

在本教程中,你将学习:
- 如何设置 Snowflake 以接收来自 Bright Data 交付基础设施的数据。
- 配置 Goodreads Books 数据集以直接交付到 Snowflake 内部 stage。
- 触发一个快照并将其加载到可查询的表中,然后针对 600 万+ 条图书记录运行 SQL。
让我们开始吧!
展示 Snowflake 导入工作流
从高层来看,该管道有三个阶段,每个阶段都在其各自的章节中介绍:
- Snowflake 设置:创建数据库、stage、role,以及 Bright Data 将用于认证的服务用户。这是 SQL 最密集的部分,但每条命令都完整给出并按顺序运行。
- Bright Data 配置:从 marketplace 选择一个数据集,将其连接到你的 Snowflake 环境,并触发一个快照。Bright Data 将文件直接推送到你的内部 stage。
- 加载与查询:一条
COPY INTO命令将已暂存的文件移动到结构化表中。其余部分是标准 SQL。
输出是一个完全可查询的 Snowflake 表,填充了结构化的网络数据,并按你的用例所需的任意计划刷新。无需 CSV 导出,无需自定义 ETL 胶水代码。
了解每个阶段的更多信息以及如何实现它们!
1. Snowflake 设置
Bright Data 通过直接认证进入你的 Snowflake 账户来交付文件。这需要一个专用的内部 stage(传入文件的落地区域)、一个对该 stage 具有写入权限的服务 role,以及一个分配给该 role 的服务用户。
为此目的使用专用对象可以将导入与分析工作负载分离,并使以后更容易审计、撤销或轮换凭据。
2. Bright Data 数据集配置与快照交付
Bright Data 的 数据集 Marketplace 包含预构建、已验证的数据集,覆盖 Amazon、LinkedIn、Crunchbase、Glassdoor、酒店列表、房地产、职位发布等。每个数据集都附带完整的字段参考,因此你可以在第一个字节到达之前设计你的 Snowflake schema。
直接 Snowflake 交付适用于 数据集 产品。如果你使用的是 Web 爬虫工具 APIs,则将文件交付到 S3 bucket 并从外部 stage 加载。
一旦你将 Snowflake 配置为交付目的地,Bright Data 就会处理传输。它使用你创建的服务用户进行认证,将文件暂存到你的内部 stage,并在 控制面板 中记录交付。你可以按需、按计划或通过 Marketplace 数据集 API 触发快照。
3. 加载与查询
当文件进入 stage 后,一条 COPY INTO 命令即可将它们加载到你的表中。从那里开始,你使用标准 SQL 查询,无需特殊语法,也无需新工具。
设置 Snowflake 以接收 Bright Data
让我们从准备 Snowflake 端开始构建该管道。本节中的所有命令都在 Snowsight 的 SQL worksheet 中运行或通过 SnowSQL 运行。先运行以下内容以确保你拥有创建数据库、role 和用户所需的权限:
USE ROLE ACCOUNTADMIN;先决条件
要跟随本节内容,你应具备:
- 一个具有
ACCOUNTADMIN或SYSADMIN权限的 Snowflake 账户。 - 对 Snowflake UI(Snowsight)的基本熟悉。
步骤 #1:创建数据库和 schema
在 Snowflake 中,database 是所有数据对象的顶层容器。schema 位于 database 内部,并将相关的表、stage 和其他对象分组在一起。为 Bright Data 创建专用的 database 和 schema 可将其对象与现有数据分离,并使权限更易于管理。
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;如果你愿意,也可以使用现有的 database。在后续命令中,凡是出现 bright_data_db 的地方都替换为其名称。
步骤 #2:创建专用 warehouse
在 Snowflake 中,warehouse 是执行 SQL 语句(包括 COPY INTO)的计算集群。它与存储分离,这意味着你只在其实际运行时为计算付费。为 Bright Data 导入创建专用 warehouse 可使这些计算成本可见,并防止导入工作负载与分析查询争夺资源。
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60 会在 60 秒无活动后关闭 warehouse,以便它不会在交付间隙空转。AUTO_RESUME = TRUE 会在下一次 COPY INTO 运行时自动将其恢复。XSmall 可以轻松处理大多数 Bright Data 交付。如果数据量增长,请调整大小。
步骤 #3:创建内部命名 stage
在 Snowflake 中,stage 是在加载到表之前文件所处的命名位置。内部命名 stage 位于 Snowflake 内部本身。无需 S3 bucket 或外部云存储。
该 stage 是 Bright Data 与你的表之间的桥梁。Bright Data 不会逐行将数据直接加载到表中,而是先将结构化文件(Parquet 或 JSON)存入 stage。随后 Snowflake 通过 COPY INTO 批量读取这些文件,这比逐行插入显著更快且更具成本效率。它还为你提供了一个检查点:你可以检查 stage 中的文件,验证它们看起来正确,并选择何时触发加载。
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';步骤 #4:创建 role 并授予正确权限
在 Snowflake 中,role 是可分配给用户的一组权限。与其直接向用户授予权限,不如将权限授予 role 并将该 role 分配给用户。这使得以后无需触及用户账户本身即可轻松撤销或修改访问权限。
该 role 仅为 Bright Data 提供其所需的访问权限,不多也不少。
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;以下是每个 grant 的作用以及为何需要它:
- 对 database 和 schema 的 USAGE:允许该 role 查看并导航到其中的对象。没有它,即使该 role 直接对 stage 具有权限,Snowflake 也会返回“object does not exist”错误。
- 对 warehouse 的 USAGE:允许该 role 针对该 warehouse 执行 SQL 语句。这使
COPY INTO能够实际运行。 - 对 warehouse 的 OPERATE:允许该 role 在 warehouse 被挂起时将其恢复。没有它,当 Bright Data 触发加载时,自动挂起的 warehouse 将无法恢复。
- 对 stage 的 READ:
COPY INTO需要它来将文件从 stage 读取并加载到表中。 - 对 stage 的 WRITE:Bright Data 首先将文件存入 stage 需要它。
步骤 #5:创建 Bright Data 服务用户
服务用户 是为系统或应用程序而非个人创建的 Snowflake 账户。使用专用服务用户意味着 Bright Data 的访问与任何人类用户账户隔离,并且你可以轮换或撤销其凭据而不影响其他人。
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSE 可防止 Snowflake 在首次登录时提示重置密码,否则会破坏自动化连接。DEFAULT_ROLE、DEFAULT_WAREHOUSE 和 DEFAULT_NAMESPACE 确保服务用户无论会话如何发起,都始终在正确的上下文中连接。最后一行将 bright_data_loader role 分配给该用户,使其拥有步骤 #4 中定义的全部权限。
请安全存储用户名和密码。你将在下一节将它们粘贴到 Bright Data 控制面板 中。
步骤 #6:将 Bright Data 的 IP 加入允许列表(如果你使用 Network Policy)
如果你的 Snowflake 账户强制执行 Network Policy,则需要将 Bright Data 的交付服务器添加到允许列表。以下 IP 在撰写时是最新的。在应用之前,请与 Bright Data 支持或其文档核实最新范围,因为静态 IP 可能会变化:
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);如果你的账户没有启用任何 Network Policy,请跳过此步骤。
步骤 #7:创建目标表
本教程以 Goodreads 图书数据为示例。下面的 schema 直接映射到 Bright Data 的 Goodreads Books 数据集以 JSON 形式交付的字段名称:
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANT 是 Snowflake 的半结构化类型。它按原样存储数组和嵌套对象,并允许你使用点表示法和括号语法(author[0]:name, community_reviews['5_stars']:reviews_num)进行查询。这避免了在加载时扁平化复杂的嵌套字段。你可以在之后通过视图或 LATERAL FLATTEN 在确定需要哪些子字段后再进行处理。
一些值得理解的字段决策:
author作为 VARIANT:每本书可以有多个作者。该字段以对象数组形式到达。将其存储为 VARIANT 可保留所有作者数据,而无需单独的 join 表。genres作为 VARIANT:genre 也是一个数组。一本书可以属于多个 genre。当你需要按 genre 查询时,使用LATERAL FLATTEN(INPUT => genres)将其扁平化。num_reviews作为 VARCHAR:Bright Data 的数据字典将该字段标记为 Text 而非 Number,这意味着它可能以格式化形式到达(例如"1,234"而不是1234)。如果你需要对其进行聚合,请在查询时使用TO_NUMBER(REPLACE(num_reviews, ',', ''))进行转换。community_reviews作为 VARIANT:包含按星级划分的评分明细,每个星级都有数量和百分比。将其存储为 VARIANT,并按需查询特定星级。
注意:如果你从 marketplace 选择不同的数据集(LinkedIn 公司、职位发布、Amazon 产品等),请调整 schema 以匹配其字段列表。Bright Data 在 控制面板 中每个数据集页面上都为每个数据集提供完整字段参考。
太棒了!你的 Snowflake 环境现在已准备好接收来自 Bright Data 的数据。
配置 Bright Data 交付到 Snowflake
Snowflake 端就绪后,让我们配置 Bright Data 将数据推送到其中。
先决条件
要跟随本节内容,你应具备:
- 一个具有有效订阅或试用的 Bright Data account。
- 上一节中的 Snowflake 连接详情:account identifier、username、password、database、schema、stage 和 warehouse 名称。
步骤 #1:选择一个数据集
登录你的 Bright Data account 并导航到 Web 数据集 > 数据集 Marketplace。搜索 Goodreads 并从结果中选择 Goodreads Books 数据集。
在数据集页面上,查看左侧面板中的字段列表。注意每个字段如何直接映射到你在步骤 #7 中创建的表中的列。这在单行数据到达之前就确认了你的 schema 是正确的。
步骤 #2:将 Snowflake 配置为交付目的地
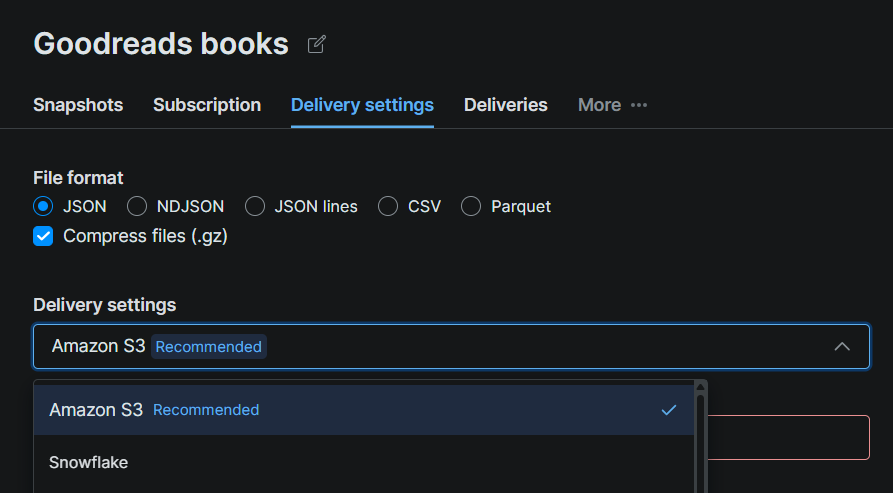
在数据集页面上点击 Delivery Settings 选项卡,并选择 Snowflake 作为目的地。使用你的 Snowflake 设置详情填写连接表单:
| 字段 | 值 |
|---|---|
| Account identifier | 你的 Snowflake account URL(例如 xy12345.us-east-1) |
| Database | bright_data_db |
| Schema | web_data |
| Stage | bright_data_stage |
| Warehouse | bright_data_wh |
| Role | bright_data_loader |
| User | brightdata_svc |
| Password | 你在步骤 #5 中设置的密码 |
连接表单下方的三个字段是可选的,在本教程中可以保留默认值:
- 数据集 file name:Bright Data 暂存的文件的自定义前缀。留空以使用默认命名。
- Batch size (number of records):Bright Data 打包到每个暂存文件中的记录数量。默认值适用于大多数工作负载。
- Group batches into one file (.tar):在暂存前将所有批次合并为一个归档文件。除非你的管道明确需要每次交付一个文件,否则保持不勾选。
点击 Test Snowflake。绿色确认表示 Bright Data 可以认证并写入你的 stage。测试通过后,点击 Save。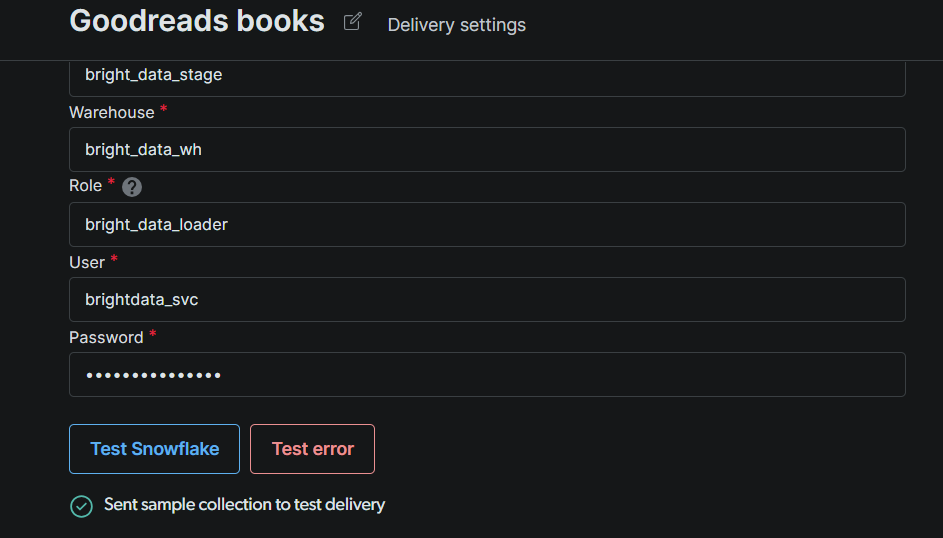
注意:如果测试失败,请按顺序检查三件事:(1) account identifier 格式(Snowflake 期望 orgname-accountname 或旧版 accountid.region.cloud 格式);(2) 服务用户是否拥有步骤 #4 中的所有 grants,包括 Role 分配;(3) 如果你的账户启用了 Network Policy,Bright Data 的 IP 是否已加入允许列表。
步骤 #3:请求一个快照
在数据集页面上,点击 Deliveries 选项卡。然后点击右上角的 Add delivery +。这会打开一个交付配置面板,你可以在其中选择目的地(Snowflake)、选择要交付的快照或日期范围,并确认。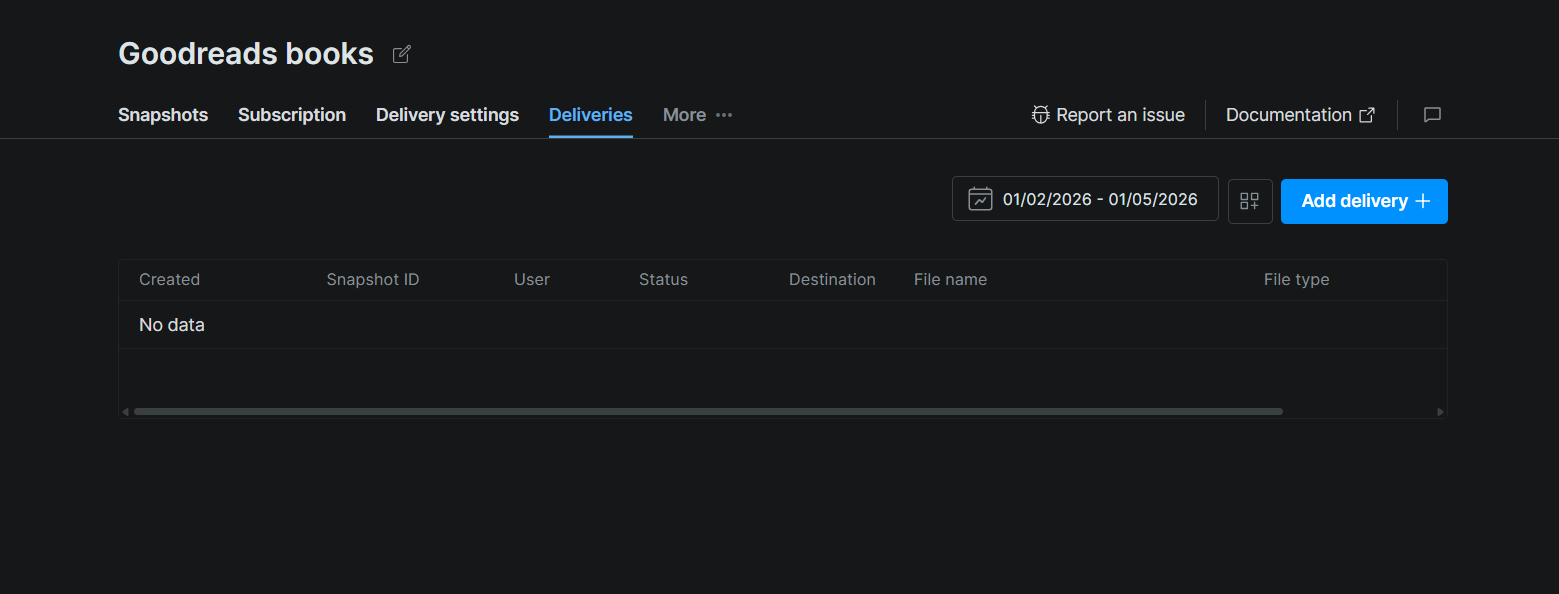
提交后,交付会出现在表格中,包含 Snapshot ID、Status、Destination、File name 和 File type 等列。当 Bright Data 完成将文件推送到你的 stage 后,Status 将从 pending 变为 complete。
要以编程方式触发交付,Marketplace 数据集 API 使用两步流程:首先调用 Filter API 创建一个过滤后的快照,然后调用 Deliver Snapshot 将其推送到你的 Snowflake stage。
步骤 1:创建过滤后的快照:
curl --request POST \
--url "https://api.brightdata.com/datasets/filter" \
--header "Authorization: Bearer YOUR_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'响应包含一个 snapshot_id。将其传递给下一次调用。
步骤 2:将快照交付到你的 Snowflake stage:
curl --request POST \
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver" \
--header "Authorization: Bearer YOUR_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"destination": "snowflake"
}'Bright Data 默认会使用为你的数据集配置的格式。如果你想显式指定,请在请求体中添加 "format": "parquet" 或 "format": "ndjson"。到达 stage 的格式就是你在 COPY INTO 的 FILE_FORMAT 中传入的格式。
轮询 GET /datasets/snapshots/YOUR_SNAPSHOT_ID 以检查交付状态,或在 控制面板 的 Deliveries 选项卡中监控。当 Status 列显示 complete 时,你的文件已在 stage 中并准备好加载。太棒了!
当交付完成时,你还会收到一封电子邮件,其中包含指向 控制面板 中快照页面的链接。在那里,你可以预览前 30 条记录、检查总记录数,并下载成本汇总报告。按 每 1,000 条记录 $2.50 计费,该报告会准确显示到达了多少条记录以及它们的成本。太棒了!
将数据加载到 Snowflake
当文件落入你的内部 stage 时,Bright Data 的工作就结束了。将它们加载到表中是你的责任,而且只需要一条 SQL 命令。这种分离值得理解:它意味着你可以控制何时运行加载、应用何种错误处理,以及多久刷新一次表。
先决条件
要跟随本节内容,你应具备:
- 已完成上面的 Snowflake 设置和 Bright Data 配置部分。
- 已确认快照交付已完成(通过电子邮件或 Bright Data 控制面板 中的快照页面)。
步骤 #1:确认文件已到达 stage
在做任何事情之前运行此命令:
LIST @bright_data_db.web_data.bright_data_stage;你应该会看到列出一个或多个文件及其大小和时间戳。如果 stage 为空,说明快照尚未完成交付。请在 Bright Data 控制面板 的快照页面检查其状态。
注意结果中的文件扩展名。Bright Data 用于交付的格式决定了你在下一步传给 COPY INTO 的 FILE_FORMAT。对于 UI 触发的快照,Bright Data 通常交付 NDJSON,除非你在配置交付时另有指定。对于使用 deliver-snapshot endpoint 的 API 触发快照,格式取决于你在请求体中传入的内容。如果你看到 .parquet 文件,请使用 TYPE = 'PARQUET'。如果你看到 .json 或 .ndjson 文件,请使用 TYPE = 'JSON'。
步骤 #2:将文件加载到表中
对于 Parquet 文件:
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';对于 JSON 或 NDJSON 文件:
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME(仅 Parquet)会自动映射列名,因此顺序无关紧要。ON_ERROR = CONTINUE 会跳过格式错误的行,而不是中止整个加载。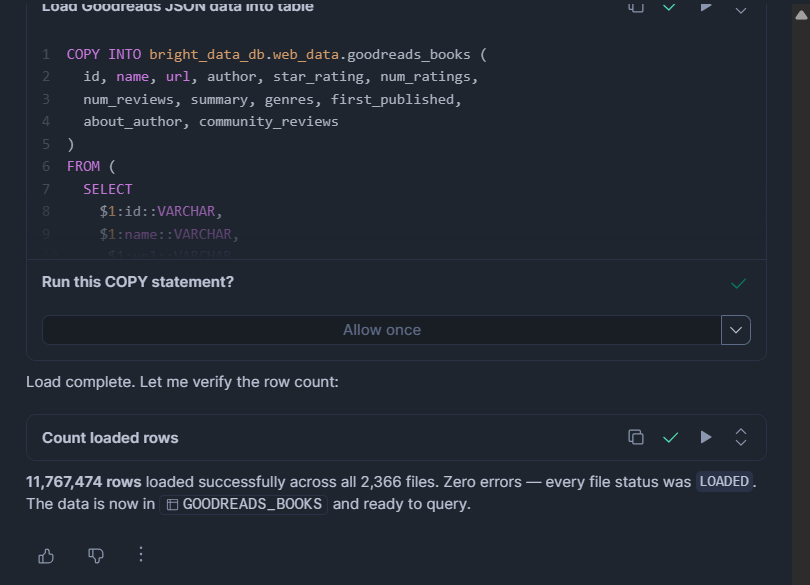
步骤 #3:验证加载
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORY 显示已加载行数、已跳过行数、已处理的文件名,以及任何失败行的确切错误消息。每次加载后都要查看它,尤其是第一次。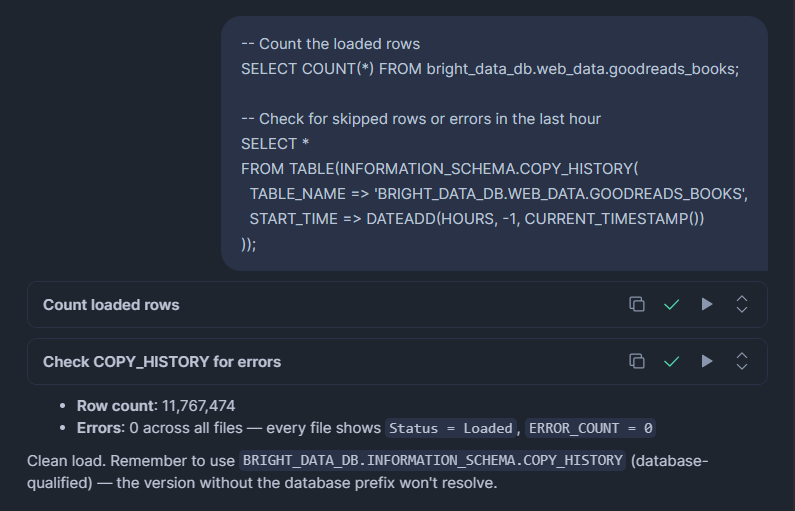
查询数据
当 Goodreads 图书数据进入 Snowflake 后,其价值在于跨数百万个标题规模化理解阅读趋势、作者表现和 genre 热度。下面的查询直接反映了这些用例。
检查原始数据
在编写分析查询之前,先验证数据是否符合预期:
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;结果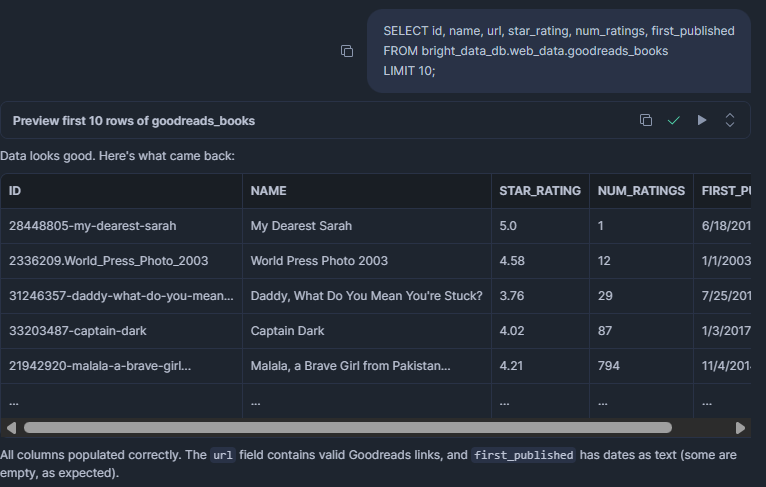
哪些书拥有最强的读者验证?
仅有高 star_rating 还不够。一本 4.8 星但只有 12 人评分的书几乎说明不了什么。该查询会找出既高评分又广泛被阅读的书,这种组合表明一本书具有真正的持久力。
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;结果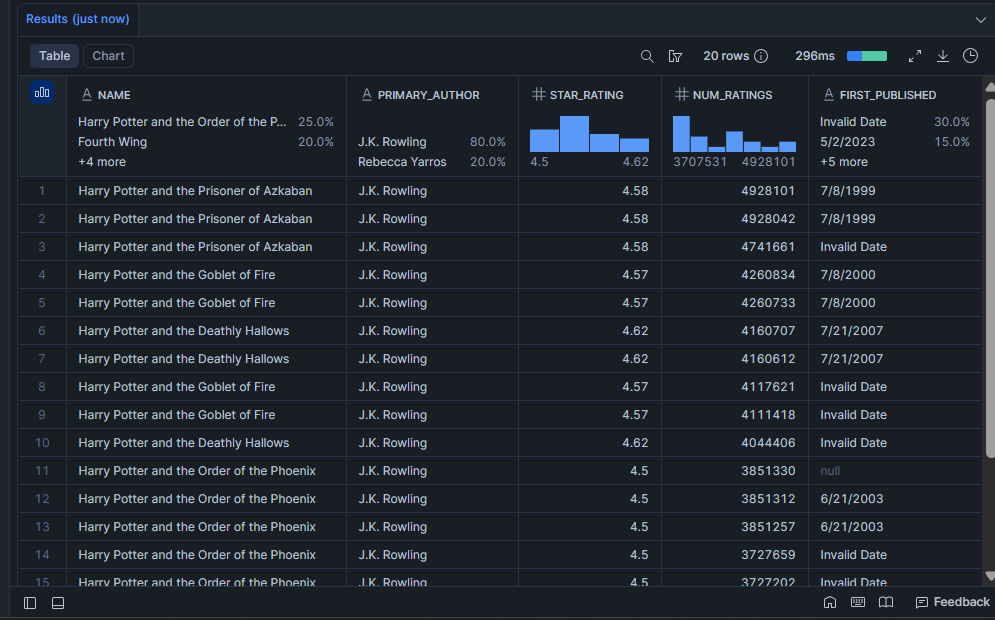
哪些 genres 拥有最多标题以及最高平均评分?
用于理解读者需求集中在哪里。一个标题数量很大但平均评分很低的 genre 可能充斥着低质量条目,这对出版商或推荐引擎来说是一个机会。
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;结果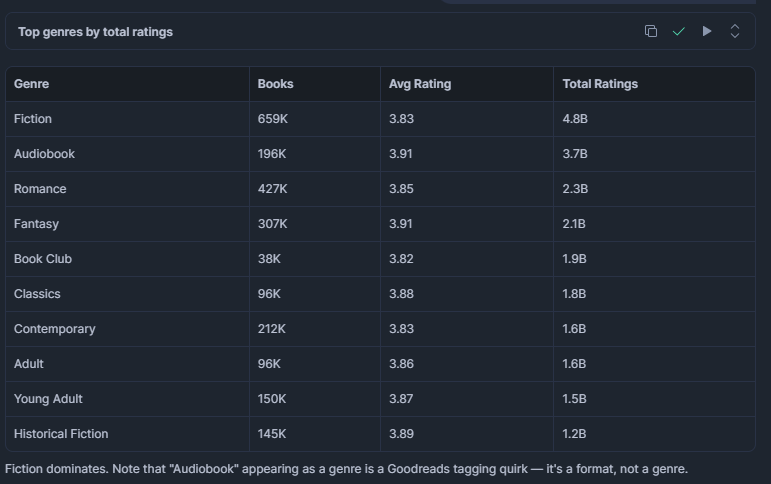
数据集中被关注最多的作者是谁?
作者关注者数量是平台受众的代理指标。将其与平均图书评分配对,可以显示最受关注的作者是否也最受尊敬,或者关注者数量与质量是否出现分化。
about_author 是每条图书记录上的扁平对象,因此无需数组索引即可直接查询。请注意,这反映的是该特定图书页面上对作者的描述,可能与 author(署名作者数组)略有不同。
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;结果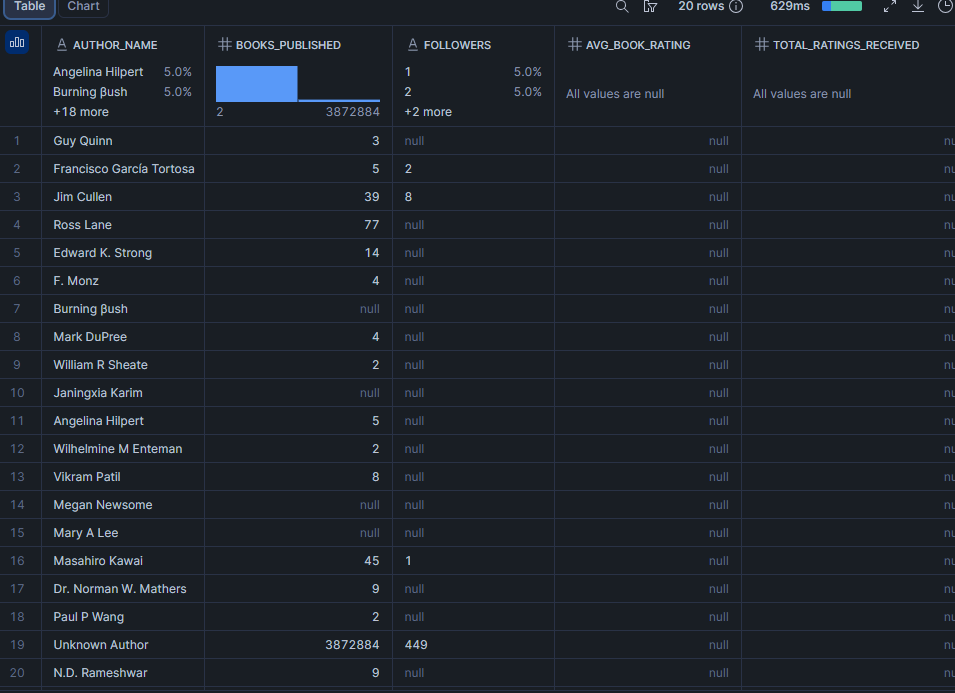
注意:followers 以文本排序,因为源字段是 VARCHAR(它可能包含格式化值,如 "12.3k")。如果你的数据集交付的是干净的整数,请用 TO_NUMBER(followers) 进行转换并按数值排序。
一本书有多两极分化?从 community reviews 中提取星级明细
一本书可能平均评分很高,但 1 星评论占比也很大,这可能意味着它具有争议性而非普遍受喜爱。该查询会拉取任意特定图书的评分分布。
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviews 会在星级明细旁给出总的文字评论数量,这有助于区分那些吸引大量长篇文字观点的书与那些只收集无声星级评分的书。
Et voilà!你现在拥有一个可用的管道,它从 Bright Data 拉取结构化网络数据,并使其可在 Snowflake 中查询。
自动化刷新
在生产使用中,你会希望新快照自动加载,而不是每次手动运行 COPY INTO。从选项 A 开始。只有当你需要在交付完成后的几秒内更新表时,才转到选项 B。
选项 A:用于按计划驱动导入的 Snowflake Task
Snowflake Task 按 cron 计划运行 COPY INTO,无需额外基础设施。在 Bright Data 中设置匹配的交付计划,以便当 task 触发时文件已在 stage 中就绪。
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;专业提示:在你的第一次自动化运行中,在 task 触发后检查 COPY_HISTORY,以确认计划时间与 Bright Data 完成交付的时间一致。如果 task 在交付完成之前运行,它会发现一个空 stage 并加载零行。
选项 B:用于低延迟事件驱动导入的 Snowpipe REST API
Snowpipe 会在文件到达 stage 后的几秒内加载它们,并通过其 insertFiles REST endpoint 以编程方式触发。仅当你的用例需要近实时新鲜度时才使用它。与选项 A 相比,它会增加显著的设置复杂度。
设置分为两部分。首先,创建 pipe:
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;注意没有 AUTO_INGEST = TRUE。对于内部命名 stage,通过云消息实现自动导入仅适用于 AWS 托管的 Snowflake 账户,并且目前是预览功能。REST API 方法适用于所有云平台。
其次,当快照就绪时,将你的 webhook handler 连接起来以列出暂存文件并将它们提交给 Snowpipe:
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")注意:Snowpipe REST API 需要密钥对认证,而不是密码认证。生成 RSA 密钥对,将公钥分配给 Snowflake 中的 brightdata_svc(ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...'),并在上方传入私钥文件路径。使用 pip install snowflake-ingest 安装 SDK。
结论
在本文中,你学习了如何构建一个从 Bright Data 到 Snowflake 的完整网络数据导入管道。该工作流:
- 使用专用 database、stage、role 和服务用户准备 Snowflake,Bright Data 将直接针对其进行认证。
- 将 Bright Data 数据集配置为以 Snowflake 作为交付目的地,无需中间存储。
- 通过 控制面板 的 Deliveries 选项卡或 数据集 API 触发快照,然后监控交付状态直到文件到达 stage。
- 使用一条
COPY INTO命令将暂存文件加载到结构化的 Snowflake 表中,并使用标准 SQL 查询数据。
同样的设置适用于 Bright Data marketplace 中的任何数据集:Amazon 产品、LinkedIn 公司、职位发布、酒店列表、Crunchbase 记录等。每一个都遵循相同的交付模式;只有表 schema 会变化。
立即创建一个免费的 Bright Data account,开始将实时网络数据引入你的 Snowflake 环境!



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





