

在本文中,你将学习:
- 什么是使用 Camoufox 进行网页爬取,以及它如何降低基于指纹的机器人检测。
- 如何将 Camoufox 与 Bright Data 住宅代理 配置在一起,以实现稳定的数据采集。
- Camoufox 适合的场景、规模化时的瓶颈,以及何时迁移到 Bright Data 的 Scraping Browser 或 Web Unlocker 用于生产环境。
什么是 Camoufox?核心功能一览

Camoufox 是一个开源的反检测浏览器,基于修改版 Firefox 构建。它专为浏览器自动化与 网页爬取 场景设计,用于应对标准无头浏览器容易被识别并拦截的问题。
Camoufox 的重点是在浏览器引擎层面改变浏览器行为,从而降低检测风险,而不是仅依赖 JavaScript 层面的“伪装技巧”。
核心功能:
- 浏览器指纹控制:Camoufox 会修改浏览器指纹属性,例如 navigator 属性、图形接口、媒体能力以及语言/区域设置信号。这些修改在浏览器层面生效,可减少不一致性,而这类不一致性往往是 反机器人系统 用于识别自动化的关键。
- 引擎级隐身补丁:Camoufox 反检测浏览器会移除或修改默认浏览器构建中暴露的自动化标记,包括处理会泄露自动化框架的属性,并避免常见的无头浏览器特征,同时不向页面上下文注入容易被检测到的脚本。
- 会话隔离与可变性:每个 Camoufox 浏览器会话都是隔离的,可在不同运行之间使用不同的指纹配置文件。这有助于在抓取多页或重启浏览器时避免会话关联。
安装与设置
安装 Camoufox:Camoufox 以 Python 包形式发布,并附带一个固定版本的 Firefox 内核浏览器,从而避免浏览器版本漂移导致的指纹不稳定问题。
pip install -U camoufox[geoip]
下载浏览器
camoufox fetch
Python 与操作系统要求:Windows 与 macOS 均需 Python 3.9 或更高版本。每个 Camoufox 实例大约占用 200 MB 内存,因此在低内存系统上并发能力会受限。
可选虚拟环境(推荐):使用虚拟环境可避免依赖冲突(例如影响 SSL 处理、字体渲染或图形 API 的冲突)。Windows 与 macOS 都同样适用。
python -m venv camoufox-envcamoufox-env\Scripts\activate # Windowssource camoufox-env/bin/activate # macOS基础教程:使用 Camoufox 进行网页爬取
本节演示使用 Camoufox 进行网页爬取 的最小工作流程。代码会启动 Camoufox 浏览器,打开新页面,并像真实用户一样加载 URL。它会等待网络活动全部结束,以确保 JavaScript 渲染内容可用。
随后会截取整页截图,以便直观确认页面是否渲染成功。最后从页面 body 中提取可见文本,验证抓取是否正常。
from camoufox.sync_api import Camoufox
with Camoufox(headless=True) as browser:
page = browser.new_page()
page.goto("<replace_with_a_link>")
page.wait_for_load_state("networkidle")
page.screenshot(path="page.png", full_page=True)
content = page.text_content("body")
print(content[:500])脚本会在项目目录中保存一张名为 page.png 的截图,展示完整渲染后的网页。终端会打印页面可见文本的前一部分,确认内容提取成功。如果页面正常加载,不会产生错误。
Camoufox 很适合用来快速原型验证基于浏览器的 爬取工作流,因为它暴露的是真实 Firefox 行为,而不是对其进行抽象封装。
其浏览器原生(C++ 级别)指纹能力,在与高质量住宅代理配合的早期会话中,成功率可达到约 92%。
作为开源工具,它对学习现代反爬系统如何评估浏览器指纹、Cookie 和会话状态尤为有价值。
在 Camoufox 中配置 Bright Data 代理
本节说明如何正确将 Bright Data 住宅代理配置到 Camoufox 中,以实现稳定的真实环境网页爬取。
为什么住宅代理很重要
住宅代理 会通过真实的消费者 IP 地址转发请求,而不是通过数据中心基础设施。因此,对于网站会主动监控流量模式、IP 信誉或请求来源的爬取任务,住宅代理通常更有效。
许多现代网站会部署机器人防护系统,快速封禁云或数据中心的 IP 段。住宅 IP 能显著降低风险,因为它更像正常用户流量,并且在地理位置上与真实浏览行为更一致。对于内容密集型平台、地区限定页面或实施限速与访问策略的网站,这一点尤其重要。
与 Camoufox 搭配时,住宅 代理 具备两大优势:真实的浏览器指纹与 IP 层面的真实性。这种组合能提高页面加载成功率、降低 CAPTCHA 频率,并让爬虫更长时间运行而无需人工干预。对于生产级爬取流水线,住宅代理是核心基础组件。
配置:Bright Data 凭证 + GeoIP 自动对齐
登录 Bright Data 控制台,进入 Proxy Infrastructure(代理基础设施)区域。这里用于创建与管理所有代理区域(zone)。
点击 Create proxy 按钮开始创建新的代理区域。Bright Data 会引导你完成一个简短的配置流程。
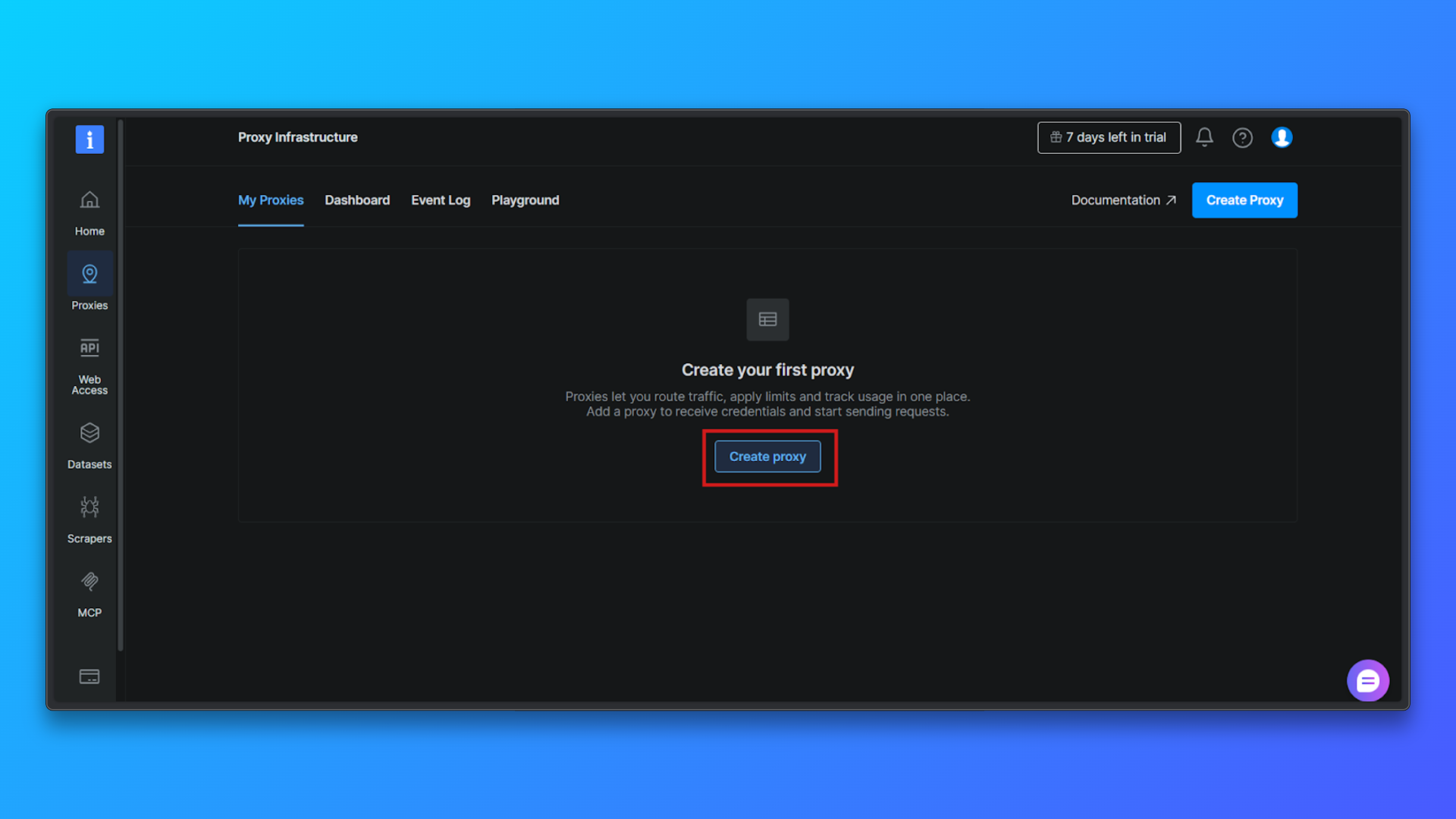
选择代理类型 → Residential:在代理类型列表中选择 Residential。住宅代理通过真实住宅 IP 路由流量,与数据中心代理相比能显著降低被检测概率。
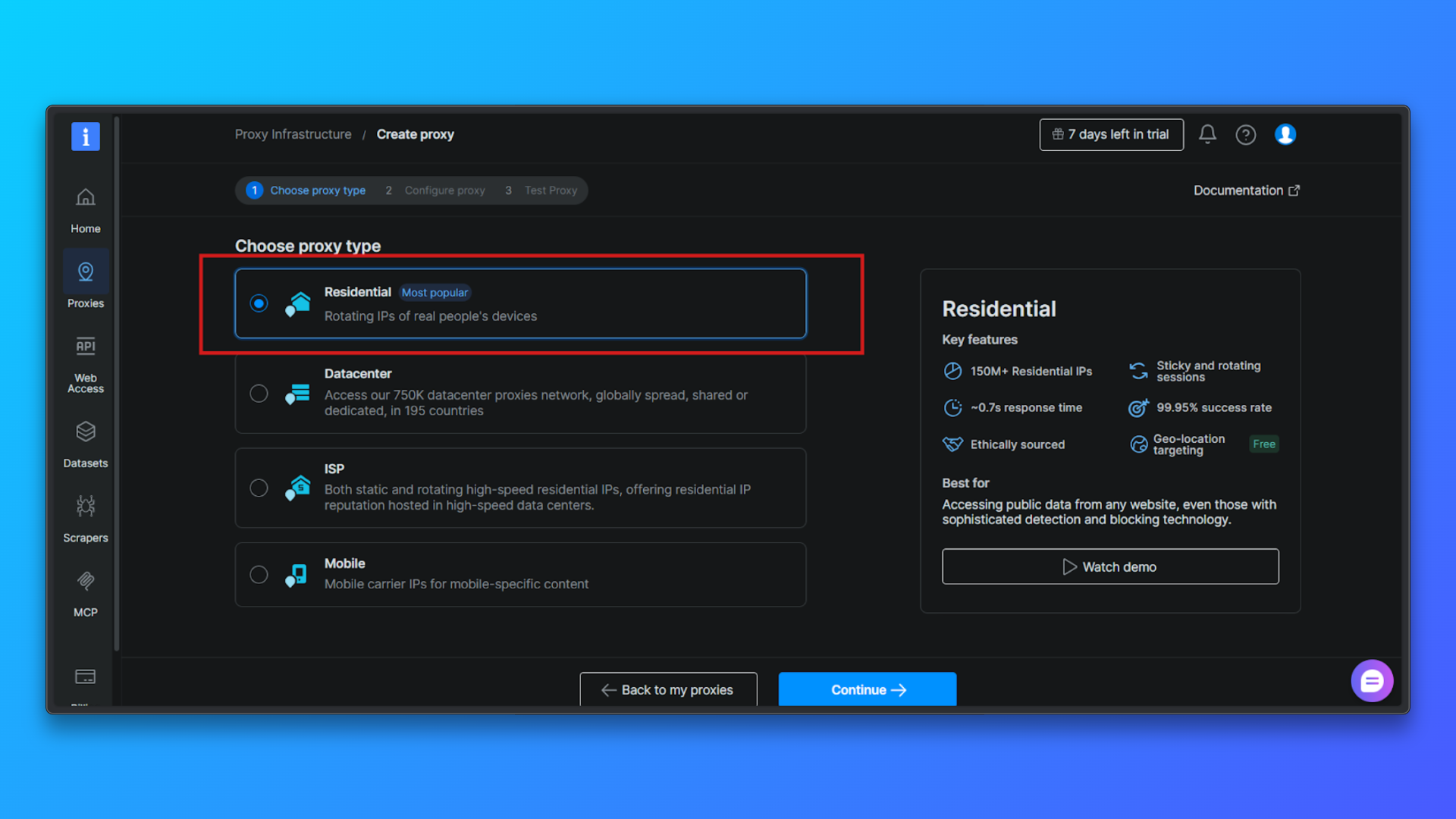
配置代理(可选):你可以按需配置:国家定向、会话行为、访问模式。
对初学者来说,默认配置通常足够。你可以不改动高级选项直接继续。
点击 Continue 创建 Zone:确认配置并完成创建。Bright Data 会创建住宅代理 zone,并跳转到 Overview 页面。
在 Overview 页查看代理凭证:在 Overview 标签页中,你会看到:
- Customer ID
- Zone 名称
- 用户名
- 密码
- 代理 host 和端口
- 访问模式
- 可直接使用的终端命令
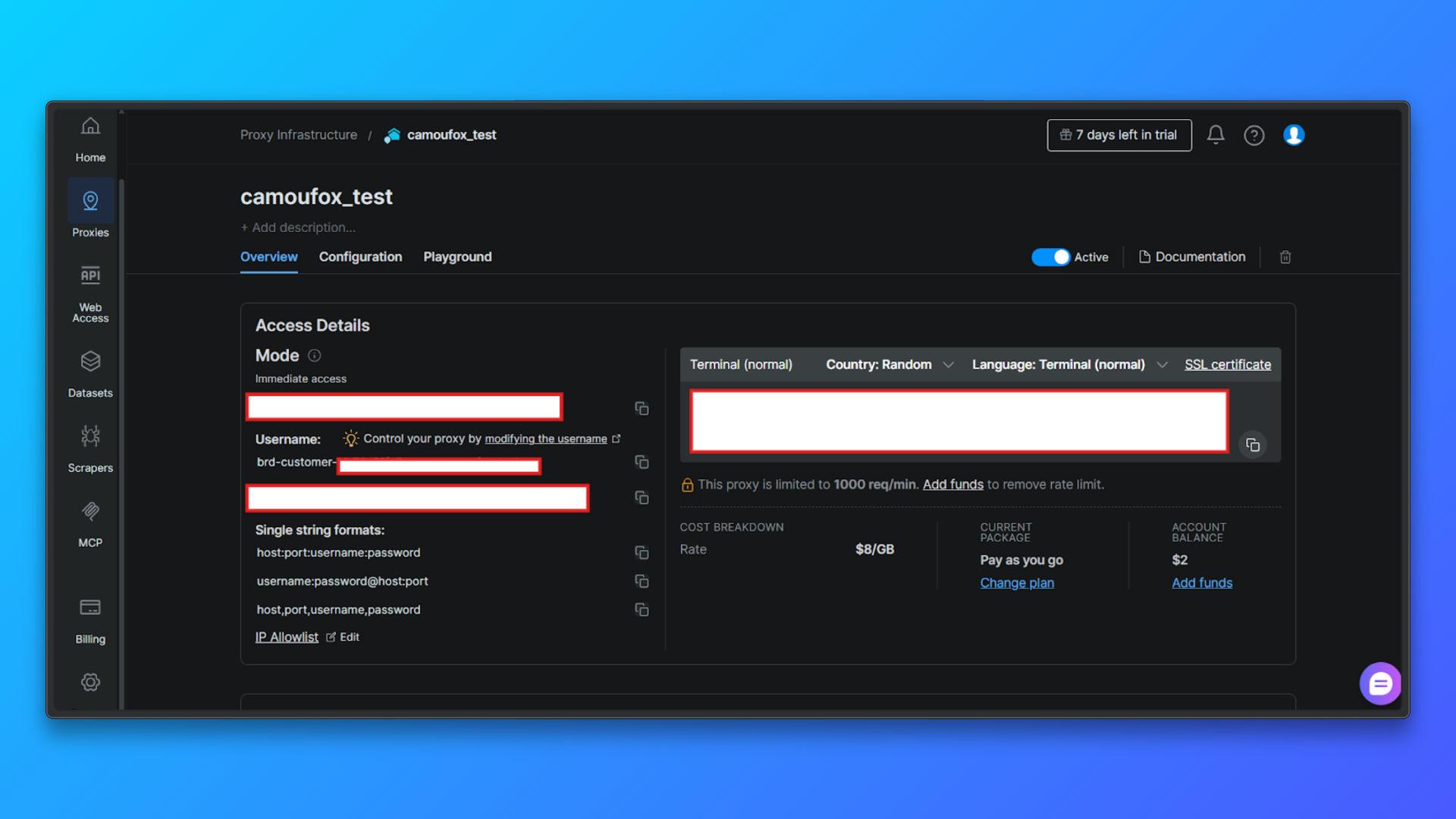
这些值会在后续代码配置代理时用到。
使用终端命令验证凭证:复制控制台提供的终端(curl)命令并在本地运行。
该命令会通过代理向 Bright Data 测试端点发送请求,并返回:
- HTTP 状态码
- 服务器响应
- 分配的 IP 详情
- 国家、城市、ASN 信息
成功响应表明:
- 代理凭证有效
- 认证正常
- 住宅 IP 路由已生效
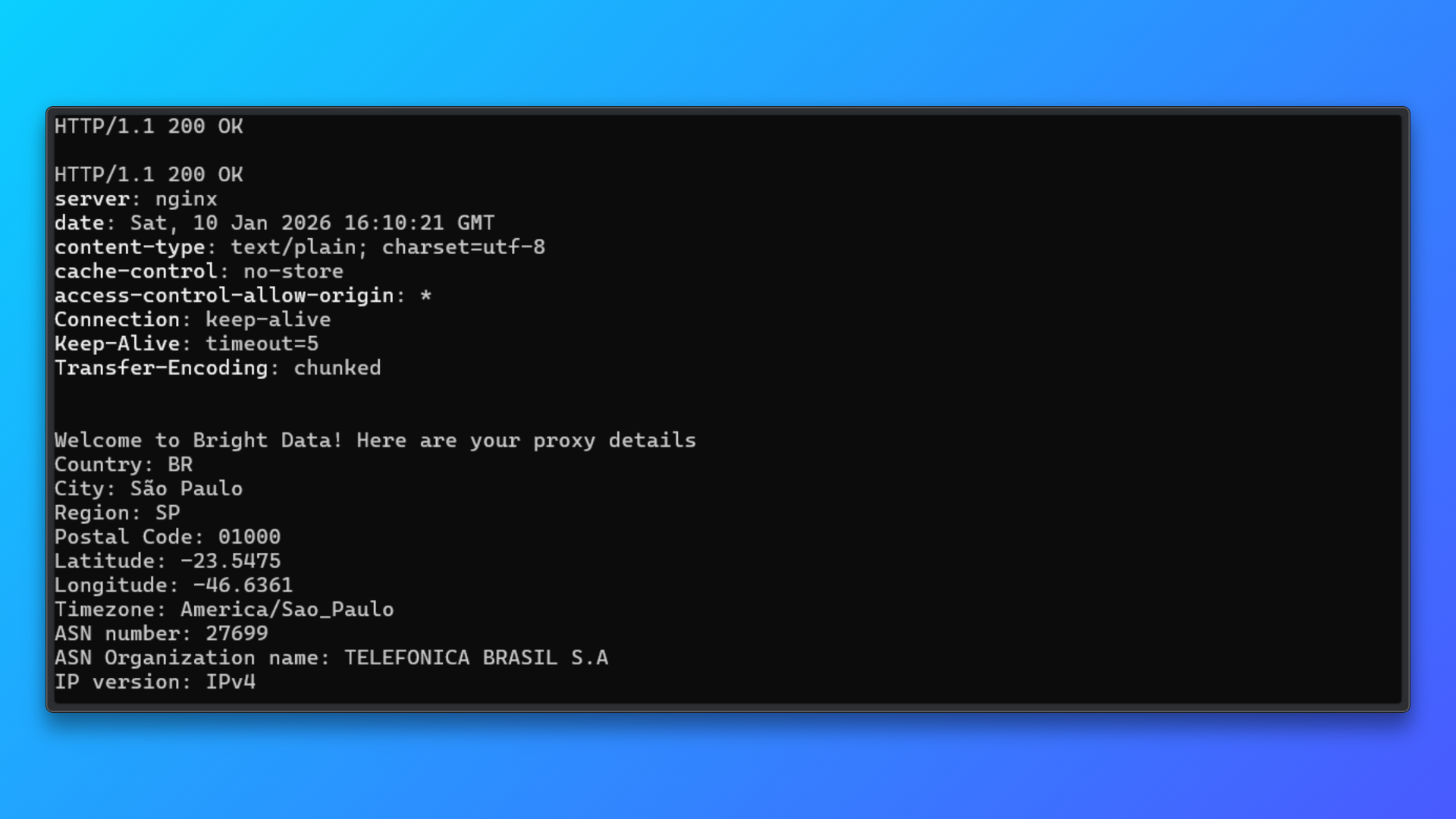
该验证步骤可在集成到 Camoufox 或任何爬取代码前,先隔离并排除代理配置问题。
Bright Data 支持在用户名中直接进行国家级路由,因此你无需手动管理 IP。
Camoufox 可以通过 geoip=True 可选地将浏览器行为与代理的地理位置对齐,从而提升 IP 位置与浏览器信号的一致性。
代码示例:Camoufox + Bright Data
现在我们把 Bright Data 代理配置到 Camoufox 中。
第 1 步:导入 Camoufox
from camoufox.sync_api import Camoufox第 2 步:定义 Bright Data 代理配置
proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<customer_id>-zone-<zone_name>-country-us",
"password": "<your_proxy_password>",
}server对 Bright Data 来说是固定值。- 国家定向通过用户名处理。
- 在真实部署中,凭证应安全存储在环境变量中。
第 3 步:启用代理启动 Camoufox
with Camoufox(
proxy=proxy,
geoip=True,
headless=True,
) as browser:
page = browser.new_page(ignore_https_errors=True)
page.goto("https://example.com", wait_until="load")
print(page.title())脚本成功运行后,Camoufox 会启动一个无头 Firefox 实例,并通过 Bright Data 住宅代理进行路由。浏览器会加载 https://example.com,并将页面标题打印到控制台。
输出
代理轮换策略
Bright Data 在网络层管理 IP 轮换,但实际爬取效果高度依赖于浏览器层面的会话如何组织与复用。代理轮换的核心在于:在多次请求中保持尽可能逼真的浏览行为。
使用 Bright Data 住宅 IP 时,爬取工作流通常能达到约 92% 的页面加载成功率,即大多数页面能完整加载而不会被拦截或中断。相比之下,使用数据中心代理的类似方案在受保护站点上成功率往往只有约 50%,尤其当网站启用了指纹识别、IP 信誉检查或行为检测时。
以下是使用 Camoufox + Bright Data 进行网页爬取时最可靠的轮换策略:
- 基于会话的轮换:不是每个请求都更换 IP,而是在限定的页面访问次数内复用同一个浏览器会话。达到阈值(例如访问若干页面或完成一个逻辑任务)后关闭会话并创建新会话。这更符合真实用户浏览方式,并能保持 Cookie、请求头与导航模式的连续性。该策略在匿名性与真实感之间取得平衡,适用于多数抓取/爬取场景。
- 基于失败的轮换:仅在出现异常时轮换会话。如果页面加载失败、超时或返回异常内容,则丢弃当前会话并创建新会话。这样可避免在成功请求时进行不必要轮换,同时仍能从封禁或不稳定线路中恢复。特别适合预期会偶发网络不稳定的长时间运行爬虫。
- 国家定向路由:Bright Data 允许在代理用户名中直接指定地理路由。通过在凭证中嵌入国家代码,请求会稳定路由到特定地区的 IP。适用于访问地区限制内容或确保本地化页面返回正确结果。为获得最佳效果,浏览器地理定位行为应与代理国家保持一致,避免信号不匹配。
- 感知速率的爬取:仅靠轮换并不能在高频请求下避免封禁。感知速率的爬取会在页面访问之间加入刻意暂停,避免快速跳转等“连发式”导航模式。即使用住宅 IP,抓取过快也会显得异常。适度延迟 + 会话复用会比激进高频轮换更接近真实用户行为。
- 避免过度轮换:每个请求都轮换 IP 通常并无帮助。过度轮换会造成不自然的流量模式,增加连接开销,有时反而更易触发风控。多数情况下,适度复用会话并进行可控轮换能带来更好的稳定性与长期成功率。
故障排查
- SSL 或 HTTPS 错误:当 HTTPS 流量经由代理转发时,可能出现证书/签发者警告。务必创建页面时忽略 HTTPS 错误,以确保导航成功。
- 页面加载超时:住宅代理可能引入额外延迟。提高导航超时时间;如果只需部分内容,可避免等待完整加载。
- 代理认证失败:确认代理用户名格式符合 Bright Data 要求,并使用了正确端口与密码;确保控制台中该代理 zone 处于启用状态。
- 地区或语言内容不正确:若页面返回非预期地区内容,请确认凭证中正确指定了国家路由,并启用了地理对齐。
- CAPTCHA 或封禁频繁:通常意味着抓取行为过于激进。降低请求频率、提高会话复用效率,并避免在单一浏览器实例中并行加载多个页面。
- 页面内容不完整或不一致:部分页面会动态加载数据。使用合适的等待条件,并在提取前确认所需元素已出现。
- 浏览器意外崩溃或断连:定期重启浏览器会话,并限制单次会话持续时间,避免长期任务导致资源耗尽。
- Bright Data Web Unlocker:对于 Cloudflare 完全阻断浏览器自动化的网站,Bright Data 的 Web Unlocker 可自动绕过 Cloudflare,无需编写代码,避免浏览器层面的各种绕行方案。
真实电商项目:使用 Camoufox 进行网页爬取(完整代码)
该项目演示在受 Cloudflare 保护的电商类目页面上,使用 Camoufox 进行基于浏览器的网页爬取。目标是在多页分页中提取结构化商品数据,同时以可控且可复现的方式处理导航失败与分页逻辑。
这类工作流常见于价格监控、目录分析与竞品情报。
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
import time
# Bright Data proxy configuration (masked)
proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<customer_id>-zone-<zone_name>-country-us",
"password": "<your_proxy_password>",
}
results = []
with Camoufox(
proxy=proxy,
headless=True,
geoip=True,
) as browser:
# Create a new browser page and allow HTTPS interception
page = browser.new_page(ignore_https_errors=True)
page.set_default_timeout(60000)
base_url = "https://books.toscrape.com/"
max_pages = 5
for page_number in range(1, max_pages + 1):
try:
print(f"Scraping page {page_number}")
# Navigate to the page
page.goto(
base_url,
wait_until="domcontentloaded"
)
# Locate all product cards
books = page.locator(".product_pod")
count = books.count()
if count == 0:
print("No products found, stopping crawl")
break
# Extract data from each product
for i in range(count):
book = books.nth(i)
title = book.locator("h3 a").get_attribute("title")
price = book.locator(".price_color").inner_text()
availability = book.locator(".availability").inner_text().strip()
results.append({
"title": title,
"price": price,
"availability": availability,
"page": page_number,
})
# Add a small delay to avoid aggressive request patterns
time.sleep(2)
except TimeoutError:
print(f"Timeout on page {page_number}, skipping")
continue
except Exception as e:
print(f"Unexpected error on page {page_number}: {e}")
break
print(f"\nCollected {len(results)} books")
# Preview a few results
for item in results[:5]:
print(item)Camoufox 会启动一个基于真实 Firefox 的浏览器实例,而 Bright Data 提供的住宅 IP 地址看起来更像真实用户流量。
脚本访问 Books to Scrape 网站,等待 DOM 加载完成,然后定位页面上的每个商品卡片。
对每个图书条目,它会提取标题、价格、库存状态等结构化字段,并存入 Python 列表,供后续处理。
代码还包含真实场景必需的基础稳健性机制:优雅处理导航超时、遇到不可预期错误时安全停止爬取,并在页面加载之间加入小延迟以避免激进的流量模式。
同时显式忽略 HTTPS 拦截错误,这在通过会终止 TLS 的代理路由浏览器流量时是必要的。
输出:
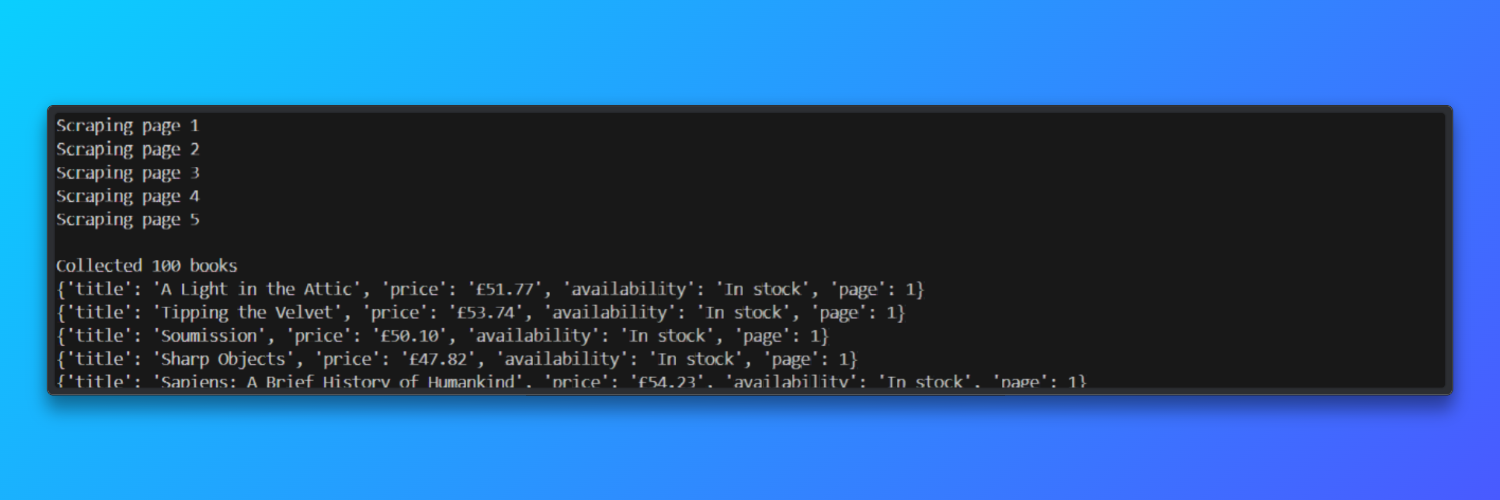
在测试运行中,爬虫在约 45 秒内处理了 5 个分页页面,并在使用 Bright Data 住宅代理时实现了约 92% 的页面加载成功率。
性能基准与局限
本节总结使用 Camoufox + 住宅代理时观察到的性能数据、实际限制与规模化影响,以及这些限制如何决定下一步架构选择。
测得的基准(观察值)
- 指纹鲁棒性:Camoufox 在 CreepJS 测试中得分 70%+,对开源工具而言,说明其对常见浏览器指纹检测具备较强抵抗力。
- 内存占用:每个浏览器实例约 200 MB RAM,直接限制了普通服务器的横向扩展能力。
- 会话寿命:Cookie 每 30–60 分钟过期,需要手动刷新或重启会话以维持访问。
- 随时间衰减的成功率:第 1 小时约 92% → 第 2 小时约 40% → 第 3 小时约 10%,随着会话老化,检测系统会适应并提高拦截。
- 基础设施对比:Bright Data 提供 1.75 亿+ IP、99.95% 可用性,并且用户侧维护时间为 0。
规模化时观察到的限制
当使用 Camoufox 的网页爬取运行更久或规模更大时,会逐步暴露以下限制:
- 会话过期:Cookie 通常 30–60 分钟内过期,需要手动刷新或重启浏览器以保持访问。
- 内存占用:每个浏览器实例约消耗 200 MB RAM,限制普通服务器并发。
- 并发上限:在 8 GB 服务器上,实际可行并发约为 ~30 个浏览器实例,超过后稳定性明显下降。
- 随时间可靠性下降:成功率会随会话老化而明显下滑——第 1 小时 ~92%,第 2 小时 ~40%,第 3 小时 ~10%(若不干预)。
- 运维开销:要维持稳定结果通常需要每月 20–30 小时的主动维护与调参。
对于需要长期运行任务或可预测稳定性的团队,这些限制会让重点从“爬取逻辑”转移到“基础设施管理”。
此时,托管方案会成为更现实的替代选择。Bright Data 的基础设施提供 1.75 亿+ 住宅 IP、99.95% 可用性,并免去了手动管理 Cookie 与会话的需求。
在生产环境中,这通常能带来 99%+ 的稳定成功率,避免自建浏览器自动化方案中随时间衰减的问题。
当把维护时间与基础设施成本一并计算时,托管方案往往能降低月度总成本。($1,200/月 vs $2,850 自建(含维护))。
Camoufox vs Puppeteer vs Bright Data(对比表)
下表对比了 Camoufox + Bright Data 住宅代理、Puppeteer 与 Bright Data Scraping Browser 在真实爬取项目中最关键的维度。
| 功能 | Camoufox + Bright Data 代理 | Puppeteer | Bright Data Scraping Browser |
|---|---|---|---|
| 成功率 | 住宅代理下成功率约 ~92% | 在受保护站点约 ~15–30% | 稳定 99%+ 成功率 |
| 搭建成本 | 中等:需要代理与指纹调优 | 高:需要补丁与插件 | 低:开箱即用 |
| Cookie 管理 | 每 30–60 分钟需手动刷新 | 完全手动处理 | 自动 Cookie 管理 |
| 扩展上限 | 每台服务器约 ~30 个并发浏览器 | 约 ~50 个并发浏览器 | 无限扩展 |
| 每月维护时间 | 20–30 小时持续维护 | 40–60 小时维护 | 0 小时 |
| 成本(100 万请求) | 约 ~$2,850(含代理费用) | 约 ~$2,500 + 工程时间 | 总成本约 ~$1,200 |
何时迁移到 Bright Data
用于绕过反爬的 Camoufox 浏览器非常适合构建早期爬取工作流,但并不是为持续、高吞吐的生产使用而设计。
随着项目规模扩大,30–60 分钟的 Cookie 过期、长时间运行的成功率下降,以及需要频繁重启浏览器等问题,会带来明显的运维开销。
当使用 Camoufox 的网页爬取需要稳定 99%+ 成功率、并发高于每台服务器约 ~30 个浏览器、并且需要无需持续调参的可预测性能时,迁移到 Bright Data 就成为更现实的下一步。
Bright Data 的托管采集方案会自动处理浏览器指纹、会话保持、重试与扩展,从而消除手动维护并稳定长期运行的流水线。
关键要点
本指南展示了 Camoufox 网页爬取在实践中的使用方式、优势与限制。Camoufox 与住宅代理结合,非常适合用于原型验证、实验探索,以及理解现代反爬系统。
对于对可靠性、规模与成本效率有要求的生产环境,像 Bright Data 这样的托管采集基础设施通常具备更清晰的运维路径。
如果你的 Camoufox Python 配置已经可用,但仍需要频繁重启、重置会话或调代理,那么瓶颈通常在基础设施,而不是爬取逻辑本身。
了解 Bright Data 的住宅代理与 Scraping Browser,以降低维护成本,并在规模化场景下实现稳定、生产级的结果。
另外,Bright Data 的 Scraping Browser 也是 Camoufox 的生产级替代方案:它会自动处理指纹、会话保持与重试。
总体而言,它是市场上规模最大、速度最快、可靠性最高的爬取导向代理网络之一。
立即注册并开始你的免费代理试用!



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





