

在本教程中,你将学习:
- AWS Glue 是什么,以及它能提供什么。
- 为何 Bright Data 借助其网页数据获取服务支持 ETL 管道。
- 如何在 AWS Glue 中将 Bright Data 集成到 ETL 作业里。
让我们开始吧!
AWS Glue 是什么?
AWS Glue 是一项无服务器数据集成服务,旨在简化在任意规模下从多个来源发现、准备和组合数据的流程。
它允许你构建用于分析、机器学习和应用开发的 ETL(Extract, Transform, Load)工作流,无需管理基础设施。AWS Glue 可加速数据管道开发,并使数据易于访问以便分析。这通过集中式数据目录以及可视化与代码化的作业编写工具来实现。
它提供的三个最相关特性是:
- 发现并组织数据:自动推断 schema、编目元数据,并连接 AWS、本地以及其他云中的数据源。
- 转换并清洗数据:可视化作业编辑器、交互式笔记本、流式 ETL 支持,以及内置基于 ML 的去重功能。
- 构建并监控管道:支持作业调度、自动化与弹性扩展,并可通过详细洞察与触发器监控管道。
为什么要将 Bright Data 集成到你的 AWS Glue ETL 工作流中
将 Bright Data 集成到 AWS 的 ETL 工作流中,可以显著扩展数据管道的范围与质量。
虽然 传统 ETL 主要聚焦于从已知来源提取结构化数据,但 Bright Data 能让你访问实时的结构化网页数据。这将解锁原本需要手动收集或复杂爬虫基础设施才能获得的洞察。
除了丰富的网页数据提取(E)能力外,Bright Data 也能改进你的 转换(T) 阶段。在转换期间,你可以通过为记录追加实时市场、产品或社交信息来丰富数据集。例如,你可以把股票表现指标、竞品定价或公司元数据添加到内部数据集中。
这些洞察可帮助团队做出更明智的决策。数据验证也是另一项关键收益,因为通过抓取工具获得的数据可以与权威来源进行交叉对照。这有助于你在加载到目标数据存储之前确保准确性。
如何使用 Bright Data 为 AWS Glue ETL 作业获取网页数据
本指导章节将展示一种在 AWS Glue ETL 作业中集成 Bright Data 的方式。具体来说,你将看到如何构建如下示例 ETL 管道:
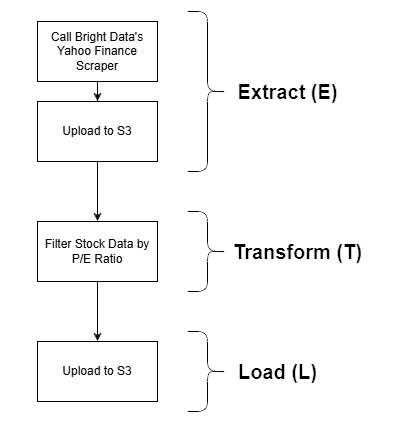
Bright Data 在 Extract(E) 阶段发挥作用,这得益于其强大的网页数据获取选项。这里使用 Yahoo Finance 抓取工具来获取股票数据,然后按市盈率(P/E)进行过滤,最终存入 S3 存储桶。这是一个简单示例,但仍然是完整 ETL 工作流的现实演示。
注意:完成本教程后,你还可以探索并评估在 AWS Glue 中集成 Bright Data 的其他方式。
按照以下说明开始吧!
前置条件
在开始本教程之前,请确保你已完成以下准备:
- 一个 AWS 账户(即使是免费试用账户也可以)。
- 一个已配置 API key 的 Bright Data 账户。按照官方说明 生成你的 API key。
- 在 AWS 账户中创建好的 S3 存储桶。
- 具备基础 Python 知识,用于编写脚本以集成 Bright Data 爬虫工具 API,并将抓取的数据上传到你的 S3 存储桶。
- 具备基础 SQL 技能,用于在 ETL 管道的 Transform(T) 阶段编写简单查询。
本教程中,我们假设你的 S3 存储桶名为 bright-data-etl-bucket:
另外,熟悉一下 Bright Data Web Scraping APIs 的工作方式也会很有帮助。
步骤 #1:开始使用 Bright Data 抓取工具 API
在开发 ETL 管道时,你显然应该从 Extract(E) 阶段开始。第一步是使用 Bright Data 的 Yahoo Finance Scraper 获取数据,因此熟悉它很重要。
如果你还没有账号,先创建一个 Bright Data 账户。否则,登录到现有账户。在控制面板中,进入“Web Scrapers”板块:
接着进入 “Web Scrapers Library” 标签页。搜索 “finance”,并选择 “Yahoo Finance Scraper”。打开可用的爬虫工具:
在 Yahoo Finance Scraper 页面,你可以查看该抓取工具的输入要求与输出 schema: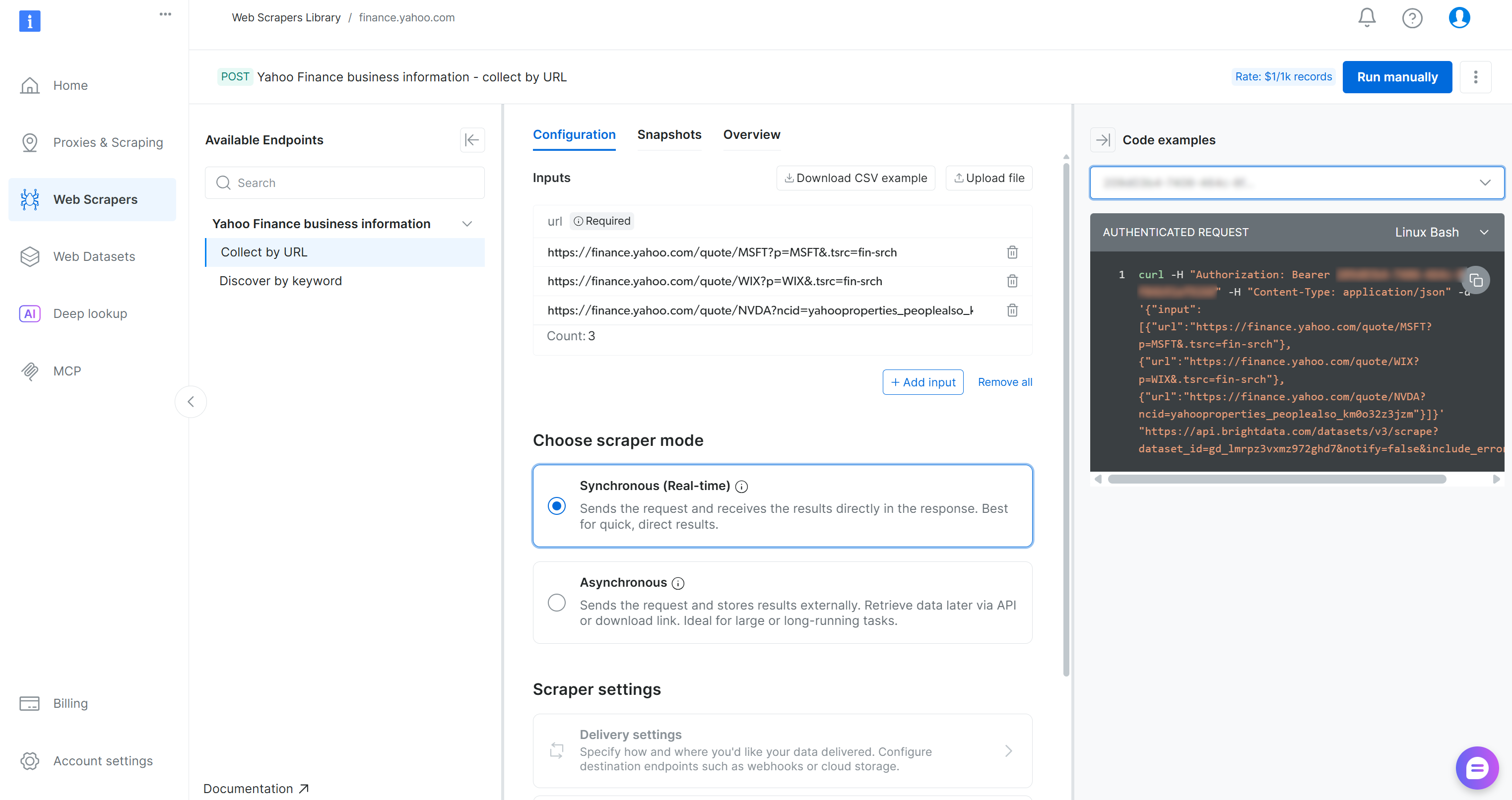
控制面板还提供多种编程语言的代码片段,便于快速配置。关键点在于:该爬虫接受一个或多个 Yahoo Finance 股票页面作为输入,并返回结构化的实时股票数据。完美!
步骤 #2:配置 S3 投递(Delivery)
Bright Data Web Scraping APIs 支持自动将抓取的数据投递到 Amazon S3。因此,利用这个有用功能可以加速数据收集步骤。要配置 Amazon S3 投递,你首先需要启用异步模式。
在 “Configuration” 标签页中,选择 “Asynchronous” 选项。然后点击 “Delivery settings” 按钮: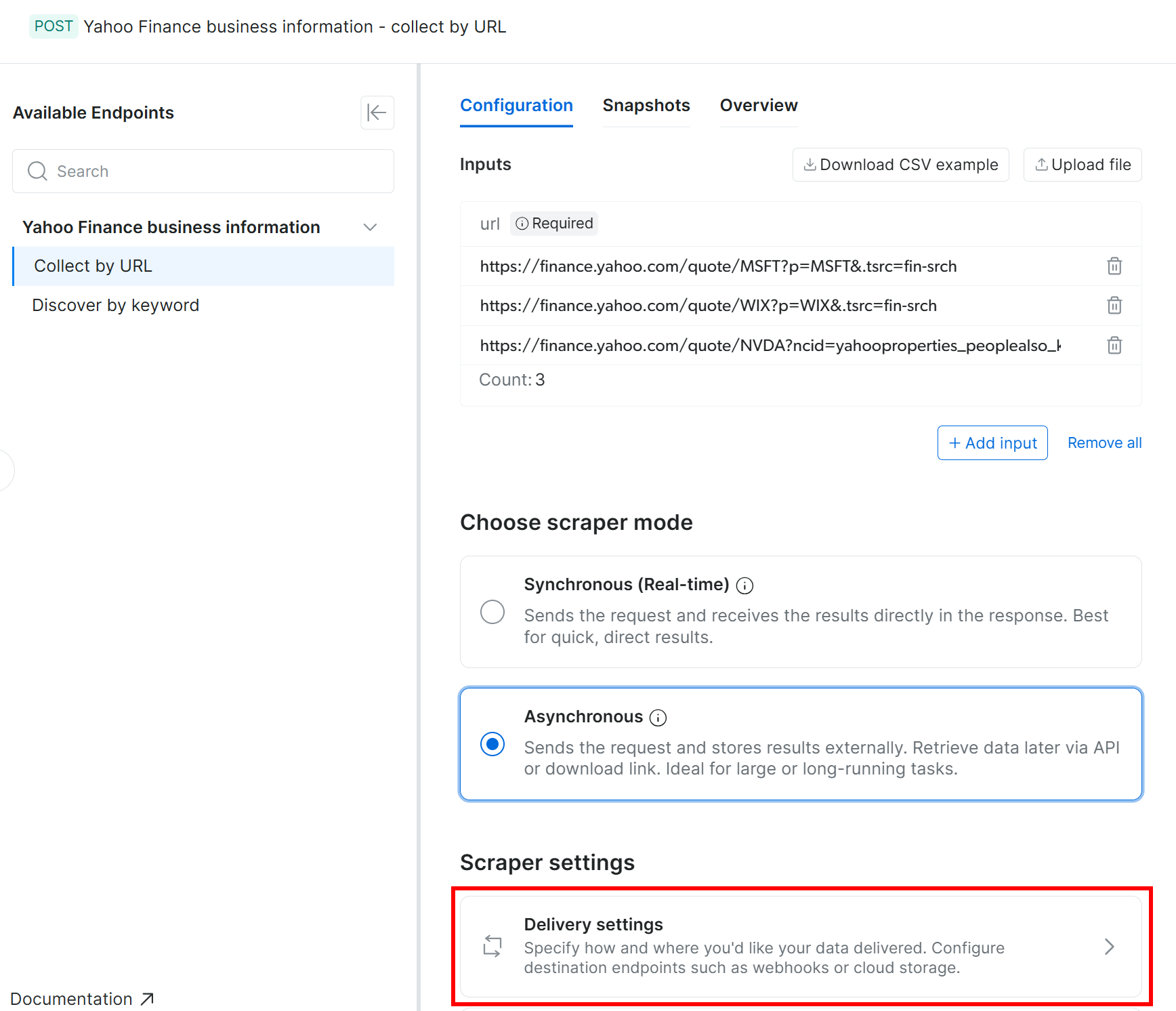
按如下方式填写表单,将数据投递配置到你的 Amazon S3 存储桶:
- 启用 “Enable delivery” 开关。
- 将格式设置为
JSON。 - 存储目标选择 “Amazon S3”。
- 输入你的 S3 存储桶名称(本例为
bright-data-etl-bucket)。(Endpoint URL 可留空。) - “Target path” 留空,这样文件会上传到存储桶根目录。
- 将 “Authentication type” 设置为 “Access keys”。
- 粘贴你的 AWS Access Key ID 和 AWS Secret Access Key。
- 将文件名设置为
stocks。
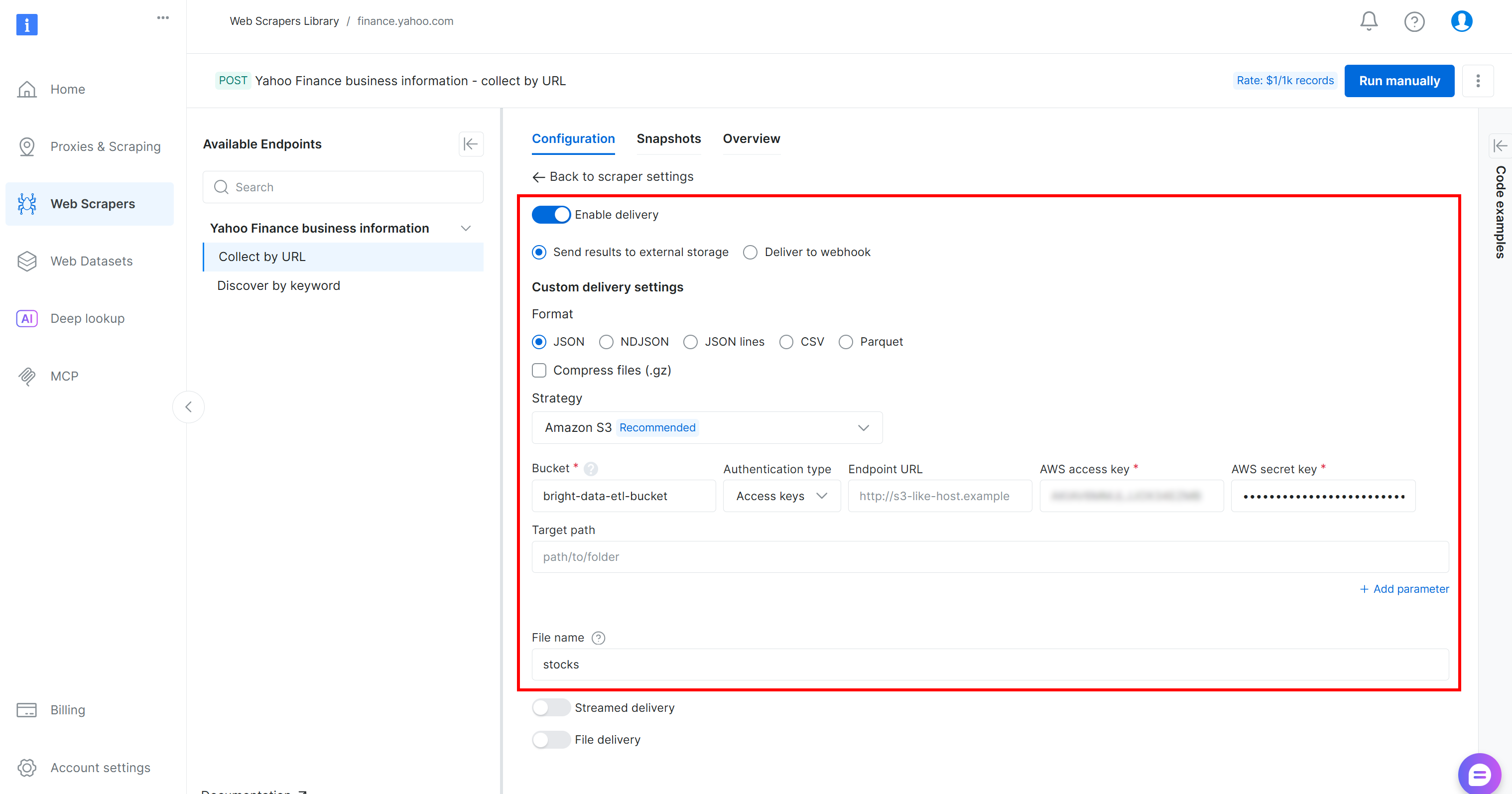
在该配置下,Web 抓取工具 API 将以异步模式运行。这意味着 Bright Data 会创建一个在其基础设施上运行的抓取任务。任务完成后,抓取到的数据会自动上传到你的 Amazon S3 存储桶,随后你的 AWS Glue ETL 作业即可访问。太棒了!
步骤 #3:运行网页数据提取逻辑
为了验证网页数据提取逻辑可用,添加几个 Yahoo Finance 股票 URL(例如 NVDA、AAPL、GOOGL、MSFT、AMZN、TSLA、META、AVGO、BRK.B、LLY),然后点击 “Run manually” 按钮: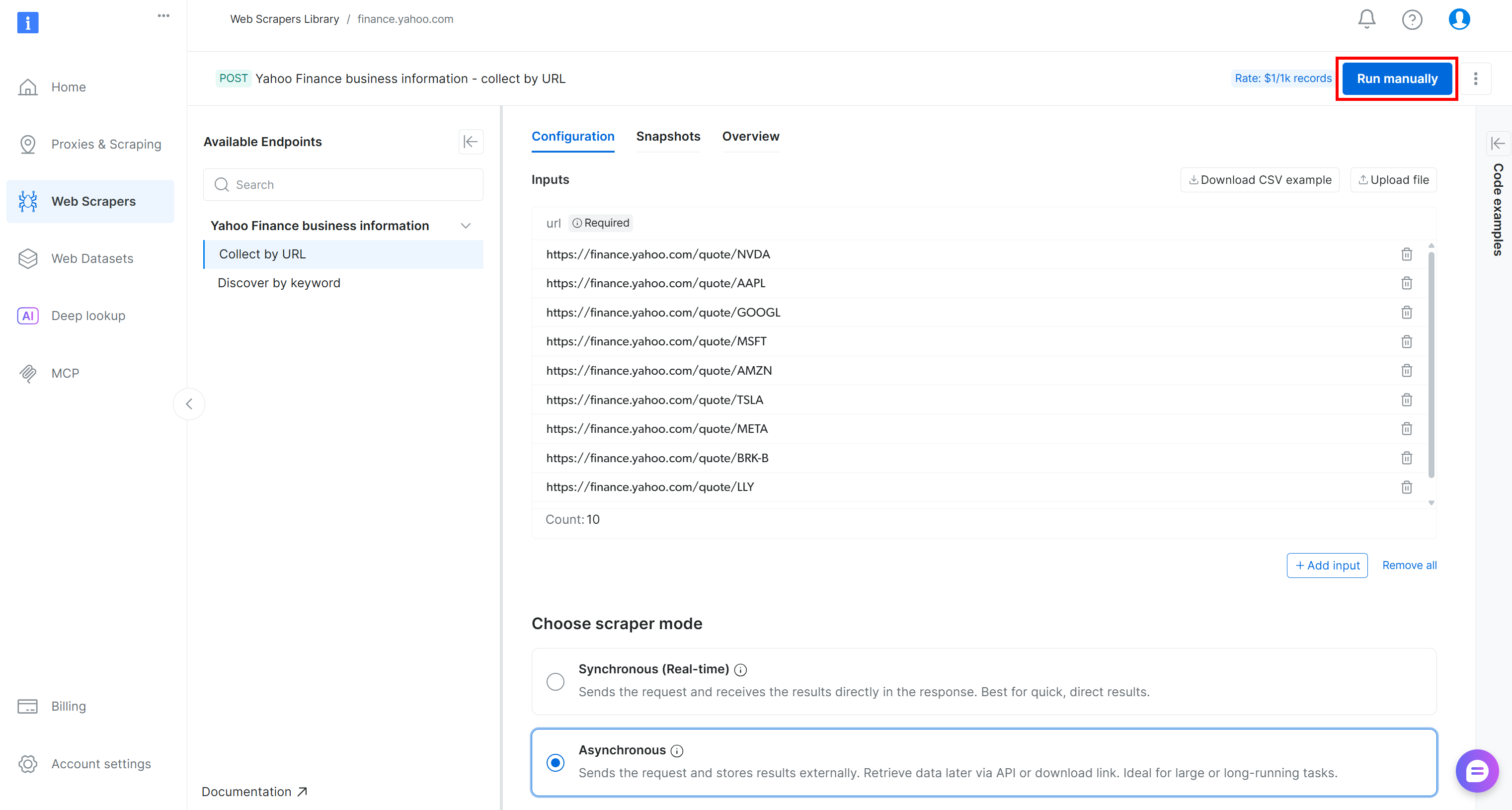
抓取工具 API 请求会被发送,抓取任务将在云端启动。你可以在 Bright Data 控制面板中实时监控任务状态: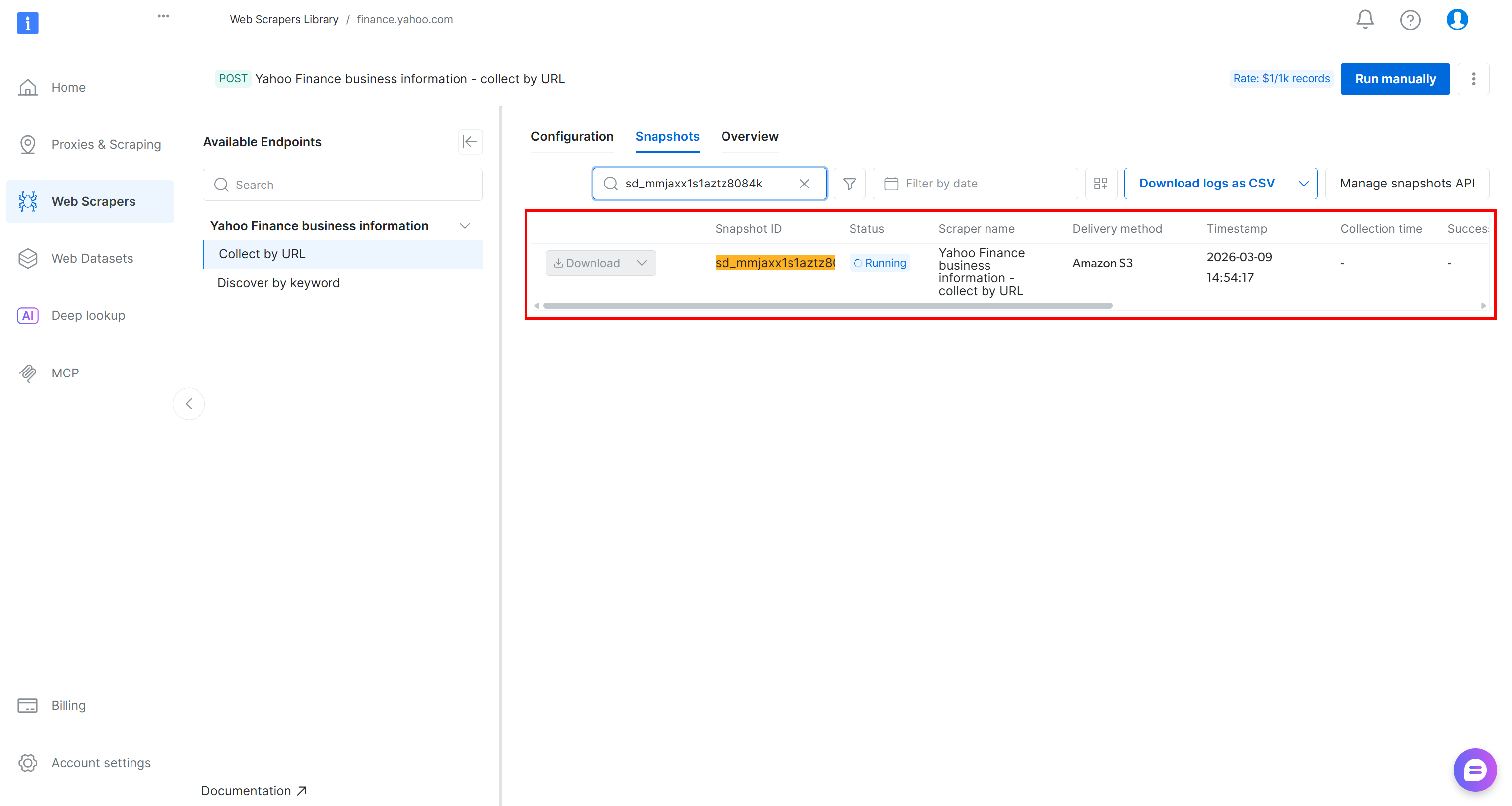
或者,你也可以使用 Bright Data 控制台(右侧栏)提供的某个代码片段,以你偏好的编程语言通过程序方式达到同样效果:
当任务状态变为 “Ready” 时,检查你的 AWS S3 存储桶。你会看到一个名为 stocks.json 的新文件: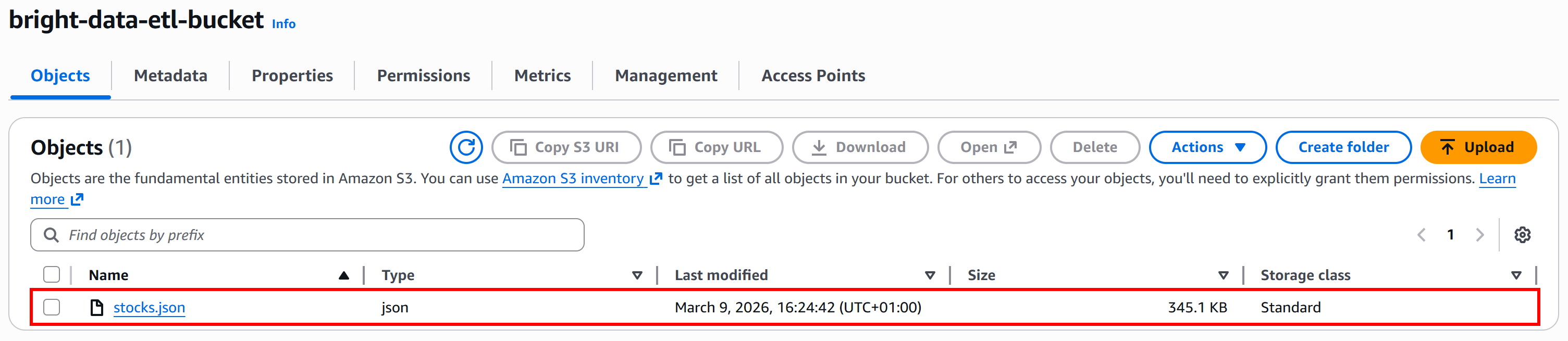
如果你在浏览器中打开 stocks.json 文件,会看到类似如下内容: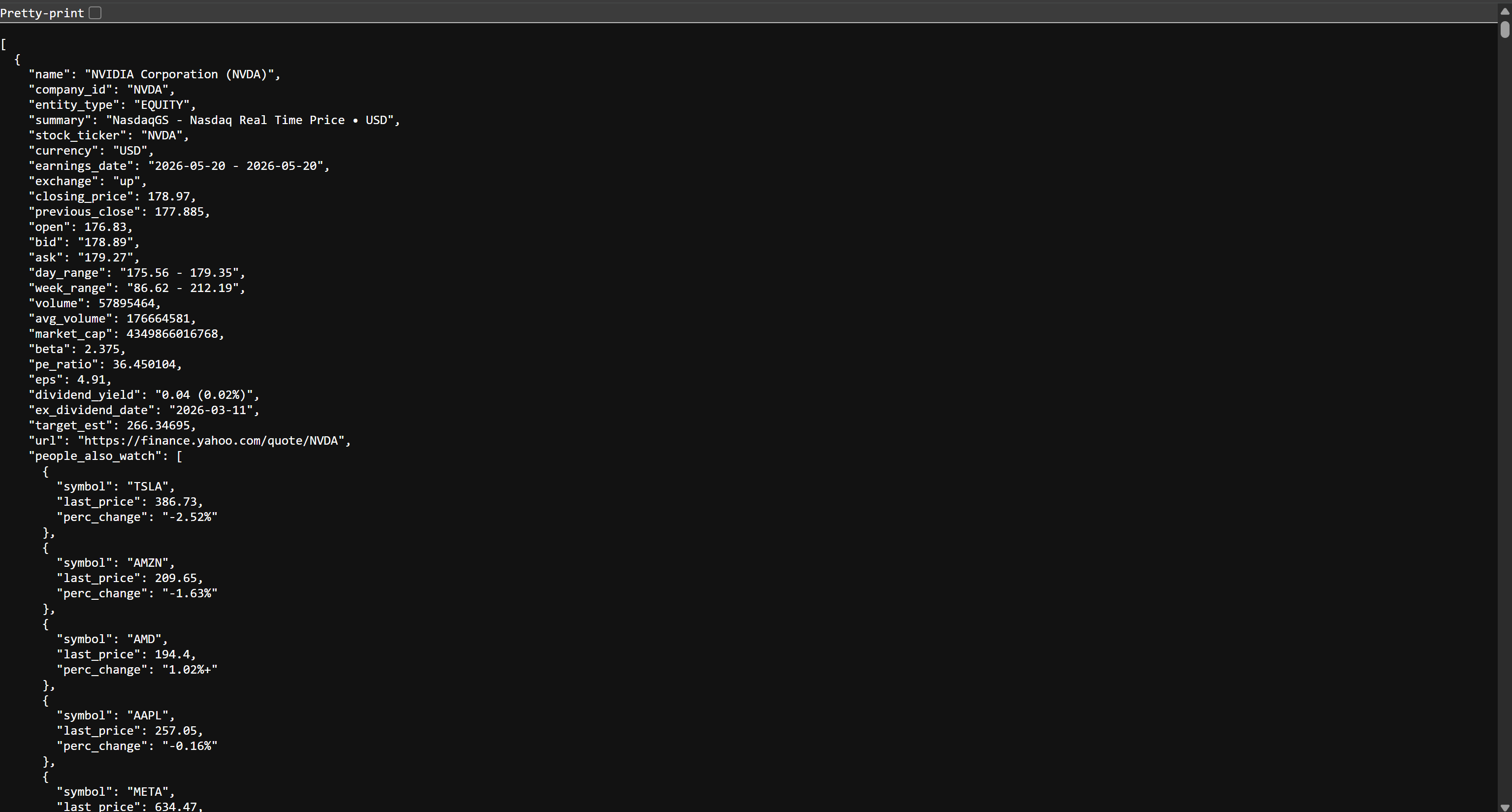
这些就是 Yahoo Finance 上的同一份股票数据,只是被结构化为 JSON 格式。该数据由 Bright Data Web 抓取工具 API 抓取而来。任务完成!现在你已经具备构建 AWS Glue ETL 管道所需的数据。
步骤 #4:初始化你的 AWS Glue 作业
登录 AWS Console 并搜索 “AWS Glue”。选择该服务以打开其主页。
然后点击 “Go to ETL jobs” 按钮,打开 AWS Glue Studio,这是创建 ETL 工作流的官方界面: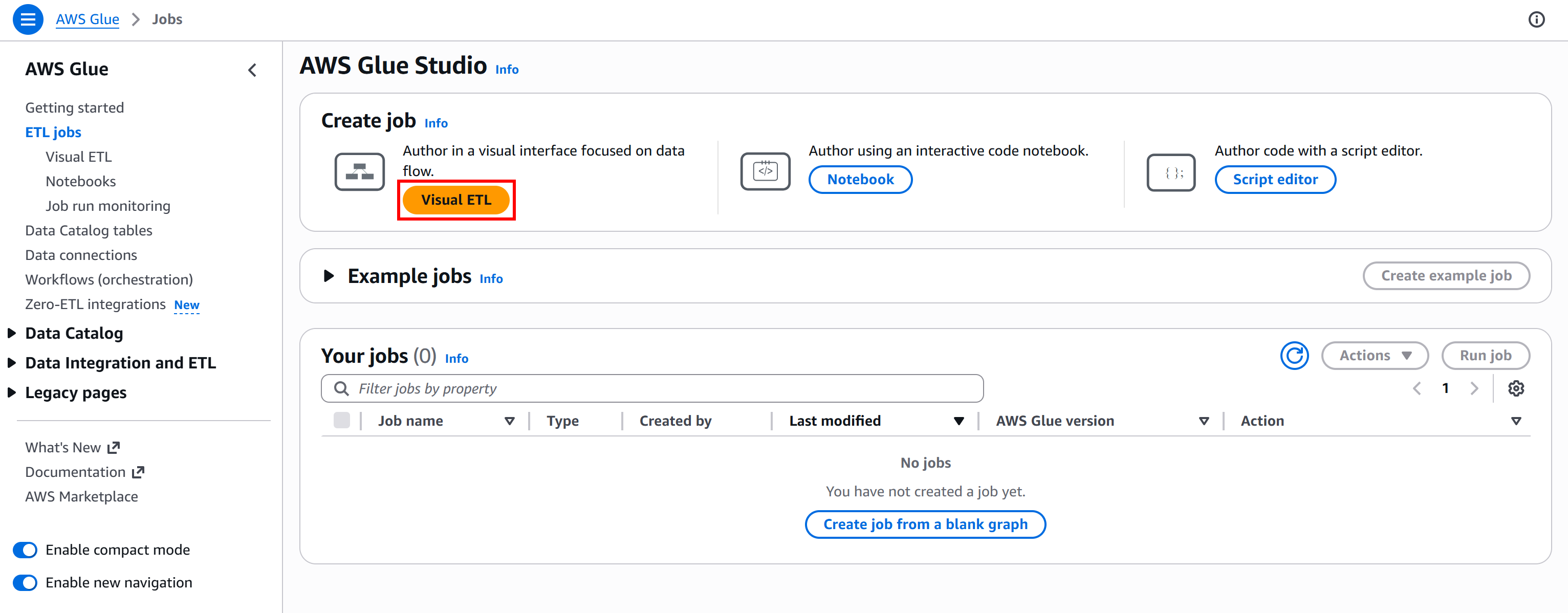
在这里,你可以初始化一个新的 AWS Glue 作业。本教程选择 “Visual ETL” 选项,建议用于通过简化的拖拽界面构建管道。
随后你会进入一个空白画布,可通过连接不同节点以可视化方式定义 AWS Glue ETL 工作流:
为你的 ETL 作业起一个描述性名称,例如 “Bright Data Glue ETL Job”。完成后,你就可以开始构建 ETL 管道了。
步骤 #5:创建 IAM 角色
要运行 AWS Glue 作业,你必须提供一个 IAM 角色,用于访问 Amazon S3 等资源并管理 AWS Glue。这些权限对作业、爬虫(crawler)和开发端点等 Glue 组件是必需的。
要直接在 Glue Studio 中创建角色,进入 “Job details” 面板并点击 “Create new role” 按钮: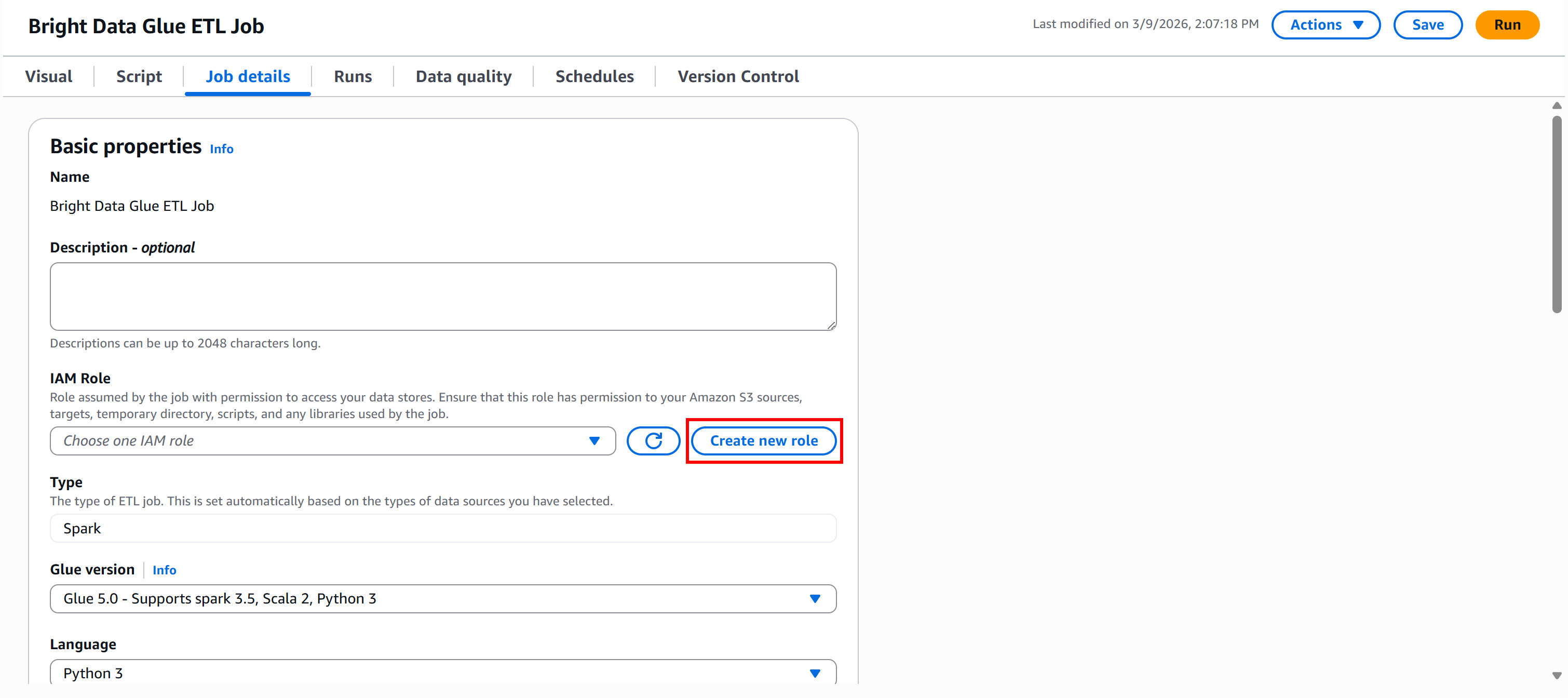
在 “Create role” 部分,为你的 IAM 角色取一个描述性名称,例如 "bd-glue-role":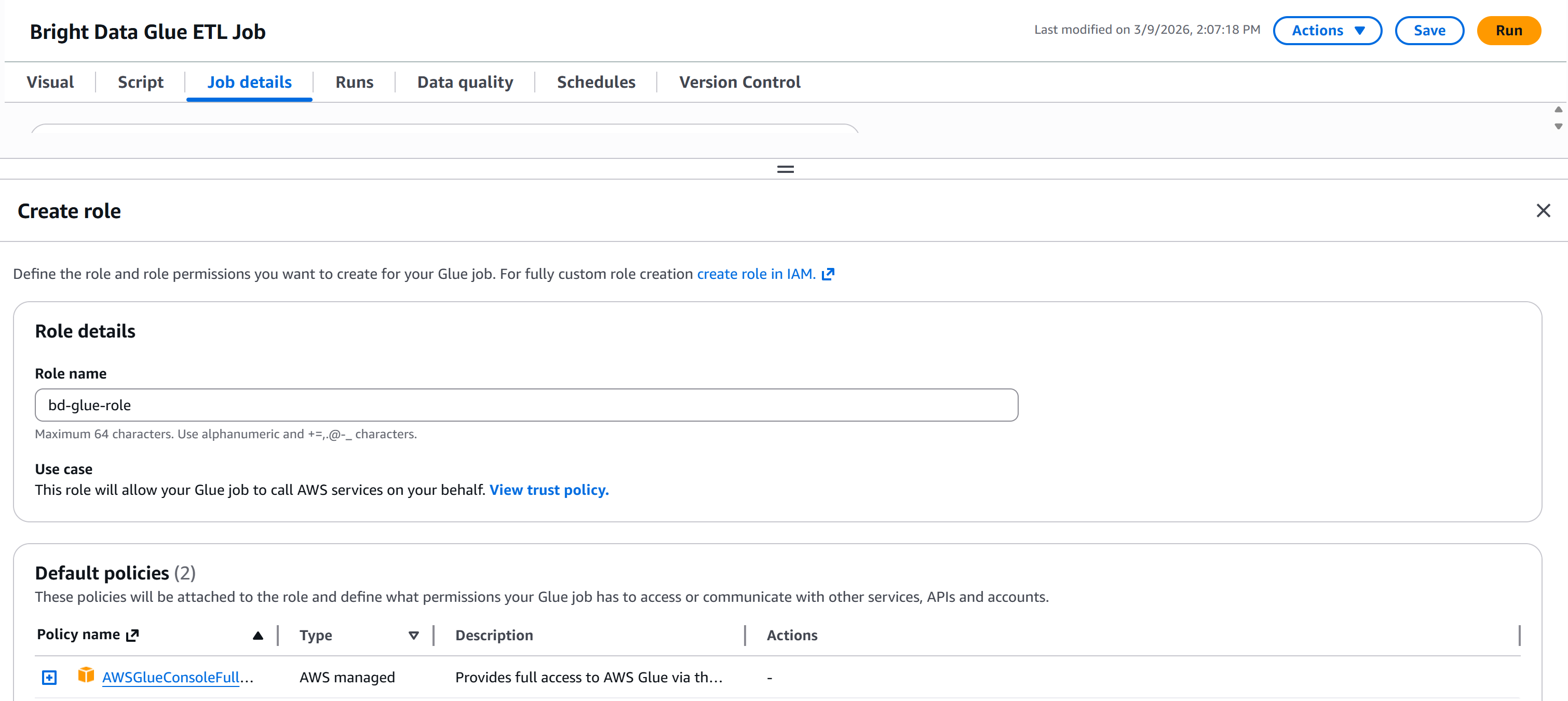
默认情况下,AWS 会附加两条必需策略:
AWSGlueConsoleFullAccess:通过 AWS 管理控制台提供对 AWS Glue 的完全访问权限。AWSGlueServiceRole:AWS Glue 服务角色策略,允许访问相关服务,包括 EC2、S3 和 Cloudwatch Logs。

接下来,获取你的 S3 存储桶 ARN。你可以在 S3 控制台中该存储桶的 “Properties” 页面找到: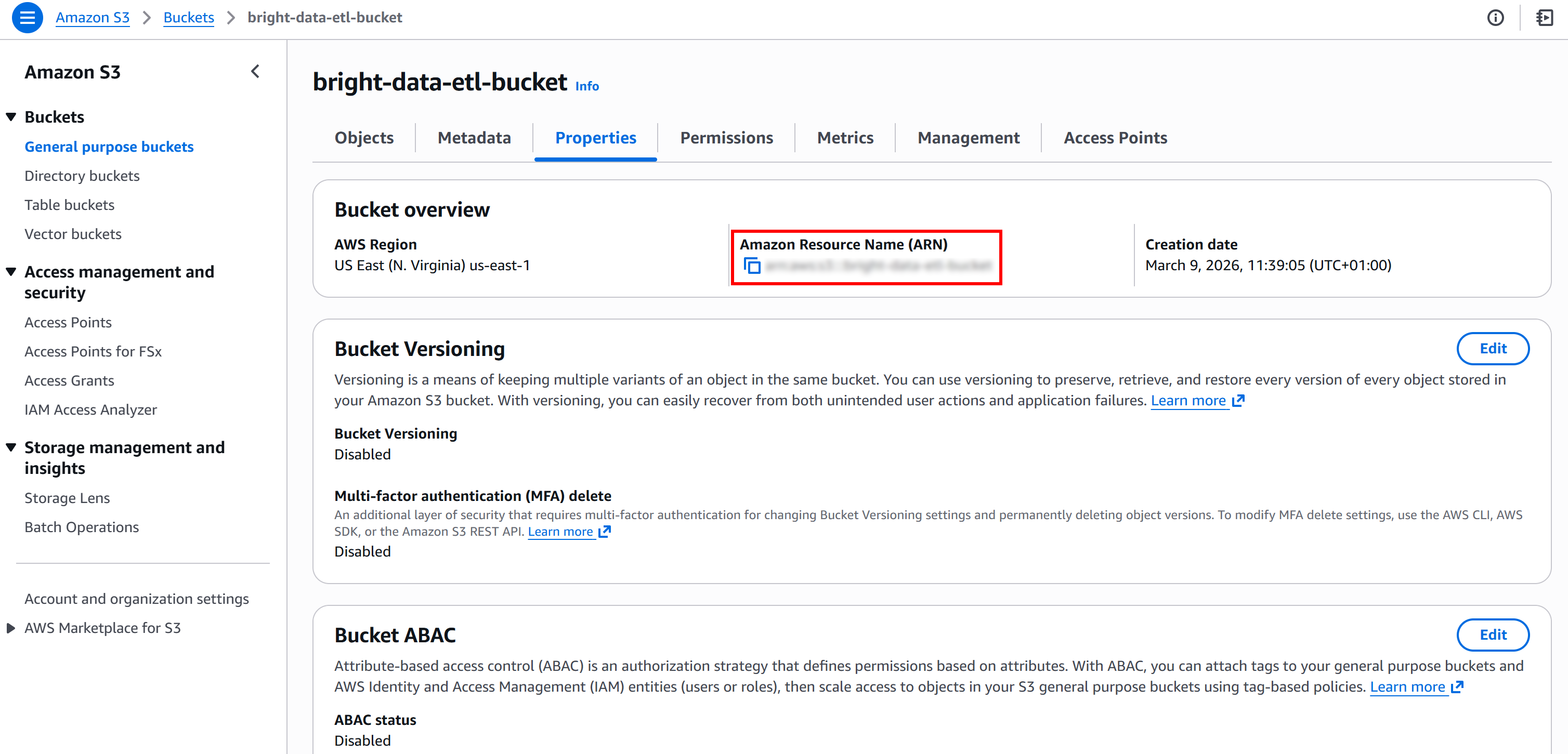
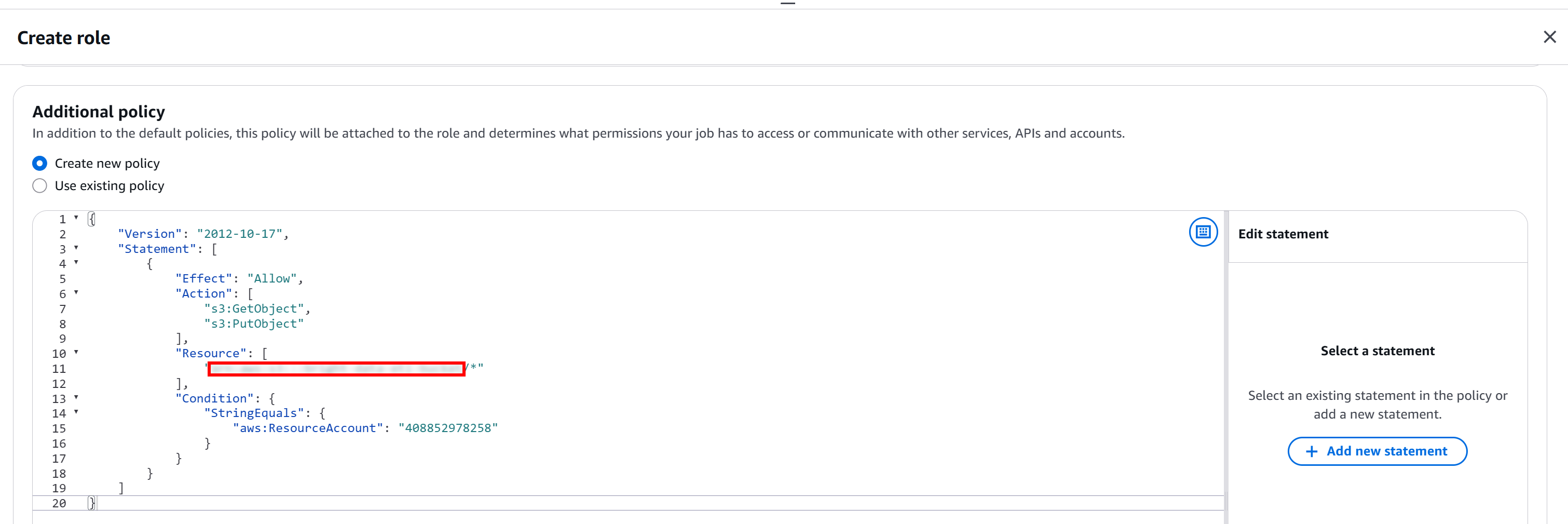
这条信息用于覆盖 AWS Glue 提供的默认策略。具体来说,把 S3 存储桶 ARN 粘贴到 “Create role” 页面中 “Additional policy” 文本编辑器的 “Resource” 字段里:
"Resource": {
"<YOUR_S3_BUCKET_ARN>/*"
}
最后点击 “Create role” 按钮。创建完成后,该角色会自动出现在你的 AWS Glue 作业配置中: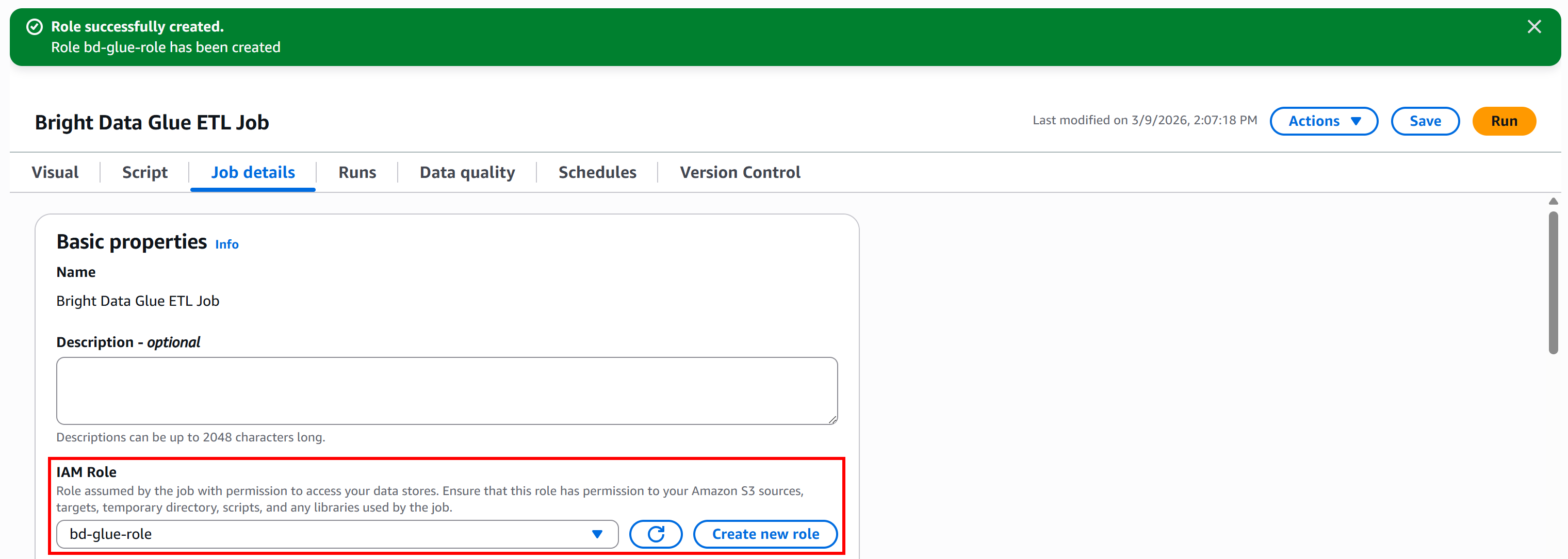
很好!你的 AWS Glue 作业现在拥有访问 S3 并运行 ETL 管道所需的 IAM 权限角色。
步骤 #6:在管道中添加 Extract(E)节点
管道的 Extract(E) 阶段在你运行 Bright Data 抓取工具、收集股票数据并上传到 Amazon S3 时就已经开始了。
现在的目标是让 AWS Glue ETL 管道连接到这些数据以便处理。为此,进入 “Add nodes” 面板的 “Sources” 标签页并选择 “Amazon S3” 节点。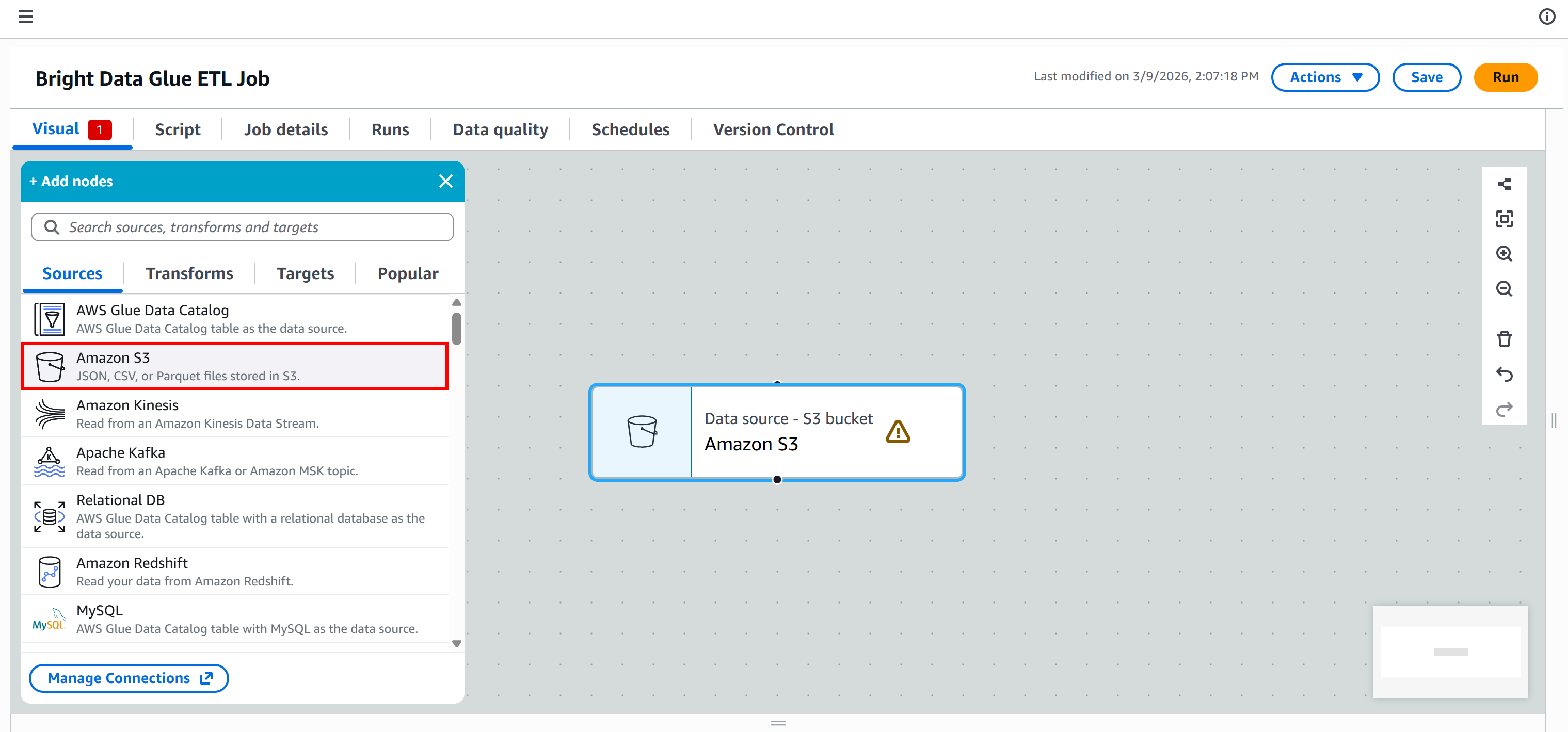
画布上会出现一个 “Data source – S3 bucket – Amazon S3” 节点。点击它并配置 S3 数据源: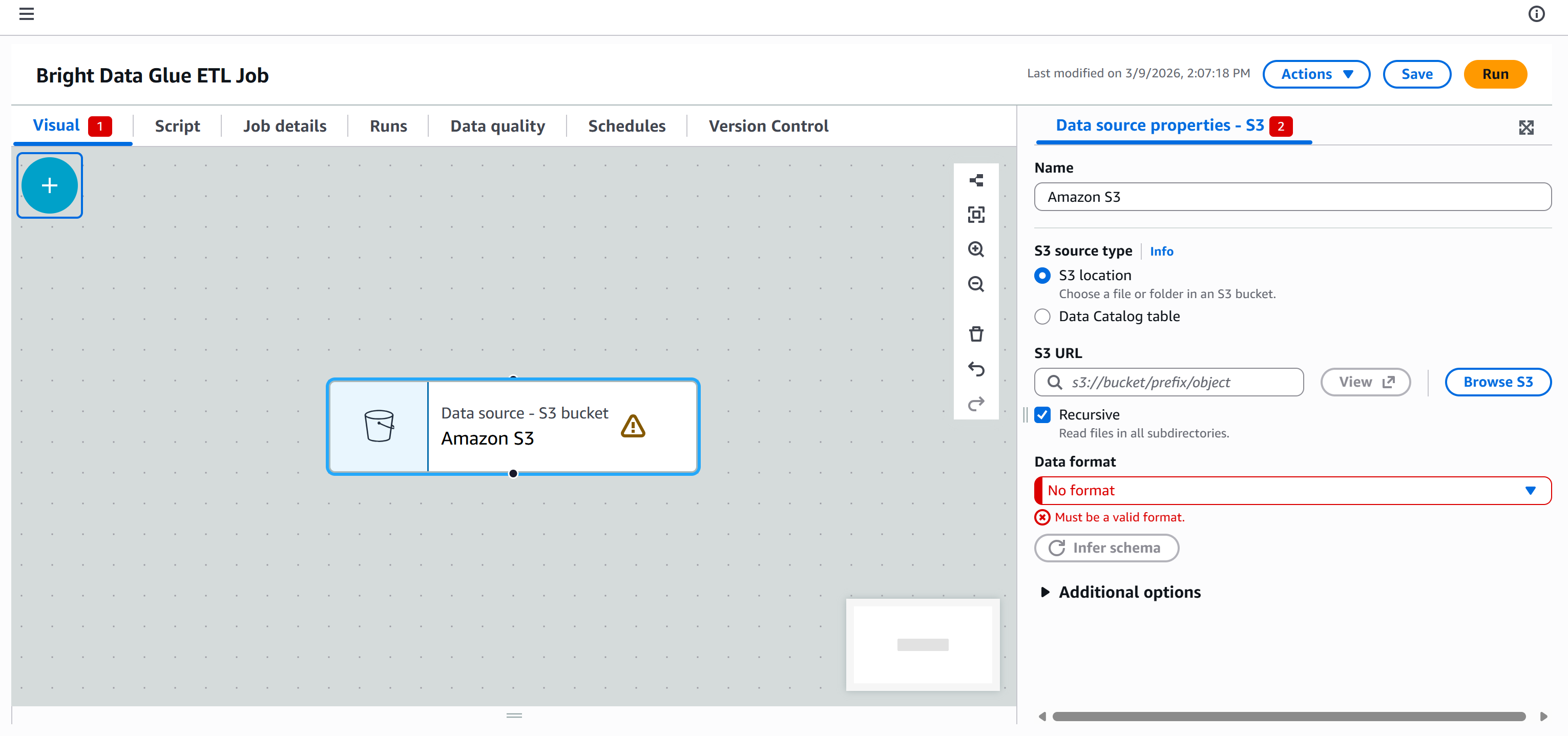
点击 “Browse S3” 按钮并选择你的 S3 存储桶(例如 bright-data-etl-bucket)。
选择存储桶后,AWS Glue 会在 “S3 URL” 字段填入类似如下内容:
s3://bright-data-etl-bucket默认情况下,AWS Glue 会尝试读取指定 S3 路径下的所有文件。由于我们知道输入文件的确切名称,请更新 “S3 URL” 以直接指向该文件:
s3://bright-data-etl-bucket/stocks.json这会告诉 AWS Glue 使用之前上传的 stocks.json 文件,其中包含由 Yahoo Finance Scraper 抓取的数据。
接下来,配置数据格式。由于输入数据集是 JSON 文件,请选择 “JSON” 作为输入格式。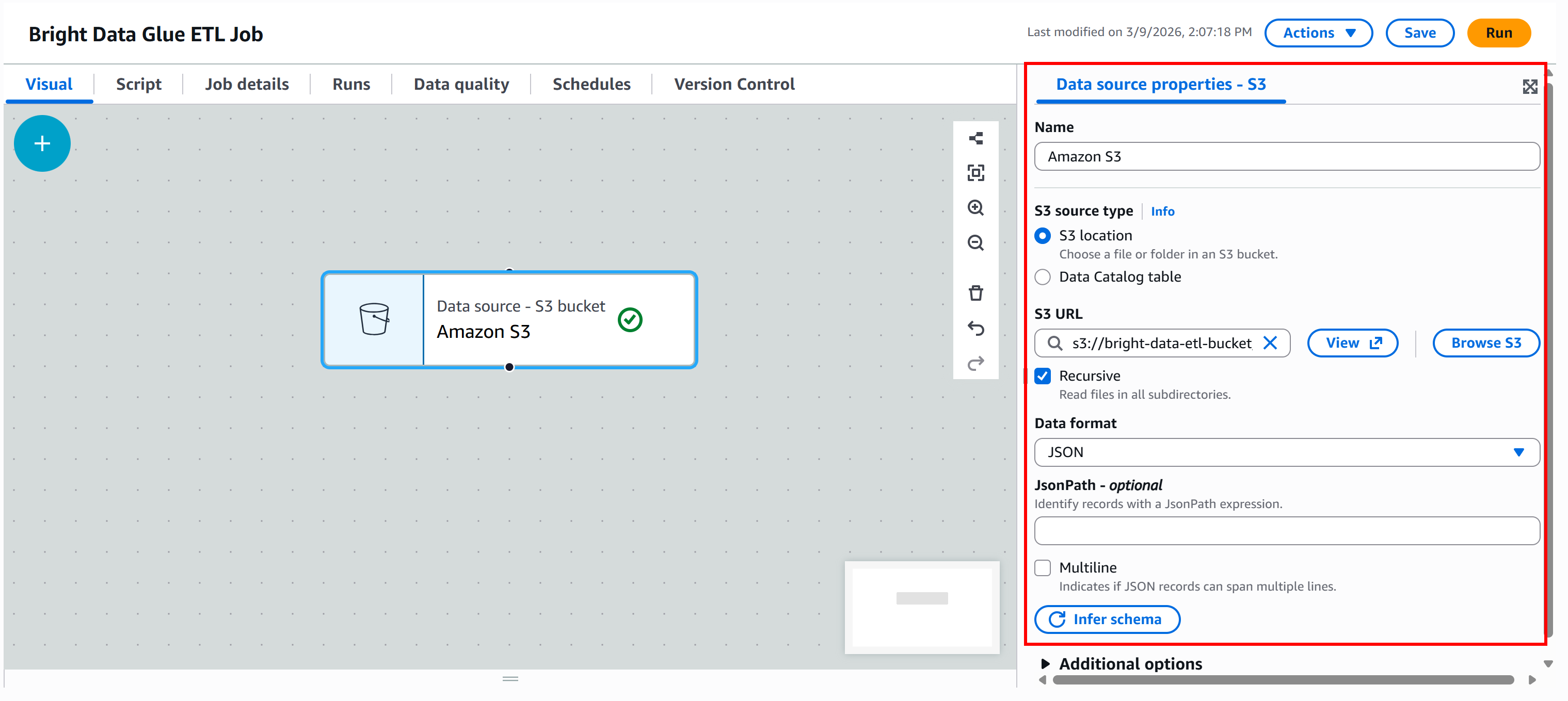
然后点击 “Infer schema” 按钮。AWS Glue 会自动分析输入 JSON 文件并生成相应 schema。
在节点的 “Output schema” 部分,你会看到从 JSON 数据中推断出的结构: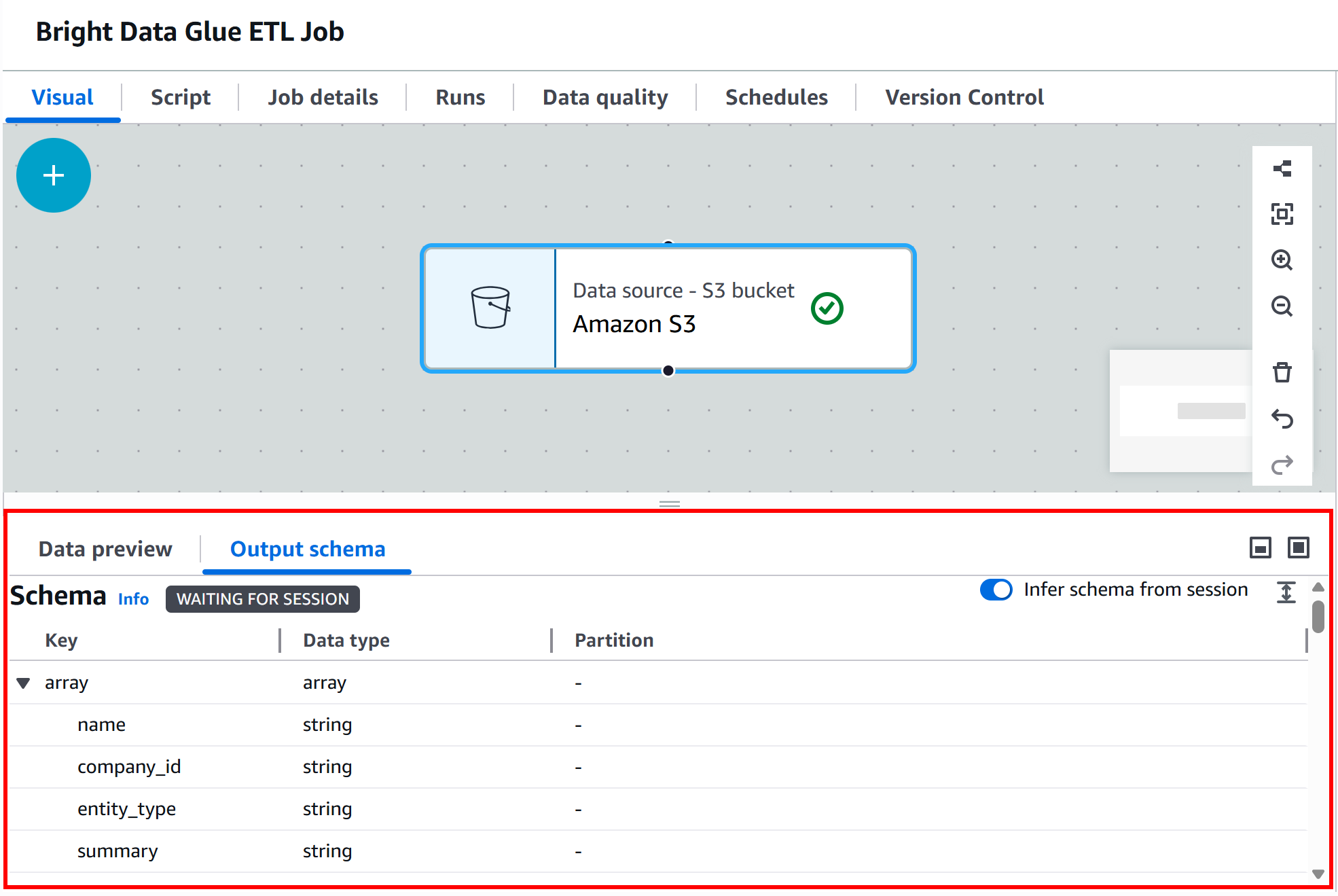
推断出的 schema 与 Bright Data Yahoo Finance 抓取工具返回的输出数据 schema 一致。很酷!
步骤 #7:定义 Transform(T)逻辑
如前所述,这只是一个简单示例,因此 Transform(T) 步骤会保持最小化。目标是通过 SQL 查询过滤源数据,仅保留市盈率(P/E)小于 30 的公司。
为此,进入 “Transforms” 标签页并选择 “SQL Query” 节点: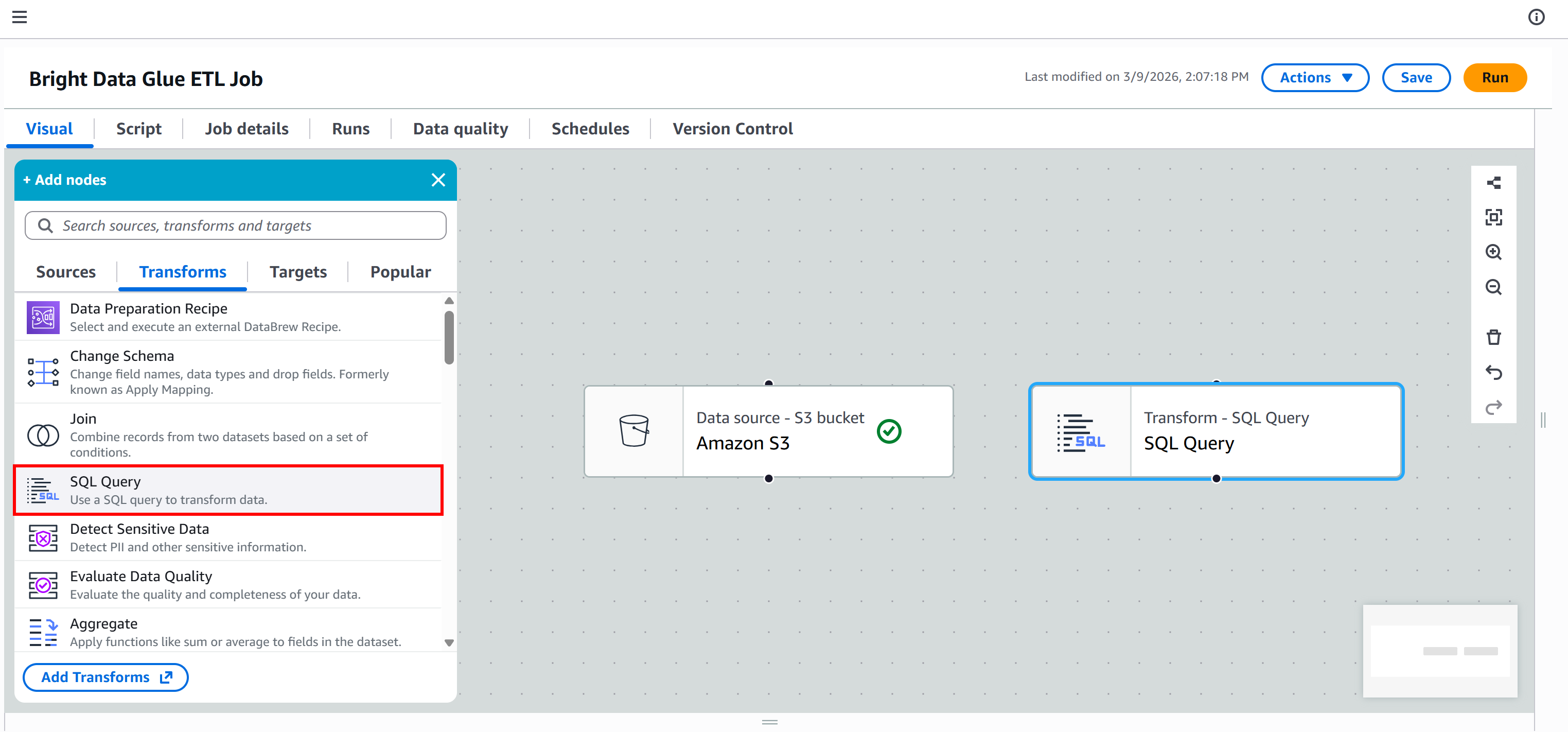
该节点会被添加到画布。点击并配置它,使其父节点为 “Amazon S3”。这意味着 Amazon S3 节点的输出成为 “SQL Query” 节点的输入。换句话说,你将在抓取到的 JSON 数据上执行 SQL 查询。
接着,将输入数据集的别名定义为 stocks,并添加这条 SQL 查询:
select stock_ticker, pe_ratio from stocks
WHERE pe_ratio < 30;该查询从每条抓取的股票记录中选择 stock_ticker 和 pe_ratio 字段,仅保留市盈率小于 30 的记录。
如果你想知道这些字段从何而来:stock_ticker 与 pe_ratio 是 Bright Data Yahoo Finance 爬虫工具返回的属性之一(AWS Glue 已在上一步自动推断出来):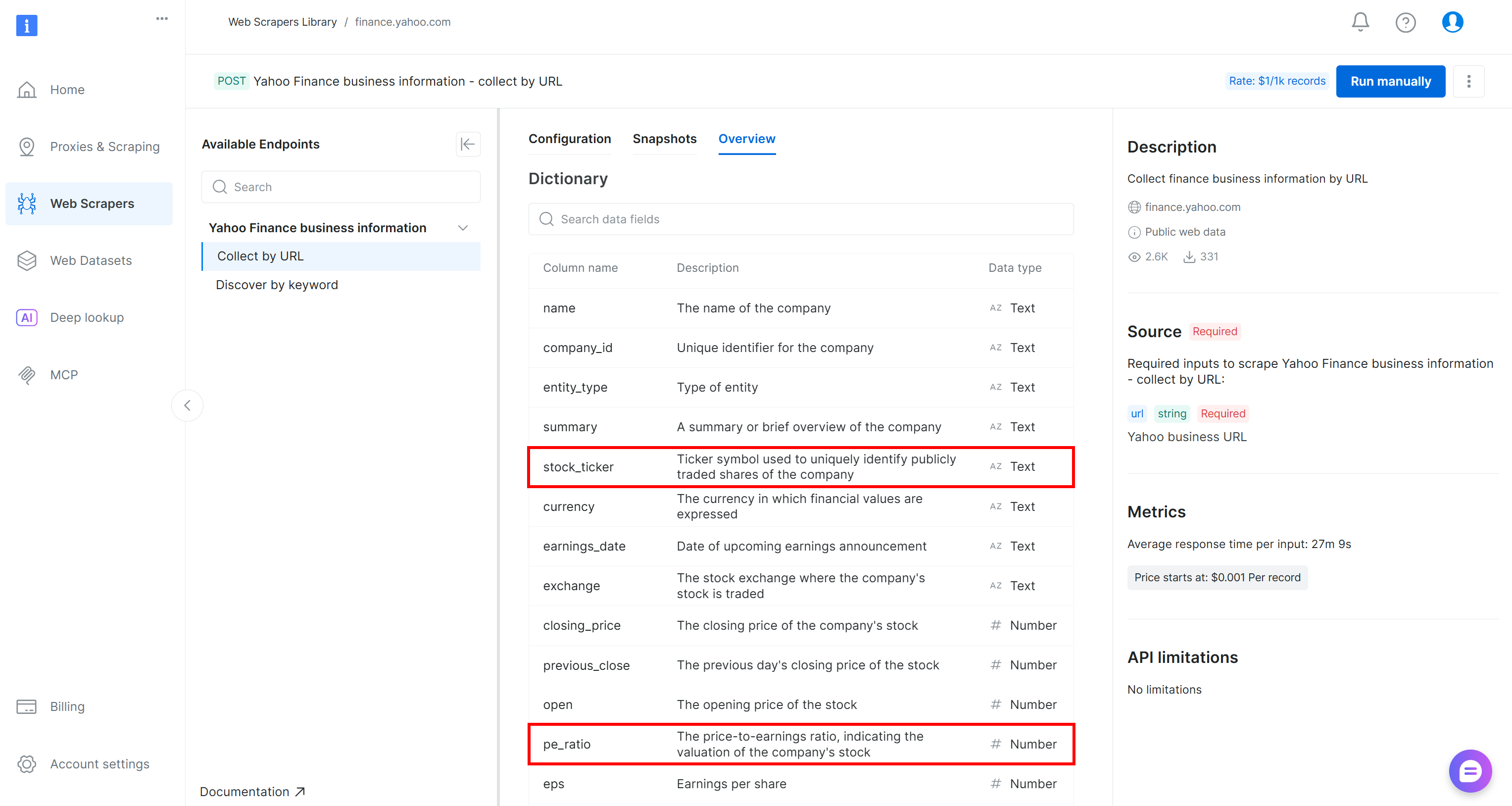
此时,你的 ETL 管道应如下所示: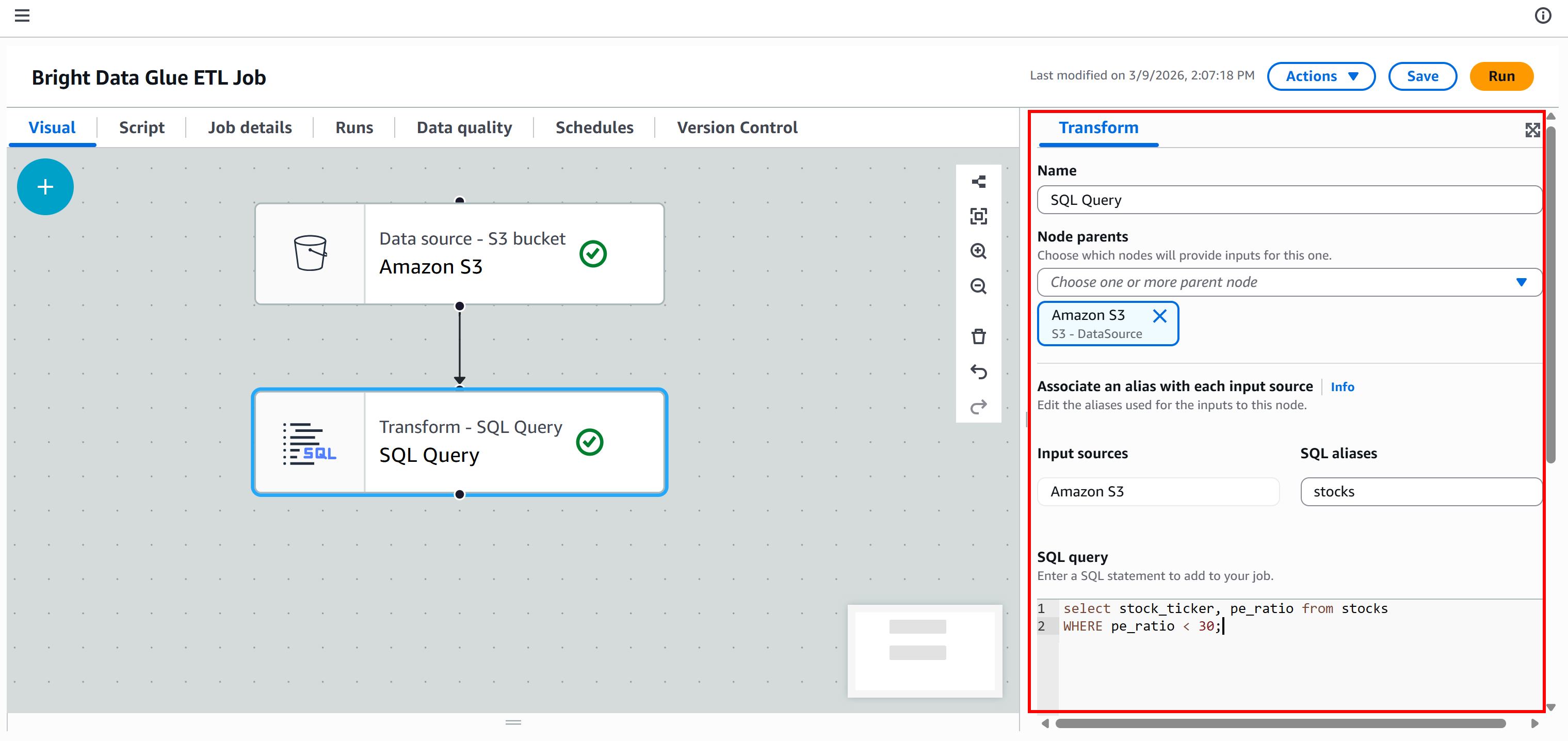
注意:在真实生产管道中,Transform(T) 阶段通常包含多个步骤。你可以通过添加多个 transform 节点并按顺序连接它们来实现,或在工作流中创建多个分支。
步骤 #8:在 Load(L)阶段连接到你的 S3 存储桶
“SQL Query” 节点的输出就是过滤并转换后的数据。最后一步是将这些数据存储到你的 S3 存储桶中,以完成 ETL 管道的 Load(L) 阶段。
在 “Targets” 标签页中,再添加一个 Amazon S3 节点: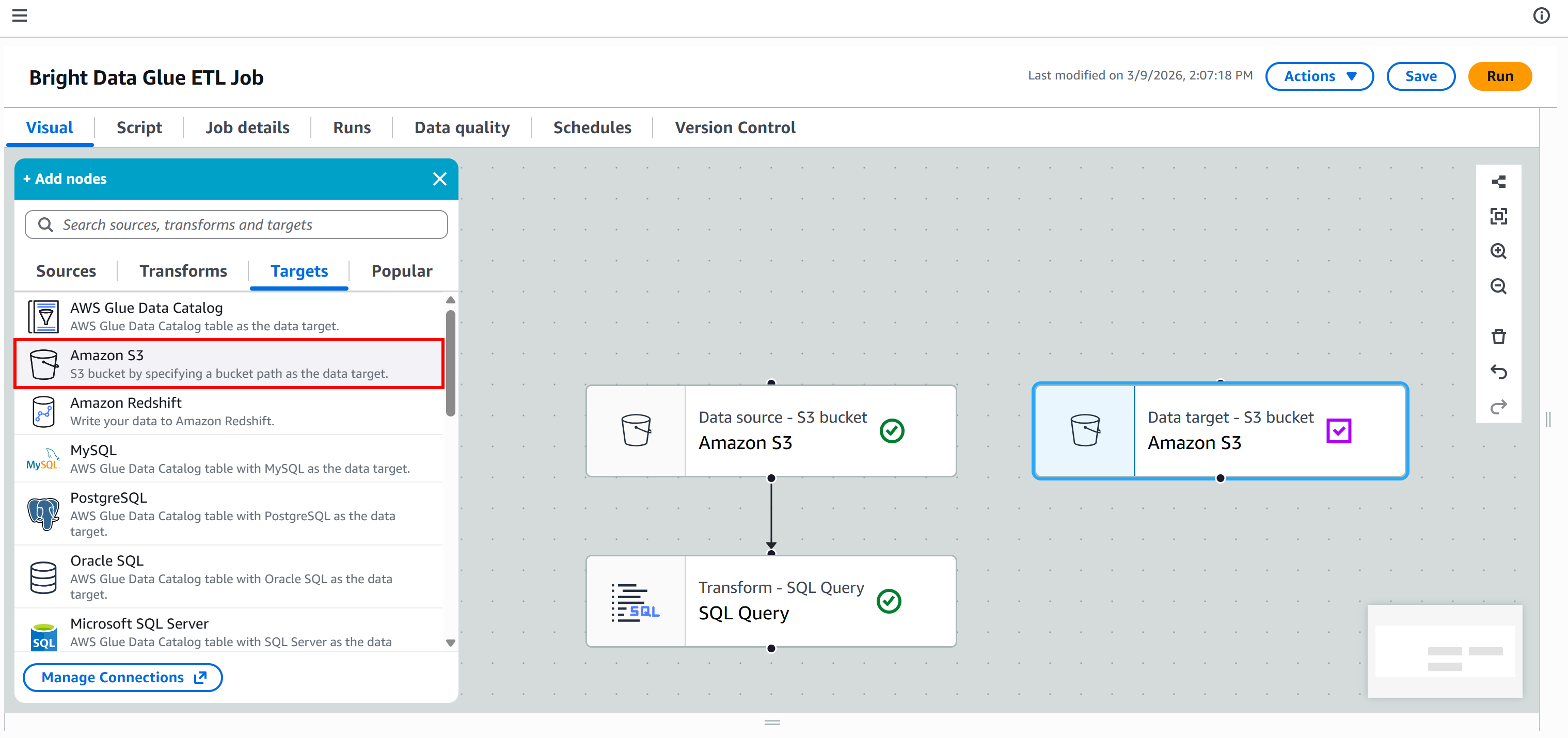
点击新节点进行配置。将父节点设置为你的 “SQL Query” 节点。“SQL Query” 节点的输出会作为输入发送到新的 Amazon S3 节点。
将输出格式定义为 “JSON”,不启用压缩。然后指定目标输出 S3 文件夹,例如:
s3://bright-data-etl-bucket/output/注意:请确保将 bright-data-etl-bucket 替换为你实际的 S3 存储桶名称。
这样,转换后的数据会被存入 /output 文件夹中。
其余选项保持默认,然后点击 “Save” 更新你的 AWS Glue ETL 作业: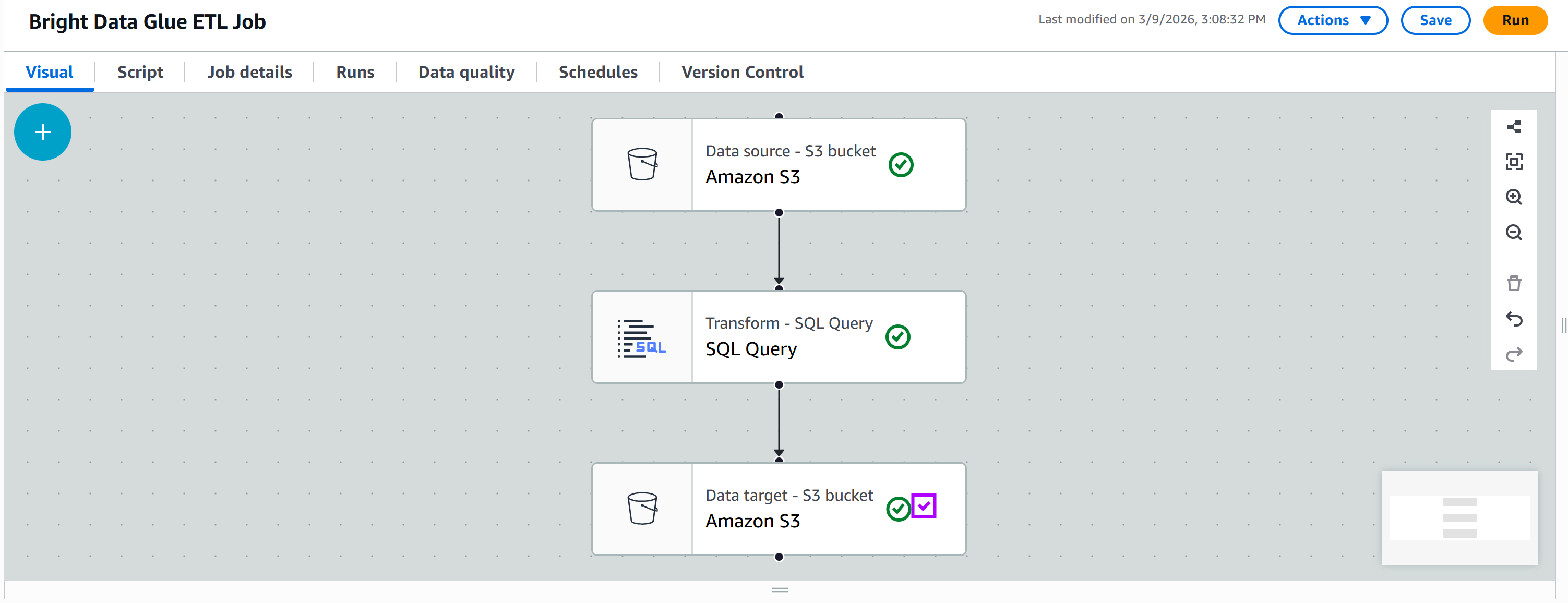
太好了!你的 ETL 管道现已完全配置完成,随时可以运行。
步骤 #9:运行管道并查看结果
点击 “Run” 按钮启动 AWS Glue 作业。你会看到类似如下通知:
切换到 “Runs” 标签页监控管道执行情况: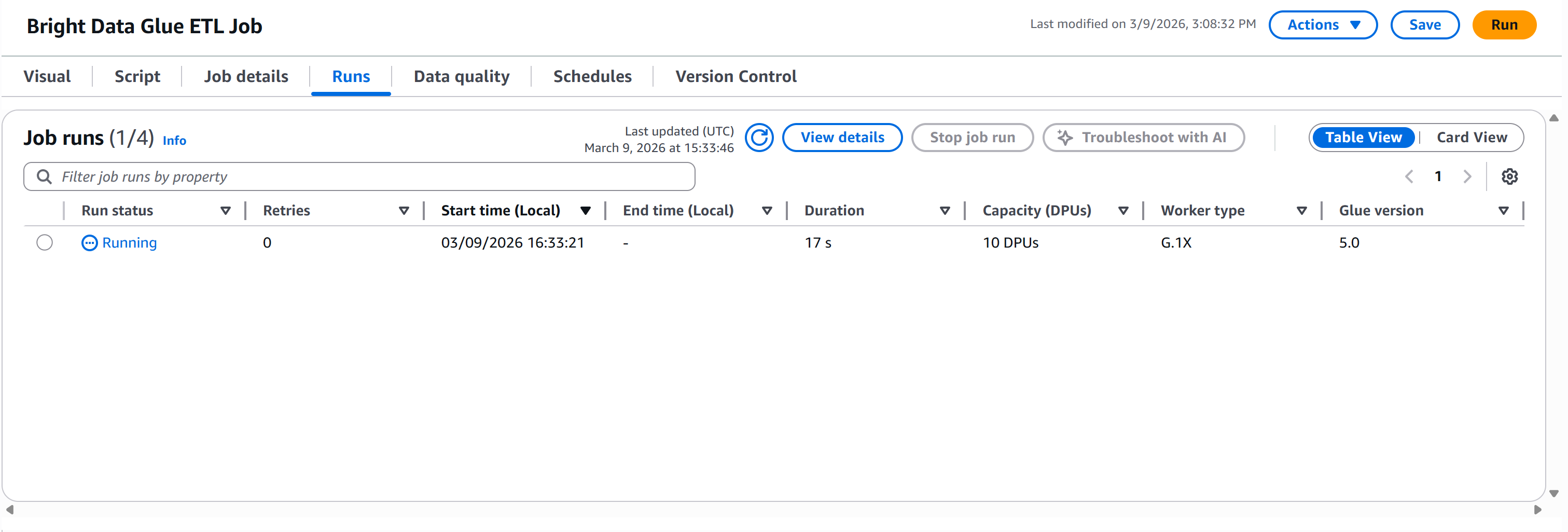
等待 “Run status” 变为 “Succeeded”。这可能需要超过一分钟,请耐心等待:
完成后,输出文件会出现在 S3 存储桶的 /output 文件夹中: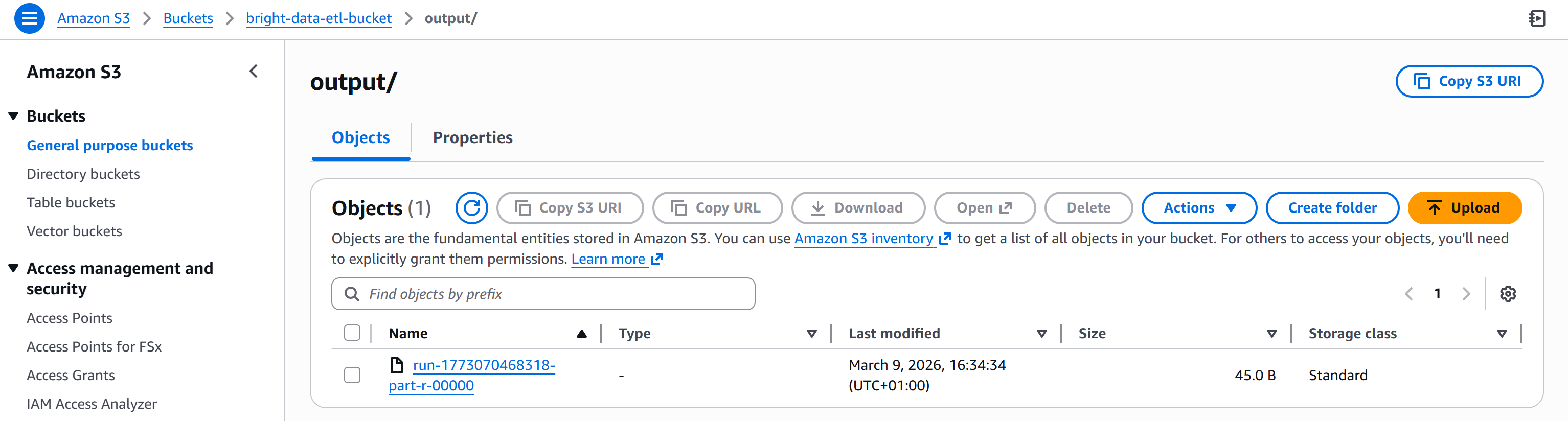
打开生成的文件,你将看到市盈率低于过滤阈值(例如小于 30)的股票列表:
如你所见,结果股票包括 AMZN、BRK.B、META、MSFT 和 GOOGL。
Voilà!你刚刚构建了一个与 Bright Data 集成的 AWS Glue ETL 管道。Extract 阶段利用 Bright Data 的网页爬虫工具 API,Transform 阶段使用 SQL 过滤数据,Load 阶段将结果存回 S3。
AWS Glue ETL 作业中其他 Bright Data 集成思路
毫无疑问,Bright Data 凭借其 网页数据获取能力,能够在 ETL 管道的 Extract 阶段发挥重要作用。
不过,Bright Data 也不止能用于提取,还可在包括 Transform 阶段在内的环节用于数据增强、校验或验证。例如,你可以:
- 增强公司画像:使用 ZoomInfo 抓取工具 为从网页来源提取的记录追加企业画像数据(firmographic)。
- 验证员工信息:集成 LinkedIn Profiles 来核验职位、邮箱或社交资料。
- 获取竞品定价或产品详情:使用 Amazon 爬虫工具 或 Amazon Reviews 抓取工具 以市场洞察丰富数据集。
- 添加 SEO 或搜索数据:使用 SERP API 将搜索引擎排名数据或关键词洞察纳入转换后的数据集,并用于数据验证。
如果你想知道如何实现该集成,请参考官方指南:定义自定义可视化 transforms。你只需包含一个带描述信息的 JSON 文件,以及一个包含 Bright Data API 集成逻辑的 Python 文件即可。
结论
在本教程中,你了解了 AWS Glue 是什么,以及 Bright Data 如何通过多种网页抓取解决方案增强其能力。
尤其是,你看到了 Bright Data 的 Web Scraping APIs 如何同时支持 ETL 管道的 Extract(E) 和 Transform(T) 阶段(无论是获取原始数据、丰富数据集,还是验证信息)。
立即创建一个免费的 Bright Data 账户,开始探索我们的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




