
某全球金融机构需要将来自网页的实时市场数据与机密的内部分析数据进行整合。它们的数据分别存放在本地数据仓库(用于敏感客户数据)与 Azure Data Lake(用于可扩展分析)中。本指南将教你如何通过 Bright Data 的 API 连接这两部分,实现安全、准实时的数据集成。
你将学习:
- 为什么金融机构需要混合数据架构
- 如何使用 Bright Data 以合规方式采集网页数据
- 如何在 Azure Data Lake 与本地数据仓库之间建立安全的双向同步
- 如何验证端到端的数据同步
- 如何在不迁移敏感数据的前提下进行统一分析
- 在 GitHub 中哪里可以找到示例配置与脚本
什么是混合数据集成,以及金融行业为什么需要它
金融机构必须遵守 GDPR、SOC 2、MiFID II、巴塞尔协议 III 等严格监管法规,这些法规会限制数据可以存放的位置。公共网页数据为实时市场情报提供支撑,而现有的内部数据集则支持长期建模与合规需求。传统的 ETL 系统 很少能够同时安全地整合这两类数据。
挑战:如何在不牺牲安全性与合规性的前提下,将外部市场数据与内部分析数据结合起来?
解决方案:Bright Data 通过 API 提供结构化、合规的网页数据,而 Azure 的混合基础设施则确保敏感数据留在本地。
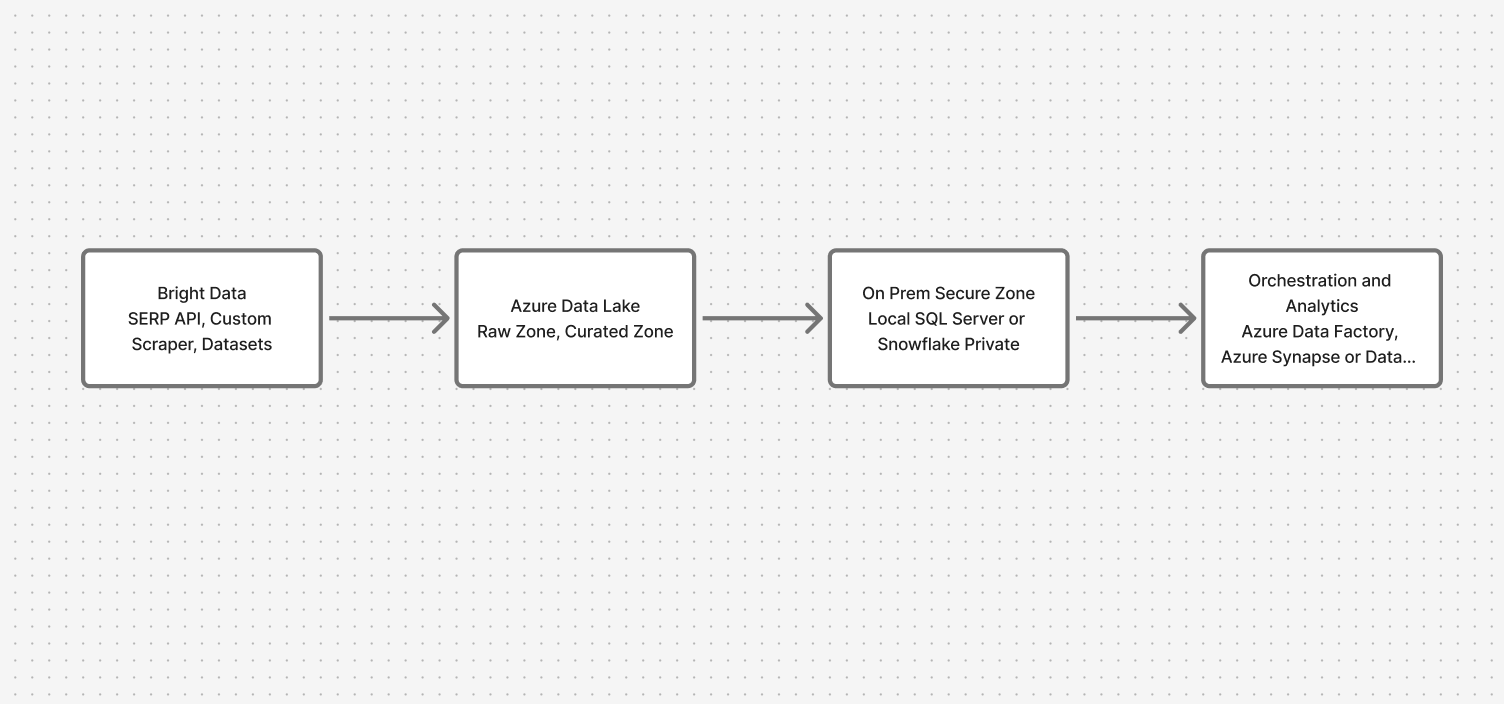
架构概览:安全地打通云端与本地
整个系统分为四个关键层次:
- 数据采集:Bright Data API(SERP、自定义爬虫、数据集)
- 云端落地区:Azure Data Lake(原始区与精炼区)
- 本地安全区:本地 SQL Server 或 Snowflake
- 编排与分析:带私有终结点的 Azure Data Factory,以及用于联邦查询的 Synapse/Databricks
这样既能让网页数据持续流入,又能保证敏感数据始终留在本地。

前置条件
在开始之前,你需要:
- 已开通且具有 API 访问权限的 Bright Data 账号
- 已启用 Data Lake、Data Factory 以及 Synapse 或 Databricks 的 Azure 订阅
- 可通过私有网络访问的本地数据库(ODBC 或 JDBC)
- 安全私有链路(ExpressRoute 或 Private Endpoint 私有终结点)
- 用于克隆示例仓库的 GitHub 账号
💡 提示:请先在非生产环境工作区中完成全部步骤。
分步实现
1. 使用 Bright Data 采集金融网页数据
我们将配置 Bright Data 的自定义爬虫(Custom Scraper),以提取股票价格、监管文件以及财经新闻。爬虫输出的结果是适合分析的 结构化 JSON。
数据示例如下:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
简化配置:scraper_config.yaml 定义了抓取什么、以及抓取频率。它会定位金融站点,抽取特定数据点,并设置按小时调度及 webhook 通知。
这种方式确保你以零人工干预的方式持续获得干净、结构化的数据。
# scraper_config.yaml
name: financial_data_aggregator
description: >
Collects real-time stock prices, SEC filings, and financial news headlines
for hybrid cloud integration.
targets:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
selectors:
- name: symbol
type: text
selector: "h1[data-testid='quote-header'] span"
- name: price
type: text
selector: "fin-streamer[data-field='regularMarketPrice']"
- name: headline
type: text
selector: "article h3 a"
- name: filing_type
type: text
selector: "td[class*='filetype']"
- name: filing_date
type: text
selector: "td[class*='filedate']"
- name: filing_url
type: link
selector: "td[class*='filedesc'] a"
pagination:
type: next-link
selector: "a[aria-label='Next']"
output:
format: json
file_name: financial_data.json
schedule:
frequency: hourly
timezone: UTC
webhook: "https://<your-webhook-endpoint>/brightdata/ingest"
notifications:
email_on_success: [email protected]
email_on_failure: [email protected]2. 将数据安全写入 Azure Data Lake
接下来我们使用 Azure Function,将采集到的数据路由至 Azure Data Lake。这个函数扮演安全网关角色:
- 通过 HTTPS POST 接收来自 Bright Data 的 JSON 数据
- 使用托管身份(Managed Identity)进行身份验证(无需管理密钥)
- 按数据源与时间戳组织文件,便于追踪
- 为合规追踪添加元数据标签
结果:你的市场数据被写入按分区组织的文件夹中,便于管理与查询。
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# Environment variables
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # e.g., "https://myaccount.blob.core.windows.net"
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# Initialize blob client with managed identity
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Parse incoming JSON from Bright Data
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# Prepare target path
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# Upload JSON file
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"Data from {source} saved to {blob_path}",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""Simple helper to identify source name."""
# Look for field 'source' in the first element of array
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. 将非敏感子集同步到本地环境
并非所有数据都需要在环境间流动。我们使用 Azure Data Factory 作为智能过滤器,仅选择适合同步到本地数据仓库的安全数据子集。
整个流程在实践中的工作方式如下:
流水线首先扫描 Data Lake 中新落地的文件,然后应用智能过滤逻辑,只包含公共、非敏感数据——例如市场价格与股票代码,而不是客户信息或内部专有分析。
使该流程安全可靠的关键点:
私有终结点在 Azure 与本地基础设施之间创建一条专用通道,完全绕过公共互联网。这既消除了暴露于外部威胁的风险,又保证了稳定性能。
结合水印跟踪的增量加载机制意味着系统只会迁移新增或变更记录。再叠加自动架构验证,既避免重复数据,又能保持两个环境的严格对齐。
下面来看这在实际 流水线代码 中是如何实现的:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"name": "Filter_PublicData",
"type": "Filter",
"dependsOn": [
{
"activity": "Get_Metadata",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
"preCopyScript": "IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));"
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Log_Load_Status",
"type": "StoredProcedure",
"dependsOn": [
{
"activity": "Copy_To_OnPrem_SQL",
"dependencyConditions": ["Succeeded", "Failed"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
"linkedServiceName": {
"referenceName": "OnPrem_SQL_LinkedService",
"type": "LinkedServiceReference"
}
}
],
"annotations": ["HybridIntegrationDemo"]
}
}关键组件分解:
- Lookup_NewFiles 是流水线的“哨兵”,用于识别 Data Lake 中需要处理的新数据,避免重复处理旧文件。
- Get_Metadata 对这些文件做进一步检查,包括大小、修改时间与结构,确保在继续处理前文件是完整、有效的。
- Filter_PublicData 是安全控制的核心步骤。利用之前嵌入的分类元数据,它会自动过滤掉任何敏感数据,仅让公共市场信息继续下游处理。
- Copy_To_OnPrem_SQL 负责实际传输,同时具备多重保护。preCopyScript 确保目标表存在且架构正确,而私有终结点则保证传输过程始终在安全网络中进行。
- Log_Load_Status 提供关键可观测性——每次同步操作都会记录在本地数据库中。这既满足合规部门对审计轨迹的要求,也让运维团队可以即时了解流水线健康状况。
真正的价值在于:本地团队可以获得所需的市场背景与实时情报,而敏感客户数据与专有模型则完全保留在安全位置。这是敏捷性与安全性的最佳平衡。
4. 启用双向同步校验
数据一致性对于可靠的业务决策至关重要。你需要确信云端分析与本地报表展示的是同一组数据。我们构建了持续运行的自动化 数据校验 机制,为这一点提供保障。
验证流程如下:
- 行数对比是第一层预警机制。它能快速识别传输失败或加载不完整等重大问题。如果云端与本地的记录数不一致,你可以立刻意识到需要排查。
- 哈希校验和为你的数据创建“数字指纹”。无需人工比对成千上万条记录,而是为每个数据集生成加密哈希。哪怕只有一个字符变化,哈希值也会完全不同,从而瞬间发现数据损坏或部分传输的问题。
- 近乎实时的同步意味着校验每隔几分钟就会运行一次,而不是等到夜间批处理任务结束才发现问题。系统会在分钟级别内捕获异常,保证数据始终新鲜可靠。
- 自动告警让数据问题立即转化为可执行任务。当系统检测到不一致时,会通过 Slack、邮件或现有监控工具发送通知,从而在影响业务决策之前完成修复。
实际代码示例如下:
def validate_sync():
# Compare record counts between systems
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"Record count mismatch: Cloud {cloud_count} vs On-prem {onprem_count}")
return False
# Generate checksums for data integrity validation
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"Data integrity failure: Checksums don't match")
return False
# Verify sync timeliness
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"Sync delay detected: Last sync {last_sync_time}")
return False
return True5. 在不迁移敏感数据的前提下构建统一分析
关键优势在于:你可以通过“虚拟关联”的方式将云端与本地数据联合分析,而不必迁移敏感信息。
示例查询:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapse 通过外部表(external tables)指向你的本地数据仓库,而 Databricks 则可通过带有基于角色访问控制(RBAC)的 JDBC 连接来访问。
合规与审计轨迹最佳实践
要满足审计与法律要求,需要一套系统化的数据追踪与安全机制。下面是我们构建合规框架的方式:
- 完整的数据迁移日志:所有数据传输都会记录在 Azure Monitor 与本地 SIEM 中,形成一份不可篡改的“数据从哪来、到哪去、何时移动”的记录,为审计提供完整可追溯性。
- 清晰的数据来源标识:使用 Bright Data 源 ID 作为“数字指纹”,并在数据生命周期中一直保留,从而可以将任意分析结果回溯到最初的数据采集来源。
- 自动化血缘追踪:通过 Azure Purview 绘制数据在流水线中如何被转换,自动记录哪些原始数据源参与生成了特定报表,以及过程中应用过哪些转换。
- 集中式访问控制:将 Azure AD 与本地 LDAP 同步,把现有安全策略统一应用于云端与本地,从而在两个环境中实现一致的权限管理。
最终你将获得自动化合规报告、集中式安全管理,以及一套既保护数据又不会拖慢团队效率的框架。
常见挑战与 Bright Data 的助力
| 挑战 | Bright Data 功能 |
|---|---|
| IP 封锁或请求频率限制 | 住宅代理与 ISP 代理(1.5 亿+ IP) |
| CAPTCHA 或登录门槛 | Web Unlocker 自动处理验证 |
| 重度 JavaScript 网站 | Scraping Browser(基于 Playwright 的渲染) |
| 站点频繁变更 | 托管数据服务(Managed Data Services),带 AI 自动修复 |
结论与下一步
金融机构可以通过将 Bright Data 的 API 与 Azure 混合基础设施结合使用,在安全的前提下整合公共数据与私有数据。
最终得到的是一套既合规又兼具敏捷与管控能力的系统。
💡 如果你更倾向于完全托管的数据访问方式,可以使用 Bright Data 托管数据服务(Managed Data Services),由我们负责端到端的数据采集与交付。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





