

在本文中,您将了解到
- 谷歌人工智能概述是什么?
- 它是如何工作的,以及为什么抓取它会很有价值。
- 如何通过分步教程搜索 Google AI 概览。
- 所面临的挑战以及如何克服这些挑战。
让我们深入了解一下!
什么是谷歌人工智能概述?
谷歌人工智能概述是集成到谷歌搜索中的一项功能,可在搜索结果顶部提供人工智能生成的摘要。在幕后,它由谷歌的双子座大型语言模型提供支持。
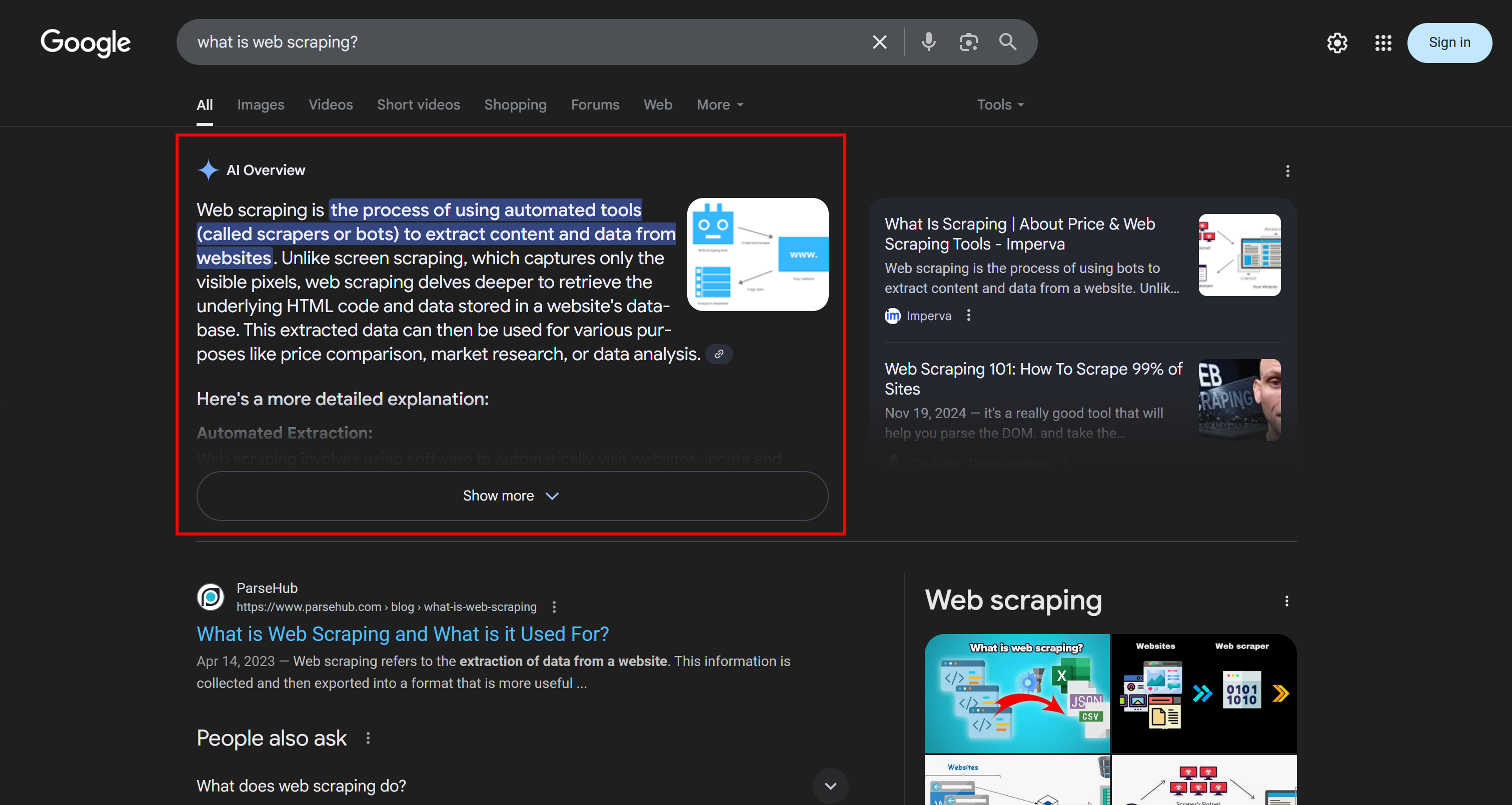
这些概述综合了多个网络来源的信息,为用户的查询提供了简明的答案。它们通常包含原始文章的链接,帮助用户深入了解。
截至 2026 年 5 月,人工智能概述现已在 200 多个国家和地区以及 40 多种语言中提供。该功能最初只在美国提供。
为什么要抓取谷歌人工智能概述?
谷歌人工智能概述响应不仅仅是 Gemini 或任何其他人工智能提供商可以生成的一般响应。其关键区别在于,它们植根于 SERP(搜索引擎结果页面)链接和这些链接中的内容。
换句话说,他们的内容有现实世界的文章、网页和网站作为支持,通常还包括进一步阅读和扩展的链接。这是法学硕士通常难以做到的。
因此,通过对谷歌人工智能概述进行程序化抓取,您可以建立一种人工智能驱动的 SERP 聊天机器人,利用实际的 SERP 结果生成RAG 优化的回复。这样做的目的是获得基于当前可验证网络内容的答案。
正如您在本文结尾将了解到的,虽然这种方法肯定很有趣,但也存在一些固有的挑战。因此,您可以考虑参考我们的指南,了解如何通过 RAG 构建 SERP 聊天机器人。
如何用 Python 抓取 Google AI 概览:分步指南
在本教程中,我们将指导您完成 Google AI 概览的搜索过程。您将学习如何构建一个 Python 脚本,以便:
- 连接至 Google。
- 执行搜索查询。
- 等待载入人工智能概述。
- 从中抓取 HTML。
- 将内容转换为 Markdown。
- 将其导出到输出文件
请按照以下步骤查看如何执行 Google AI 概览搜索!
步骤 #1:项目设置
在开始之前,请确保您的计算机上安装了 Python 3。如果没有,请下载并按照安装向导进行操作。
打开终端并运行以下命令:
mkdir google-ai-overview-scraper
cd google-ai-overview-scraper
python -m venv venv这将为你的 scraper 项目创建一个新文件夹google-ai-overview-scraper/,并初始化虚拟环境。
在您最喜欢的 Python IDE 中加载项目文件夹。PyCharm Community Edition或带有 Python 扩展的 Visual Studio Code是两个不错的选择。
在项目文件夹中创建scraper.py文件:
google-ai-overview-scraper/
├── venv/ # Your Python virtual environment
└── scraper.py # Your scraping scriptscraper.py现在是一个空白脚本,但很快就会包含搜索逻辑。
在集成开发环境的终端中,激活虚拟环境。在 Linux 或 macOS 中,执行此命令:
source ./venv/bin/activate或者,在 Windows 上执行
venv/Scripts/activate太好了!现在你已经为你的抓取项目建立了一个干净的 Python 环境。
步骤 #2:安装 Playwright
谷歌是一个动态平台,随着最近的更新,它现在需要执行 JavaScript 才能完全加载大多数页面。此外,手动制作一个有效的谷歌搜索 URL 也很麻烦。因此,与谷歌搜索交互的最佳方式是在浏览器中模拟用户行为。
换句话说,要抓取 “人工智能概述 “部分,你需要一个浏览器自动化工具。这样,您就可以启动一个真正的浏览器,加载网页,并以编程方式与之交互–就像用户一样。
Playwright 是 Python 的最佳浏览器自动化工具之一。在激活的 Python 虚拟环境中,通过playwrightpip 软件包安装Playwright:
pip install playwright现在,完成 Playwright 的安装:
python -m playwright install该命令将下载 Playwright 控制网络浏览器所需的浏览器可执行文件和其他组件。
有关使用该工具的更多详情,请阅读我们的Playwright 网络搜索指南。
太棒了!现在您已经准备好一切,可以开始从 Google 搜索人工智能概述部分了。
步骤#3:浏览谷歌主页
打开scraper.py文件,导入 Playwright 并在无头模式下初始化一个Chromium 实例:
import asyncio
from playwright.async_api import async_playwright
async def run():
async with async_playwright() as p:
# Start a new Chromium instance
browser = await p.chromium.launch(headless=True) # Set to False while developing
context = await browser.new_context()
page = await context.new_page()该代码段创建了一个 Playwright页面实例,允许你以编程方式控制浏览器标签页。设置headless=True 会在后台运行浏览器,而不显示图形用户界面。如果您正在开发或想要调试,请设置headless=False,以便观察脚本运行时的情况。
由于async_playwright以异步方式运行,因此脚本必须使用 Python 的asyncio模块。
免责声明:需要注意的是,Google AI 概览的新功能通常首先在美国推出。为了获得更准确的结果,您可能需要将您的设备地理定位到美国的某个城市。您可以通过将 Playwright 与网页代理集成来实现这一点。具体来说,您可查看我们的美国代理选项。
从现在起,我们将假定您在美国境内开展业务。
现在,使用 Playwright 的goto()方法打开 Google 主页:
await page.goto("https://google.com/")请务必记住在脚本结束时关闭浏览器以清理资源:
await browser.close()把这一切放在一起,你就会得到:
import asyncio
from playwright.async_api import async_playwright
async def run():
async with async_playwright() as p:
# Start a new Chromium instance
browser = await p.chromium.launch(headless=True) # Set to False while developing
context = await browser.new_context()
page = await context.new_page()
# Navigate to Google
await page.goto("https://google.com/")
# scraping logic goes here ...
# Close the browser and free resources
await browser.close()
asyncio.run(run())太棒了你已经准备好像 Google 一样抓取动态网站了。
步骤 #4:提交搜索表
在浏览器中打开 Google 主页。右键单击搜索栏,选择 “检查”,打开浏览器的 “开发工具”:
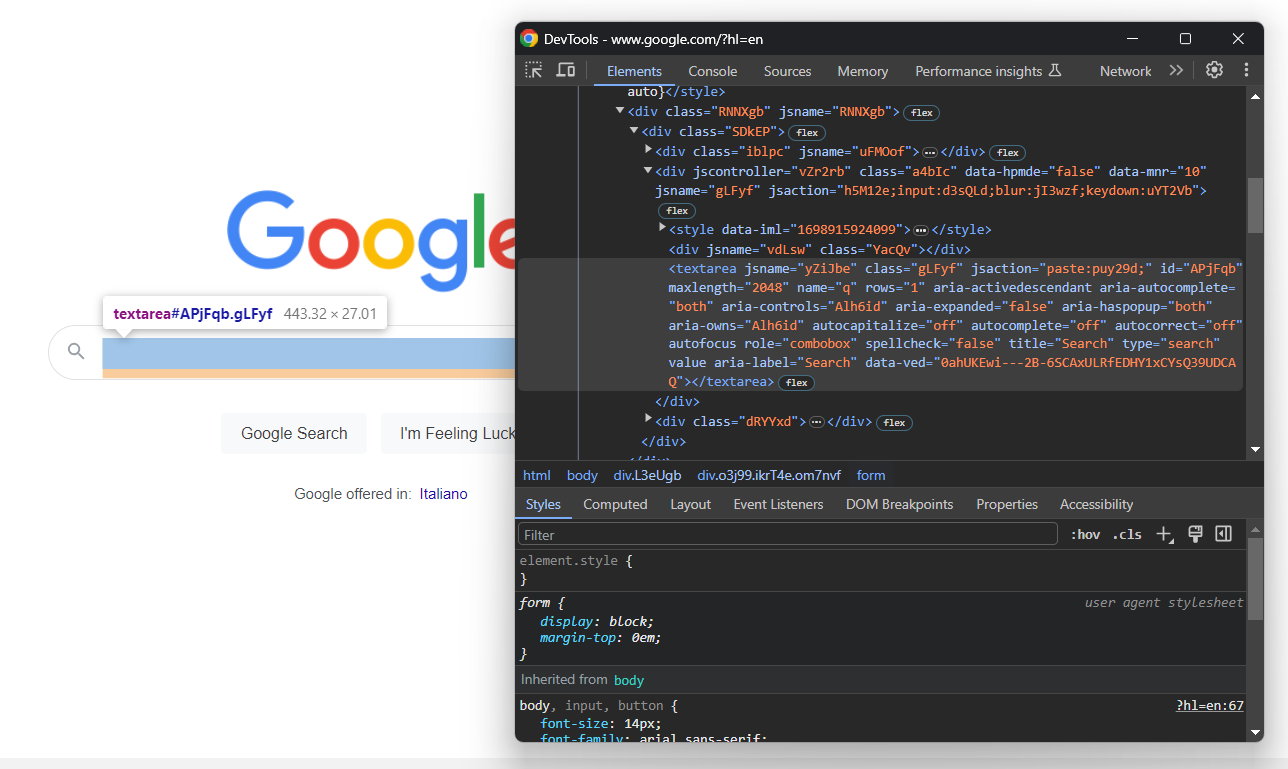
Google 的 HTML 结构通常使用动态生成的类和属性,而这些类和属性在每次部署时都可能发生变化。这就使得它们在抓取时不可靠,因为你的选择器会随着时间的推移而损坏。
取而代之的是稳定的 HTML 属性。例如,搜索文本区域有一个明确的aria-label属性:
textarea[aria-label="Search"]使用fill()方法选择搜索文本框并填写 Google 搜索查询:
await page.fill("textarea[aria-label='Search']", search_query)在本例中,search_query变量的定义如下:
search_query = "What is web scraping?"请注意,使用问题式查询是促使谷歌生成人工智能概述部分的好方法。这一点很重要,因为搜索结果页面并不总是包含该部分。请根据您的具体情况调整搜索查询。
然后,模拟按 Enter 键触发搜索:
await page.keyboard.press("Enter")如果以无头模式(headless=False)运行脚本,并在page.close()行设置断点,就会看到下面的内容:
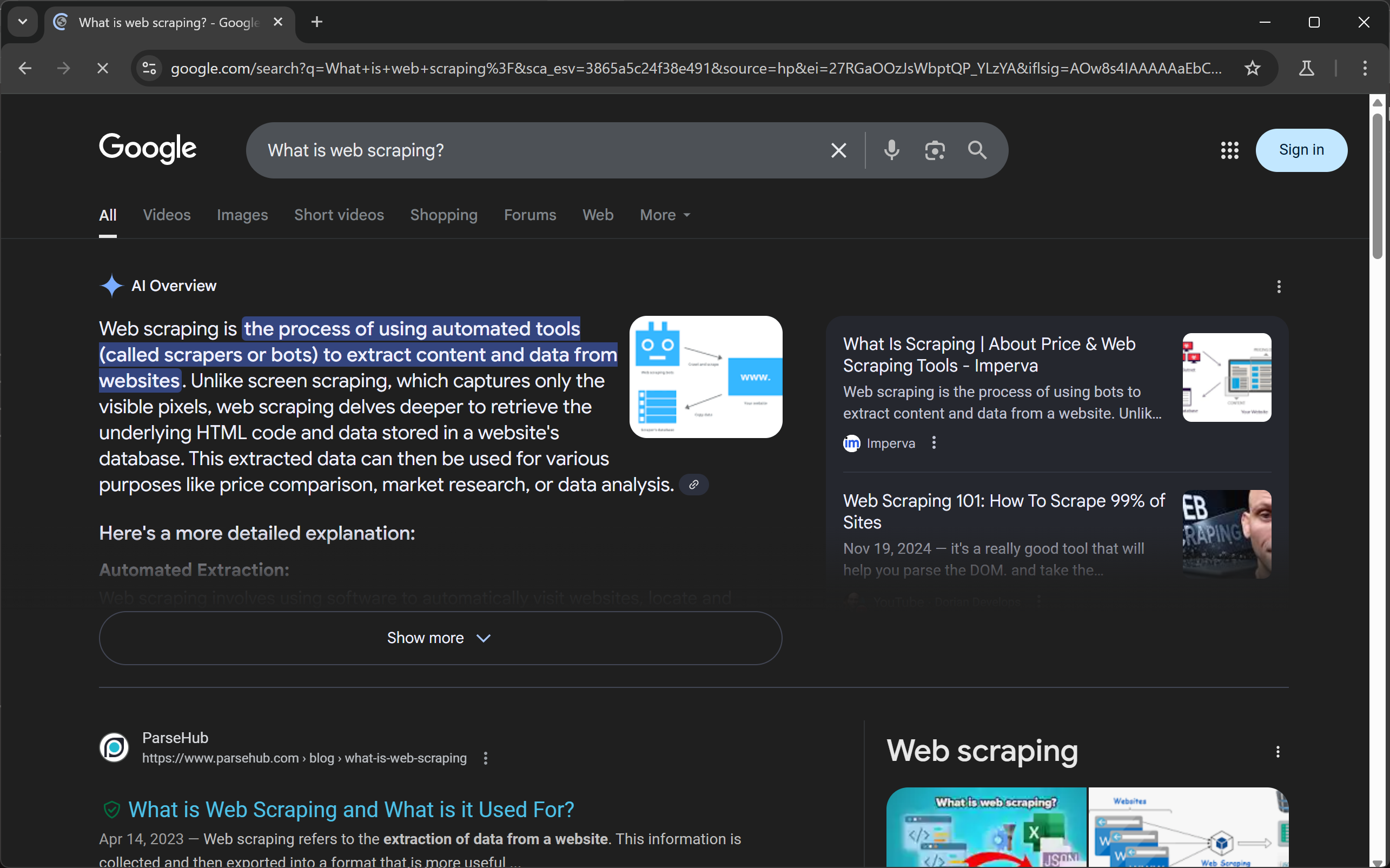
注意结果页面顶部的 “人工智能概述 “部分。如果没有显示,请尝试使用不同的、更类似于问题的查询重新运行脚本。太神奇了
步骤 #5:抓取谷歌人工智能概述部分
如果探索一下谷歌人工智能概述功能的工作原理,你会发现有三种情况是可能发生的:
- 缓存响应:人工智能概述片段已缓存并立即显示。
- 实时生成:人工智能概述是动态生成的,在谷歌处理查询时会有短暂延迟。
- 没有人工智能概述:Google 完全不显示人工智能概述部分。
在本节中,我们将重点讨论情景 2,即即时生成人工智能概述。这是最棘手的情况,同时也涵盖了方案 1。
要触发它,请尝试使用新的或不太常见的问题式查询。例如
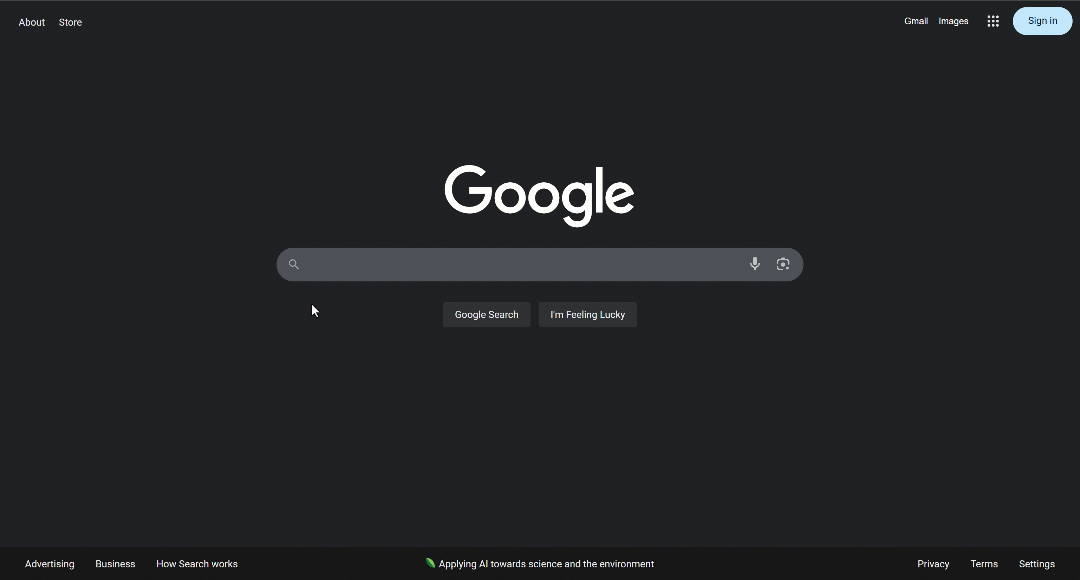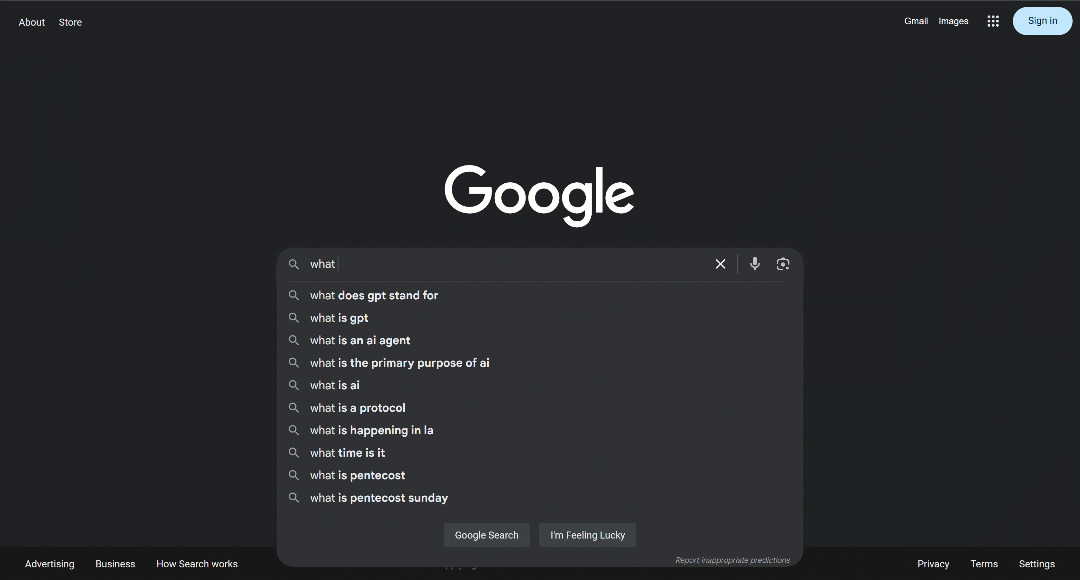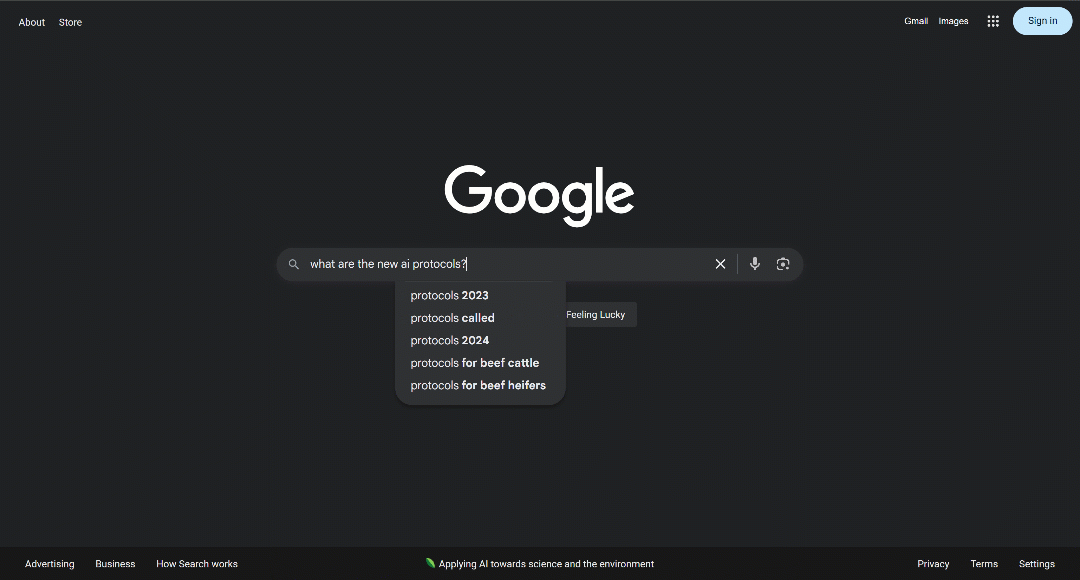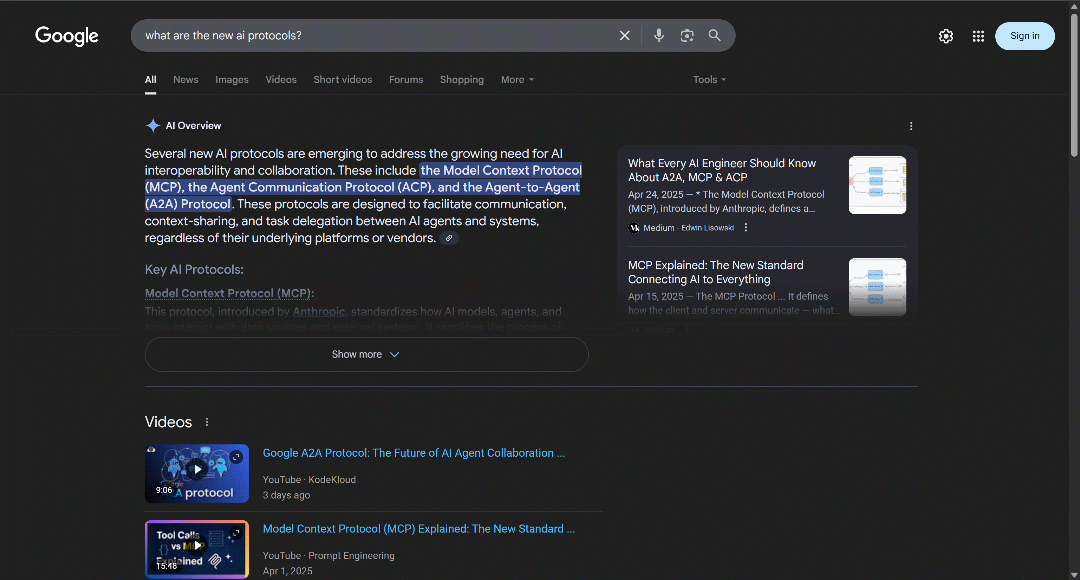
如上图所示,”人工智能概述 “部分会在几毫秒的处理后出现。具体来说,只有当标题元素包含 “人工智能概述 “文本时,才可认为该部分已准备就绪。
因此,请检查包含 AI 概述标题的元素:
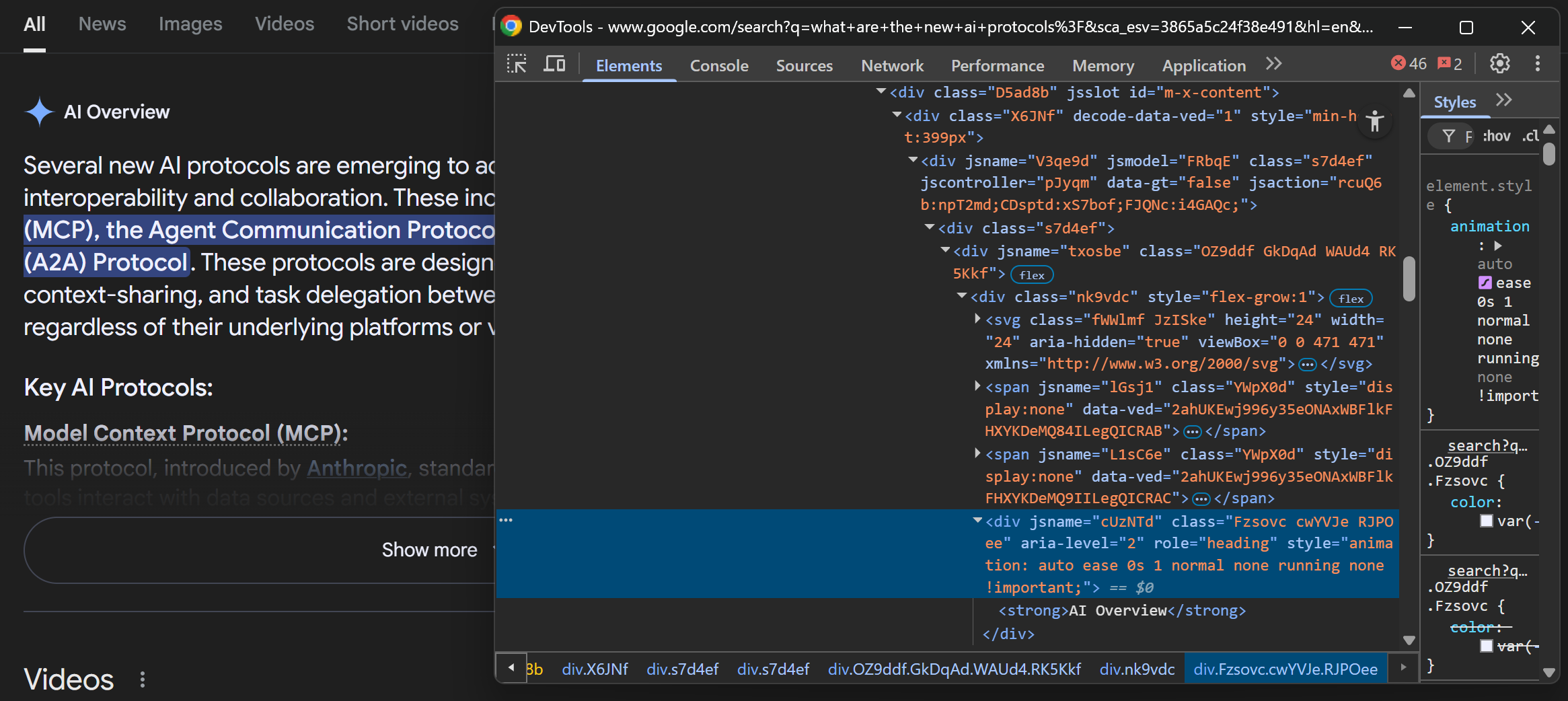
您可以使用以下 CSS 选择器选择标题:
div[jsname][role="heading"] strong为确保 AI 概述部分的存在,请等待该元素出现并包含正确的文本:
await page.locator(
"div[jsname][role='heading'] strong", has_text="ai overview"
).first.wait_for(timeout=30000)这会等待页面上带有 “ai 概述”(不区分大小写)文本的元素出现长达 30 秒(30000 毫秒)。
现在您可以确定人工智能概述部分已经加载,准备对其进行抓取。在大多数情况下,部分内容最初会隐藏在 “显示更多 “按钮后面:
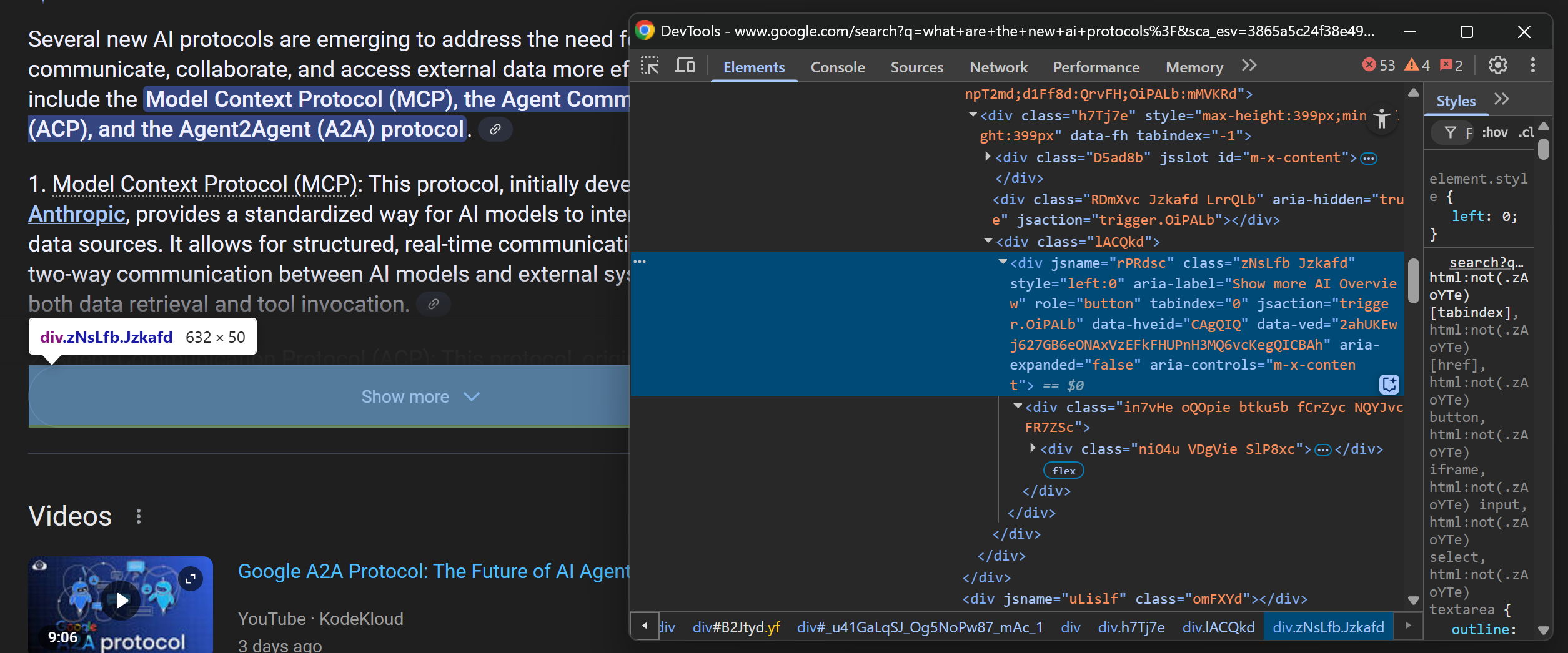
要抓取完整的回复,请检查是否有 “显示更多 “按钮,然后点击它:
try:
# Clicking the "Show more" button if it is present on the page
ai_overview_show_more_button = page.locator("div[aria-label='Show more AI Overview']").first
await ai_overview_show_more_button.click()
except PlaywrightTimeoutError:
print("'Show more' button not present")不要忘记导入PlaywrightTimeoutError,当locator()函数没有找到指定元素时,就会触发它:
from playwright.async_api import TimeoutError as PlaywrightTimeoutError一旦整个部分可见,检查 HTML 结构以确定如何选择它:
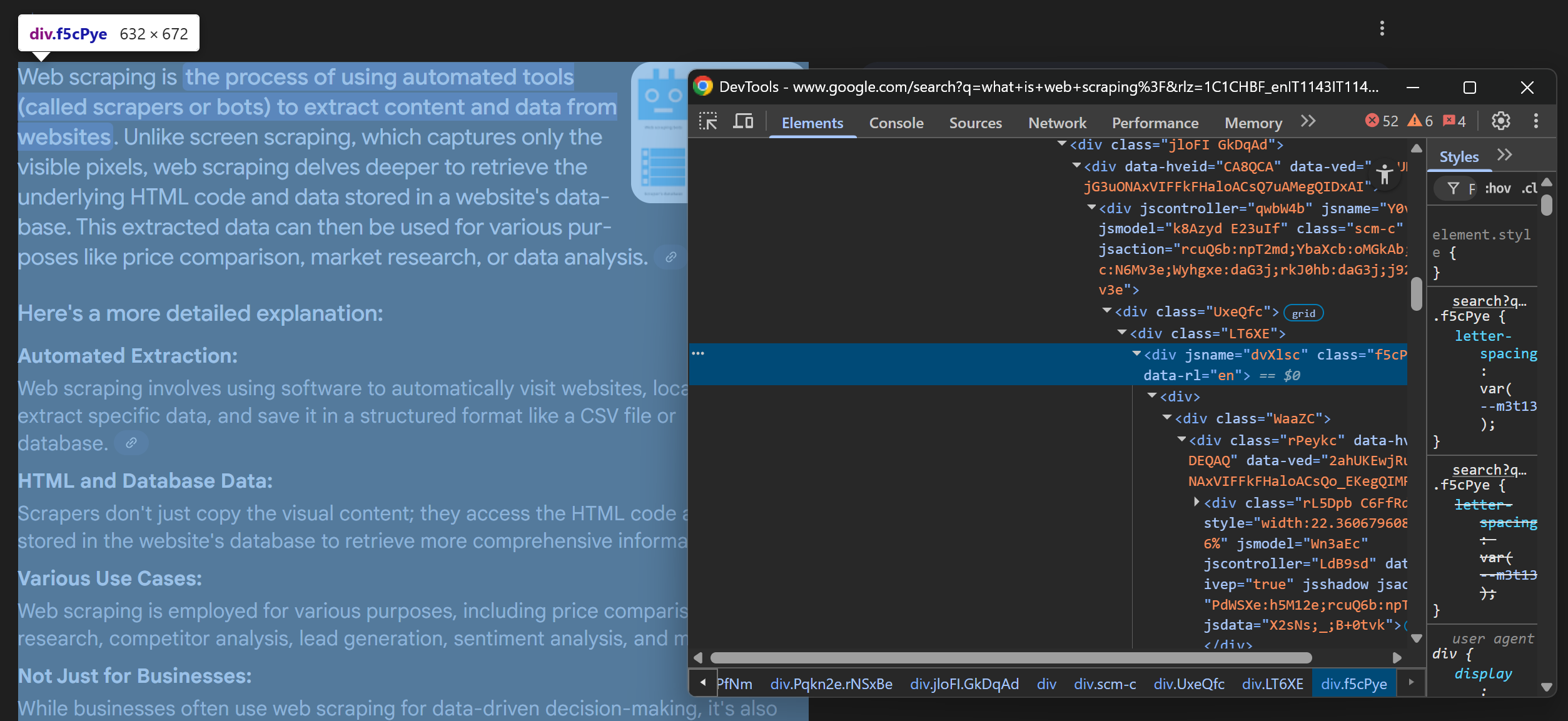
可以看出,AI 概述的主要内容可以通过 CSS 选择器来选择:
div[jsname][data-rl] div使用以下代码定位元素并提取其 HTML 代码:
ai_overview_element = page.locator("div[jsname][data-rl] div").first
ai_overview_html = await ai_overview_element.evaluate("el => el.outerHTML")如果你想知道为什么我们要提取 HTML 而不只是文本,请继续阅读。
开始了!您已成功搜索到 Google AI 概述部分。
第 6 步:将 Google AI 概述 HTML 转换为 Markdown
说到网络抓取,最常见的目标是从元素中提取文本,而不是完整的 HTML。然而,在大多数情况下,谷歌人工智能概述部分中人工智能生成的内容并不是纯文本。
相反,它可以包括要点、链接、小标题甚至图片。如果将这些内容视为纯文本,就会抹去所有的结构和上下文,而这些都是您需要保留的宝贵信息。
因此,更好的办法是将人工智能概述视为原始 HTML,然后将其转换为 Markdown,这是人工智能应用程序的理想格式。
要将 HTML 转换为 Markdown,请在激活的环境中安装Markdownify:
pip install markdownify导入:
from markdownify import markdownify as md并利用它将 HTML 数据转换为 Markdown 数据:
ai_overview_markdown = md(ai_overview_html)太好了!剩下的工作就是将刮取的 AI 概览导出为 Markdown 文件。
步骤 #7:导出抓取的数据
使用 Python 标准库打开名为ai_overview.md 的输出文件,并将转换后的 Markdown 内容写入其中:
with open("ai_overview.md", "w", encoding="utf-8") as f:
f.write(ai_overview_markdown)这标志着您的 Google AI 概述搜索之旅即将结束!
步骤 #8:将所有内容整合在一起
现在,scraper.py应该包含
import asyncio
from playwright.async_api import async_playwright
from playwright.async_api import TimeoutError as PlaywrightTimeoutError
from markdownify import markdownify as md
async def run():
async with async_playwright() as p:
# Start a new Chromium instance
browser = await p.chromium.launch(headless=True) # Set to False while developing
context = await browser.new_context()
page = await context.new_page()
# Navigate to Google
await page.goto("https://google.com/")
# Fill out search form
search_query = "What is web scraping?" # Replace it with the search query of interest
await page.fill("textarea[aria-label='Search']", search_query)
await page.keyboard.press("Enter")
# Wait for the AI overview section to be ready
await page.locator(
"div[jsname][role='heading'] strong", has_text="ai overview"
).first.wait_for(timeout=30000)
try:
# Clicking the "Show more" button if it is present on the page
ai_overview_show_more_button = page.locator("div[aria-label='Show more AI Overview']").first
await ai_overview_show_more_button.click()
except PlaywrightTimeoutError:
print("'Show more' button not present")
# Extract the AI overview HTML
ai_overview_element = page.locator("div[jsname][data-rl] div").first
ai_overview_html = await ai_overview_element.evaluate("el => el.outerHTML")
# Convert the HTML to Markdown
ai_overview_markdown = md(ai_overview_html)
# Export the Markdown to a file
with open("ai_overview.md", "w", encoding="utf-8") as f:
f.write(ai_overview_markdown)
# Close the browser and free resources
await browser.close()
asyncio.run(run())哇只用了不到 50 行代码,你就完成了 Google 的人工智能概述部分。
启动上述谷歌人工智能概述扫描仪:
python script.py如果一切按预期进行,项目文件夹中将出现ai_overview.md文件。打开它,你应该会看到类似的内容:
Web scraping is the process of using automated tools (called scrapers or bots) to extract content and data from websites. Unlike screen scraping, which captures only the visible pixels, web scraping delves deeper to retrieve the underlying HTML code and data stored in a website's database. This extracted data can then be used for various purposes like price comparison, market research, or data analysis.
Here's a more detailed explanation:
* **Automated Extraction:**
Web scraping involves using software to automatically visit websites, locate and extract specific data, and save it in a structured format like a CSV file or database.
* **HTML and Database Data:**
Scrapers don't just copy the visual content; they access the HTML code and data stored in the website's database to retrieve more comprehensive information.
* **Various Use Cases:**
Web scraping is employed for various purposes, including price comparison, market research, competitor analysis, lead generation, sentiment analysis, and more.
* **Not Just for Businesses:**
While businesses often use web scraping for data-driven decision-making, it's also valuable for individuals seeking price comparisons, market trends, or general data analysis.
* **Consider Ethical and Legal Implications:**
When web scraping, it's crucial to be aware of the website's terms of service and robots.txt file to ensure you are not violating their policies or engaging in illegal activities. 复制上述 Markdown 内容并粘贴到 Markdown 查看器(如 StackEdit)中:
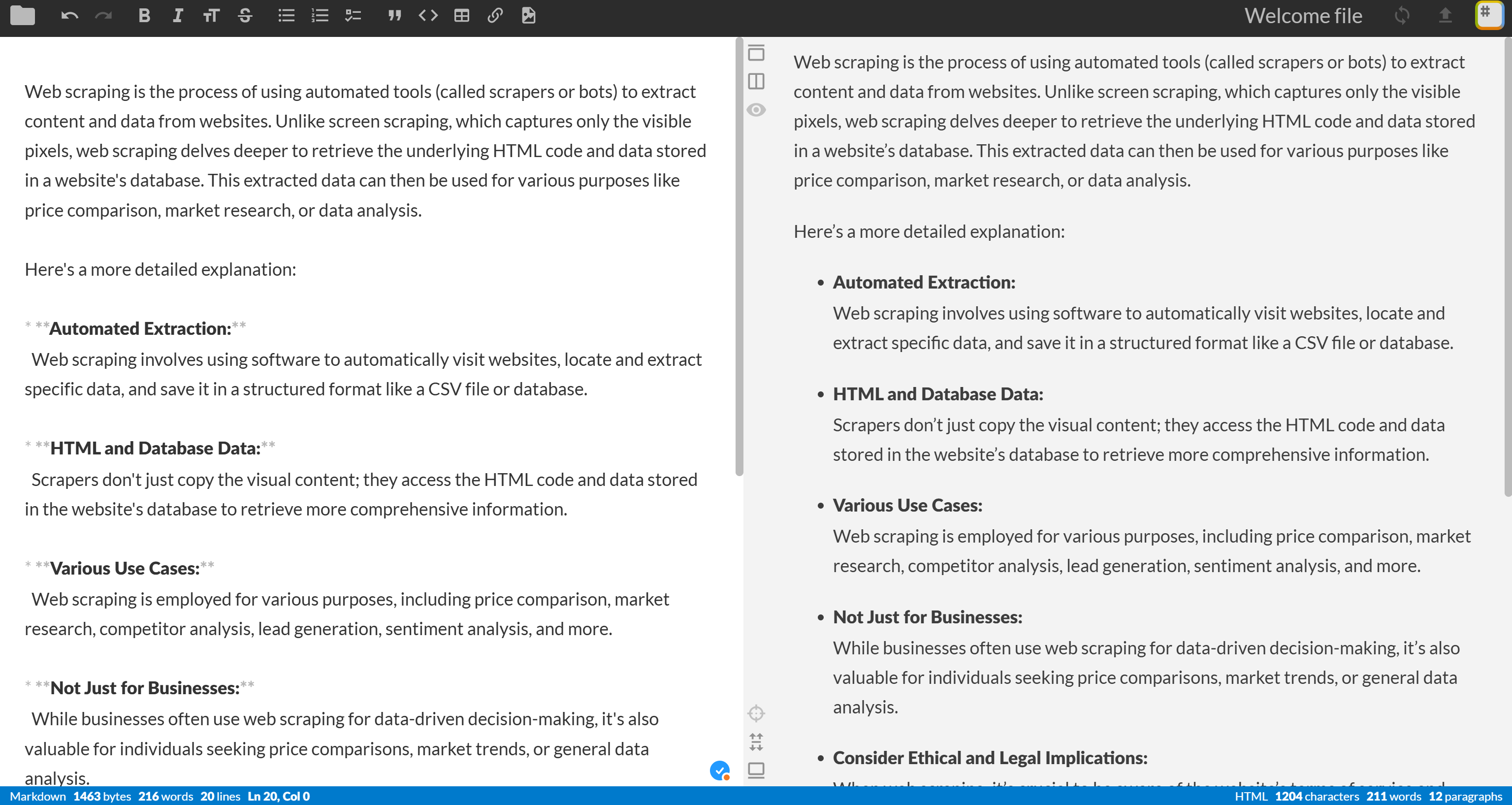
这正是谷歌人工智能概述片段的结构化、易读和信息丰富版本–从原始 HTML 转换为简洁的 Markdown!
好了!任务完成
搜索谷歌人工智能概述的挑战
如果您一直以 “为首 “模式运行脚本,那么在某些时候,您很可能会遇到这个阻塞页面:
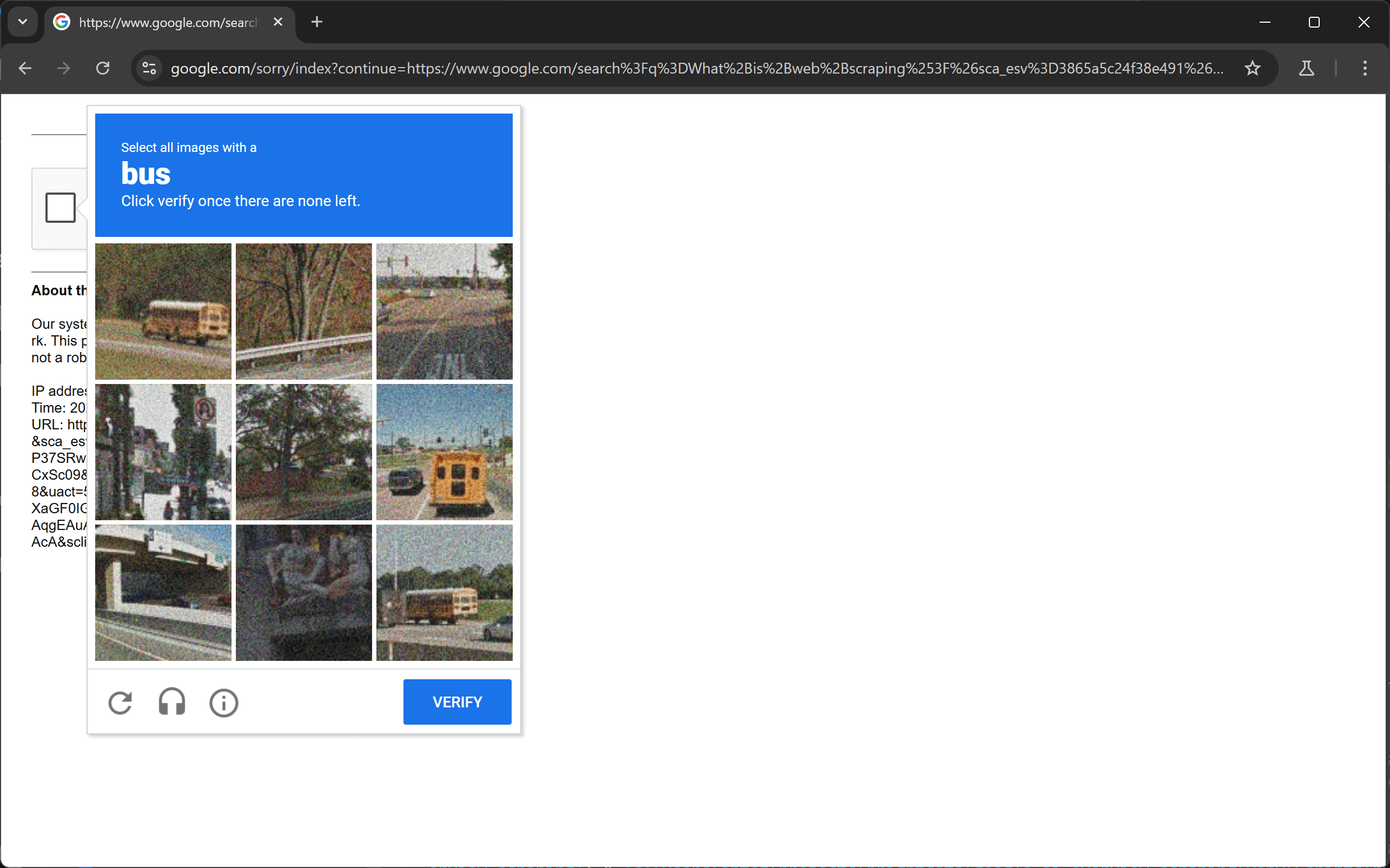
如果自动请求次数过多或使用的 IP 地址可靠度较低,Google 就会将您的活动检测为机器人活动,并通过重新验证码向您提出挑战。
作为一种变通方法,您可以尝试用 Python 绕过验证码。这对较简单的验证码有效,但对较先进或较新的 reCAPTCHA 版本(如reCAPTCHA v3)则经常失败。
在这种情况下,您可能需要高级验证码解决服务。另一种方法是将 Playwright 配置为在 Chromium 以外的浏览器上运行。问题是,默认情况下,Playwright 在 Chromium(或其他任何浏览器)上使用的方式会被 Google 的反僵尸系统检测到。
为避免被发现,您可以将 Playwright 与AI Agent Browser 集成。这是一款与 Playwright 兼容的云浏览器,专门用于代理工作流中的网络搜索和数据检索。
这种方法的优势包括几乎无限的可扩展性和大幅减少验证码挑战。即使出现验证码,Agent Browser 也具有验证码解决功能和代理集成功能,允许您将 Google AI 概览搜索定位到任何国家或语言。
结论
在本教程中,您了解了什么是 Google AI 概述,以及如何从中抓取数据。正如您所看到的,编写一个简单的 Python 脚本来自动检索这些数据只需几行代码。
虽然这种解决方案适用于小型项目,但对于大规模搜索来说并不实用。谷歌使用了业内最先进的反机器人技术,这可能会导致验证码或 IP 禁止。此外,在许多页面上扩展此流程将大大增加基础设施成本。
如果您的人工智能工作流程需要 Google SERP 数据,请考虑使用可直接提供人工智能就绪SERP 数据的 API,如Bright Data 的 SERP API。
创建一个免费的 Bright Data 账户,即可访问我们人工智能数据基础设施中的所有解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


