
在这篇博客文章中,你将了解:
- Zencoder 是什么,以及它提供哪些产品来通过 AI 改进软件开发。
- 为什么通过网页访问扩展它能让输出更可靠、更准确。
- Bright Data 如何支持 Zencoder 集成,用于网页抓取、搜索、发现和浏览器自动化。
- 如何使用 MCP 将 Bright Data 连接到 Zencoder Zenflow(及其 IDE 插件)。
- 如何使用官方 Agent skills 让 Zencoder 产品了解 Bright Data。
- Bright Data + Zencoder 集成能实现什么,并通过一个完整示例进行说明。
让我们开始吧!
什么是 Zencoder?
Zencoder 是一家为 AI 驱动的编码代理提供解决方案的公司,这些代理可作为自主的结对程序员。
其主要产品是 Zenflow,一个 AI 编排平台,可在 IDE、CI/CD 流水线和桌面环境中运行多代理工作流。它使代理能够在完整代码库上下文、结构化工作流以及内置质量门禁的支持下,规划、构建、测试并验证代码。其最终目标是大规模自动化软件开发与运维任务。
Zenflow 支持两种模式:
- Zenflow Code:用于软件开发的 AI 代理(构建、测试、重构)。
- Zenflow Work:用于跨 Jira、Slack 等工具的企业工作流 AI 代理。
注意:Zencoder 也可通过 IDE Agents 在 Visual Studio Code 和 JetBrains 中使用。
Zencoder 产品支持的主要功能包括:
- 多代理编排:多个 AI 代理协作完成规划、编码、审查和审计任务。
- 完整代码库上下文:代理在行动前理解多仓库架构与依赖关系。
- 结构化工作流:“Spec → plan → build → test → verify” 流水线取代临时提示。
- 内置验证:自动化测试、linting 和代码审查在输出被接受前确保质量。
- 并行执行:多个代理在隔离环境中同时运行。
- 跨工具集成:可与 GitHub、Jira、Slack、CI/CD 系统等协作。
- 企业级控制:基于角色的访问、审批门禁、审计日志与合规支持(SOC 2、ISO)。
- 自主调度:代理自动运行依赖更新或 PR 审查等周期性任务。
了解更多 请参阅官方文档。
为什么要让 Zencoder AI 代理具备探索网页并从中获取数据的能力
就像任何其他由 LLM 驱动的解决方案一样,Zencoder 代理也受到一个根本限制的约束:信息衰减。由于大型语言模型生成的响应源自其训练数据集,它们只能在固定的过去时间窗口内运行。
在快速演进的技术生态中,这种延迟构成了巨大障碍。这样的编码代理可能会提出过时的库方法,或忽略关键的新安全更新。为了绕过这些限制,你的 AI 模型需要实时网页连接。这正是 Bright Data 发挥作用的地方!
Bright Data 的 AI 就绪基础设施 使你的 Zencoder 代理能够超越其初始训练。这样,它就获得了以下能力:
- 执行实时搜索:浏览 Google 或其他搜索引擎以获取最新文档与信息,减少幻觉与过时建议。
- 验证精确性:将代码片段与 Stack Overflow 讨论或 GitHub issues 交叉核对,以提升调试准确性。
- 提取结构化数据:从实时网页中收集数据,以填充本地仓库或为开发与测试生成逼真的模拟数据。
- 增强文档:为 README 文件或内部项目 wiki 推荐可信、高声誉的 URL。
- 以及更多……
Bright Data 的决定性优势在于其庞大的全球代理网络,拥有覆盖 195 个国家/地区的 4 亿+ 住宅 IP。该基础设施提供无限并发、99.99% 正常运行时间以及 99.95% 成功率。
通过将 Bright Data 集成到 Zencoder 产品中,结果是可扩展的 AI 代理,它们以结构化、最新且具上下文的网页数据为基础。
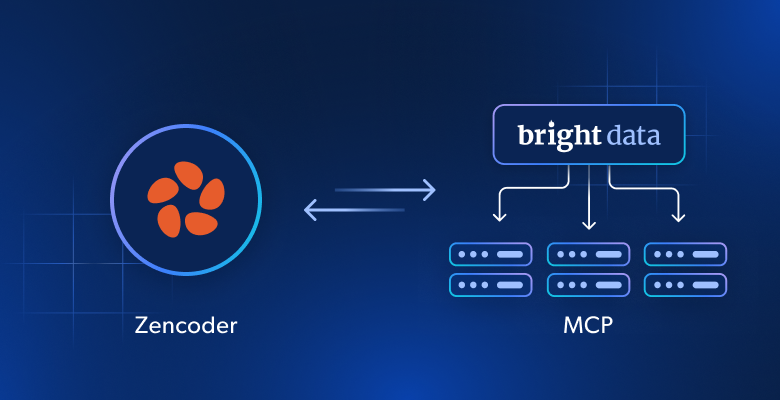
如何将 Zencoder AI 代理连接到 Bright Data 的网页数据基础设施
Bright Data 通过两种集成方式支持 Zencoder:
- Bright Data Web MCP:MCP 服务器,暴露 70+ 个用于网页数据访问、提取与浏览器自动化的工具。
- Bright Data 技能:Agent 技能,用于指导 Zencoder 代理有效使用 Bright Data 解决方案。
请注意,这些方法不是替代关系,而是协同关系。具体来说,某个特定 skill 会为 Web MCP 工具的最佳使用提供指导。
重要:以下章节将提及通过 MCP 和 Agent skills 将 Bright Data 集成到 Zenflow 中。Zencoder IDE 插件也依赖相同的相关配置文件。因此,设置保持不变(仅 UI 截图和一些细微说明有所不同)。
Bright Data Web MCP
Bright Data Web MCP 提供 70+ 个工具,用于与 Bright Data 的基于 API 的产品与服务 交互。
即使在 Rapid 模式(免费层)下,核心工具也包括:
| Tool | Description |
|---|---|
search_engine + batch version for parallel usage |
以结构化 JSON 或 Markdown 检索 Google、Bing 或 Yandex 结果 |
scrape_as_markdown + batch version for parallel usage |
将任何网页转换为干净的 Markdown,同时处理反机器人保护绕过 |
discover |
AI 驱动的搜索,返回排序后的相关网页结果 |
然后,Pro mode 解锁从 GitHub、NPM、PyPI、Amazon、LinkedIn、Yahoo Finance、YouTube、Zillow、Google Maps 以及其他 40+ 平台提取结构化数据的高级能力。此外,它还暴露用于完整浏览器自动化的工具。
Bright Data 技能
Bright Data 技能 包括:
| Skill | Description |
|---|---|
search |
执行网页搜索并返回结构化结果 |
scrape |
将页面抓取为干净的 Markdown,并处理机器人保护 |
data-feeds |
从 40+ 站点提取结构化数据并进行定时轮询 |
bright-data-mcp |
编排 Web MCP 工具,以改进搜索、抓取和自动化 |
brightdata-cli |
Bright Data CLI 使用指南,涵盖抓取、代理和数据集管理 |
bright-data-best-practices |
正确且高效使用 Bright Data API 的参考 |
scraper-builder |
通过引导式站点分析与提取步骤构建生产级爬虫工具 |
competitive-intel |
使用跨市场与竞争对手的网页数据进行实时竞争分析 |
seo-audit |
使用实时网页信号、结构与排名指标进行 SEO 审计 |
design-mirror |
复刻 UI 设计模式、tokens 与组件结构 |
通用步骤
在接下来的两章中,我们将分别探讨如何使用 MCP 和 Agent 技能 将 Bright Data 集成到 Zenflow 中。现在,让我们先关注在开始之前所需的一些通用设置步骤。
前置条件
要跟随本教程,请确保你具备:
- 本地已安装 Node.js 22+。
- 一个 Zencoder 账户(Free 计划或试用即可)。
- 一个已配置 API key 的 Bright Data 账户(请参考生成 API key 的官方指南)。
安装并配置 Zenflow
下载 Zenflow 安装程序,运行它,然后启动应用程序。你应该会看到如下欢迎界面:
登录(如果你尚未注册则注册)以将你的 Zencoder 账户连接到 Zenflow。
系统会引导你完成一些设置问题。回答它们,然后选择你的默认 AI 代理:
最后再点击一次“Next”以完成设置:
做得好!你已成功安装 Zenflow。现在是时候为 Bright Data 集成配置它了。
通过 Web MCP 将 Bright Data 连接到 Zencoder
在本节中,你将被引导在 Zenflow 中设置 Bright Data Web MCP。
前置条件
为了更轻松地跟随,建议你具备:
- 对 MCP 工作原理的基本理解。
- 熟悉 Bright Data Web MCP 提供的工具。
注意:“通用步骤”章节中列出的前置条件在这里同样适用。
步骤 #1:开始使用 Bright Data 的 Web MCP
在将 Bright Data 的 Web MCP 连接到 Zenflow 之前,请确保 MCP 服务器能在你的机器上正确运行。
首先,登录你的 Bright Data 账户。如需快速设置,请按照 Bright Data 控制面板中 “MCP” 部分的说明操作: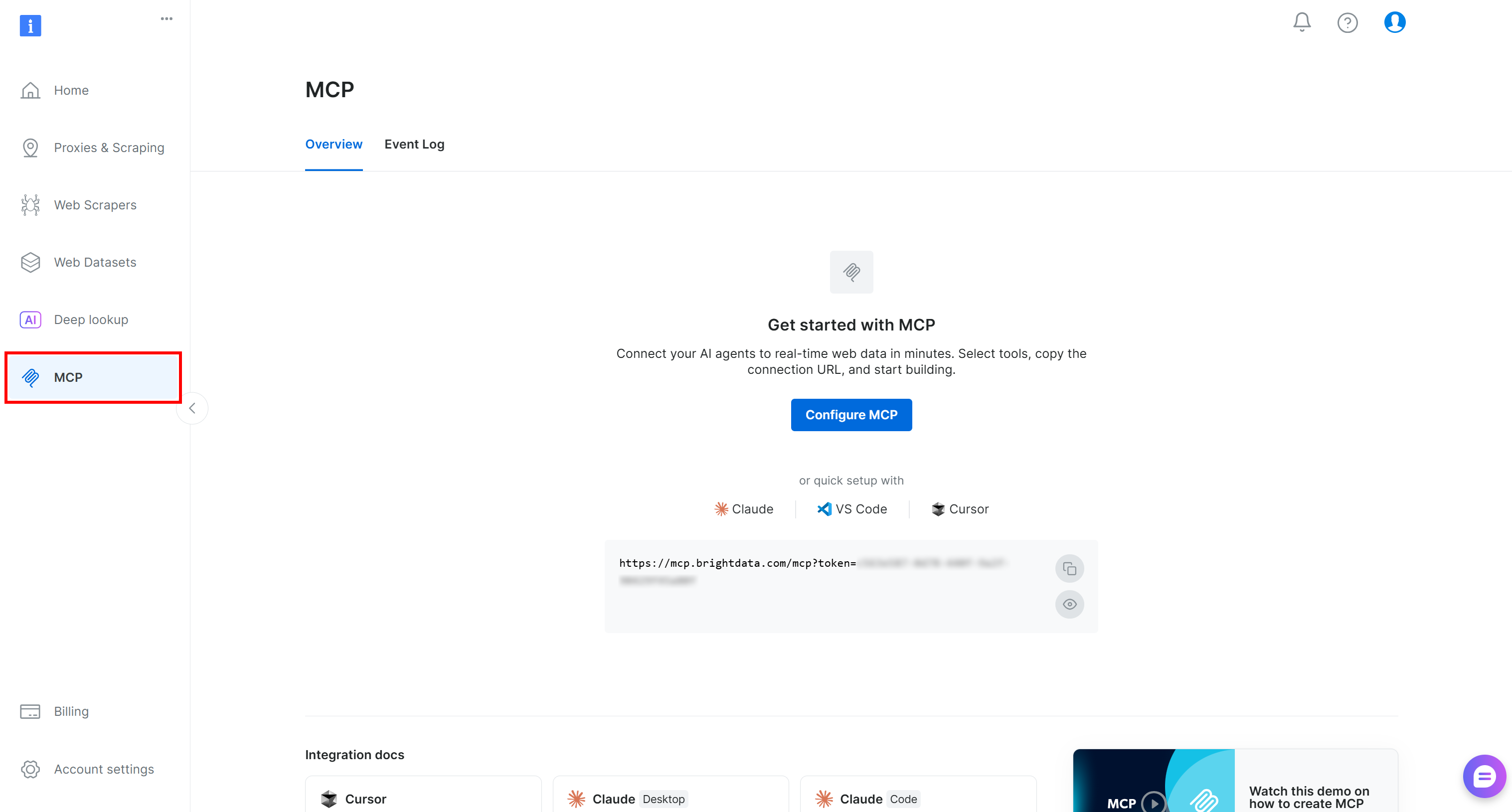
或者,如需更多指导,请按照下面的手动设置步骤操作。
首先,全局安装 Web MCP:
npm install -g @brightdata/mcp检查 MCP 服务器是否能通过以下命令启动:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp或者等效地,在 PowerShell 中:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 占位符替换为你实际的 Bright Data API key。该命令会设置所需的 API_TOKEN 环境变量,并通过 @brightdata/mcp 包在本地启动 Web MCP 服务器。
如果一切正常,你应该会看到这些日志:
首次运行时,@brightdata/mcp 包会在你的 Bright Data 账户中创建两个 区域:
mcp_unlocker:用于 网络解锁器 的 区域。mcp_browser:用于 Browser API 的 区域。
这些 区域 为 Web MCP 中可用的 70+ 工具提供支持。如有需要,你也可以配置自定义 区域,如官方仓库所述。
要验证 区域 是否已创建,请前往 Bright Data 控制面板中的 “Proxies & Scraping Infrastructure” 部分: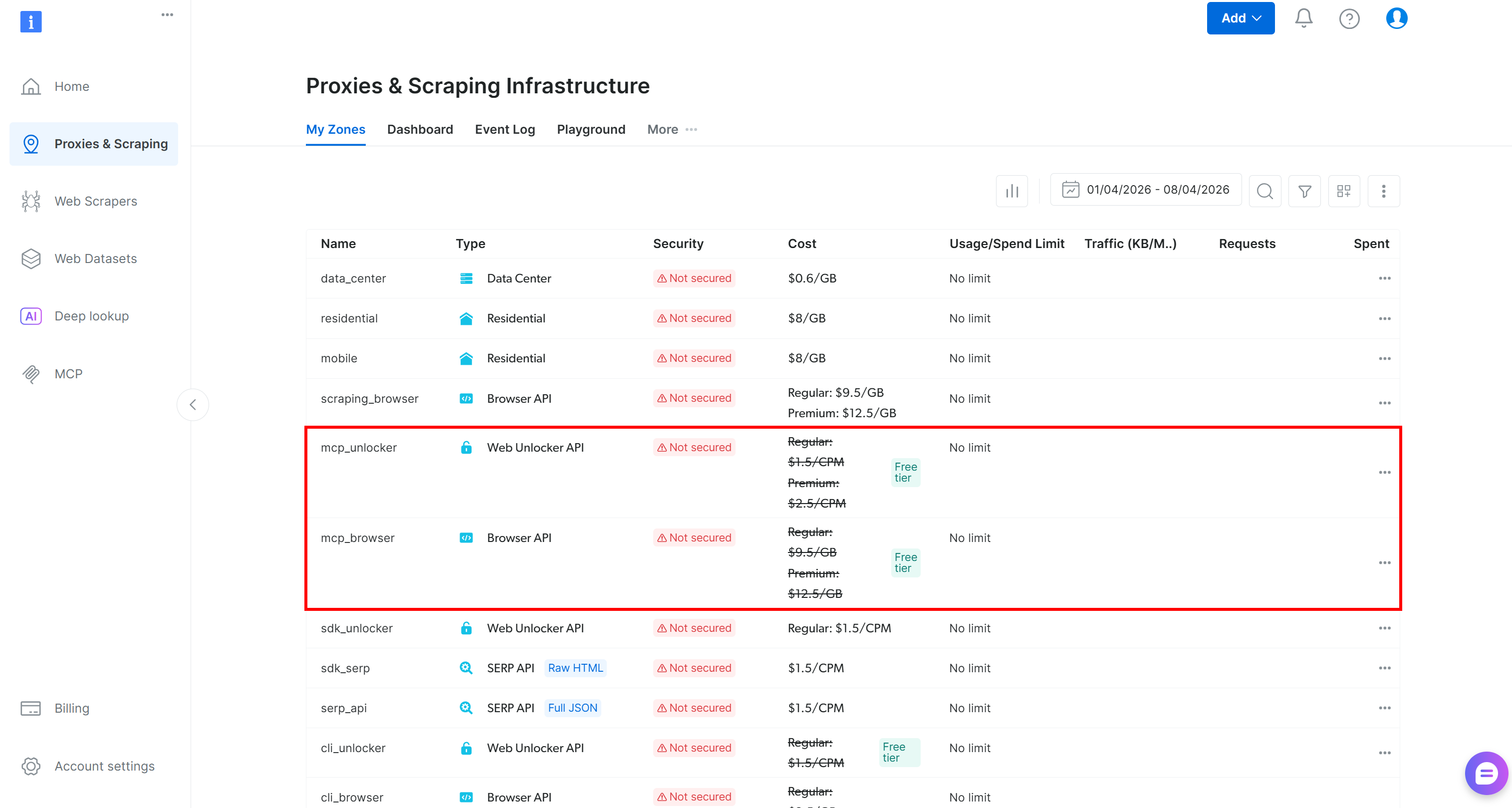
请记住,在 Web MCP 免费层(Rapid 模式)中,你只能访问一组有限的工具。
要解锁全部 70+ 工具,你必须启用 Pro mode。为此,设置 PRO_MODE="true" 环境变量:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或者,在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp注意:Pro mode 不包含在免费层中,并且会产生额外费用。
完美!你刚刚验证了 Bright Data Web MCP 能在你的机器上运行。接下来,你将配置 Zencoder Zenflow 以连接到它。
步骤 #2:在 Zenflow 中配置 Web MCP
所有 Zencoder 产品都支持 MCP 集成,通过位于 ~/.zencoder/settings.json 的配置文件实现。你可以手动编辑该文件,或通过 Zenflow UI 访问它。
对于 UI 工作流,先点击左下角的 “Settings” 图标:
然后导航到 “MCP Servers” 部分,你可以直接从 UI 编辑配置文件: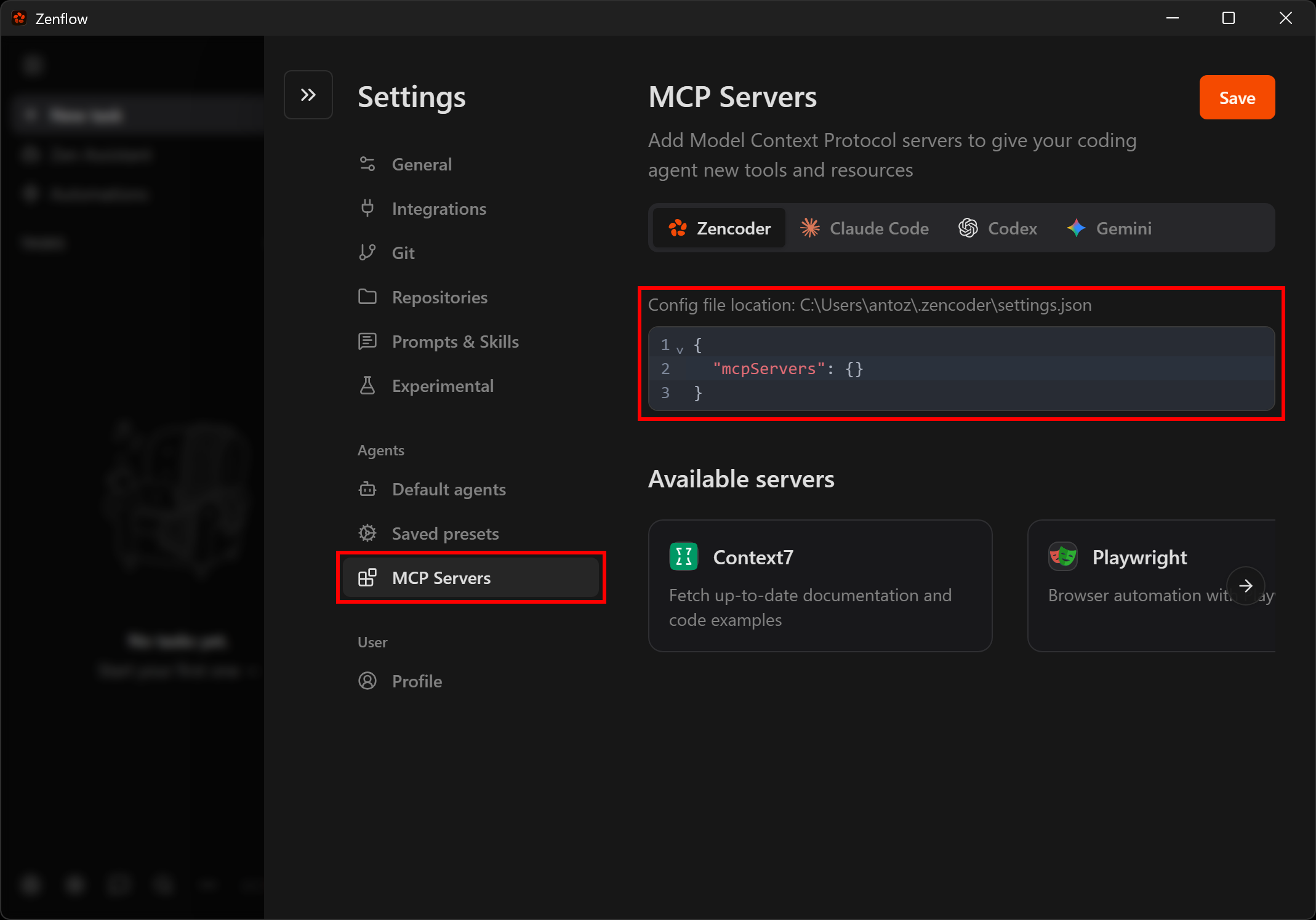
确保你的 ~/.zencoder/settings.json 文件包含以下内容:
{
"mcpServers": {
"bright-data-web-mcp": {
"type": "stdio",
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}如果你通过 UI 编辑,请输入相同配置并点击 “Save”: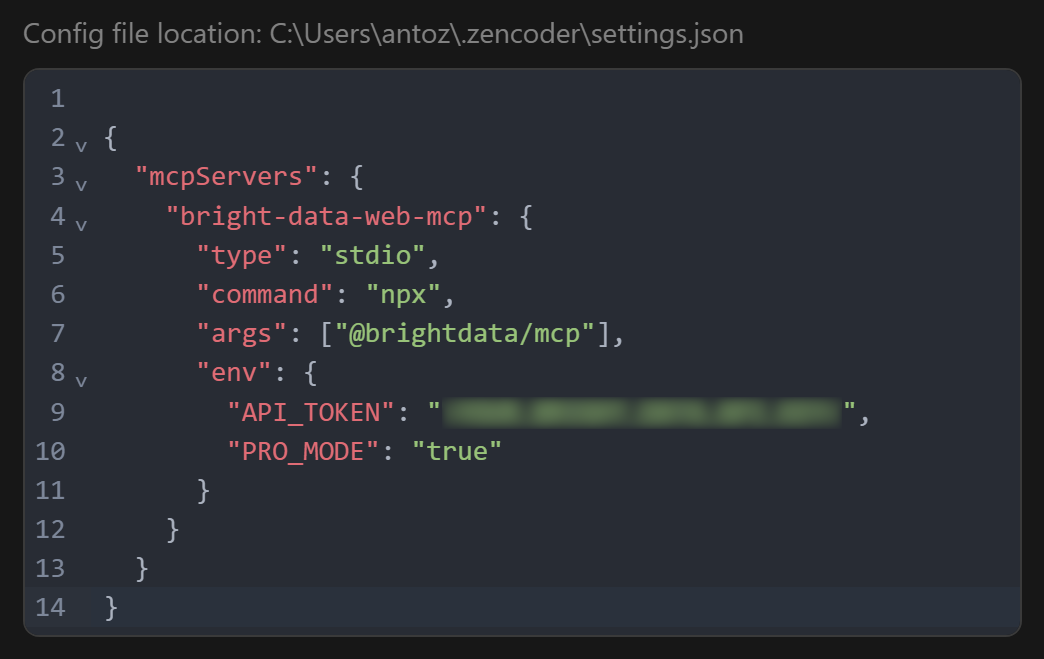
此设置镜像了你之前测试的 npx 命令,并使用环境变量进行身份验证与配置:
API_TOKEN(必需):你的 Bright Data API key。PRO_MODE(可选):设置为"true"以启用 Pro 功能,或移除它以使用免费层。
配置完成后,Zencoder 将使用指定的 npx 命令启动本地 Web MCP 服务器并连接到它。太棒了!
步骤 #3:验证 Web MCP 连接
在撰写本文时,Zenflow 未提供直接的 UI 来检查可用的 MCP 工具。要验证连接,请切换到 Work 模式并发送如下提示:
Which MCP tools do you have access to?你应该会看到类似的结果: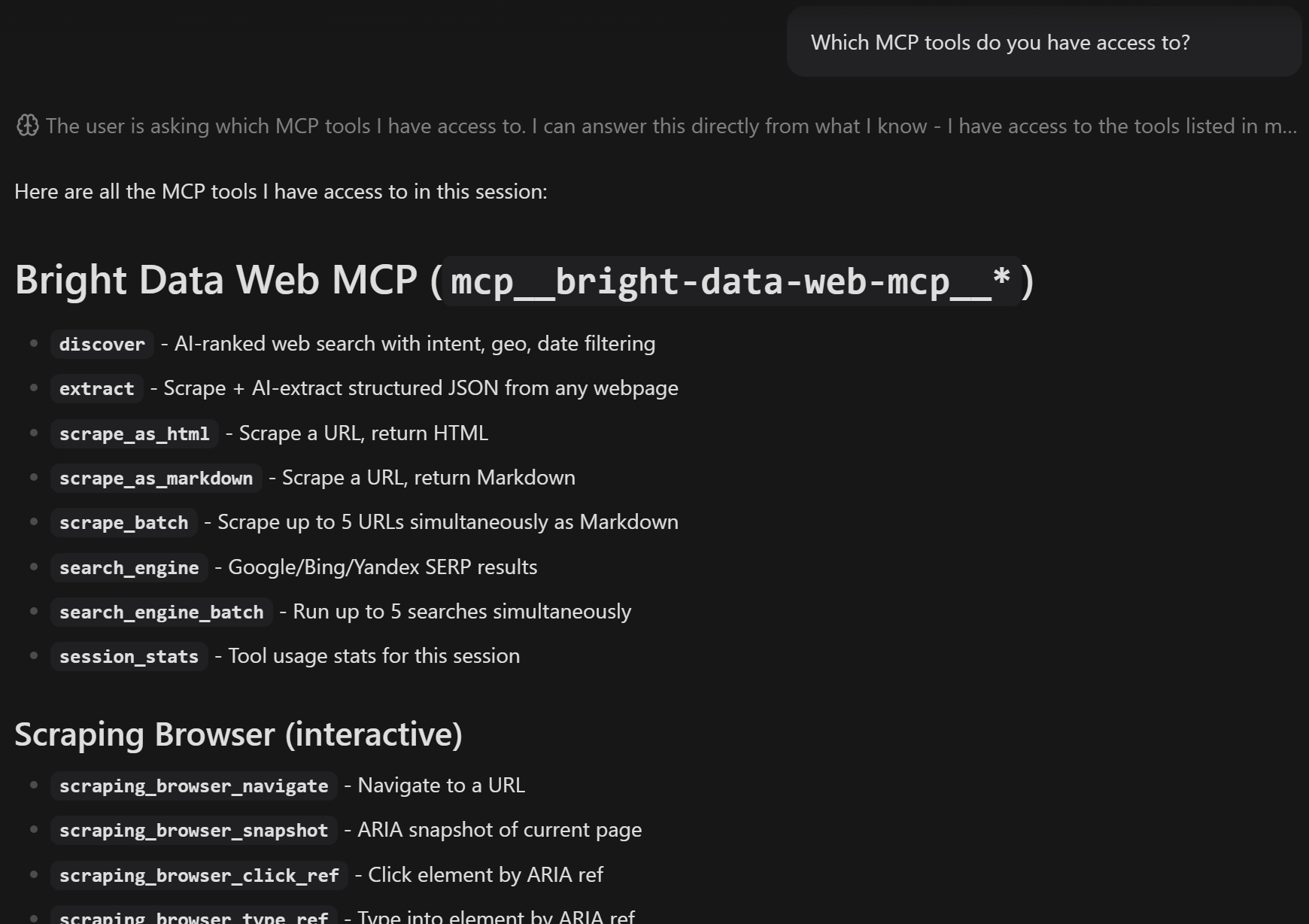
响应将列出所有可用的 MCP 工具。在 Pro mode 下,列表包含 70+ 个 Web MCP 工具。否则,你只会看到 Rapid(免费)模式下可用的工具。
很好!这确认 Bright Data Web MCP 已正确连接,并向你的 Zencoder 产品暴露工具。在本文后面,你将看到如何在真实工作流中将 Web MCP 与 Bright Data 技能 一起使用。
将 Bright Data skills 添加到 Zencoder
在这里,你将学习如何通过 Vercel 的 技能 工具提供的引导式工作流,将 Bright Data skills 添加到你的 Zencoder 设置中。
快速手动设置:如果你更喜欢手动方式,请先克隆 Bright Data 技能 仓库。然后,将 skills 复制到 ~/.zencoder/skills 目录中:
git clone https://github.com/bright-cn/skills
cp -r skills/skills/* ~/.zencoder/skills/否则,请按照下面更具引导性的方式操作!
前置条件
请确保你具备:
- 已在本地安装并配置 Bright Data CLI(这是 Bright Data 技能 的主要前置条件)。
- 对 Bright Data 技能 的基本了解。
注意:如需快速设置 Bright Data CLI,请参考 “Bright Data CLI: Installation & Setup” 指南。或者,阅读专门的博客文章。
对 Agent 技能 standard 的基本理解,以及对 Vercel 的 技能 CLI 工具 的一些熟悉也会有所帮助。
步骤 #1:安装 Bright Data skills
要在你的 Zencoder 环境中安装 Bright Data 技能,请运行:
npx skills add brightdata/skills -a zencoder上述命令会安装 技能 包并启动设置流程,该流程将:
- 从官方 Agent 技能 Directory 下载 Bright Data skills。
- 将它们配置为可跨所有 Zencoder 产品使用,包括 Zenflow 和 IDE 插件
你首先会看到一个界面,可选择要安装哪些 技能: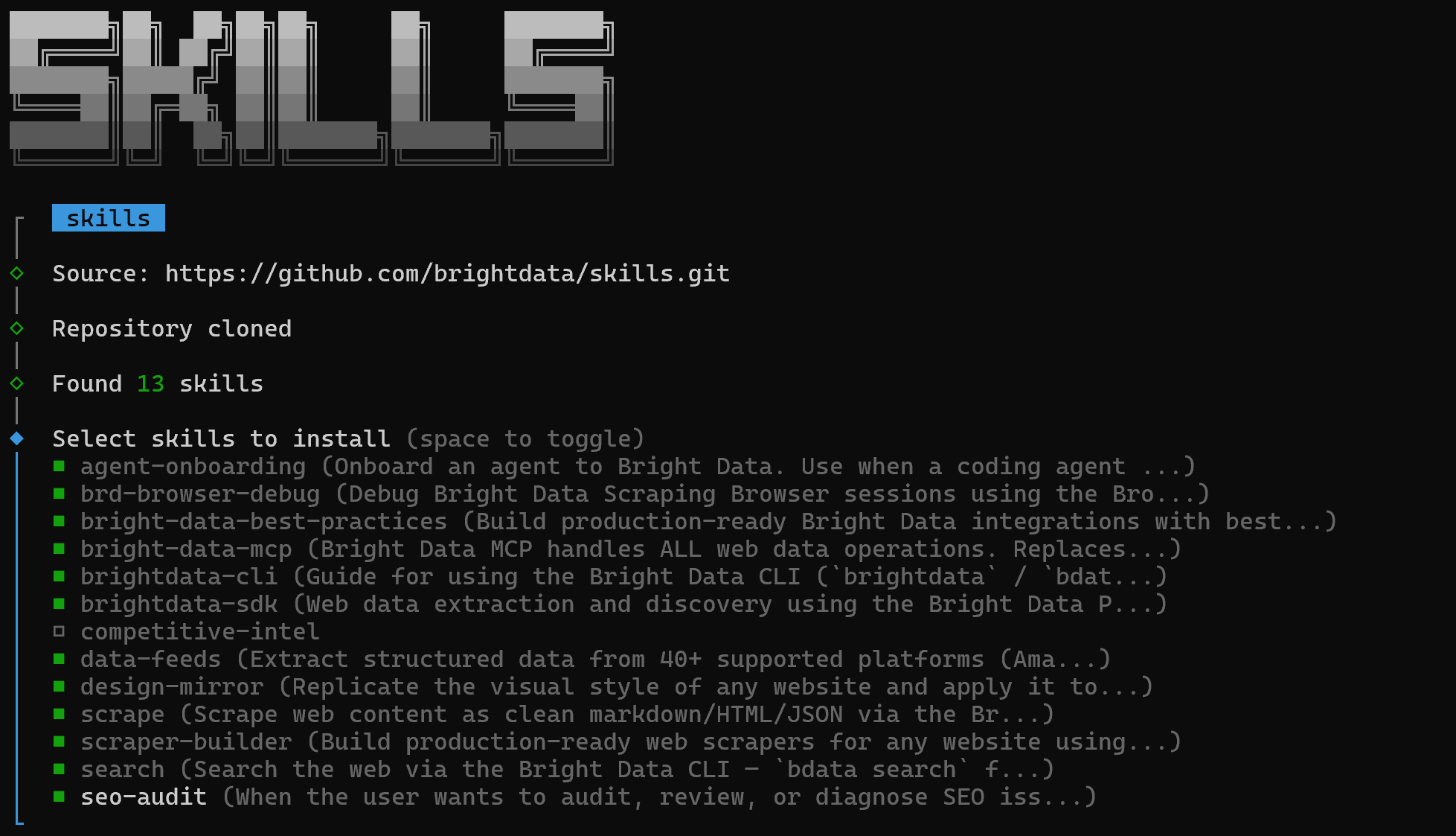
要安装全部内容,请使用空格键选择每个 skill,然后按 Enter。
接着,系统会提示你选择安装范围。由于 Web MCP 集成是全局配置的,你也应全局安装 Bright Data 技能。因此,选择 “Global” 选项:
接下来,你将看到 “Installation Summary” 和 “Security Risk Assessment” 部分。仔细审阅两者并按 Enter 确认。最后,你将收到确认消息: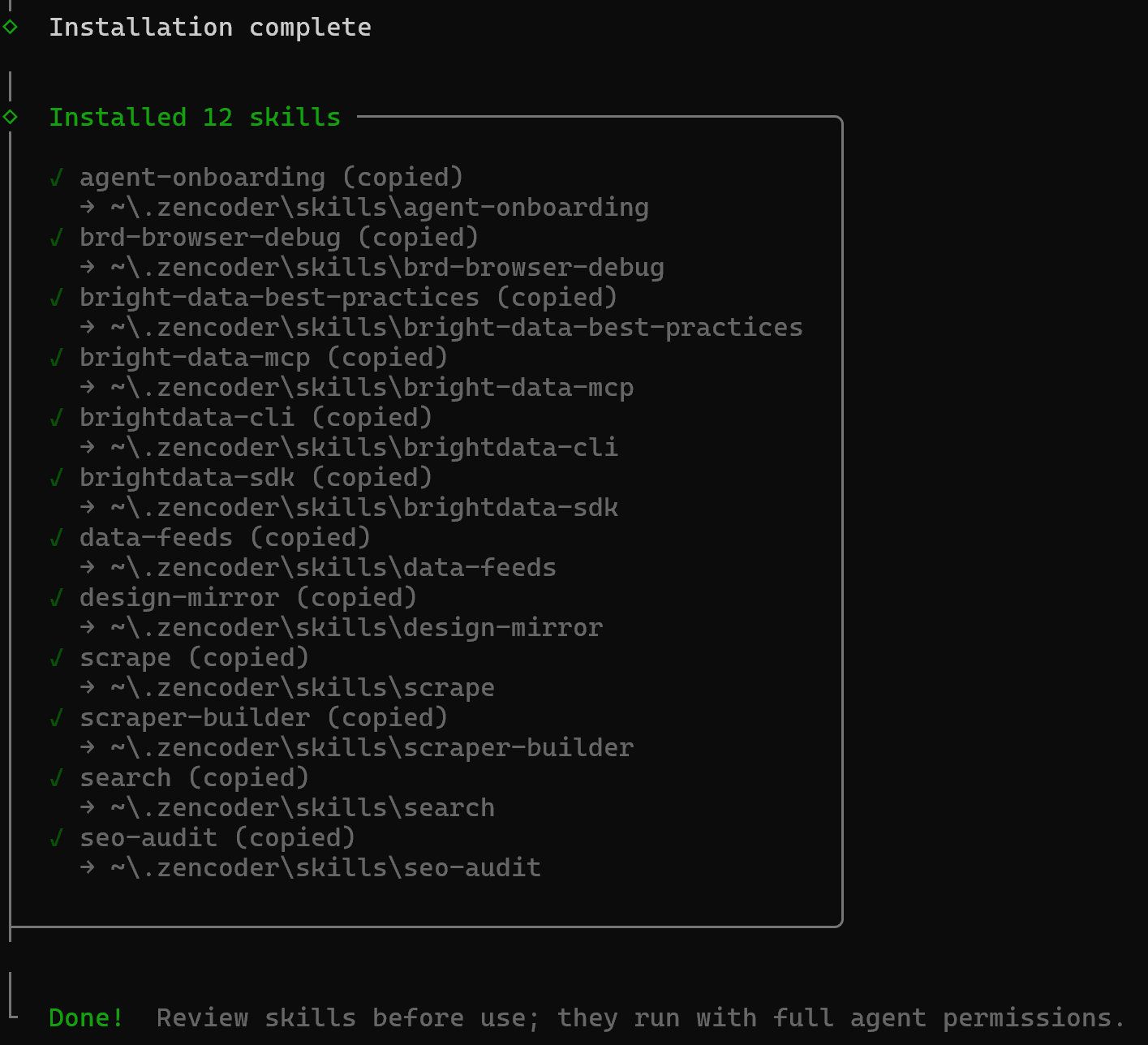
Bright Data 技能 将被安装到 ~/.zencoder/skills 目录中。重启你的 Zencoder 产品以确保加载更改。太棒了!
步骤 #2:验证 技能 是否可用
你现在应该可以将已安装的 skills 作为特殊命令访问。要验证这一点,请在 Zencoder 中按 /,并检查 Bright Data 技能 是否出现在列表中(与默认的 Zencoder skills 一起):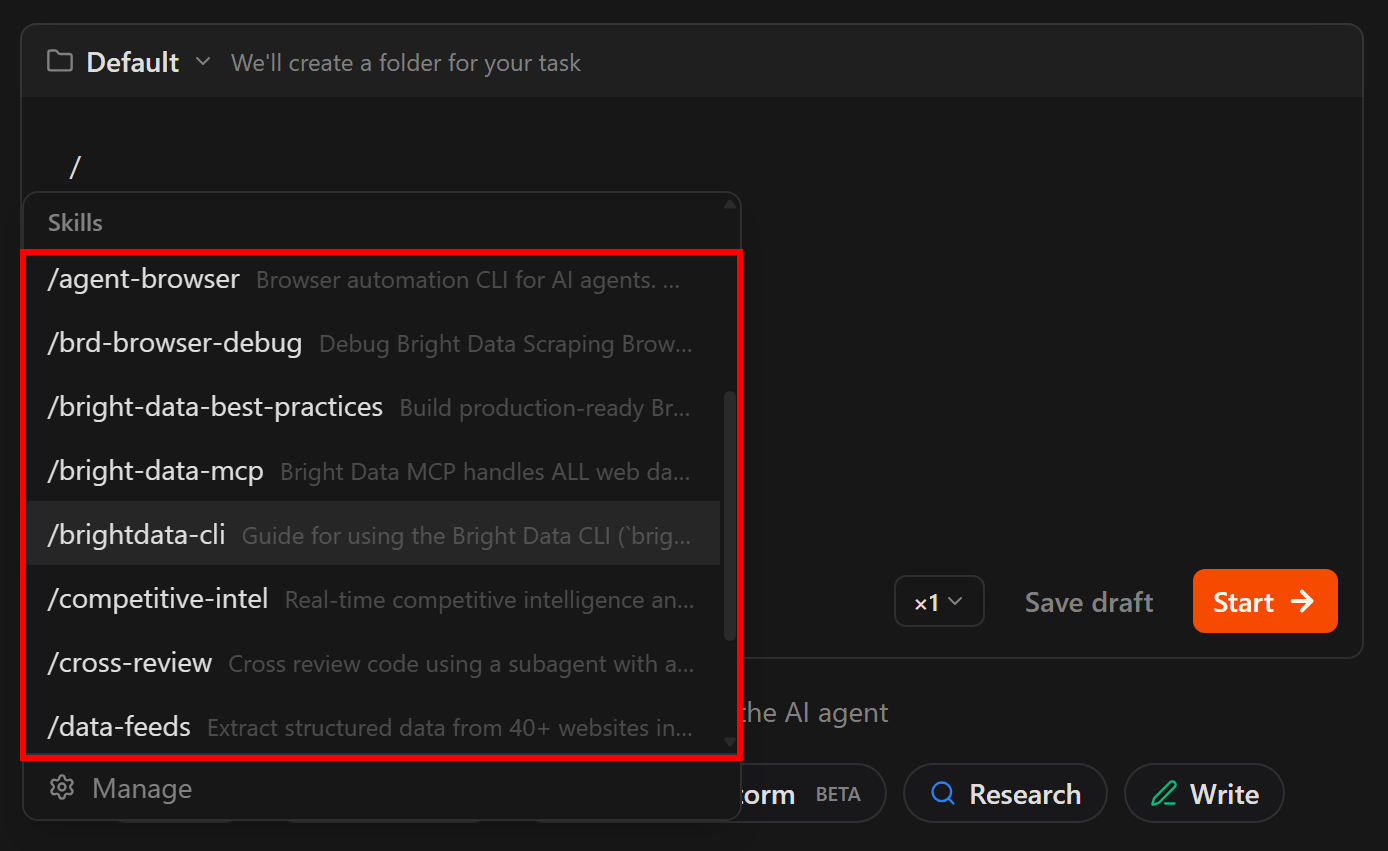
列出的命令应与 Bright Data 技能 匹配,从而确认安装成功。
重要:如果 skills 未出现,请重启你的 Zencoder 产品。在 Zenflow 中,确保 技能 也被复制到 ~/.agents/skills(你也可以使用 npx skills add brightdata/skills -a cline 将它们安装到该文件夹中)。然后,重启 Zenflow。
可选:如果你尚未配置 Bright Data CLI,请运行 onboarding skill 并按照说明操作:
/agent-onboarding
任务完成!在下一章中,你将看到如何在 Zencoder AI 代理中充分利用 Bright Data Web MCP 和 技能。
Zencoder + Bright Data:更高阶的 AI 辅助体验
为了验证 Zencoder + Bright Data 设置有多强大,请考虑一个需要真实世界网页数据的具体任务。
假设你正在为当前项目寻找最佳的 Python 哈希库。
在这种场景下仅依赖 LLM 可能存在风险。毕竟,AI 模型可能不了解最近的更新、安全问题、影响特定库的 CVE,或底层算法的变化。因此,让代理以实时网页数据为基础非常重要。
你可能还希望从 PyPI 或 GitHub 等来源抓取信息。这将为 AI 代理提供关于依赖项、安装命令、维护状态等方面的额外细节。
使用如下提示实现目标:
Discover online the best Python libraries for hashing. Start by performing a contextual search on Google, access the most relevant 2-3 pages, and then select a list of the top 5-7 Python libraries. For each library, scrape structured data from its PyPI page.
With the scraped data, produce a final structured report with a ranking, including for each library: a description, main capabilities, installation instructions, and (if available) requirements, GitHub links, and other relevant details.在 Work 模式下运行它,随后应发生如下情况: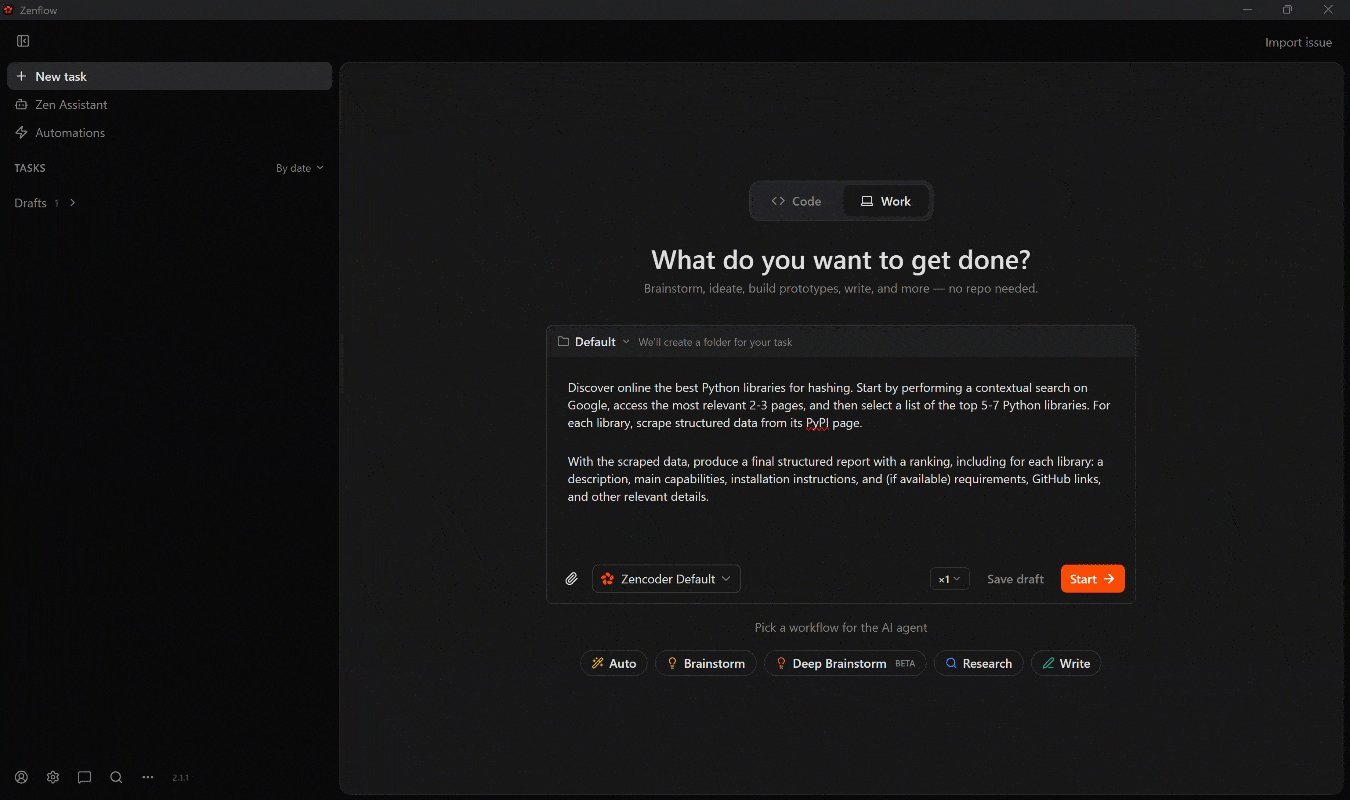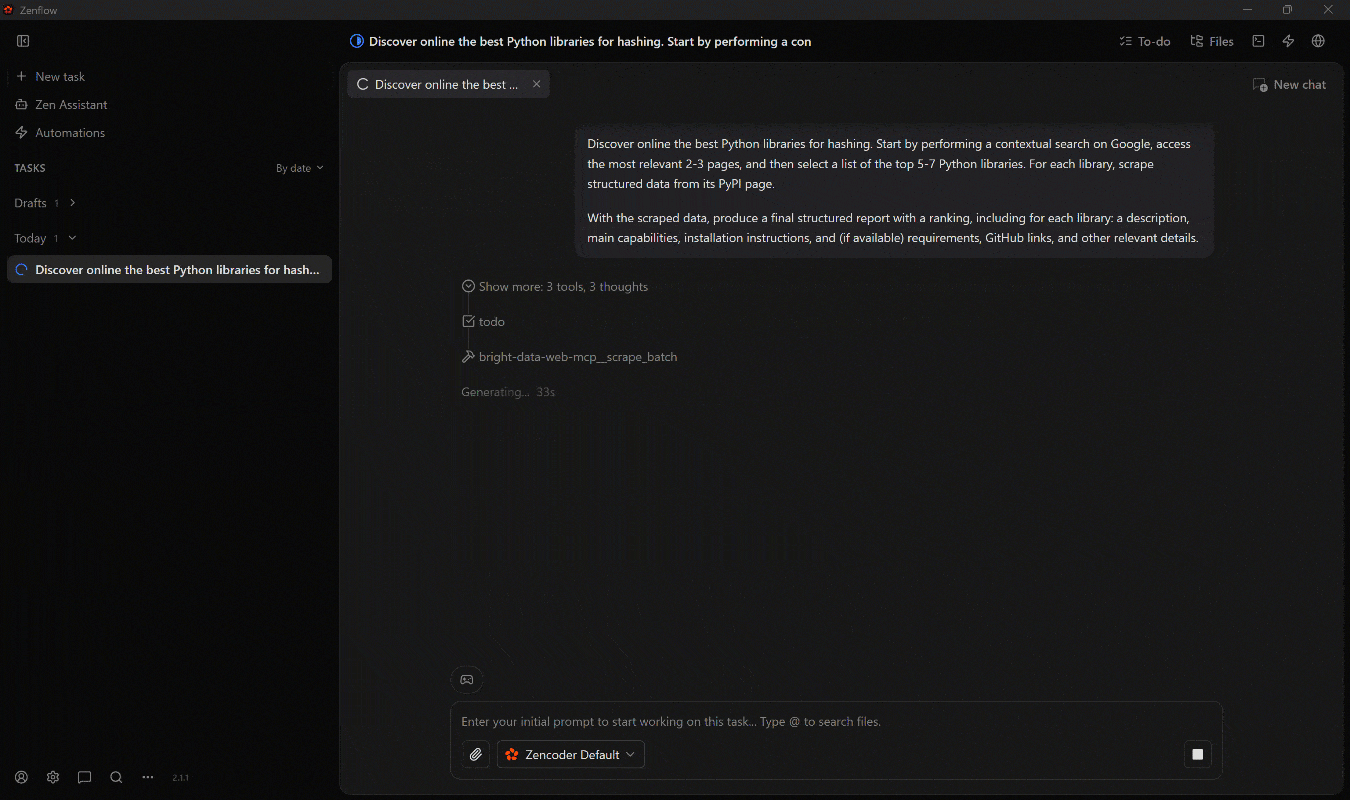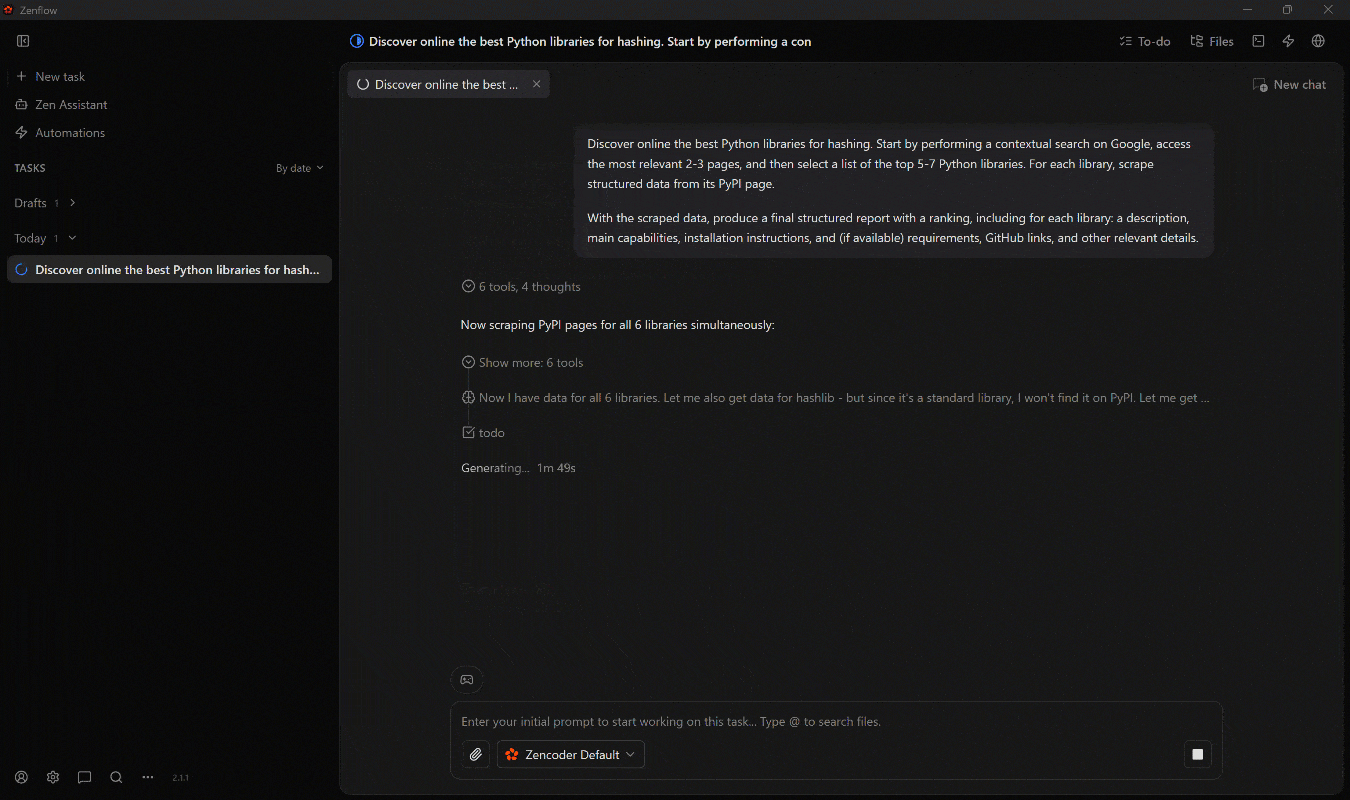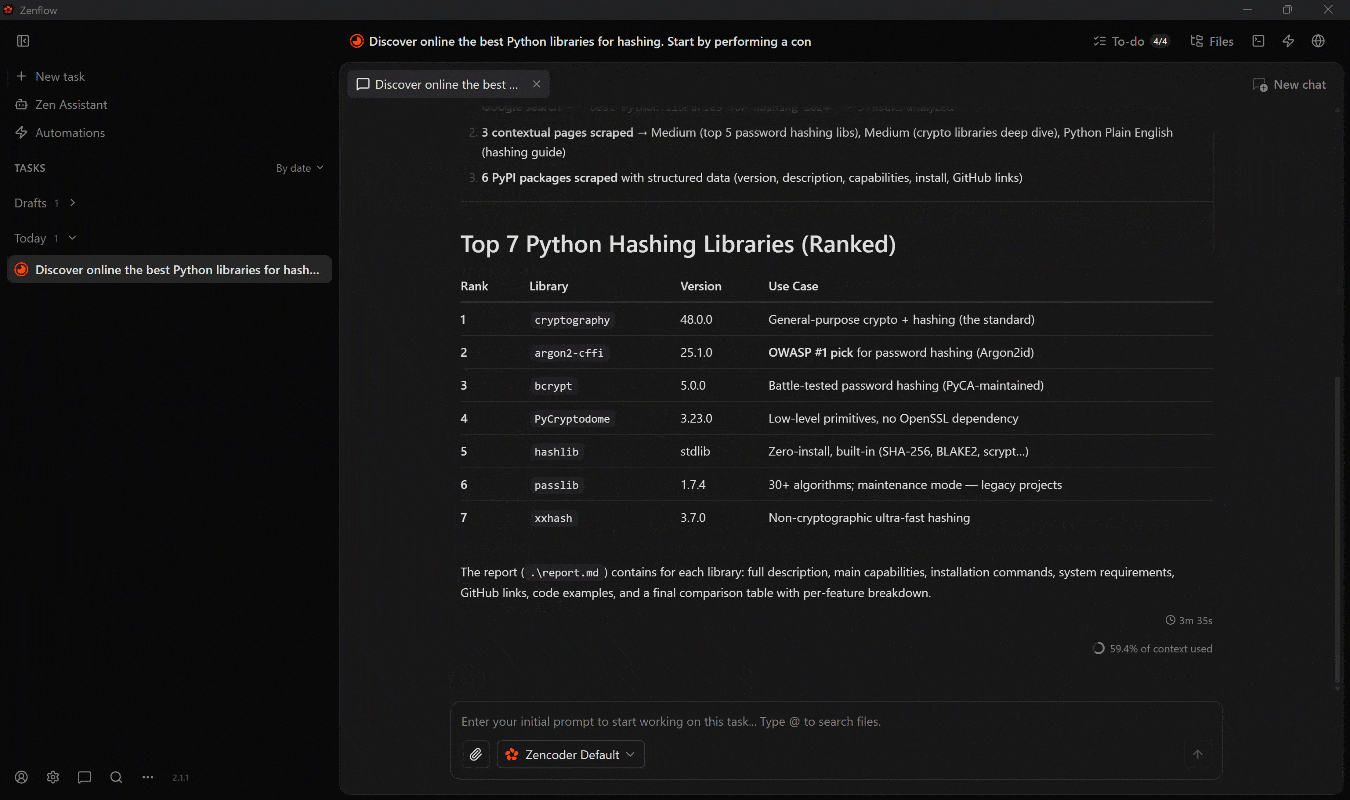
发生了以下情况:
- 代理首先定义一个计划。
- 它使用 Web MCP 中的
search_engine工具(由 Bright Data 搜索引擎 API 支持)来检索具上下文的 Google SERP 结果。 - 它选择最相关的页面,并使用
scrape_batch(通过 网络解锁器 API)对其进行抓取。 - 它识别出最相关的 7 个库,并通过并行调用
web_data_pypi_packageWeb MCP Pro 工具,用结构化 PyPI 数据对其进行丰富。 - 它将所有收集的信息聚合到最终的
report.md文件中。
最终输出是在项目目录中的一个 report.md 文件: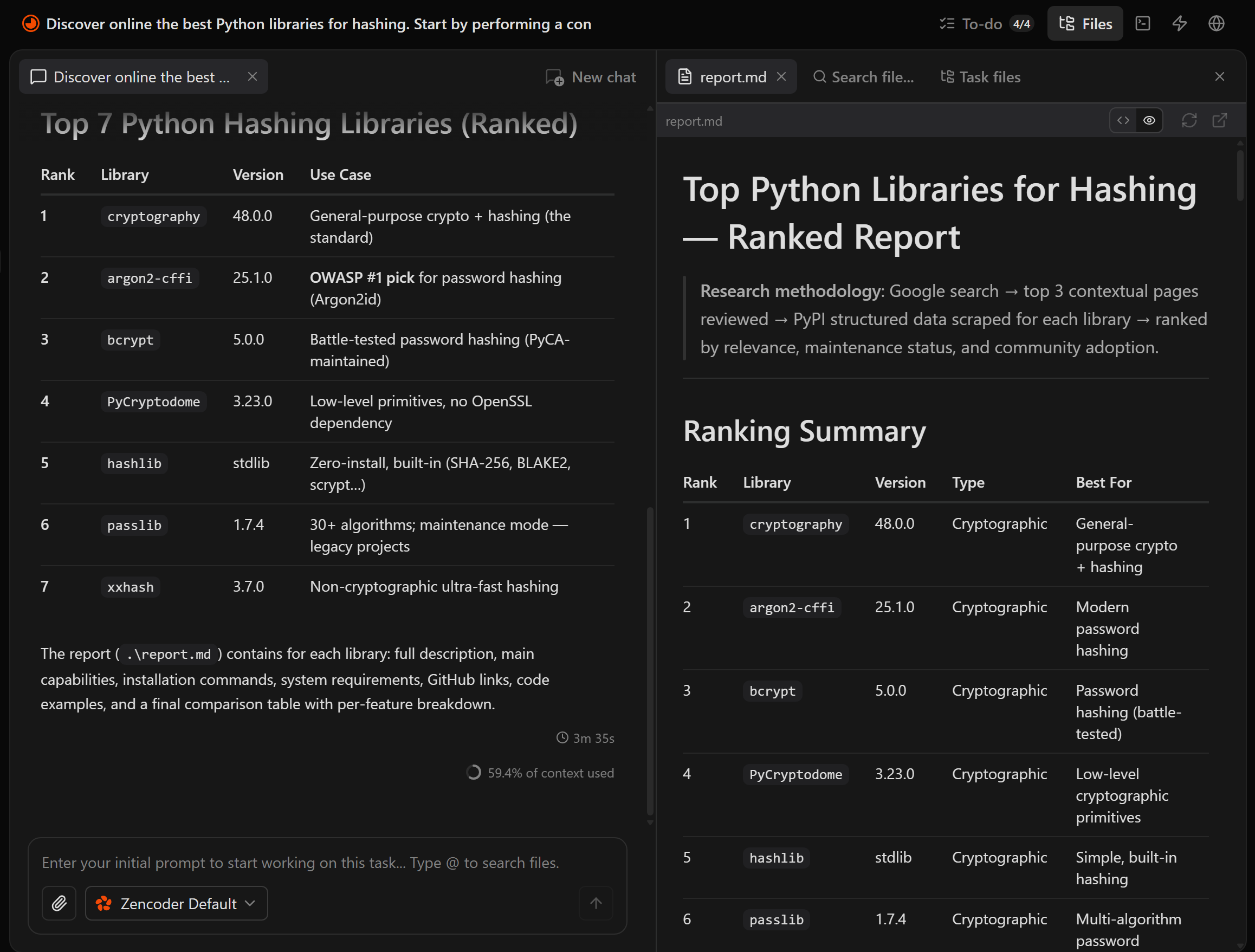
打开它,你将看到一份结构化的 Markdown 报告,其中包含详细、可验证的信息。聚焦于某个 Python 哈希库: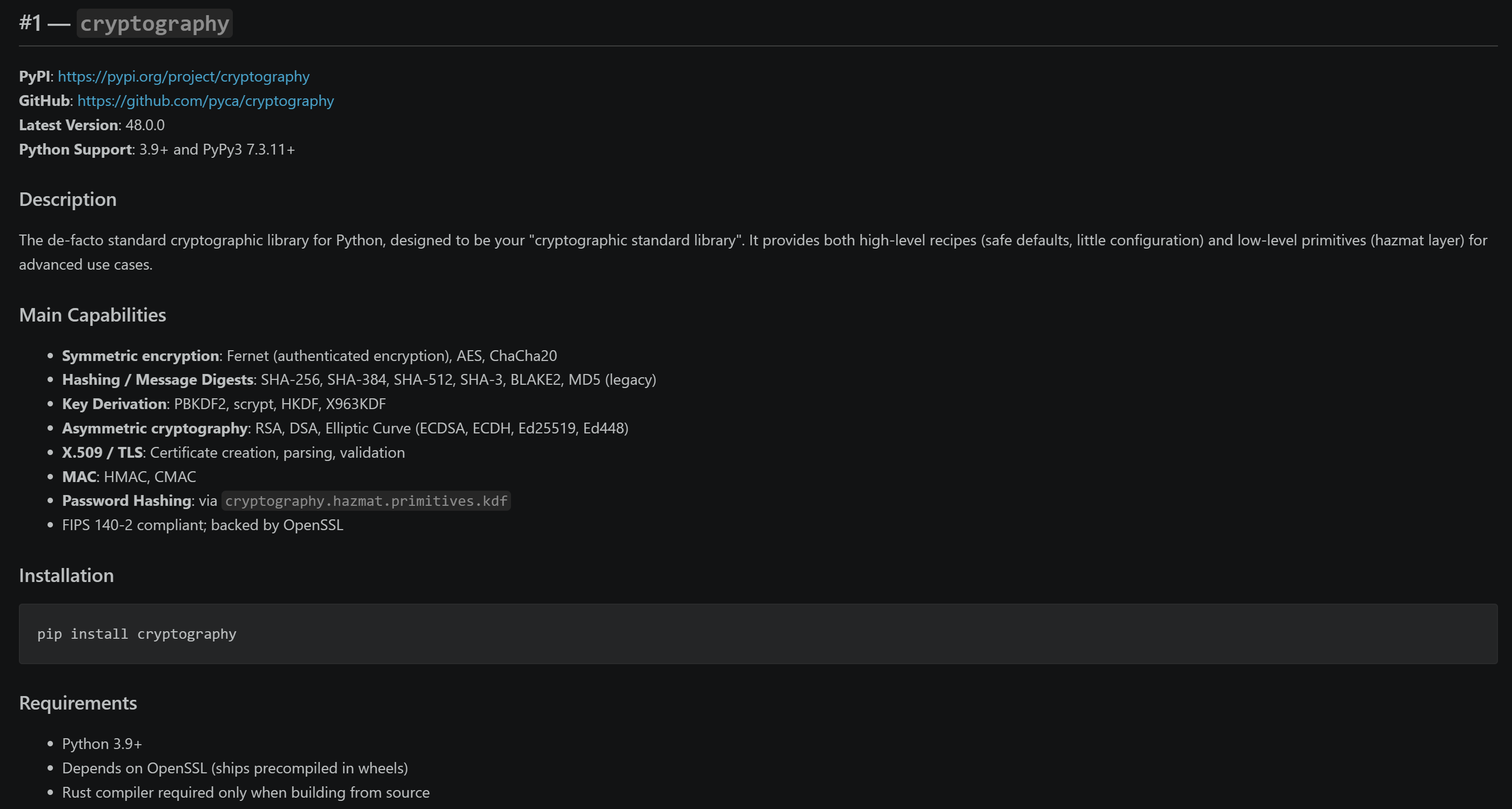
注意每个库部分都是基于实时 PyPI 数据,而不是仅基于模型训练知识。
该报告还包含一个对比表以支持决策: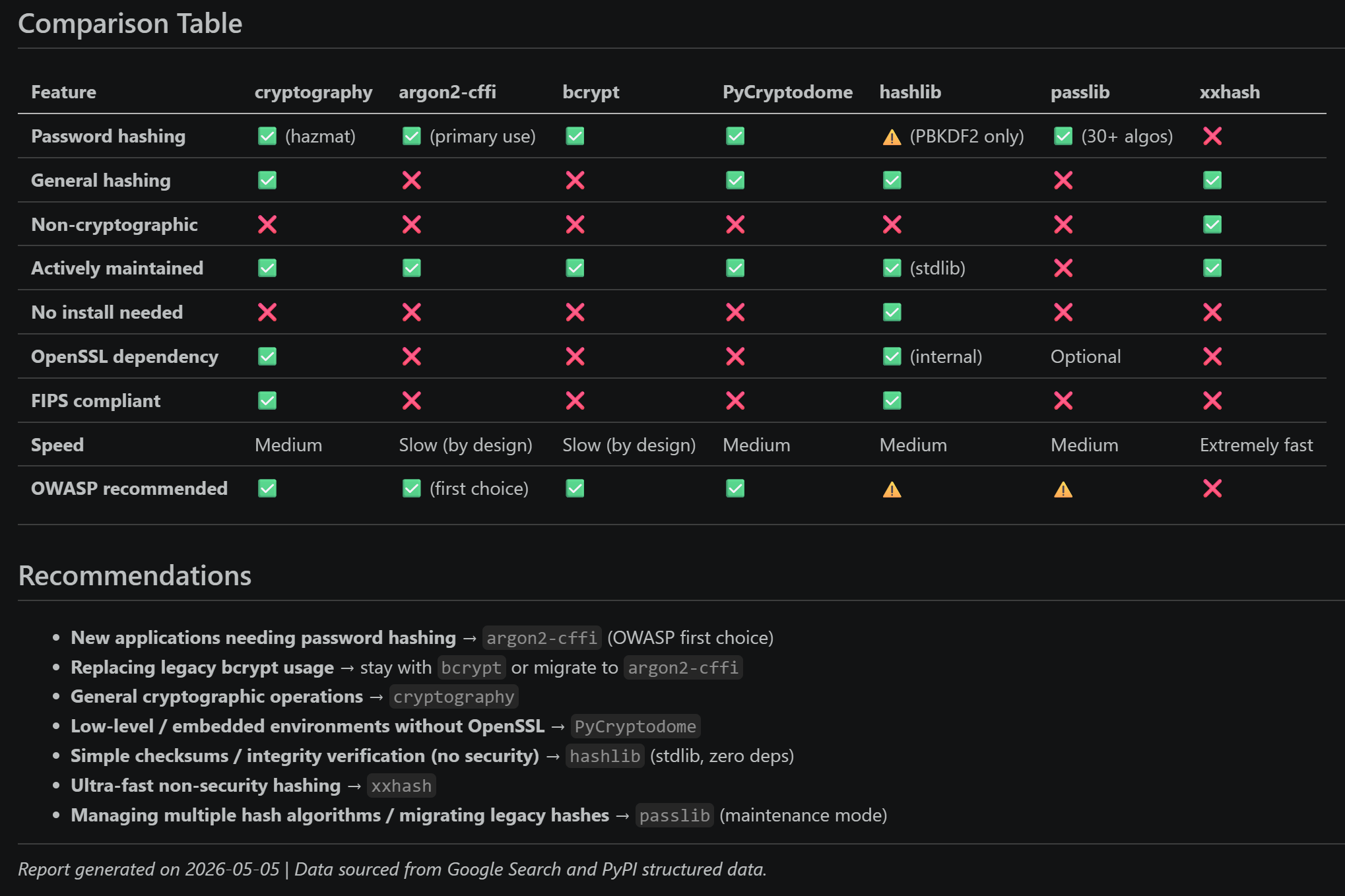
瞧!这个简单示例展示了将 Bright Data 集成到 Zenflow Work(或任何其他 Zencoder 产品)中的价值。Zencoder 代理现在可以从网页检索 AI 就绪的最新信息,在广泛的用例中生成更可靠的输出。
结论
在本教程中,你了解了 Zencoder 是什么,以及它通过 Zenflow 及其 IDE 插件提供哪些功能。特别是,你看到了为什么以及如何通过 Web MCP 和 其官方 技能 将 Zencoder 产品连接到 Bright Data,从而扩展它们。
该集成极大增强了 Zencoder AI 编码辅助体验。得益于它,底层 AI 代理获得了与网页交互的能力,可用于 grounding、研究以及自动化浏览器操作。
如需更高级的工作流,请探索 Bright Data 生态系统中完整的 AI 能力服务范围。
立即创建一个免费的 Bright Data 账户,并开始集成我们面向 AI 基础设施就绪的网页数据工具!



高级 SEO 专家
 6 years experience
6 years experience
Daniel Shashko 是 Bright Data 的高级 SEO/GEO 专家,专注于 B2B 营销、国际 SEO,以及开发 AI 驱动的代理、应用与网页工具。




