
数据过滤曾经只是一个简单的数据库技巧。如今,它是支撑 AI、确保合规并帮助你超越竞争对手的核心业务能力。
在本指南中,你将学习:
- 什么是数据过滤。
- 数据过滤为何重要。
- 为何应使用自动化数据过滤。
- Deep Lookup 如何让数据过滤变得简单。
开始吧!
什么是数据过滤?
数据过滤的本质是:只呈现你真正关心的数据。把它想象成咖啡滤纸——只让你得到想要的“好东西”,而不是咖啡渣。其机制很直接:你设定规则(例如:只显示加利福尼亚的客户),系统就会排除所有不符合规则的内容。
我们在日常生活中都在使用数据过滤。当你在亚马逊搜索“100 美元以内的无线耳机”,你在过滤。当你的市场团队拉取“过去 6 个月未购买的客户”列表,他们在过滤。当你按发件人对收件箱排序时,你也在过滤。
概念虽简单,但在组织中规模化使用数据过滤,需要对数据有扎实理解并配备合适工具。如今,数据过滤关系到每个组织的成功,接下来我们会告诉你原因。
数据过滤为何重要
在大数据时代,过滤是理解数据的必需手段。
今天大多数公司都坐拥“数据金矿”,却永远无法充分利用。并不是因为数据本身没有价值,而是因为他们无法高效地从海量数据中挖掘出重要内容。
换个角度想:你的公司可能为每位客户采集了上百个数据点。但当关键时刻需要识别最有价值的细分群体时,你真的会手动翻查 5 万条客户记录吗?当然不会。你可能抽样、做些合理猜测,然后尽力而为。
这正是过滤要解决的问题。以下是高效数据过滤不可或缺的原因:
- 穿透噪音:分析师不再把时间浪费在无关数据上,而是专注于真正能推动业务的模式。
- 加速一切:数据集更小意味着查询更快、洞见更快,决策从几周缩短到几天。
- 发现隐藏模式:当你去除杂乱后,原本不可见的趋势会变得一目了然。
- 实实在在省钱:需要存储和处理的数据更少,基础设施成本更低;并且团队的时间价值大幅提升。
- 保持合规:自动过滤敏感信息,让你不必担心意外暴露客户数据。
总之,数据过滤是原始数据与明智决策之间的桥梁。接下来,我们将看看实践中如何开展过滤,以及一些有效过滤的常见技术。
使用亚马逊平台数据的手工过滤演练
我们来走一遍团队在需要过滤数据时最常做的事情。我们将使用一个真实的亚马逊产品数据集(由 Bright Data Datasets 提供)来展示实际流程。该数据集包含来自不同品类和地区的产品标题、品牌、价格、评分等多种字段。
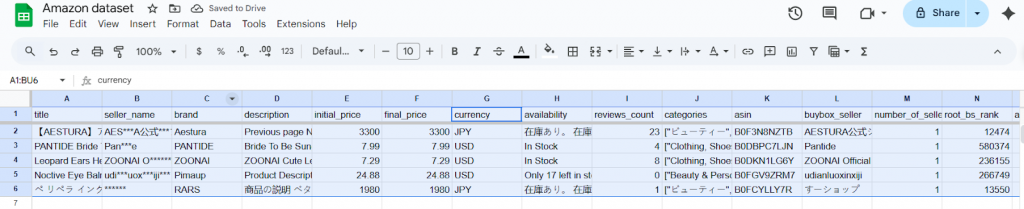
面对如此宽泛的列表,数据从业者需要将与特定分析无关的产品剔除,只保留有用信息。通常会采取以下步骤:
- 先过滤掉不符合初始兴趣标准的条目。实践中,这通常意味着排除目标品类或范围之外的产品。例如,如果我们只关心美妆产品,就移除属于其他品类的记录。
- 使用 Google 表格或 Excel 等工具,进入“数据”选项卡并点击“创建筛选器”。
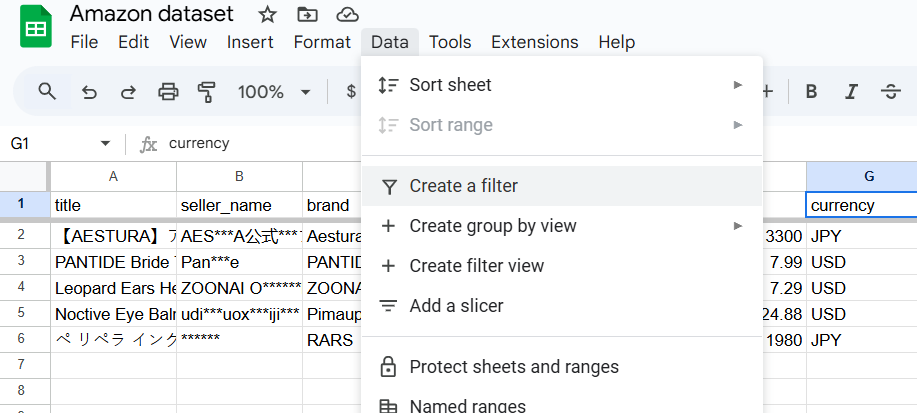
- 随后每一列都会出现筛选器,你可以据此任意定制数据集。
- 例如,如果你想按币种过滤,只保留定价为 USD 的产品,就到“价格/币种”列应用该筛选。
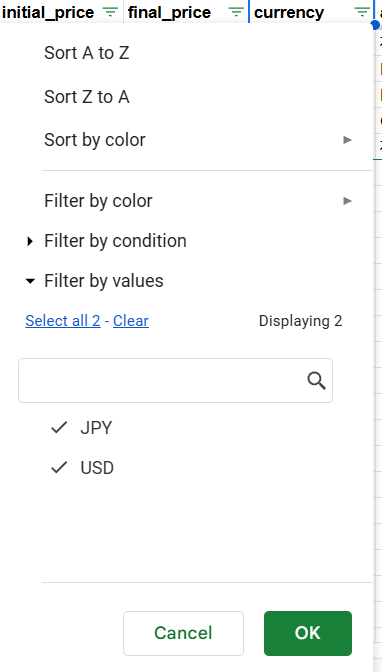
- 一旦取消勾选 JPY,数据集就只会显示以 USD 定价的产品。
第一次这么做时,感觉相当不错:你掌控全局,能清楚看到发生了什么,还能一路捕捉有趣的模式。“哇,看起来环保产品的评分确实更高!”
但实际上往往会变成这样:
- 第 1 周:太棒了!我喜欢这种掌控感。
- 第 4 周:好吧,有点重复了,但我还能找到不错的洞见。
- 第 12 周:我整个早上都在重复昨天的同一套过滤。
- 第 24 周:我是不是忘了清除上一次的筛选……这些数字还准确吗?
很多出色的分析师都是这样被消耗殆尽的。并不是因为工作没有价值,而是他们把 80% 的时间花在机械操作上,而非真正的分析。
既然你已经了解了如何手工过滤数据,我们来看看这种方法的优缺点。
手工过滤的优点
- 手工过滤提供即时的可视化反馈,让你立刻看到结果并迭代调整筛选器。工作中还能及时发现意外模式或数据质量问题。
- 你还能结合业务语境做出更细腻的判断。例如在过滤“customers_say”或“top_review”字段时,人类判断可以识别自动系统可能错过的情绪与诉求。
- 它支持灵活探索,利于发现驱动型分析。比如你可能注意到“climate_pledge_friendly”= TRUE 的产品评分更高,从而获得新的战略洞见。
- 入门门槛低:任何熟悉表格工具的成员都可以在无需技术培训或专用工具的情况下开展分析。
- 通过筛选视图,你可以获得一定的审计可见性;记录的筛选标准有助于结果复现与团队协作。
手工过滤的缺点
- 规模限制很快显现。Google 表格中过滤 1 万行以上就会明显卡顿。面对数以百万计的亚马逊产品,你只能看到很小一部分样本。
- 复杂度越高,耗时越多。以上述 8 步过滤流程为例,一次分析需要 15–20 分钟。若要每天重复或覆盖多个品类,几乎不可持续。
- 重复操作导致人为错误概率上升。比如误选了运算符(大于与小于)、或忘记清理上一次筛选,都会造成错误分析。
- 不同使用者之间的一致性差,容易产生相互矛盾的洞见。两位分析师可能对“高质量卖家”的理解不同,在“seller_name”或“rating”上设定的阈值也不同。
- 可复现性有限,无法实现自动化。每次手工过滤都需要人工介入,难以支持定时报表或实时看板。
- 机会成本高。分析师把大量时间花在过滤上时,使用自动化方案的竞争对手已据此行动。用于机械过滤的时间本可以投入到战略分析与决策中。
整体而言,手工数据过滤为分析师提供了高度的控制与清晰度,适用于探索式分析或注重细微差别的小规模数据集。但在大规模数据场景中,其低效与高错误风险使之不适合大数据或常规工作流。
在这些情况下,转向自动化过滤方法或工具会更好,接下来我们将解释原因。
为什么自动化数据过滤更聪明、更快速且可扩展
当我们谈到自动化过滤时,重点不只是速度。自动化不仅把你以前的做法加速,而且能完成你手工根本无法做到的事情。
还记得那个包含 73 个不同字段的亚马逊数据集吗?手工时,你也许只会探索 5–10 种字段组合;而借助自动化,你可以并行测试上千种组合。你可能会发现:带有环保徽章的产品,在特定价格区间、由特定类型卖家售卖时,客户留存率其实高出 23%。
这些不是“碰巧发现”的洞见,而是当你能系统性地从各个角度穷尽性探索时自然涌现的结果,而这只有自动化数据过滤才能实现。
自动化过滤通过把你的标准编写为可被机器执行的规则,并在规模上持续运行,从根本上改变了分析师或公司的能力边界——在几秒内处理数百万条记录,同时同时应用数百种过滤组合。
不再逐列点击,而是以声明式方式定义过滤器,把过滤尽可能“推到数据源附近”,从而获得快速、可重用的数据。通过自动化数据过滤,你可以并行穷尽性地探索上千种字段交互,揭示人类有限探索预算下无法发现的模式,并能稳定复现。
| 维度 | 手动 | 自动化 |
|---|---|---|
| 速度/延迟 | 人工节奏;每次运行需数分钟至数小时 | 机器节奏;规模化下数秒至数分钟 |
| 可扩展性 | 受 UI 与内存限制 | 横向扩展(分布式计算、谓词下推) |
| 可靠性 | 易受人为错误影响 | 确定性、可测试、幂等 |
| 新鲜度 | 批处理,临时 | 可调度或流式;接近实时 |
| 一致性 | 因人而异 | 逻辑受版本控制;输出可复现 |
| 成本 | 隐性人力成本;返工 | 计算优化;缓存与谓词下推 |
| 治理 | 难以审计 | 数据血缘、日志、审批、访问控制 |
你能用到的最佳自动化过滤工具之一就是 Bright Data 的 Deep Lookup,下面我们将详细介绍。
介绍 Deep Lookup:用自然语言过滤数据
Deep Lookup 是 Bright Data 的 AI 研究工具,可将自然语言提示转为结构化且准确的数据集。使用 Deep Lookup,你可以用简单描述提出需求,并以可用的数据表格形式获得结果。
无需拼接多个来源或编写复杂查询,你只需描述你想要的实体(公司、产品、人物、新闻、房产)、它们必须满足的过滤条件,以及你想看到的列。Deep Lookup 会在后台完成过滤、充实与结构化处理,最终交付可直接用于分析的结果。
Deep Lookup 的工作方式
Deep Lookup 鼓励使用两行提示格式,类似这样:
- Find all… <实体与条件>
- Show: <你想要的列>
例如,一个 Deep Lookup 的示例如下:
***Find all Amazon Beauty & Personal Care products priced ≤ $25 with rating ≥ 4 and in stock.***
***Show: product name, brand, current price, rating, number of reviews, product URL***Deep Lookup 会根据上述描述:
- 识别所需的数据源
- 在数据库层面应用你的过滤条件(而不是先把所有数据下载下来再过滤)
- 用额外上下文丰富结果
- 返回干净、结构化、可立即使用的数据集
对于更复杂的查询,你可以采用更结构化的写法:
FIND ALL: [entity types]
FILTERS:
- Condition #1
- Condition #2
SHOW:
- Column #1 [Enrichment or Constraint]
- Column #2 [Enrichment or Constraint]关键在于:你在描述业务逻辑,而非技术实现。你不需要知道该调用哪些 API、如何处理分页、或到哪里获取竞品价格数据。
通过 Deep Lookup 返回的数据集会以 Websets 形式交付:它们经过核验并有完整引用,可自定义(选择精确字段),且随着 Deep Lookup 持续扫描新来源而保持最新。
在实际使用中,流程是:
- 提出问题
- 抓取并推理
- 获得可执行结果
你可以按实体、行业、地域和数据字段来定制 Websets,以匹配你的具体用例。
结语
至此你已经看到,数据过滤可以把凌乱、压倒性的信息转化为清晰的决策。手工过滤能建立直觉,但自动化带来速度、一致性,以及发现“单列筛选”永远找不到的模式的能力。
这正是Bright Data 能帮到你的地方。借助 Deep Lookup,你用自然语言陈述条件,就能获得干净、结构化、始终新鲜的数据集,直接接入看板、笔记本或模型。配合 Bright Data 的 Datasets(如本指南中的亚马逊数据集),你可以从想法到洞见再到生产落地,全程无需维护脆弱的数据管道。
准备好看看自动化过滤能为你的数据做些什么了吗?使用免费 Bright Data 账户试用 Deep Lookup。把你一直在手工应用的过滤规则交给它,看看有哪些洞见是你过去错过的。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





