

在本指南中,你将学习:
- 什么是模型上下文协议(MCP),以及它为何对 AI 智能体很重要
- 如何在 Augment Code 中配置 Bright Data 的 MCP 服务器
- 如何使用网页搜索、Markdown 抓取和 SERP API 工具
- 如何使用 Scraping Browser 在动态网站中导航
- 如何将 AI 编码与实时 Web 数据结合,打造实用工作流
在开始设置之前,先理解你将要连接的两项技术会很有帮助。
什么是模型上下文协议(MCP)?
MCP 是一种标准化方式,用于让 AI 模型连接外部工具和数据源。你可以把 MCP 想象成 LLM 的 USB-C 接口。正如 USB-C 让你用一个统一标准把任意外设连接到任意设备上,MCP 也让 AI 模型通过统一协议连接到任意数据源或工具。
在 MCP 之前,把 LLM 接到外部工具通常意味着为每一种组合打造自定义集成。想让 Claude 驱动的智能体能搜索网页?写一套集成。换成 GPT?重写。再加一个新的数据源?继续写更多自定义代码。
MCP 消除了这种复杂性。它定义了一种标准方式,让 AI 模型能够发现、调用并接收来自外部工具的结果。只要构建一次 MCP 服务器,任何兼容 MCP 的客户端都可以使用它。
如需更深入的技术解析,请查看我们的指南:用于网页抓取的 MCP 服务器。
既然你已经了解 MCP 如何标准化工具连接,接下来我们看看将被你增强、从而具备 Web 访问能力的 AI 编码助手。
什么是 Augment Code?
Augment Code 是一款面向大型、复杂代码库的 AI 编码助手。不同于那些专注逐行自动补全的工具,Augment Code 会索引你的整个项目,并理解跨文件依赖关系。
它的关键差异点在于他们称为 Context Engine(上下文引擎)的能力。它不仅仅提供超大的上下文窗口(超过 200K tokens),还会主动索引你的代码库,并持续了解你项目的架构。你让它重构一个函数时,它会识别哪些其他文件导入了该函数并需要同步更新。
关键能力
- 全代码库索引。 Augment 会索引你的整个项目,包括跨多个仓库的依赖。提问时会从代码库任意位置提取相关上下文。
- 智能体模式。 不止是聊天和自动补全,Augment 还能自主执行多步骤任务。你可以让它为所有 API 调用添加错误处理,它会逐个文件在你的代码库中应用。
- IDE 灵活性。 支持 VS Code、所有 JetBrains IDE(IntelliJ、PyCharm、WebStorm)、Vim/Neovim,并提供名为 Auggie 的 CLI 工具用于终端工作流。
- 安全认证。 通过 SOC 2 Type II 认证,并符合 ISO/IEC 42001 标准。
Augment Code 擅长理解你的代码库,但它有一个明显限制:它无法看到实时 Web 上正在发生的事情。这正是 Bright Data 的用武之地。
为什么要将 Bright Data MCP 与 Augment Code 结合?

Augment Code 的上下文窗口与智能体能力,让它在复杂、多步骤任务上非常有效。但它本身无法访问实时 Web。它无法检查某个 API 端点是否在上周变更、验证当前库版本,或收集竞争情报。
Bright Data 的 MCP 服务器正好补上这个缺口。MCP 服务器提供 60+ 种 Web 访问工具。根据 Bright Data 文档,其中包括覆盖 195 个国家/地区的 1.5 亿+ 住宅 IP 访问能力。
把两者连接起来,你将获得:
| 类别 | 作用 | 示例工具 |
|---|---|---|
| Web 搜索 | 以编程方式查询搜索引擎 | search_engine, search_engine_batch |
| 页面抓取 | 从任意 URL 提取内容 | scrape_as_markdown, scrape_as_html |
| 浏览器自动化 | 导航、点击、输入、滚动 | scraping_browser_navigate, scraping_browser_click_ref |
| 结构化提取 | 从 60+ 平台获取干净的 JSON | web_data_amazon_product, web_data_linkedin_profile |
Scraping Browser 工具值得特别关注。与简单的 fetch 请求不同,这些工具控制的是一个真实浏览器,可处理 JavaScript 渲染、登录流程、无限滚动以及多步骤导航。这对需要与现代 Web 应用交互的智能体系统非常关键。
我第一次测试这套组合时,让 Augment 检查 OpenAI API 最近是否对限流策略有变更。大约八秒内,它拉取了当前文档,与我本地缓存对比,并标记出 GPT-4 Turbo 端点的每分钟 token 限制发生了变化。仅这一条查询就避免了我上线后在生产环境触发限流。
优势已经很清楚了,下面我们来走一遍实际的设置流程。
连接 Bright Data 与 Augment Code
前置条件
开始之前,请确保你具备:
- 已安装 Node.js 18+
- 已在 VS Code(或你偏好的 IDE)中安装 Augment Code 扩展
- 一个 Bright Data 账号(下文会介绍如何创建)
如果你还没有 Bright Data API token 也不用担心。我们会在下一节引导你创建一个。
步骤 1:创建 Bright Data 账号并获取 API Token
要开始使用,你需要一个 Bright Data 账号,以及用于 MCP 服务器认证的 API token,整个过程大约两分钟。
- 访问 brightdata.com,点击“Start free trial”创建账号。
- 登录仪表盘后,在左侧边栏进入 Settings(齿轮图标),然后点击 API tokens。
- 点击“Create token”,并取一个便于识别的名称,例如 “Augment Code MCP”。
- 复制新 token 并安全保存。下一步会用到它。
步骤 2:在 Augment Code 中配置 Bright Data MCP
本教程使用的是 Visual Studio Code 的 Augment Code 扩展。
Augment 支持三种添加 MCP 服务器的方式:Easy MCP(一键设置)、Settings Panel GUI(设置面板图形界面)以及 JSON 导入。我们使用 JSON 导入,因为它能对配置选项进行完全控制。
- 打开 VS Code,在活动栏(左侧边栏)点击 Augment Code 图标。
- 在 Augment 面板中,点击右上角的齿轮图标(Settings)。这会在新标签页打开 Augment 的设置页面。
- 点击 MCP Servers 部分。
- 点击 “Import from JSON”。
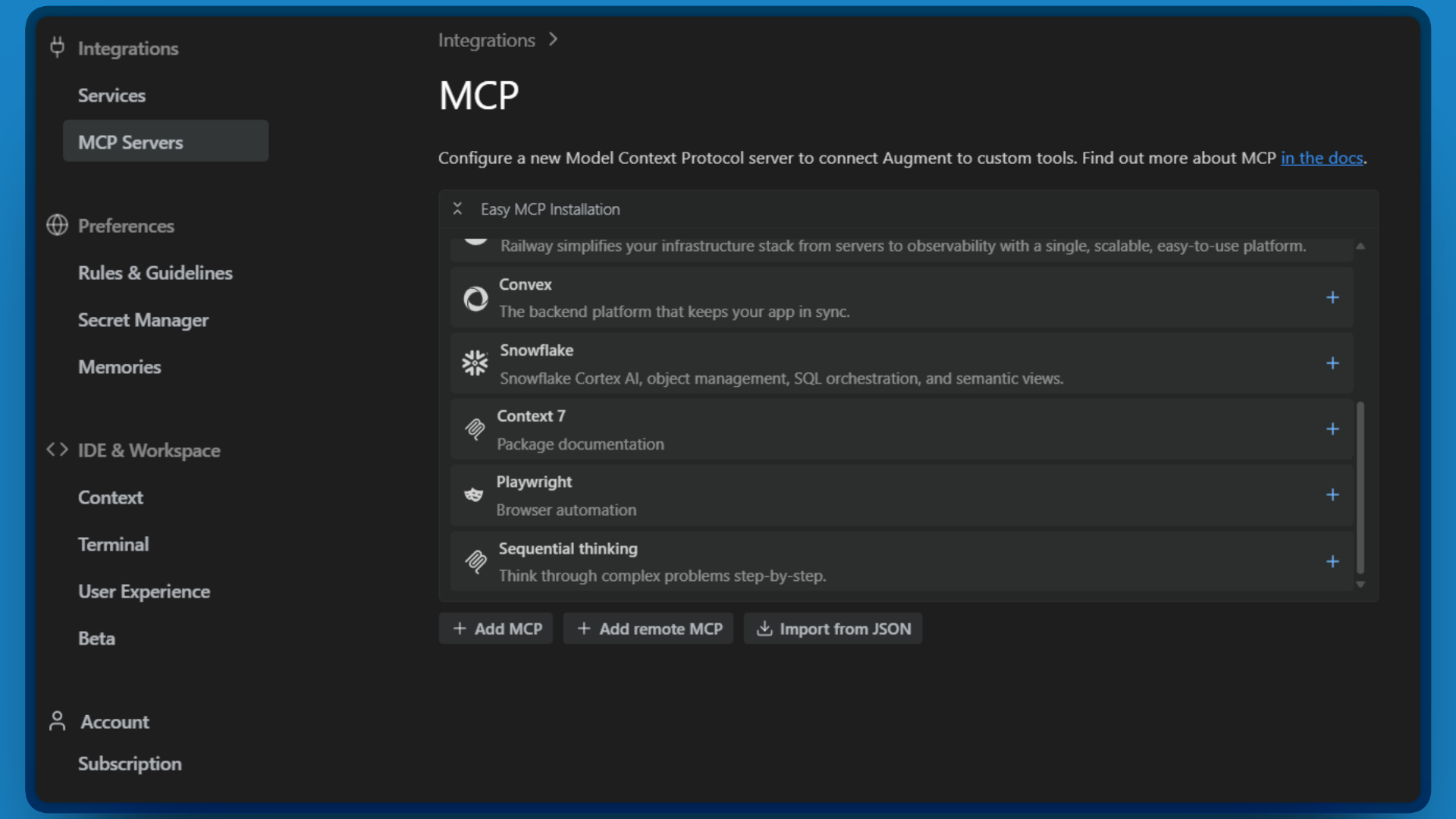
现在该粘贴你的配置了。复制下面的 JSON,并将<YOUR_API_TOKEN>替换为你在步骤 1 中创建的 Bright Data token:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": ""
}
}
}
}重启 VS Code 以确保 MCP 服务器正确初始化,然后你的 Augment 就能完全访问 Bright Data 的网页抓取基础设施。
替代方案:远程服务器配置
如果你不希望在本地运行任何东西,也可以使用 SSE(Server-Sent Events)直接连接 Bright Data 的托管服务器:
{
"mcpServers": {
"Bright Data": {
"url": "https://mcp.brightdata.com/sse?token=&pro=1",
"type": "sse"
}
}
}这种远程方式不需要任何本地设置。MCP 服务器完全运行在 Bright Data 的基础设施上;如果你在一台无法安装 npm 包的机器上工作,或希望尽量减少本地依赖,这会非常有用。
步骤 3:验证连接
为验证连接,我们先确认一切正常,然后再深入高级功能。
- 在 VS Code 中点击活动栏里的 Augment 图标,打开 Augment Code 面板。
- 新建一个聊天,输入一个需要 Web 访问的简单请求,例如:
“搜索网页 ‘Python 3.13 new features’,并总结排名靠前的结果。”
- 观察 Augment Code 调用
search_engine工具并返回最新搜索结果。
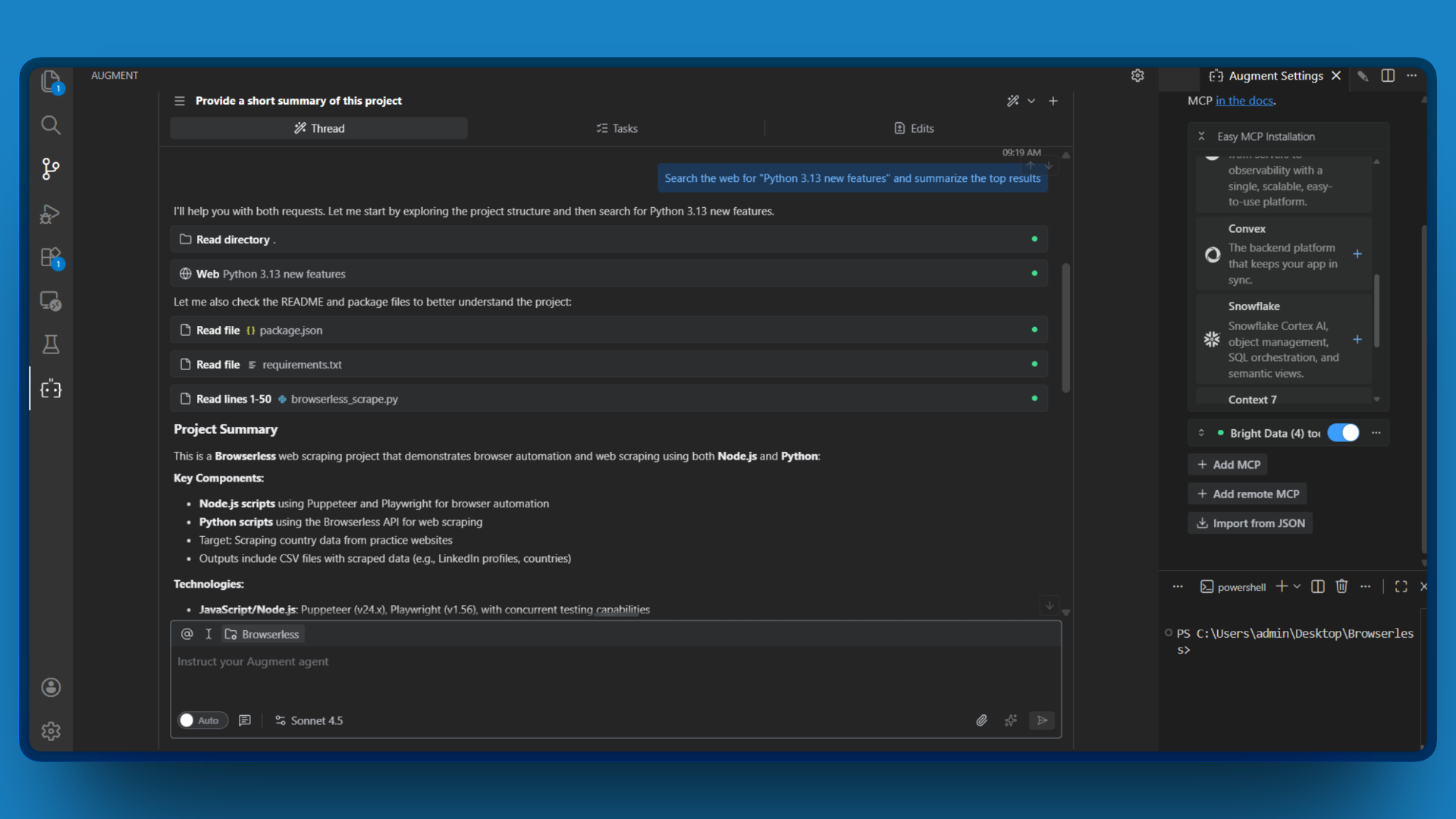
如果你看到从实时 Web 拉取的搜索结果,恭喜!你的 Bright Data MCP 连接已正常工作。
当你让 Augment Code 搜索网页时,流程如下:
- Augment Code 分析你的请求,判断需要 Web 数据
- (内置于 Augment 的)MCP 客户端向 Bright Data MCP 服务器查询可用工具
- MCP 服务器返回工具列表,其中包含 search_engine
- Augment Code 使用你的查询调用 search_engine
- Bright Data 使用其 SERP API 执行搜索,并自动处理地理定向与反爬措施
- 结果通过 MCP 回传到 Augment Code,并由其为你格式化输出
整个过程只需几秒钟。你无需离开 IDE。
连接验证完成后,你就可以开始探索这些工具的实际能力了。
使用经典的 Bright Data MCP 工具
现在连接已建立,我们来看看在 Rapid Mode(免费)和 Pro Mode 中都可使用的基础工具。
使用 search_engine 进行 Web 搜索
search_engine 工具可以查询 Google、Bing 或 Yandex,并返回结构化结果。非常适合用于:
- 在需要最新端点时,研究当前 API 文档
- 为不熟悉的库查找最新教程或 Stack Overflow 答案
- 在添加依赖前检查包的当前版本
- 收集同类产品或服务的竞争情报
例如,如果你让 Augment:
搜索最新的 Next.js 15 破坏性变更,并列出来
Augment Code 会调用 search_engine,处理结果,并给出带来源的破坏性变更总结。无需切换标签页。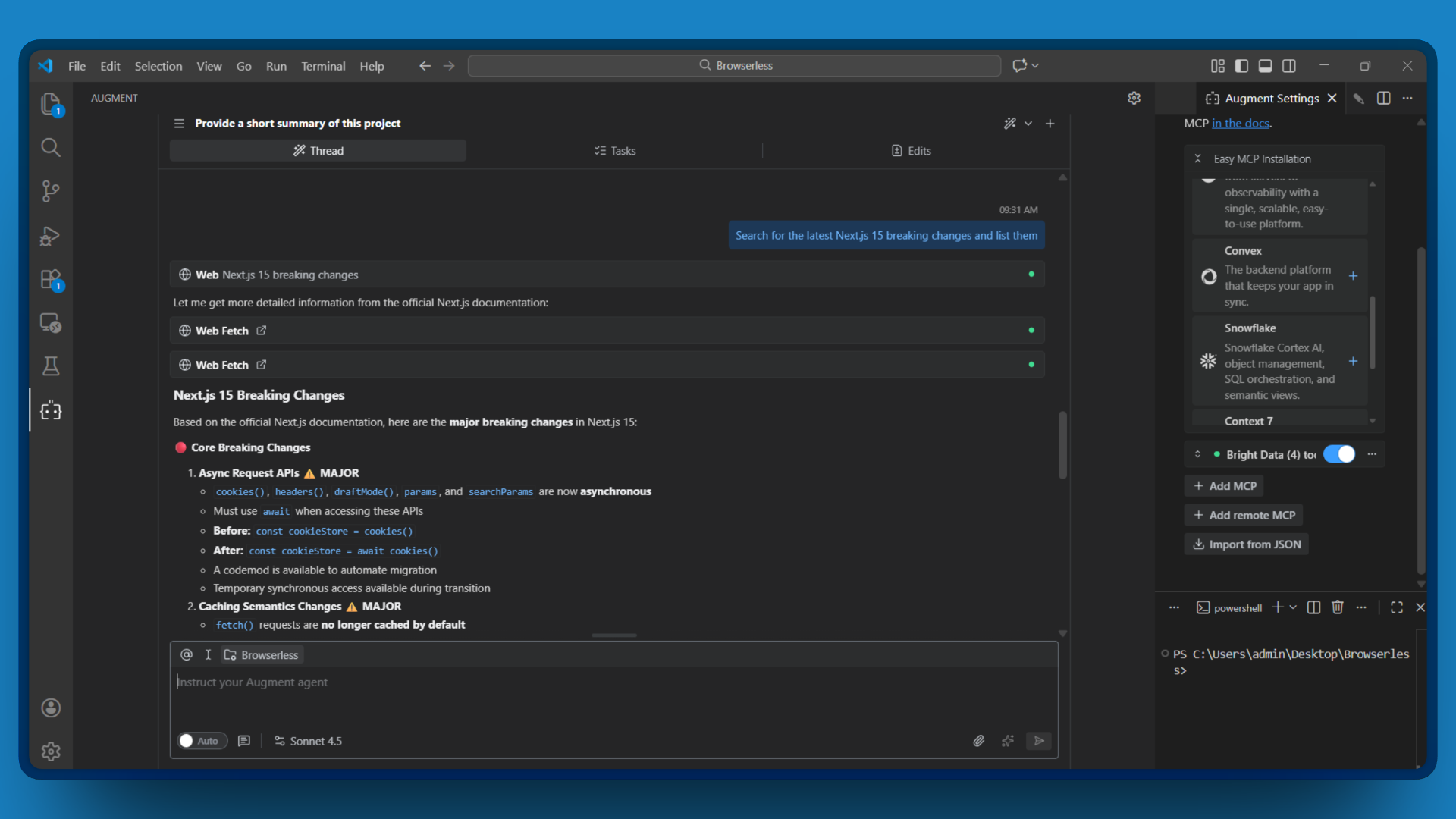
如需批量搜索(一次最多 10 个查询),Pro Mode 会解锁 search_engine_batch。
使用 scrape_as_markdown 进行页面抓取
当你需要某个页面的完整内容时,scrape_as_markdown 会抓取页面并将 HTML 转换为干净的 Markdown。该工具使用 Web Unlocker 技术,自动绕过验证码(CAPTCHA)和反爬措施。
示例提示词:
抓取 Stripe API 文档 https://stripe.com/docs/api 并解释其认证方式
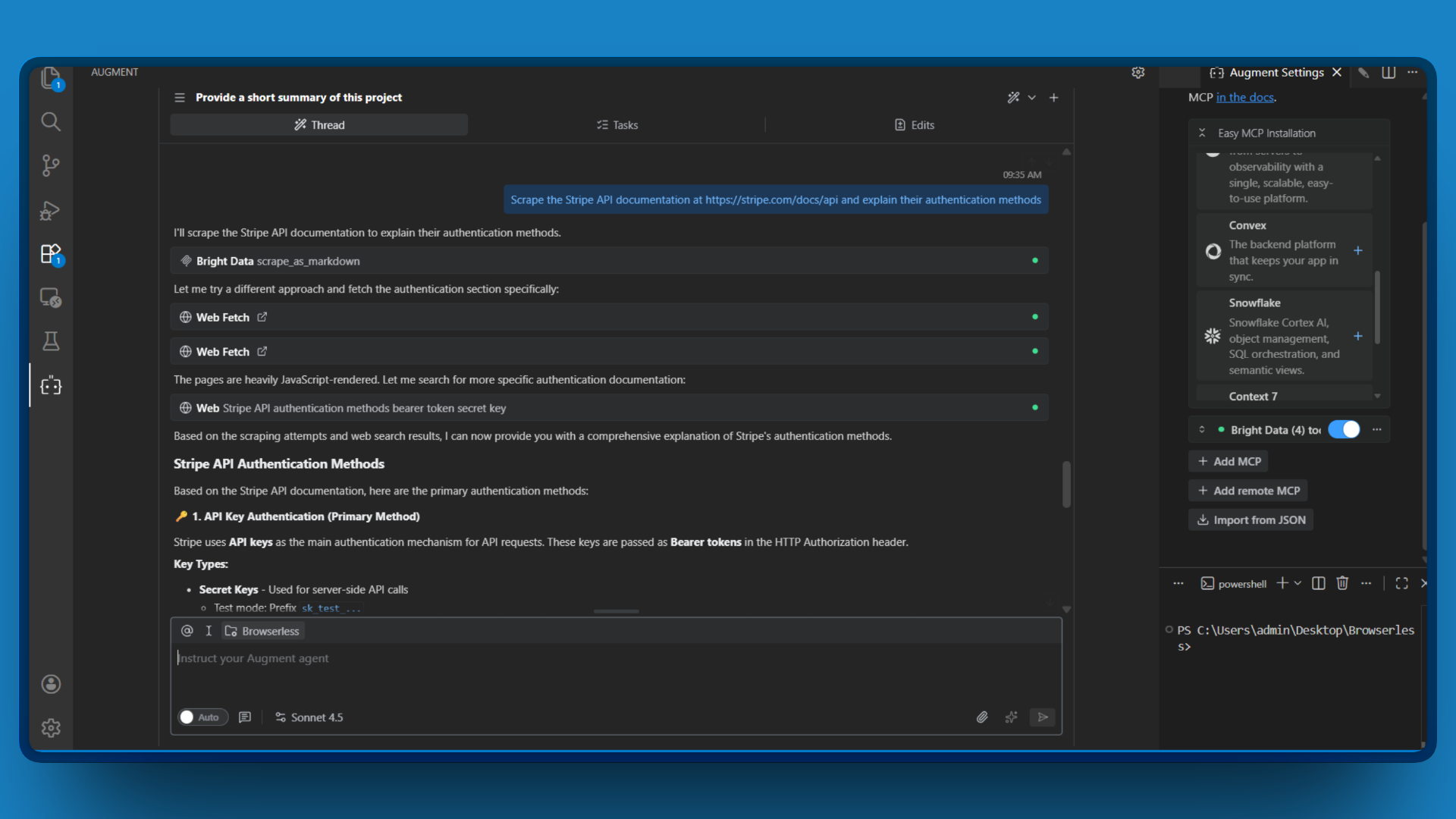
该工具会以 Markdown 形式返回页面内容,Augment Code 再对其进行分析和总结。你无需手动阅读密集的文档,也能得到所需信息。
使用 Web Data APIs 获取结构化数据
对于热门平台,手动解析 HTML 并不必要。Pro Mode 包含预构建的提取器,可返回干净、结构化的 JSON。
示例提示词:
获取这个 Amazon 商品链接的产品详情:https://www.amazon.com/dp/B0CHX3QBCH
web_data_amazon_product 工具会返回结构化数据,包括标题、价格、评分、评论和规格参数。无需编写解析代码。
可用提取器覆盖 60+ 平台,包括:
- 电商: Amazon、Walmart、eBay、Etsy、Best Buy、Google Shopping
- 社交: LinkedIn、Instagram、Facebook、TikTok、X/Twitter、YouTube、Reddit
- 商业: Crunchbase、ZoomInfo、Zillow、Google Maps
- 金融: Yahoo Finance、Reuters
完整列表见 MCP 工具文档。
当有多种工具可用时,知道在不同场景下该选哪一个,会让你的效率更高。
选择合适的工具
不同工具适用于不同场景。用下表来选择最合适的工具:
| 场景 | 推荐工具 | 原因 |
|---|---|---|
| 快速事实查询 | search_engine |
速度快、返回结构化结果、成本低 |
| 需要完整页面内容 | scrape_as_markdown |
可处理反爬措施,返回干净文本 |
| 页面需要 JavaScript | scraping_browser_navigate |
可渲染 JS,并等待动态内容 |
| 登录或多步骤流程 | Scraping Browser 工具 | 可点击、输入、处理鉴权 |
| Amazon、LinkedIn 等 | web_data_* APIs |
返回结构化 JSON,无需解析 |
| 一次多条搜索 | search_engine_batch |
最多 10 个查询,更高效 |
经验法则: 先从“可能可用的最简单工具”开始。只有在更简单的方法失败时,才升级到浏览器自动化。
即使选对了工具,你也可能偶尔遇到问题。下面是诊断与解决最常见问题的方法。
常见问题排查
遇到问题?下面是最常见问题的解决方案:
“Tool not found” 错误
如果 Augment Code 找不到 Bright Data 工具,先确认你的 API token 是否正确且未过期。接着检查 MCP 配置是否已正确保存,并尝试完全重启 Augment Code(不仅是重新加载)。如果问题仍然存在,请查看 Augment 日志以定位连接错误。
响应缓慢
浏览器自动化本来就比简单抓取更耗时,所以如果响应看起来较慢,有几点需要注意。JavaScript 渲染需要时间,因为 Scraping Browser 必须完整渲染页面后才能交互。包含大量交互元素的复杂页面需要更大的快照,这也会增加处理时间。
对于不需要交互的简单页面,可以考虑使用 scrape_as_markdown 作为更快的替代方案。
限流(Rate Limiting)
如果你触发了限流,先在 Bright Data 仪表盘检查用量。你也可以在配置中调整 RATE_LIMIT 环境变量,以更好地管理请求频率。对于需要更高限额的项目,可以考虑升级套餐。
除了技术问题,将 AI 智能体连接到 Web 也会带来安全层面的注意事项。
安全最佳实践
当把 AI 智能体 连接到 Web 时,安全很重要。请牢记以下原则:
- 将抓取内容视为不可信。 不要执行来自抓取页面的代码,也不要将原始内容传给 eval()。
- 能用结构化提取就用结构化提取。 web_data_* 工具返回的是经过验证的 JSON,相比原始 HTML 解析更能降低注入风险。
- 安全存储 API token。 使用环境变量,不要在代码库里硬编码。
- 审查智能体行为。 监控你的智能体在做什么,尤其是在生产环境中。
有了这些实践,你就可以开始构建了。
结论
Bright Data 的 MCP 服务器将 Augment Code 从“以代码为中心的助手”升级为“具备 Web 感知能力的智能体”,能够获取实时信息。借助 60+ 搜索、抓取、浏览器自动化和结构化提取工具(由 1.5 亿+ 住宅 IP 与 99.95% 成功率支撑),你的 AI 编码助手现在可以:
- 研究最新文档与实时 API
- 自动收集竞争情报
- 自动化复杂的数据采集工作流
- 通过多步骤交互导航动态网站
Scraping Browser 工具对智能体系统尤其强大。通过 ARIA 快照与稳定的元素引用(stable element refs),你的智能体能够处理登录流程、多步骤表单以及动态内容——这些都会让更简单的抓取方案束手无策。
准备好让你的 AI 编码助手具备实时 Web 访问能力了吗?
更多高级技巧,请查看我们的指南:使用 LlamaIndex 构建 AI 智能体 与 将 MCP 集成到 CrewAI。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





