

在这篇博客文章中,你将了解:
- 为什么 TensorFlow 是通过机器学习进行数据分析的理想工具。
- 应当依赖哪些解决方案来收集能够为业务提供有价值洞察的高质量数据。
- 如何利用 TensorFlow 对通过 Bright Data 获取的亚马逊商品评论进行情感分析。
让我们开始吧!
为什么要使用 TensorFlow 与机器学习来分析数据
数据之所以有价值,是因为它能帮助你获得洞察。对企业而言尤为如此——企业利用数据做决策、调整策略并优化结果。常见目标包括提升客户满意度以及优化整体营销策略表现。
在进行数据分析时,TensorFlow 是最受欢迎的开源库之一。它为机器学习和人工智能系统提供动力,支持广泛的任务场景。
在本文中,我们将特别使用 TensorFlow 对商品评论进行情感分析。同时,同样的技术也可以用于许多其他用例,例如用户反馈分析、推荐系统、预测建模等。
如何从你的业务中获取数据
无论你的机器学习或人工智能流程多么先进,所有数据分析师都知道,“更多数据往往胜过更好的算法”。简而言之,获得有意义洞察的关键在于数据的质量和数量。
但如何获得大量优质数据呢?数据获取并不容易,因此依赖像 Bright Data 这样的可信数据提供商非常重要。
Bright Data 为你提供了多种数据解决方案,包括:
- Web Scraper API:通过网络爬虫,以编程方式从数十个热门站点获取结构化网页数据。
- Dataset Marketplace:来自 100+ 网站、包含数十亿条记录的新鲜、开箱即用数据集。
- 托管式数据采集服务:企业级全托管数据采集服务,让你无需操心开发与维护即可获取数据与洞察。
这些产品适用于研究人员、中小企业(SMB)和大型企业。具体而言,它们可以用于采集公开网页数据,以支撑机器学习工作流、AI 训练、智能体开发,以及众多其他场景。
如何对通过 Bright Data 获取的亚马逊商品评论进行情感分析
在接下来的分步章节中,你将使用 TensorFlow 构建一个真实世界的数据分析流程。我们将围绕一个典型用例——对商品评论进行情感分析——展开。
假设你是一家在亚马逊上销售多款产品的企业。为了提升客户满意度,你需要一个流程,定期监控用户对每款产品留下的评论,并执行情感分析,以了解哪些方面做得好、哪些需要改进。
在这个示例中,我们将聚焦于下面这款亚马逊产品:
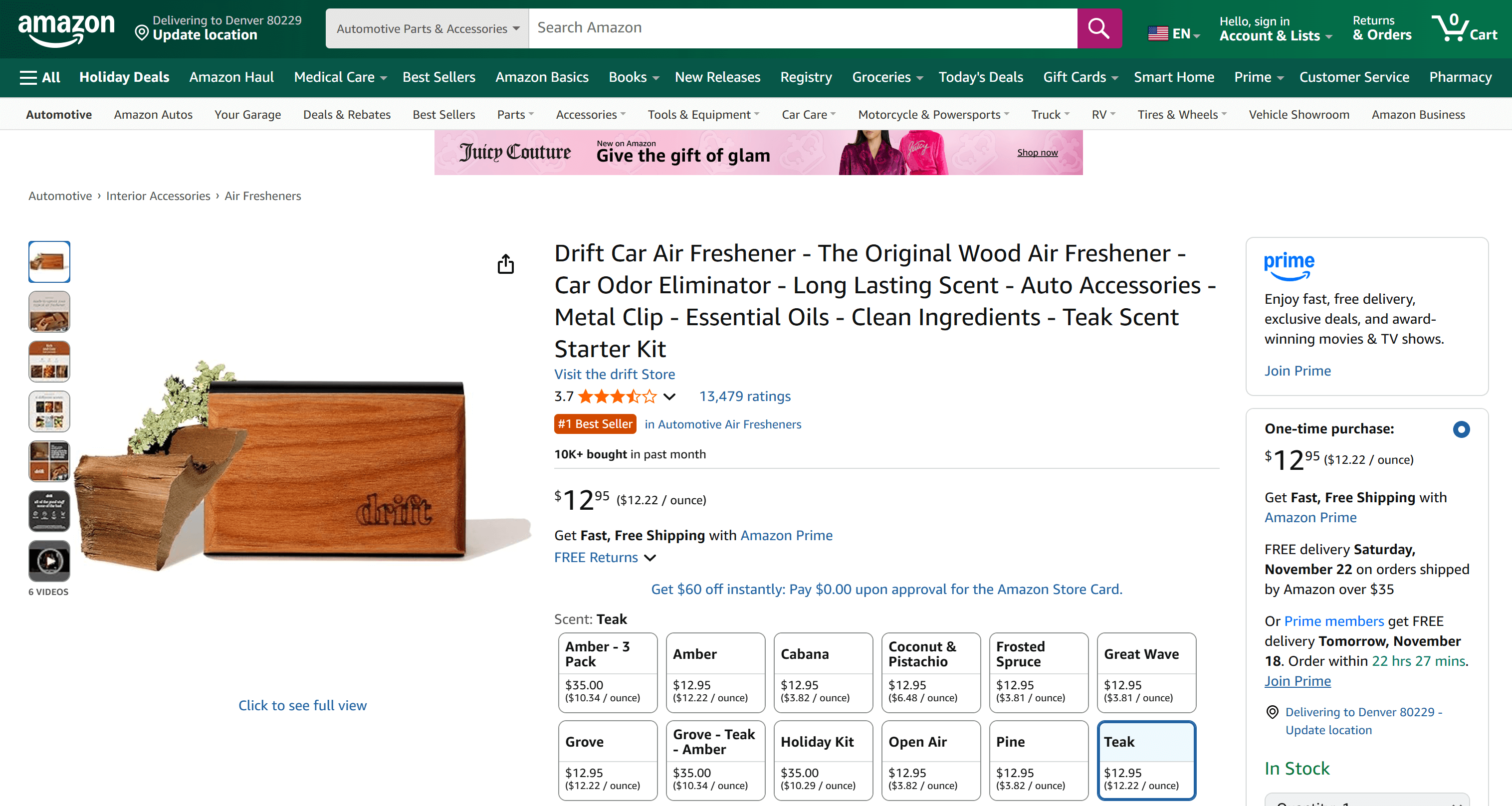
注意:你可以将该工作流扩展到多款亚马逊产品,因为 Bright Data 的 Amazon Reviews Scraper 支持在无限扩展的前提下抓取多款商品的评论。
这是一个很好的例子,因为该商品拥有大量评论,并且在 1–5 星之间分布较为均衡:
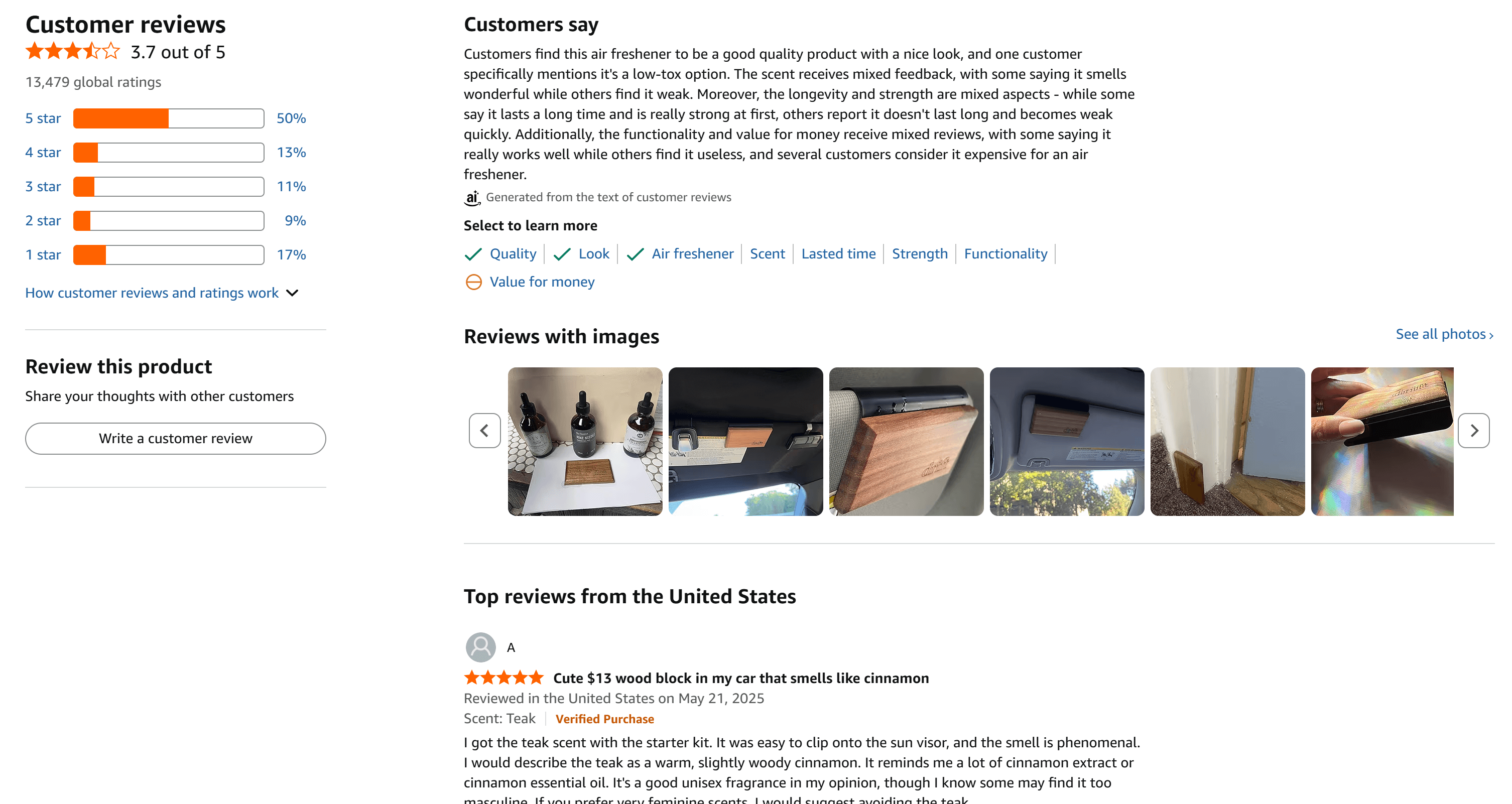
按照下述步骤构建一个企业级情感分析流程。该商品的评论将通过 Bright Data 获取,然后在 Python 中使用 TensorFlow 的机器学习工作流进行分析。
先决条件
要跟随本教程,请确保你已经具备:
- 本地安装好 Python 3.9+。
- 一个带有 API 密钥的Bright Data 账号。
如果你还没有 Bright Data 账号,也不用担心,接下来的步骤会引导你完成设置。
熟悉 Universal Sentence Encoder 模型、向量嵌入的工作原理,以及 Keras 中带全连接层的 Sequential 模型将有助于你更深入理解本教程中的 TensorFlow 情感分析逻辑。
步骤一:创建 JupyterLab 项目
由于本次 TensorFlow 机器学习流程也将涉及图表和数据可视化,因此很适合使用 JupyterLab 作为开发环境。之后,代码可以很容易迁移到生产级 ML 流水线上。
首先,创建一个项目文件夹,并进入该目录:
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysis接着,在该目录中初始化一个虚拟环境:
python -m venv .venv现在来激活虚拟环境。在 macOS/Linux 中运行:
source .venv/bin/activate在 Windows 中运行:
.venvScriptsactivate在已激活的环境中,使用 jupyterlab 包安装 JupyterLab:
pip install jupyterlab然后启动 JupyterLab:
jupyter lab你将看到 JupyterLab 界面:
在 “Notebook” 区域下点击 “Python 3 (ipykernel)” 按钮创建新笔记本:
给你的笔记本起一个名字并保存。
完成!现在你已经拥有一个非常适合使用 TensorFlow 开发机器学习数据分析工作流的 Python 环境。
步骤二:安装依赖库
添加一段代码单元,并通过以下命令安装所需库:
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requests运行该单元以安装本次实现所需的全部依赖:
tensorflow:用于构建和训练机器学习模型。tensorflow-hub:用于加载预训练机器学习模型。scikit-learn:用于数据预处理、训练/测试集划分、评估指标和类别权重计算。pandas:用于处理表格数据和进行聚合分析。numpy:用于数值计算和数组处理。matplotlib:用于绘制图表和可视化结果。requests:用于发起 HTTP 请求并与 Bright Data Scraper API 交互。
然后,再添加一个代码单元以导入并配置所有依赖库:
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow import keras
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.utils.class_weight import compute_class_weight
from IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)太棒了!从现在起,你的所有代码单元都可以直接用于 Bright Data 的数据获取以及基于 TensorFlow 的分析工作流。
步骤三:开始使用 Bright Data Amazon Reviews Scraper
在编写抓取亚马逊评论的代码之前,先花一点时间完成 Bright Data 账号的配置,并熟悉所需的数据抓取解决方案。
在本教程中,我们将使用 Bright Data Amazon Reviews API,它可以让你以编程方式抓取指定商品的最新评论数据。如果你希望持续监控自家商品的评论,这种方式非常理想。
对于更通用的场景,Bright Data 还提供了一个现成的 “Amazon Reviews” 数据集,包含超过 2860 万条评论: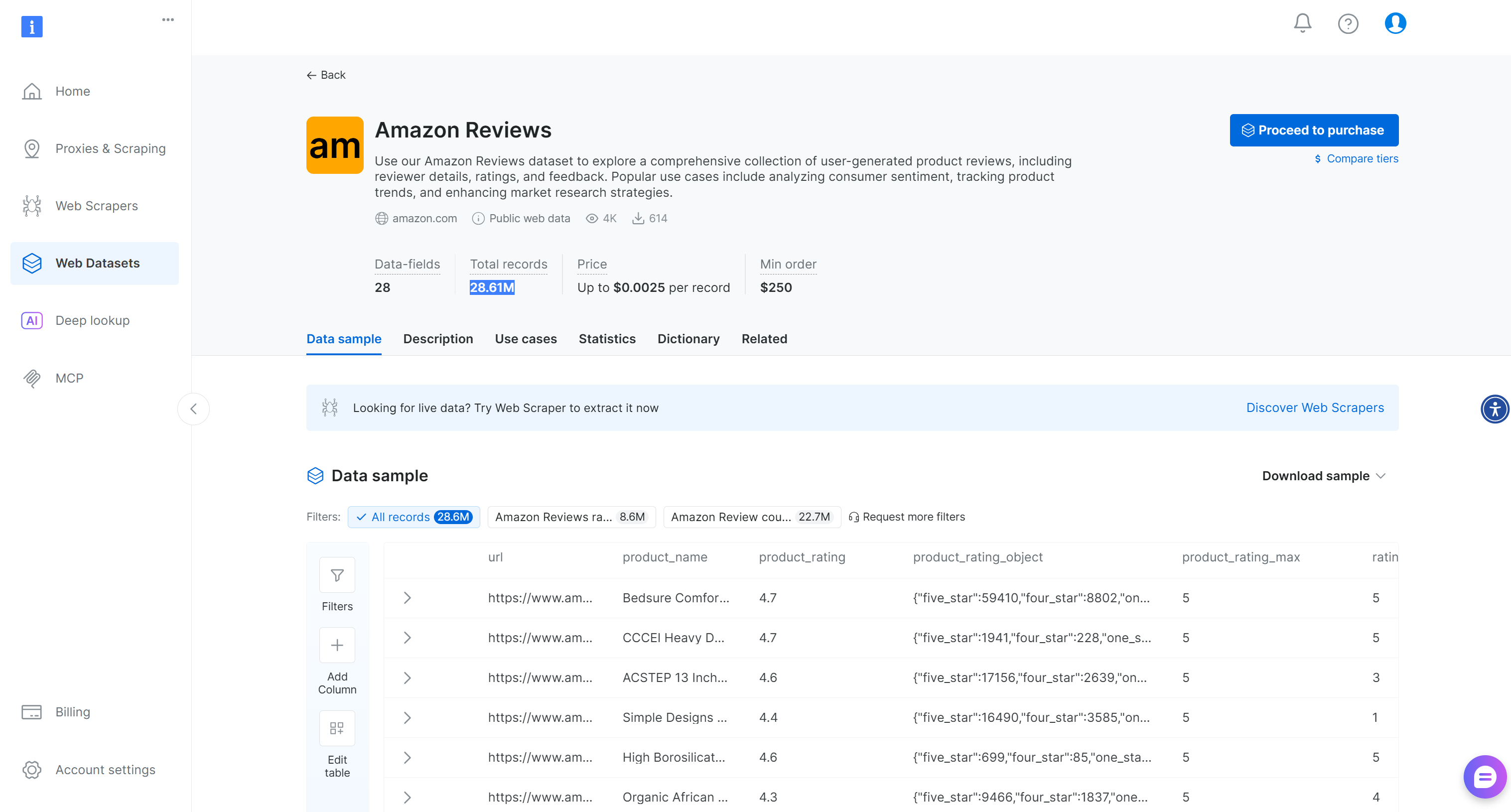
如果你还没有 Bright Data 账号,可以注册一个。如果已有账号,则登录并进入你账号中的 “Web Scrapers Library” 页面:
搜索 “amazon”,然后选择 “Amazon Reviews – collect by URL” 爬虫:
在该页面,你可以查看如何生成可集成的代码,或直接通过无代码 Web 应用试用该爬虫。
选择 “Scraper API” 选项,你将来到如下页面: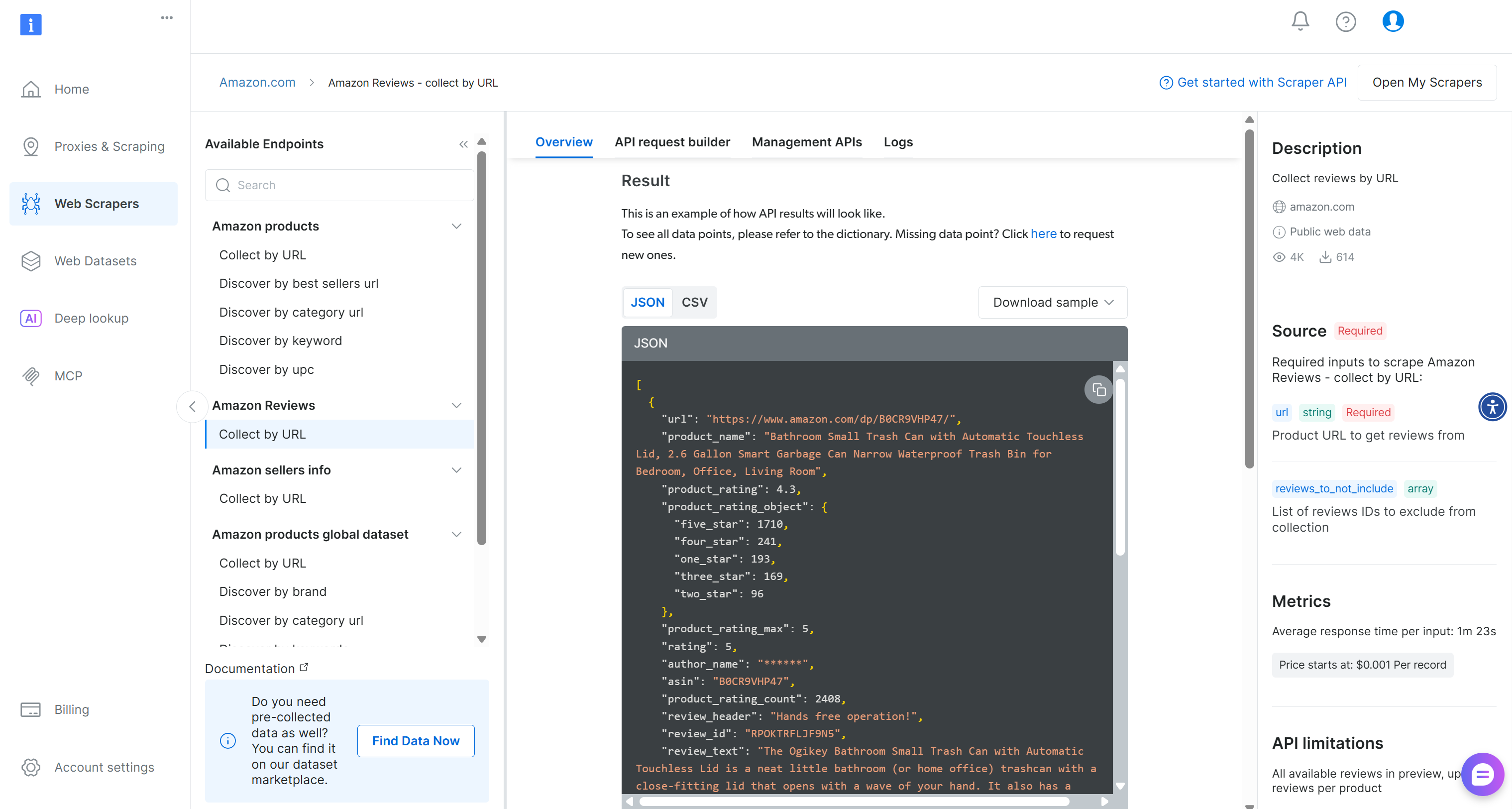
在这里,你可以查看支持的输入参数和输出格式。特别是,该数据集返回一组亚马逊评论,其 ID 为 gd_le8e811kzy4ggddlq。
要通过 API 调用该爬虫,你必须使用 Bright Data API 密钥来对请求进行身份验证。如果你还没有密钥,请参照官方指南生成一个。请妥善保存,因为稍后会用到。
很好!现在你已准备好使用 Bright Data 的 Amazon Reviews 爬虫来获取商品评论数据进行分析。
步骤四:获取亚马逊商品评论数据
在笔记本中新建一个代码单元,并粘贴以下代码:
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
def trigger_snapshot(amazon_product_url):
# Trigger the Bright Data Web Scraper API for a given Amazon product URL
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # ID of the "Amazon Reviews - collect by URL" scraper
"include_errors": "true",
}
# Format input data for the API call
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # Authenticate the request
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Snapshot ID: {snapshot_id}")
return snapshot_id
else:
print(f"Request failed! Status code: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# Poll the Bright Data Scraper API until the snapshot is ready, then save it
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.text
# Write the snapshot to a file
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(f"Snapshot not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Status code: {response.status_code}")
print(response.text)
break
# Amazon product URL to retrieve reviews from
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# Trigger snapshot and download reviews
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")将 <YOUR_BRIGHT_DATA_API_KEY> 占位符替换为你之前生成的实际 Bright Data API 密钥。
上述代码将:
- 通过
datasets/v3/trigger触发评论爬虫,这会在 Bright Data 云端使用 Amazon Reviews 爬虫启动一项抓取任务。 - 使用
datasets/v3/snapshot/{snapshot_id}轮询生成的数据快照,等待 Bright Data 完成评论抓取。 - 将最终数据导出为 CSV(因为指定了
format="csv"),并以product-reviews.csv保存到本地。
这正是 Web Scraper API 工作流的运作方式。更多详情请参阅 Bright Data 官方文档。
当你运行该代码单元时,应该会看到类似如下的输出:
随后,你会在项目文件夹中看到一个 product-reviews.csv 文件。打开后可以看到已抓取的结构化评论数据:
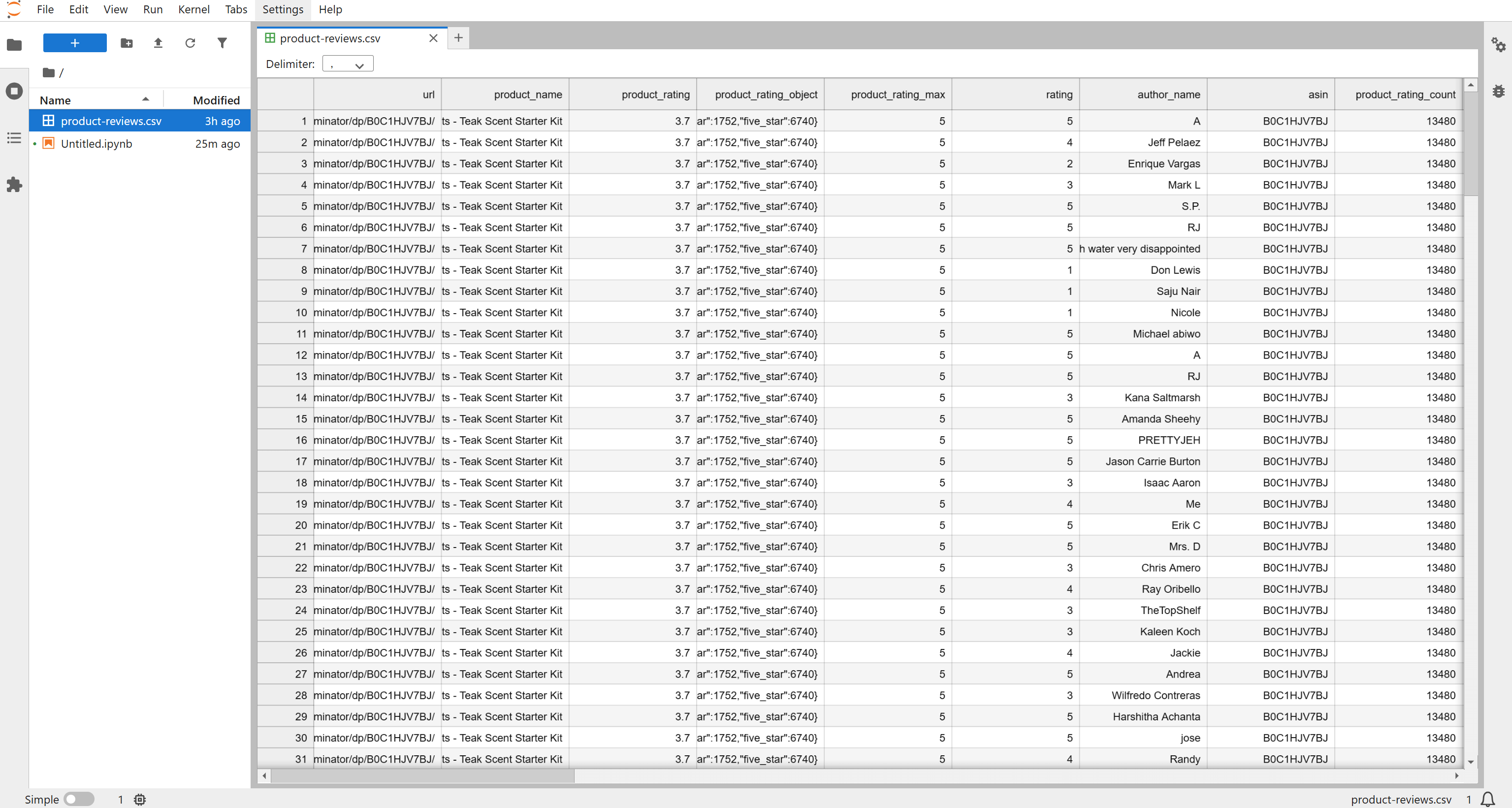
默认情况下,该爬虫会返回最近约 200 条评论,但你可以通过调整 API 输入参数获取更多数据。对于本教程来说,这 196 条评论已经足够用来完成情感分析流程。
很棒!你现在已经拥有可供 TensorFlow 分析的最新亚马逊商品评论数据。
步骤五:探索已抓取的数据
首先,从 product-reviews.csv 文件中加载抓取到的评论数据:
# Load product reviews from the CSV file generated via Bright Data
df = pd.read_csv("product-reviews.csv")
# Convert review posted dates to datetime
df["date"] = pd.to_datetime(df["review_posted_date"])
# Drop reviews with missing text
df = df.dropna(subset=["review_text"])
# Sort reviews by publication date (ascending)
df = df.sort_values(by="date", ascending=True)
print(f"Loaded {len(df)} reviews.")运行该单元,你将看到加载的评论总数:
Loaded 196 reviews.接下来,分析评分分布:
print(df["rating"].value_counts())你应能看到类似输出:
rating
1 74
2 31
3 16
4 12
5 63如上所示,评论在 1–5 星之间分布相对均衡。为了更好地可视化该分布,可以使用 Matplotlib 绘制柱状图:
# Compute the number of reviews per rating (1–5 stars)
rating_counts = df["rating"].value_counts().sort_index()
# Plot the rating distribution as a bar chart
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("Rating Distribution (1–5 stars)")
plt.xlabel("Stars")
plt.ylabel("Count")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()你将得到类似如下的图表: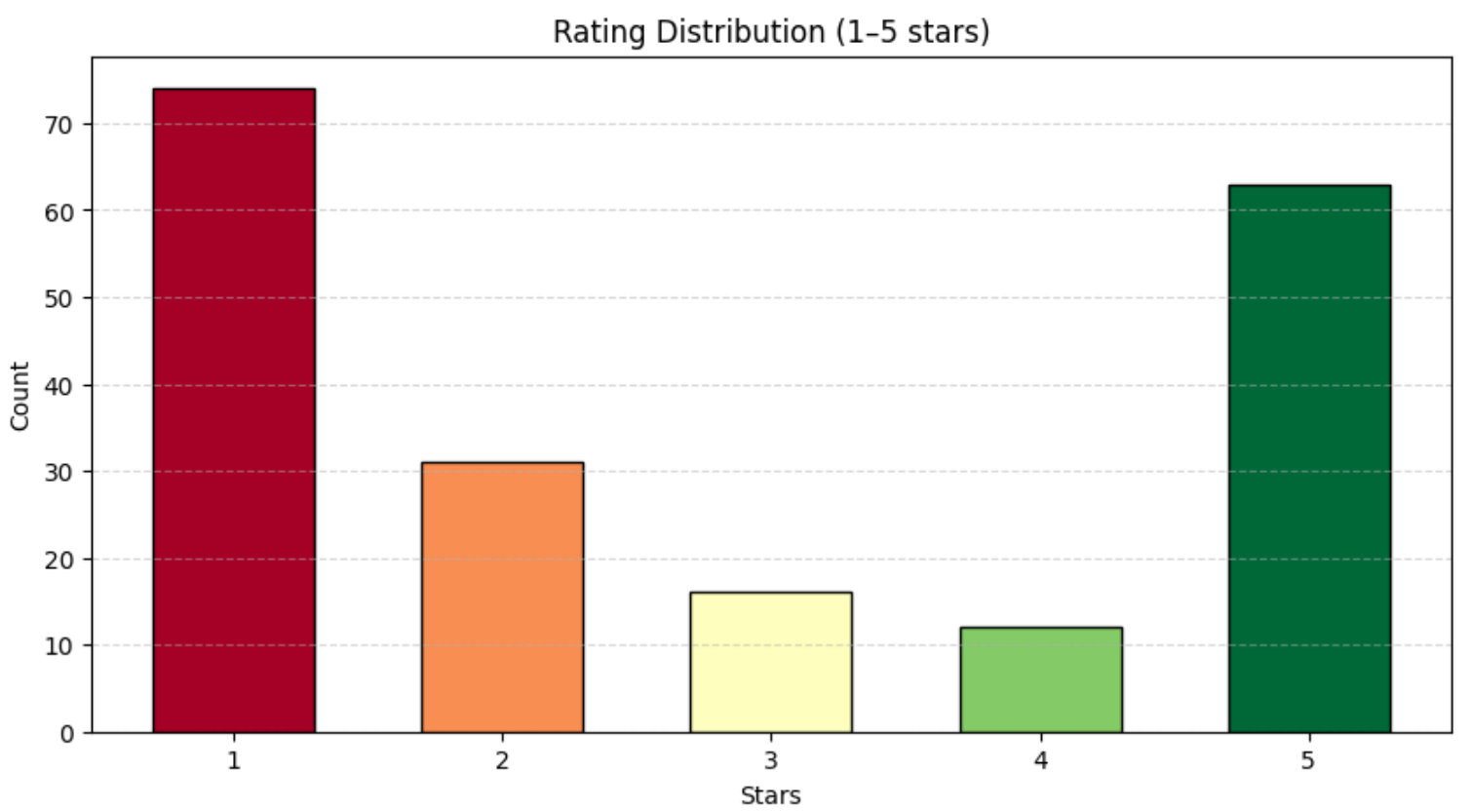
很好!现在你对刚刚获取的亚马逊评论数据有了一个清晰的整体认识。在进入模型训练和情感分析之前,这样的基础了解非常重要。
步骤六:为评论打上情感分析标签
在使用机器学习之前,先对情感分类任务做一点简化:忽略 3 星评论。因为这类评论通常比较中性,难以明确归类为正面或负面。
如果保留 3 星评论,模型就需要学习一个三分类问题(正面 / 中性 / 负面),这需要更多数据和更复杂的建模。相反,我们将任务转换为二元情感分类:
- 4–5 星评论视为“正面”(
1); - 1–2 星评论视为“负面”(
0)。
基于此,在 TensorFlow 中实现如下情感分析逻辑:
# Drop neutral reviews (rating=3) for binary sentiment clarity
df = df[df["rating"] != 3]
# Map ratings to sentiment: 1=positive (>=4), 0=negative (<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# Load Universal Sentence Encoder embeddings
print("Loading Universal Sentence Encoder embeddings...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # fixed float32
y = df["sentiment_label"].values
# Split dataset into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# Compute class weights to handle class imbalance
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# Build a simple dense classifier with Input layer first
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# Force model to build to avoid retracing
_ = model(X_emb[:1])
# Train the model
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# Predict on validation set and evaluate
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("nSentiment Model Classification Report:")
print(classification_report(y_val, y_pred))
# Predict on full dataset and save sentiment scores
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()
# 在完整数据集上进行预测并保存情感分数
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()这段代码使用了 Universal Sentence Encoder 将每条评论转换为语义向量。如果你对该模型不熟悉:Universal Sentence Encoder 是 Google 提供的一个模型,它将文本映射到 512 维的嵌入向量,可用于文本分类、语义相似度等自然语言处理任务。
这些嵌入捕捉了评论中表达的语气、情感和意图等信息。随后,Keras 的 Sequential 模型通过一系列全连接(Dense)层来学习区分正面和负面情感的模式。模型输出的是一个概率值,其中:
- 接近
1.0的值表示正向情感; - 接近
0.0的值表示负向情感。
模型为每条评论分配一个这样的得分。验证集上的分类报告如下:
Sentiment Model Classification Report:
precision recall f1-score support
0 0.91 0.95 0.93 21
1 0.93 0.87 0.90 15
accuracy 0.92 36
macro avg 0.92 0.91 0.91 36
weighted avg 0.92 0.92 0.92 36这表明:
- 模型在未见过的验证数据上达到了 92% 的准确率。
- 正负两类的精确率和召回率都表现稳定、较高。
- 训练集与验证集准确率相近,说明模型并未出现明显过拟合。
为了更好地可视化训练过程,可以添加如下图表:
plt.plot(history.history["accuracy"], label="Train Accuracy")
plt.plot(history.history["val_accuracy"], label="Validation Accuracy")
plt.title("Sentiment Model Training Performance")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()该图将展示整个训练过程: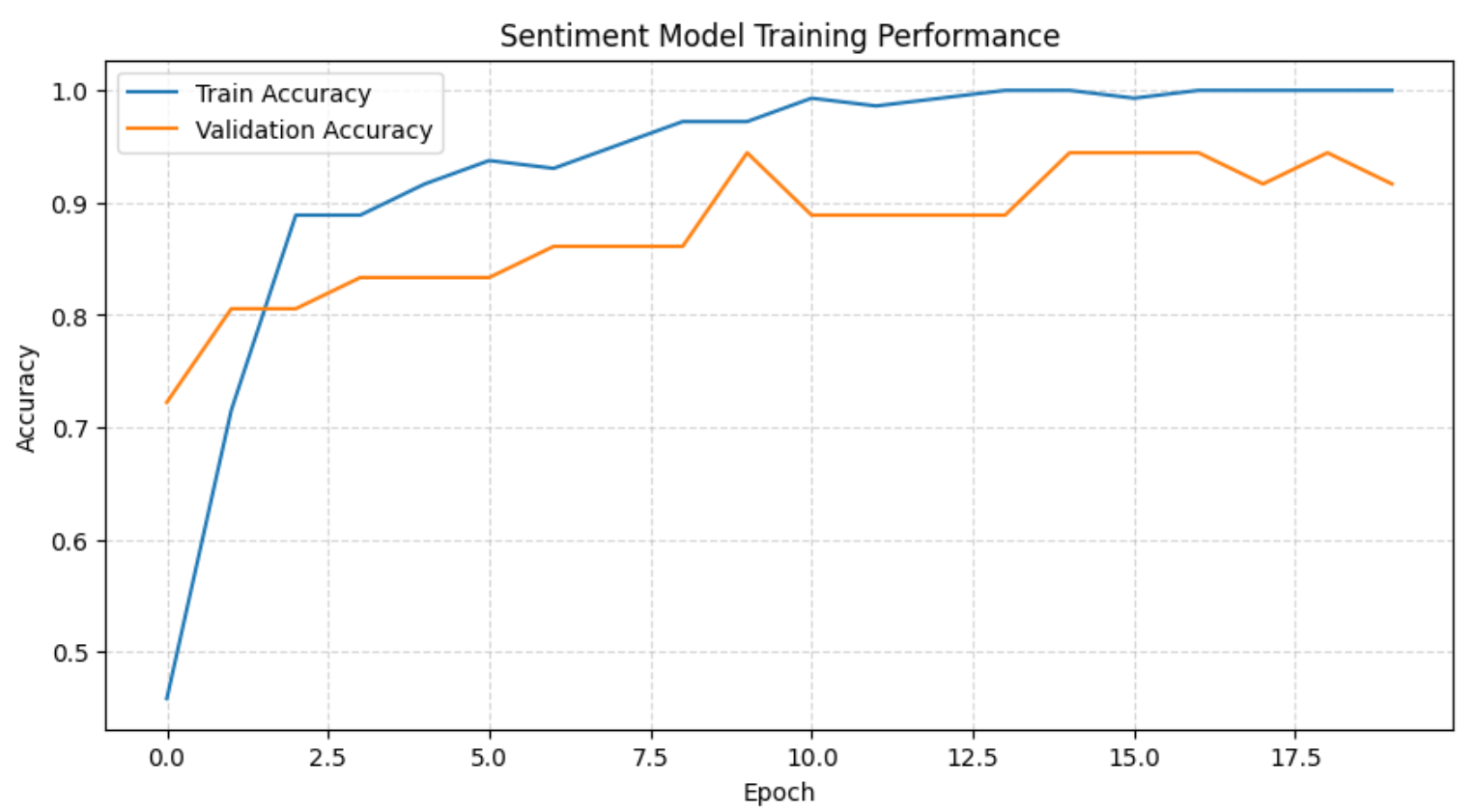
从图中以及训练日志可以看出,模型在前几个 epoch 就快速学到了情感边界,此后稳定在较高的验证准确率。随着训练推进,训练集准确率接近 100%,验证集准确率始终保持较高水平,说明在当前数据规模下只存在轻微且可接受的过拟合。
最后,对预测的情感概率做一个可视化:
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("Predicted Sentiment Score Distribution")
plt.xlabel("Sentiment Score")
plt.ylabel("Count")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()结果如下所示: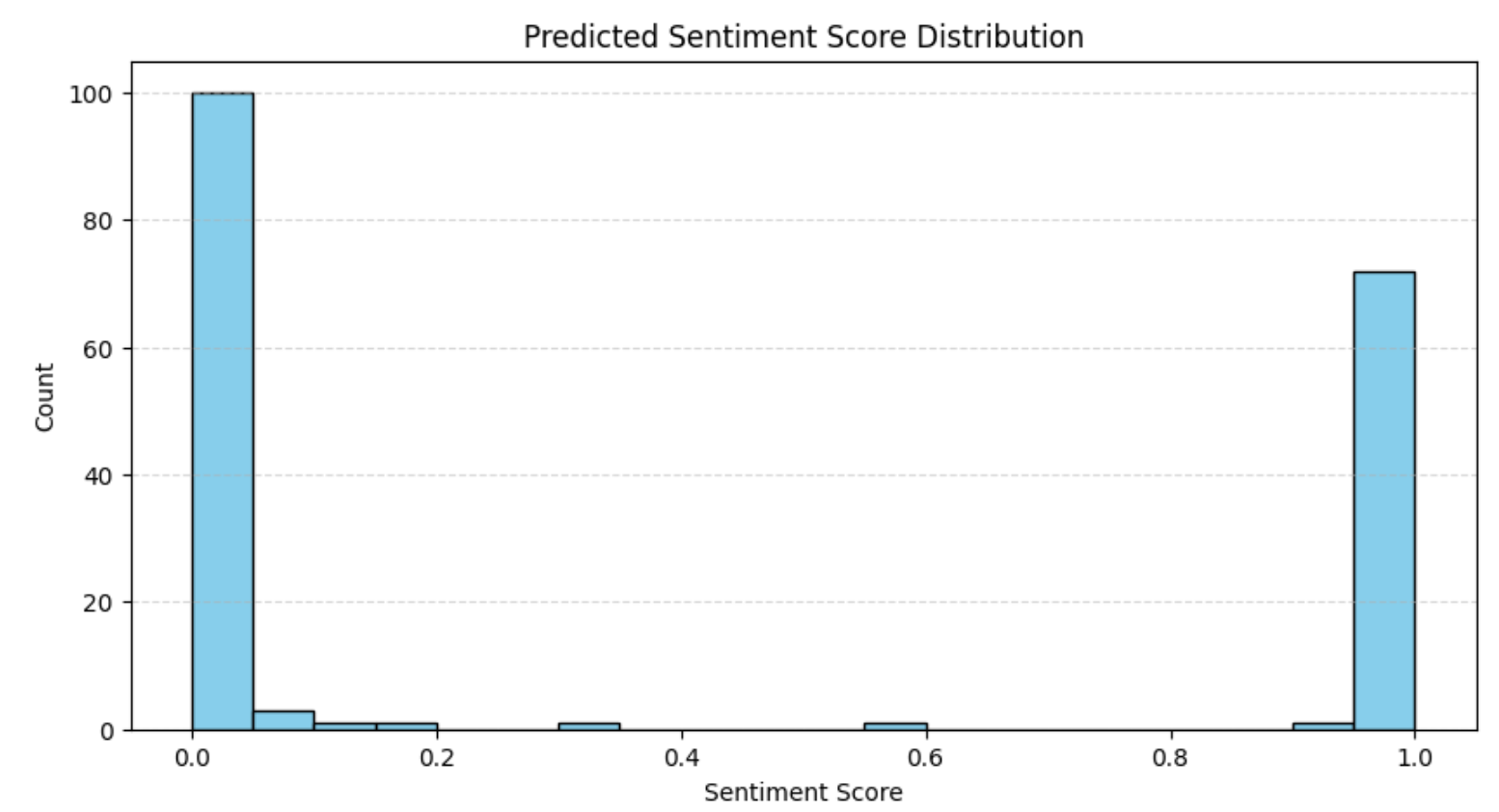
该分布与之前的评分分析相一致:大多数评论要么非常正面,要么非常负面。在电商平台上,这种“极化”评价模式很常见。
太好了!情感分析到这里就完成了。
步骤七:研究情感随时间的变化
现在,每条评论都拥有了一个情感得分,我们可以来可视化过去一年中客户情感的变化趋势。下面通过对每日平均情感值进行 7 天滚动平均,来平滑掉日常波动:
# Prepare daily average sentiment
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# Filter to last year
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# Compute 7-day rolling trend
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# Set one x-axis label per month
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # Month Start
)
# Plot daily sentiment and rolling trend
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="Daily Sentiment")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="7-Day Rolling Trend")
# Set x-axis labels
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("Daily Average Sentiment (Last Year) + Trend")
plt.xlabel("Date")
plt.ylabel("Sentiment Score")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()这将生成如下“情感随时间变化”的图表: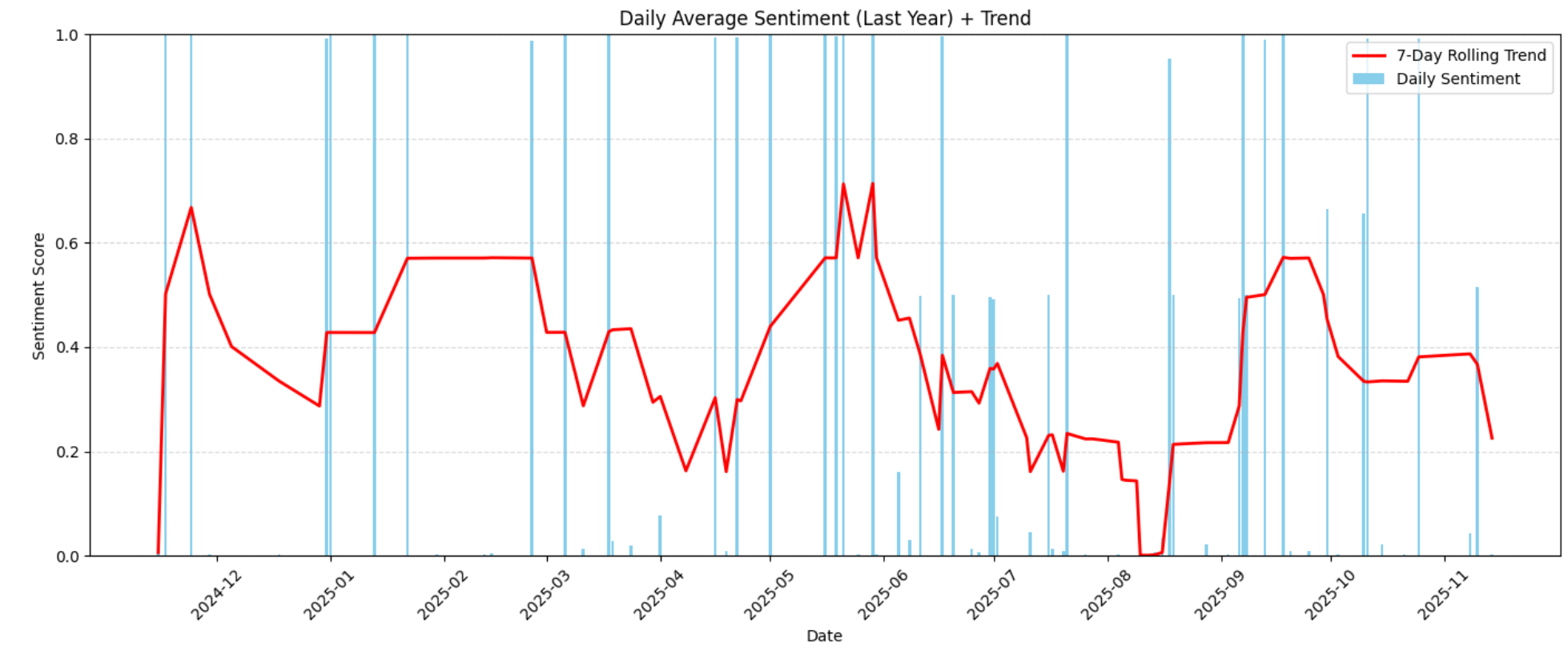
该可视化展示了全年情感上升或下降的走势。这些趋势有助于你识别客户满意度提升或下滑的时间段,以及是否有外部因素(例如产品变更、延迟、缺陷或价格调整)导致情感产生变化。
例如,在图表中可以清楚地看到 2026 年 6 月至 2026 年 8 月中旬之间,情感值急剧下降,从略偏正面(约 0.6)跌至极度负面(接近 0.0):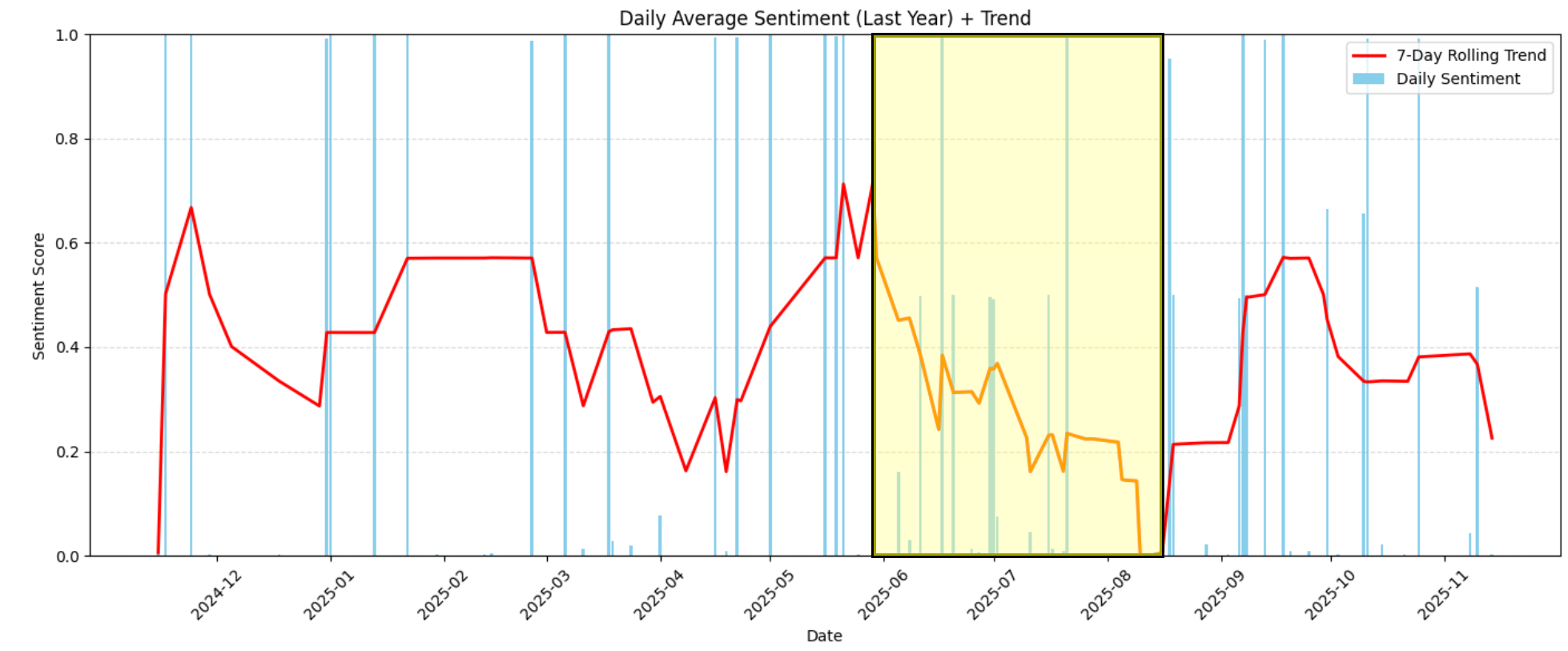
为了弄清这段时间发生了什么,我们可以将数据集限制在这些日期范围内:
# Filter reviews between June 2026 and mid-August 2026
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"Number of reviews in period: {len(df_filtered)}")输出显示该时间段共有 34 条评论:
Number of reviews in period: 34接下来,总结该时间段内各评分的情感分数情况:
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("nRating summary:")
print(rating_summary)结果类似如下:
Rating summary:
rating num_reviews avg_sentiment
0 1 16 0.004767
1 2 11 0.048928
2 4 2 0.998977
3 5 5 0.993221这告诉我们,在 34 条评论中有 27 条是 1 或 2 星,并且它们的情感得分快接近 0.0。
然后,用图表展示评分与情感之间的关系:
# Plot sentiment vs rating in a chart
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="Number of Reviews")
ax1.set_xlabel("Rating")
ax1.set_ylabel("Number of Reviews", color="skyblue")
ax1.tick_params(axis="y", labelcolor="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="Average Sentiment")
ax2.set_ylabel("Average Sentiment Score", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("Sentiment Analysis vs Rating (2026-06-01 to 2026-08-15)")
fig.tight_layout()
plt.show()生成的图表如下: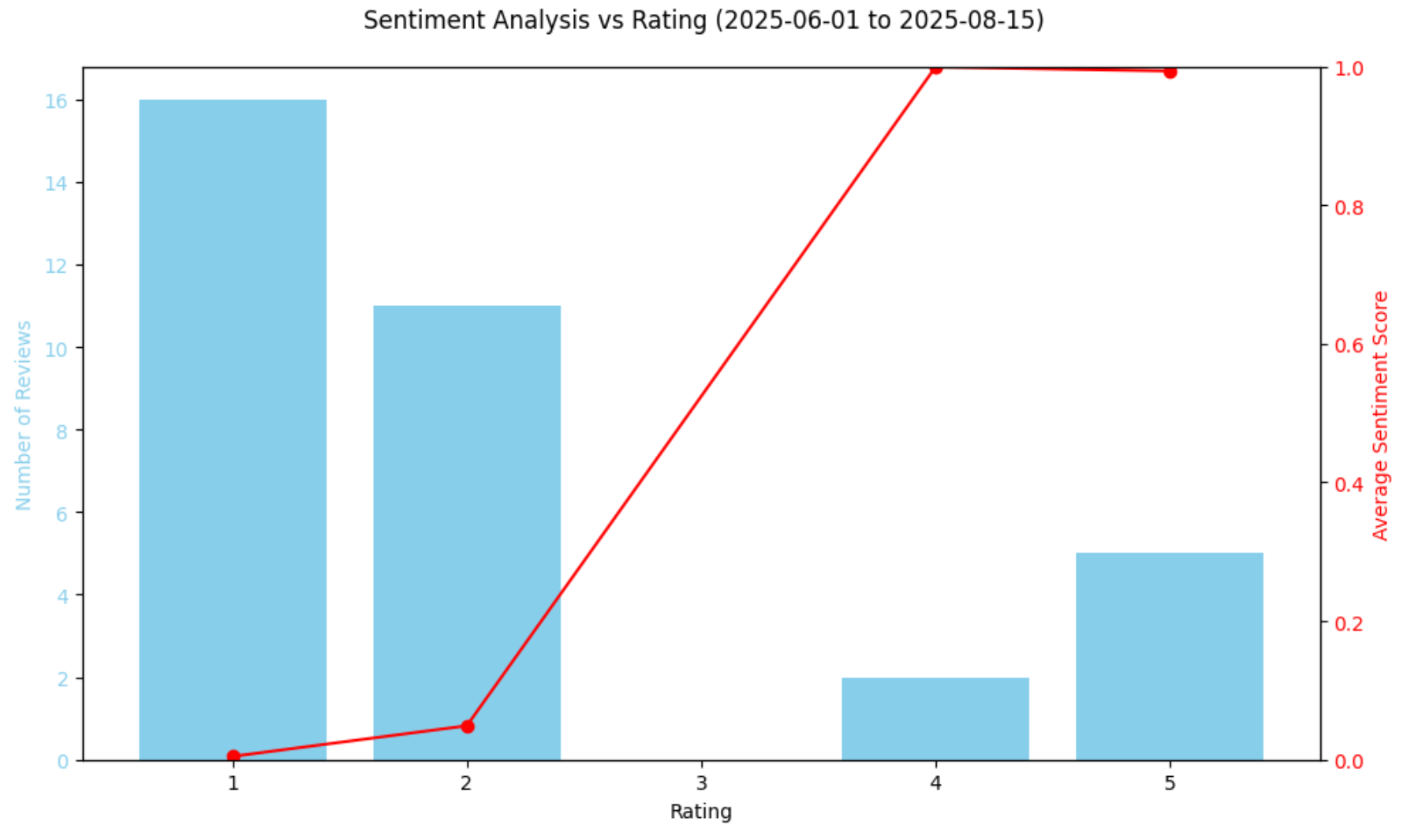
该图进一步印证了情感的急剧下滑:该时期的大多数评论都极为负面。有趣的是,从模型的情感得分来看,4 星评论的平均情感得分甚至略高于 5 星评论。这并非错误,而是反映了“星级评分并不总能完全反映情绪语气”这一事实。有些 5 星评论的文字中仍可能包含担忧或负面表述,而部分 4 星评论则可能采用极其正面的语言。
毕竟,虽然星级评分能快速反映用户大致感受,但并不总能捕捉评论文本中的全部细微差别。通过对比模型预测的情感得分与数值评分,你可以更好地了解评论语言是否与给出的星级一致,从而发现异常情况,例如高星评论中的负面措辞,或低星评论中隐含的积极态度。
接下来,让我们继续深入分析这段评分骤降期间的评论内容!
步骤八:阅读相关评论
真正弄清 2026 年 6 月至 2026 年 8 月中旬评论下降背后原因的最后一步,是直接查看这些评论本身。可以使用以下代码实现:
# Select relevant columns
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# Display the table in notebook via HTML
display(HTML(df_table.to_html(index=False)))结果将是如下 HTML 表格:
可以看出,这一时期的大多数评论都在抱怨香味消失得很快或味道不够浓。这凸显出在这些周内出货产品可能存在质量或生产问题。
这种洞察极具价值,因为它可以帮助你回溯并检查生产流程、修复反复出现的问题,并有机会通过优惠券或折扣等方式主动联系不满意的客户。
注意:上述评论分析流程也可以进一步结合大语言模型(LLM)自动化,从而构建一个真正全自动、可用于生产环境的管道。
Et voilà!得益于 Bright Data 的爬取能力,你成功获取了亚马逊商品数据;随后,你使用 TensorFlow 进行了情感分析,研究了趋势变化,并找出了特定时间段内评分下滑的原因。
总结
在本文中,你学习了如何通过 Bright Data 从亚马逊商品中获取评论数据,并在 Python 笔记本中构建基于 TensorFlow 的机器学习流程,对其进行情感分析和趋势研究。
该项目非常适合那些希望持续监控用户评论并提升客户满意度的中小企业或大型企业。如果没有 Bright Data 面向企业提供的数据服务,这样的分析将难以实现。
这些解决方案包括丰富的数据集市场以及Web Scraper API,帮助你从包括 Amazon、LinkedIn、Yahoo Finance 在内的 100 多个域名采集历史或最新数据。有了这些数据,你就可以将其输入 TensorFlow 或类似技术中,通过机器学习进行分析。
立即创建一个免费的 Bright Data 账号,试用我们的爬虫 API 或探索我们的数据集吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



