在本文中,你将看到:
- CloakBrowser 是什么、它提供什么以及它如何工作。
- 什么是 Bright Data 浏览器 API、它提供哪些功能,以及它所带来的基础设施优势。
- 这两种解决方案如何实现隐身浏览和指纹管理。
- 这两种工具所依赖的不同基础设施模型。
- CloakBrowser 和 Browser API 都可使用的受支持集成与工具。
- 最终的 CloakBrowser vs Bright Data Browser API 对比表,一目了然地比较它们。
让我们开始吧!
CloakBrowser 概述
在深入 CloakBrowser vs Bright Data Browser API 对比之前,先了解 CloakBrowser 能带来什么。
CloakBrowser 是什么?

CloakBrowser 是一个基于自定义 Chromium 二进制文件构建的开源隐身浏览器。它作为浏览器自动化和网页抓取解决方案运行。
与依赖 JavaScript 注入、浏览器补丁或配置调整的传统隐身插件不同,CloakBrowser 直接在 Chromium C++ 源码层面修改浏览器指纹。该方法旨在产生更一致、更真实的浏览器行为。
该工具可作为 Playwright 和 Puppeteer 的即插即用替代方案。它包含内置指纹管理、类人交互模拟、代理支持、持久化浏览器配置文件,以及与 AI 代理和自动化框架 的集成。
在最近几周,该项目获得了显著关注。它从几千个 GitHub stars 增长到 截至撰写时超过 21.2k stars。
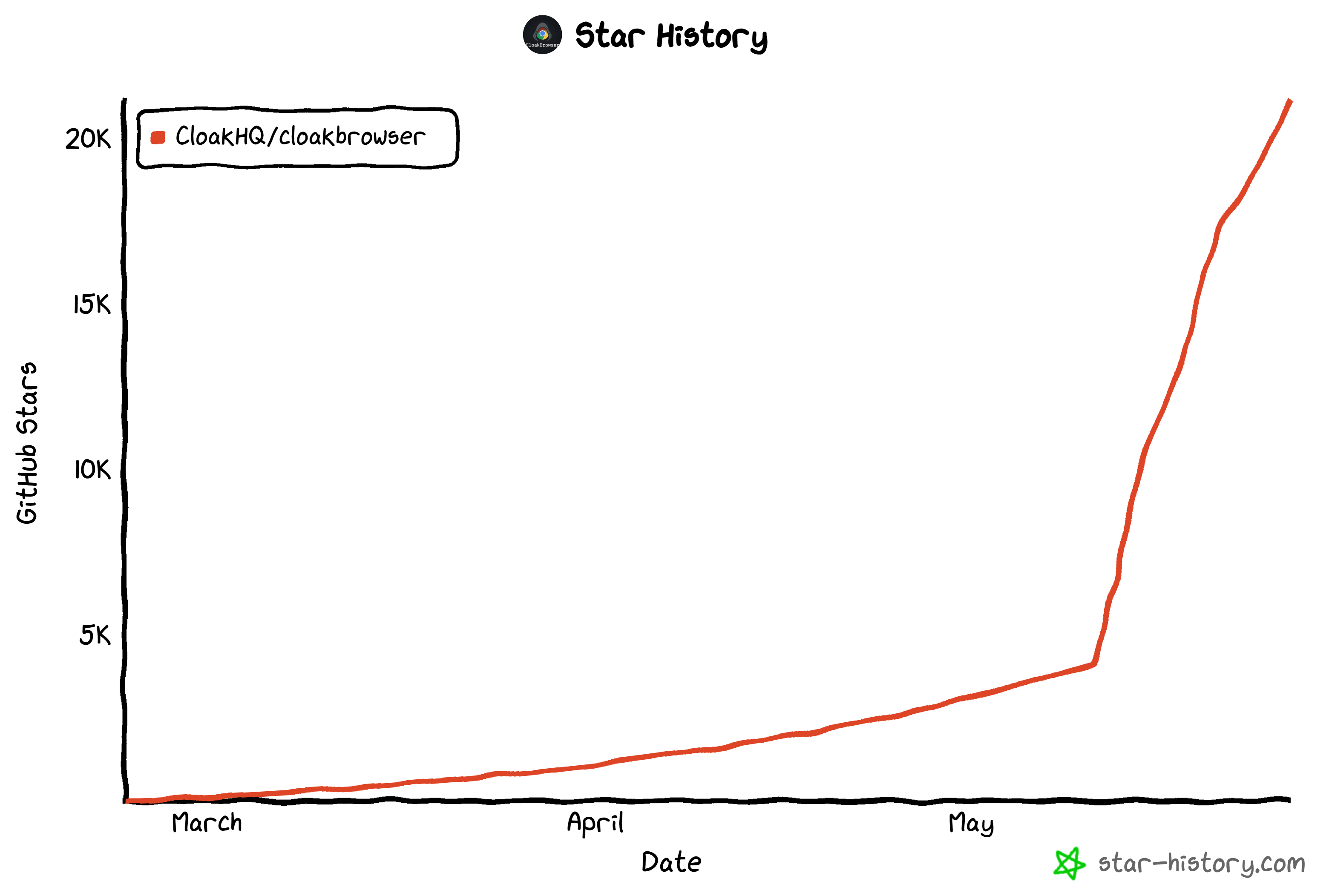
它甚至出现在 GitHub 全平台的每周趋势仓库中:
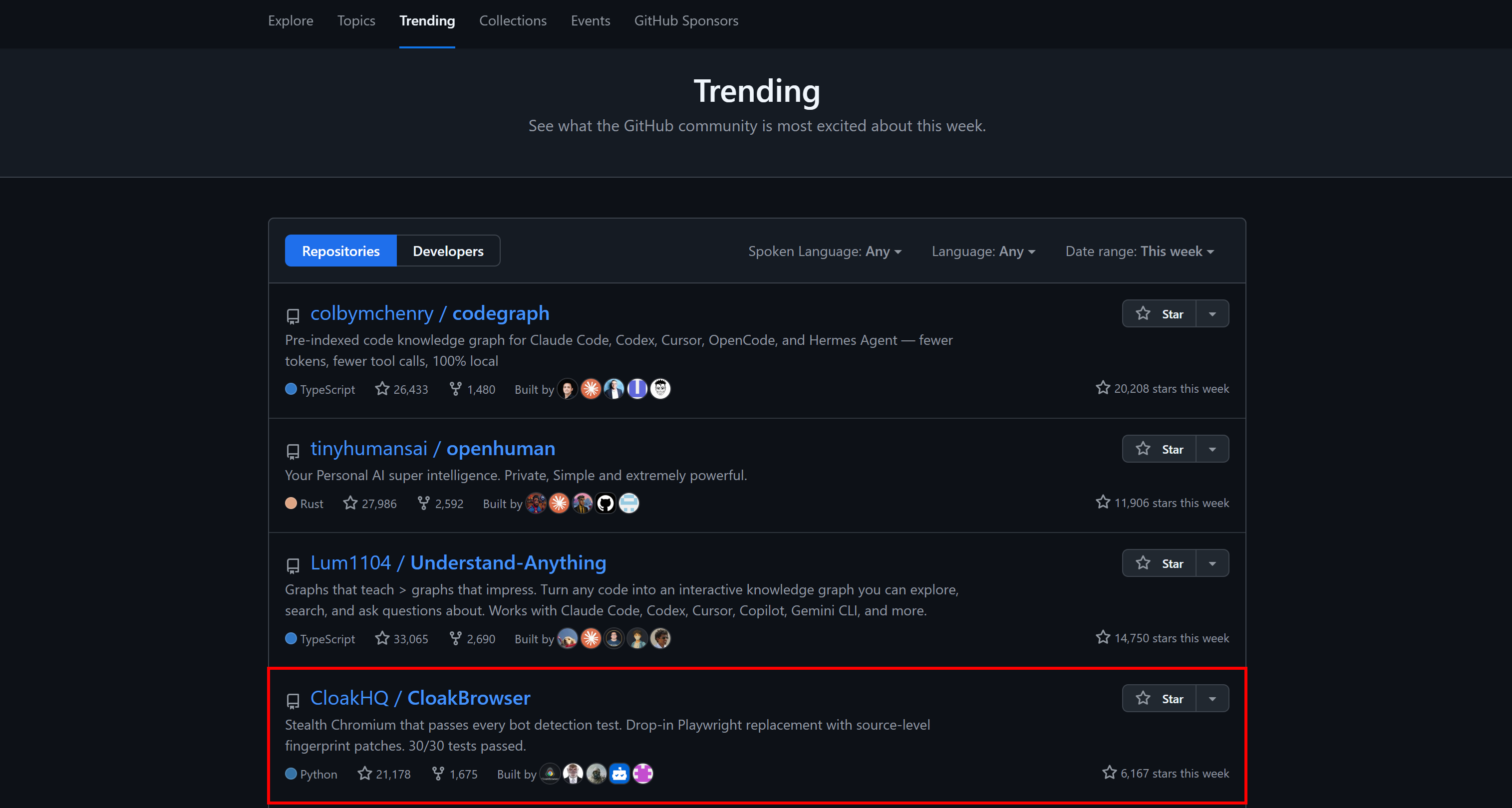
主要功能
以下是 CloakBrowser 项目提供的主要功能:
- 源码级 Chromium 指纹补丁:直接在浏览器引擎中对 GPU、canvas、WebGL、音频、字体和时间信号应用 58+ 项 C++ 修改。
- 自动二进制管理:自动为你下载自定义 Chromium 构建版本,无需任何手动设置。
- 即插即用的 Playwright 和 Puppeteer 替代方案:保持相同的 API,因此现有自动化代码只需改动几行代码即可运行。
- 类人交互引擎:通过单个
humanize=True标志模拟真实的鼠标移动、键盘节奏、滚动行为和点击动态。 - 高级代理支持:支持带认证的 HTTP 和 SOCKS5 代理,并可选基于 GeoIP 的时区与语言环境对齐。
- 持久化浏览器配置文件:可在会话之间保留 cookies、
localStorage和缓存,以支持长期存续的已认证工作流。 - 指纹控制系统:使用确定性或随机种子,在会话之间生成一致或轮换的浏览器身份。
- 高反爬成功率:在基准测试中通过 reCAPTCHA v3、Cloudflare Turnstile、FingerprintJS 和 BrowserScan 等主要系统。
CloakBrowser 如何工作
CloakBrowser 作为一个轻量的自动化层运行在自定义 Chromium 浏览器之上。其工作方式如下:
- 你使用
pip或npm安装 CloakBrowser。 - 首次运行时,它会自动为你的操作系统下载预构建的 Chromium 二进制文件。
- 此后的每个会话都会在该自定义浏览器中启动。
- 你现有的代码保持不变,并继续使用标准的 Playwright 或 Puppeteer API。
注意:CloakBrowser 也可以通过 Docker 进行设置,并通过 Playwright、Puppeteer、Selenium 或任何兼容 CDP 的框架等标准工具进行连接。
该 Chromium 二进制文件包含数十项底层 C++ 修改,用于调整或掩盖浏览器指纹信号。它还通过改变内部浏览器信号和 CDP 层信号来降低自动化检测。这些更改会直接编译进下载的 Chromium 二进制文件中。
该设计的一个关键影响是:只有封装层是开源的,而浏览器二进制文件以预编译产物形式分发。这限制了对指纹逻辑的直接检查或逆向工程(由 WAFs 和其他反机器人解决方案 背后的公司进行),因为关键修改嵌入在已编译代码中。
快速开始
先安装 CloakBrowser。在 Python 中运行:
pip install cloakbrowser或者在 Node.js 项目中,使用以下方式安装:
npm install cloakbrowser安装完成后,你可以使用标准的 Playwright 或 Puppeteer API。例如,下面是一个 Playwright 风格的 Python 示例:
# pip install cloakbrowser
from cloakbrowser import launch
browser = launch()
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Expected result: "Example Domain"
browser.close()或者等效的 JavaScript 示例:
// npm install cloakbrowser
import { launch } from "cloakbrowser";
const browser = await launch();
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Expected result: "Example Domain"
await browser.close();请注意,自动化逻辑与常规 Playwright 或 Puppeteer 保持完全一致。CloakBrowser 只改变浏览器的启动方式,而不改变你编写自动化代码的方式。
唯一的区别是 launch() 函数,它会初始化一个 CloakBrowser 会话。默认情况下,它会以默认隐身配置启动一个无头浏览器会话。若需更多控制,请参阅 launch() 函数支持的参数。
当你首次运行脚本时,CloakBrowser 会:
- 检测你的操作系统。
- 为你的平台下载预构建的基于 Chromium 的二进制文件。
- 将其缓存在本地以供将来使用。
从那时起,每次 launch() 调用都会通过 Playwright 或 Puppeteer 启动自定义 Chromium 二进制文件。
定价
CloakBrowser 没有订阅费用、使用限制或付费层级。因此,你可以自由安装并使用它。然而,真实世界的成本来自周边基础设施。
为了可扩展使用,你必须依赖与 可信的第三方代理提供商 的集成。代理对于分布式自动化工作负载至关重要,并且会根据流量规模和地理覆盖范围成为主要运营成本。
此外,在生产环境中,CloakBrowser 通常使用 Docker 部署在多台服务器上。这支持水平扩展,但也会引入额外开销,包括容器编排、实例管理、监控以及持续维护。
因此,即使 CloakBrowser 本身是免费的,随着规模扩大,运营复杂性和基础设施成本也会增加。
Bright Data 的 Browser API 简介
继续本次 CloakBrowser vs Bright Data Browser API 对比,深入了解 Browser API。
Browser API 是什么?
Bright Data 的浏览器 API 是一种云端托管的浏览器自动化方案,针对大规模、生产级网页交互和数据采集进行了优化。
它无需运行和维护本地浏览器基础设施,而是允许你将现有的 Playwright、Puppeteer 或 Selenium 脚本连接到完全托管的隐身浏览器。这些浏览器会在云端自动扩展并维护。
从核心来看,它面向可靠性、解锁能力和规模至关重要的场景。常见用例包括动态网页抓取、自动化 QA/测试、线索生成等。
它由 Bright Data 庞大的 4 亿+ IP 代理网络 提供支持,实现强大的地理分布、IP 轮换,以及无限并发与可扩展性。该解决方案开箱即用地处理验证码破解、指纹识别、会话管理和 JavaScript 渲染。凭借这些功能,它在对抗高度防护的网站时实现了很高的成功率。
Browser API 支持所有兼容 CDP 的工具,以及通过 Web MCP 的现代 AI 代理工作流。这意味着它也适用于需要实时浏览、点击并提取信息的自主代理。
主要功能
以下是 Bright Data Browser API 的关键功能:
- 云端托管的浏览器基础设施:完全托管的浏览器在云端运行,消除本地设置、代理管理和基础设施维护。
- Playwright、Puppeteer、Selenium 兼容性:与大多数 浏览器自动化框架 直接集成,允许以最小改动复用现有脚本,实现快速迁移。
- 内置验证码破解:自动检测并解决 CAPTCHA 和挑战-响应系统,减少抓取中断并免除对外部服务的需求。
- 大规模代理网络访问:利用 4 亿+ 地址的住宅 IP 池,实现地理分布式请求,减少封锁与检测。
- 浏览器指纹模拟:模拟真实用户的浏览器特征,以降低检测风险并提升对抗高级反机器人系统的可靠性。
- 自动扩展基础设施:根据需求动态配置浏览器会话,在无需手动扩展的情况下支持高并发工作负载。
- Chrome DevTools 调试:使用 DevTools 提供会话检查,允许你在抓取执行期间监控日志、网络请求和浏览器行为。
- 地理位置定向:支持精确到国家、城市或 ASN 级别的定向,以访问本地化内容、测试区域体验,并准确抓取地理限制数据。
- 自动恢复:恢复会话以保持连续性,减少停机时间并提升在不稳定或被封锁环境中的鲁棒性。
- AI 代理兼容性(通过 Web MCP):支持能够导航、点击、滚动并提取网页数据的自主浏览器代理,实现高级 AI 驱动的自动化工作流。
- 数据完整性验证:通过内置验证机制确保提取的数据一致且可靠,从而提升下游分析与生产流水线的质量。
如需更多信息,探索官方文档。
Browser API 如何工作
Browser API 通过在完全托管的云端浏览器中运行你的浏览器自动化脚本来工作。你使用单个 CDP 端点进行连接,你的代码会在真实浏览器环境中远程执行。基本上,你与浏览器交互就像它在本地一样,但执行、扩展和解锁完全由平台管理并在云端发生。
在幕后,该平台处理所有基础设施复杂性。它会自动管理代理轮换、浏览器指纹、会话处理、验证码破解等。每个会话都运行在可扩展的云环境中,可根据需求动态分配资源。这意味着无需手动设置即可实现高并发。
快速开始
首先,你需要在 你的 Bright Data 账户中配置一个 Browser API 区域。如果你尚未这样做,创建一个 Bright Data 账户。否则,直接登录。
在 Bright Data 控制面板中,选择 “Web Access > Create an API” 选项:
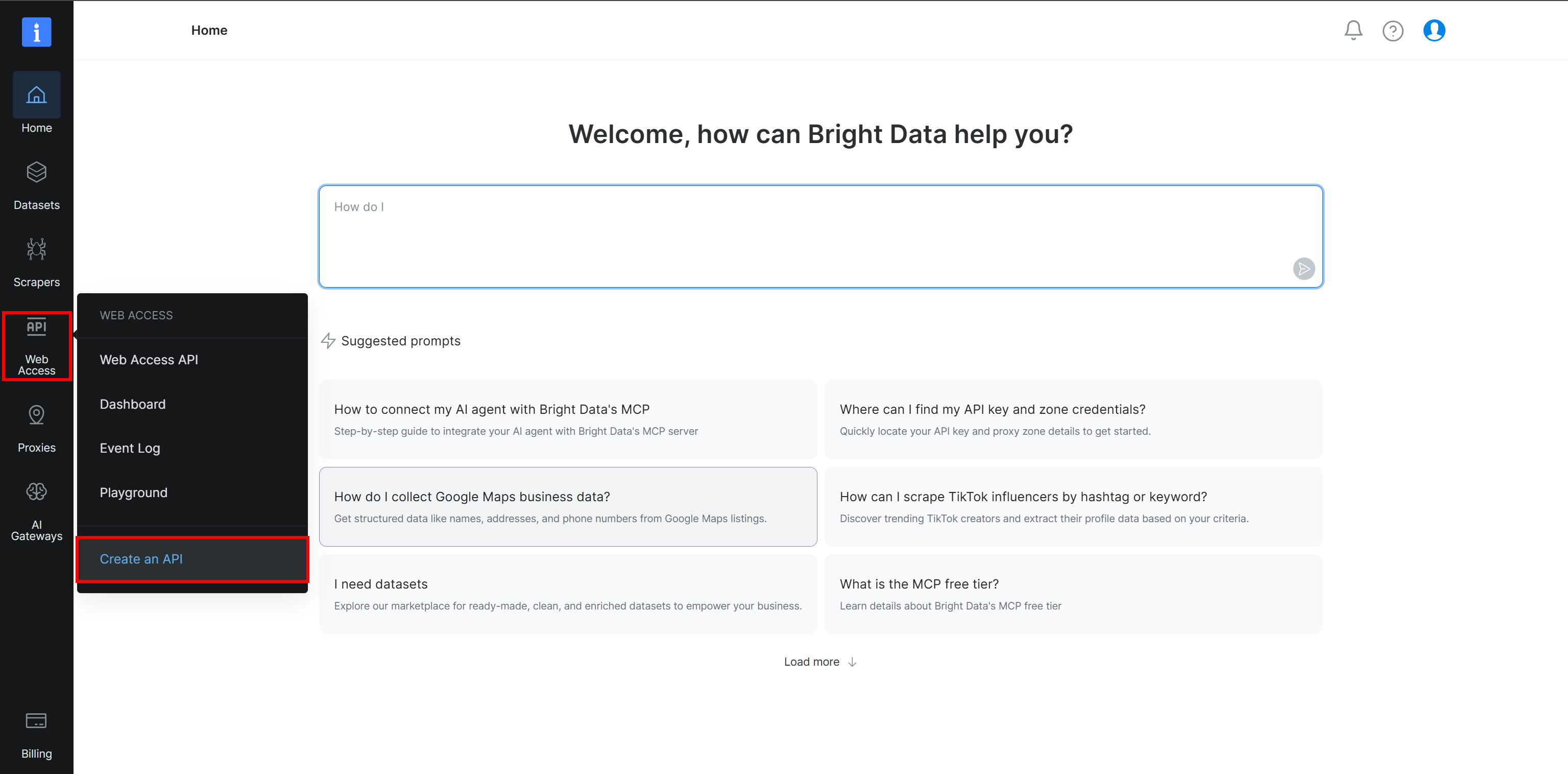
在 “Web Access API > Add API” 页面,选择 “Browser API” 类型:

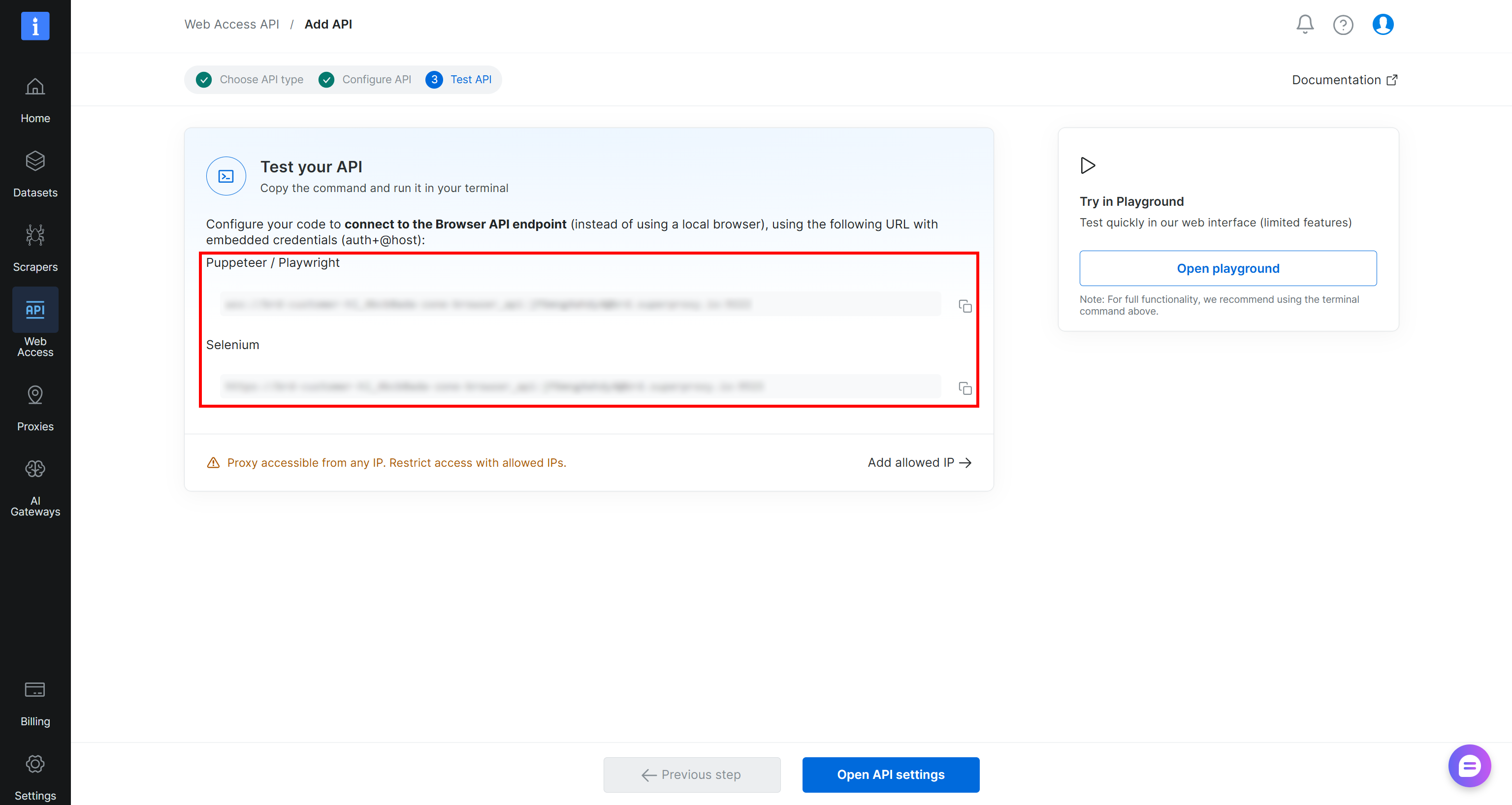
按照向导操作,为你的 Browser API 区域命名(例如 browser_api),并按需进行配置。完成设置流程后,你将获得 Puppeteer、Playwright 和 Selenium 的连接 URL:
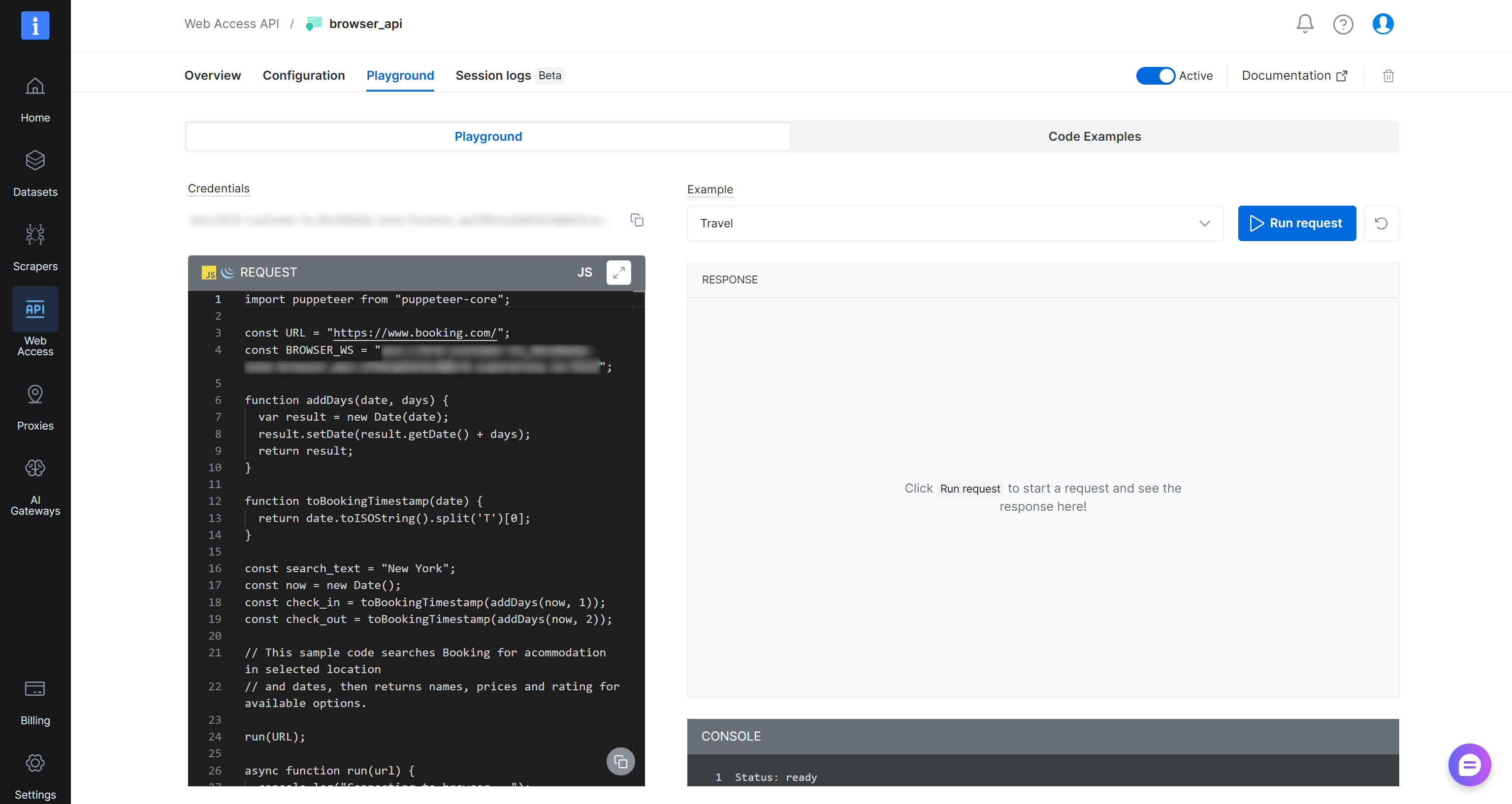
然后,点击 “Open API settings” 按钮以访问 Browser API Playground。在这里,你可以获取用于与常见浏览器自动化框架和编程语言集成的即用型代码片段:
使用远程连接 URL,在 Python 中通过 Playwright 以 CDP 方式连接,如下所示:
# pip install playwright
from playwright.sync_api import sync_playwright
# Replace with your Browser API connection URL
BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222"
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(BROWSER_API_CDP)
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Expected result: "Example Domain"
browser.close()或者等效的 JavaScript 示例:
// npm install playwright
const { chromium } = require("playwright");
# Replace with your Browser API connection URL
const BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222";
(async () => {
const browser = await chromium.connectOverCDP(BROWSER_API_CDP);
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Expected result: "Example Domain"
await browser.close();
})();自动化逻辑与标准 Playwright 或 Puppeteer 保持一致。唯一变化是你连接浏览器的方式。通过使用 connect_over_cdp()/connectOverCDP(),你将执行重定向到完全托管的 Browser API 云实例(而不是依赖本地浏览器)。
定价
Browser API 采用按流量付费模式,你只需为通过云浏览器基础设施传输的数据 GB 计费。具体而言,Browser API 定价 遵循以下方案:
| Plan | Price |
|---|---|
| Pay as you go (no commitment, usage-based billing) | $8/GB |
| 71 GB included | $499/mo ($7/GB) |
| 166 GB included | $999/mo ($6/GB) |
| 399 GB included | $1,999/mo ($5/GB) |
不会对浏览器实例、执行时间或并发收取费用。所有国家/地区按相同费率计费,使得跨地域定价可预测。唯一例外是 premium domains,由于额外的解锁复杂性,会产生更高的每 GB 成本。
注意:你也可以通过免费试用 免费测试 Browser API 以及任何其他 Bright Data 产品。
由于定价直接取决于流量,优化带宽对成本效率和性能很重要。阅读 关于带宽优化的官方指南。
隐身浏览的方法差异
CloakBrowser 和 Browser API 都旨在降低机器人检测。然而,它们在隐身浏览与指纹管理方面采取了两种根本不同的方法。
CloakBrowser 通过在本地运行修改过的 Chromium 二进制文件来实现反机器人绕过。它在启动时生成一致的浏览器指纹,伪装 GPU、屏幕尺寸、字体、canvas、WebGL、音频和硬件规格等可检测信号。
你还可以通过 确定性指纹种子 控制身份持久性,并通过启动标志对特定属性进行微调。这使得 CloakBrowser 特别适合在你需要精确指纹控制以及跨会话可复现的浏览器身份时使用。
相反,Browser API 通过完全托管的云端浏览器提供隐身能力。它不暴露底层指纹标志,而是在幕后处理浏览器指纹。同时,它提供配置以及 自定义 CDP 操作 来控制高级行为。这些功能让你能够模拟特定设备、更改地理位置、屏蔽广告、配置验证码破解等。
基础设施差距
CloakBrowser 为你提供一个隐身的本地 Chromium 二进制文件。然而,围绕它的一切仍由你负责。这意味着如果你想大规模运行自动化,你需要配置机器、管理浏览器并发、配置并轮换代理、监控故障等。
当然,你会获得提供 CloakBrowser 环境和用于通过 CDP 连接的浏览器服务器的 Docker 镜像。但从一个 Docker 镜像到真正可用的可扩展浏览器基础设施,是另一项挑战。这需要工程技能、基础设施专业知识,以及并非所有团队都具备的预算。
Bright Data 的 Browser API 采取了非常不同的方法。它不是给你一个需要管理的浏览器,而是在云端提供完全托管的浏览器基础设施。代理轮换、浏览器编排、扩展、并发和监控都由其管理。你只需将浏览器自动化脚本或 AI 代理连接到远程端点,Bright Data 就会为你处理所有运营复杂性。
特别是,Browser API 由 Bright Data 具备 SLA 支持的企业级基础设施提供保障。它提供 99.99% 正常运行时间、无限并发、99.95% 成功率、无限可扩展性,并符合 GDPR、CCPA 以及其他隐私与安全法规。
这种差异是整个 CloakBrowser vs Browser API 对比的关键点。CloakBrowser 无疑是一个很棒的工具。然而,Browser API 是两者中唯一一个真正可以被视为完整浏览器自动化基础设施的方案。
这也是 Browser API 相比 CloakBrowser 的最大优势。通过从第一天起降低运营负担,它让你能够专注于自动化逻辑——这才是最重要的。
支持的集成
CloakBrowser 原生支持 Playwright 和 Puppeteer 脚本。然而,它需要一个额外依赖(cloakbrowser),同时仍依赖标准的 Playwright 系统依赖。
除了原生 API 之外,CloakBrowser 通过基于 Docker 的服务器设置暴露一个兼容 CDP 的浏览器。这样,它可以与任何符合 CDP 的工具集成。它还原生支持一些 AI 代理框架,如 CrawAI、Browser Use 和 LangChain。
Browser API 支持 Playwright、Puppeteer 和 Selenium,但无需任何额外依赖。此外,它与所有基于 CDP 的工具完全兼容,包括 浏览器使用、Stagehand、Agent 浏览器 以及类似的基于 AI 的自动化框架。
此外,Bright Data 的 Browser API 通过 Web MCP tools 暴露。这些包括:
| Tool | Description |
|---|---|
scraping_browser_navigate |
打开或复用会话并导航到 URL,同时重置网络跟踪 |
scraping_browser_go_back |
返回上一页并返回更新后的 URL 和标题 |
scraping_browser_go_forward |
前进并返回更新后的 URL 和标题 |
scraping_browser_snapshot |
捕获带交互元素引用的 ARIA 快照 |
scraping_browser_click_ref |
使用其 ARIA 引用点击元素 |
scraping_browser_screenshot |
捕获页面或全页截图 |
scraping_browser_wait_for_ref |
通过 ARIA 引用等待元素可见 |
scraping_browser_get_text |
从页面 body 提取可见文本 |
scraping_browser_get_html |
获取页面 HTML 内容 |
scraping_browser_scroll |
滚动到页面底部 |
scraping_browser_scroll_to_ref |
滚动到特定被引用的元素 |
MCP 支持使 Browser API 成为一个代理式浏览器,将兼容性扩展到广泛的 AI 代理框架生态系统。支持的解决方案包括 LangChain、Agno、OpenClaw、LlamaIndex、CrewAI、Dify、Mastra、Claude Code、Codex、Claude Desktop,以及 70+ 其他。
Bright Data Browser API vs CloakBrowser:并排对比
在下面最终的 CloakBrowser vs Bright Data Browser API 表格中比较这两种解决方案:
| Aspect | CloakBrowser | Bright Data Browser API |
|---|---|---|
| Core concept | 本地隐身 Chromium 二进制文件 | 完全托管的云端浏览器基础设施 |
| Nature | 开源封装层 + 专有补丁浏览器二进制文件 | 专有 |
| Dependencies | 需要 cloakbrowser + 系统依赖 |
无额外依赖 |
| CDP support | ✔️(通过 Docker 服务器) | ✔️(原生云端 CDP 端点) |
| Stealth approach | 源码级 Chromium 指纹补丁 | 托管式指纹处理 |
| Fingerprint control | 通过种子和启动标志实现高控制 | 通过 CDP 操作用于设备模拟进行控制 |
| Proxy management | 需要外部代理提供商 | 内置 4 亿+ IP 代理网络 |
| CAPTCHA handling | 非原生 | 内置验证码破解 |
| Framework support | Playwright、Puppeteer、兼容 CDP 的工具 | Playwright、Puppeteer、Selenium、兼容 CDP 的工具 |
| AI agent integration | 支持部分 AI 框架(Browser Use、LangChain、CrawAI) | 通过 Web MCP 覆盖广泛生态(LangChain、LlamaIndex、CrewAI、Agno、Claude,以及 70+ 其他) |
| Infrastructure responsibility | 用户自管 | 由 Bright Data 完全托管 |
| Scaling | 需要手动水平扩展 | 自动弹性扩展,且无限并发 |
| Uptime guarantees | 取决于用户基础设施 | 99.99% SLA 支持的正常运行时间 |
| Cost model | 软件免费,基础设施另计成本 | 按每 GB 流量计费的定价 |
最终结论
CloakBrowser 和 Browser API 都是强大、具备隐身能力的浏览器自动化解决方案。CloakBrowser 凭借其开源属性,在你需要对浏览器指纹进行最大程度的本地控制以及完全自主管理的基础设施时最合适。它尤其适用于实验性或高度定制化的设置。
对于生产规模的抓取、可靠的自动化,或与 AI 代理的集成,Bright Data 的 Browser API 应该是首选。其完全托管的基础设施、内置解锁能力和弹性扩展消除了运营开销。这使其对希望专注于自动化逻辑而非基础设施管理的团队而言更为实用。
结论
在这篇 Bright Data Browser API vs CloakBrowser 对比文章中,你了解了两种工具是什么、它们提供哪些功能以及它们如何工作,以及它们的成本是多少。
CloakBrowser 是一个开源浏览器自动化解决方案,当你想要底层控制时非常出色。相反,Browser API 更适合更可靠的企业级或代理式浏览器自动化集成。
今天就探索 Browser API,并开始将其集成到你的自动化脚本中。
创建一个 Bright Data 账户并探索我们面向 AI 的网页数据自动化解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。