

在本教程中,你将学习:
- 什么是 Mistral Vibe 以及它提供什么。
- 为什么通过 Web 访问扩展它可以让你克服其最大的限制。
- Bright Data 如何支持 Vibe 集成以实现网页抓取、网页搜索和浏览器自动化。
- 如何通过 MCP 将 Bright Data 连接到 Mistral Vibe 编码代理。
- 如何通过 Agent 技能 让 Mistral Vibe 了解 Bright Data 解决方案。
- Bright Data + Mistral Vibe 集成的优势,并附带一个完整示例。
让我们开始吧!
什么是 Mistral Vibe?
Mistral Vibe 是一个由 Mistral 的 AI 模型驱动的开源 CLI 编码助手。具体来说,它提供了一个对话式界面,使用自然语言来探索、修改并与代码库交互。
Vibe 帮助开发者自动化重复性任务、重构代码、运行 shell 命令,并将工作委派给子代理。它具有开源特性,在 GitHub 上拥有超过 3.8k 星标。
其主要功能包括:
- 与 Mistral AI 模型进行交互式聊天,用于代码探索与修改。
- 文件读/写、搜索/替换,以及 shell 命令执行。
- 将任务委派给子代理以实现并行工作流。
- 项目感知上下文与 Git 集成。
- 自定义技能与斜杠命令系统。
- 自动补全、持久化历史记录以及可配置的 UI 主题。
- 工具执行审批与受信任文件夹等安全功能。
为什么 Mistral Vibe 需要访问 Web
无论你配置的 Mistral 模型多么强大,Vibe 编码代理都会遇到每个 LLM 都共有的关键约束:信息停滞!归根结底,LLM 只会生成源自训练期间使用的数据集的输出。问题在于,这些训练材料构成了历史的静态快照……
考虑到技术世界发展如此迅速,这种限制就显得非常重大。LLM 可能会推荐过时的编程习惯、使用已弃用的函数,或完全忽略最近发布的更新。
要解决这些限制,你必须为你的 AI 软件工具增强实时 Web 访问。这正是 Bright Data 所提供的!
Bright Data 面向 AI 的 Web 访问基础设施 使你的代理能够自主地:
- 从相关在线来源发现最新信息,并像普通用户一样在 Google 和其他引擎上执行网页搜索。
- 从文档页面、Stack Overflow、论坛和其他来源学习,以保持最新,并在需要时自我纠正。
- 为填充数据库或模拟响应等任务检索真实、结构化的 Web 数据。
- 建议相关链接以供进一步阅读,或增强你的
README.md文件。 - 处理广泛的其他真实世界用例。
Bright Data 的与众不同之处在于其庞大的网络基础设施,由覆盖 195 个国家/地区的超过 4 亿住宅代理 IP 支持。这使其能够在实现 99.99% 正常运行时间和 99.95% 成功率的同时实现无限扩展。
如何通过网页抓取、搜索和探索能力扩展 Mistral Vibe
Bright Data 通过两种可能的集成方式支持 Mistral Vibe:
- Bright Data Web MCP:官方 Bright Data MCP 服务器,提供 60+ 工具来与 Bright Data 基于 API 的产品与服务交互。
- Bright Data 技能:一组与 Agent 技能 标准对齐的技能,为 AI 代理提供有效使用 Bright Data 产品所需的知识。
重要:这两种方法并非互斥。恰恰相反,它们是互补且协同的!这是因为 Bright Data skills 包含一个技能,可帮助 AI 编码代理最大化利用 Web MPC 工具。
Bright Data Web MCP
Bright Data Web MCP 提供 60+ 工具,支持自动化 Web 数据收集、结构化数据提取以及浏览器交互。
即使在免费层级,它也提供了有趣的工具:
| Tool | Description |
|---|---|
search_engine |
以 JSON 或 Markdown 格式检索 Google、Bing 或 Yandex 结果。 |
scrape_as_markdown |
将任意网页转换为干净的 Markdown,绕过反机器人措施。 |
discover |
搜索 Web 并使用 AI 驱动的相关性对结果进行排序。 |
你还可以访问 search_engine 和 scrape_as_markdown 工具的批处理版本。
不过,Pro mode 才是 Web MCP 真正大放异彩之处。这将解锁用于从 Amazon、GitHub、LinkedIn、YouTube、TikTok、Yahoo Finance、Zillow、Google Maps 等平台提取结构化数据的高级工具。此外,你还将获得用于浏览器自动化的工具。
Bright Data 技能
Bright Data 技能 包括:
| Skill | Description |
|---|---|
search |
搜索 Google 并获取包含标题、链接和描述的结构化 JSON 结果。支持分页。 |
scrape |
将任意网页抓取为干净的 Markdown,具备绕过机器人、验证码破解以及 JavaScript 渲染能力。 |
data-feeds |
从包括 Amazon、LinkedIn、TikTok、YouTube、eBay 和 Walmart 在内的 40+ 网站提取结构化数据,等等。 |
bright-data-mcp |
编排 Bright Data MCP 工具,以实现更好的搜索、抓取、提取和浏览器自动化。 |
scraper-builder |
指导代理构建可用于生产的爬虫工具,从站点分析到完整实现。 |
bright-data-best-practices |
使用 Bright Data 的 网络解锁器、搜索引擎 API、爬虫工具 API 和 Browser API 的参考。 |
python-sdk-best-practices |
brightdata-sdk Python 包指南,涵盖 async/sync 客户端、抓取工具、数据集和错误。 |
brightdata-cli |
使用 Bright Data CLI 进行抓取、搜索、数据提取、代理和监控的说明。 |
competitive-intel |
提供实时竞争洞察:定价、评论、招聘信号、内容、SEO 和市场地图。 |
design-mirror |
复制设计系统模式、tokens 和组件,以实现一致的 UI。 |
brd-browser-debug |
调试 Bright Data 浏览器会话,包含失败分诊、带宽跟踪、CAPTCHA 破解报告和模式。 |
通用步骤
在展示如何通过 MCP 或 技能 将 Bright Data 集成到 Vibe 之前,你需要先处理一些通用的前置操作。
前提条件
要跟随本教程,请确保你具备:
- 基于 Unix 的操作系统,例如 Linux、macOS,或在 Windows 中配置好的 WSL。
- 本地已安装 Node.js。这是为了在本地设置 MCP 并通过
技能包安装 skills 所必需的。如果你计划手动安装 技能 并远程连接到 Web MCP,则可以跳过此前提条件。 - 一个 Mistral 账户,最好已经配置好 API key。
- 一个已定义 API key 的 Bright Data 账户。
要生成 Bright Data API key,请遵循官方指南。
步骤 #1:安装 Mistral Vibe
打开终端并运行以下命令以下载并执行 Vibe 安装脚本:
curl -LsSf https://mistral.ai/vibe/install.sh | bash这将启动 Mistral Vibe 安装工具,它会检索并安装所有必需的软件包: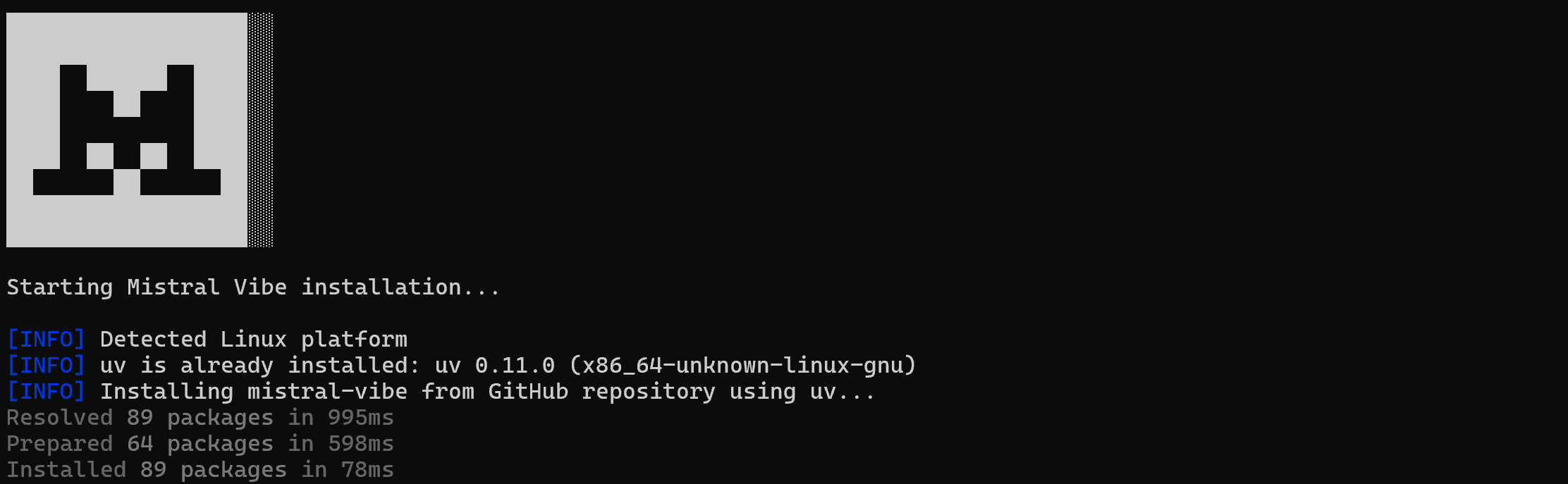
安装完成后,你应该会看到类似这样的输出:
!注意“[SUCCESS]”消息
现在,你可以通过以下方式在系统上运行 Mistral Vibe:
vibe做得好!Vibe 已成功安装。
步骤 #2:完成设置
在终端中为你的项目创建一个文件夹(或导航到现有文件夹)。在此示例中,我们将假设你的项目目录是 mistral-bright-data-example:
mkdir mistral-bright-data-example
cd mistral-bright-data-example在你的项目文件夹内,启动 Mistral Vibe:
vibe第一次运行该工具时,你会看到类似这样的欢迎消息: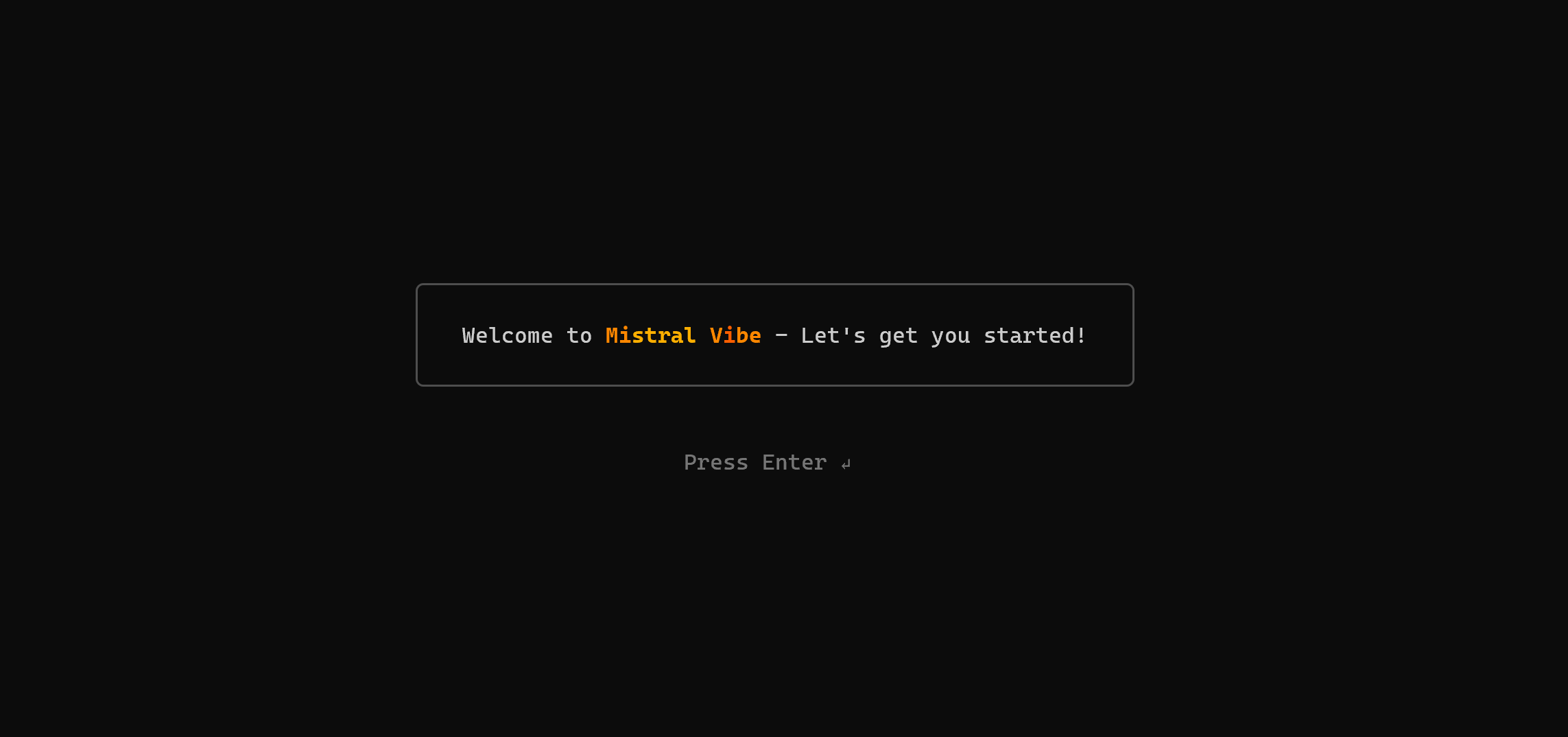
按 Enter,然后系统会提示你输入 Mistral API key。如果你还没有,请前往你账户中的 Mistral Vibe CLI 页面,并在 “Start for free with your API plan” 下拉菜单下点击 “Generate your API key” 按钮: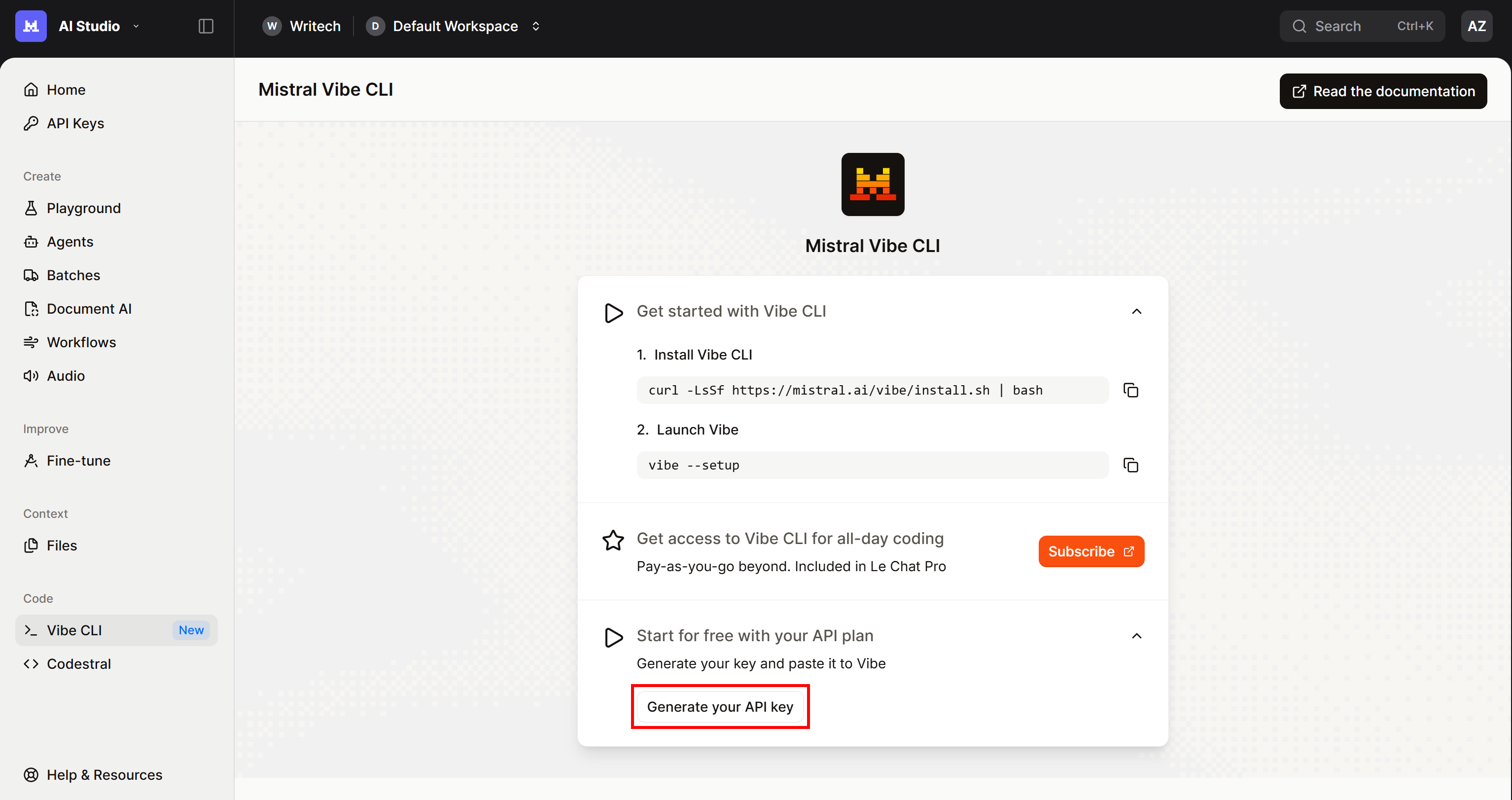
按照说明操作,订阅一个计划(即使是免费的 “Experiment” 计划也可以),并生成你的 API key。
获得 Mistral API key 后,将其粘贴到字段中并按 Enter:
输入 API key 后,你将进入 Mistral Vibe 终端 UI:
从这里,你可以配置模型、系统提示等。这也是你将发起提示的地方。
太棒了!Mistral Vibe 现在已配置完成,并准备在你的系统上运行。
将 Bright Data Web MCP 连接到 Mistral Vibe
本节将指导你完成在 Mistral Vibe 中配置 Bright Data Web MCP 本地实例的过程。
前提条件
为了更轻松地跟随本节内容,建议具备:
- 对 MCP 的工作原理有基本理解。
- 对 Bright Data Web MCP 暴露的工具有一定了解。
另外,请记住,“通用步骤”章节中列出的前提条件在这里同样适用。
步骤 #1:开始使用 Bright Data 的 Web MCP
在 Mistral Vibe 中配置 Bright Data 的 Web MCP 之前,你需要验证 MCP 服务器能在你的机器上运行。或者,你可以跳过此步骤并配置到 Bright Data Web MCP 的远程连接。
首先,登录你的 Bright Data 账户。要快速设置,请按照控制面板 “MCP” 部分中的向导操作: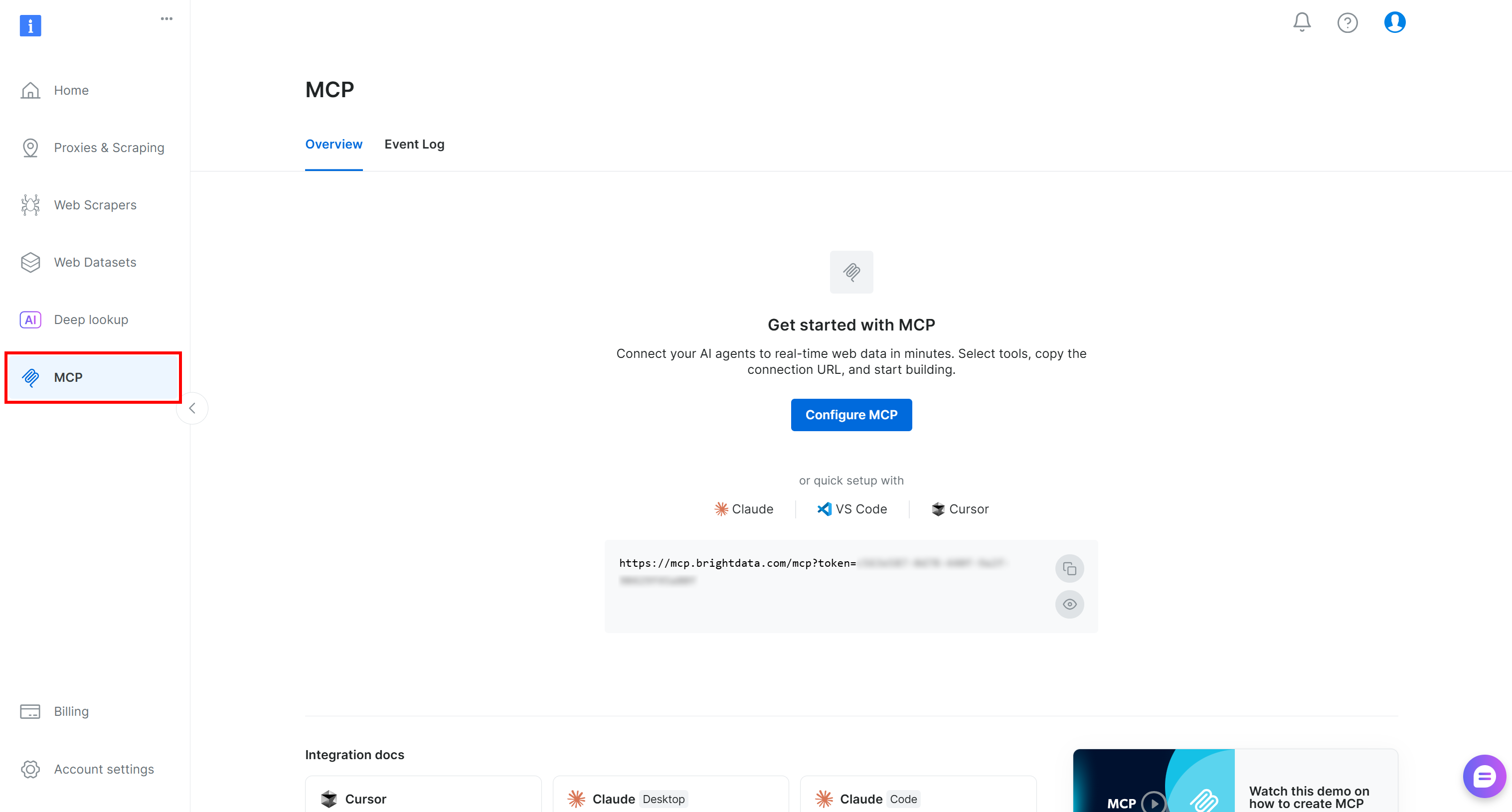
否则,如需更多指导,请参考下面的说明。
首先,通过 @brightdata/mcp 包全局安装 Web MCP:
npm install -g @brightdata/mcp使用以下命令验证 MCP 服务器在本地启动:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你实际的 Bright Data API key。该命令会设置所需的 API_TOKEN 环境变量并在本地启动 Web MCP 服务器。
如果成功,你应该会看到类似的输出:
首次启动时,@brightdata/mcp 包会在你的 Bright Data 账户中自动创建两个区域:
mcp_unlocker:用于 网络解锁器 的区域。mcp_browser:用于 Browser API 的区域。
这两个区域为 Web MCP 中可用的 60+ 工具提供支持。请注意,你也可以配置你自己的自定义区域,如文档中所述。
要确认标准区域已创建,请前往 Bright Data 控制面板中的 “Proxies & Scraping Infrastructure” 页面。你应该会在表格中看到这两个区域: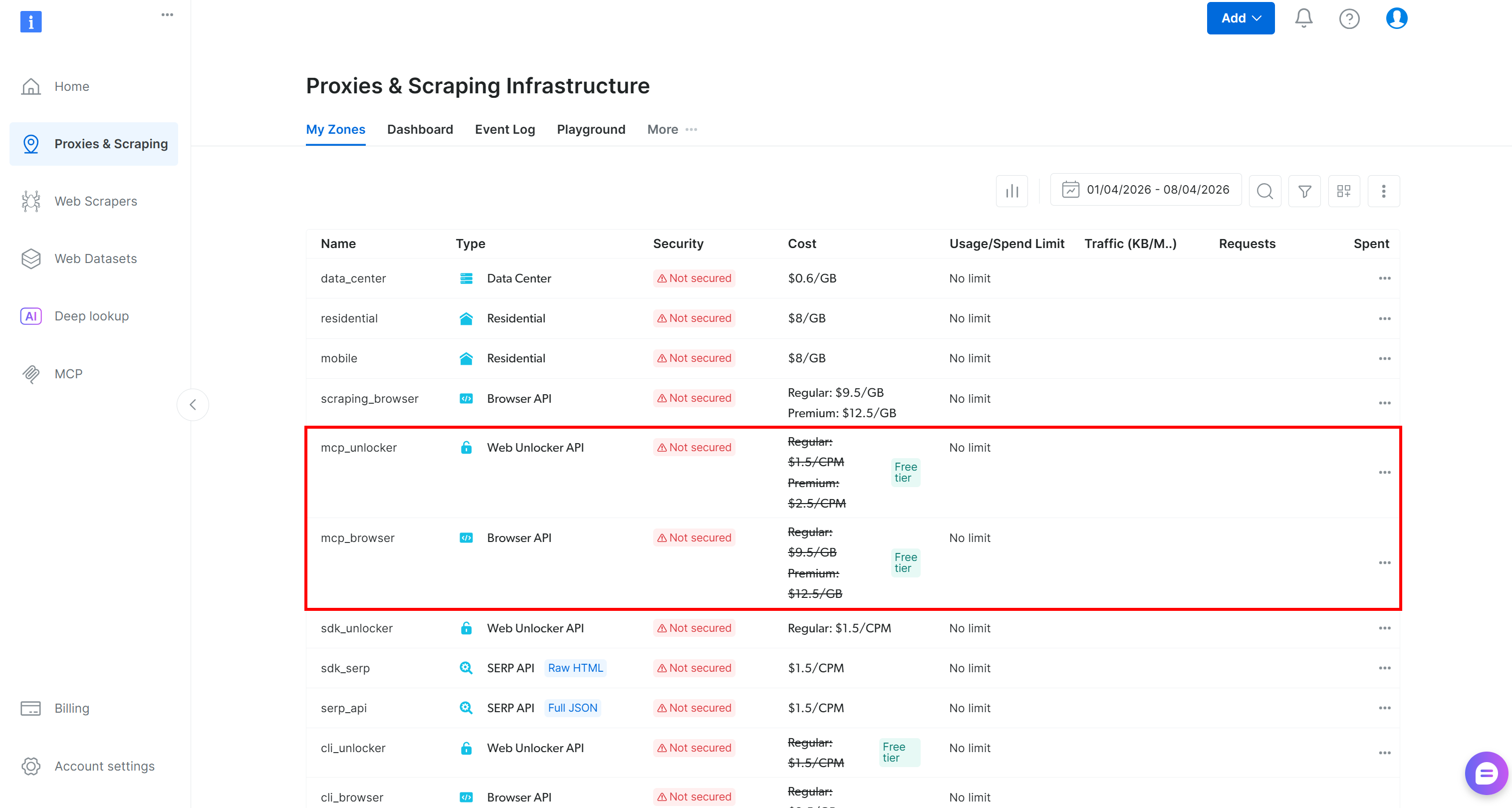
在 Web MCP 免费层级中,仅提供 search_engine 和 scrape_as_markdown 工具(+ 它们的批处理版本),以及 discover 工具。
要解锁全部 60+ 工具,请通过设置 PRO_MODE="true" 环境变量来启用 Pro mode:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp注意:Pro mode 不包含在免费层级中,并且会产生额外费用。
太棒了!你刚刚验证了 Web MCP 服务器可以在你的机器上运行。接下来,你将配置 Mistral Vibe 以自主启动服务器并连接到它。
步骤 #2:在 Mistral Vibe 中配置 Web MCP
在你的项目目录中,在 .vibe 目录内创建一个 config.toml 文件:
mistral-bright-data-example/
├── .vibe/
│ └── config.toml
└── ...这代表你项目中本地 Mistral Vibe 配置的文件。要配置 Web MCP 连接,请确保 ./.vibe/config.toml 文件包含以下内容:
[[mcp_servers]]
name = "bright-data"
transport = "stdio"
command = "npx"
args = ["@brightdata/mcp"]
env = { "API_TOKEN" = "<YOUR_BRIGHT_DATA_API_KEY>", "PRO_MODE" = "true" }此设置镜像了你之前测试的 npx 命令,使用环境变量来提供凭据和配置:
API_TOKEN:必需。将其设置为你的 Bright Data API key。PRO_MODE:可选。如果你不打算使用 Pro mode,请移除它(或将其设置为"false")。
如果你想为所有项目全局配置 Web MCP,请将相同配置添加到你的 ~/.vibe/config.toml 文件中。
注意:通过类似配置(transport = "http"),你可以通过 Streamable HTTP 连接到远程 Bright Data Web MCP。这种方法更适合企业级场景。
太棒了!Web MCP 现在应该可以在 Mistral Vibe 中使用了。
步骤 #3:验证连接
再次启动 Mistral Vibe:
vibe这一次,你应该会看到已连接一个 MCP 服务器: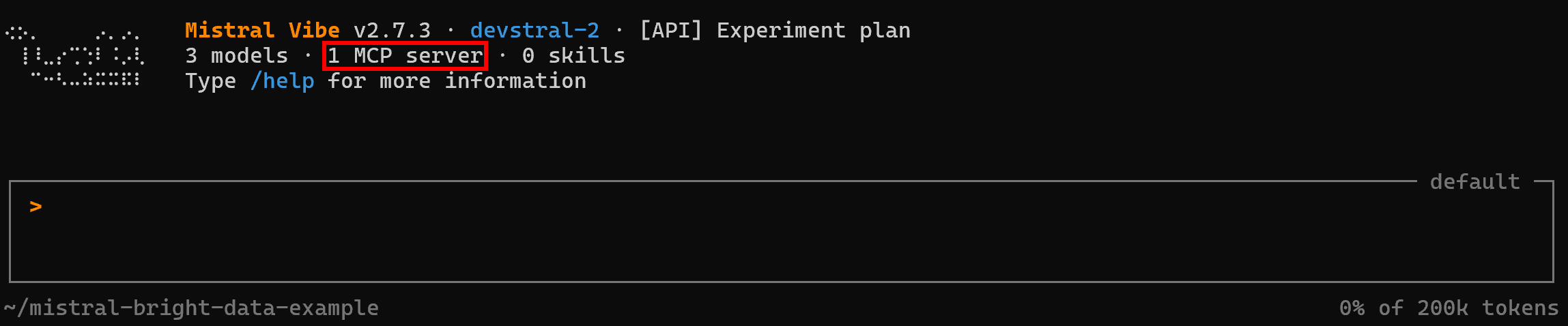
由于没有直接命令可用于检查 MCP 连接,请提出如下问题:
Which MCP tools do you have access to?在 Rapid(免费层级)模式下(省略 PRO_MODE 或将其设置为 false),你将看到五个免费工具: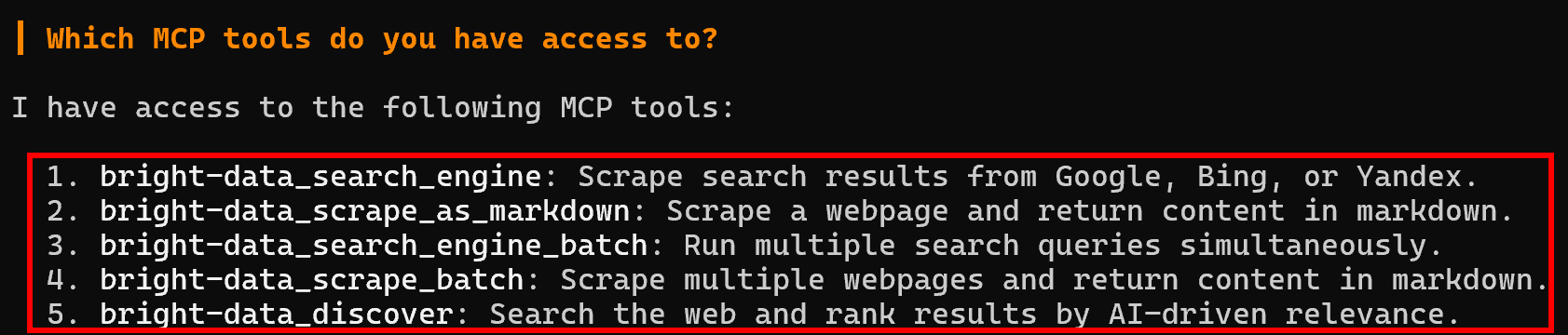
相反,在 Pro mode 下,你将可以访问全部 60+ 工具: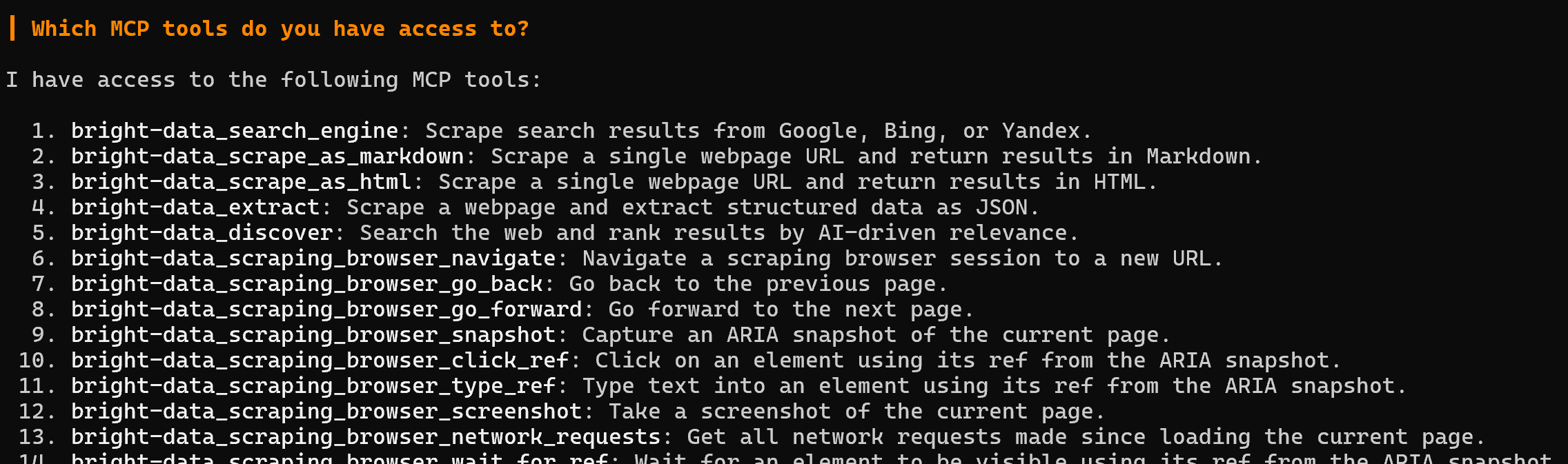
恭喜!这确认了 Bright Data Web MCP 正在正确地向 Mistral Vibe 暴露工具。(在本文后面,我们将展示 Web MCP 与 Bright Data 技能 一起实际运行的效果。)
将 Bright Data skills 添加到 Mistral Vibe
在这里,你将通过 Vercel 的 技能 工具提供的引导式体验,将 Bright Data skills 添加到你的 Vibe 项目中。
注意:对于手动方式,克隆 Bright Data 技能 仓库。接下来,只需将 skills/skills/ 文件夹的内容复制到你项目的 .vibe/skills 目录中:
git clone https://github.com/brightdata/skills
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.vibe/skills/现在,让我们来看一个简化且更可靠的流程!
前提条件
要继续本教程的这一部分,请确保你具备:
- 对 Agent 技能 标准如何工作的理解。
- 对 Vercel 的
技能工具有基本熟悉度,它是一个专用于在 AI 编码代理解决方案中管理 skills 的 CLI。 - 对 Bright Data 技能有一定了解。
除了“通用步骤”章节中列出的前提条件外,你还需要:
- 在你的 Bright Data 账户中设置一个 网络解锁器 API 区域。
- 本地安装
jq包。
要在基于 Debian 的操作系统上安装 jq(一个用于处理 JSON 的工具,类似于 sed),请运行:
sudo apt-get install curl jq同样地,在 macOS 上,执行:
brew install curl jq要快速设置 网络解锁器 API 区域,请参考 “创建你的第一个 Unlocker API” 指南。或者,按照下一章操作。
步骤 #1:在你的 Bright Data 账户中添加一个 网络解锁器 API 区域
登录你的 Bright Data 账户。在控制面板中,导航到 “Proxies & Scraping” 页面并查看 “My Zones” 表格: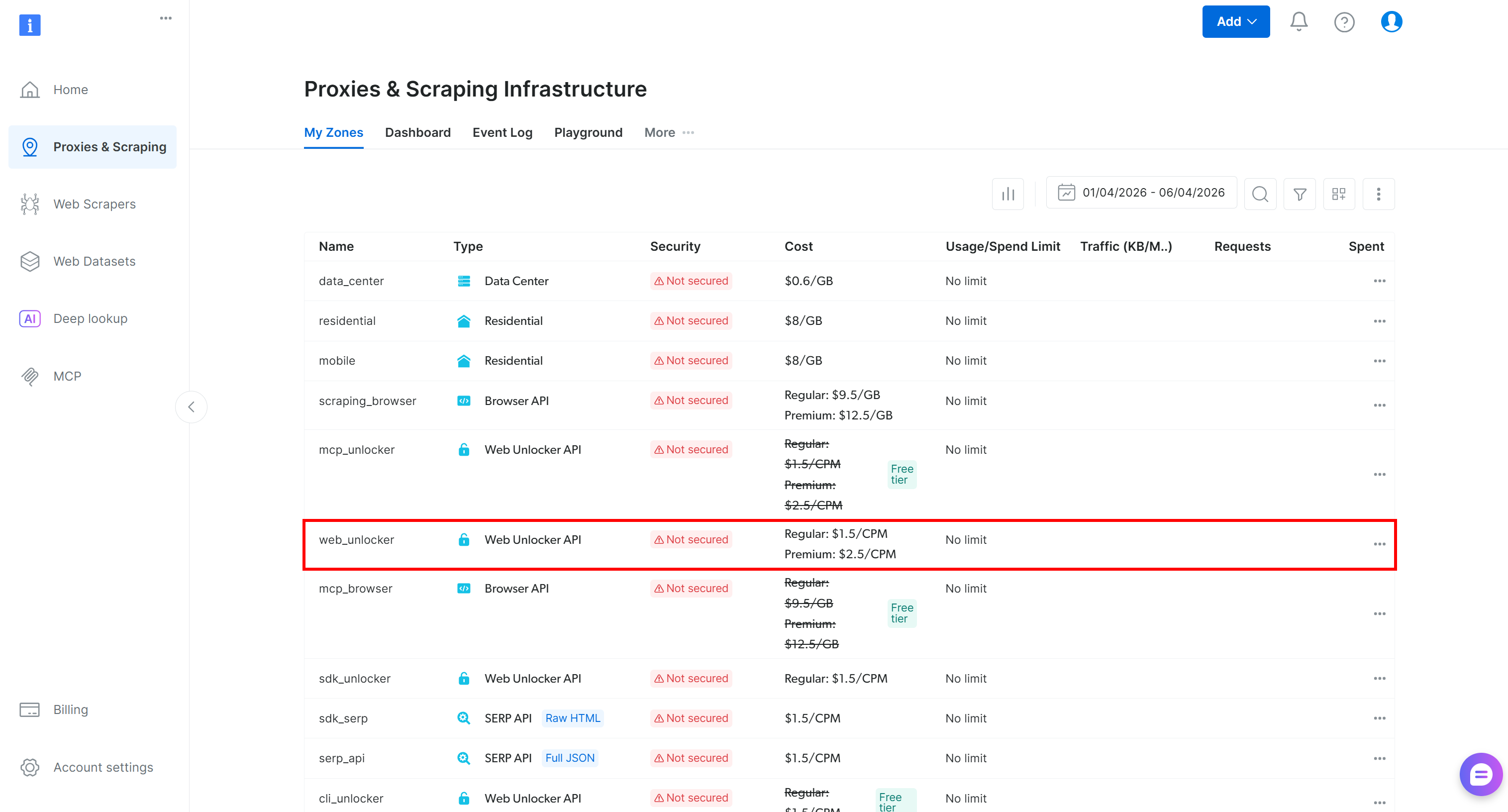
如果 网络解锁器 API 区域(例如 web_unlocker)已经存在,你可以继续下一步。
如果不存在,请滚动到 “Unblocker API” 卡片并点击 “Create 区域” 按钮来创建一个: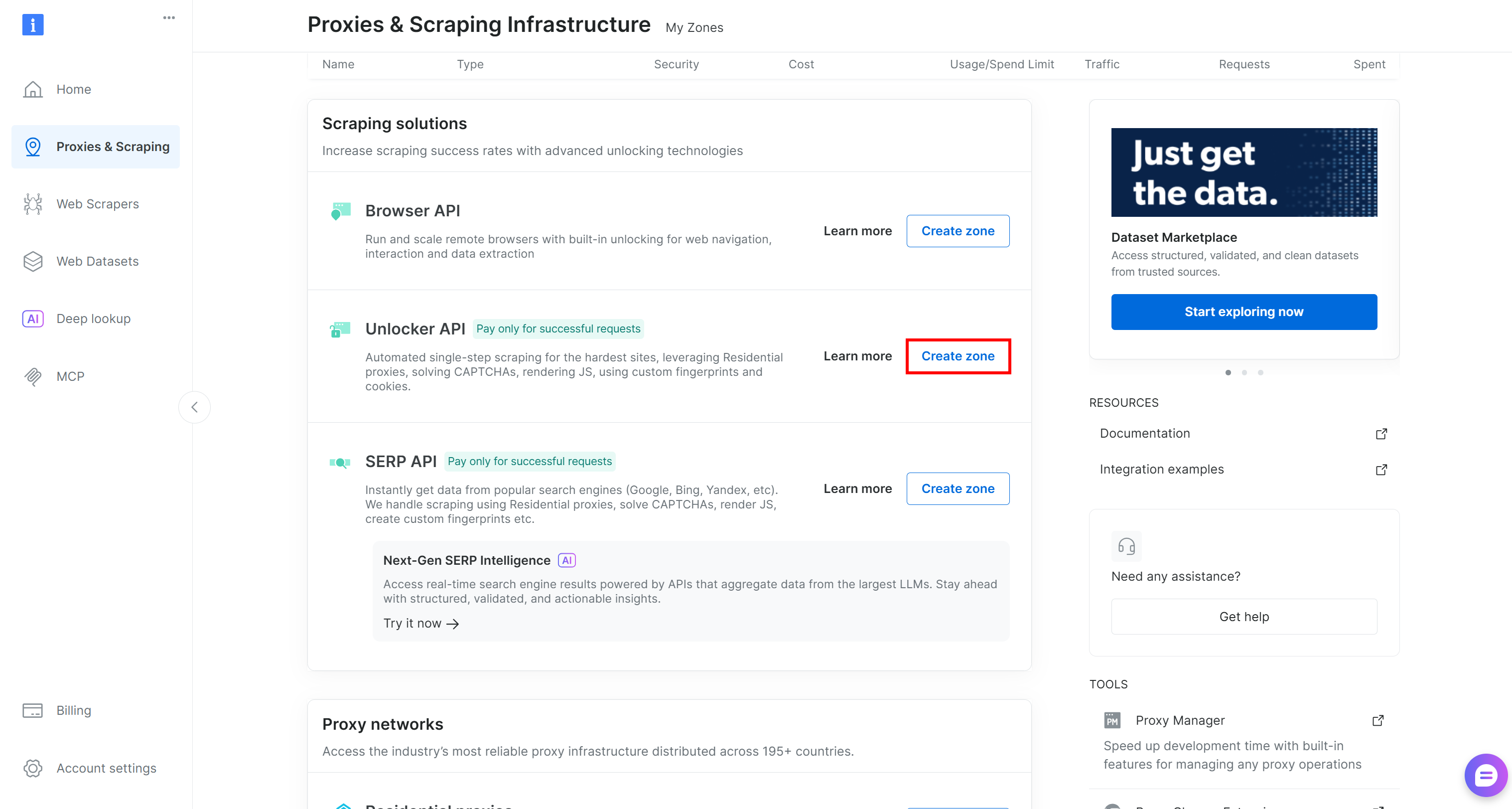
为你的区域选择一个清晰的名称,并完成设置向导,直到区域变为激活状态。完美!
步骤 #2:完成 Bright Data 技能 设置
Bright Data skills 需要以下两个环境变量才能工作:
BRIGHTDATA_API_KEY:用于对 Bright Data API 请求进行身份验证。BRIGHTDATA_UNLOCKER_ZONE:指定你的 网络解锁器 API 区域,从而启用网页抓取(以及搜索能力,作为一个搜索引擎 API 来运行)。
使用以下命令在你的系统中定义这些变量:
export BRIGHTDATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>"将占位符替换为你刚刚配置的值,就可以开始了!
步骤 #3:安装 Bright Data 技能
在你的项目文件夹中,运行以下命令:
npx skills add brightdata/skills -a mistral-vibe该命令会安装 技能 包并启动设置流程,该流程将:
- 从官方 Agent skills Directory 获取 Bright Data 技能。
- 将它们配置为可在 Mistral Vibe 中使用。
一开始,你会看到一个屏幕,你可以在其中选择要安装哪些 技能: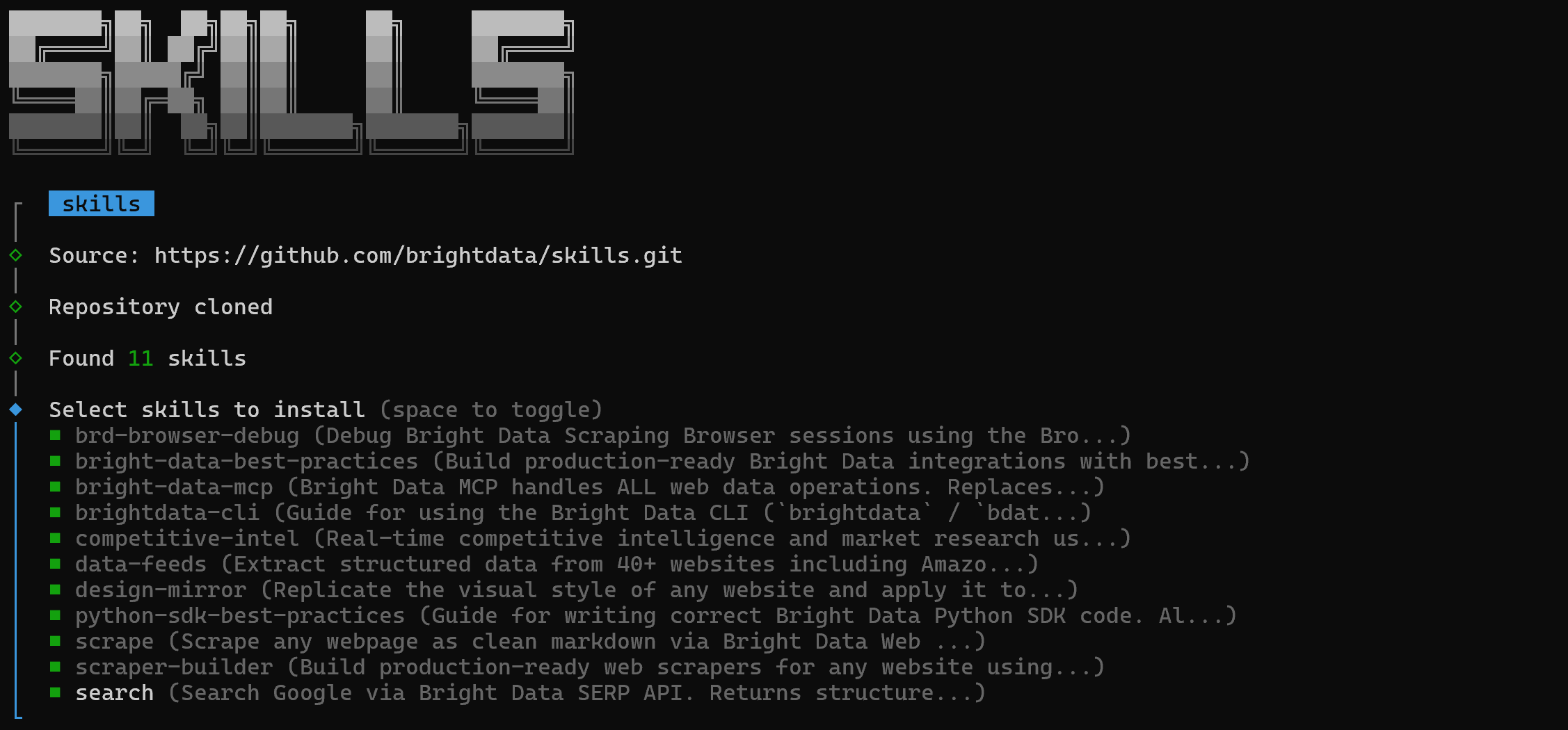
要全部安装,请使用空格键切换每一个,然后按 Enter。
接下来,选择安装范围并继续:
然后你将看到 “Installation Summary” 和 “Security Risk Assessment” 报告。查看它们并按 Enter 确认。最后,你会收到类似这样的确认消息: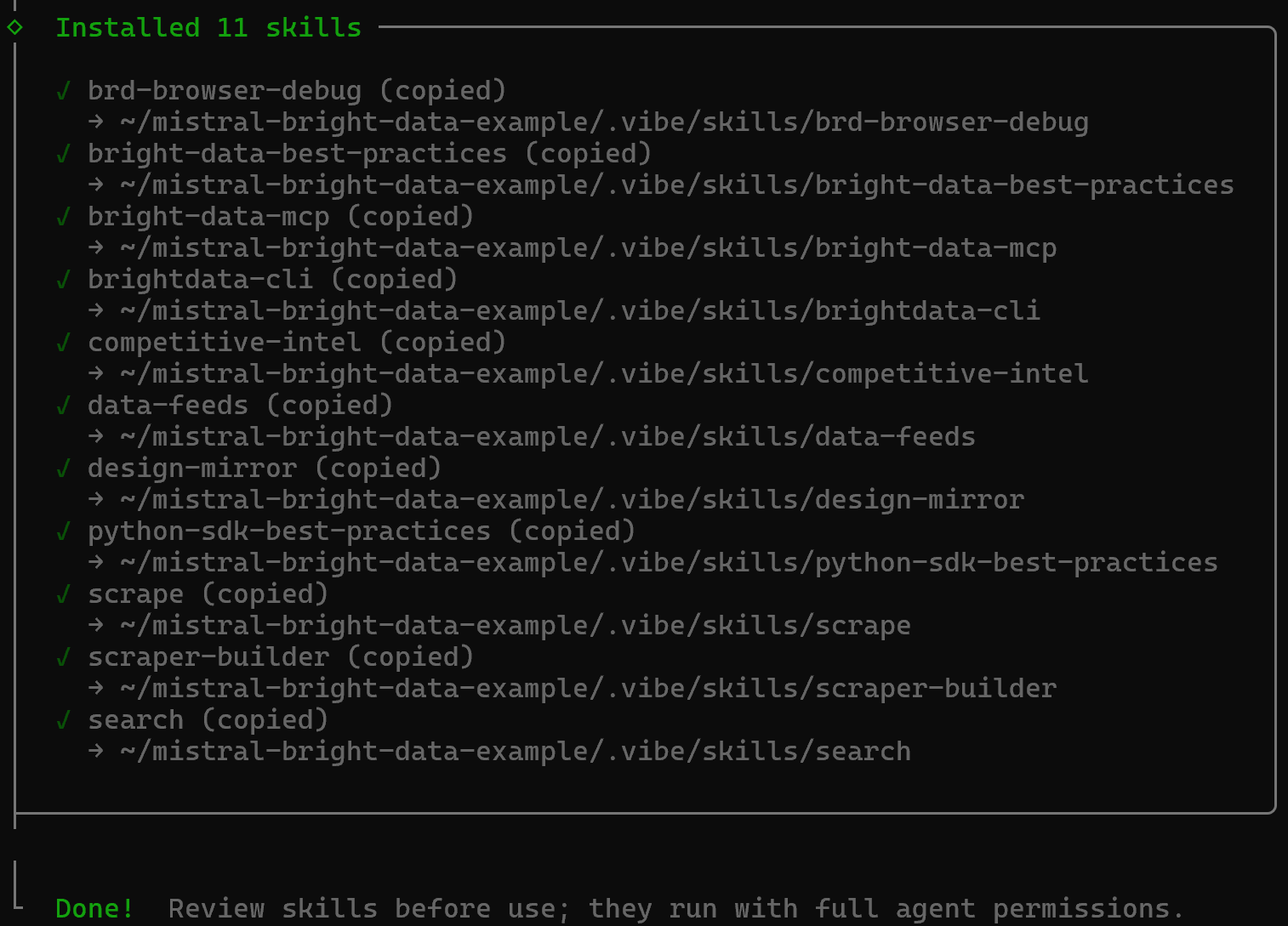
Bright Data 技能 将被复制到 .vibe/技能 目录中:
mistral-bright-data-example/
├── .vibe/
│ ├── config.toml
│ └── skills/
│ ├── brd-browser-debug/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── competitive-intel/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
└── ...很好!Bright Data 技能 现在已安装并可在 Mistral Vibe 中使用。
步骤 #4:验证设置
再次运行 Mistral Vibe:
vibe你应该会注意到编码代理现在可以访问 11 个 技能: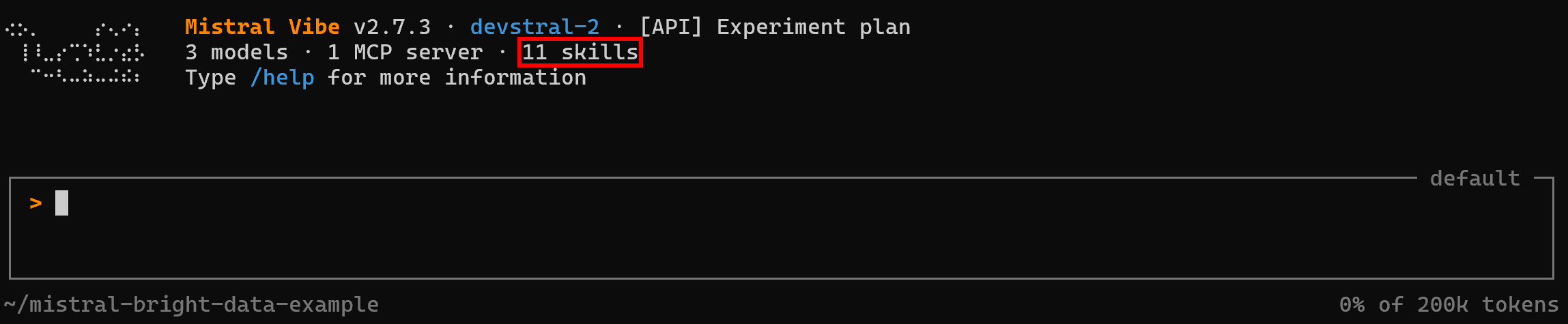
这些对应于 11 个 Bright Data 技能。通过运行以下提示来确认这一点:
Which skills do you have access to?响应应如下所示: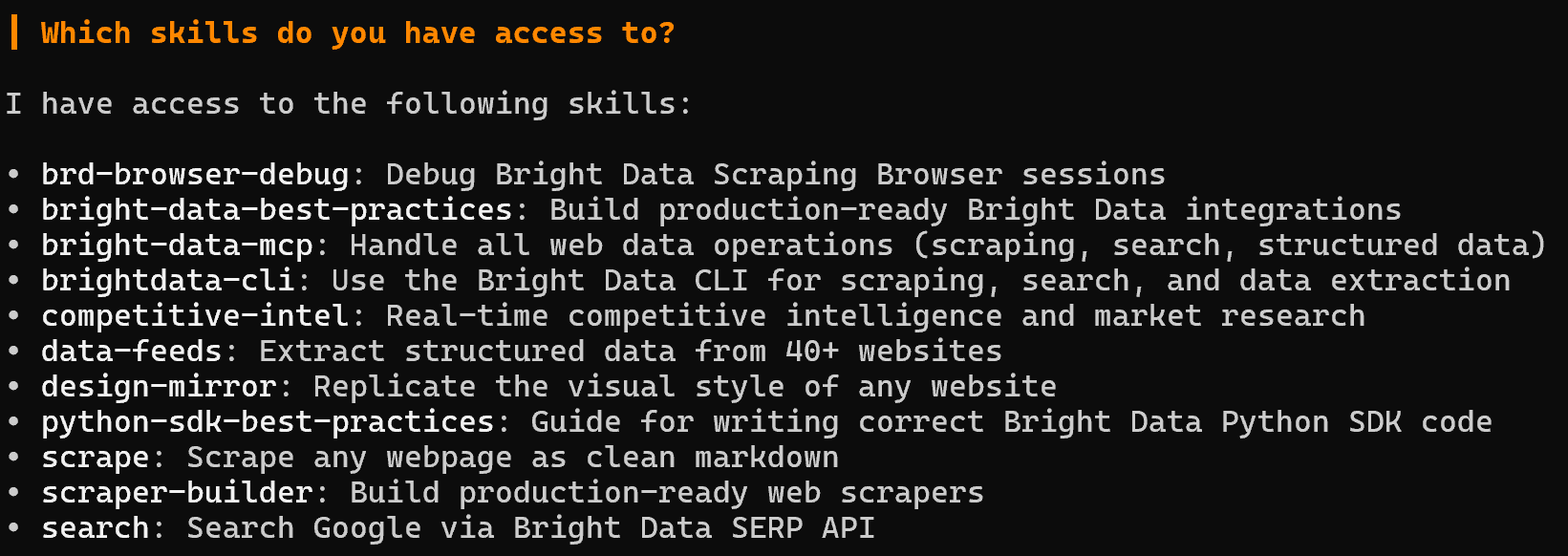
注意列出的 技能 如何与 .vibe/skills 目录中的文件夹名称匹配。
任务完成!在下一章中,你将看到如何在 Vibe 中充分利用 Bright Data Web MCP 和 技能 设置。
Mistral Vibe + Bright Data:终极代理式代码体验
现在你已经通过 MCP 和 skills 将 Bright Data 集成到 Mistral Vibe 中,来探索此设置能让你实现什么!我们将使用一个具体的真实世界示例,尽管还有无数其他场景也是可能的。
假设你想为下一个项目发现并分析最好的 JavaScript 数据可视化库。与其手动在线搜索并分析每个库,你可以让你的编码助手用如下提示来处理:
On Google, search for the top 5 most popular open-source libraries for data visualization in JavaScript. For each library, gather its main information from the official NPM package page. Then, from the discovered GitHub page of each library, scrape the main information in Markdown. Save the collected data in a structured JSON file.
Then, create a Python notebook project with a virtual environment. The notebook should read the JSON data file, create relevant plots and tables in dedicated cells, and include explanatory comments for each visualization to help make informed decisions.这很有趣,因为输出不仅仅是传统的 Markdown 报告。它会生成一个可交互的 Jupyter notebook,你可以运行并在其基础上继续构建。然后你可以复用该模板来分析其他库,让你的编码代理通过 Bright Data 检索所需的源数据。
显而易见的是,仅靠标准的 Mistral 模型或大多数 LLM 无法完成此任务。原因在于该任务涉及网页搜索和抓取,既通过结构化数据 feeds,也通过通用的 Markdown 内容检索。
运行该提示,你将得到类似如下内容: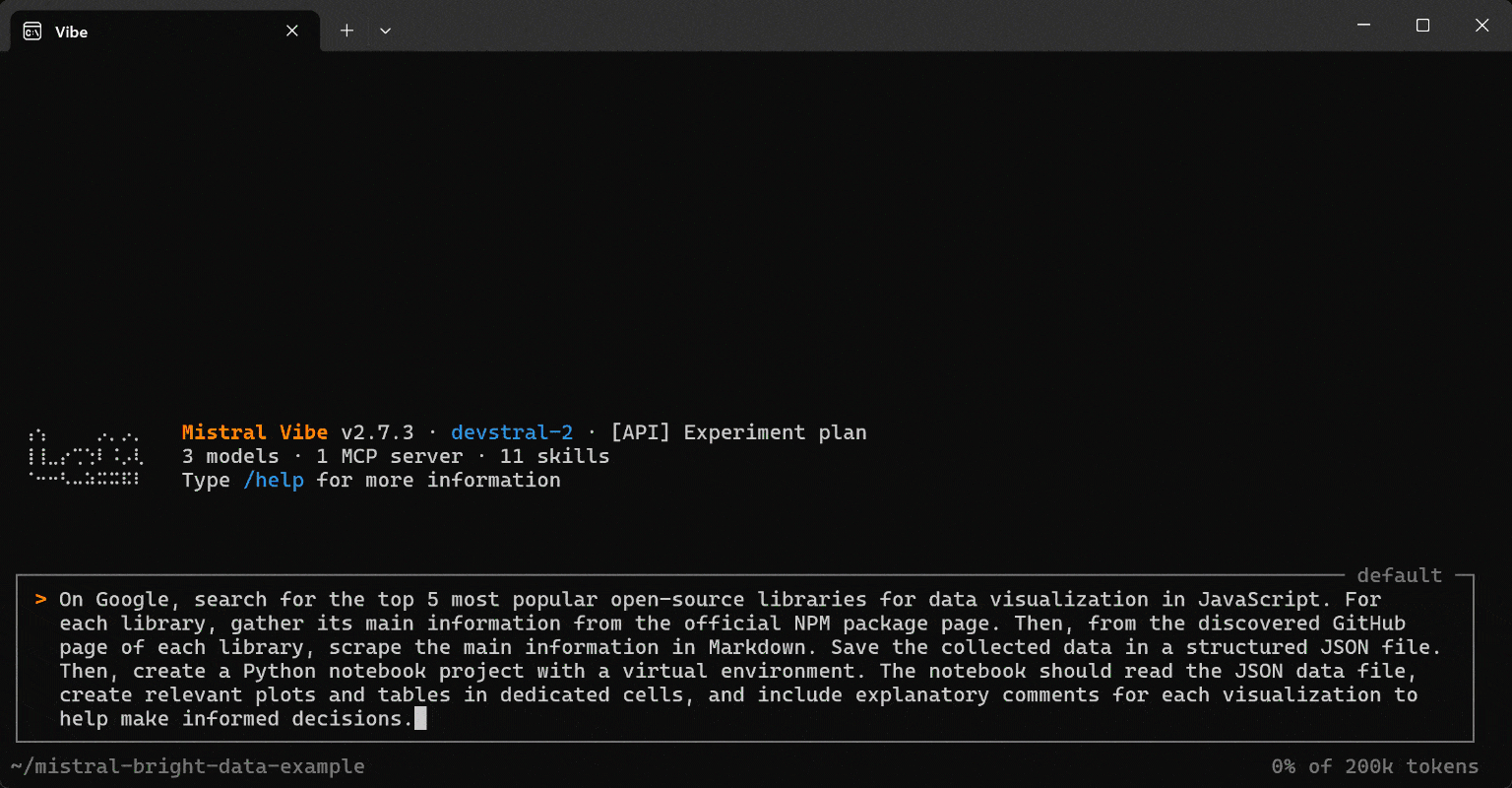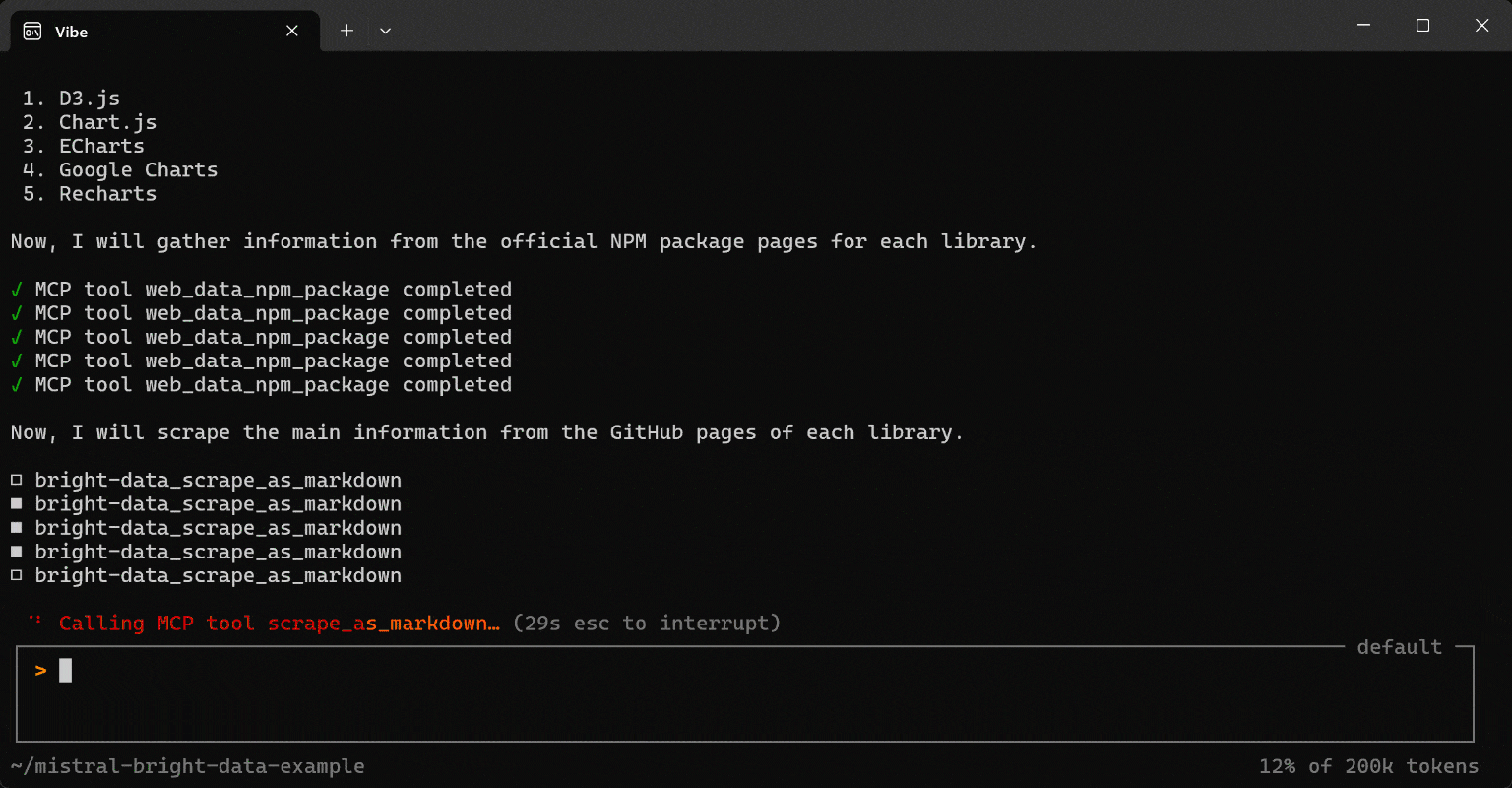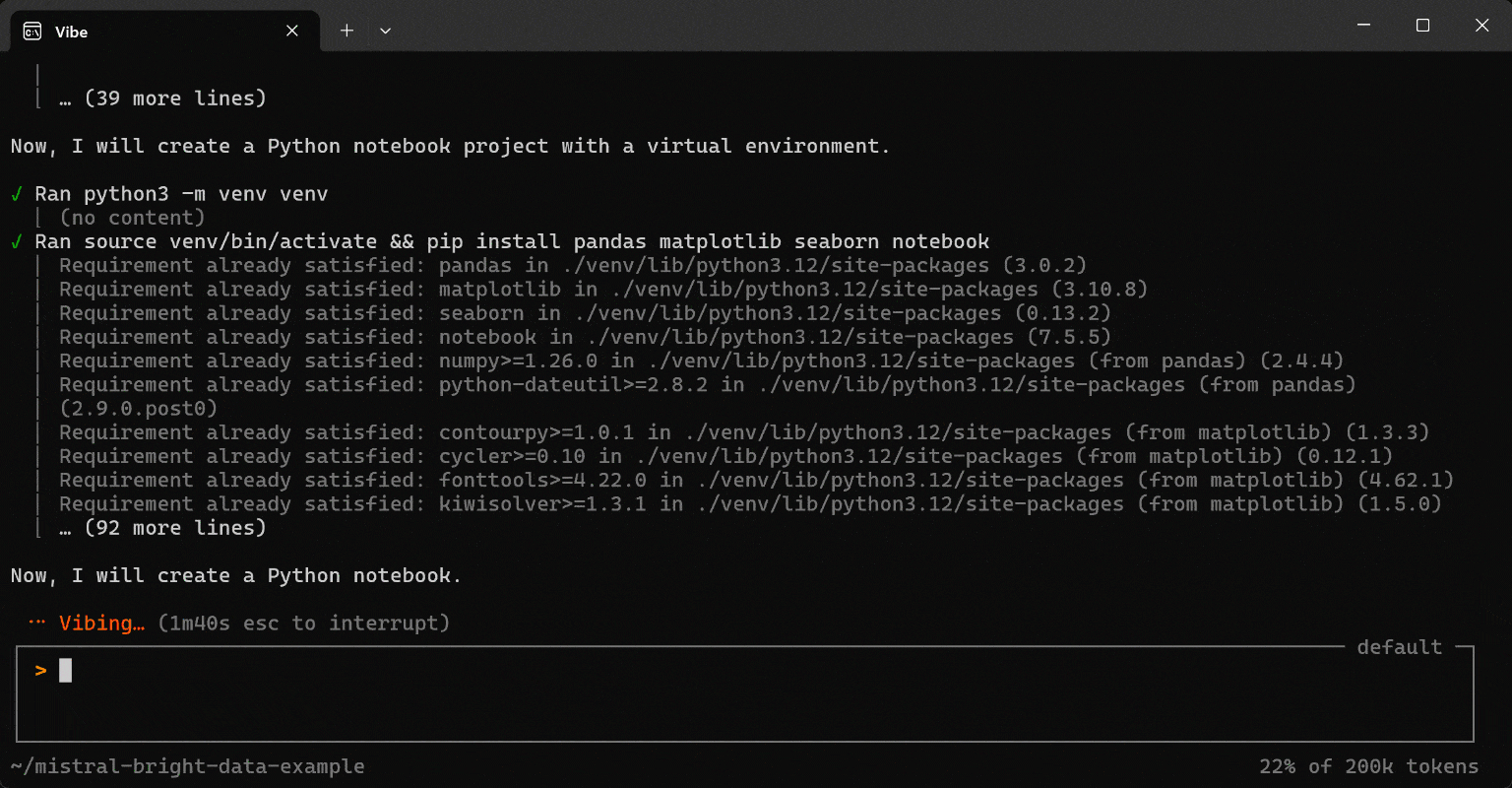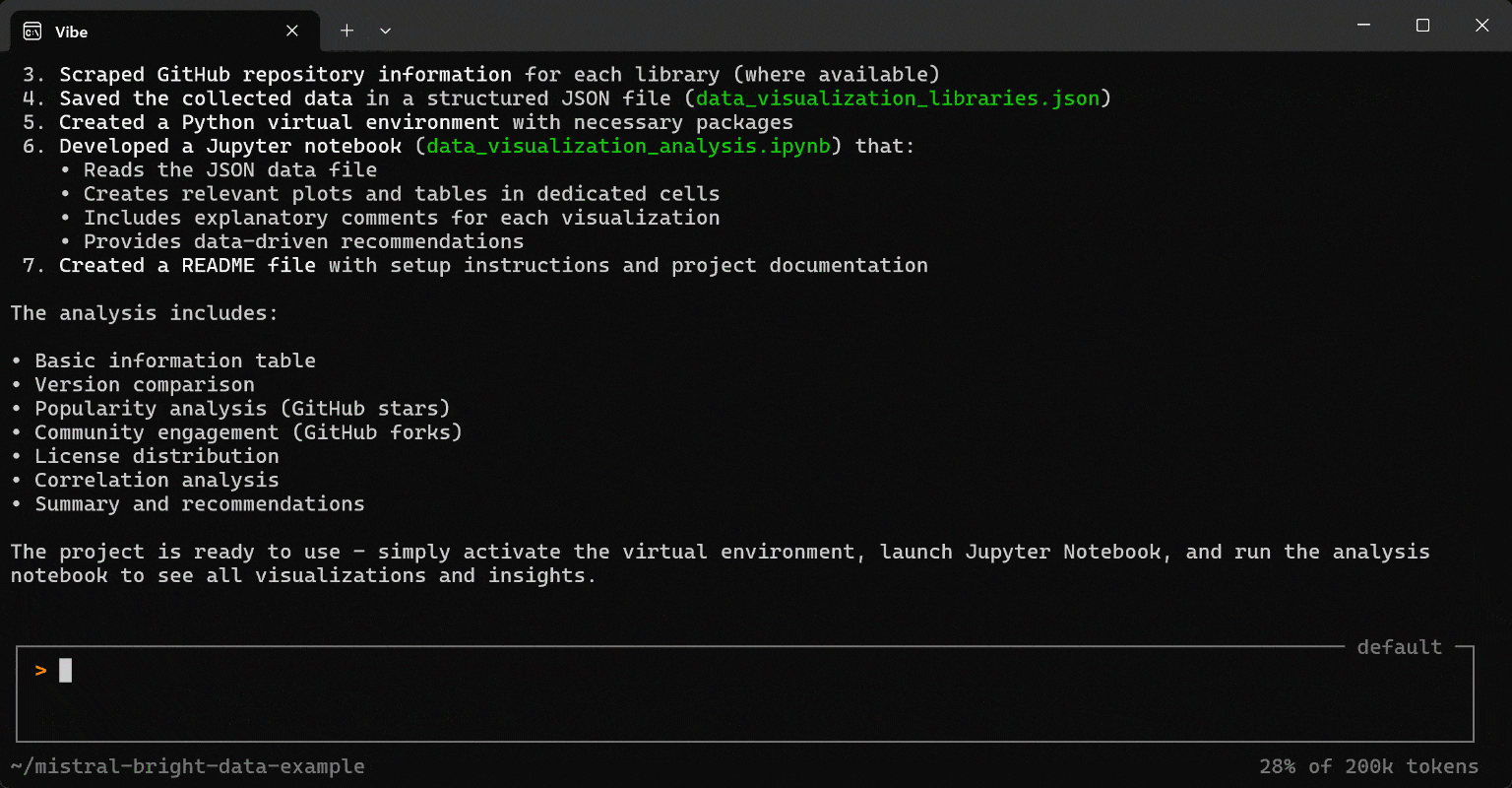
下面是 Mistral Vibe 编码代理如何处理该任务的:
- 使用 Bright Data 的
search_engine工具在 Google 上搜索 JavaScript 中排名前 5 的开源数据可视化库。 - 使用
web_data_npm_packagePro 工具从官方页面收集结构化的 NPM 包信息。 - 使用
scrape_as_markdown工具以 Markdown 形式抓取 GitHub 仓库信息。 - 将收集到的数据保存到结构化 JSON 文件(
data_visualization_libraries.json)中。 - 使用必要的软件包创建一个 Python 虚拟环境。
- 开发一个 Jupyter notebook(
data_visualization_analysis.ipynb),它:- 读取 JSON 文件。
- 在专用单元格中创建相关图表和表格。
- 为每个可视化包含解释性注释。
- 提供数据驱动的建议。
- 创建一个包含设置说明和项目文档的
README.md文件。 - 分析包括:
- 基本信息表。
- 版本对比。
- 使用 GitHub stars 的热度分析。
- 使用 GitHub forks 的社区参与度分析。
- 许可证分布。
- 总结与建议。
生成的项目已可直接使用。只需按照 README.md 文件中的说明激活虚拟环境、启动 Jupyter Notebook 并运行分析即可。
注意:Mistral AI 为每个任务选择了完美的 Bright Data 工具。这些知识来自已配置的 技能,它们帮助 AI 编码代理做出明智的决策。
首先,检查存储在 data_visualization_libraries.json 中的抓取数据: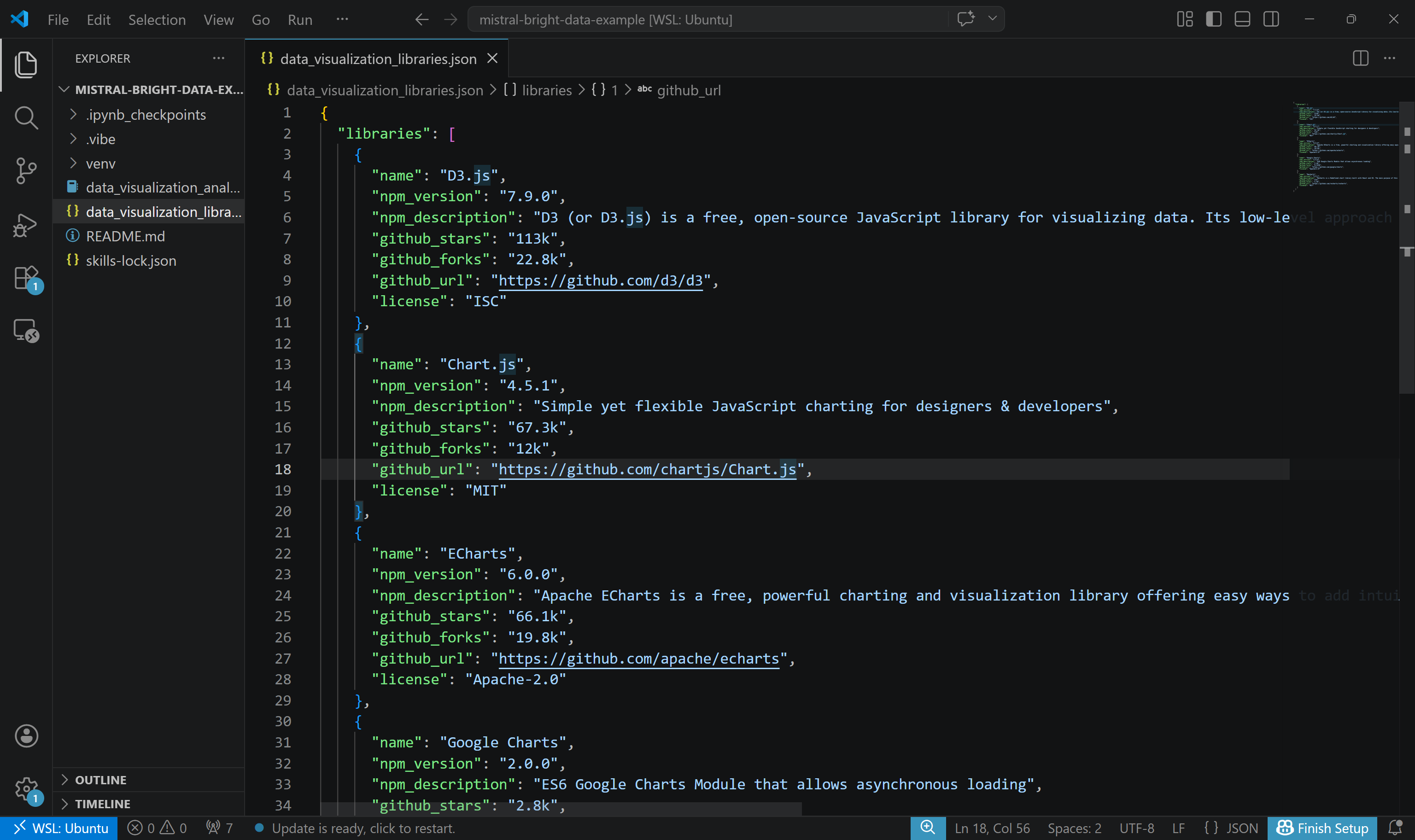
注意这里包含了按预期从 NPM 和 GitHub 抓取的真实、上下文相关且最新的数据。
接下来,打开 Jupyter Notebook 以探索所有可视化和洞察。看看分析有多详细,它结合了图表和解释性文本: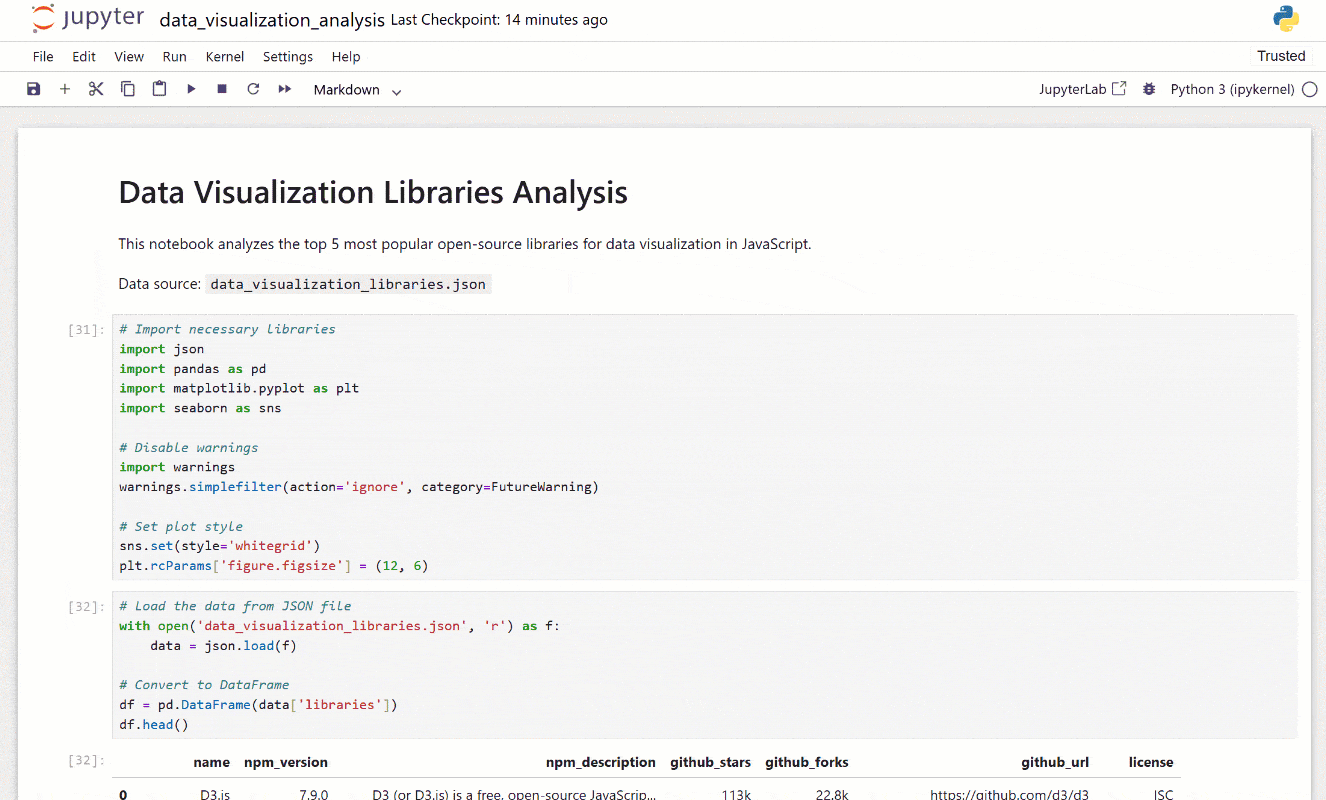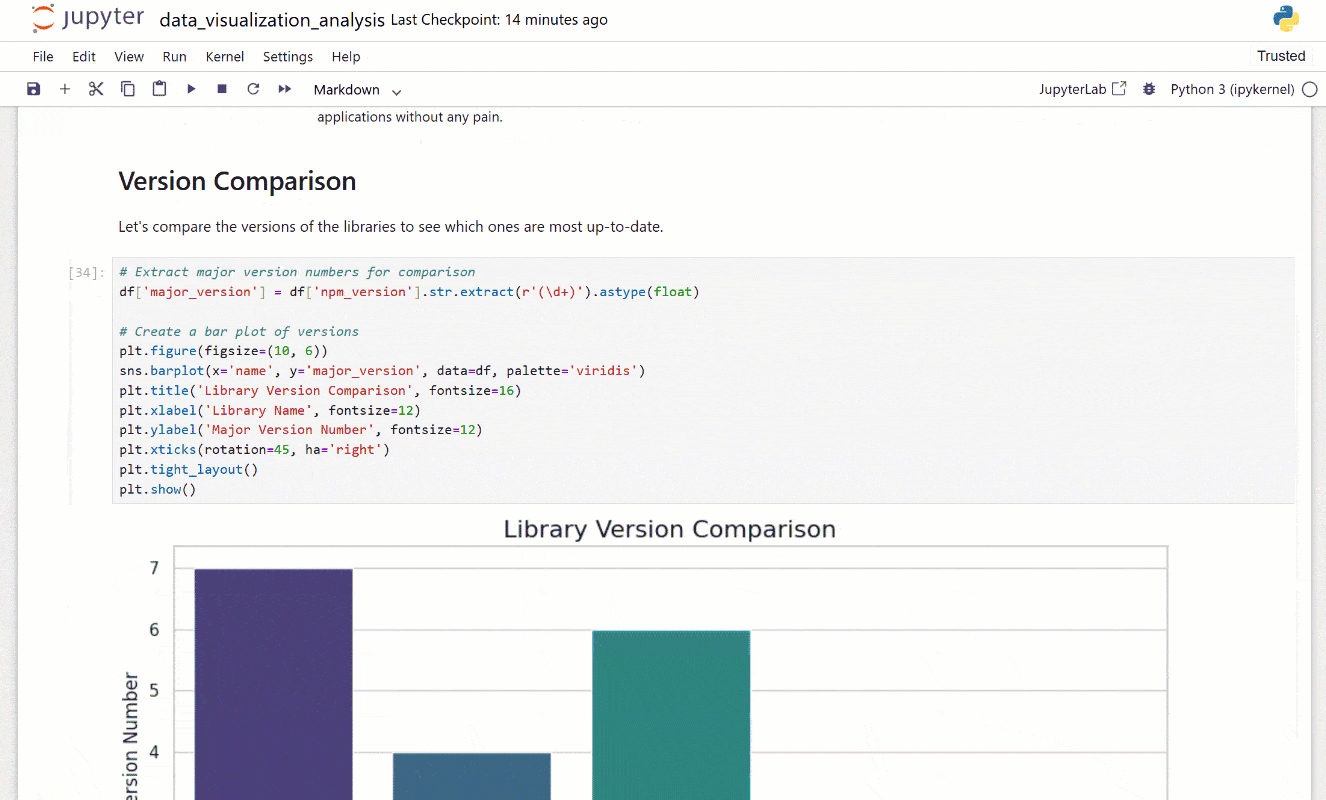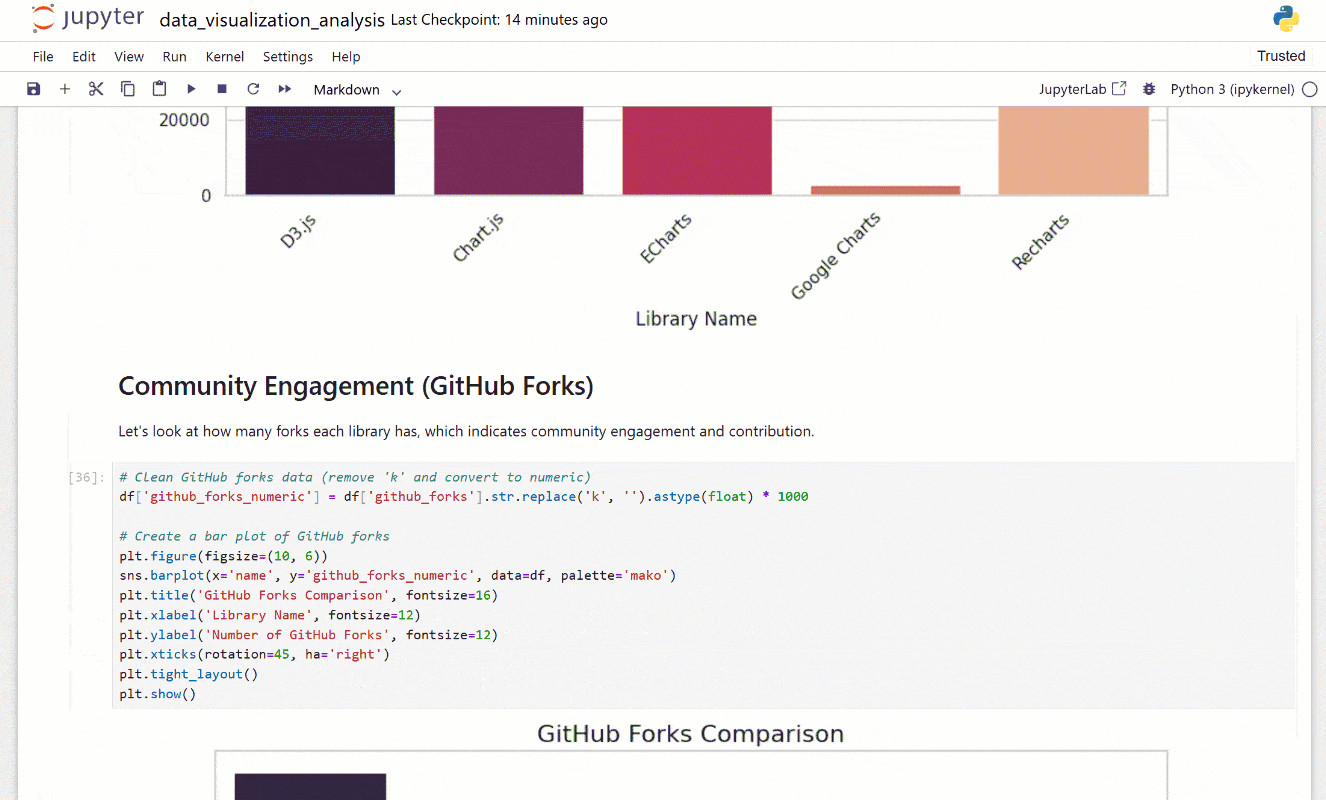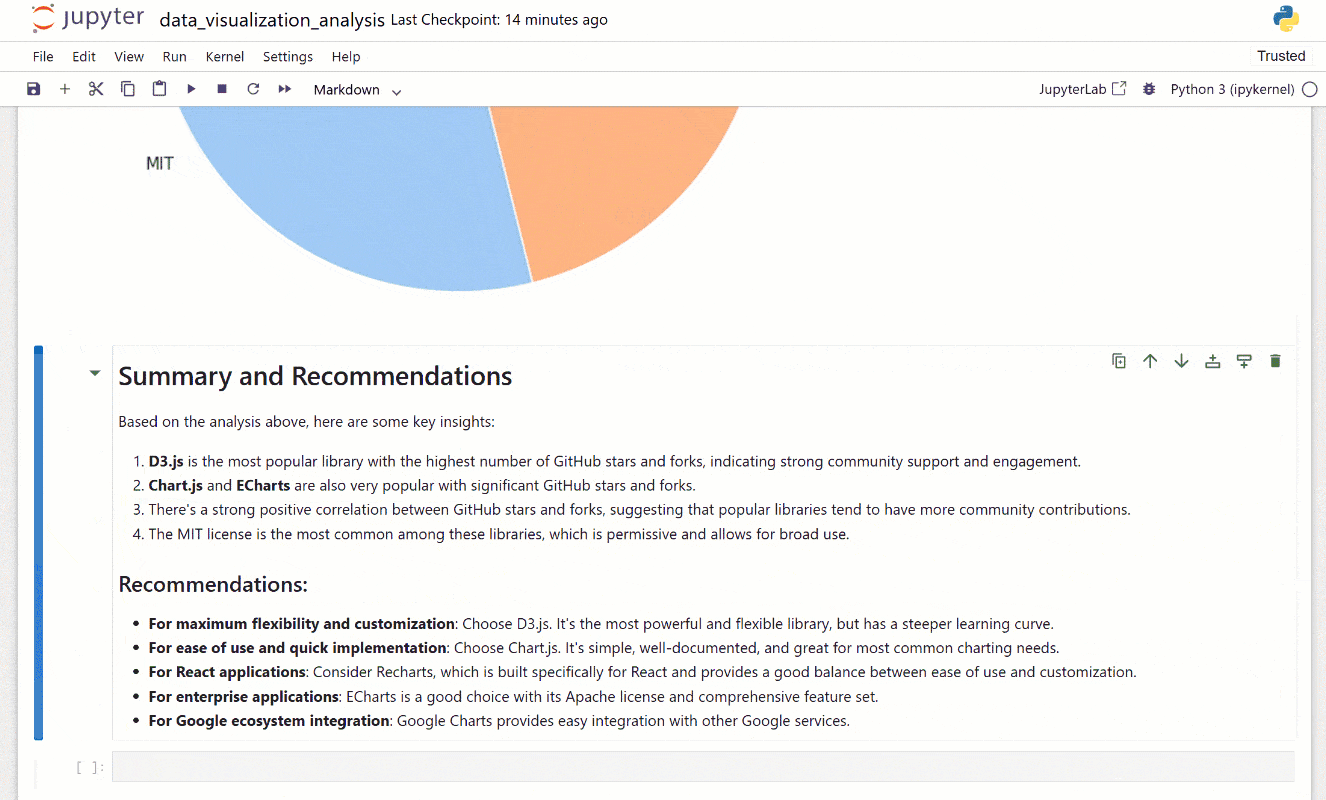
Et voilà! 这清楚地展示了将 Bright Data 工具集成到 Mistral Vibe 中的好处。
结论
在这篇博文中,你了解了什么是 Mistral Vibe 以及它带来了什么。特别是,你看到了为什么以及如何通过 Web MCP 和 Agent 技能 将其连接到 Bright Data 来扩展它。
这种集成为 Vibe AI 编码代理配备了强大的新能力,使其编码能力更加有效。这些能力包括网页搜索、结构化数据提取、实时 Web 数据检索以及自动化 Web 交互。
如需更高级的工作流,请探索 Bright Data 生态系统中面向 AI 的全套服务。
立即注册一个免费的 Bright Data 账户,并开始试用我们的 Web 数据工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。





![注意“[SUCCESS]”消息](https://paper-attachments.dropboxusercontent.com/s_7D5D83644E586B9C90375A2DE6CC3C493594107D072BCFAAA418FBE13A858CF8_1775641358514_image.png){kind=link}