


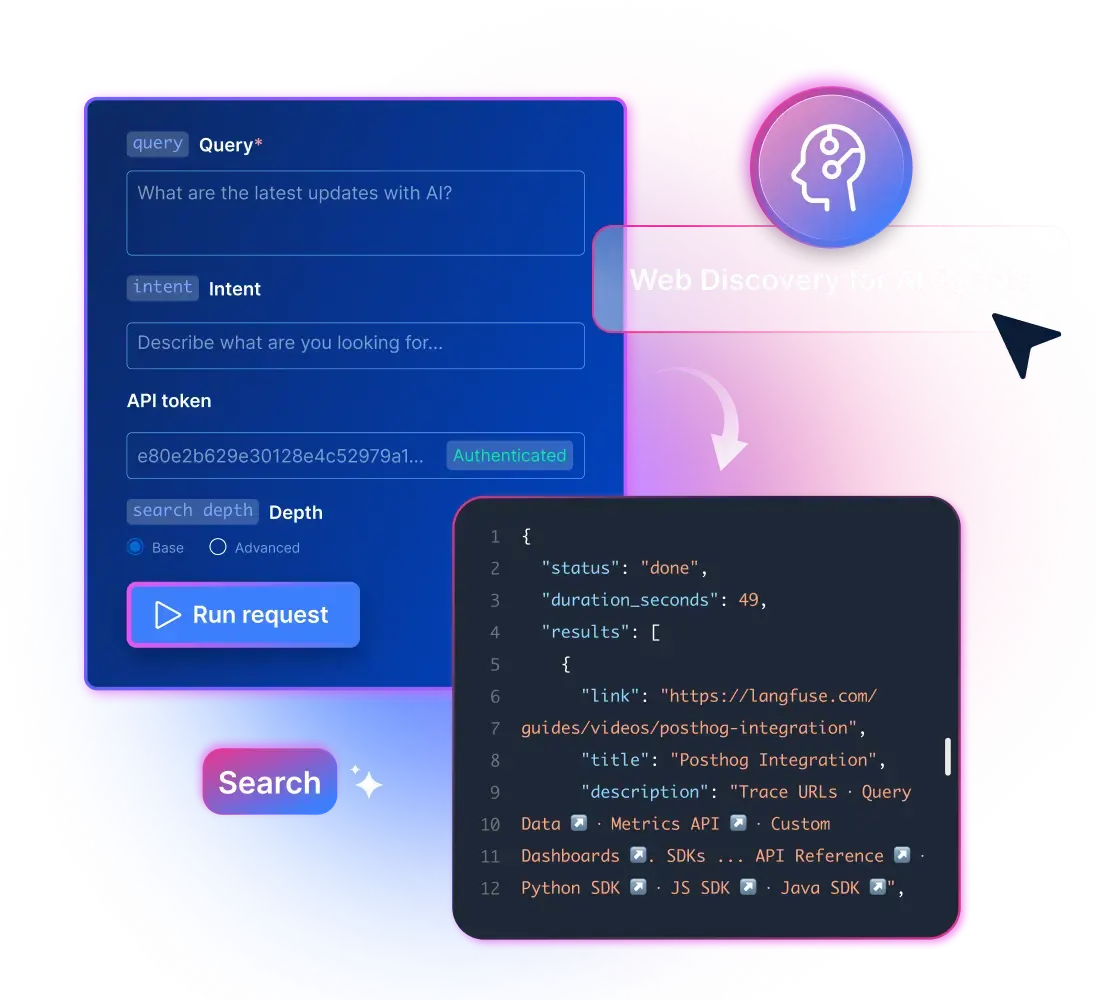
Discover API:面向 AI 代理的来源发现
在代理执行提取、抓取或补全之前,它需要先知道“去哪里找”。Discover API 会从公开网络返回一组实时、排序后的 URL,能够直接输入到你的代理提取、分析或监控流水线中。

- 始终从网络
实时检索 - 每次请求最多
返回 1000 条结果 - 按
意图排序 - 为并行的代理
工作负载而生
你的代理式网页数据流水线的第 1 步
返回你的代理下一步应优先访问的数据来源,排序依据是任务相关性,而非 SEO 排名
每次请求最多返回 1,000 个可直接用于流水线的 URL。无需分页逻辑,也无需额外去重开销。
每个 URL 都会实时验证。你的代理不会把失效的端点传递到流水线的下一阶段。
可选:提供清洗后的 Markdown 来源文本,用于核验与 RAG
为高吞吐、并行的代理工作负载打造
为什么代理会使用 Discover搜索引擎是为人类设计的。搜索 API 通常针对速度与头部链接优化。Discover 则面向“具备市场感知”的工作流而构建——这些工作流需要最新性、高召回以及可核验的上下文。
优先选择与任务匹配的数据来源,而不是 SEO 表现最好的来源
无需手动分页逻辑,即可检索最多 1000 条结果
降低来自过期缓存或索引路径的风险

可选:提供清洗后的 Markdown 来源文本,用于核验与 RAG

为高吞吐、并行的代理工作负载打造

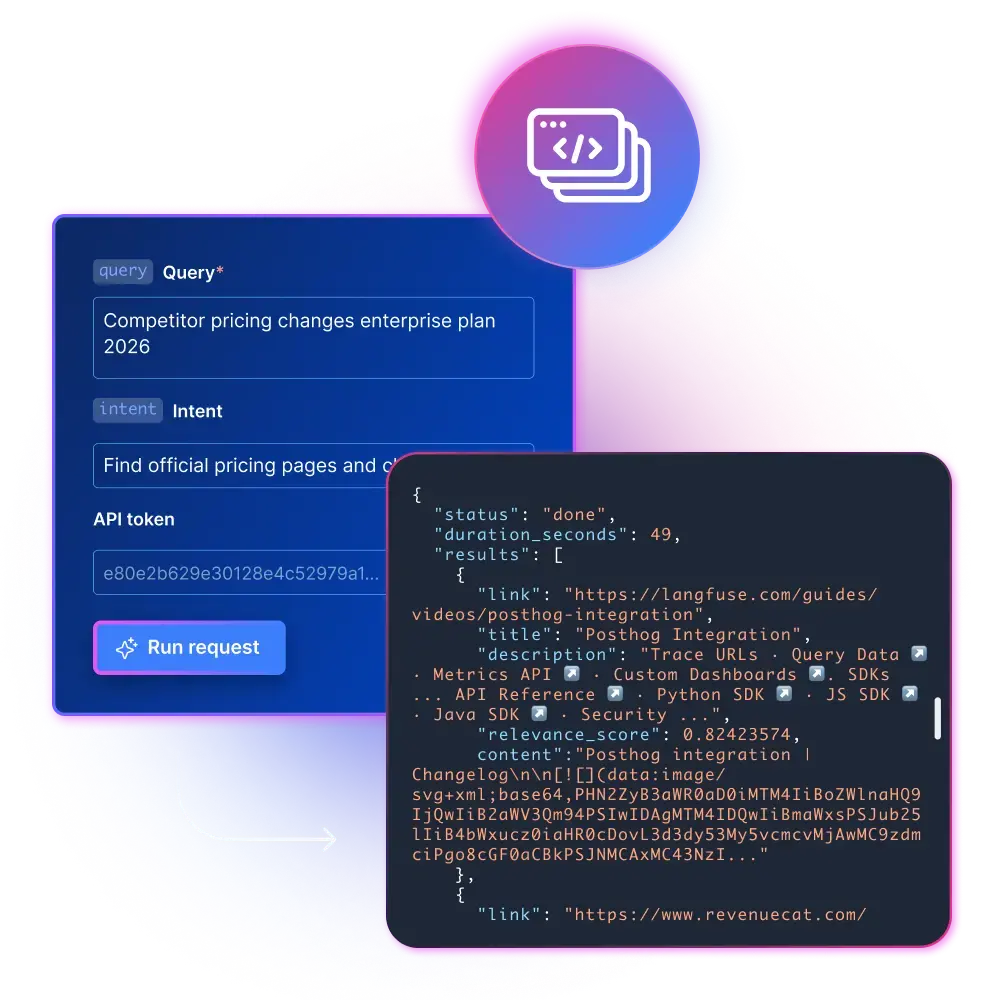
`POST https://api.brightdata.com/discover`
```bash
curl "https://api.brightdata.com/discover"
-H "Authorization: Bearer "
-H "Content-Type: application/json"
-d '{
"query": "competitor pricing changes enterprise plan 2026",
"num_results": 50,
"intent": "find official pricing pages and change notes",
"content": true,
"format": "markdown"
}'
require('request-promise')({
url: 'https://geo.brdtest.com/mygeo.json',
proxy: 'http://brd-customer-[your customerID]-zone-residential:"[your password]"@brd.superproxy.io:33335',
})
.then(function(data){ console.log(data); },
function(err){ console.error(err); });
import requests
url = "https://api.brightdata.com/datasets/snapshots/{id}/download"
headers = {"Authorization": "Bearer "}
response = requests.get(url, headers=headers)
print(response.json())
using System;
using System.Net;
class Example
{
static void Main()
{
// Replace '[your customerID]' and '[your password]' with your actual credentials
var client = new WebClient();
client.Proxy = new WebProxy("brd.superproxy.io:33335");
client.Proxy.Credentials = new NetworkCredential("brd-customer-[your customerID]-zone-residential", "[your password]");
Console.WriteLine(client.DownloadString("https://geo.brdtest.com/mygeo.json"));
}
}
快速开始
为市场情报而生

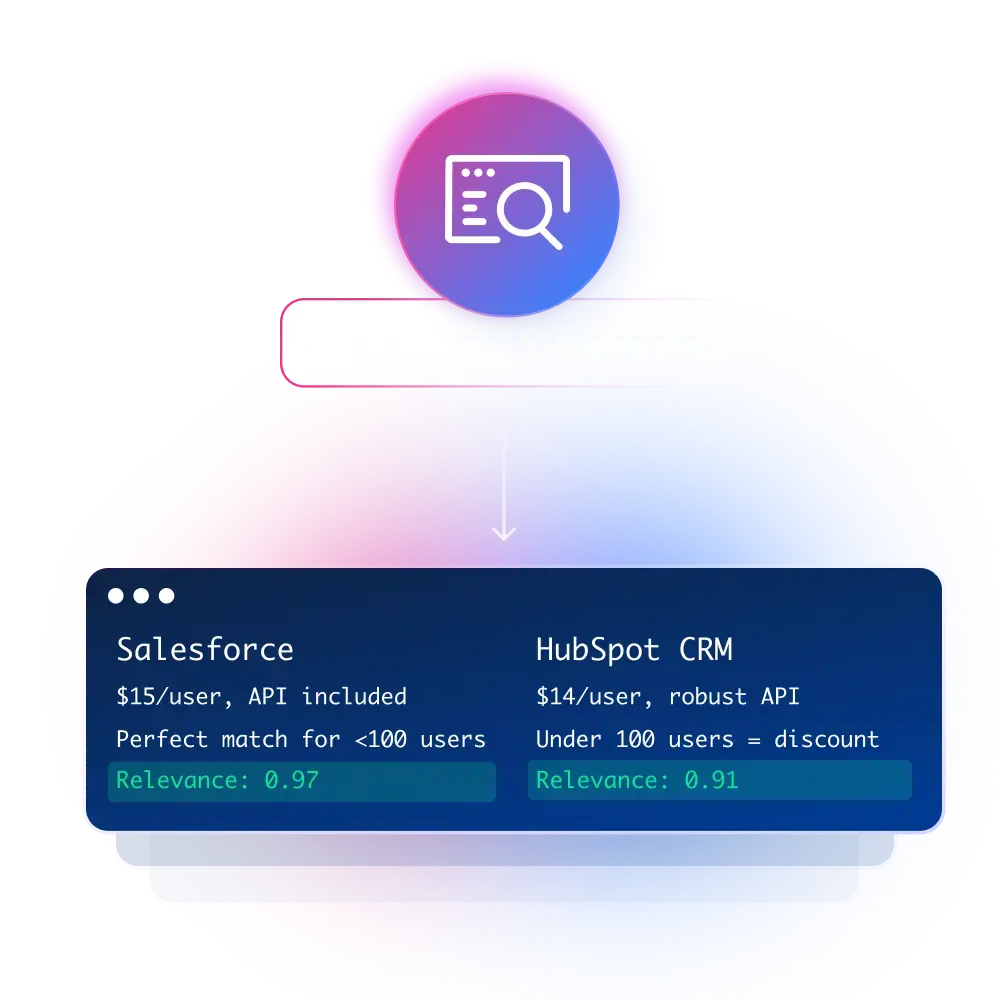
竞品情报
追踪价格、新品发布与市场定位变化

风险监控
识别事件、政策变更与关键信号

尽职调查
在多个独立来源之间交叉验证主张与事实

数据补全
用可核验的实时网页数据填充 CRM

垂直搜索引擎
为单一领域构建按意图排序的搜索

另类数据
捕捉全网长尾信号
与 Bright Data 数据集协同设计
使用 Discover 实现实时发现与最新证据获取;使用 Bright Data 数据集用于基线支撑与规模化快速检索。对于大规模、可重复的数据需求,数据集比反复对同一实体重新发现更具成本效益,同时也能在代理执行实时发现之前,提供更强的起点。
常见问题
Discover 是缓存的还是索引的?
Discover 始终是实时的。每次请求都会在查询时刻针对实时网络执行。
intent 有什么作用?
intent 用于告诉 Discover 代理想要完成什么,因此结果会按任务进行排序。
什么时候应该使用 include_content?
当你需要核验或使用来源文本进行 RAG 事实支撑时,使用 include_content=true。
我应该使用 Discover 还是数据集?
使用数据集获取基线覆盖;使用 Discover 进行实时发现与最新证据获取。大多数团队会两者结合使用。
我可以做历史研究或监控吗?
可使用 Web Archive API 用于历史回填与长期监控。
如果我需要超过 1000 条结果怎么办?
可串联多次 Discover 调用,或使用数据集进行批量导入,然后用 Discover 持续保持新鲜度。