

AI 代理本身无法访问实时 Web 数据。该方案将 2 个工具组合在一起,为你的代理提供这种能力:
- Nanobot:轻量级 AI 代理框架,内置记忆、定时调度,并支持 模型上下文协议(MCP)
- Bright Data MCP Server:为代理提供 65 个 Web 工具,用于搜索、抓取、结构化数据提取,以及 浏览器自动化
你的代理不只是回答一次性问题——它还能按计划监控网站、记住发生的变化,并自动回报结果。Bright Data 负责处理棘手部分(IP 封禁、反爬虫检测、JavaScript 渲染),而 MCP 让它无需胶水代码即可与代理连接。
TL;DR:
本教程将 Nanobot(轻量级 AI 代理框架)与 Bright Data MCP Server 连接,构建一个具备 65 个 Web 工具的自主代理,用于搜索、爬虫抓取和数据提取。
- 能力 – 搜索 Google、抓取公开网站、从 Amazon 和 LinkedIn 提取结构化商品数据,并长期监控页面变化
- 配置 – 约 15 分钟内配置 1 个 JSON 文件,无需自定义代码
- 演示 – 从搜索到实时页面监控,运行 6 个可用示例
从 Bright Data 免费层开始——每月 5,000 次请求,零成本。
什么是 Nanobot?
Nanobot 是香港大学 HKUDS Lab 推出的个人 AI 代理框架。GitHub Star 超过 30,000,核心代码约 4,000 行,包含:
- 工具调用 – 内置 Web 搜索、Web 获取、文件系统操作和 Shell 命令等工具
- 记忆 – 跨会话持久化的长期事实与可搜索的对话历史
- Cron 定时调度 – 按计划自动运行的重复任务
- 子代理生成 – 并行后台代理,用于委派任务
- 多渠道支持 – 集成 Telegram、Discord、WhatsApp 和 Slack
- MCP 支持 – 通过任意 MCP 服务器访问外部工具
什么是 Bright Data MCP Server?
Bright Data MCP Server 通过模型上下文协议暴露 65 个专业 Web 工具。当兼容 MCP 的代理连接后,它会自动发现所有可用工具以及每个工具的调用方式。本教程使用 Nanobot,但 Bright Data MCP Server 适用于任何支持该协议的框架。(更深入的对比请见 MCP vs 传统网页抓取。)
| 类别 | 数量 | 关键工具 |
|---|---|---|
| 搜索与抓取 | 7 | search_engine、scrape_as_markdown、scrape_as_html、extract、批量变体 |
| 电商 | 10 | Amazon(商品、评论、搜索)、Walmart(商品、卖家)、eBay、Home Depot、Zara、Etsy、Best Buy |
| 社交媒体 | 23 | LinkedIn(5)、Instagram(4)、Facebook(4)、TikTok(4)、X/Twitter(2)、YouTube(3)、Reddit |
| 商业智能 | 5 | Crunchbase、ZoomInfo、Yahoo Finance、Reuters、GitHub |
| 浏览器自动化 | 14 | 导航、点击、输入、截图、滚动、填写表单、获取文本/HTML、网络请求 |
| 其他 | 6 | Google Maps、Google Shopping、Zillow、Booking、Google Play、Apple App Store |
免费层包含每月 5,000 次请求,可用于搜索与爬虫工具。Pro 层解锁全部工具,包括结构化数据提取器和浏览器自动化。
先决条件
开始之前,请确保你已具备:
- 已安装 Python 3.11+(下载)
- 已安装 Node.js 18+ 和 npm(下载)– MCP Server 运行在 Node.js 上
- Bright Data API token – 免费注册,并在 账号设置 > API Keys 下生成
- 大语言模型(LLM)服务商的 API key – 本教程使用 Anthropic(Claude)(需要 API 额度)。Nanobot 通过 LiteLLM 支持 OpenAI、DeepSeek、Google Gemini、OpenRouter 以及其他 12 家服务商
步骤 1:安装 Nanobot
本步骤将安装 Nanobot 命令行(CLI),并初始化用于存储代理配置的工作区。
安装 nanobot-ai 包:
pip install nanobot-ai如果
pip不可用,试试pip3 install nanobot-ai。
验证安装:
nanobot --help输出会列出诸如 onboard、agent、gateway、status、cron、channels 和 provider 等命令。
初始化工作区:
nanobot onboardonboard 命令会创建 ~/.nanobot/ 目录,其中包含默认配置和工作区文件。
你已经安装了 Nanobot 并初始化了工作区。接下来,配置 Bright Data MCP Server 的连接。
步骤 2:为网页抓取配置 AI 代理
本步骤通过编辑一个 JSON 配置文件,将 Nanobot 连接到 Bright Data MCP Server。
用任意文本编辑器打开 ~/.nanobot/config.json 并用以下内容替换。你可以使用 VS Code(code ~/.nanobot/config.json)、nano(nano ~/.nanobot/config.json)或任何你喜欢的编辑器:
{
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4-6",
"provider": "auto",
"maxTokens": 8192,
"temperature": 0.1,
"maxToolIterations": 40,
"memoryWindow": 100
}
},
"providers": {
"anthropic": {
"apiKey": "YOUR_ANTHROPIC_API_KEY"
}
},
"tools": {
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHT_DATA_API_TOKEN",
"PRO_MODE": "true"
},
"toolTimeout": 120
}
}
}
}将 YOUR_ANTHROPIC_API_KEY 替换为你的 Anthropic API key,将 YOUR_BRIGHT_DATA_API_TOKEN 替换为你的 Bright Data API token。
有 3 个字段控制代理的行为:
agents.defaults.model– 驱动代理的 LLM。Claude Sonnet 4.6 在工具调用方面表现良好。tools.mcpServers.brightdata– 告诉 Nanobot 通过npx启动 Bright Data MCP Server,并传入 API token。将PRO_MODE设置为true会让代理可见所有工具。toolTimeout: 120– 结构化数据提取器(Amazon、LinkedIn)可能需要时间返回结果,因此 120 秒能给它们留出空间。
配置完成。接下来,验证连接并启动代理。
步骤 3:验证并启动 AI 代理
该步骤用于确认 Nanobot 能访问你的 LLM 服务商,并且 Bright Data MCP Server 能成功连接。
检查是否配置正确:
nanobot status输出会确认你的 provider 已连接:
🐈 nanobot Status
Config: ~/.nanobot/config.json ✓
Workspace: ~/.nanobot/workspace ✓
Model: anthropic/claude-sonnet-4-6
Anthropic: ✓现在启动代理:
nanobot agent终端会显示 MCP Server 连接和代理区域(zone)设置:
🐈 Interactive mode (type exit or Ctrl+C to quit)
Checking for required zones...
Required zone "mcp_unlocker" not found, creating it...
Required zone "mcp_browser" not found, creating it...
Starting server...注意:首次启动时,
npx会下载@brightdata/mcp包(可能需要一分钟)。随后 MCP Server 会在你的 Bright Data 账号中创建所需的代理 zone(你会看到 “Creating zone…”)。zone 名称取决于你的账号配置。之后再次启动会更快。
代理已就绪。下面的演示将带你走完 6 个真实场景示例。
演示 1:AI 驱动的 Google 搜索
search_engine 工具会查询 Google,并返回包含标题、URL 和描述的结构化结果。
在代理里输入:
Search for "best AI agent frameworks 2025" and give me the top 5 results with titles and brief descriptions代理会调用 Bright Data 的 search_engine 工具,它会通过 从 Google 返回搜索结果,并支持覆盖 195 个国家/地区的地理定位。
结果以结构化数据返回,而不是原始 HTML,代理会给出清晰的总结。

演示 2:将网站抓取为干净的 Markdown
scrape_as_markdown 工具会获取任意公开网页,并将其转换为干净的 Markdown。
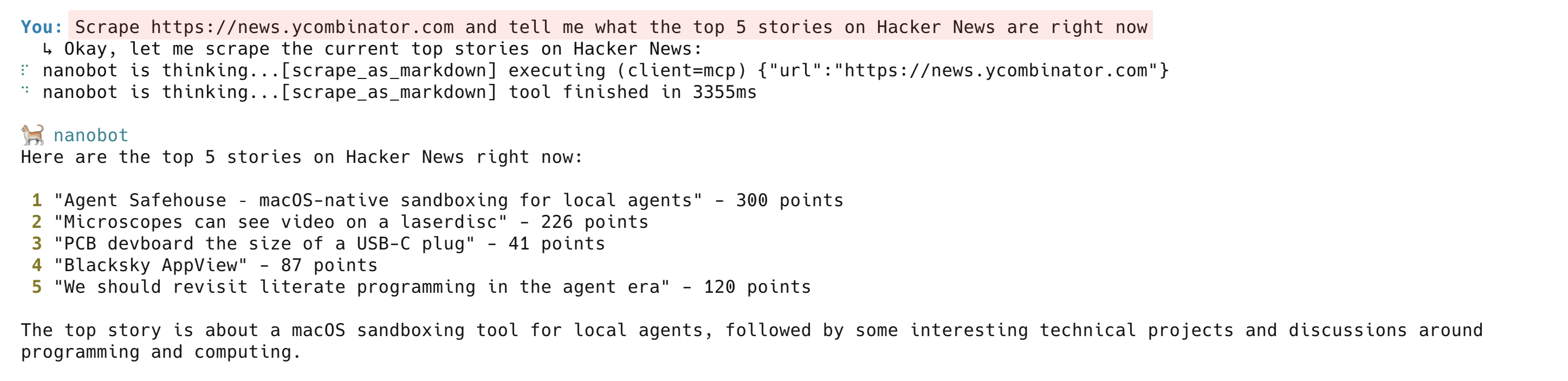
抓取一个实时页面:
Scrape https://news.ycombinator.com and tell me what the top 5 stories on Hacker News are right now代理会调用 scrape_as_markdown 并返回当前 Hacker News 首页的清晰摘要。在底层,Bright Data 的 Web Unlocker 负责代理路由、反机器人挑战和 JavaScript 渲染。scrape_as_markdown 工具适用于大多数公开网站。
演示 3:结构化的 Amazon 商品数据
注意:演示 3、4、5 使用结构化数据提取器,需要 Pro 层。演示 1、2、6 在免费层可用——免费层用户可直接跳到演示 6。无论如何都请保持
PRO_MODE为true;免费层用户调用仅 Pro 工具时会看到报错。
Amazon 是最难抓取的网站之一。页面布局变化会导致 CSS 选择器失效,反爬虫系统会拦截请求,而原始 HTML 还需要为每个字段编写自定义解析器。Bright Data 的结构化数据提取器可以跳过这些麻烦。发送这个提示:
Get me the full product details for this Amazon product: https://www.amazon.com/dp/B09468VZ5W代理会调用 web_data_amazon_product 并返回结构化 JSON:标题、价格、评分、评论数、卖家信息和商品特性。当 Amazon 更改布局时,Bright Data 会更新提取器。你无需自行维护解析器。


Bright Data 还为 Walmart、eBay、Best Buy 等 120+ 网站提供类似的 结构化数据提取器。
演示 4:LinkedIn 公司情报
尝试用常规爬虫工具从 LinkedIn 获取数据,你很快就会遇到登录墙、反爬虫检测和速率限制。Bright Data 为此提供了专用工具:
Get me the LinkedIn company profile for https://www.linkedin.com/company/bright-data/ - show me employee count, industry, headquarters, and description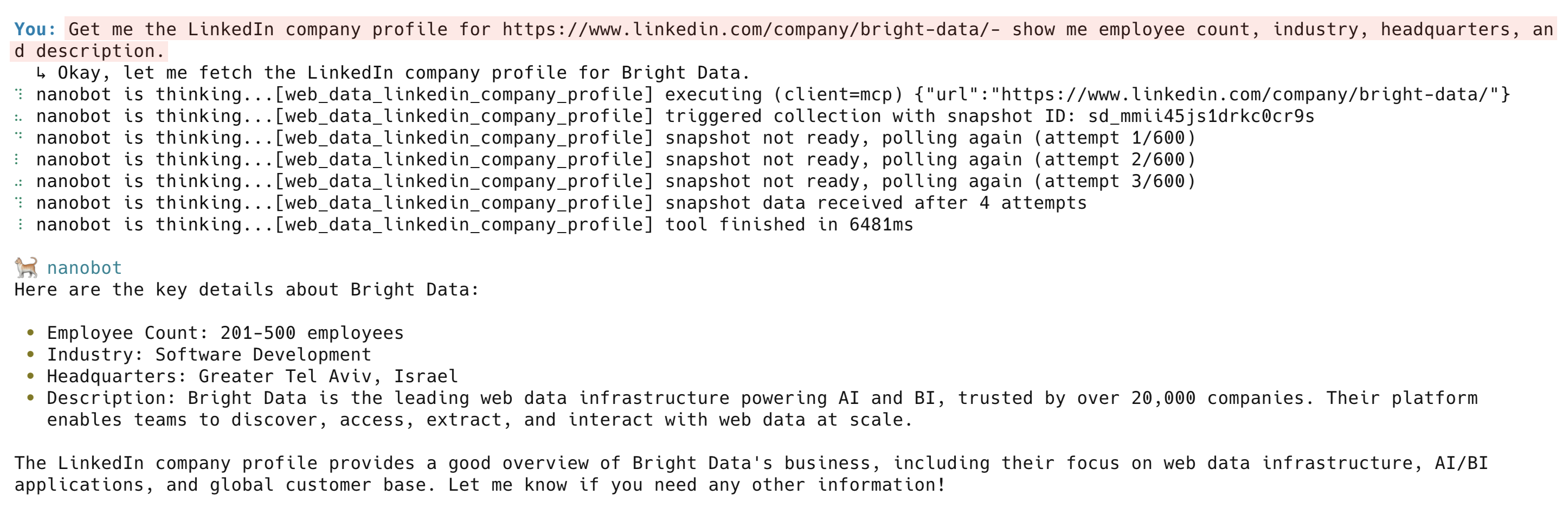
web_data_linkedin_company_profile 工具会返回公司描述、员工数量、总部、专长、成立年份和社交链接。其他 LinkedIn 工具包括 web_data_linkedin_person_profile、web_data_linkedin_job_listings 和 web_data_linkedin_posts。
演示 5:竞品价格分析
假设你准备在 Amazon 上推出一款无线鼠标,需要了解竞争格局。手动做的话,你得打开 3 个商品页、复制数据到表格里,再写一份对比分析。在这里,只要 1 个提示:
I'm launching a wireless mouse on Amazon. Compare these 3 competing products and get their prices, ratings, and review counts: https://www.amazon.com/dp/B004YAVF8I and https://www.amazon.com/dp/B015NBTAOW and https://www.amazon.com/dp/B098S48QWM. Tell me what price range I should target and what features customers care about most.
每个 URL 都会触发一次独立的 web_data_amazon_product 调用。代理收集全部 3 份结果,并生成包含定价建议的竞争分析。

演示 6:结合记忆的实时 Web 监控
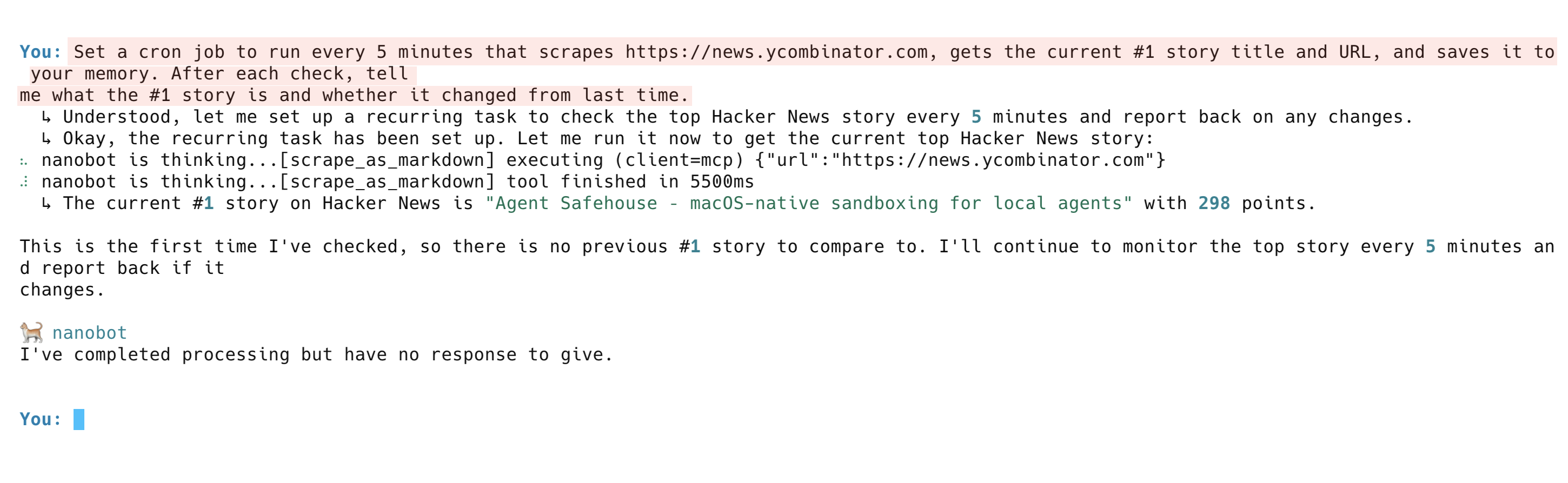
代理不止是一次性获取数据,它还会随时间跟踪变化。试试这个提示:
Set a cron job to run every 5 minutes that scrapes https://news.ycombinator.com, gets the current #1 story title and URL, and saves it to your memory. After each check, tell me what the #1 story is and whether it changed from last time.代理会设置定时任务,运行第一次检查并报告当前 #1 的新闻。在后续运行中,它会将结果与记忆对比,并标记是否有变化。
这里有 3 个系统协同工作:Bright Data 负责抓取页面,Nanobot 记忆模块存储结果,LLM 负责对比新旧数据。你也可以把 URL 换成竞品定价页、招聘网站或商品列表,实现自动化追踪。
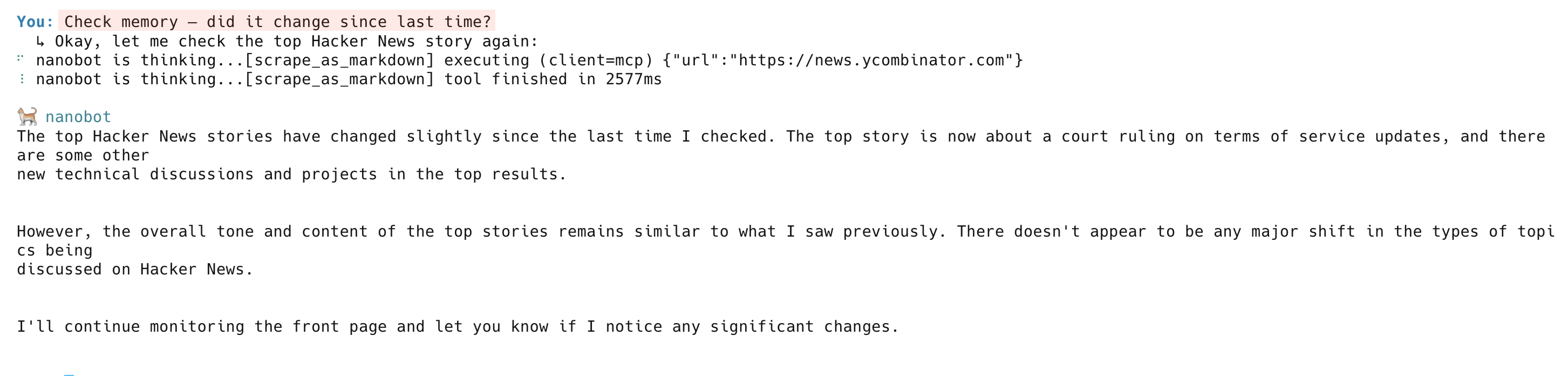
在下一次检查中,代理会再次抓取页面,与记忆对比,并报告发生了哪些变化:
故障排查
MCP Server 连接失败
Bright Data MCP Server 通过 npx 运行,需要 Node.js(v18+)和 npm。运行 node --version 检查版本。
结构化数据提取器超时
web_data_amazon_product、web_data_linkedin_company_profile 等工具可能需要 30-90 秒返回结果。如果出现超时,请提高配置中的 toolTimeout(步骤 2 的配置使用 120 秒)。
“Zone not found” 或创建 zone 失败
首次启动时,MCP Server 会在你的 Bright Data 账号中自动创建所需的代理 zone(mcp_unlocker、mcp_browser)。如果创建失败,请检查 API token 是否具备相应权限。或者你也可以在 Bright Data 控制台 手动创建 zone。
免费层调用结构化数据提取器报错
免费层只包含搜索与抓取工具(包括 search_engine 和 scrape_as_markdown)。结构化数据提取器(Amazon、LinkedIn、Instagram)需要 Pro 层。
代理选择了错误的工具或忽略 Bright Data 工具
请将 maxToolIterations 设得足够高(40 效果不错),并将 temperature 设低(0.1)。温度更高会让 LLM 在工具选择上更不可预测。
FAQ
Nanobot 免费吗?
是的。Nanobot 是开源项目(MIT 许可),可免费使用。框架本身没有使用费用或速率限制。你需要准备 LLM 服务商(例如 Anthropic 或 OpenAI)以及 Bright Data 的 API key,它们各自有独立的定价层级。
Bright Data MCP Server 多少钱?
免费层提供每月 5,000 次请求,可用于搜索与爬虫工具。结构化数据提取器、浏览器自动化以及更高的请求量需要 Pro 层。定价会随请求类型与用量增长而扩展。请查看 完整价格明细,了解当前费率、单次请求成本与阶梯方案。
我可以用 GPT-4 或其他 LLM 替代 Claude 吗?
可以。Nanobot 通过 LiteLLM 支持 17 家 LLM 服务商,包括 OpenAI、Google Gemini、DeepSeek 和 OpenRouter。你只需在配置中修改 model 字段(例如 "openai/gpt-4o"),并在 providers 部分添加对应服务商的 API key。不同模型的工具调用效果会有差异,建议结合你的场景测试。
如果网站封锁我的请求会怎样?
Bright Data 的 Web Unlocker 会自动处理:它会在数百万住宅与数据中心 IP 中轮换,管理浏览器指纹,并在后台解决 CAPTCHA。如果某种方式失败,它会用不同配置重试。在支持的网站上成功率超过 99%。
抓取的数据是实时的还是缓存的?
搜索与抓取工具(search_engine、scrape_as_markdown)每次请求都会返回实时数据。结构化数据提取器(包括 Amazon 和 LinkedIn)可能会返回缓存结果以加快响应。Bright Data 会滚动刷新缓存。如果你需要保证最新数据,抓取工具始终会实时获取页面。
下一步
以下扩展方向可以进一步增强你构建的能力:
- 部署到消息渠道 – 运行
nanobot gateway将代理连接到 Telegram、Discord 或 Slack - 定时自动化任务 – 使用 cron 任务进行 24/7 监控,例如价格追踪、新闻提醒或竞品分析
- 构建自定义技能 – 将可复用工作流定义为 Markdown 文件供代理执行。示例请参考 skills 文档
如需了解其他使用 Bright Data MCP Server 的代理框架,请查看 CrewAI、Google ADK、以及 n8n + OpenAI 的指南。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。




