

在本指南中,您将学习:
- SeleniumBase 是什么,以及它为何适合用于网页爬虫
- 它与原生 Selenium 的比较
- 它提供的功能和优势
- 如何使用它来搭建一个简单的爬虫
- 如何在更复杂的用例中利用它
让我们开始吧!
什么是 SeleniumBase?
SeleniumBase 是一个基于 Python 的浏览器自动化框架。它构建在 Selenium/WebDriver APIs 之上,为网页自动化提供了专业级工具包,支持从测试到爬虫等广泛任务。
SeleniumBase 是一个一体化库,可用于测试网页、自动化工作流程并扩展基于 Web 的各种操作。它配备了高级功能,如 CAPTCHA 绕过、反机器人检测,以及提升生产力的相关工具。
SeleniumBase 与 Selenium:功能与 API 对比
为了更好地理解为何选择 SeleniumBase,有必要将其与最初的 Selenium(即它的基础工具)进行直接对比。
以下是 Selenium 与 SeleniumBase 的快速对比表:
| 功能 | SeleniumBase | Selenium |
|---|---|---|
| 内置测试运行器 | 与 pytest、pynose 和 behave 集成 |
需要手动设置测试集成 |
| 驱动管理 | 自动下载与浏览器版本匹配的驱动 | 需要手动下载和配置驱动 |
| Web 自动化逻辑 | 将多个步骤整合到单个方法调用中 | 实现相同功能需要多行代码 |
| 选择器处理 | 自动检测 CSS 或 XPath 选择器 | 需要在方法调用中显式指定选择器类型 |
| 超时处理 | 应用默认的超时时间以防止出错 | 若未显式设置超时,方法会立即失败 |
| 错误输出 | 提供清晰、可读的错误消息,便于调试 | 产生较为冗长且不易理解的错误日志 |
| 仪表盘和报告 | 内置仪表盘、报告和失败截图功能 | 无内置仪表盘或报告功能 |
| 桌面 GUI 应用 | 提供可视化工具用于运行测试 | 缺少用于测试执行的桌面 GUI 工具 |
| 测试录制器 | 内置测试录制器,可根据手动浏览器操作自动生成脚本 | 需要手动编写脚本 |
| 测试用例管理 | 提供 CasePlans,可在框架内组织测试并直接记录步骤 | 无内置的测试用例管理工具 |
| 数据应用支持 | 包含 ChartMaker,可从 Python 生成 JavaScript 用于创建数据应用 | 无构建数据应用的额外工具 |
接下来,让我们深入了解这些差异!
内置测试运行器
SeleniumBase 与流行的测试运行器(如 pytest、pynose 和 behave)集成。这些工具提供了有组织的结构、便捷的测试发现与执行、测试状态跟踪(如已通过、失败或跳过),以及用于自定义设置(如选择浏览器)的命令行选项。
在原生 Selenium 中,通常需要手动实现选项解析器,或依赖第三方工具从命令行进行配置。
增强的驱动管理
默认情况下,SeleniumBase 会自动下载与浏览器主版本匹配的驱动版本。您可以通过在 pytest 命令后使用 --driver-version=VER 参数来自定义。例如:
pytest my_script.py --driver-version=114而对于原生 Selenium,则需要您手动下载并配置相应的驱动,确保其与浏览器版本兼容。
多操作合并方法
SeleniumBase 将多个步骤合并为单个方法,从而简化 Web 自动化。例如,driver.type(selector, text) 方法会执行以下操作:
- 等待元素可见
- 等待元素可交互
- 清除已有文本
- 输入指定文本
- 如果文本以
"n"结尾则提交
而在原生 Selenium 中,实现相同逻辑需要几行代码。
简化的选择器处理
SeleniumBase 可以自动区分 CSS 选择器和 XPath 表达式,无需像原生 Selenium 那样在方法调用中显式指定 By.CSS_SELECTOR 或 By.XPATH。当然,如果您愿意,也可以手动指定。
使用 SeleniumBase 的示例:
driver.click("button.submit") # Automatically detects as CSS Selector
driver.click("//button[@class='submit']") # Automatically detects as XPath原生 Selenium 等价的代码为:
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()默认与自定义超时时间
SeleniumBase 默认为方法应用 10 秒的超时时间,确保元素有足够时间加载,避免出现在原生 Selenium 中常见的立即失败问题。
您也可以直接在方法调用中设置自定义的超时时间,如下所示:
driver.click("button", timeout=20)对应的原生 Selenium 代码会更为繁琐:
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()清晰的错误输出
SeleniumBase 在脚本失败时会提供简洁、易读的错误信息。而原生 Selenium 往往会产生冗长且晦涩的日志,增加调试难度。
仪表盘、报告与截图
SeleniumBase 自带生成测试运行仪表盘和报告的功能;也可以在 ./latest_logs/ 文件夹中保存失败时的截图,方便调试。原生 Selenium 并不具备这些开箱即用的功能。
额外功能
与 Selenium 相比,SeleniumBase 包含如下扩展:
- 桌面 GUI 应用程序,可视化运行测试,例如适用于
pytest的 SeleniumBase Commander 和适用于behave的 SeleniumBase Behave GUI。 - 内置的 Recorder / Test Generator,可根据手动浏览器动作创建测试脚本,大大减少编写针对复杂流程测试的工作量。
- 一个名为 CasePlans 的测试用例管理软件,用于在框架内部组织测试并记录步骤说明。
- 类似 ChartMaker 之类的工具,可通过将 Python 生成的 JavaScript 嵌入来构建数据应用,使其超越常规的测试自动化用途。
SeleniumBase:功能、方法与命令行选项
下面让我们来看看是什么让 SeleniumBase 与众不同,以及它提供了哪些功能和 API。
功能
以下列出了部分 SeleniumBase 的核心功能:
- 配备 Recorder 模式,可立即生成 Python 浏览器测试。
- 在同一个测试中支持多浏览器、多标签页、iframe 以及代理。
- 支持内置的基于 Markdown 技术的测试用例管理软件。
- 智能等待机制可自动提高稳定性并减少测试波动。
- 兼容
pytest、unittest、nose以及behave做测试发现和执行。 - 包含高级日志工具,可生成仪表盘、报告和截图。
- 可在无头模式下运行测试,隐藏浏览器界面。
- 支持跨多个并行浏览器进行多线程测试执行。
- 允许使用 Chromium 的移动设备模拟器运行测试。
- 可在通过代理服务器(支持认证)运行测试。
- 可以自定义测试时使用的浏览器 User-Agent。
- 可防止被一些阻止 Selenium 自动化的站点识别。
- 可与 selenium-wire 集成来检查浏览器网络请求。
- 提供灵活的命令行界面,可进行自定义测试执行选项。
- 全球配置文件可管理测试设置。
- 可与 GitHub Actions、谷歌云、Azure、S3 与 Docker 等集成。
- 支持从 Python 中执行 JavaScript。
- 通过在 CSS 选择器中使用
::shadow选择器,可与 Shadow DOM 元素交互。
更多功能请参考官如需查看完整列表,请参阅文档。务必阅读我们关于如何使用 SeleniumBase 与代理的博客。方文档。
方法
下面列出了部分常用的 SeleniumBase 方法:
driver.open(url):在当前浏览器窗口中导航到指定 URL。driver.go_back():返回上一个访问的 URL。driver.type(selector, text):在指定选择器对应的字段中输入文本。driver.click(selector):点击由选择器标识的元素。driver.click_link(link_text):点击包含指定文本的链接。driver.select_option_by_text(dropdown_selector, option):通过可见文本来选择下拉菜单中的选项。driver.hover_and_click(hover_selector, click_selector):在某元素上悬停并点击另一个元素。driver.drag_and_drop(drag_selector, drop_selector):将一个元素拖拽到另一个元素上。driver.get_text(selector):获取指定元素的文本。driver.get_attribute(selector, attribute):获取元素的指定属性值。driver.get_current_url():获取当前页面的 URL。driver.get_page_source():获取当前页面的 HTML 源代码。driver.get_title():获取当前页面的标题。driver.switch_to_frame(frame):切换到指定的 iframe 容器。driver.switch_to_default_content():退出 iframe 回到主文档。driver.open_new_window():在同一会话中打开新的浏览器窗口。driver.switch_to_window(window):切换到指定的浏览器窗口。driver.switch_to_default_window():返回最初的浏览器窗口。driver.get_new_driver(OPTIONS):通过指定的选项开启一个新的驱动会话。driver.switch_to_driver(driver):切换至指定的浏览器驱动。driver.switch_to_default_driver():返回最初的浏览器驱动。driver.wait_for_element(selector):等待直至指定元素可见。driver.is_element_visible(selector):检查指定元素是否可见。driver.is_text_visible(text, selector):检查指定文本是否在元素中可见。driver.sleep(seconds):暂停执行指定秒数。driver.save_screenshot(name):以.png格式保存截图,并使用给定名称。driver.assert_element(selector):验证指定元素是否可见。driver.assert_text(text, selector):验证元素中是否存在指定文本。driver.assert_exact_text(text, selector):验证元素中文本是否与指定字符串精确匹配。driver.assert_title(title):验证当前页面的标题是否符合预期。driver.assert_downloaded_file(file):验证指定文件是否已下载。driver.assert_no_404_errors():验证页面上无损坏链接。driver.assert_no_js_errors():验证页面上无 JavaScript 错误。
更多方法请参考官方文档。
命令行选项
SeleniumBase 为 pytest 扩展了如下命令行选项:
--browser=BROWSER:设置要使用的浏览器(默认:chrome)。--chrome:--browser=chrome的简写。--edge:--browser=edge的简写。--firefox:--browser=firefox的简写。--safari:--browser=safari的简写。--settings-file=FILE:覆盖默认的 SeleniumBase 设置。--env=ENV:设置测试环境,可通过driver.env访问。--account=STR:设置账号,可通过driver.account访问。--data=STRING:额外测试数据,可通过driver.data访问。--var1=STRING:额外测试数据,可通过driver.var1访问。--var2=STRING:额外测试数据,可通过driver.var2访问。--var3=STRING:额外测试数据,可通过driver.var3访问。--variables=DICT:额外测试数据,可通过driver.variables访问。--proxy=SERVER:PORT:使用代理服务器。--proxy=USERNAME:PASSWORD@SERVER:PORT:使用带认证的代理服务器。--proxy-bypass-list=STRING:指定要跳过代理的主机列表(例如“*.foo.com”)。--proxy-pac-url=URL:通过 PAC URL 使用代理。--proxy-pac-url=USERNAME:PASSWORD@URL:使用带认证的 PAC URL 代理。--proxy-driver:使用代理下载驱动。--multi-proxy:在多线程中允许使用多个认证代理。--agent=STRING:修改浏览器的 User-Agent 字符串。--mobile:启用移动设备模拟模式。--metrics=STRING:设置移动参数(如“CSSWidth,CSSHeight,PixelRatio”)。--chromium-arg="ARG=N,ARG2":设置 Chromium 参数。--firefox-arg="ARG=N,ARG2":设置 Firefox 参数。--firefox-pref=SET:设置 Firefox 偏好。--extension-zip=ZIP:加载 Chrome 扩展.zip/.crx文件。--extension-dir=DIR:加载 Chrome 扩展目录。--disable-features="F1,F2":禁用指定功能。--binary-location=PATH:设置 Chromium 的二进制文件路径。--driver-version=VER:指定驱动版本。--headless:使用默认的无头模式。--headless1:使用 Chrome 旧版的无头模式。--headless2:使用 Chrome 新版的无头模式。--headed:在 Linux 上启用浏览器 GUI 模式。--xvfb:在 Linux 上使用 Xvfb 运行测试。--locale=LOCALE_CODE:设置浏览器的语言区域。--reuse-session:所有测试使用同一个浏览器会话。--reuse-class-session:对同一个测试类复用会话。--crumbs:在复用会话之间删除 Cookies。--disable-cookies:禁用 Cookies。--disable-js:禁用 JavaScript。--disable-csp:禁用内容安全策略 (CSP)。--disable-ws:禁用网络安全 (Web Security)。--enable-ws:启用网络安全。--log-cdp:记录 Chrome DevTools Protocol (CDP) 事件。--remote-debug:同步至 Chrome Remote Debugger。--visual-baseline:设置布局测试的可视化基准。--timeout-multiplier=MULTIPLIER:对默认超时时间进行倍数放大。
完整的命令行选项定义请参见官方文档。
使用 SeleniumBase 进行网页爬虫:分步教程
让我们通过一个循序渐进的教程,学习如何用 SeleniumBase 编写爬虫,从 Quotes to Scrape 这个沙箱站点获取数据:
如果想查看使用原生 Selenium 的类似步骤,可以参阅我们关于使用 Selenium 进行网页爬虫的教程。
步骤 #1:项目初始化
开始之前,请确保本地已安装 Python 3。如果尚未安装,请从此处下载并安装。
打开终端,执行以下命令创建一个项目目录:
mkdir seleniumbase-scraperseleniumbase-scraper 将会存放您的 SeleniumBase 爬虫代码。
进入该目录,并在其中初始化一个虚拟环境:
cd seleniumbase-scraper
python -m venv env然后在您喜欢的 Python IDE(例如VS Code + Python 扩展或PyCharm Community 版)中打开该项目文件夹。
在项目目录中创建 scraper.py 文件,此时目录结构看起来类似:

稍后,scraper.py 将包含您的爬虫逻辑。
在 IDE 的终端中激活虚拟环境。Linux 或 macOS 上可使用:
./env/bin/activateWindows 下则使用:
env/Scripts/activate在激活的环境中,运行以下命令来安装 SeleniumBase:
pip install seleniumbase太好了!您现在已经拥有一个专门用于 SeleniumBase 网页爬虫的 Python 环境。
步骤 #2:SeleniumBase 测试设置
虽然 SeleniumBase 支持使用 pytest 的语法来编写测试,但实际上爬虫并不一定就是测试脚本。不过,您仍可通过SB 语法来利用 SeleniumBase 提供的所有 pytest 命令行扩展选项:
from seleniumbase import SB
with SB() as sb:
pass
# Scraping logic... 然后您可以使用如下命令执行脚本:
python3 scraper.py注意:在 Windows 上,请将 python3 替换为 python。
若想以无头模式执行,可使用:
python3 scraper.py --headless也可以组合多个命令行选项。
步骤 #3:连接到目标页面
使用 open() 方法告诉自动化浏览器访问目标页面:
sb.open("https://quotes.toscrape.com/")如果您在有头模式(GUI 模式)下执行脚本,会短暂看到一个如下浏览器窗口:
需要注意的是,与原生 Selenium 相比,您无需显式地关闭浏览器驱动,SeleniumBase 会自动处理。
步骤 #4:选择引用(Quote)元素
在浏览器中以无痕模式打开目标页面并检查引用元素:
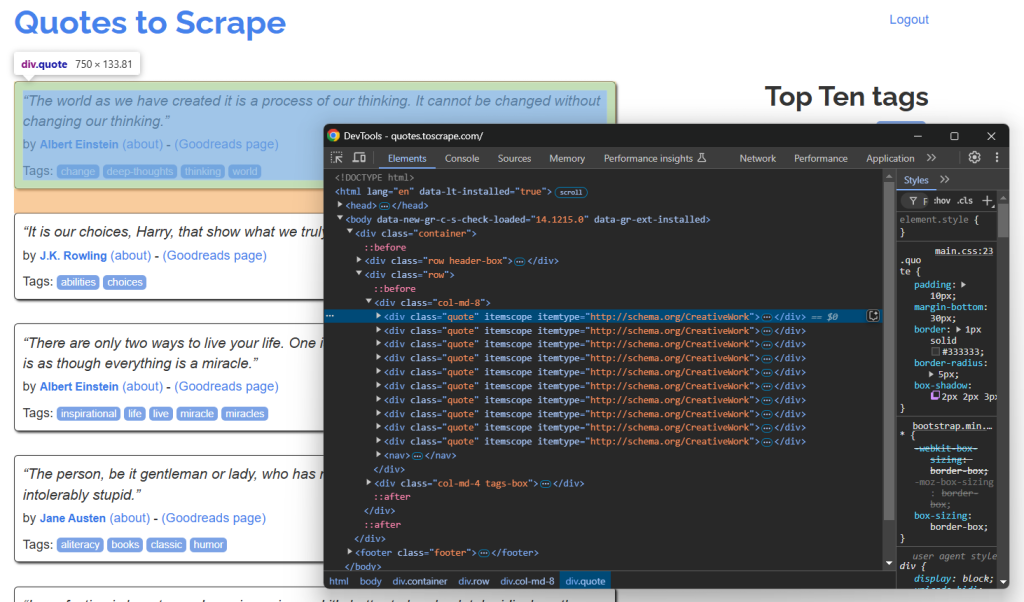
由于页面上包含多个引用,可以先创建一个 quotes 数组来存储爬取到的数据:
quotes = []从 DevTools 面板可见,所有引用都可以用 .quote 这个 CSS 选择器来选中。使用 find_elements() 选中所有:
quote_elements = sb.find_elements(".quote")然后,遍历这些元素,从每个引用元素中爬取数据,并将其添加到一个数组中:
for quote_element in quote_elements:
# 爬取逻辑...非常好!爬取逻辑的主体结构已经就绪。
步骤 #5:爬取引用数据
检查单个引用元素:
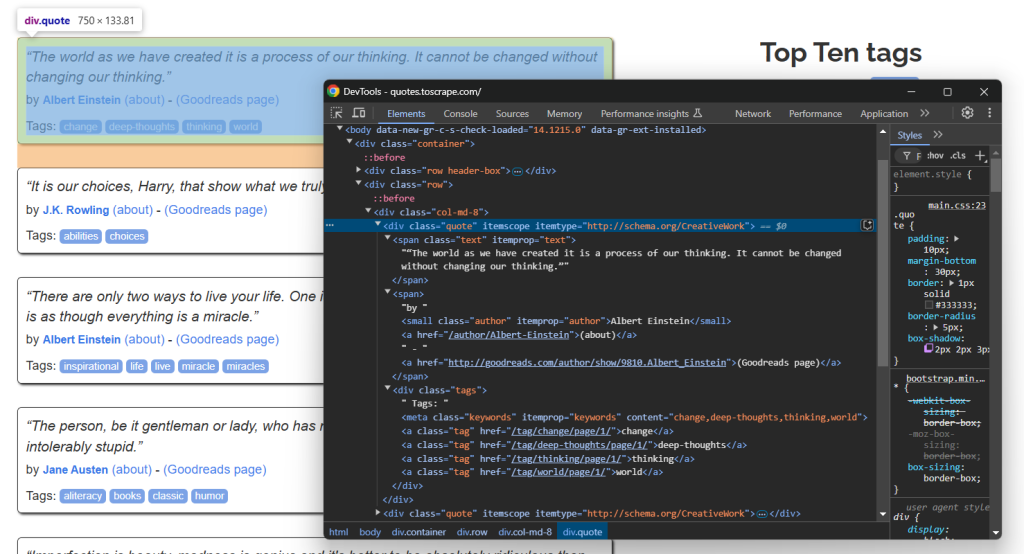
您会注意到可以爬取:
- 来自
.text的引用文本 - 来自
.author的引用作者 - 来自
.tag的引用标签
通过选择各相应节点并获取其 text 属性即可:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)请注意,find_elements() 返回的是原生 Selenium 的 WebElement 对象,因此在该对象内部查找元素时,需要使用 Selenium 的原生方法并指定 By.CSS_SELECTOR。请确保在脚本开头已经导入了 By:
from selenium.webdriver.common.by import By留意到爬取标签需要一个循环,因为单个引用可能会有一个或多个标签。还注意到我们用 replace() 方法去除文本中表示双引号的特殊字符。
步骤 #6:填充引用数组
创建一个 quote 对象来保存每条引用的数据,并将其添加到 quotes 数组中:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)棒极了!SeleniumBase 的基础爬取逻辑已经完成。
步骤 #7:实现爬取逻辑
我们知道目标站点中有多个分页。要转到下一页,只需点击底部的“Next →”按钮:
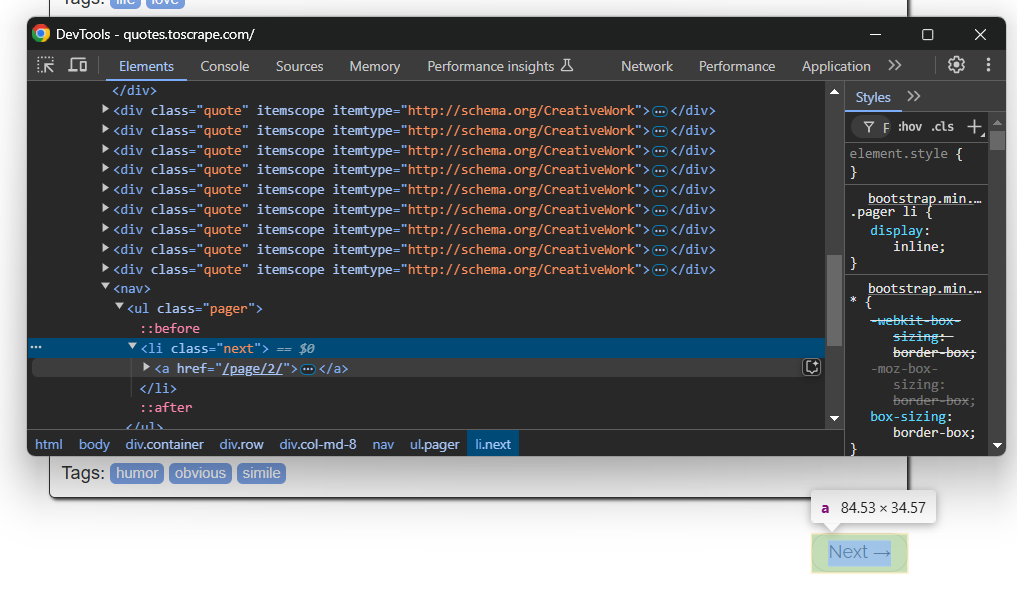
在最后一页,该按钮将不会存在。
要实现网页爬取并获取所有分页内容,可以在循环中点击“Next →”按钮,并在按钮不存在时停止:
while sb.is_element_present(".next"):
# Scraping logic...
# Visit the next page
sb.click(".next a")这里用到了 SeleniumBase 提供的 is_element_present() 方法来判断按钮是否存在。
很好!现在 SeleniumBase 爬虫将遍历整站。
步骤 #8:导出所爬取的数据
最后,将保存在 quotes 数组中的数据导出为 CSV 文件:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Flatten the quote objects for CSV writing
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
别忘了在脚本开头导入 Python 标准库的 csv:
import csv步骤 #9:整合所有代码
现在,您的 script.py 文件应包含如下代码:
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# Connect to the target page
sb.open("https://quotes.toscrape.com/")
# Where to store the scraped data
quotes = []
# Iterate over all quote pages
while sb.is_element_present(".next"):
# Select all quote elements on the page
quote_elements = sb.find_elements(".quote")
# Iterate over them and scrape data for each quote element
for quote_element in quote_elements:
# Data extraction logic
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Populate a new quote object with the scraped data
quote = {
"text": text,
"author": author,
"tags": tags
}
# Add it to the list of scraped quotes
quotes.append(quote)
# Visit the next page
sb.click(".next a")
# Export the scraped data to CSV
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Flatten the quote objects for CSV writing
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})使用以下命令在无头模式下运行 SeleniumBase 爬虫:
python3 script.py --headless数秒钟后,项目文件夹下会出现一个 quotes.csv 文件。
打开它,就可以看到:
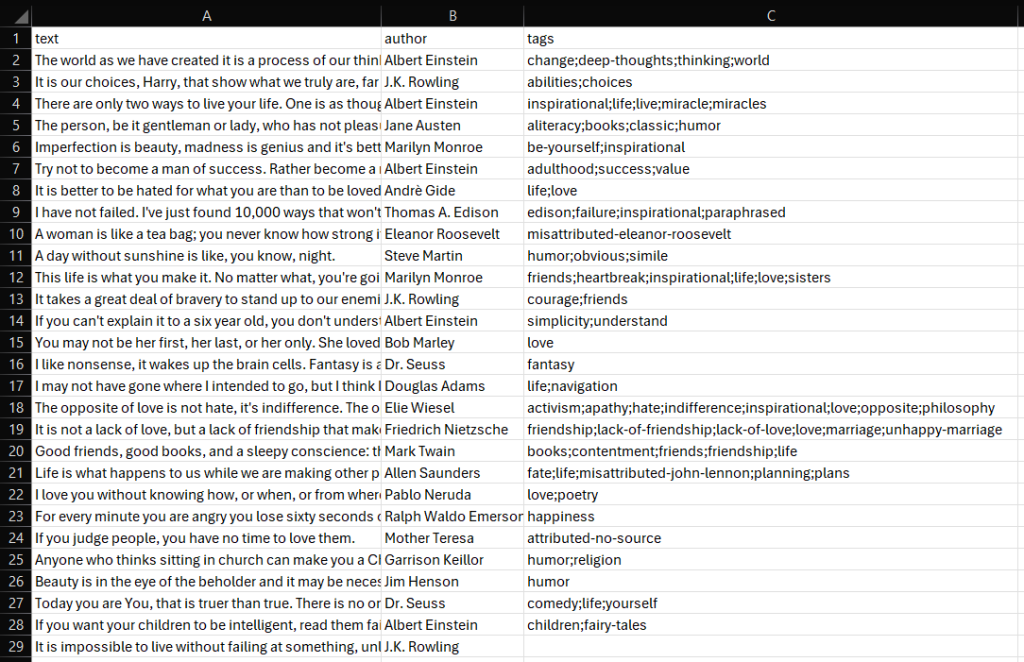
瞧!SeleniumBase 爬虫已经顺利完成。
高级 SeleniumBase 爬虫用例
现在您已经学到 SeleniumBase 的基础用法,可以进一步探索一些更复杂的场景。
自动化表单填写与提交
注意:Bright Data 不会在登录后进行爬取。
SeleniumBase 也允许模拟人工用户对页面元素进行操作。例如,假设您需要与如下登录表单交互:
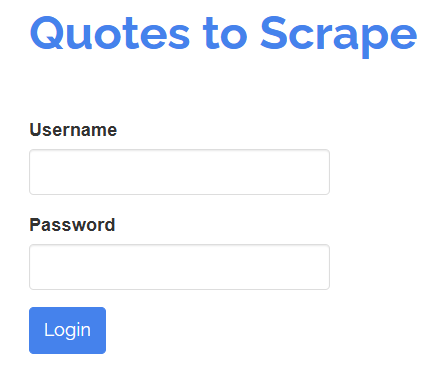
目标是在“Username”和“Password”输入框中填入信息,然后点击“Login”按钮提交表单。下面是使用 SeleniumBase 编写测试的示例:
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# Visit the target page
self.open("https://quotes.toscrape.com/login")
# Fill out the form
self.type("#username", "test")
self.type("#password", "test")
# Submit the form
self.click("input[type="submit"]")
# Verify you are on the right page
self.assert_text("Top Ten tags")以上示例更偏向于测试场景,因此继承了 BaseCase 类,这样就能编写 pytest 测试。
使用以下命令运行该测试:
pytest login.py您会看到浏览器打开、载入登录页面、填写表单并提交,然后检查页面上是否包含指定文本。
终端的输出类似:
login.py . [100%]
======================================== 1 passed in 11.20s ========================================= 绕过简单反机器人技术
很多网站会设置高级反爬虫措施,如 CAPTCHA 验证、请求频率限制、浏览器指纹检测等。如果想成功爬取而不被阻止,就必须绕过这些防护。
SeleniumBase 提供了一个名为 UC Mode 的功能(详见 Undetected-Chromedriver Mode),可以让爬虫看起来更像真人用户,从而避开一些反机器人检测服务,它们有时会直接屏蔽爬虫或触发 CAPTCHA。
UC Mode 基于 undetected-chromedriver,并进行了若干更新、修复与改进,例如:
- 自动切换 User-Agent,降低被检测的风险。
- 根据需要自动配置 Chromium 启动参数。
- 提供特殊的
uc_*()方法用于绕过 CAPTCHA。
下面演示如何在 SeleniumBase 中使用 UC Mode 来绕过反爬虫挑战。
以访问Scraping Course站点的简单反爬虫页面并处理 CAPTCHA 为例:
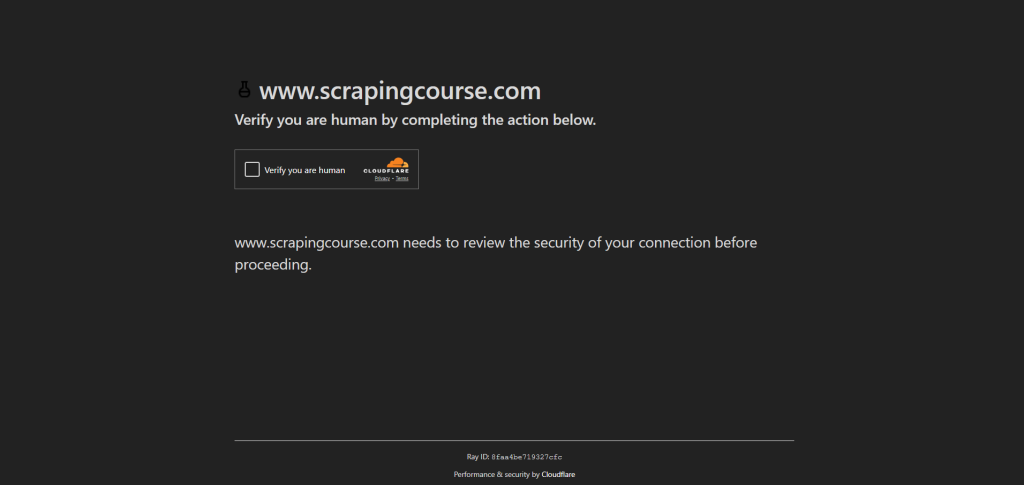
要绕过这些反爬虫检测并处理 CAPTCHA,请启用 UC Mode,并使用 uc_open_with_reconnect() 和 uc_gui_click_captcha():
from seleniumbase import SB
with SB(uc=True) as sb:
# Target page with anti-bot measures
url = "https://www.scrapingcourse.com/antibot-challenge"
# Open the URL using UC Mode with a reconnect time of 4 seconds to avoid initial detection
sb.uc_open_with_reconnect(url, reconnect_time=4)
# Attempt to bypass the CAPTCHA
sb.uc_gui_click_captcha()
# Take a screenshot of the page
sb.save_screenshot("screenshot.png")运行脚本后,注意 uc_gui_click_captcha() 依赖 PyAutoGUI,SeleniumBase 在首次使用时会为您自动安装:
PyAutoGUI required! Installing now...您会看到脚本自动控制鼠标点击“Verify you are human”复选框。screenshot.png 文件将出现于您的项目文件夹,画面看起来:
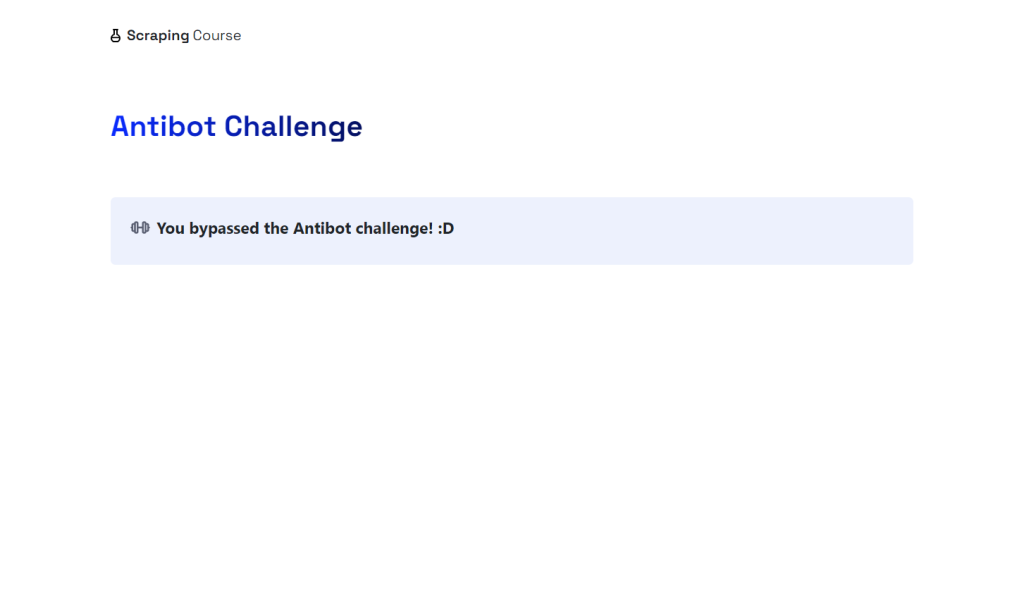
瞧!Cloudflare 验证已被绕过。
绕过高级反机器人技术
反机器人解决方案正变得愈发复杂,仅依靠 UC Mode 并不总是奏效。SeleniumBase 还提供了一个特殊的 CDP Mode(Chrome DevTools Protocol Mode)。
CDP Mode 在 UC Mode 上进行扩展,通过使用 CDP-Driver 来让爬虫看起来更加“类人化”。当普通的 UC Mode 在驱动被断开与浏览器的连接时无法进行 WebDriver 操作,CDP-Driver 仍可与浏览器交互,从而克服此局限。
CDP Mode 基于 python-cdp、trio-cdp 和 nodriver,专门用于应对一些真实网站上的高级反爬手段。下面是一个简单示例:
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# Target page with advanced anti-bot measures
url = "https://gitlab.com/users/sign_in"
# Visit the page in CDP Mode
sb.activate_cdp_mode(url)
# Handle the CAPTCHA
sb.uc_gui_click_captcha()
# Wait for 2 seconds for the page to reload and the driver to retake control
sb.sleep(2)
# Take a screenshot of the page
sb.save_screenshot("screenshot.png")脚本运行后,效果类似:
就是这样!您现在已经掌握了 SeleniumBase 爬虫的进阶技巧。
结论
在本文中,您了解了什么是 SeleniumBase、它提供的功能与方法,以及如何使用它进行网页爬虫。从基础用法开始,然后拓展到更复杂的场景。
虽然 UC Mode 和 CDP Mode 能够绕过某些反爬虫机制,但它们并非万能。
如果请求过多,网站仍有可能封锁您的 IP,或者使用更复杂的多步 CAPTCHA;此时,仅使用 SeleniumBase 也可能遇到瓶颈。更有效的方式是在使用 Selenium 等浏览器自动化工具的同时,结合云端、可高度扩展的专用爬虫浏览器——例如 Bright Data 的 Scraping Browser。
Scraping Browser 能完美配合 Playwright、Puppeteer、Selenium 等自动化工具,自动在每次请求中切换出口 IP,处理浏览器指纹,处理重试、验证码解决等等。轻松应对被封锁的风险,让您专注于核心数据采集流程。
立即注册并开始免费试用吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



