
在本文中,你将了解:
- Akamai 是什么以及其反机器人系统如何工作。
- 如何验证某个网站是否使用 Akamai。
- 处理 Akamai 机器人检测绕过的高层方法。
- 如何使用开源工具通过 Akamai 挑战。
- 如何在静态请求和浏览器自动化场景中,更可靠地处理 使用 Bright Data 绕过 Akamai。
让我们开始吧!
Akamai 的反机器人机制如何工作
Akamai 同时作为 CDN 和机器人管理层运行,位于用户与源站服务器之间。每个请求都会经过其边缘网络,在那里被检查并被允许、被挑战或被阻止。
从反机器人角度来看,Akamai 依赖一个多层检测系统:
- 第 1 层——网络与请求分析:评估 IP 信誉和协议层模式(例如 TLS 指纹识别)。
- 第 2 层——指纹识别与客户端分析:Akamai 注入在浏览器中运行的 JavaScript 挑战,以收集设备特征、浏览器配置以及执行环境行为等信号。这些指纹有助于区分真实浏览器与无头或自动化浏览器,即使 HTTP 请求看起来有效也是如此。
- 第 3 层:行为分析:包括鼠标移动、按键模式、导航流程以及动作之间的时间间隔。这是更高级的机器人尝试模仿人类以避免检测,并落入不确定性的“灰色地带”的地方。
基于这些信号,Akamai 会分配一个风险评分(Bot Score),并将流量分类为合法用户、已知机器人和可疑流量等类别。响应会相应变化:流量可能被允许、被限速、通过 CAPTCHA 等机制被挑战,或被完全阻止。
如何检查网站是否受 Akamai 保护
要判断某个网站是否依赖 Akamai,你应该寻找网络层和浏览器层指标的组合。
例如,考虑 一个 Zalando 产品页面,它广为人知位于 Akamai 的 CDN 和反机器人层之后。打开浏览器 DevTools,导航到 “Network” 选项卡,然后重新加载页面。检查浏览器发出的请求,重点关注响应头: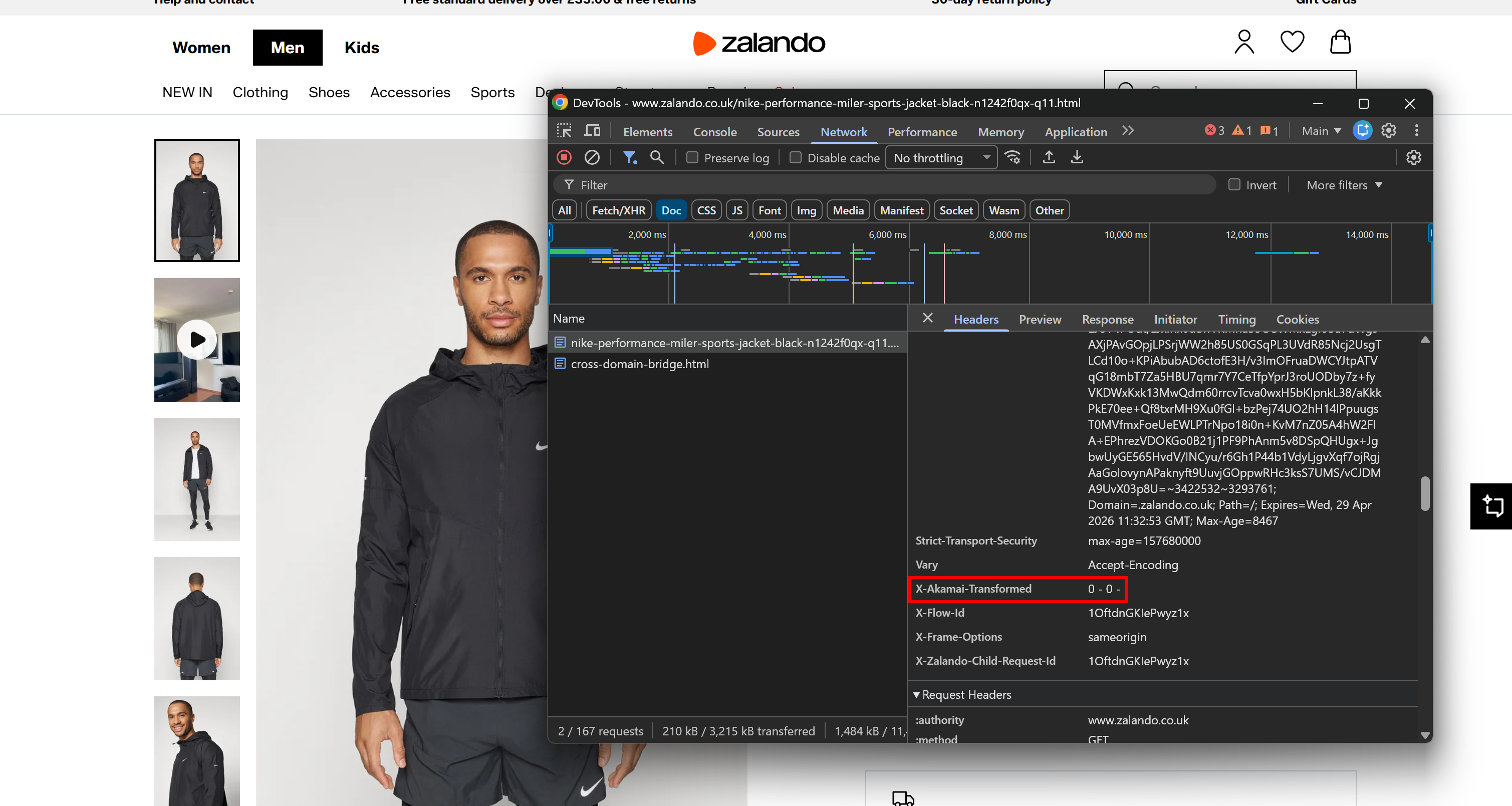
你可能会注意到一个 X-Akamai-Transformed 响应头。X-Akamai-* 响应头的存在表明流量正在通过 Akamai 的 CDN 层处理。
另一个强信号来自服务器设置的 cookie。你可以在 “Application” 选项卡下的 “Cookies” 部分找到它们。在由 Akamai 支持的页面上,你会注意到 as _abck 和 ak_bmsc。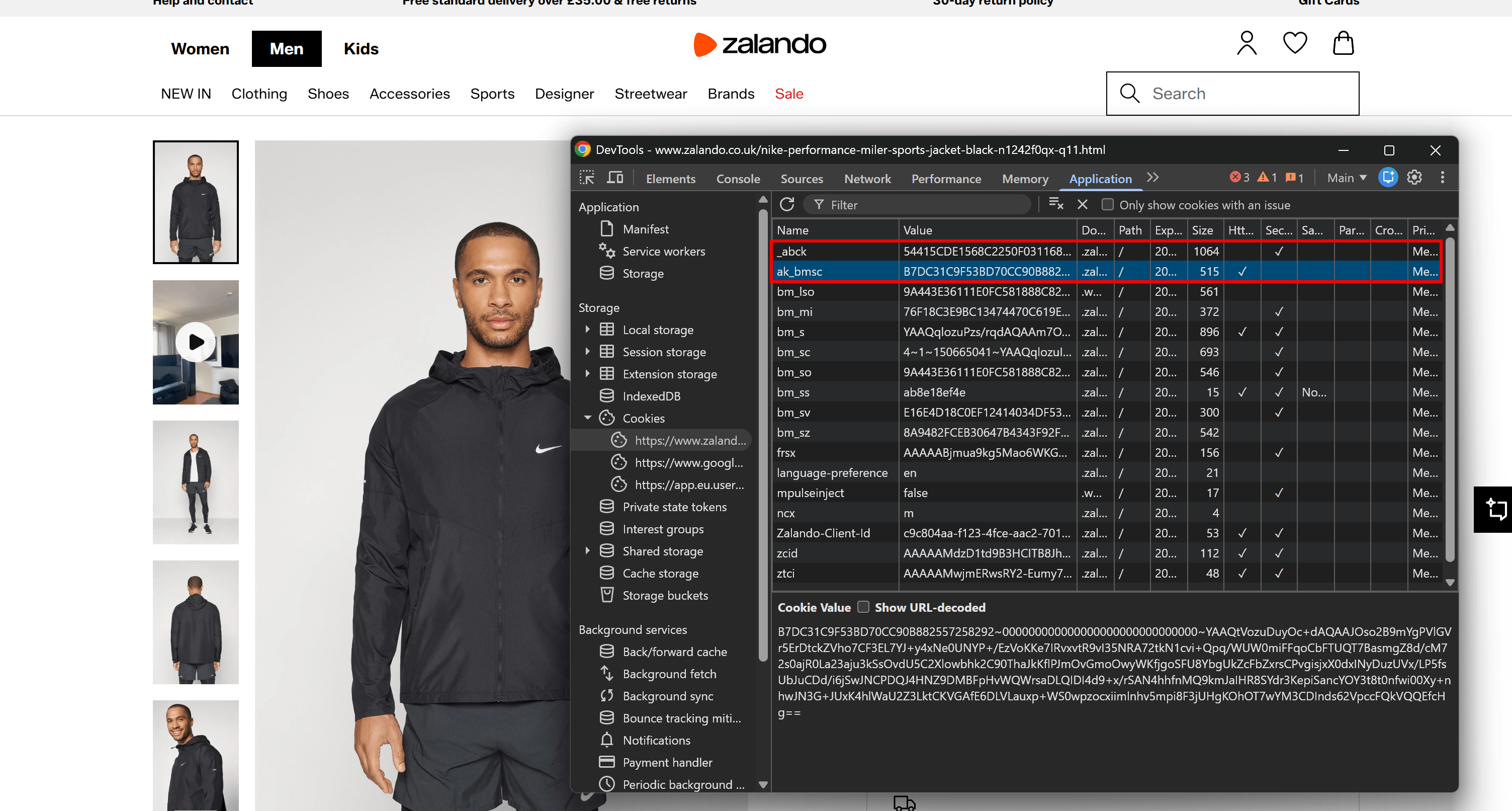
这些是 Akamai 机器人检测系统设置的关键 cookies:
_abck:用于行为跟踪和风险评分的长生命周期 cookie(可持续数月)。ak_bmsc:用于检测浏览行为异常的短生命周期会话 cookie(在数小时内过期)。
虽然可能还有其他信号,但这些足以识别大多数由 Akamai 支持的网站。
Akamai 机器人检测实战
为了理解 Akamai 的反机器人机制在自动化场景中的表现,考虑两种常见方法:
- 使用 像 Requests 这样的 HTTP 客户端 向目标服务器发送直接请求。
- 使用 像 Playwright 这样的浏览器自动化工具 在无头模式下渲染页面。
注意:目标页面仍然是前面提到的同一个 Zalando 产品页面。
Akamai vs Requests
尝试通过 requests 库检索一个由 Akamai 管理的页面:
# pip install requests
import requests
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
response = requests.get(url)
print("Status code:", response.status_code)
print("\nPage HTML:\n")
print(response.text[:2500])脚本将打印:
Status code: 403这表明服务器使用 403 Forbidden 响应拒绝了请求。返回的 HTML 将返回一个错误页面,而不是预期的产品内容。
因此,基本的 requests 调用不足以访问由 Akamai 管理的页面。使用 大多数标准 HTTP 客户端 也会出现相同结果。
Akami vs Playwright
使用 Playwright 在无头模式下访问目标页面。然后,打印 HTTP 状态码并截图:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with sync_playwright() as p:
# Visit the target page in headless mode
browser = p.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()同样,请求被阻止,输出将是:
Status code: 403生成的截图将包含一个访问拒绝页面,而不是预期的产品内容: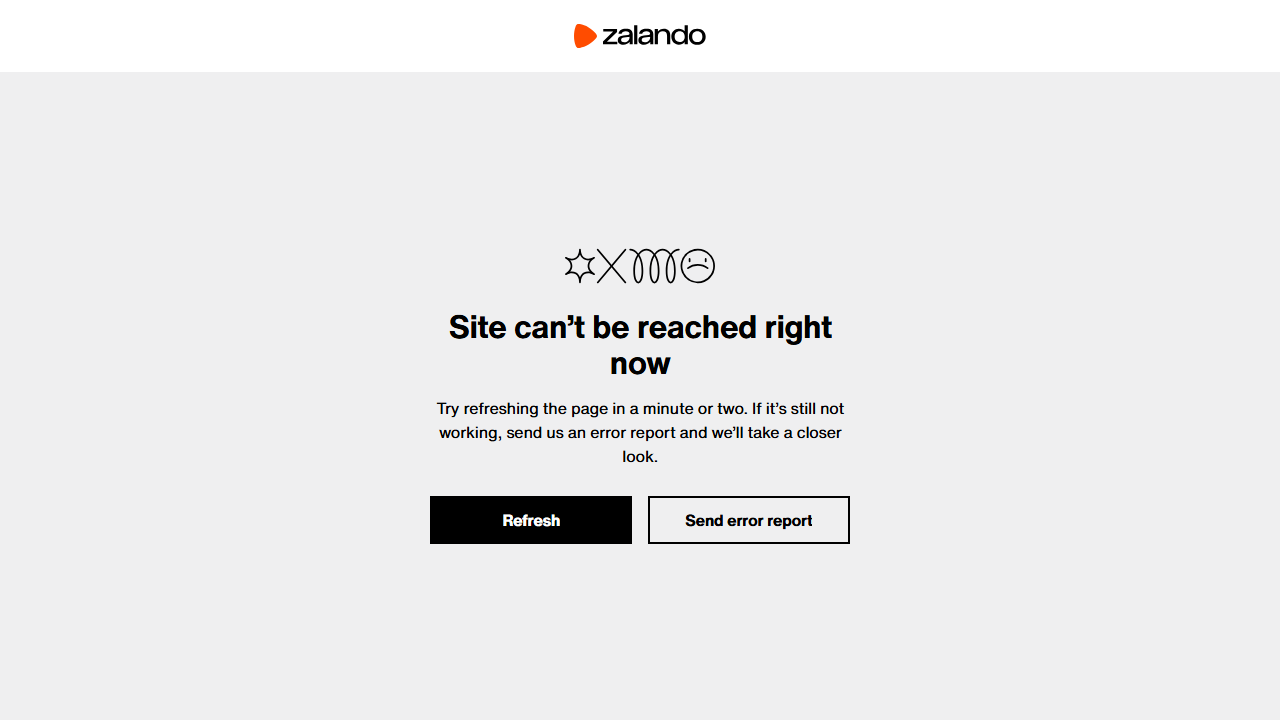
错误页面表明在未提供详细信息的情况下不允许访问。
注意:与其他反机器人系统(例如 Cloudflare)不同,Akamai 的错误响应通常会因网站而异。
Akamai 机器人检测绕过的高层方法
在本章中,你将探索绕过 Akamai 机器人检测的主要方法。如果你赶时间,请参考下面的汇总表。
| 方法 | 简要描述 | 优点 | 缺点 |
|---|---|---|---|
| 直连源站访问 | 如果源站 IP 暴露,尝试通过直接向源站服务器发送请求来绕过 CDN | 无需额外工具 | 实际中很少奏效 |
| 开源浏览器自动化绕过工具 | 使用特定自动化框架来模拟真实用户浏览器会话 | 免费 | 由于可被逆向工程与基于 IP 的封锁而可被检测 |
| 高级反机器人抓取工具 | 使用托管的云服务为你处理一切 | 高可靠、可扩展、最少配置、处理完整反机器人栈 | 付费 |
方法 #1:直连源站访问
归根结底,Akamai 是一个 CDN。这意味着它位于目标源站服务器与你(用户)之间,通过其分布式边缘网络路由流量的同时缓存并保护内容。
理论上,如果源站服务器的 IP 地址被暴露(例如通过历史 DNS 记录或错误配置),你可能尝试直接向其发送请求。这将意味着直接绕过 Akamai 网络,因为你的流量现在会在 CDN 层之外路由。
在实践中,这种方法由于以下几个原因而不可靠:
- 源站访问限制:正确配置的源站服务器只接受来自 CDN IP 段的流量,或要求经过身份验证的请求(例如签名头或令牌)。
- 网络层控制:防火墙和安全组通常会阻止直接的公网访问。
- 暴露有限:发现 CDN 背后的源站 IP 并不常见,因为现代配置旨在防止这种泄露。
由于这些限制,在配置良好的环境中,直连源站访问通常不可行。这更像是一个理论概念,而不是一种实用方法。
方法 #2:依赖开源浏览器自动化绕过工具
各种开源 浏览器自动化库 会生成类似真实用户行为的自动化会话。这些包括 Camoufox、SeleniumBase、NODRIVER 以及其他面向反机器人的自动化框架等工具。此外,一些 一体化抓取框架(如 Scrapling) 也提供类似能力。
这些工具会调整底层浏览器以实现逼真的指纹,同时提供类似 Selenium 或类似 Playwright 的浏览器自动化 API。即使在无头模式下运行浏览器自动化,这也同样适用。
然而,这种 Akamai 机器人检测绕过方法有两个主要限制:
- 开源可见性:由于这些工具是开源的,其实现细节是公开可见的。因此,像 Akamai 这样的反机器人提供商可以对其进行逆向工程,暂时阻止或降低其有效性(直到发布更新)。这在检测系统与自动化工具之间形成了持续的猫鼠游戏循环。
- 基于 IP 的执行:这种方法非常擅长绕过基于指纹的检查。然而,抓取请求仍然源自你的 IP 地址。因此,Akamai 仍然可以通过限速或基于 IP 信誉的机制阻止你。为缓解这一点,你必须集成一个 第三方高级动态代理轮换服务。
方法 #3:集成高级 Akamai 绕过抓取工具
绕过 Akamai 机器人防护最可靠且可扩展的方法是使用高级网页抓取工具。这些服务处理完整的挑战栈,包括浏览器指纹识别、自动化检测、IP 管理、验证码破解,以及基础设施扩展。
你无需直接管理请求,而是提供一个目标 URL 并接收解锁后的内容。这可能通过标准 HTTP 响应交付,或者在某些情况下,通过浏览器自动化会话交付。
由于这些解决方案部署在云端,与开源库不同,不存在被逆向工程的风险。此外,它们通常构建在大规模代理网络之上,从而实现企业级可扩展性。
主要缺点是成本,因为这些服务是商业产品。尽管如此,每次成功请求的成本通常非常低(有时仅为几分之一美分)。
如何使用开源解决方案绕过 Akamai
直连源站访问更像是一种理论方法,而不是实用方法。因此,让我们先演示如何使用反机器人专用的浏览器自动化工具来绕过 Akamai 保护。
在本节中,我们将测试 Camoufox 和 SeleniumBase,尽管其他工具也同样值得信赖。目标测试将是访问前面提到的受保护 Zalando 产品页面,并尝试对其截图。
注意:下面的结果指的是使用住宅 IP 的单次脚本运行。同一脚本在服务器上或规模化执行时,很可能由于限速或 IP 信誉问题而失败。
查看 Camoufox 和 SeleniumBase 针对 Akamai 保护内容的实战表现!
使用 Camoufox 进行 Akamai 绕过测试
pip install camoufox然后检索浏览器二进制文件:
python -m camoufox fetchCamoufox 构建在 Playwright 之上,因此其 API 非常相似。访问目标页面,打印 HTTP 状态码,并使用以下方式截图:
# pip install camoufox
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with Camoufox(headless=True) as browser:
# Visit the target page
page = browser.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="camoufox_zalando.png")有关此库的更多信息,请阅读我们的 使用 Camoufox 进行网页抓取 指南。
即使在无头模式下,预期结果也应为:
Status code: 200并且生成的 camoufox_zalando.png 文件应包含渲染后的页面: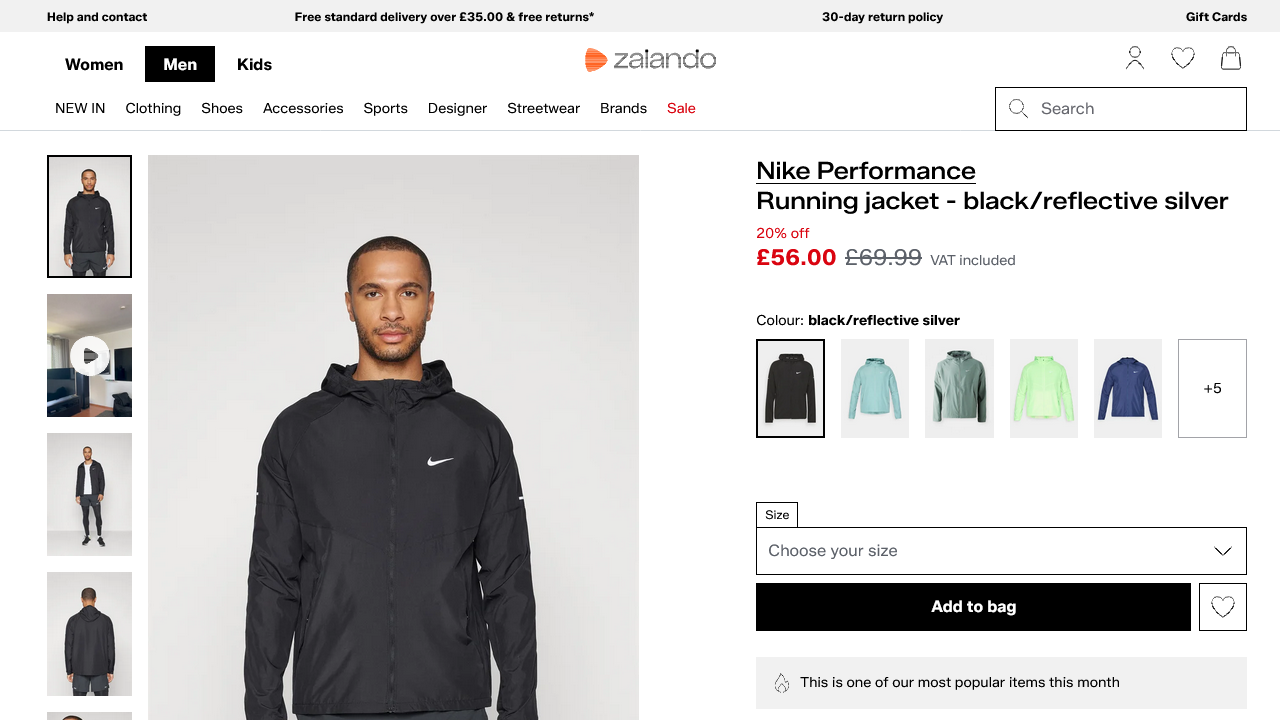
太棒了!Camoufox 成功绕过了 Akamai。
使用 SeleniumBase 进行 Akamai 绕过测试
使用以下命令安装 SeleniumBase:
pip install seleniumbase接下来,使用它在 UC Mode 中访问目标页面并截图:
# pip install seleniumbase
from seleniumbase import SB
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with SB(uc=True, headless=True) as sb:
# Open the page
sb.open(url)
# Get status code via JS (as Selenium does not expose it directly)
status = sb.execute_script(
"return window.performance.getEntries()[0]?.responseStatus || 'unknown';"
)
print("Status code:", status)
# Wait for page load
sb.sleep(3)
# Take a screenshot
sb.save_screenshot("seleniumbase_zalando.png")有关 UC mode 如何工作以及如何配置的更多信息,请参考 SeleniumBase 抓取指南。
预期结果应为:
Status code: 200并且生成的 seleniumbase_zalando.png 文件应显示: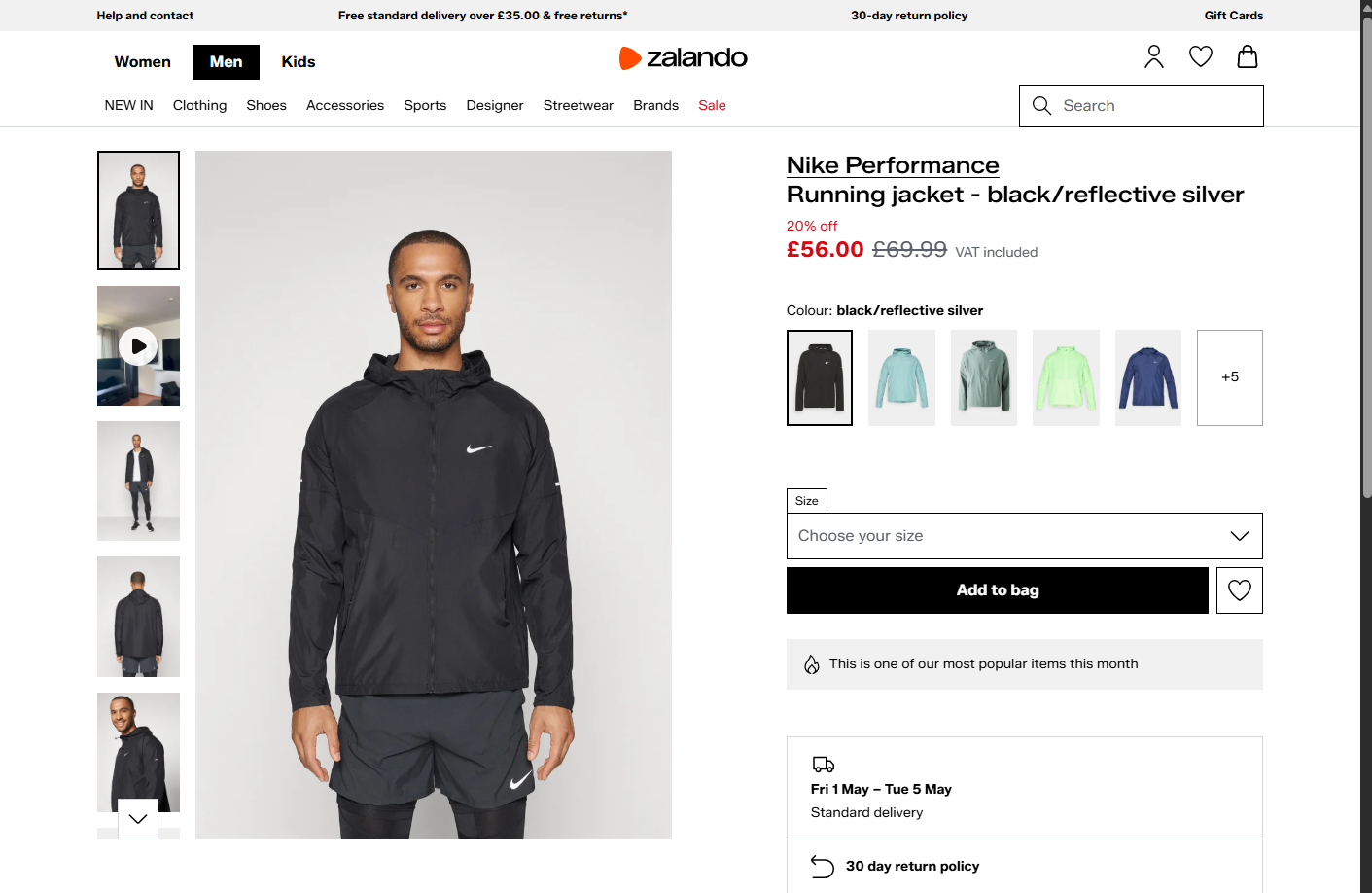
很酷!SeleniumBase 也绕过了 Akamai 的反机器人保护。
如何使用 Bright Data 规模化绕过 Akamai
Bright Data 允许你访问几乎任何网页,无论它是否受 Akamai、Cloudflare 或其他反机器人系统保护。
特别是,所有 Bright Data 抓取服务 都由一个 专用的 Akamai 机器人绕过 系统 支持。它会自动为你处理 Akamai 的反机器人挑战。
Bright Data 的一个关键优势是,它由全球最大的代理网络之一驱动,拥有超过 4 亿个 IP。这实现了无限并发、99.99% 的正常运行时间以及 99.95% 的请求成功率。此外,得益于此,它不像开源浏览器自动化工具那样会受到与 IP 相关或限速封锁的影响。
下面,我们将演示如何使用以下方式绕过 Akamai 保护:
- 网络解锁器 API:一个爬虫 API,可在一次请求中处理代理轮换、反机器人挑战(包括 Akamai)以及 CAPTCHA 破解。
- Browser API:一个基于云、针对反机器人优化的浏览器会话,可通过 Playwright、Selenium、Puppeteer 或任何兼容 CDP 的自动化工具进行控制。
请按照接下来各章中的说明操作!
使用 Bright Data 的 网络解锁器 API 绕过 Akamai
在静态抓取场景中,使用 Bright Data 网络解锁器 API 体验 Akamai 机器人检测绕过。
先决条件
要跟随本节内容,请确保你具备:
- 一个 Bright Data 账户,并已配置 一个 API key。
- 在你的账户中设置了一个 网络解锁器 API 区域。
- 一个基于 HTTP 客户端方法的抓取脚本。
要为 网络解锁器 API 使用设置你的 Bright Data 账户,请遵循官方 “创建你的第一个 Unlocker API” 指南。
示例
如果你更感兴趣的是检索页面的 Akamai 解锁后的 HTML,请像这样使用 网络解锁器 API:
import requests
# Replace with your Bright Data API key and Web Unlocker API zone name
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_API_ZONE = "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>"
target_url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
payload = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_API_ZONE,
"url": target_url,
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Perform a request to the Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
print("Status code:", response.status_code)
html = response.text
print("\nPage HTML:\n")
print(html)
# Perform web scraping on the returned HTML...结果将是:
Status code: 200然后,html 变量将包含完整的页面源代码。你可以轻松地 使用 HTML 解析器解析它,并在网页抓取工作流中从中提取你想要的数据。更多指导请参阅我们的 如何抓取 Zalando 指南。
使用 Bright Data 的 Browser API 绕过 Akamai
在这里,你将看到如何在浏览器自动化场景中使用 Bright Data Browser API 通过 Akamai 反机器人检查。
先决条件
要完成本节内容,请确保你具备:
- 在你的 Bright Data 账户中配置了一个 Browser API 区域。
- 一个浏览器自动化抓取脚本。
要获取 Browser API 连接 URL,请阅读官方 “创建你的第一个 Browser API” 指南。
这里我们将展示一个 Playwright 示例,因此 Browser API 连接 URL 将如下所示:
wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222示例
将你的 Playwright 自动化脚本连接到 Bright Data 的 Browser API,并重复前面展示的截图逻辑:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
BRIGHT_DATA_BROWSER_API_CDP_URL = "wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222"
with sync_playwright() as p:
# Connect to Bright Data CDP endpoint
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_BROWSER_API_CDP_URL)
# Create a new context and page
context = browser.new_context()
page = context.new_page()
# Visit the target page in headless mode
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()执行后,脚本将返回:
Status code: 200生成的截图将包含渲染后的页面内容: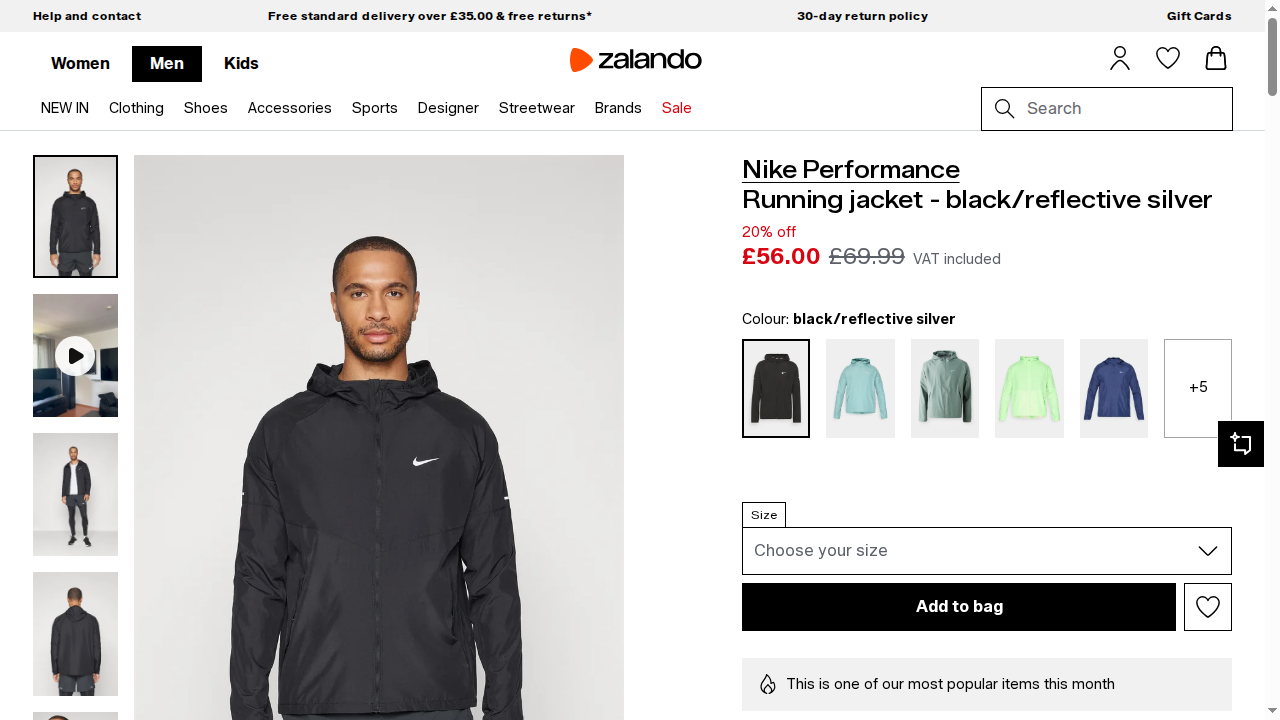
太棒了!这一次,得益于 Browser API 集成,Playwright 脚本正确运行。Browser API 在 Bright Data 云基础设施中管理的真实浏览器会话里处理自动化。
你现在可以构建自动化工作流,在不受限制的情况下与页面交互!
结论
在本文中,你了解了 Akamai 的反机器人系统如何工作,并探索了在自动化与抓取工作流中处理它的实用方法。
无论你选择哪种方法,借助专业、快速且可靠的企业级解决方案,流程都会变得更容易,例如:
- 网络解锁器 API:一个 API 端点,可自动处理限速、指纹挑战以及其他反机器人机制。
- Browser API:一个托管的云端反检测浏览器,可让你规模化自动化与任何网站的交互。
与其他 Bright Data 抓取产品一样,这些服务由 Akamai Bot Solver 驱动。
立即免费创建一个新的 Bright Data 账户并探索我们的抓取解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




