你已具备:
- 在你的计算机上安装了 Python 3.8 或更高版本。
- 一个用于访问 GPT Vision API 的 OpenAI API 密钥。
要获取你的 OpenAI API 密钥,请按照 官方指南 操作。
以下背景知识也将帮助你更好地理解本文:
- 对浏览器自动化的基本了解,尤其是使用 Playwright。
- 对 GPT Vision 工作原理的熟悉。
注意:这种方法需要使用 Playwright 等浏览器自动化工具。原因是你需要在浏览器中渲染目标页面。页面加载完成后,才能对感兴趣的特定区域进行截图。可以使用 Playwright 截图 API 来完成这一点。
步骤 #1:创建你的 Python 项目
在终端运行以下命令,为你的爬虫项目创建新文件夹:
mkdir gpt-vision-scrapergpt-vision-scraper/ 将作为使用 GPT Vision 构建网页爬虫器的主项目文件夹。
进入该文件夹,并在其中创建 Python 虚拟环境:
cd gpt-vision-scraper
python -m venv venv在你喜欢的 Python IDE 中打开项目文件夹。可使用 安装了 Python 扩展的 Visual Studio Code 或 PyCharm 社区版。
在项目文件夹中创建一个 scraper.py 文件:
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------此时,scraper.py 还是一个空文件。很快,它将包含通过 GPT Vision 实现可视化LLM 网页爬虫的逻辑。
接下来,在终端中激活虚拟环境。在 Linux 或 macOS 上,运行:
source venv/bin/activate在 Windows 上,运行:
venv/Scripts/activate很好!你的 Python 环境现在已为使用 GPT Vision 进行可视化爬虫做好准备。
注意:在下面的步骤中,我们会展示如何逐步安装依赖。如果你希望一次性安装,运行如下命令:
pip install playwright openai然后:
python -m playwright install太好了!你的 Python 环境已经就绪。
步骤 #2:连接到目标站点
首先,你需要指示 Playwright 使用受控浏览器访问目标站点。在已激活的虚拟环境中,通过以下命令安装 Playwright:
pip install playwright 随后,通过 下载所需的浏览器二进制文件 完成安装:
python -m playwright install接着,在脚本中导入 Playwright,并使用 goto() 函数导航到目标页面:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()如果你不熟悉该 API,请阅读我们关于 使用 Playwright 进行网页爬虫 的文章。
很好!你现在已拥有一个能成功连接到目标页面的 Playwright 脚本。接下来是对页面进行截图。
步骤 #3:对页面进行截图
在编写截图逻辑之前,请记住 OpenAI 按 token 用量计费。换言之,输入截图越大,费用越高。
为了降低成本,最好将截图限定在包含目标数据的 HTML 元素范围内。Playwright 支持基于节点的截图,可以做到这一点。更窄的截图还能帮助 GPT Vision 聚焦相关内容,降低产生幻觉的风险。
先在浏览器中打开目标页面并熟悉其结构。接着,右键页面内容并选择“检查”(Inspect)以打开浏览器的开发者工具:
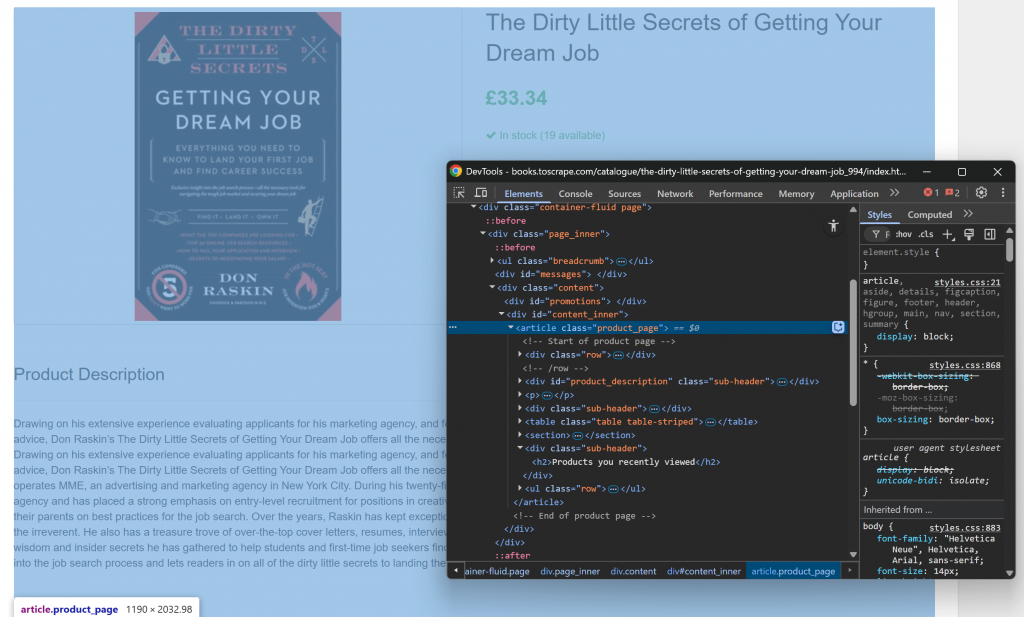
你会注意到,大多数相关内容都包含在 .product_page 这个 HTML 元素中。
由于该元素可能通过 JavaScript 动态加载或显示,你应在截图前等待它出现:
product_page_element = page.locator(".product_page")
product_page_element.wait_for()默认情况下,wait_for() 会等待该元素最多 30 秒出现在 DOM 中。这个小步骤至关重要,因为你不希望截图的是空白或不可见的区域。
现在,在所选定位器上使用 screenshot() 方法,仅对该元素进行截图:
product_page_element.screenshot(path=SCREENSHOT_PATH)这里,SCREENSHOT_PATH 是一个保存输出文件名的变量,例如:
SCREENSHOT_PATH = "product_page.png"将该信息存为变量是个好主意,因为很快还会用到。
如果你运行脚本,它会生成一个名为 product_page.png 的文件,内容如下:
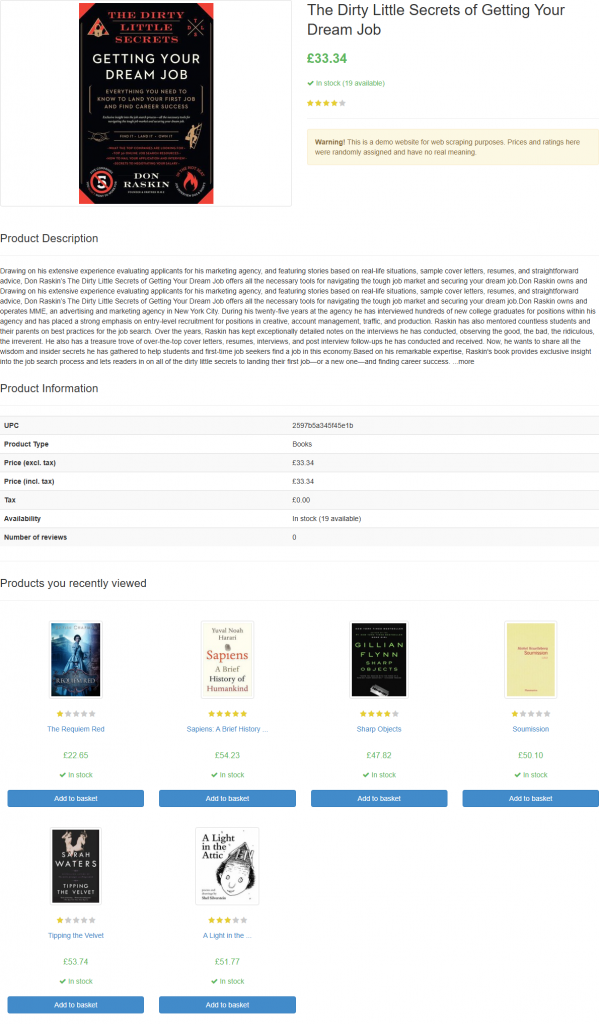
注意:将截图保存到文件是最佳实践,因为你可能希望稍后用不同的技术或模型对其进行再次分析。
棒极了!截图步骤完成。
步骤 #4:在 Python 中配置 OpenAI
要使用 GPT Vision 进行网页爬虫,你可以使用 OpenAI Python SDK。在已激活的虚拟环境中安装 openai 包:
pip install openai然后在 scraper.py 中导入 OpenAI 客户端:
from openai import OpenAI接着初始化一个 OpenAI 客户端实例:
client = OpenAI()这可让你更轻松地连接到 OpenAI API(包括 Vision API)。默认情况下,OpenAI() 构造函数会在 OPENAI_API_KEY 环境变量中查找你的 API 密钥。通过设置环境变量来配置认证是 推荐的安全做法。
在开发或测试时,你也可以选择直接在代码中添加密钥:
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)将 <YOUR_OPENAI_API_KEY> 替换为你的实际 OpenAI API 密钥。
非常好!OpenAI 的设置已经完成,你可以开始使用 GPT Vision 进行网页抓取了。
步骤 #5:发送 GPT Vision 抓取请求
GPT Vision 支持多种图像输入格式,包括公开的图片 URL。由于你使用的是本地文件,需要先将图像转换为Base64 编码字符串再发送至 OpenAI 服务器。
将截图文件转换为 Base64 的代码如下:
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") 这需要从 Python 标准库导入:
import base64现在,将编码后的图像传给 GPT Vision 以进行可视化网页抓取:
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)注意: 上述示例设置了 gpt-4.1 模型,但你可以使用任何支持视觉能力的 OpenAI 模型。
请注意,GPT Vision 直接集成在 Responses API 中。这意味着你无需进行任何特殊配置。只需通过 "type": "input_image" 包含你的 Base64 图像即可。
上述抓取提示词为:
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.你可能并不清楚目标页面的精确结构,因此提示词应尽量通用(但仍需聚焦目标)。在此,我们明确告知模型忽略不相关的部分,同时要求返回携带干净、良好结构键名的 JSON 对象。
请注意,此 OpenAI Responses API 请求被配置为在JSON 模式下工作。这可以确保模型以 JSON 格式输出数据。要启用该功能,你的提示词必须包含要求以 JSON 返回数据的指令,例如:
以 JSON 格式返回数据,并使用小写 snake_case 作为属性名。否则,请求会失败并报错:
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}当请求成功完成后,你可以通过以下方式访问解析后的结构化数据:
json_product_data = response.output_text可选地,将结果字符串解析为 Python 字典:
import json
product_data = json.loads(json_product_data)GPT Vision 的数据解析逻辑到此完成!接下来只需将抓取到的数据导出到本地 JSON 文件。
步骤 #6:导出爬虫到的数据
将 GPT Vision API 返回的输出 JSON 字符串写入文件:
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)这会创建一个 product.json 文件,存储可视化提取的数据。
做得好!你的 GPT Vision 驱动的网页抓取器已经就绪。
步骤 #7:整合所有代码
以下是 scraper.py 的完整代码:
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)哇!不到 65 行代码,你就已经用 GPT Vision 完成了可视化网页爬虫。
运行 GPT Vision 爬虫器:
python scraper.py脚本运行一段时间后,会在项目文件夹中写出 product.json 文件。打开后,你应能看到:
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}注意它成功提取了页面上的所有产品信息,包括来自纯视觉元素的评论评分:
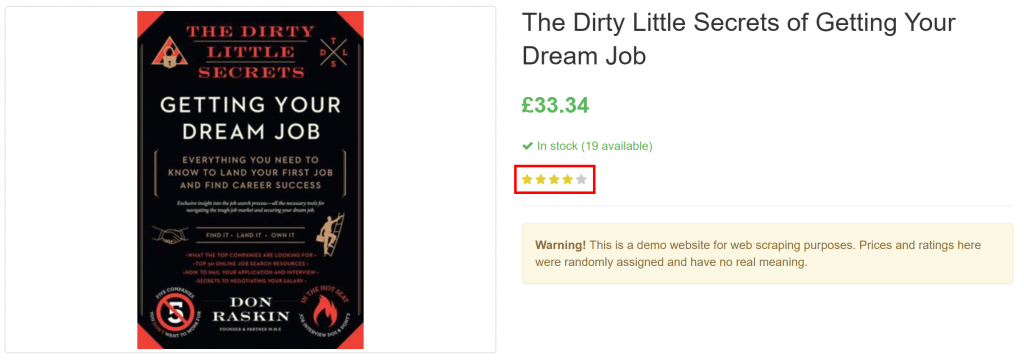
就这样!GPT Vision 成功将一张截图转换成结构良好的 JSON 文件。
下一步
要改进你的 GPT Vision 爬虫器,可以考虑以下优化:
- 提高可复用性:将脚本重构为从命令行接收目标 URL、要等待的元素 CSS 选择器以及 LLM 提示词。这样你无需修改代码即可爬虫不同页面。
- 保护你的 API 密钥:不要在代码中硬编码 OpenAI API 密钥,而是将其存储在
.env文件中并使用python-dotenv加载。或将其设置为名为OPENAI_API_KEY的全局环境变量。这两种方法都有助于保护凭证并保障代码库安全。
克服可视化网页爬虫的最大限制
这种网页爬虫方法的主要挑战在于截图步骤。虽然在像 “Books to Scrape” 这样的沙箱站点上运行顺利,但现实世界的网站则截然不同。
许多现代网站部署了 反爬措施,可能在你访问页面之前就阻止你的脚本。即使你的爬虫成功访问页面,仍可能被返回错误或人机验证挑战。例如,使用原生 Playwright 访问 G2.com 等站点时会出现这种情况:

这些问题可能由浏览器指纹、IP 信誉、速率限制、CAPTCHA 挑战等因素导致。
绕过此类阻拦的最稳健方式是依赖专用的 Web Unlocker API!
Bright Data 的 Web Unlocker 是一个功能强大的爬虫端点,背后是一个拥有超过 1.5 亿个 IP 的代理网络。它提供指纹伪装、JavaScript 渲染、CAPTCHA 自动求解等众多能力。它甚至支持截图捕获,这意味着你可以完全跳过手写的 Playwright 截图逻辑。
假设你想从 Bright Data 的 G2 卖家页面中提取平均星级评分:
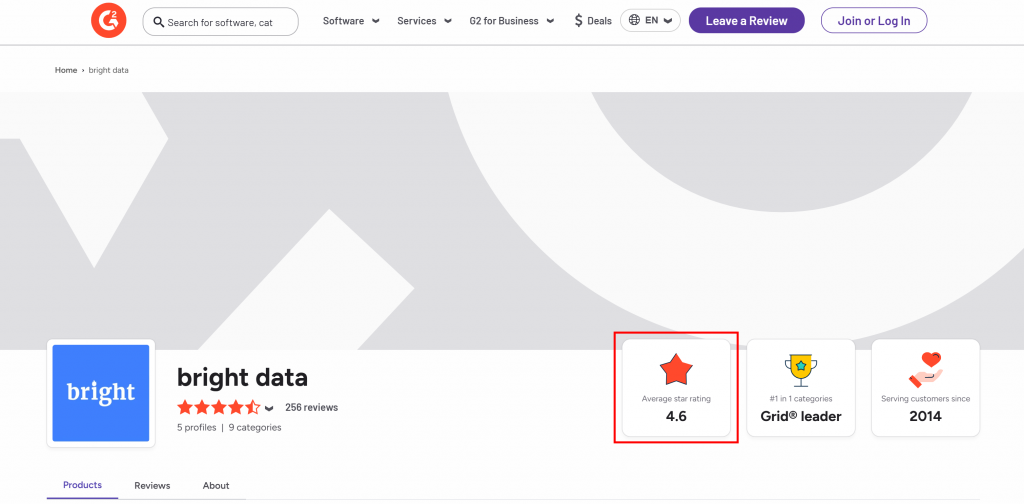
要开始,请按照文档 设置 Web Unlocker,并获取你的 Bright Data API 密钥。接着将 GPT Vision 与 Web Unlocker 一起使用:
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
print(response.output_text)运行上述脚本,它将输出如下内容:
图像中的平均星级评分为 4.6。该信息是正确的,你可以在 Web Unlocker 返回的 screenshot.png 文件中直观看到:
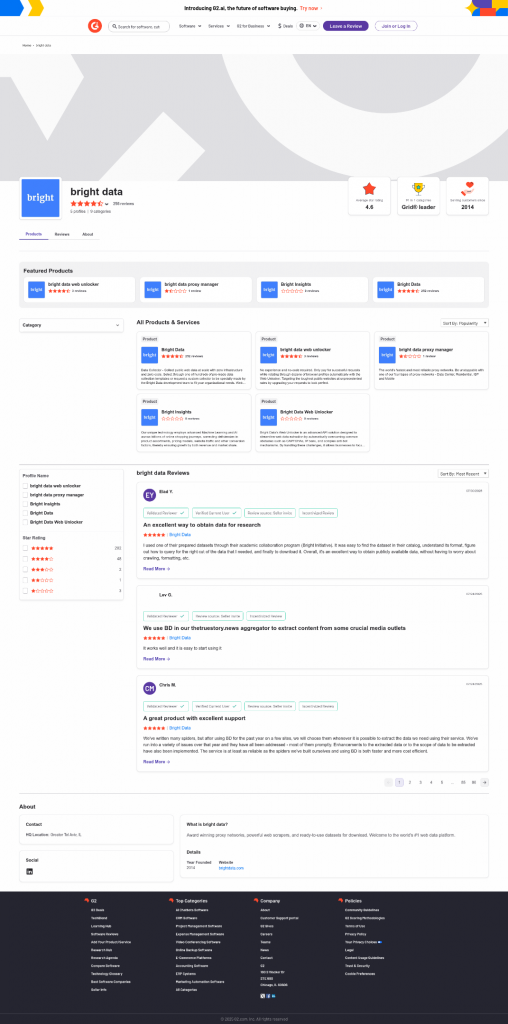
注意,你也可以使用 Web Unlocker 获取页面的完整解锁 HTML,甚至将内容以面向 AI 优化的 Markdown 格式返回。
就这样——不再有阻拦,不再有头疼。你现在拥有一个可在受保护网站上也能运行的、生产级的 GPT Vision 驱动网页爬虫器。
在更复杂的爬虫场景中查看 OpenAI SDK 与 Web Unlocker 的协同工作。
结论
在本教程中,你学习了如何将 GPT Vision 与 Playwright 的截图能力结合,构建一个由 AI 驱动的网页爬虫器。过程中最大的挑战(即截图时被阻拦)通过 Bright Data 的 Web Unlocker API 得到了有效解决。
如上所述,将 GPT Vision 与 Web Unlocker API 提供的截图功能结合,可从任何网站中以可视化方式提取数据,而无需编写自定义解析代码。这只是 Bright Data 的 AI 产品与服务 所支持的众多场景之一。
免费创建一个 Bright Data 账号,开始体验我们的数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


