

本指南将介绍以下内容:
- 开始使用百度网页抓取所需的全部知识。
- 抓取百度数据最热门且有效的方法。
- 如何使用 Python 从零开始构建自定义百度抓取工具。
- 如何使用 Bright Data SERP API 检索搜索引擎结果。
- 如何通过 Web MCP 为您的 AI 智能体提供百度搜索数据接入方案。
现在就来一探究竟吧!
了解百度 SERP
在采取任何行动之前,请先花时间了解百度 SERP(搜索引擎结果页面)的结构、包含的数据类型以及访问方式等信息。
百度 SERP URL 与机器人检测系统
在浏览器中打开百度并开始进行一些搜索。例如,搜索“bright data”。您应该会得到一个如下所示的 URL:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358在所有这些查询参数中,重要的有:
- 基础 URL:
https://www.baidu.com/s。 - 搜索查询参数:
wd。
换句话说,您可以使用更短的 URL 获得相同的结果:
https://www.baidu.com/s?wd=bright%20data此外,百度还通过 pn 查询参数来构建其分页 URL。具体来说,第二页会添加 &pn=10,之后每一页该参数值会递增10。例如,如果您想抓取以“bright data”为关键词的3页搜索结果,对应的 SERP URL 应为:
https://www.baidu.com/s?wd=bright%20data -> page 1
https://www.baidu.com/s?wd=bright%20data&pn=10 -> page 2
https://www.baidu.com/s?wd=bright%20data&pn=20 -> page 3现在,如果您尝试在 Postman 等 HTTP 客户端中直接使用简单的 GET HTTP 请求访问此类 URL,很可能会看到以下内容:
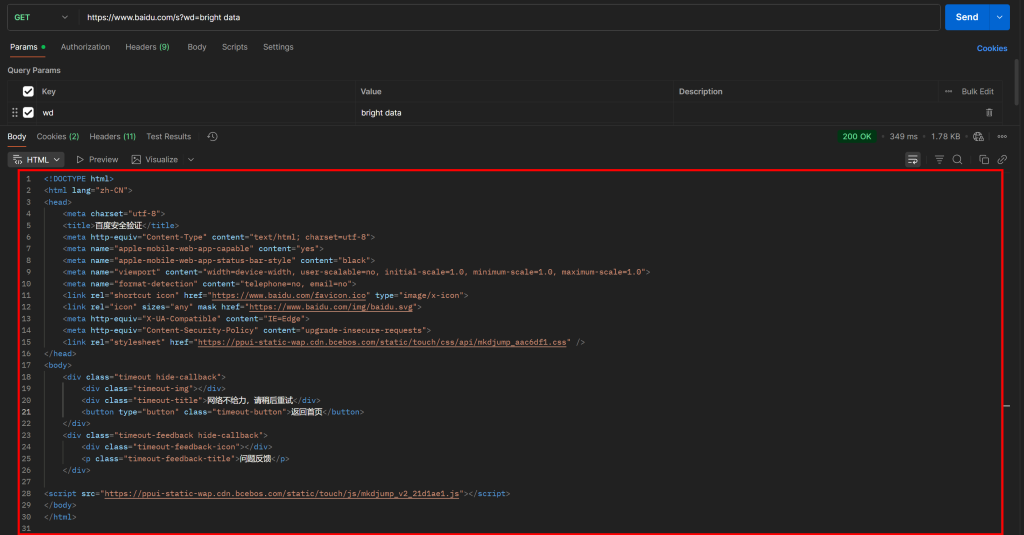
如您所见,百度返回了一个显示“网络不给力,请稍后重试”的页面(字面意思是“网络状况不佳,请稍后再试”,但实际上是一个反爬虫页面)。
即使您包含了通常在网络抓取任务中必不可少的 User-Agent 请求头,这种情况也依然会发生。换句话说,百度检测到您的请求是自动发出的,因此予以拦截并要求进行额外的人工验证。
这清楚地表明,要抓取百度数据,您需要使用浏览器自动化工具(例如 Playwright 或 Puppeteer)。仅靠 HTTP 客户端和 HTML 解析器的简单组合是远远不够的,因为这种配置会持续触发反爬虫拦截机制。
百度 SERP 中的数据
现在,请将注意力集中在浏览器中渲染的“bright data”百度 SERP 上。您应该会看到如下内容:
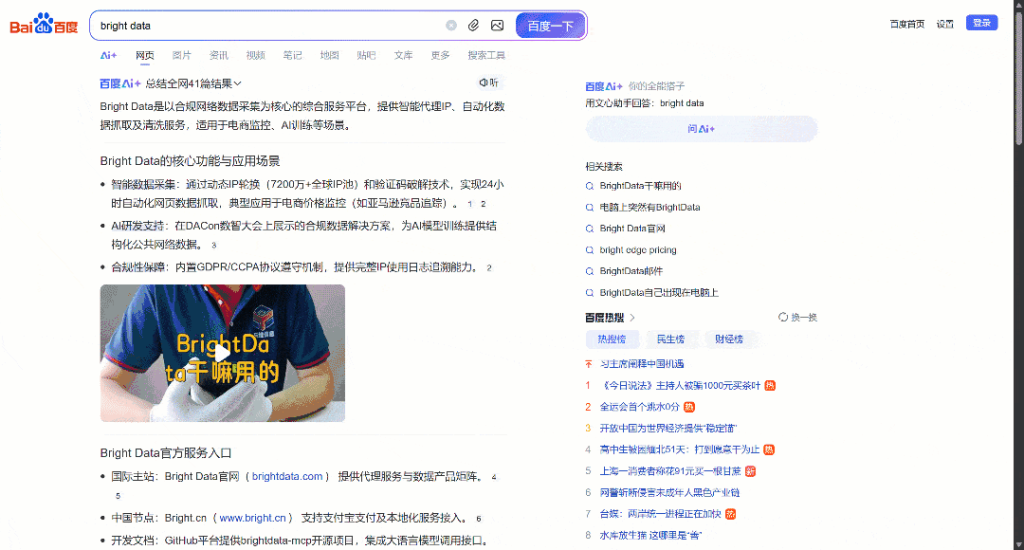
每个百度 SERP 页面都分为两栏。左侧栏包含 AI 概览(参见如何抓取 AI 概览内容),其后是搜索结果。在这一栏底部设有“相关搜索”板块,其下方则排列着分页导航组件。
右侧栏展示的是“百度热搜”,这里呈现的是百度平台上的热门或流行话题。(注意:这些热门内容不一定与您的搜索词相关。)
以上就是您可以从百度 SERP 中抓取的所有主要数据。在本教程中,我们仅聚焦于搜索结果——这部分通常是最重要的信息!
抓取百度数据的主要方法
获取百度搜索结果数据有几种方法。请在下方的汇总表中比较主要方法:
| 方法 | 集成复杂度 | 要求 | 定价 | 拦截风险 | 可扩展性 |
|---|---|---|---|---|---|
| 构建自定义抓取工具 | 中/高 | Python 编程技能 + 浏览器自动化技能 | 免费(可能需使用反爬虫浏览器以避免拦截) | 可能 | 有限 |
| 使用 Bright Data 的 SERP API | 低 | 任意 HTTP 客户端 | 付费 | 无 | 无限制 |
| 集成 Web MCP 服务器 | 低 | 支持 MCP 的 AI 智能体框架或平台 | 提供免费层级,后续为付费版本 | 无 | 无限制 |
您将通过本教程逐步掌握如何实现每种方法!
注意1:无论您选择何种方法,本指南中统一使用的目标搜索词均为“bright data”。这意味着您将具体学习如何检索针对该搜索词的百度搜索结果。
注意2:我们假设您已在本地安装 Python 并熟悉 Python 网络脚本编写。
方法1:构建自定义抓取工具
使用浏览器自动化框架或结合 HTTP 客户端与 HTML 解析器,从零开始构建百度抓取工具。
👍 优点:
- 完全掌控数据解析逻辑,能够精准提取所需内容。
- 可根据您的需求灵活定制。
👎 缺点:
- 需要投入配置、编程及维护工作。
- 在大规模执行时,可能会面临 IP 封禁、验证码、速率限制及其他网络抓取挑战 。
方法2:使用 Bright Data 的 SERP API
利用 Bright Data SERP API——这是一种高级解决方案,让您能够通过易于调用的 HTTP 端点查询百度(及其他搜索引擎)。该服务会为您处理所有反爬虫措施和扩展问题。这些特性及其众多其他优势使其成为市场上最优秀的 SERP 和搜索 API 之一。
👍 优点:
- 高度可扩展且稳定可靠,由包含超过1.5亿 IP 的代理网络提供支持。
- 无 IP 封禁或验证码问题。
- 兼容所有 HTTP 客户端(包括 Postman、Insomnia 等可视化工具)。
👎 缺点:
- 付费服务。
方法3:集成 Web MCP 服务器
通过 Bright Data 的 Web MCP,您的 AI 智能体可免费获取百度搜索结果——该服务底层直接连接 Bright Data SERP API 及 Web Unlocker。
👍 优点:
- AI 工作流与智能体的集成。
- 提供免费层级。
- 无需数据解析逻辑(该部分将由 AI 处理)。
👎 缺点:
- 对大型语言模型行为的控制能力有限。
方法1:使用 Playwright 构建 Python 自定义百度抓取工具
按照以下步骤使用 Python 构建自定义百度网络抓取脚本。
如前所述,抓取百度数据需要使用浏览器自动化,因为简单的 HTTP 请求会被拦截。在本教程章节中,我们将使用 Playwright——Python 中最优秀的浏览器自动化库之一。
步骤1:设置抓取项目
首先打开终端,为您的百度抓取工具项目创建新文件夹:
mkdir baidu-scraperbaidu-scraper/ 文件夹将包含您的抓取项目的所有文件。
接下来,进入项目目录并在其中创建 Python 虚拟环境:
cd baidu-scraper
python -m venv .venv现在,在您首选的 Python IDE 中打开项目文件夹。我们推荐使用带 Python 扩展的 Visual Studio Code 或者 PyCharm Community Edition。
在项目根目录下新建一个名为 scraper.py 的文件。项目结构应如下所示:
baidu-scraper/
├── .venv/
└── scraper.py接下来,在终端中激活虚拟环境。在 Linux 或 macOS 上,执行:
source .venv/bin/activate如在 Windows 系统上,则运行下方命令:
.venv/Scripts/activate虚拟环境激活后,使用 pip 通过 playwright 包安装 Playwright:
pip install playwright接下来,安装所需的 Playwright 依赖项(例如浏览器二进制文件):
python -m playwright install完成!您的 Python 环境现已准备就绪,可以开始构建百度网络抓取工具了。
步骤2:初始化 Playwright 脚本
在 scraper.py 中,导入 Playwright 并使用其同步 API 启动受控的 Chromium 浏览器实例:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Initialize a Chromium instance in headless mode
browser = p.chromium.launch(headless=True) # set headless=False to see the browser for debugging
page = browser.new_page()
# Scraping logic...
# Close the browser and release its resources
browser.close()以上代码片段构成了您的百度抓取工具基础框架。
headless=True 参数会让 Playwright 以无可见图形界面的方式启动 Chromium 浏览器。根据测试,此项配置不会触发百度的机器人检测机制。因此,该模式非常适用于数据抓取任务。然而,在开发或调试代码时,建议设置为 headless=False,以便实时观察浏览器的操作过程。
非常好!现在,连接到百度 SERP 并开始检索搜索结果。
步骤3:访问目标 SERP
正如前面所分析的,构建百度 SERP URL 非常简单。相较于让 Playwright 模拟用户交互(如在搜索框输入内容并提交),直接通过代码构建 SERP URL 并让 Playwright 跳转到该地址要简便得多。
以下是构建针对搜索词“bright data”的百度 SERP URL 的逻辑:
# The base URL of the Baidu search page
base_url = "https://www.baidu.com/s"
# The search keyword/keyphrase
search_query = "bright data"
params = {"wd": search_query}
# Build the URL of the Baidu SERP
url = f"{base_url}?{urlencode(params)}"千万别忘记从 Python 标准库导入 urlencode() 函数:
from urllib.parse import urlencode现在,让 Playwright 控制的浏览器通过 goto() 访问生成的 URL:
page.goto(url)如果您在调试器中以有头模式(headless=False)运行脚本,将会看到一个 Chromium 窗口加载百度 SERP 页面:
太棒了!这正是您接下来要抓取的 SERP。
步骤4:准备抓取所有 SERP 结果
在深入研究抓取逻辑之前,您必须先了解百度 SERP 的结构。首先,由于页面包含多个搜索结果元素,您需要一个列表来存储提取的数据。因此,首先初始化一个空列表:
serp_results = []接下来,在您的浏览器中使用无痕窗口打开目标百度 SERP(确保会话无残留):
https://www.baidu.com/s?wd=bright%20data右键点击其中一个搜索结果元素,选择“检查”以打开浏览器的开发者工具:
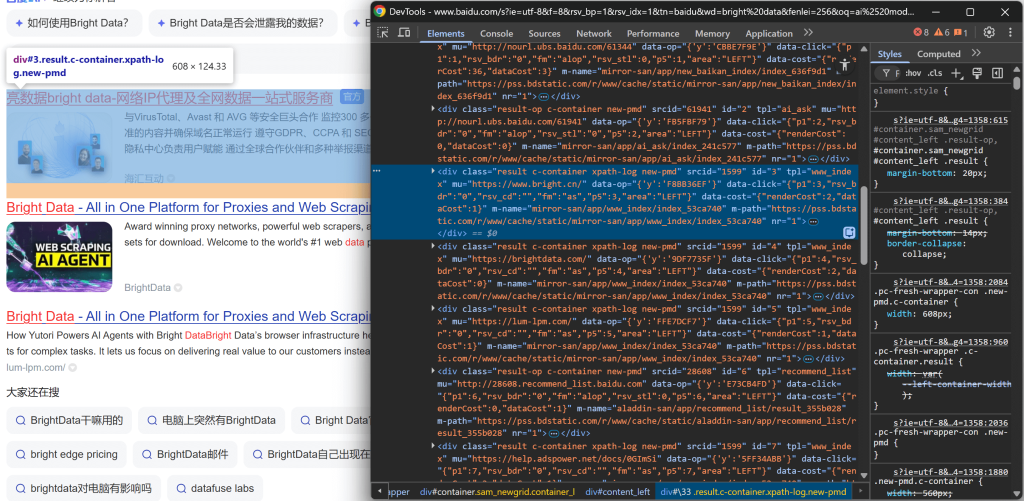
查看 DOM 结构时,您会发现每个搜索结果项都有 result 类。这意味着您可以使用 .result CSS 选择器选择页面上的所有搜索结果。
在您的 Playwright 脚本中应用该选择器:
search_result_elements = page.locator(".result")注意:如果您不熟悉此语法,请阅读我们关于 Playwright 网络抓取的指南。
最后,遍历每个选定的元素:
for search_result_element in search_result_elements.all():
# Data parsing logic...准备应用数据解析逻辑提取百度搜索结果并填充 serp_results 列表:
完美!您现在差不多快完成百度抓取工作流了。
步骤5:抓取搜索结果数据
检查百度结果页面上 SERP 元素的 HTML 结构。这次,重点关注其嵌套元素,以识别您需要提取的数据。
首先查看标题部分:
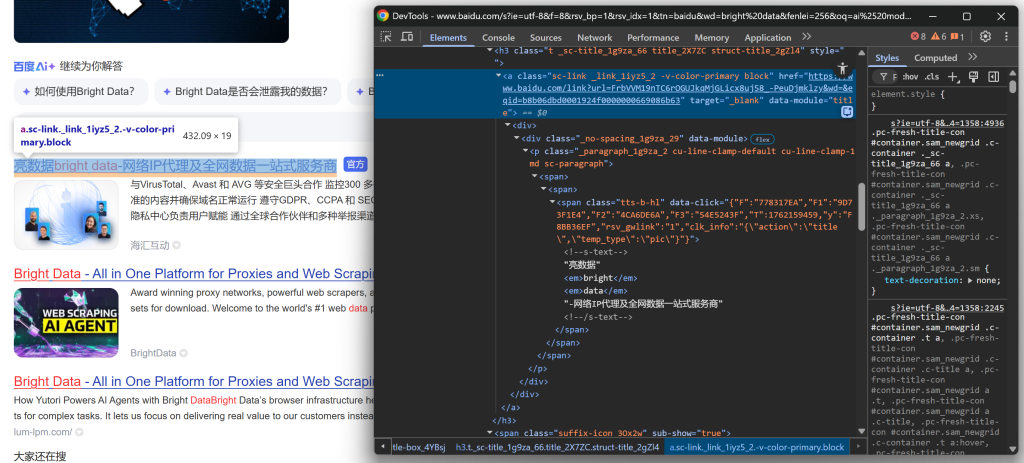
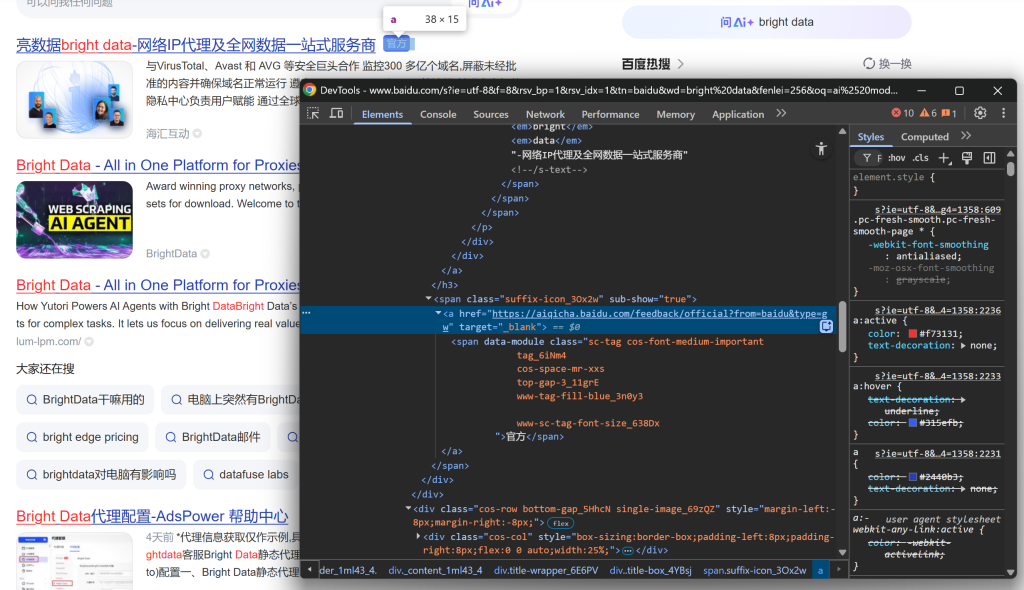
继续观察,会发现部分结果带有“官方”标签:
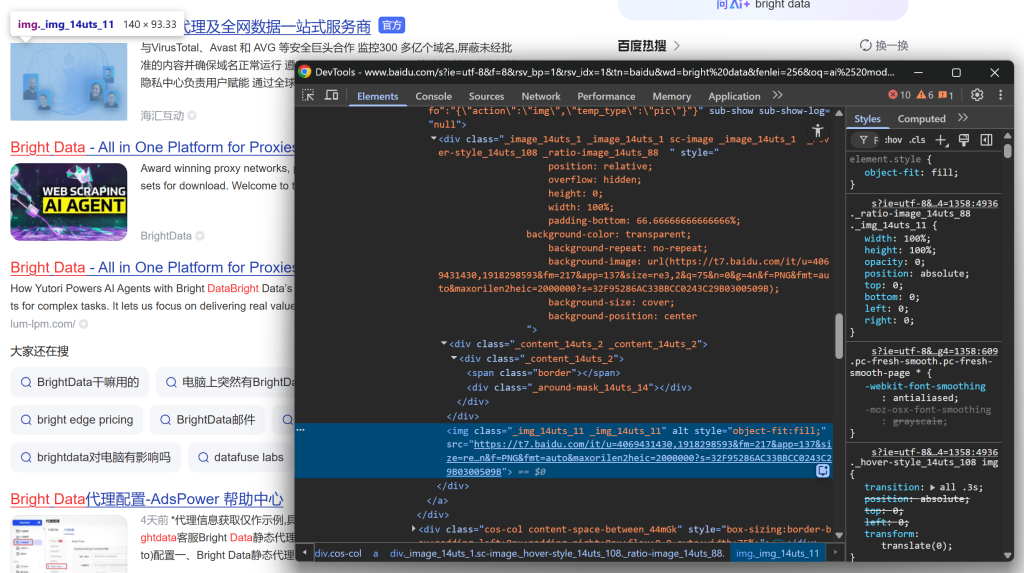
然后聚焦于 SERP 结果图片:
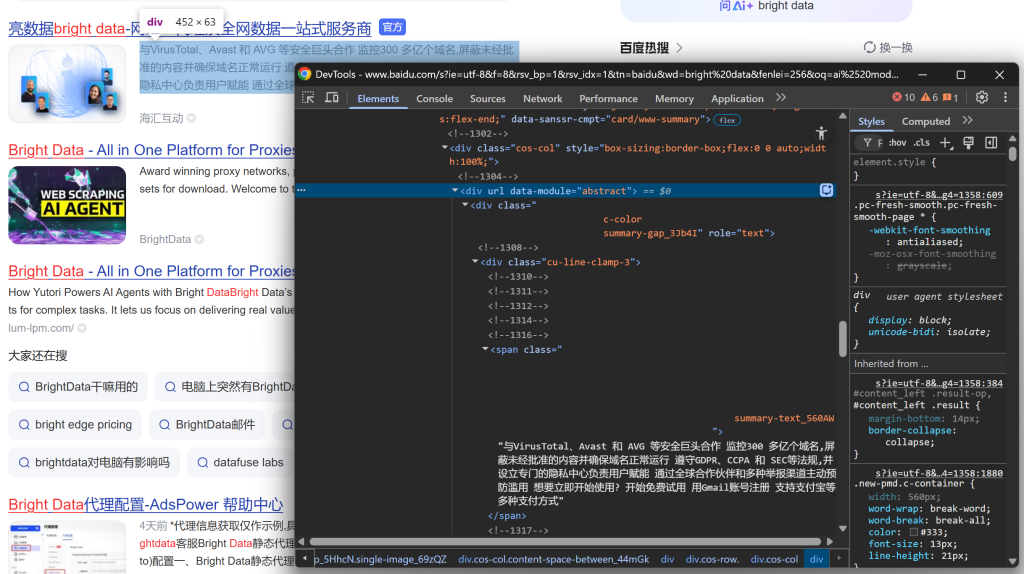
最后查看描述/摘要:
从这些嵌套元素中,您可以提取以下数据:
- 从
.sc-link元素的href属性中提取结果 URL 。 - 从
.sc-link元素的文本内容中提取结果标题。 - 从
[data-module='abstract']文本中提取结果描述/摘要。 - 从
.sc-image内的img元素的src属性中提取结果图片。 - 从
.result__snippet文本中提取结果摘要。 - 官方标签,位于
<a>元素内,其href以https://aiqicha.baidu.com/feedback/official开头(如果存在)。
使用 Playwright 的定位器 API 选择元素并提取所需数据:
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0请记住,并非所有 SERP 项目都是相同的。为防止出错,在访问元素的属性或文本之前,请务必检查元素是否存在(通过 .count() > 0 判断)。
很好!您只需定义百度 SERP 数据解析逻辑即可。
步骤6:收集已抓取的搜索结果数据
通过为每个搜索结果创建字典并将其添加到 serp_results 列表来结束 for 循环:
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
serp_results.append(serp_result)好极了!您的百度网页抓取逻辑现已完成。最后一步是导出已抓取的数据以供后续使用。
步骤7:将抓取的搜索结果导出为 CSV 文件
目前阶段,您的百度搜索结果已存储在 Python 列表中。为使数据可供其他团队或工具使用,使用 Python 内置的 csv 库将其导出为 CSV 文件:
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Dynamically read field names from the first item
fieldnames = list(serp_results[0].keys())
# Initialize the CSV writer
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Write the header and populate the output CSV file
writer.writeheader()
writer.writerows(serp_results)别忘了导入 csv:
import csv这样,您的百度抓取工具将生成一个名为 baidu_serp_results.csv 的输出文件,其中包含所有已抓取结果的 CSV 格式数据。任务完成
步骤8:整合所有代码
scraper.py 中包含的最终代码如下:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import csv
# Where to store the scraped data
serp_results = []
with sync_playwright() as p:
# Initialize a Chromium instance in headless mode
browser = p.chromium.launch(headless=True) # set headless=False to see the browser for debugging
page = browser.new_page()
# The base URL of the Baidu search page
base_url = "https://www.baidu.com/s"
# The search keyword/keyphrase
search_query = "bright data"
params = {"wd": search_query}
# Build the URL of the Baidu SERP
url = f"{base_url}?{urlencode(params)}"
# Visit the target page in the browser
page.goto(url)
# Select all the search result elements
search_result_elements = page.locator(".result")
for search_result_element in search_result_elements.all():
# Data parsing logic
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# Populate a new search result object with the scraped data
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
# Append the scraped Baidu SERP result to the list
serp_results.append(serp_result)
# Close the browser and release its resources
browser.close()
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Dynamically read field names from the first item
fieldnames = list(serp_results[0].keys())
# Initialize the CSV writer
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Write the header and populate the output CSV file
writer.writeheader()
writer.writerows(serp_results)太棒了!仅用大约70行代码,您就成功构建了一个百度数据抓取脚本。
使用以下命令测试脚本:
python scraper.py输出结果将是项目文件夹中的一个 baidu_serp_results.csv 文件。打开它,查看从百度搜索结果中提取的结构化数据:

注意:若要抓取更多结果,请使用 pn 查询参数处理分页,重复执行此过程。
大功告成!您已成功将非结构化的百度搜索结果转换为结构化的 CSV 文件。
[扩展] 使用远程浏览器服务避免被封禁
上面所示的抓取工具在小规模运行时表现良好,但扩展性不佳。当百度检测到来自同一 IP 的流量过大时,会开始拦截请求,返回错误页面或验证挑战。运行多个本地 Chromium 实例也会消耗大量资源(占用大量内存),且难以协调管理。
一个更可扩展且易于管理的解决方案是将您的 Playwright 实例连接到远程浏览器即服务抓取方案,例如 Bright Data 的 Browser API。这提供了自动代理轮换、验证码处理及反爬虫绕过、用于避免指纹识别问题的真实浏览器实例,还支持无限扩展。
按照 Bright Data Browser API 设置指南操作后,您将获得一个如下所示的 WSS 连接字符串:
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222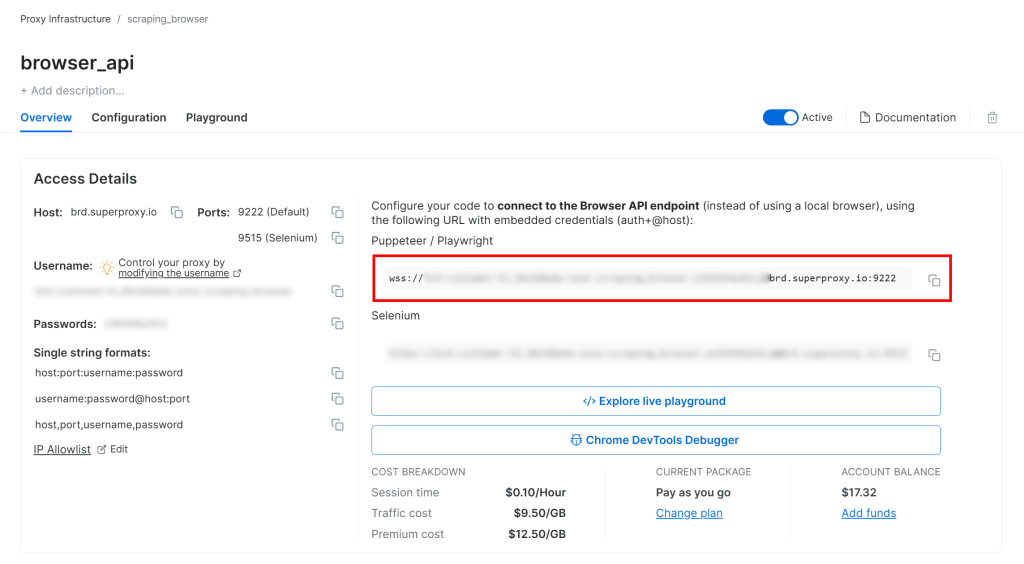
使用该 WSS URL 通过 CDP(Chrome 开发者工具协议)将 Playwright 连接到远程浏览器实例:
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
browser = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...现在,您的 Playwright 向百度发出的请求将通过 Bright Data 的 Browser API 远程基础设施进行路由,该设施由拥有1.5 亿 IP 的住宅代理网络和真实浏览器实例提供支持。这样一来,每次会话都能获得全新的 IP 地址,并模拟出真实的浏览器指纹特征。
方法2:使用 Bright Data 的 SERP API
在本章中,您将了解如何使用 Bright Data 的一站式百度 SERP API 以编程方式检索搜索结果。
注意:为简单起见,我们假设您已经有一个安装了 requests 库的 Python 项目。
步骤1:在您的 Bright Data 账户中设置 SERP API 区域
先在 Bright Data 平台中设置 SERP API 产品,用于抓取百度搜索结果。首先,创建一个 Bright Data 账户——若已拥有账户,则直接登录。
如需快速完成设置,可以参考 Bright Data 的官方 SERP API“快速入门”指南。否则,请继续执行以下步骤。
登录后,在您的 Bright Data 账户中导航至“代理与抓取”,即可访问产品页面:
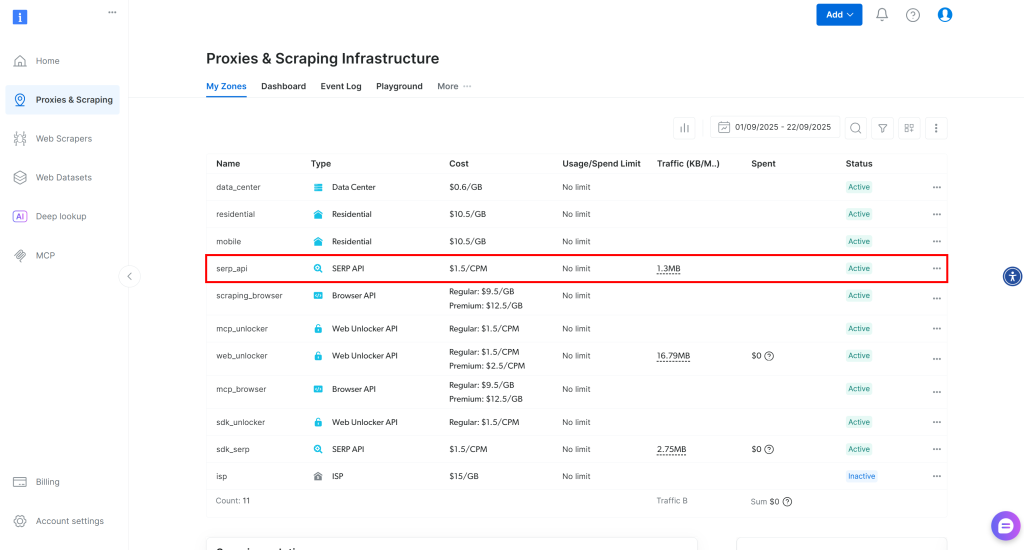
查看“我的区域”表格,其中列出了您已配置的 Bright Data 产品。若已有处于活跃状态的 SERP API 区域,即可开始使用。请直接复制区域名称(例如 serp_api),后续步骤中将需要使用该信息。
如果不存在 SERP API 区域,请向下滚动至“抓取解决方案”部分,并在“SERP API”卡片上点击“创建区域”:
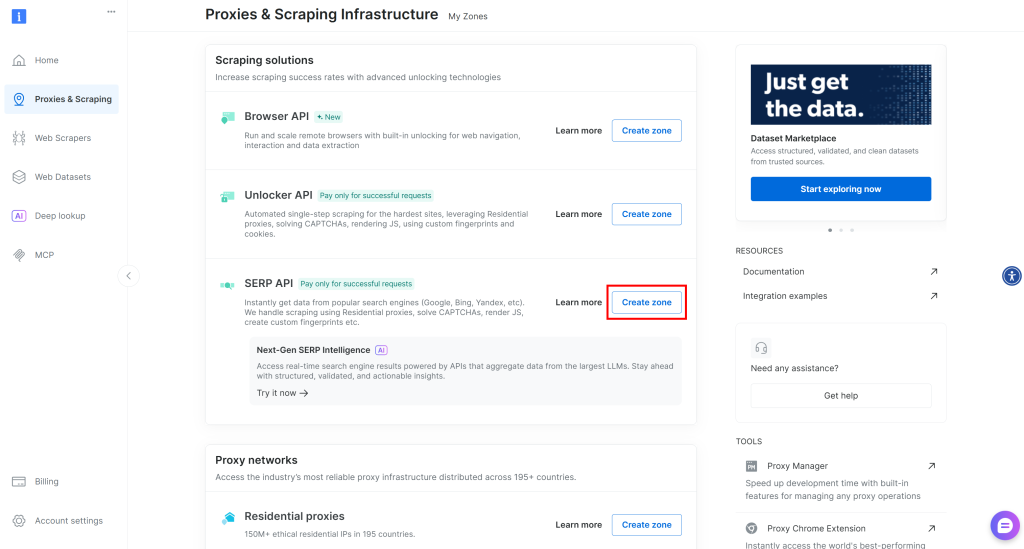
为您的区域命名(例如 serp-api),然后点击“添加”按钮:
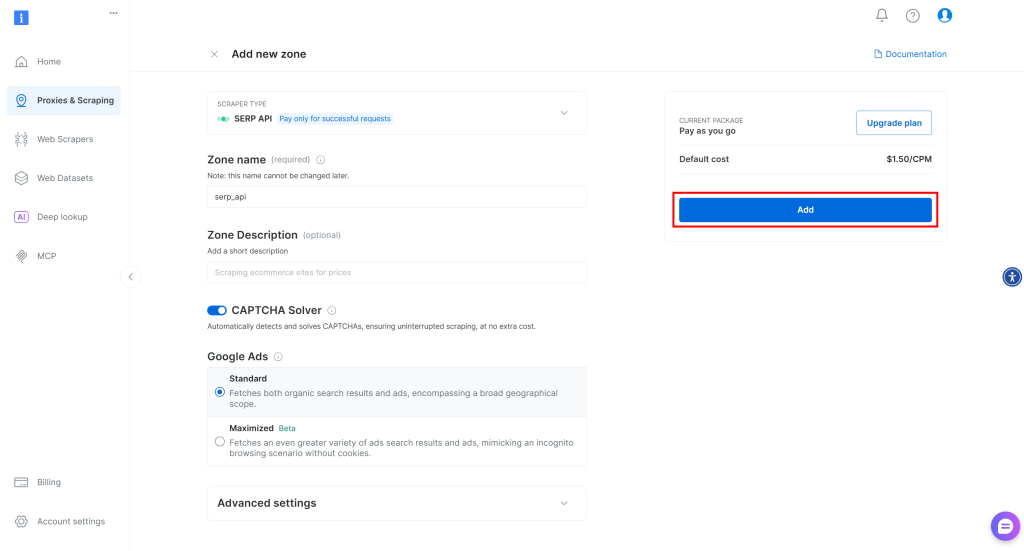
接下来,前往该区域的产品页面,并通过将开关切换至“激活”状态来确保其已启用:
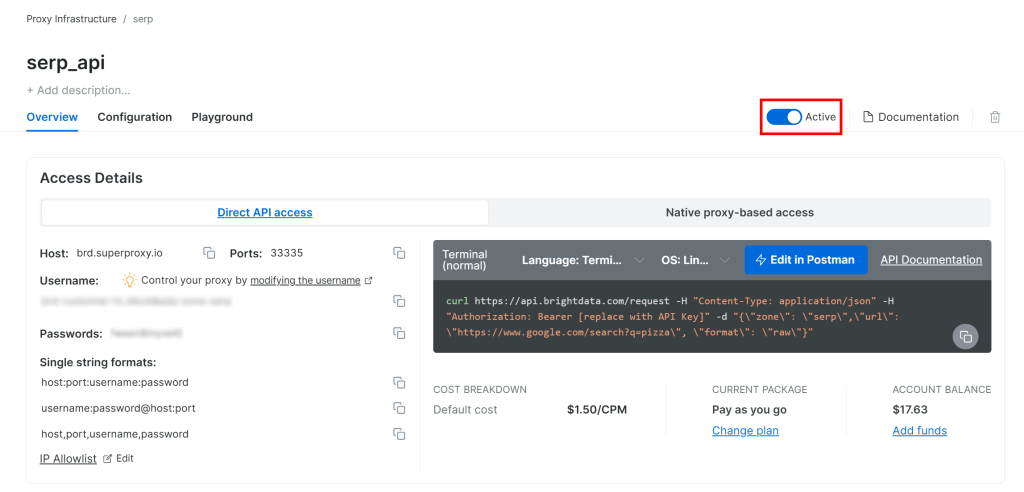
太棒了!您的 Bright Data SERP API 区域现已成功配置并可供使用。
步骤2:获取您的 Bright Data API 密钥
验证 SERP API 请求的推荐方法是使用您的 Bright Data API 密钥。如果您尚未生成 API 密钥,请按照 Bright Data 的官方指南创建您的 API 密钥。
当向 SERP API 发送 POST 请求时,请按如下所示将您的 API 密钥包含在授权头中:
"Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>"太棒了!现在,您已具备通过 Python 脚本(使用 requests 库或其他任何 Python HTTP 客户端)调用 Bright Data SERP API 所需的全部条件。
现在,让我们将所有步骤整合起来!
步骤3:调用 SERP API
在 Python 中使用 Bright Data SERP API 检索关键词“bright data”的百度搜索结果:
# pip install requests
import requests
from urllib.parse import urlencode
# Bright Data credentials (TODO: replace with your values)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>" # (e.g, "serp_api")
# Base URL of the Baidu search page
base_url = "https://www.baidu.com/s"
# Search keyword/keyphrase
search_query = "bright data"
params = {"wd": search_query}
# Build the Baidu SERP URL
url = f"{base_url}?{urlencode(params)}"
# Send a POST request to Bright Data's SERP API
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zone": bright_data_serp_api_zone_name,
"url": url,
"format": "raw"
}
)
# Retrieve the fully rendered HTML
html = response.text
# Parsing logic goes here...如需更多示例,可查看 GitHub 上的“Bright Data SERP API Python 项目”。
Bright Data SERP API 能够处理 JavaScript 渲染、集成代理网络实现自动 IP 轮换,并有效管理各类反爬虫措施,包括浏览器指纹识别、验证码等。这意味着,您不会遇到通常在使用 requests 这类基础 HTTP 客户端抓取百度数据时会弹出的“网络不给力,请稍后重试”错误页面。
简而言之,html 变量中包含已完成渲染的百度搜索结果页面。可通过以下命令打印 HTML 进行验证:
print(html)您将得到类似以下的输出结果:
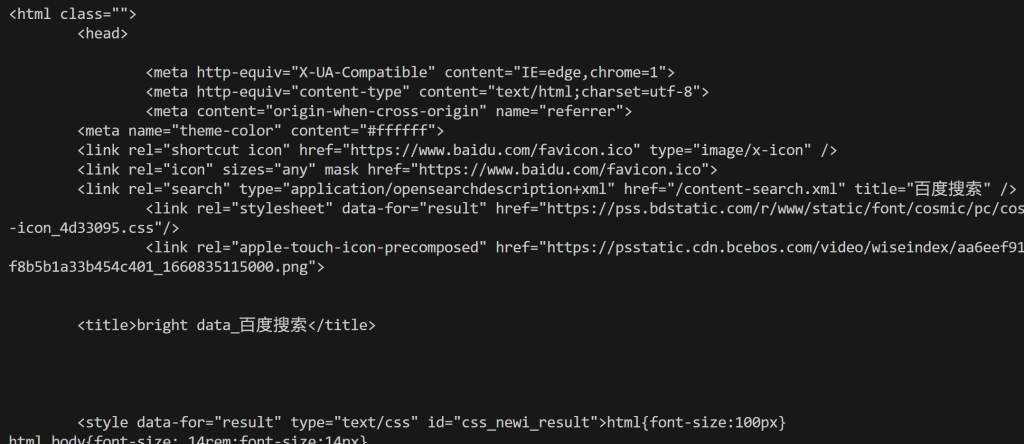
至此,您可以按照第一种方法所示解析该 HTML,提取所需的百度搜索数据。正如承诺的那样,Bright Data SERP API 可防止被封禁,助您实现无限扩展!
方法3:集成 Web MCP 服务器
请记住,SERP API(以及许多其他 Bright Data 产品)也可通过 Bright Data Web MCP 中的 search_engine 工具进行访问。
这款开源的 Web MCP 服务器为 AI 应用提供了便捷的 Bright Data 网络数据检索解决方案,包含百度数据抓取功能。具体来说,Web MCP 免费层级提供 search_engine 和 scrape_as_markdown 工具,支持您在 AI 智能体中零成本使用这些功能。
要将 Web MCP 集成至您的 AI 解决方案中,只需在本地安装 Node.js 并创建如下配置文件:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}例如,该配置方案可兼容 Claude Desktop 与 Claude Code(以及众多其他 AI 库与解决方案)。在文档中探索其他集成。
或者,您也可以通过 Bright Data 远程服务器进行连接,无需满足任何本地环境要求。
通过此集成方案,您 AI 驱动的工作流或智能体将能自主获取百度(及其他支持的搜索引擎)的 SERP 数据,并实时处理这些信息。
结语
在本教程中,您探索了三种推荐的百度数据抓取方法:
- 使用自定义抓取工具。
- 利用百度 SERP API。
- 通过 Bright Data Web MCP。
如演示所示,使用结构化数据抓取解决方案是在大规模抓取百度数据时避免被封禁的最可靠方法。这种方法必须依托先进的反爬绕过技术和稳定可靠的代理网络(例如 Bright Data 的产品)作为支撑。
立即创建免费的 Bright Data 账户,开始探索我们的抓取解决方案吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


