

大多数网络抓取的数据来自动态网站,亚马逊和油管。这些网站根据用户输入提供交互式和响应式的用户体验。例如,当您访问油管帐户时,网站会根据您的输入呈现个性化的视频内容。因此,从动态网站抓取数据可能更具挑战性,因为数据会因用户交互而持续修改。
要从动态网站抓取数据,你需要使用高级技术,模仿用户与网站的交互,浏览和选择由JavaScript生成的特定内容,并处理异步JavaScript和XML (AJAX)请求。
在本指南中,您将了解如何使用名为Selenium的开源 Python 库抓取动态网站数据。
使用Selenium从动态网站抓取数据
在开始抓取数据之前,您需要了解将要使用的Python包:Selenium。
Selenium是什么?
Selenium是一个开源Python包和自动化测试框架,让您能在动态网站上执行各种操作或任务,包括打开/关闭对话框、在油管上搜索特定关键词或填写表单等。所有这些都可以在您首选的网络浏览器中执行。
当您将Selenium与Python结合使用时,只需使用Selenium Python包编写几行Python代码即可控制网络浏览器并自动从动态网站中提取数据。
现在您已经了解了Selenium的工作原理,我们开始使用吧!
新建一个Python项目
首先,您需要创建一个新的Python项目。创建一个名为data_scraping_project的目录,用于存储采集的所有数据和源代码文件。该目录会有两个子目录:
- 脚本/scripts会包含从动态网站提取和采集数据的所有Python脚本。
- 数据/data存储了从动态网站提取的所有数据。
安装Python软件包
创建data_scraping_project目录后,您需要安装以下Python软件包来帮助您从动态网站中抓取、采集和保存数据:
- Selenium
- Webdriver Manager将管理不同浏览器的二进制驱动程序。Webdriver提供了一组API,可运行不同的命令来与站点交互,从而更轻易地解析、加载和更改内容。
- pandas将从动态网站抓取的数据保存到简单的CSV文件中。
您可以在终端运行以下pip命令来安装Selenium Python软件包:
pip install seleniumSelenium将使用二进制驱动程序来控制您选择的网页浏览器。此Python包为以下受支持的网页浏览器提供二进制驱动程序:Chrome、Chromium、Brave、Firefox、IE、Edge和Opera。
接着在终端中运行以下pip命令来安装webdriver-manager :
pip install webdriver-manager要安装pandas,请运行以下pip命令:
pip install pandas你将抓取什么内容
在本文中,你将会 抓取YouTube 频道,名为 Programming with Mosh 和 Hacker News:
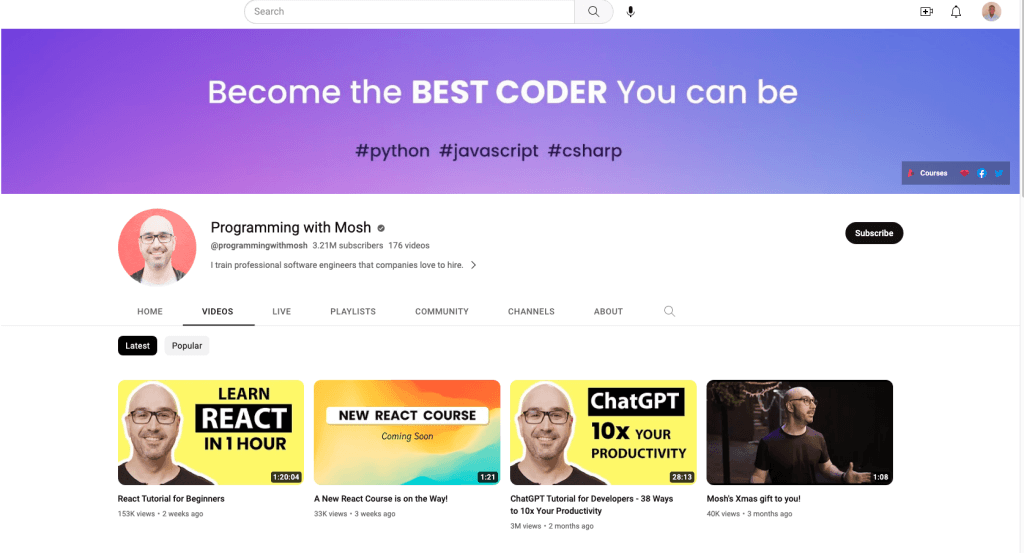
您将从“与Mosh一起编程”油管频道抓取以下信息:
- 视频标题。
- 视频链接或URL。
- 图片链接或URL。
- 特定视频的观看次数。
- 视频发布时间。
- 特定油管视频链接中的评论。
从黑客新闻频道中,您将采集以下数据:
- 文章标题。
- 文章链接。

现在您知道了抓取内容,那我们来创建一个新的Python脚本(即data_scraping_project/scripts/youtube_videos_list.py)。
导入Python包
首先,您需要导入用于抓取、采集数据并将数据保存到CSV文件中的Python包:
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd实例化Webdriver
要实例化Webdriver,您需要选择Selenium 要使用的浏览器(在本例中为谷歌Chrome),然后安装二进制驱动程序。
Chrome浏览器具有开发人员工具,能显示网页的HTML代码并识别 HTML元素以抓取和采集数据。要显示HTML代码,您需要在Chrome网页中单击右键,然后选择检察元素/Inspect Element 。
要安装Chrome的二进制驱动程序,请运行以下代码:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))Chrome的二进制驱动程序将安装在您的计算机上并自动实例化Webdriver。
使用Selenium抓取数据
要使用Selenium抓取数据,您需要在一个简单的Python变量中定义油管YouTube URL(即 网址)。您可以从此链接中采集到前文提到的除了特定YouTube URL评论以外的所有数据:
# Define the URL
url = "https://www.youtube.com/@programmingwithmosh/videos"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)Selenium 会自动在谷歌浏览器中加载YouTube链接。此外,还指定了一个时间范围(即十秒),以确保网页完全加载(包括所有HTML元素)。这有助于您抓取由JavaScript渲染的数据。
用ID和标签抓取数据
Selenium的优势之一是它可以使用网页上呈现的不同元素(包括ID和标签)提取数据。
例如,您可以使用ID元素(即后标题)或标签(即h1和p) 来抓取数据:
<h1 id ="post-title">Introduction to data scrapping using Python</h1>
<p>You can use selenium python package to collect data from any dynamic website</p>或者,如果您想从YouTube链接中抓取数据,需要使用网页上显示的ID。在网络浏览器中打开YouTube链接,然后右键单击并选择“检查”以识别 ID。接着使用鼠标查看页面,识别保存了频道上呈现的视频列表的 ID:
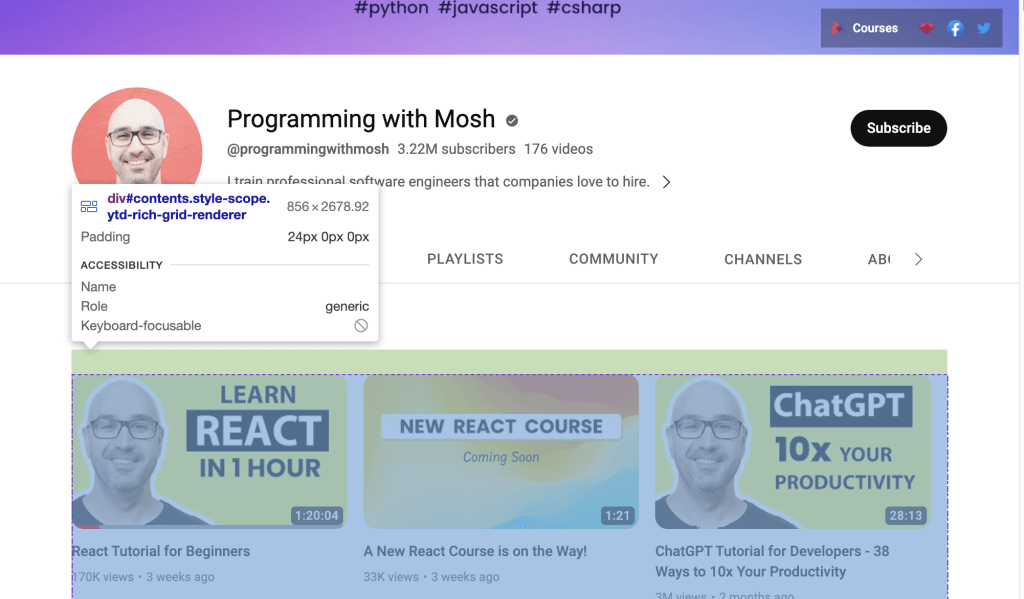
使用Webdriver抓取在所识别ID内的数据。要根据ID属性查找HTML元素,请调用Selenium的find_element()方法并将By.ID作为第一个参数,将ID作为第二个参数。
要采集每个视频的标题和链接,您需要使用video-title-link ID属性。由于您要使用此ID属性采集多个HTML元素,因此需要使用find_elements()方法:
# collect data that are withing the id of contents
contents = driver.find_element(By.ID, "contents")
#1 Get all the by video tite link using id video-title-link
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 collect title and link for each youtube video
titles = []
links = []
for video in video_elements:
#3 Extract the video title
video_title = video.get_attribute("title")
#4 append the video title
titles.append(video_title)
#5 Extract the video link
video_link = video.get_attribute("href")
#6 append the video link
links.append(video_link)此代码执行以下任务:
- 采集在内容contents yID属性内的数据。
- 从WebElement内容对象中采集元素具有video-title-link ID属性的所有HTML元素。
- 创建两个列表来附加标题和链接。
- 使用get_attribute()方法提取视频标题并传递标题。
- 将视频标题附加到标题列表中。
- 使用get_atribute()方法提取视频链接并将href作为参数传递。
- 它将视频链接附加到链接列表中。
此时,所有视频标题和链接将位于两个Python列表中:标题titles和链接links。
接下来,您需要先抓取网页上可用图片的链接,再单击YouTube视频链接观看视频。要抓取此图片链接,您需要调用 find_elements () Selenium来查找所有 HTML 元素,并将By.TAG_NAME作为第一个参数,将标签名称作为第二个参数:
#1 Get all the by Tag
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 collect img link and link for each youtube video
img_links = []
for img in img_elements:
#3 Extract the img link
img_link = img.get_attribute("src")
if img_link:
#4 append the img link
img_links.append(img_link)此代码从名为contents的WebElement对象中采集带有img标签名称的所有HTML元素。它还创建了一个列表来附加图片链接,并使用get_attribute()方法提取链接,并将src作为参数传递。最后,此代码将图片链接附加到img_links列表中。
您还可以使用ID和标签名称为每个YouTube视频抓取更多数据。在YouTube URL的网页上,您应该能够看到页面上列出每个视频的观看次数和发布时间。要提取这些数据,您需要采集所有具有metadata-line ID的HTML元素,然后从具有span标签名称的HTML元素中采集数据:
#1 find the element with the specific ID you want to scrape
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 collect data from span tag
meta_data = []
for element in meta_data_elements:
#3 collect span HTML element
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 collect span data
span_data = []
for span in span_tags:
#5 extract data for each span HMTL element.
span_data.append(span.text)
#6 append span data to the list
meta_data.append(span_data)
# print out the scraped data.
print(meta_data)此代码块从WebElement内容对象中采集ID属性为metadata-line的所有HTML元素,并创建列表以附加来自span标签的数据,包含浏览量和发布时间。
代码块还从名为meta_data_elements的WebElement 对象中采集标签名称为span的所有HTML 元素,并创建一个包含此span数据的列表。然后,它从span HTML元素中提取文本数据并将其附加到span_data列表中。最后,它将span_data列表中的数据附加到meta_data中。
从span HTML元素中提取的数据如下所示:

接下来,您需要创建两个Python列表,将浏览量和发布时间分别保存
#1 Iterate over the list of lists and collect the first and second item of each sublist
views_list = []
published_list = []
for sublist in meta_data:
#2 append number of views in the views_list
views_list.append(sublist[0])
#3 append time published in the published_list
published_list.append(sublist[1])这一步,您创建了两个从meta_data中提取数据的Python列表,并将每个子列表的浏览量附加到浏览列表view_list,将发布时间附加到发布列表published_list。
至此,您已经抓取了视频标题、视频页面URL、图片URL、浏览量及视频发布时间数据。您可以使用pandas Python包将此数据保存到pandas DataFrame中。使用以下代码将标题、链接、图片链接、浏览列表和发布列表中的数据保存到pandas DataFrame中:
# save in pandas dataFrame
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published']
)
# show the top 10 rows
data.head(10)
# export data into a csv file.
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()在pandas DataFrame中抓取的数据如下所示:
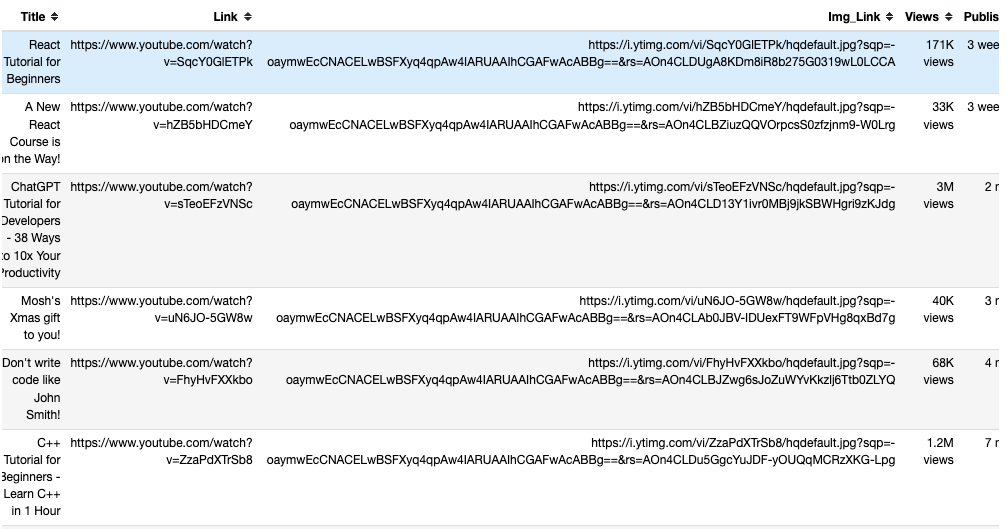
保存的数据通过to_csv()从pandas导出到名为youtube_data.csv的CSV文件中。
现在您可以运行youtube_videos_list.py,确保一切正常。
使用CSS选择器抓取数据
Selenium还可以根据HTML元素中的特定模式,使用网页上的CSS 选择器提取数据。CSS选择器根据ID、标签名、class类或其他属性来定位特定元素。
例如,这里的HTML页面有一些div元素,其中一个类名为“inline-code” :
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>您可以使用CSS选择器来查找网页上标签名为div、类名为“’inline-code”`的HTML元素。您可以应用相同的方法从YouTube视频的评论部分提取评论。
现在,让我们使用CSS选择器来采集在此YouTube视频上发布的评论。
您可以在以下标签和类名下找到YouTube的评论部分:
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>我们来创建一个新脚本(即data_scraping_project/scripts/youtube_video_
comments.py)。像之前一样导入所有必要的包,并添加以下代码以自动启动 Chrome网络浏览器,浏览YouTube视频URL,然后使用CSS选择器抓取评论:
#1 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 Define the URL
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 Load the webpage
driver.get(url)
#4 define the CSS selector
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. collect HTML elements within the CSS selector
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)这段代码实例化了Chrome驱动程序并定义 YouTube 视频链接以抓取发布的评论。然后,此代码在浏览器中加载网页,并等待十秒,直到与CSS选择器匹配的HTML元素可用。
接下来,使用名为ytd-comment-thread-renderer.ytd-item-section-renderer的CSS选择器采集所有评论HTML元素,并将所有评论元素保存在comment_blocks WebElement对象中。
然后,您可以使用ID author-text提取作者姓名,并使用ID content-text提取评论文本,从comment_blocks WebElement对象的每个评论中采集数据:
#1 specify the id attribute for author and comment
author_id = 'author-text'
comment_id = 'content-text'
#2 Extract the text value for each comment and author in the list
comments = []
authors = []
for comment_element in comment_blocks:
#3 collect author for each comment
author = comment_element.find_element(By.ID, author_id)
#4 append author name
authors.append(author.text)
#5 collect comments
comment = comment_element.find_element(By.ID, comment_id)
#6 append comment text
comments.append(comment.text)
#7 save in pandas dataFrame
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['Author', 'Comment'])
#8 export data into a CSV file.
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()这段代码指定了作者和评论的ID。然后创建了两个Python列表来添加作者姓名和评论文本。该代码从WebElement对象中采集具有指定ID属性的每个HTML元素,并将数据附加到Python列表。
最后,它将抓取的数据保存到pandas DataFrame中,并将数据导出到名为youtube_comments_data.csv的 CSV文件中。
在pandas DataFrame中,前十行的作者和评论如下所示:

使用Class类名抓取数据
除了使用CSS选择器抓取数据之外,您还可以根据特定的类名提取数据。要使用Selenium根据类名属性查找HTML元素,您需要调用find_element()方法,将By.CLASS_NAME作为第一个参数传递,将类名作为第二个参数。
在本节中,您将使用类名来采集黑客咨询上发布的文章标题和链接。在此网页上,包含每篇文章标题和链接的HTML元素都有一个titleline类名,如网页代码中所示:
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitebit comhead"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2 hours ago</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">hide</a> | <a href="item?id=35421034">119 comments</a> </span>创建一个新的Python脚本(即data_scraping_project/scripts/hacker_news.py),导入所有必要的包,并添加以下Python代码来抓取发布在黑客咨询页面上每篇文章的标题和链接:
#1 define url
hacker_news_url = 'https://news.ycombinator.com/'
#2 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 load the web page
driver.get(hacker_news_url)
#4 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 Extract the text value for each title and link in the list
titles= []
links = []
#6 Find all the articles on the web page
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 Extract title and link for each article
for story_element in story_elements:
#8 append title to the titles list
titles.append(story_element.text)
#9 extract the URL of the article
link = story_element.find_element(By.TAG_NAME, "a")
#10 appen link to the links list
links.append(link.get_attribute("href"))
driver.quit()这段代码将定义网页的URL,自动启动Chrome网络浏览器,然后浏览黑客咨询的URL。并等待十秒,直到匹配类名的HTML 元素可用。
然后,此代码会创建两个Python列表来附加每篇文章的标题和链接。它还从WebElement驱动程序对象中采集具有titleline类名的每个HTML元素,并从Story_elements WebElement 对象中提取每篇文章的标题和链接。
后,此代码将文章标题追加到titles列表,并从story_element对象中采集具有a标签名的HTML元素。它使用get_attribute()方法提取链接,并将链接附加到links列表。
接下来,您需要使用pandas的to_csv()方法导出抓取的数据。您会将标题和链接导出到名为hacker_news_data.csv的CSV文件中,并将数据保存在目录:
# save in pandas dataFrame
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# export data into a csv file.
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)以下是前五行的标题和链接在pandas DataFrame中的显示方式:
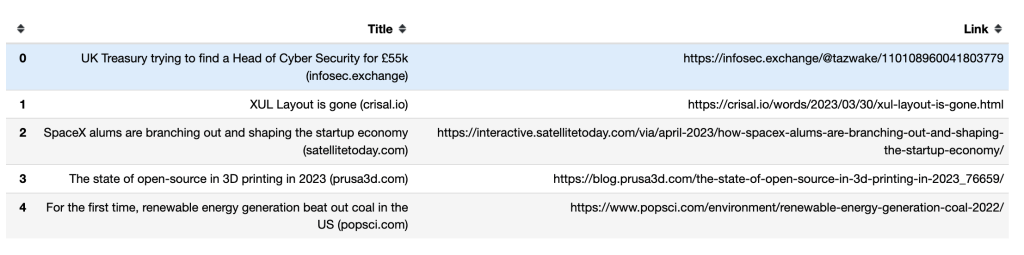
如何处理无限滚动Infinite Scrolls
当您滚动到页面底部时,一些动态网页会加载附加内容。如果您不滚动到底部,Selenium可能只会抓取屏幕上可见的数据。
要抓取更多数据,您需要指示Selenium滚动到页面底部,等待新内容加载,然后自动抓取您想要的数据。例如,以下Python脚本将滚动浏览Python图书的前40个结果并提取链接:
#1 import packages
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Instantiate a Chrome webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 Navigate to the webpage
driver.get("https://example.com/results?search_query=python+books")
#4 instantiate a list to keep links
books_list = []
#5 Get the height of the current webpage
last_height = driver.execute_script("return document.body.scrollHeight")
#6 set target count
books_count = 40
#7 Keep scrolling down on the web page
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 Wait for the page to load
time.sleep(5)
#9 Calculate the new height of the page
new_height = driver.execute_script("return document.body.scrollHeight")
#10 Check if you have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
#11 Extract the data
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 append extracted data
books_list.append(link.get_attribute("href"))
#13 Close the webdriver
driver.quit()这段代码将要使用的Python包导入并实例化,打开了Chrome浏览器。然后导航到网页并创建一个Python列表来附加每个搜索结果的链接。
通过运行return document.body.scrollHeight脚本获取当前页面的高度,并设置要采集的链接数量。接下来,只要图书数量book_count变量的值大于图书列表book_list的长度,页面就会继续向下滚动,并等待五秒钟加载。
通过运行return document.body.scrollHeight脚本计算网页的新高度,并检查是否到达页面底部。如果是,则终止循环;否则,将更新last_height并继续向下滚动页面。最后,此代码从WebElement对象中采集标签名称为a的HTML元素,提取链接并将其附加到链接列表中。采集链接后,Webdriver将关闭。
请注意:如果页面能够无限滚动,为了让脚本在某个时刻结束,您必须设置要抓取的项目总数。否则,您的代码将继续执行。
使用亮数据Bright Data抓取网页
虽然使用像 Selenium 这样的开源爬虫工具可以抓取数据,但它们往往缺乏支持。此外,该过程可能复杂且耗时。如果您正在寻找强大且可靠的网络爬取解决方案,您应该考虑亮数据。
亮数据拥有世界上最好的代理服务器,为数十家财富500强公司和超过20,000个客户提供服务。其广泛的代理类型包括:
数据中心代理 – 超过77万个数据中心IP。
住宅代理 – 来自超过195个国家的住宅设备的超过7200万个IP。
ISP代理 – 超过70万个ISP IP。
总的来说,这是市场上最大最可靠的面向数据爬取的代理网络之一。但亮数据不仅仅是一个代理提供商。它还提供一流的网络爬取服务,包括一个 亮数据浏览器(集成Puppeteer、Selenium 和 Playwright)、网络爬取 IDE 和一个 SERP API接口。
如果您不想处理数据爬取,但又对网页数据感兴趣,您可以利用亮数据现成的 数据集。







