

在本文中,你将了解:
- Bright Data Browser API 与 Vercel Agent Browser 分别是什么,以及它们在架构上的差异
- 为什么基础设施在 Agent 浏览器的性能中扮演关键角色
- 两种方案分别如何处理反爬系统、CAPTCHA 与 IP 封锁
- 扩展性、定价与 AI 集成方面的关键差异
- 如何根据你的具体用例选择合适的工具
让我们开始吧!
Bright Data Browser API
Bright Data 的 Browser API(也称为 Agent Browser)是一种云端托管的浏览器解决方案,构建在企业级代理基础设施之上。它在 Bright Data 的托管服务器上运行真实的 GUI Chromium 浏览器,并通过标准的 Chrome DevTools Protocol(CDP)进行访问。
听起来信息量很大,但本质上,Bright Data 的 scraping browser 为你提供:
- 150M+ 可轮换 IP,覆盖 195 个国家/地区的 住宅、数据中心、移动与 ISP 网络。我在做价格对比测试时曾直接定位到城市级别的地理位置,全程无需手动配置任何代理。
- 自动 CAPTCHA 解决,支持 reCAPTCHA v2/v3、hCaptcha、Cloudflare Turnstile、DataDome、PerimeterX、AWS WAF 与 GeeTest。在三个月的测试里,我没有写过一行处理 CAPTCHA 的代码。
- 完整指纹管理,覆盖 canvas、WebGL、audio context、字体与设备枚举。我在原生 Playwright 上反复遇到的“检测到自动化”错误彻底消失了。
- TLS 指纹轮换,匹配真实浏览器签名。这解决了我之前甚至难以定位的一类封锁:请求在到达页面之前就被网络层拦截并失败。
配置只需要五分钟。我把本地浏览器连接替换为 Bright Data 的 WebSocket endpoint,其它代码保持不变。我的 Puppeteer、Playwright 或 Selenium 脚本都无需修改即可运行。
对于 CAPTCHA,我可以选择让系统自动解决(默认做法),也可以在需要显式控制时监听检测事件。多数情况下,我甚至不会察觉到 CAPTCHA 的发生,因为它会在服务端解决完毕后脚本才继续执行。
Vercel Agent Browser

Vercel 构建 Agent Browser 是为了解决一个许多开发者都会遇到的特定问题:当 AI Agent 处理浏览器状态时,上下文窗口(context window)会被严重“膨胀”。
标准的 Playwright 会返回包含成千上万个节点的完整无障碍(accessibility)树。当我通过 Claude 运行 浏览器自动化 时,单次页面快照就消耗 15,000+ tokens。复杂工作流往往还没完成任务就先耗尽上下文。
Agent Browser 的 snapshot + refs 机制能把同一页面压缩到大约 1,400 tokens。你拿到的不再是包含 class、ID、ARIA label 与深层嵌套结构的冗长 HTML,而是:
- button "Sign In" [ref=e1]
- textbox "Email" [ref=e2]
- textbox "Password" [ref=e3]然后你让 agent 点击 @e1 或填写 @e2。这种 93% 的压缩意味着在触达 token 上限前,你可以进行 5 到 6 倍的浏览器交互。在一项独立基准测试中,使用 Playwright MCP 的 6 次浏览器测试消耗约 31,000 个字符(约 7,800 tokens),而 Agent Browser 仅消耗约 5,500 个字符(约 1,400 tokens),在同样的上下文预算下可进行约 5.7 倍更多的测试循环。
该工具是一个基于 Rust 的 CLI,对 Playwright 进行封装。它启动时间低于 50ms,支持 108+ 条命令,覆盖从基础导航到视频录制的各种能力,并可直接与 Claude Code、Cursor 等能够执行 CLI 的 AI Agent 集成。对我这种需要反复迭代生成代码的开发流程来说,上下文效率确实很关键。
主要权衡点:没有基础设施。Agent Browser 在本地运行并使用我的 IP,会暴露 navigator.webdriver,且不提供任何 CAPTCHA 解决或指纹管理。面对受保护的网站,我需要通过 -p 参数引入外部服务商,这会增加成本与复杂度,反而削弱其“轻量化”的优势。
测试 Bright Data 抓取能力
既然这是篇对比文章,我对两种工具都做了一些测试。
第一项测试:Cloudflare 保护的网站
我让两种工具都访问一个受 Cloudflare 保护的电商网站。任务很简单:提取商品价格。
Vercel Agent Browser:第一次能跑通,但在多次迭代中通常会失败。Agent Browser 无法可靠地对抗 Cloudflare 保护站点。成功率取决于保护等级:
| Cloudflare 设置 | Agent Browser 能工作吗? |
|---|---|
| 未使用 Cloudflare | 是 |
| 基础(低安全) | 可能 |
| Bot Fight Mode | 否 |
| Turnstile CAPTCHA | 否 |
Bright Data Browser API:3 秒加载完成。无 CAPTCHA、无挑战。住宅 IP 轮换与指纹管理自动处理了所有问题。这 3 秒的差异,体现了我在整个测试过程中反复遇到的核心基础设施差距。
| Cloudflare 设置 | Bright Data 能工作吗? |
|---|---|
| 未使用 Cloudflare | 是 |
| 基础(低安全) | 是 |
| Bot Fight Mode | 是 |
| Turnstile CAPTCHA | 是 |
这里的差异很直接:Bright Data 的代理基础设施能在网络层解决反爬挑战,而 Agent Browser 从设计之初就不是为了解决这些问题。
这也与独立基准测试结果一致:在 Proxyway 的测试中,Bright Data 在 7 个高难度域名上的平均成功率达到 98.44%,为所有受测服务商中最高。在 Indeed、Zillow、Capterra 与 Google 等特定目标上达到 100% 成功率;Amazon 为 98%,Google Shopping 为 97%。
第二项测试:在“配合型”网站上的 Token 效率
为了公平对比,我也测试了 Agent Browser 的优势场景:没有反爬保护的、配合型网站。在一个没有 bot protection 的标准文档站点上,Agent Browser 的 snapshot 系统将页面压缩到约为 Playwright 原始无障碍树输出的 10%。
具体来说,通过标准 Playwright 通常会消耗 7,000 到 8,000 tokens 的页面,在 Agent Browser 的 ref 系统下只需要几百 tokens。对于多步骤工作流(浏览文档、提取代码示例、验证输出),这意味着我可以在单个上下文窗口内完成整个会话,在触达限制之前进行 5 到 6 倍更多的交互。
使用 Bright Data 的 Browser API,我能拿到相同的数据,但原始页面输出会消耗更多 tokens。Bright Data 的设计目标并不是优化 LLM 上下文窗口,这一点在这里很明显。如果你的瓶颈是 token 预算而不是站点可访问性,那么 Agent Browser 是更好的工具。
第三项测试:AI 集成
两种工具都能与现代 AI 技术栈集成,但方式不同。
Bright Data 可直接连接 browser-use、LangChain 与 LlamaIndex。我的标准配置如下:
from browser_use import Agent
from browser_use.browser.browser import Browser, BrowserConfig
from langchain_openai import ChatOpenAI
browser = Browser(
config=BrowserConfig(
cdp_url="wss://brd-customer-XXX-zone-YYY:[email protected]:9222"
)
)
agent = Agent(
task="Extract all product prices from the homepage",
llm=ChatOpenAI(model="gpt-4o"),
browser=browser
)Vercel Agent Browser 通过 CLI 执行来工作。对于 Claude Code、Cursor 这类 AI 能直接运行 bash 命令的场景非常合适:
npx skills add vercel-labs/agent-browser随后 Claude 就可以运行 agent-browser navigate、agent-browser click @ref 等命令。对于长时间编码会话而言,这种上下文效率提升确实很有帮助。
最后一项测试:扩展性
使用 Browser API 时,扩展基本被抽象掉了。无论你是并发 5 个 session 做测试,还是并发 2,000 个 session 做生产爬取,连接串都保持一致。负载均衡、会话恢复与地理分布都由 Bright Data 端处理。
该基础设施支持无限并发浏览器会话,保持99.99% 网络可用性,并在全平台每天处理超过 20 亿次请求。平均响应时间约为住宅代理 0.7 秒、数据中心代理 0.24 秒。
Agent Browser 的扩展需要你自己负责。若要部署到 serverless,可使用轻量 Chromium 包(50MB vs 684MB 全量包)并配置 Vercel Fluid Compute 来减少冷启动。多个隔离 session 通过 --session 参数运行。
这对中等规模工作负载和开发使用很合适。但当并发超过几百个 session,你就会发现需要自己处理重试逻辑、会话隔离与地理分布——这些在 Bright Data 中是默认帮你处理的。对于高并发生产工作负载,这些运维开销会迅速累积。
定价
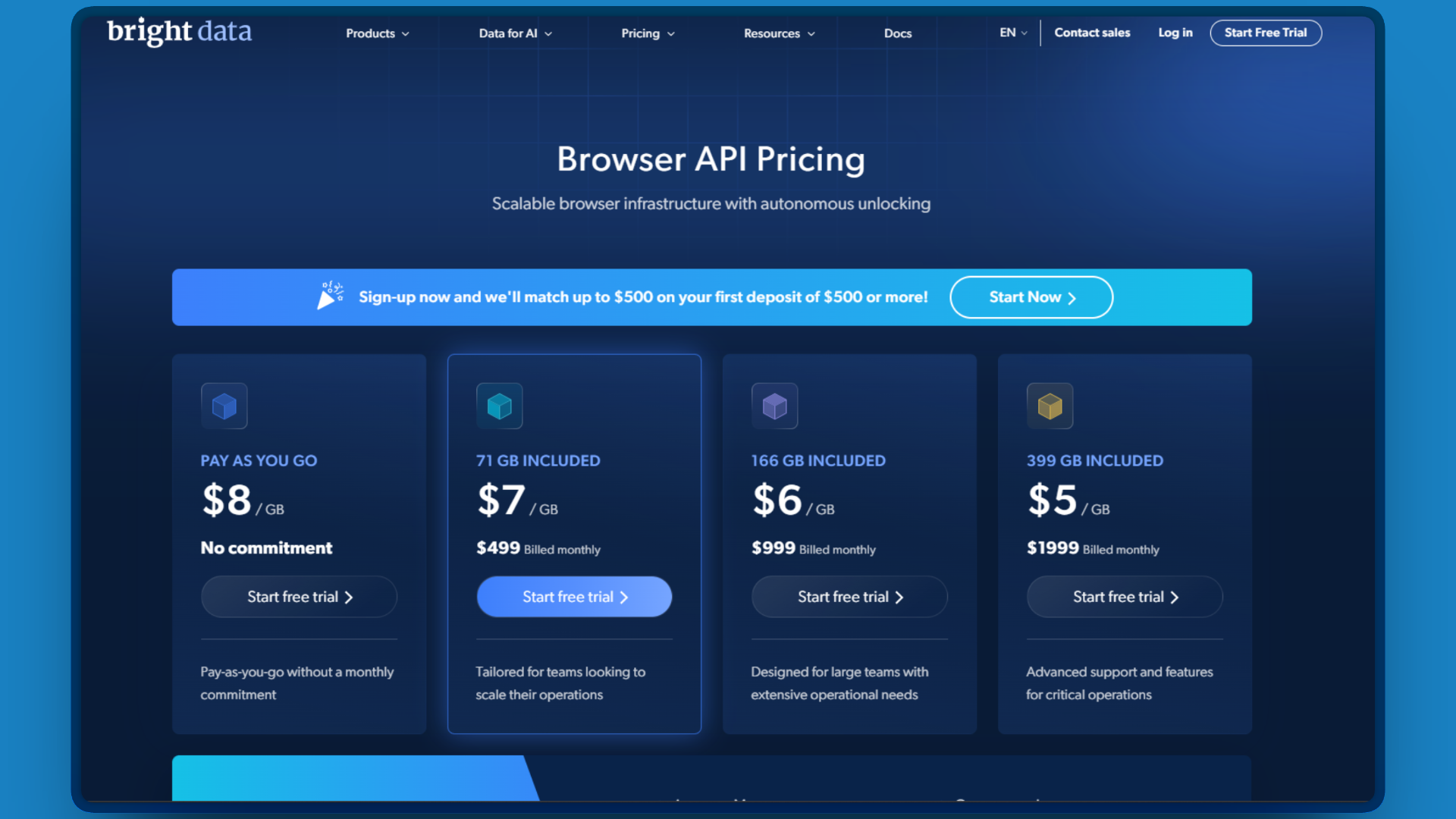
Browser API 按带宽计费:
| 方案 | 月费用 | 包含数据量 | 折算 $/GB |
|---|---|---|---|
| 按量付费 | $0 | 0 | $8.00 |
| Growth | $499 | 71 GB | ~$7.00 |
| Business | $999 | 158 GB | ~$6.00 |
| Scale | $1,999 | 400 GB | ~$5.00 |
Agent Browser 在 Apache 2.0 许可下免费,你无需为 CLI 本身付费。
但是,如果你的用例涉及受保护的网站,你很可能需要叠加外部服务。一个更贴近现实的组合示例可能是:
- Browserbase:提供带反爬能力的云浏览器:约 $150/月
- 2Captcha:解决 Browserbase 无法处理的 CAPTCHA:约 $47/月
- 住宅代理附加服务:用于仍会封锁你的站点:约 $120/月
合计约 $317/月,外加把三个独立服务串起来的集成成本,以及当故障发生时需要在三个控制台之间排查调试的成本。
对于无保护站点的开发工作流,Agent Browser 的确“零成本”。但若要在生产环境稳定访问受保护站点,Bright Data 的一体化基础设施最终可能比拼装同等能力的多家服务更便宜。
基础设施差距
在对两种工具进行大量测试后,我得出的结论是:基础设施决定了 Web 访问型 AI Agent 的成功率。
事实是,Vercel 构建了一个出色的上下文优化工具。在配合型站点的开发工作流中,你可以每天使用它。然而,它的关键限制在于:Agent Browser 没有内置的反爬能力。它在本地或 serverless 环境中以标准 Chromium 运行,这意味着:
- 没有代理轮换(你的 IP 会被封)
- 没有 CAPTCHA 解决(需要人工干预)
- 没有指纹管理(会被
navigator.webdriver检测到) - 没有 TLS 指纹优化(可能在网络层被拦截)
为了访问受保护的网站,你必须通过 -p 参数集成诸如 Browserbase、Browser Use 或 Kernel 等外部服务。这会带来复杂度、成本以及更多潜在故障点。
Bright Data 构建的是 Web 访问基础设施。对于需要访问真实网站的生产级 agent 来说,150M IP 网络、自动 CAPTCHA 解决与指纹管理不是“锦上添花”的功能,而是“必须满足”的要求。
“免费 vs 付费”的对比方式并没有抓住关键。真正的问题是:你的 agent 需要访问什么网站,以及你需要多高的成功率?对于需要规模化访问受保护站点的团队而言,拼装方案往往带来比节省更多的成本与复杂度。Bright Data 的一体化基础设施更贵,但交付也更多。
并排对比
以下是在关键维度上两种方案的对比:
| 维度 | Bright Data Browser API | Vercel Agent Browser |
|---|---|---|
| 主要定位 | 反爬绕过与 Web 访问 | AI Agent 的上下文效率 |
| 基础设施 | 托管云端,150M+ IP | 本地或 serverless(自备基础设施) |
| 代理网络 | 内置,覆盖 195 个国家/地区 | 无(需要外部服务商) |
| CAPTCHA 解决 | 自动,支持 8+ 种类型 | 无内置 |
| 指纹管理 | 完整浏览器签名控制 | 无(易被检测) |
| 上下文效率 | 标准(完整页面状态) | 通过 snapshot + refs 减少 93% |
| 定价 | $5-8/GB 带宽 | 免费(Apache 2.0 许可) |
| 扩展性 | 无限并发会话 | 受本地/serverless 资源限制 |
| AI 集成 | LangChain、LlamaIndex、MCP Server | CLI 方式(Claude Code、Cursor 等) |
结论
Bright Data Browser API 与 Vercel Agent Browser 面向的是同一问题的不同层面:为AI Agents提供可靠、高效的 Web 访问能力。
当你的 agent 运行在配合型网站上,并且 token 效率是主要瓶颈时,Vercel Agent Browser 是正确选择。它能减少 93% 的上下文开销、启动时间低于 50ms,是面向开发工作流、编码助手与自验证 agent 的实用工具。在这个用例下,它非常难被超越。
但开发与生产是两种不同环境。当你的 agent 需要以规模化方式访问真实、受保护的网站时,讨论重点会从 token 预算转向成功率。Bright Data Browser API 在高难度域名上提供 98%+ 成功率,支持 8+ 种类型的自动 CAPTCHA 解决,并在 195 个国家/地区提供 150M+ IP 支撑的无限并发会话。这种基础设施对生产级 agent 不是可选项,而是其运行的底座。
对于需要在开放 Web 上稳定运行的 AI Agent 团队来说,Bright Data Browser API 能开箱即用地提供这套底座能力。
延伸阅读



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





