

在本指南中,您将了解到
- 开发人工智能代理的
浏览器使用库是什么 - 为什么它的功能受限于它所控制的浏览器
- 如何使用抓取浏览器克服这些限制
- 如何建立一个在浏览器中运行的人工智能代理,并通过与 Scraping Browser 的集成避免阻塞?
让我们深入了解一下!
什么是浏览器使用?
Browser Use是一个开源 Python 项目,可让人工智能代理访问网站。它能识别网页上的所有交互元素,使代理能与它们进行有意义的交互。简而言之,浏览器使用库允许人工智能以编程方式控制浏览器并与之互动。
具体来说,它提供的主要功能有
- 强大的浏览器自动化:将先进的人工智能与强大的浏览器自动化相结合,简化人工智能代理的网络交互。
- 视觉+HTML 提取:整合视觉理解和 HTML 结构提取,实现更有效的导航和决策。
- 多标签管理:可处理多个浏览器标签,为复杂的工作流程和并行任务打开大门。
- 元素跟踪:使用 XPath 跟踪点击的元素,可重复 LLM 所做的准确操作,确保一致性。
- 自定义操作:支持定义自定义操作,如保存到文件、写入数据库、发送通知或处理人工输入。
- 自我纠正机制:内置错误处理和自动恢复系统,使自动化流水线更加可靠。
- 支持任何 LLM:通过 LangChain 与所有主要 LLM 兼容,包括 GPT-4、Claude 3 和 Llama 2。
人工智能代理开发中浏览器使用的局限性
浏览器使用 “是一项开创性技术,在 IT 界产生了前所未有的影响。在短短几个月内,该项目就在 GitHub 上获得了 60,000 多颗星,这一点也不足为奇:
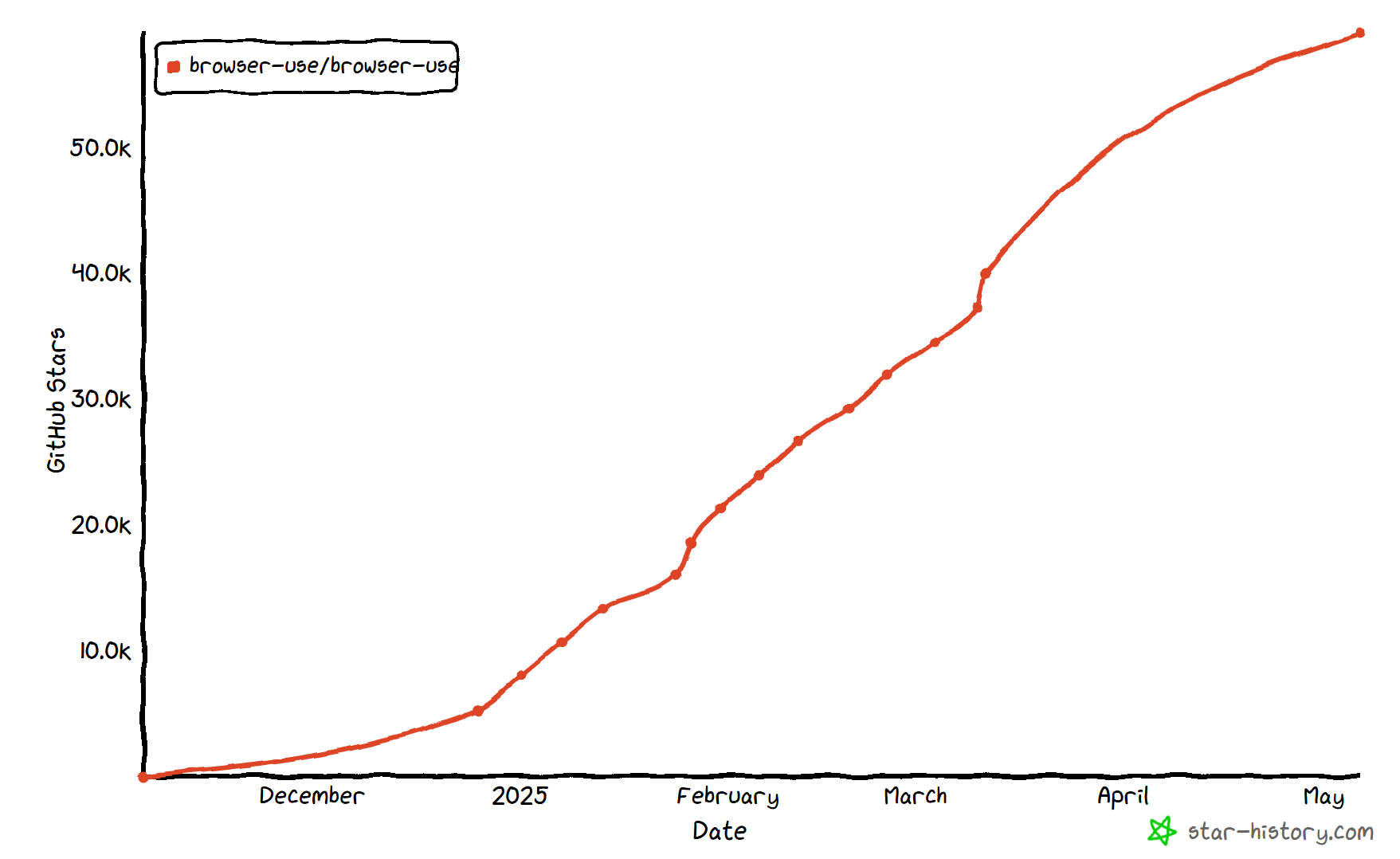
此外,它背后的团队还获得了超过 1700 万美元的种子基金,这充分说明了这个项目的潜力和前景。
不过,我们必须认识到,Browser Use 提供的浏览器控制功能并非基于魔法。相反,该库将视觉输入与人工智能控制相结合,通过Playwright(一个功能丰富的浏览器自动化框架,但也有一定的局限性)实现浏览器自动化。
正如我们在之前关于Playwright 网络抓取的文章中所指出的,限制因素并非来自自动化框架本身。恰恰相反,它们来自于它所控制的浏览器。具体来说,像 Playwright 这样的工具会启动带有特殊配置和工具的浏览器,从而实现自动化。问题是,这些设置也会使它们暴露在反僵尸检测系统的检测之下。
这就成了一个大问题,尤其是在构建需要与保护良好的网站进行交互的人工智能代理时。例如,假设您想利用 “浏览器使用 “来构建一个人工智能代理,为您将特定商品添加到亚马逊的购物车中。您可能会得到这样的结果:
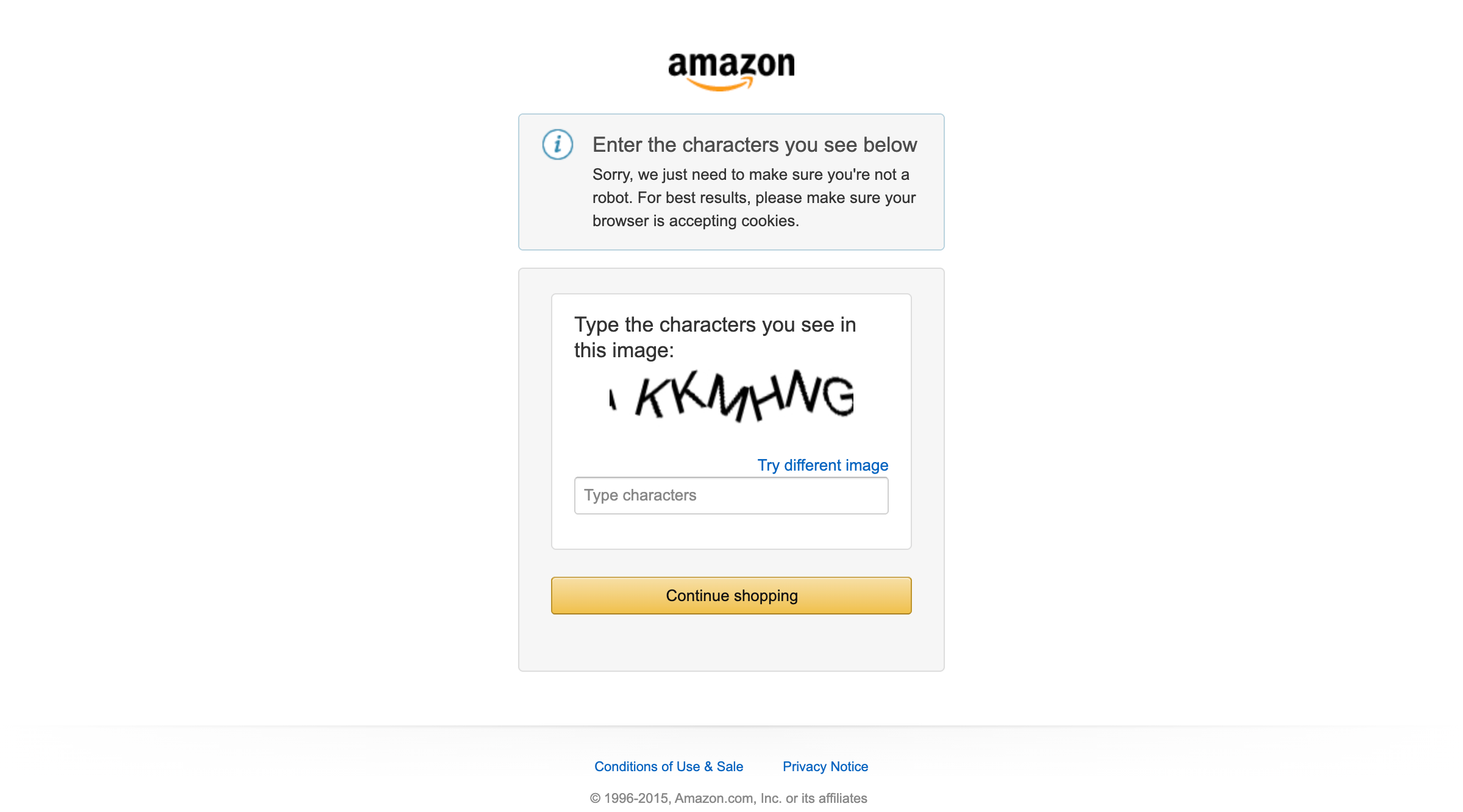
如您所见,亚马逊反机器人系统可以检测并阻止您的人工智能自动化。特别是,电子商务平台可能会显示具有挑战性的亚马逊验证码,或以 “对不起,我们出错了 “的错误页面作为回应:

在这种情况下,人工智能代理就会 “玩完”。因此,虽然 “浏览器使用 “是一个神奇而强大的工具,但要充分发挥它的潜力,还需要进行深思熟虑的调整。最终目标是避免触发反机器人系统,从而使人工智能自动化能够按预期运行。
为什么说扫描浏览器是一种解决方案?
现在你可能会想”为什么不通过 Playwright 对使用浏览器控制的浏览器进行调整,使用特殊标记来降低被检测到的几率呢?这的确是可行的,也是Playwright Stealth 等库所使用的策略的一部分。
然而,绕过反机器人检测远比翻转几个标志要复杂得多…
它涉及 IP 信誉、速率限制、浏览器指纹识别和其他高级方面的因素。你不能简单地通过一些手动技巧来战胜复杂的反僵尸系统。你真正需要的是一个从头开始构建的解决方案,让反僵尸和反搜索防御系统无法检测到。这就是抓取浏览器的用武之地!
抓取浏览器解决方案提供了非常有效的反检测功能。那么,市场上最好的反检测浏览器是什么呢?Bright Data 的抓取浏览器!
其中,Scraping Browser是基于云的下一代网络浏览器,可提供
- 可靠的 TLS 指纹,可与真实用户混为一谈
- 无限制的可扩展性,适用于大批量抓取
- 自动 IP 轮换,由 150M+ IP 代理网络提供支持
- 内置重试逻辑,可从容处理失败的请求
- 开箱即用的验证码解决功能
- 全面的反僵尸绕过工具包
Scraping Browser 集成了所有主要的浏览器自动化库,包括 Playwright、Puppeteer 和 Selenium。因此,它与浏览器的使用完全兼容,因为该库建立在 Playwright 的基础之上。
通过将 Scraping Browser 集成到浏览器使用中,你可以绕过之前遇到的亚马逊拦截,或避免其他网站上的类似拦截。
如何将浏览器与搜索浏览器结合使用
在本教程中,您将学习如何将浏览器使用与 Bright Data 的 Scraping Browser 集成。我们将构建一个由 OpenAI 驱动的人工智能代理,它可以向亚马逊购物车添加商品。
这只是展示人工智能驱动的浏览器自动化功能的一个例子。请注意,人工智能代理可以根据您的需求和目标,与其他网站进行交互。重要的是,它可以为您执行繁琐的操作,从而节省大量时间和精力。
具体来说,我们即将构建的亚马逊人工智能代理将能够
- 使用远程 Scraping Browser 实例连接到亚马逊,以避免检测和阻止。
- 阅读提示中的项目清单。
- 搜索、选择正确的产品并自动添加到购物车。
- 访问购物车并提供整个订单的摘要。
请按照以下步骤了解如何利用浏览器使用 Scraping 浏览器!
先决条件
要学习本教程,请确保您具备以下条件:
- 一个 Bright Data 账户。
- 受支持的人工智能提供商(如 OpenAI、Anthropic、Gemini、DeepSeek、Grok 或 Novita)提供的 API 密钥。
- 掌握Python 异步编程和浏览器自动化的基本知识。
如果您还没有 Bright Data 或 AI 提供商账户,请不要担心。我们将在下面的步骤中教您如何创建。
步骤 #1:项目设置
开始之前,请确保您的系统已安装 Python 3。否则,请从官方网站下载并按照安装说明进行操作。
打开终端,为人工智能代理项目创建一个新文件夹:
mkdir browser-use-amazon-agentbrowser-use-amazon-agent文件夹将包含基于 Python 的人工智能代理的所有代码。
导航进入项目文件夹,并在其中建立虚拟环境:
cd browser-use-amazon-agent
python -m venv venv现在,在您最喜欢的 Python IDE 中打开项目文件夹。带有 Python 扩展的 Visual Studio Code或PyCharm Community Edition都是不错的选择。
在browser-use-amazon-agent文件夹中新建一个名为agent.py 的 Python 文件。现在您的项目结构应该是这样的
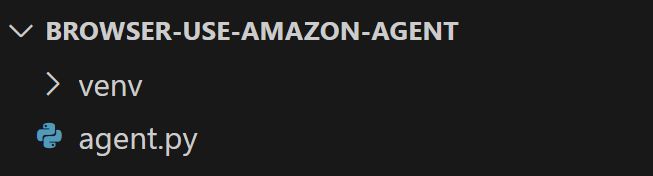
此时,agent.py 只是一个空脚本,但它很快就会包含完整的人工智能浏览器自动化逻辑。
在集成开发环境的终端中,激活虚拟环境。在 Linux/macOS 上,运行
source venv/bin/activate在 Windows 上执行
venv/Scripts/activate一切就绪!现在,您的 Python 环境已经准备就绪,可以使用浏览器使用和扫描浏览器构建人工智能代理了。
步骤 #2:设置环境变量 阅读
您的项目将与第三方服务(如 Bright Data 和您选择的人工智能提供商)集成。最好不要在 Python 代码中直接硬编码 API 密钥和连接秘密,而是从环境变量中加载它们。
为了简化这项工作,我们将使用python-dotenv库。在激活的虚拟环境中,使用以下命令安装该库:
pip install python-dotenv在agent.py文件中导入该库,并使用load_dotenv() 加载环境变量:
from dotenv import load_dotenv
load_dotenv()现在你可以从本地.env文件读取变量了。将其添加到你的项目中:
现在,您可以通过这行代码在代码中访问这些环境变量:
env_value = os.getenv("<ENV_NAME>")不要忘记从 Python 标准库中导入os:
import os太好了!现在,您可以从 envs 中安全地读取与第三方服务集成的秘密了。
步骤 #3:开始使用浏览器
激活虚拟环境后,安装浏览器使用程序:
pip install browser-use由于该库依赖于多个依赖项,这可能需要几分钟时间。所以,请耐心等待。
由于浏览器使用模式下使用的是 Playwright,您可能还需要安装Playwright 的浏览器依赖项。为此,请运行以下命令:
python -m playwright install这将下载必要的浏览器二进制文件,并设置 Playwright 正常运行所需的一切。
现在,从browser-use 中导入所需的类:
from browser_use import Agent, Browser, BrowserConfig我们很快就会使用这些类来构建人工智能代理的浏览器自动化逻辑。
由于browser-use提供了异步 API,因此需要使用异步入口点初始化agent.py:
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())上述代码段使用 Python 的asyncio库来运行异步任务,这对于使用浏览器工作是必需的。
干得好下一步是配置 Scraping 浏览器并将其集成到脚本中。
步骤 #4:开始使用扫描浏览器
有关一般集成说明,请参阅Scraping Browser 官方文档。否则,请按照以下步骤操作。
要开始使用,如果还没有,请创建一个 Bright Data 帐户。登录后,进入用户仪表板,点击 “获取代理产品 “按钮:
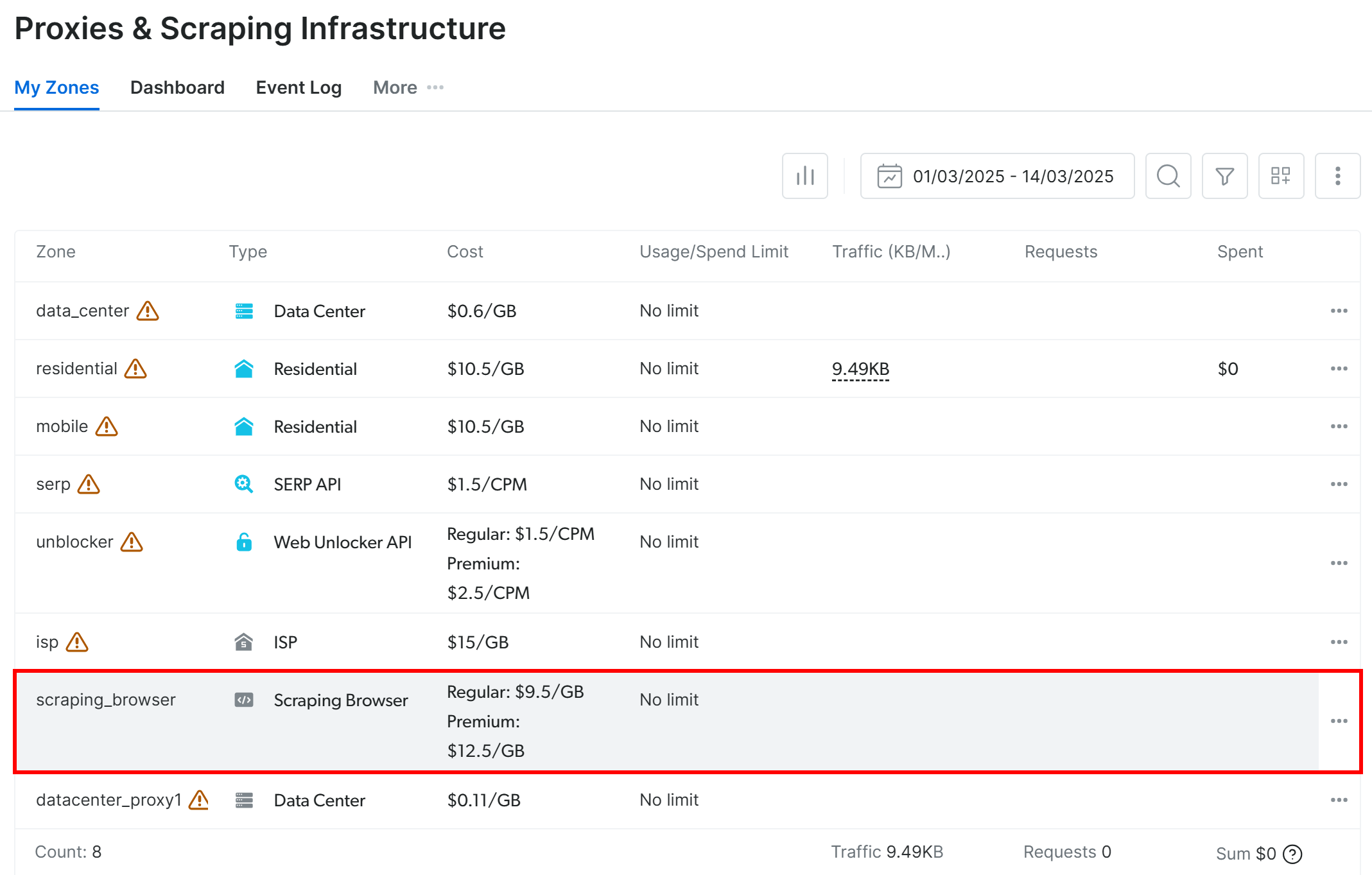
在 “Proxies & Scraping Infrastructure “页面,查找 “My Zones”(我的区域)表,然后选择 “Scraping Browser”(搜索浏览器)类型的行:
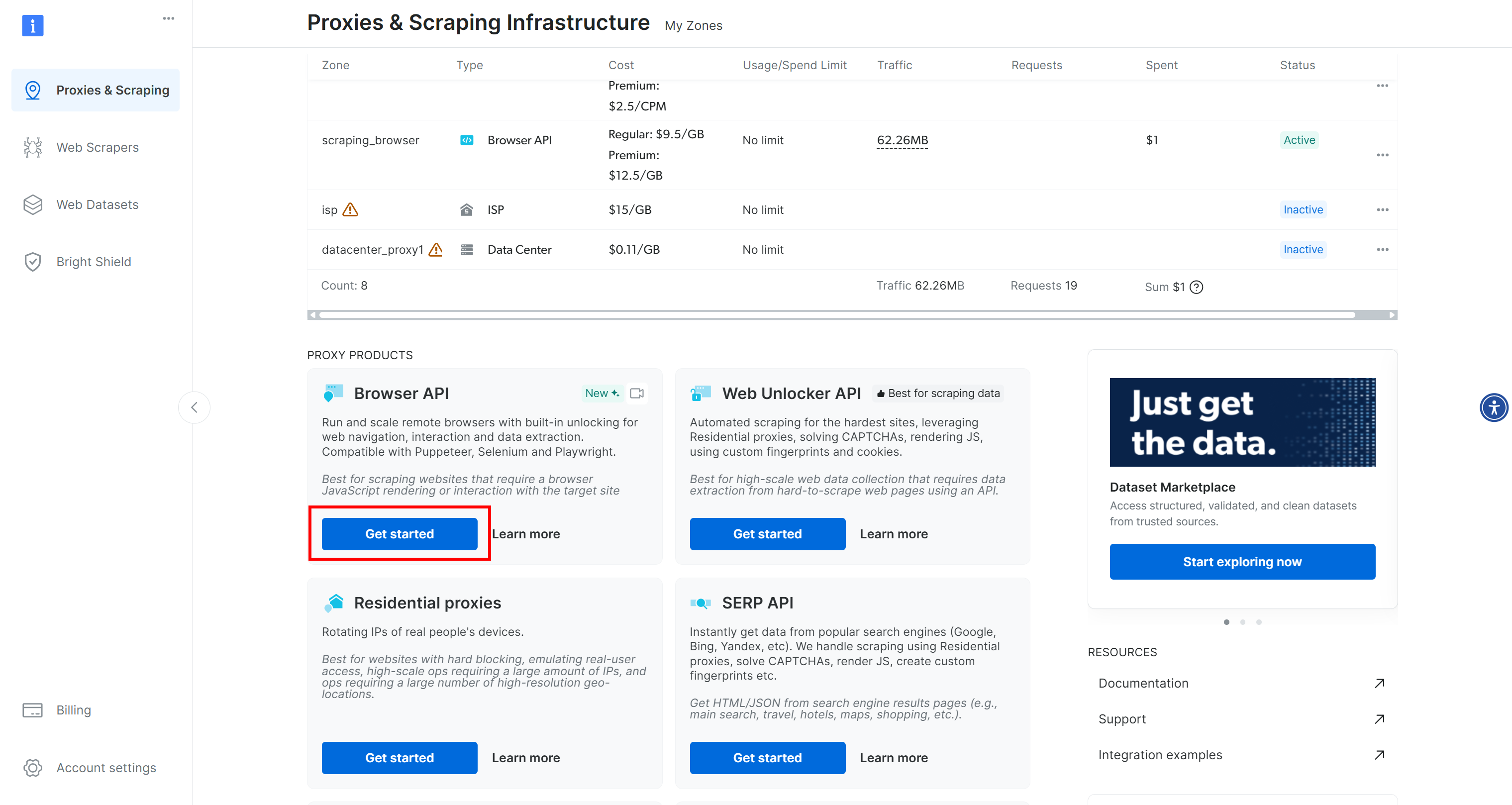
如果没有看到这一行,说明您还没有配置 Scraping 浏览器区域。在这种情况下,请向下滚动,直到找到 “Browser API “卡,然后按下 “Get Started(开始)”按钮:
接下来,按照指导设置首次配置 Scraping 浏览器。
到达产品页面后,通过切换开/关开关来启用它:

现在,进入 “配置 “选项卡,确保启用 “高级域 “和 “验证码解码器”,以发挥最大功效:
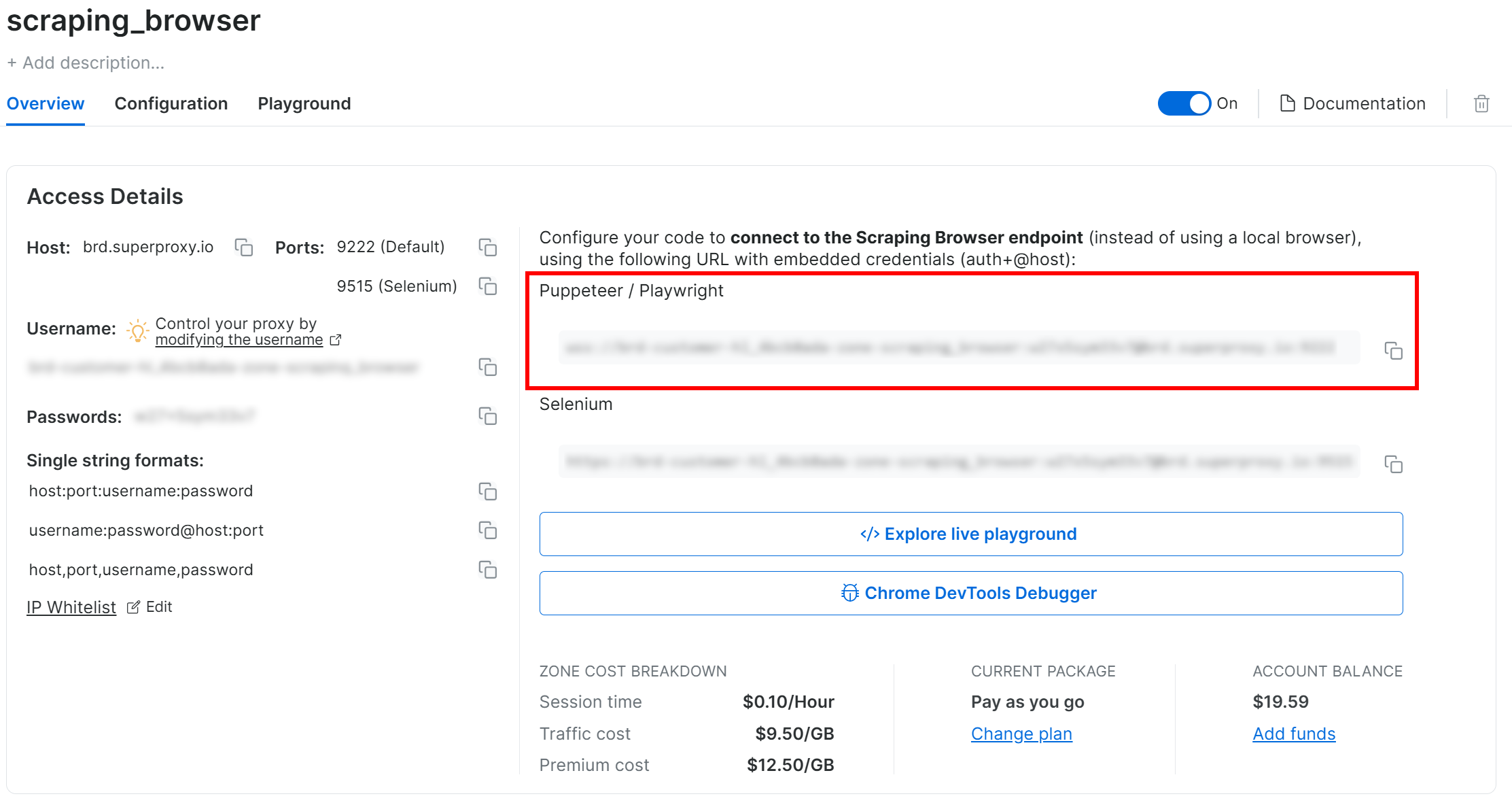
切换到 “概览 “选项卡,复制 Playwright Scraping 浏览器连接字符串:
将此连接字符串添加到.env文件中:
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"替换为 替换为刚才复制的值。
现在,在你的agent.py文件中,用以下方式加载环境变量:
SBR_CDP_URL = os.getenv("SBR_CDP_URL")太神奇了现在,你可以在浏览器中使用 Scraping Browser 了。在深入了解之前,我们先将 OpenAI 添加到脚本中,完成第三方集成。
步骤 #5:开始使用 OpenAI
免责声明:以下步骤侧重于集成 OpenAI,但您也可以轻松调整以下说明,以适用于浏览器使用支持的任何其他人工智能提供商。
要在浏览器中启用人工智能功能,需要外部人工智能提供商提供有效的 API 密钥。在此,我们将使用 OpenAI。如果您尚未生成 API 密钥,请按照OpenAI 的官方指南创建一个。
获得密钥后,将其添加到.env文件中:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"确保将 替换为您的实际 API 密钥。
接下来,从agent.py 中的langchain_openai导入ChatOpenAI类:
from langchain_openai import ChatOpenAI请注意,浏览器使用依赖于LangChain来处理人工智能集成。因此,即使您没有在项目中明确安装langchain_openai,它也已可供使用。如需更多指导,请阅读我们关于如何在 LangChain 工作流程中集成 Bright Data 的教程。
使用gpt-4o模型设置 OpenAI 集成:
llm = ChatOpenAI(model="gpt-4o")无需额外配置。这是因为langchain_openai会自动从OPENAI_API_KEY环境变量中读取 API 密钥。
关于与其他人工智能模型或提供商的集成,请参阅浏览器使用官方文档。
步骤 #6:在浏览器中集成 “搜索浏览器”。
要连接到使用浏览器的远程浏览器,需要这样使用BrowserConfig对象:
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)该配置指示 Playwright 连接到远程 Bright Data Scraping Browser 实例。
步骤 #7:定义自动化任务
现在是时候使用自然语言定义您希望人工智能代理在浏览器中执行的任务了。
在这样做之前,请确保您已在脑海中清晰地定义了目标。在这种情况下,我们假定你希望人工智能代理:
- 连接至 Amazon.com。
- 将 PlayStation 5 游戏机和 Astro Bot PS5 游戏添加到购物车。
- 到达购物车页面并生成当前订单的摘要。
如果您只向 Browser Use 提供了这些基本说明,那么事情可能不会像预期的那样顺利。这是因为有些产品有多个版本,有些页面可能会提示您购买额外的保险,有些项目可能无法使用,等等。
因此,在这些情况下,添加额外的注释来指导人工智能代理做出决定是有意义的。
此外,为了提高性能,用文字清楚地概述最重要的步骤也很有帮助。
有鉴于此,您的人工智能代理应该在浏览器中执行的任务可以这样描述:
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""请注意,这个版本非常详细,足以指导人工智能代理完成常见场景,并防止其陷入困境。
漂亮!看看如何启动这项任务。
步骤 #8:启动人工智能任务
使用人工智能代理的任务定义,初始化浏览器使用的代理对象:
agent = Agent(
task=task,
llm=llm,
browser=browser,
)现在您可以使用
await agent.run()此外,任务完成后不要忘记关闭 Playwright 控制的浏览器,以释放其资源:
await browser.close()完美!Browser Use + Bright Data Scraping Browser 集成现已完全设置完毕。现在只需将所有内容整合在一起,运行完整的代码即可。
步骤 #9:将所有内容整合在一起
您的agent.py文件应包含
from dotenv import load_dotenv
import os
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
import asyncio
from langchain_openai import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())就是这样!只需不到 100 行代码,您就构建了一个功能强大的人工智能代理,将浏览器与 Bright Data 的 “Scraping Browser “结合使用。
要执行人工智能代理,请运行
python agent.py一旦启动,浏览器使用将记录它所做的一切。由于 Scraping 浏览器在云中运行,没有可视化界面,因此这些日志对于了解代理正在做什么至关重要。
以下是日志内容的简短摘录:
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.如您所见,人工智能代理成功地找到了所需的商品,将它们添加到购物车,并生成了一份干净的摘要。所有这一切,亚马逊都没有阻止或禁止,这都要归功于 Scraping 浏览器!
浏览器使用功能还包括录制浏览器会话以便调试的功能。虽然远程浏览器还不能使用这种功能,但如果可以的话,你就能看到人工智能代理在操作过程中令人着迷的回放.
真正的催眠–令人兴奋的一瞥,让我们看到人工智能驱动的浏览技术已经取得了多大的进步。
步骤 #10:下一步
我们在这里构建的亚马逊人工智能代理只是一个起点–概念验证,以展示可能实现的功能。为了使它能够投入生产,以下是一些改进意见:
- 连接到您的亚马逊账户:允许代理登录,以便访问订单历史和推荐等个性化功能。
- 实施采购工作流程:扩展代理以实际完成购买。这包括选择运输选项、应用促销代码或礼品卡以及确认付款。
- 通过电子邮件发送确认或报告:在最终完成任何付款交易之前,代理可以通过电子邮件发送购物车和预定操作的详细摘要,供用户批准。这样既能让您保持控制,又能增加一层责任感。
- 从愿望清单或输入列表中读取项目:让代理从保存的亚马逊愿望清单、本地文件(如 JSON 或 CSV)或远程 API 端点动态加载项目。
结论
在这篇博文中,您将了解到如何结合使用流行的浏览使用库和抓取浏览器 API,在 Python 中构建一个高效的人工智能代理。
如图所示,将 “浏览使用 “与 Bright Data 的 “抓取浏览器 “相结合,您就可以创建能够与几乎任何网站进行可靠交互的人工智能代理。这只是 Bright Data 的工具和服务如何增强高级人工智能驱动自动化的一个例子。
探索我们的人工智能代理开发解决方案:
- 自主人工智能代理:使用一套功能强大的应用程序接口,实时搜索、访问任何网站并与之互动。
- 垂直 AI 应用程序:建立可靠的自定义数据管道,从特定行业来源提取网络数据。
- 基础模型:访问符合要求的网络规模数据集,以便进行预训练、评估和微调。
- 多模态人工智能:利用世界上最大的图像、视频和音频资源库,为人工智能进行优化。
- 数据提供商:与值得信赖的提供商建立联系,大规模地获取高质量的人工智能就绪数据集。
- 数据包:获取精心策划、随时可用、结构化、丰富和注释的数据集。
如需了解更多信息,请访问我们的人工智能中心。
创建 Bright Data 帐户,试用我们为人工智能代理开发提供的所有产品和服务!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




