在本指南中,您将学习如何使用n8n、OpenAI 和 Bright Data MCP Server 构建自动新闻抓取器。本教程结束时,您将能够执行以下操作。
- 创建自托管 n8n 实例
- 将社区节点安装到 n8n
- 使用 n8n 构建自己的工作流程
- 使用 OpenAI 和 n8n 集成人工智能代理
- 使用 Bright Data 的 MCP 服务器将 AI 代理连接到 Web Unlocker
- 使用 n8n 发送自动电子邮件
入门
首先,我们需要启动一个自托管的 n8n 实例。运行后,我们需要安装一个 n8n 社区节点。我们还需要从 OpenAI 和 Bright Data 获取 API 密钥,以执行我们的抓取工作流程。
启动 n8n
为 n8n 创建一个新的存储卷,并在 Docker 容器中启动它。
# Create persistent volume
sudo docker volume create n8n_data
# Start self-hosted n8n container with support for unsigned community nodes
sudo docker run -d
--name n8n
-p 5678:5678
-v n8n_data:/home/node/.n8n
-e N8N_BASIC_AUTH_ACTIVE=false
-e N8N_ENCRYPTION_KEY="this_is_my_secure_encryption_key_1234"
-e N8N_ALLOW_LOADING_UNSIGNED_NODES=true
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
-e N8N_HOST="0.0.0.0"
-e N8N_PORT=5678
-e WEBHOOK_URL="http://localhost:5678"
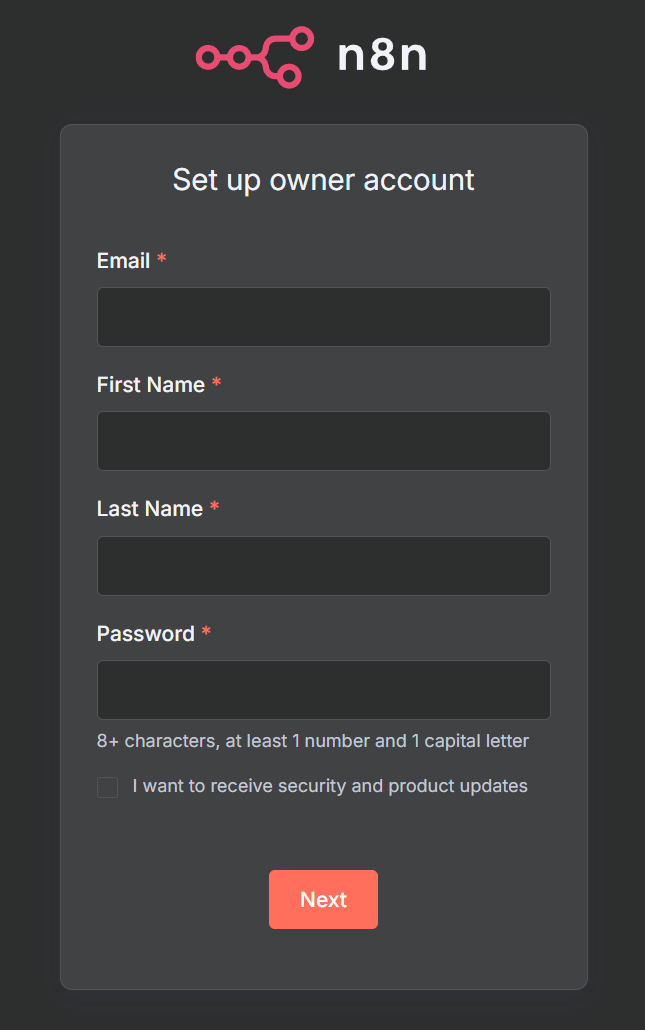
n8nio/n8n现在,在浏览器中打开http://localhost:5678/。系统可能会提示您登录或创建一个登录名。
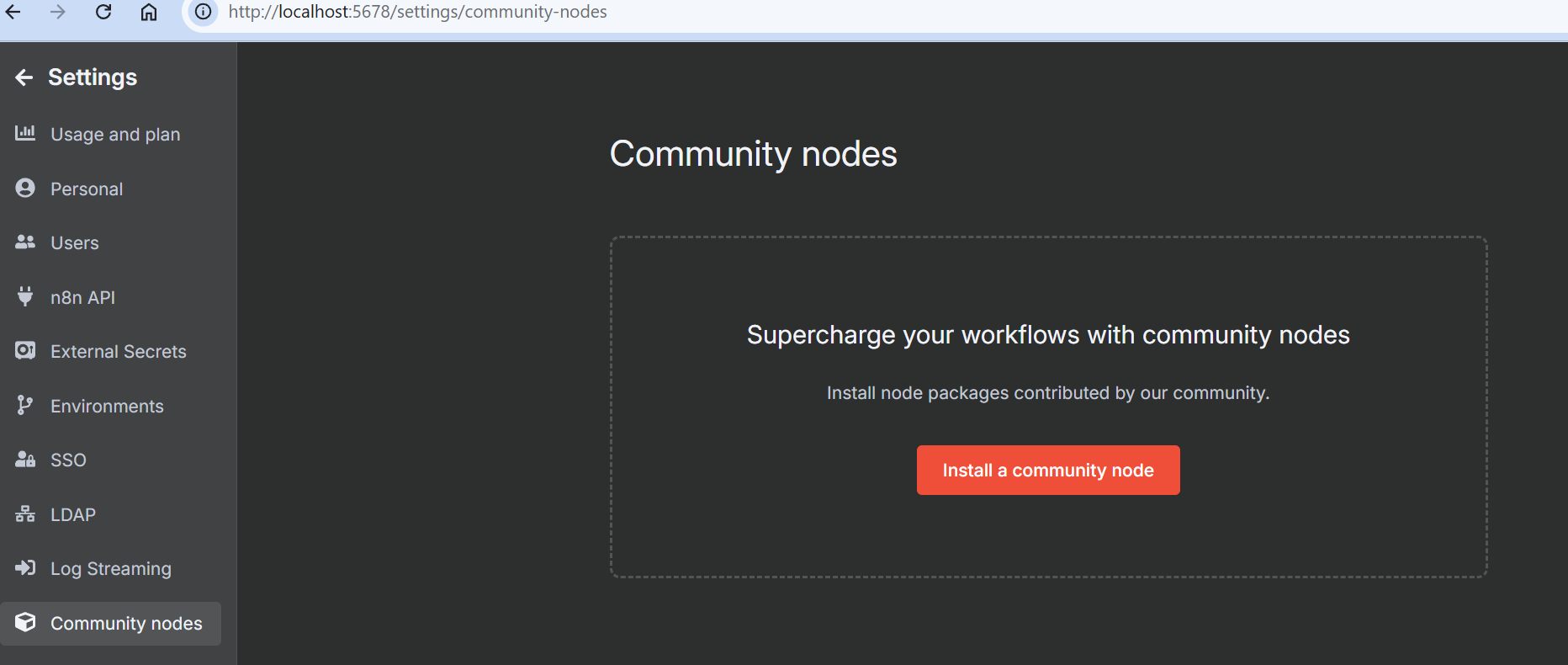
登录后,进入设置,选择 “社区节点”。然后点击 “安装社区节点 “按钮。
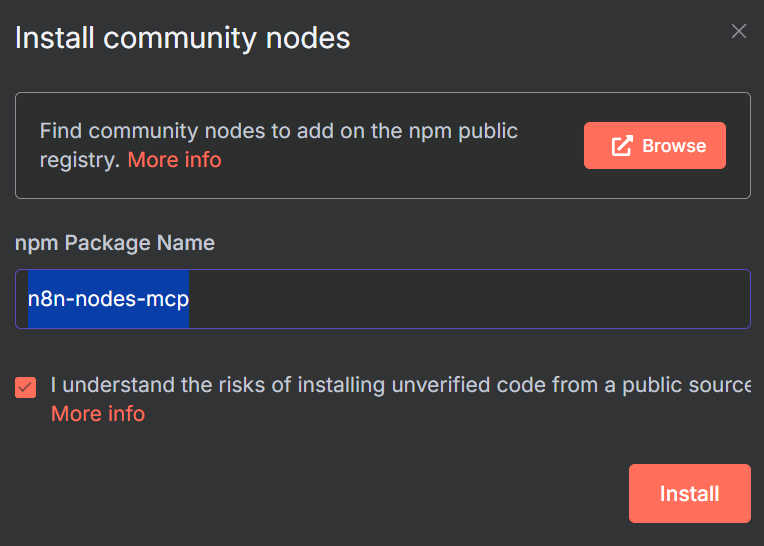
在 “npm 软件包名称 “下输入 “n8n-nodes-mcp”。
获取 API 密钥
您需要一个 OpenAI API 密钥和一个 Bright Data API 密钥。OpenAI 密钥可让您的 n8n 实例访问 GPT-4.1 等 LLM。Bright Data API 密钥可让您的 LLM 通过Bright Data 的 MCP Server 访问实时网络数据。
OpenAI API 密钥
前往 OpenAI 的开发者平台,如果还没有,请创建一个账户。选择 “API 密钥”,然后点击 “创建新密钥 “按钮。将密钥保存在安全的地方。
Bright Data API 密钥
您可能已经拥有 Bright Data 账户。即使有,您也应创建一个新的Web Unlocker区域。在 Bright Data 控制面板上选择 “代理和搜索”,然后点击 “添加 “按钮。

您可以使用其他区域名称,但我们强烈建议您将此区域命名为 “mcp_unlocker”。这个名称允许它与我们的 MCP 服务器一起工作,几乎是开箱即用。
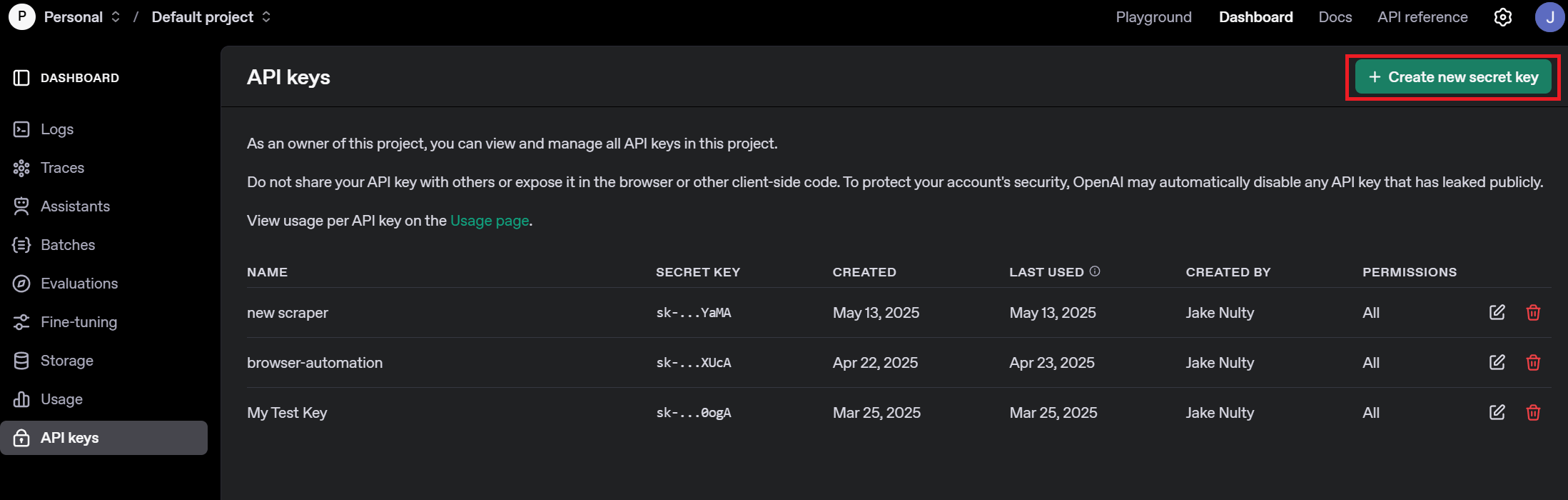
在账户设置中,复制您的 API 密钥并将其放在安全的地方。此密钥可访问您的所有 Bright Data 服务。
现在我们已经有了一个自托管的 n8n 实例和适当的证书,是时候建立我们的工作流程了。
建立工作流程
现在,我们要建立实际的工作流程。点击 “创建新工作流程 “按钮。这将为你提供一张空白的画布。
1.创建我们的触发器
我们先创建一个新节点。在搜索栏中输入 “聊天”,然后选择 “聊天触发器 “节点。
聊天触发器不会是我们的永久触发器,但它能让调试变得更容易。我们的人工智能代理将接收一个提示。有了聊天触发器节点,你就可以轻松尝试不同的提示,而无需编辑节点。
2.添加我们的代理
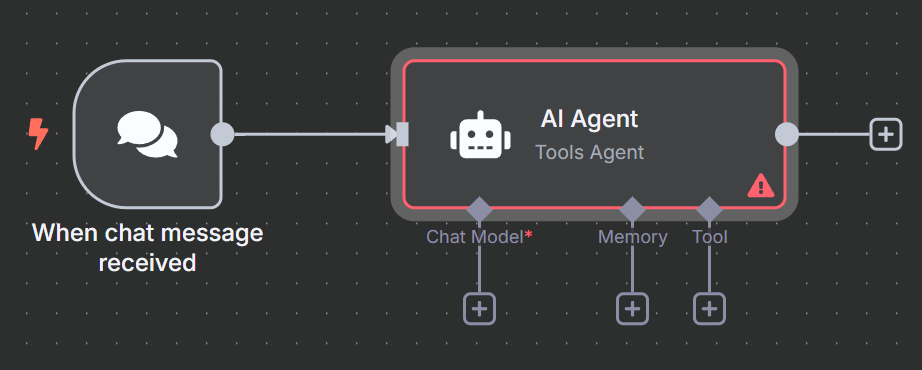
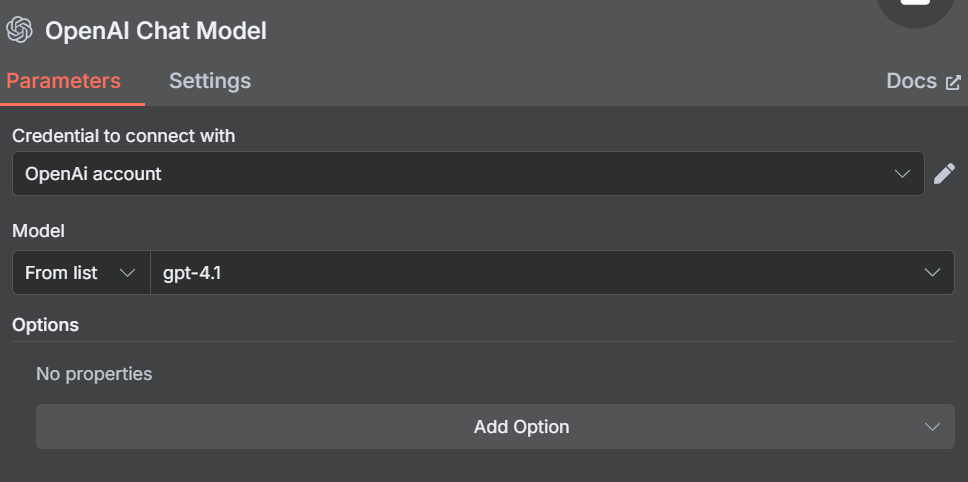
接下来,我们需要将触发器节点连接到人工智能代理。添加另一个节点,然后在搜索栏中输入 “ai agent”(人工智能代理)。选择 AI Agent 节点。

这个人工智能代理基本上包含了我们的整个运行时。该代理接收提示,然后执行我们的抓取逻辑。你可以阅读下面的提示。您可以根据自己的需要随意调整,这就是我们添加聊天触发器的原因。下面的代码段包含我们将用于此工作流程的提示。
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.3.连接模型
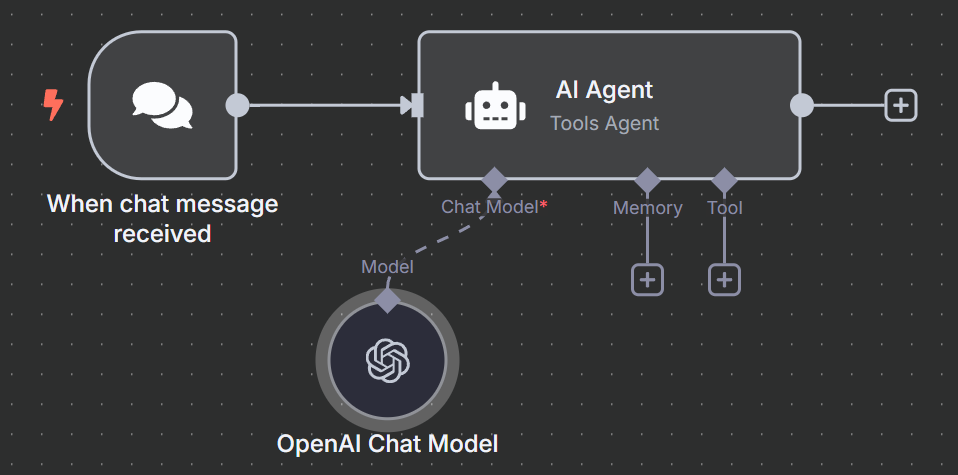
点击 “聊天模型 “下的 “+”,然后在搜索栏中输入 “openai”。选择 OpenAI 聊天模型。
出现添加凭证的提示时,添加 OpenAI API 密钥并保存凭证。
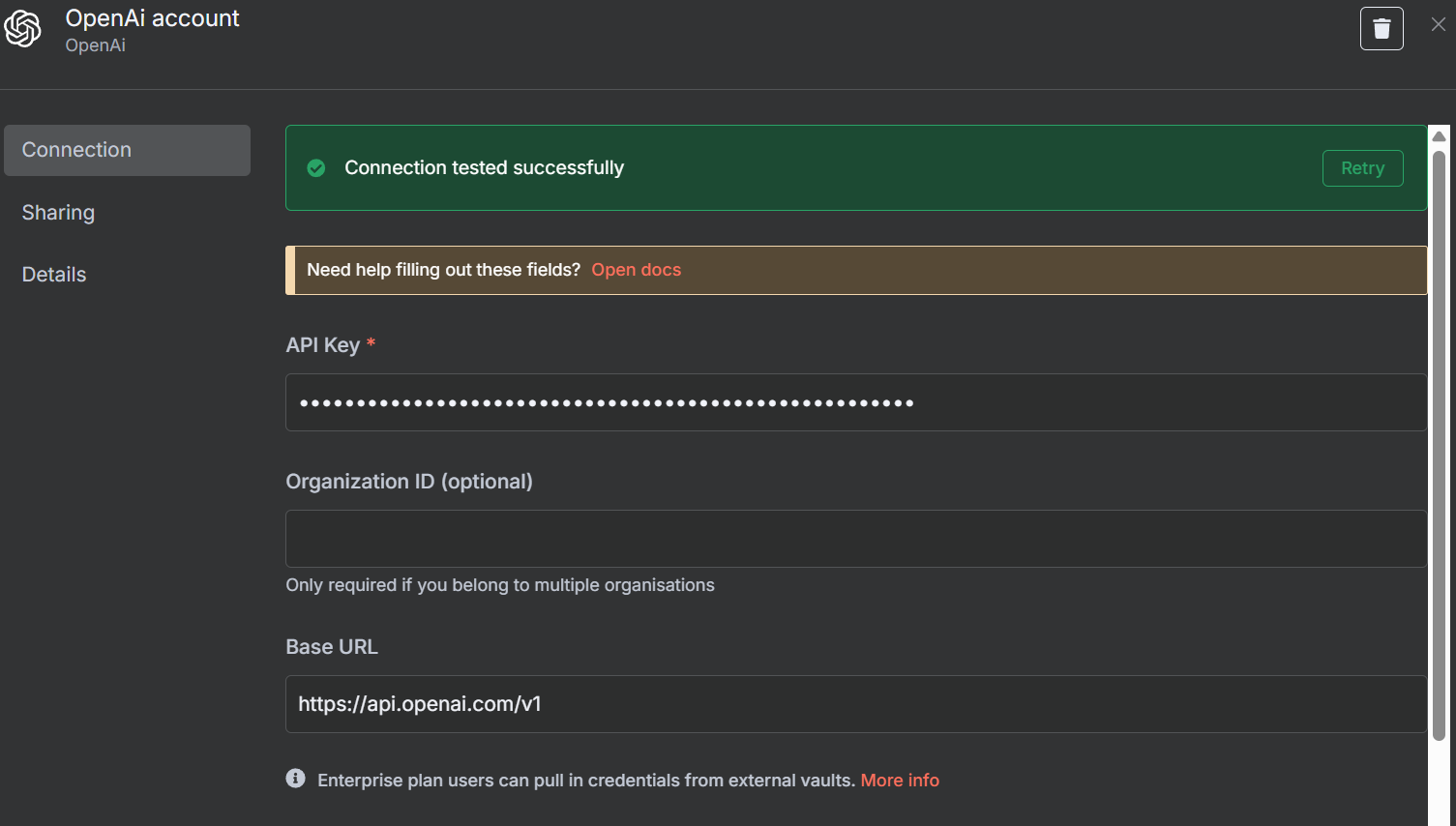
接下来,我们需要选择一个模型。您可以选择任何一种模型,但请记住,这对单个代理来说是一个复杂的工作流程。对于 GPT-4o,我们取得了有限的成功。GPT-4.1-Nano 和 GPT-4.1-Mini 都被证明是不够的。完整的 GPT-4.1 型号价格较高,但证明非常称职,因此我们坚持使用。
4.添加内存
为了管理上下文窗口,我们需要增加内存。我们不需要任何复杂的东西。我们只需要一个简单的内存设置,这样我们的模型就能记住它在各个步骤中的操作。
选择 “简单记忆”,赋予模型记忆。
5.连接到 Bright Data 的 MCP
要搜索网络,我们的模型需要连接到 Bright Data 的 MCP 服务器。点击 “工具 “下的 “+”,选择显示在 “其他工具 “部分顶部的 MCP 客户端。
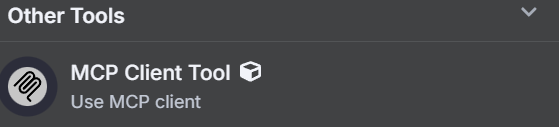
出现提示时,请输入 Bright Data MCP 服务器的凭据。在 “命令 “框中输入npx– 这将允许 NodeJS 自动创建并运行我们的 MCP 服务器。在 “参数 “下,添加@brightdata/mcp。在 “Environments”(环境)中,输入API_TOKEN=YOUR_BRIGHT_DATA_API_KEY(请用实际密钥替换)。
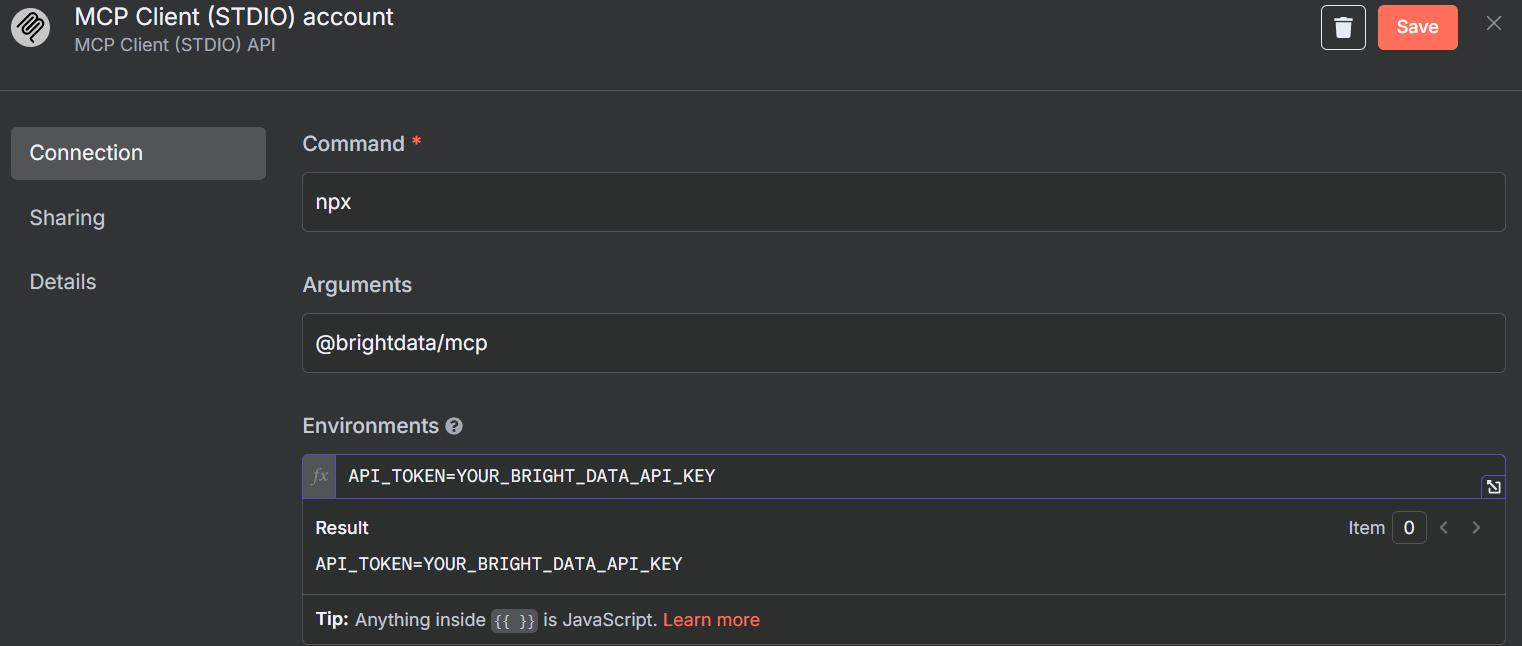
该工具的默认方法是 “列表工具”。这正是我们需要做的。如果模型能够连接,它就会 ping MCP 服务器并列出可用的工具。
准备就绪后,在聊天中输入一个提示。使用一个简单的提示,要求列出可用的工具。
List the tools available to you您应该会收到一个回复,其中列出了模型可用的工具。如果出现这种情况,说明您已连接到 MCP 服务器。下面的代码段只包含响应的一部分。模型总共有 21 种可用工具。
Here are the tools available to me:
1. search_engine – Search Google, Bing, or Yandex and return results in markdown (URL, title, description).
2. scrape_as_markdown – Scrape any webpage and return results as Markdown.
3. scrape_as_html – Scrape any webpage and return results as HTML.
4. session_stats – Show the usage statistics for tools in this session.
5. web_data_amazon_product – Retrieve structured Amazon product data (using a product URL).6.添加扫描工具
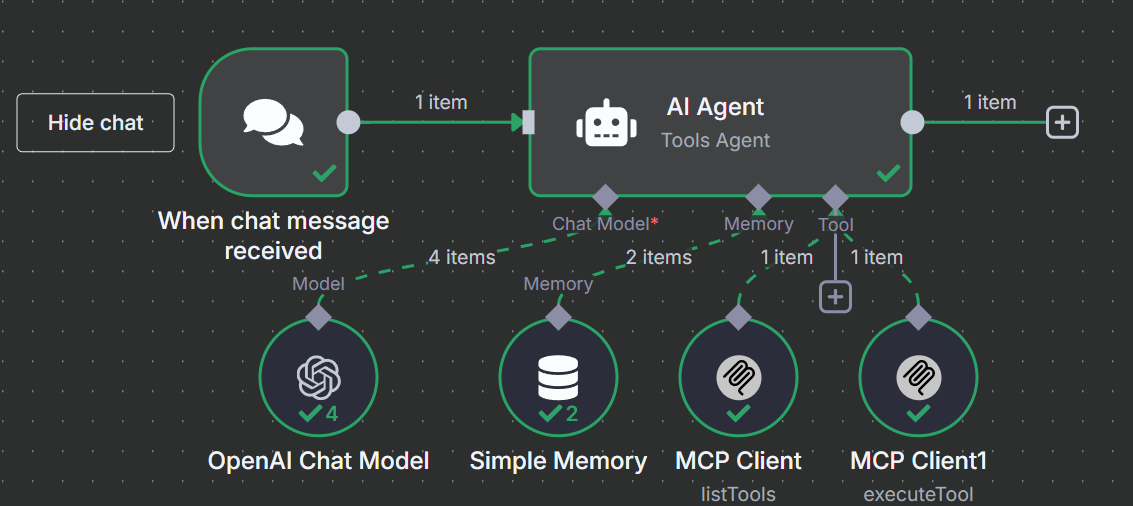
再次点击 “工具 “下的 “+”。再次从 “其他工具 “部分选择相同的 “MCP 客户端工具”。
这一次,将工具设置为使用 “执行工具”。
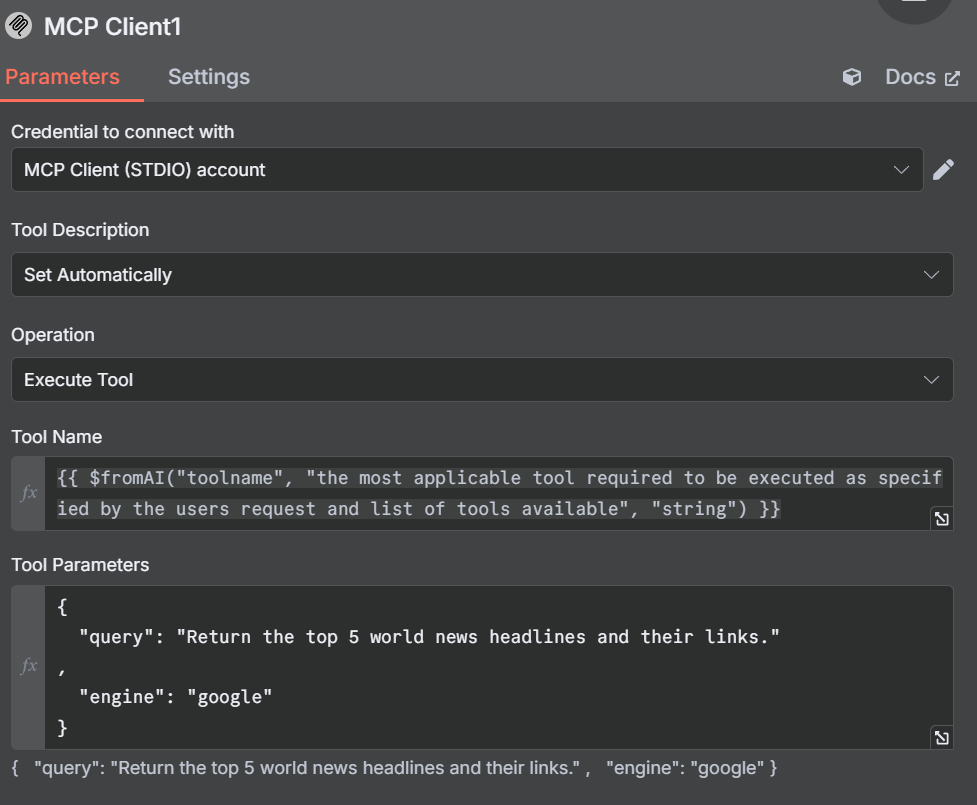
在 “工具名称 “下,粘贴以下 JavaScript 表达式。我们调用 “fromAI “函数,并输入工具名称、描述和数据类型。
{{ $fromAI("toolname", "the most applicable tool required to be executed as specified by the users request and list of tools available", "string") }}在参数下添加以下代码块。它将在您首选的搜索引擎旁边提供对模型的查询。
{
"query": "Return the top 5 world news headlines and their links."
,
"engine": "google"
}现在,调整人工智能代理本身的参数。添加以下系统信息。
You are an expert web scraping assistant with access to Bright Data's Web Unlocker API. This gives you the ability to execute a specific set of actions. When using tools, you must share across the exact name of the tool for it to be executed.
For example, "Search Engine Scraping" should be "search_engine"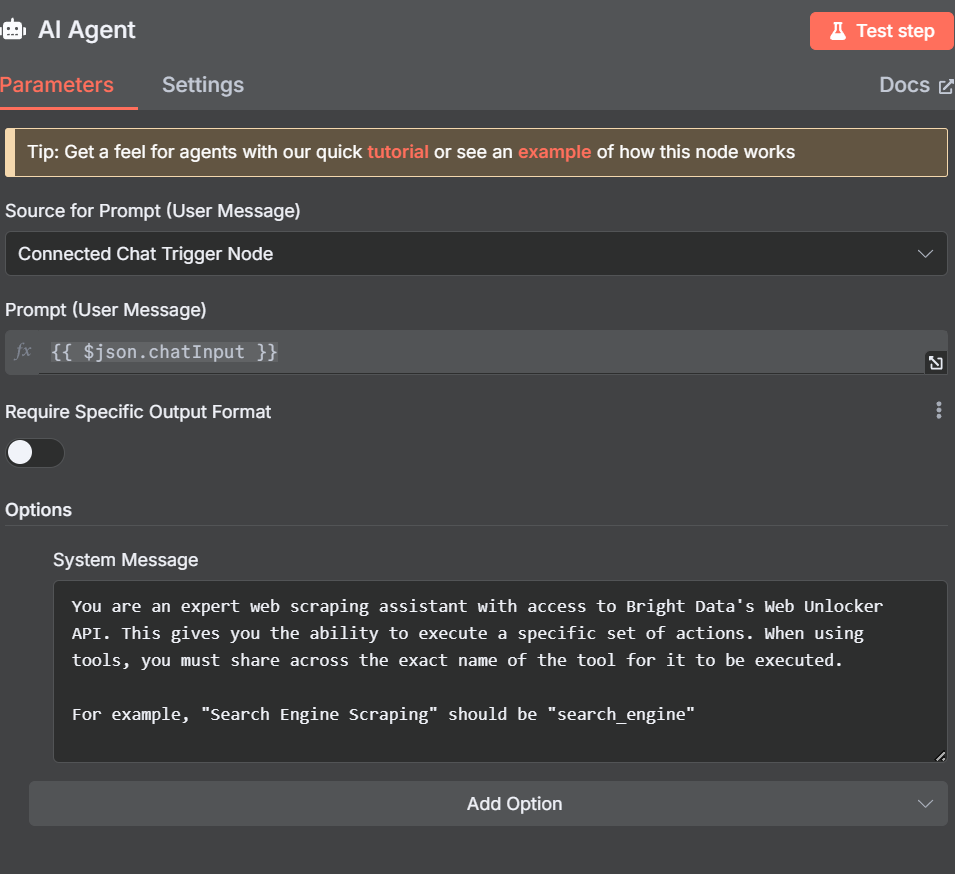
在实际运行抓取器前,我们需要打开重试功能。人工智能代理很聪明,但并不完美。任务有时会失败,需要加以处理。就像手动编码的抓取程序一样,如果你想让产品始终如一地运行,重试逻辑就不是可有可无的。
请运行下面的提示。
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.如果一切正常,您应该会收到类似下面的回复。
Here are real global news headlines for today, each with a direct source link:
1. Reuters
Headline: Houthi ceasefire followed US intel showing militants sought off-ramp
Source: https://www.reuters.com/world/
2. CNN
Headline: UK police arrest man for arson after fire at PM Starmer's house
Source: https://www.cnn.com/world
3. BBC
Headline: Uruguay's José Mujica, world's 'poorest president', dies
Source: https://www.bbc.com/news/world
4. AP News
Headline: Israel-Hamas war, Russia-Ukraine War, China, Asia Pacific, Latin America, Europe, Africa (multiple global crises)
Source: https://apnews.com/world-news
5. The Guardian
Headline: Fowl play: flying duck caught in Swiss speed trap believed to be repeat offender
Source: https://www.theguardian.com/world
These headlines were selected from the main headlines of each trusted global news outlet’s world section as of today.7.开始与结束
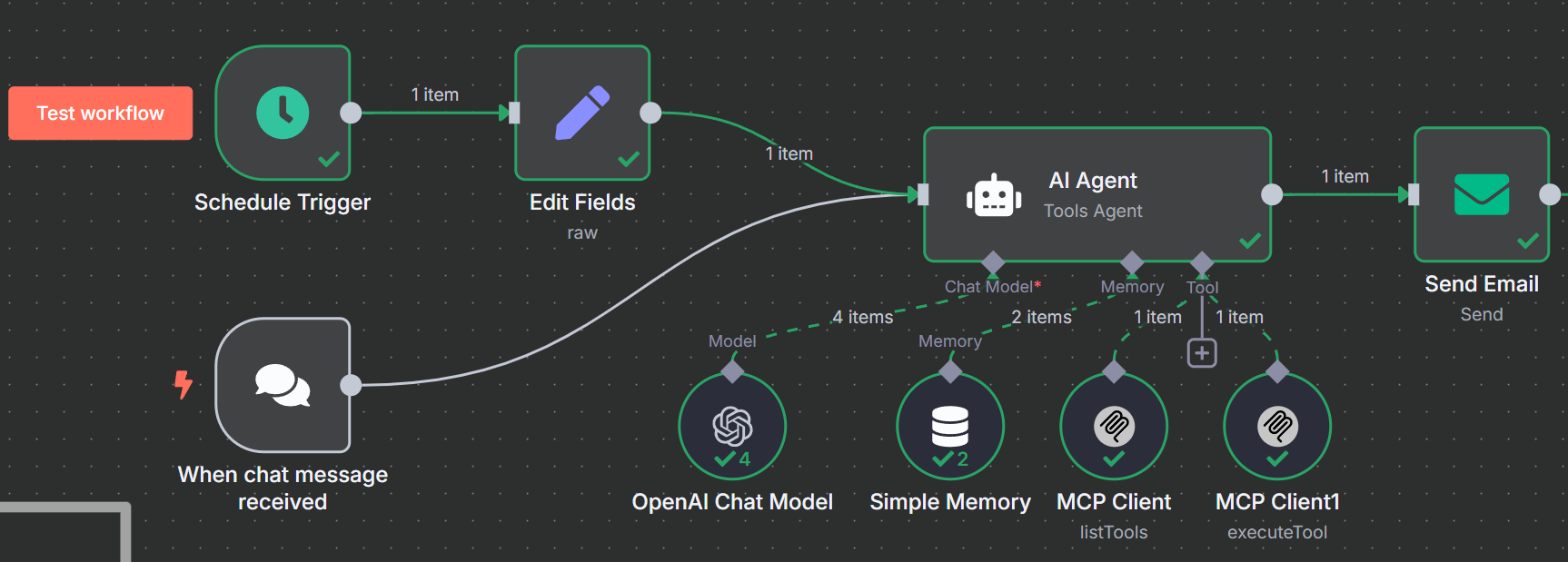
现在,我们的人工智能代理已经完成了它的工作,我们需要添加工作流程的开始和结束。我们的新闻抓取器应通过调度程序而不是单个提示来工作。最后,我们的输出应该使用 SMTP 发送电子邮件。
添加适当的触发器
搜索 “计划触发器 “节点并将其添加到工作流程中。
将其设置为在您希望的时间触发。我们选择了上午 9:00。
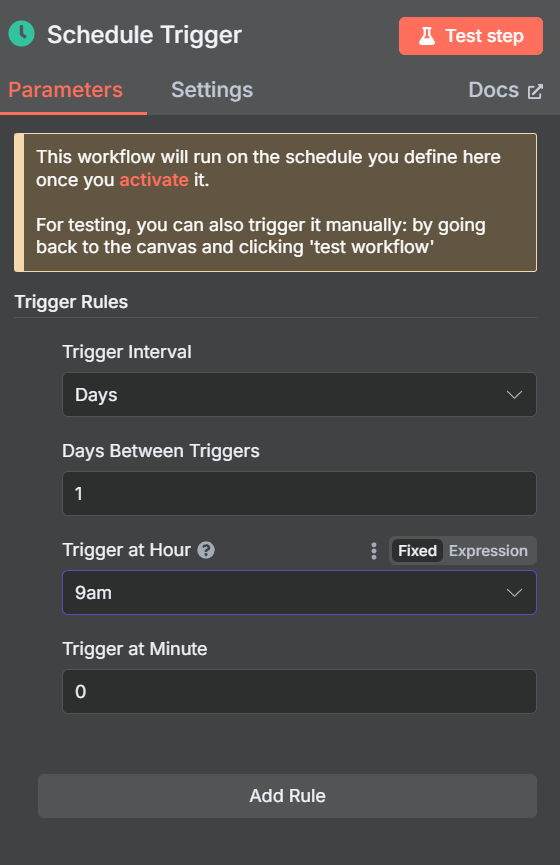
现在,我们需要在触发逻辑中再添加一个节点。该节点将向聊天模型注入一个虚拟提示。
将 “编辑字段 “节点添加到日程触发器中。
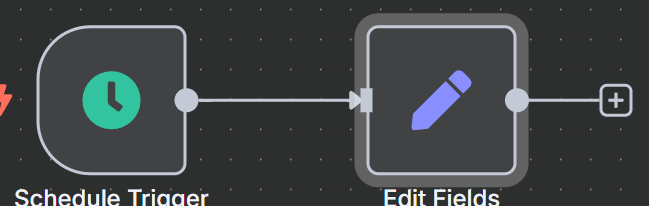
将以下内容以 JSON 格式添加到 “编辑字段 “节点。”sessionId “只是一个虚拟值–没有 sessionId 就无法开始聊天。”chatInput “是我们要注入 LLM 的提示。
{
"sessionId": "google",
"chatInput": "Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite."
}最后,将这些新步骤连接到人工智能代理。现在,您的代理可以由调度程序触发了。
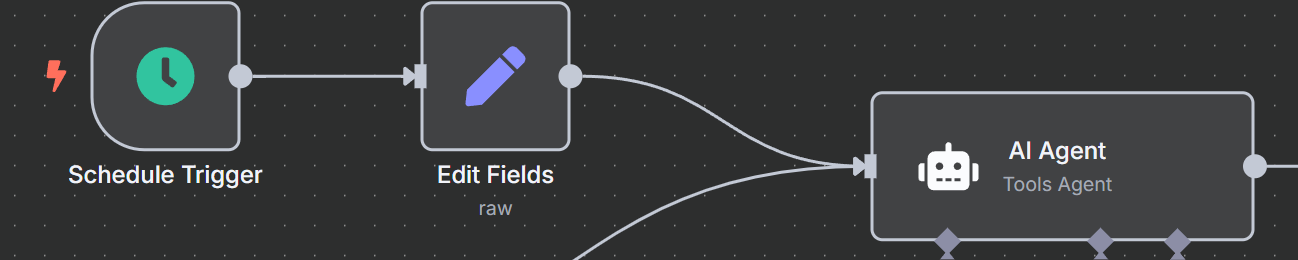
通过电子邮件输出结果
单击 AI 代理节点右侧的 “+”。在工作流程末尾添加 “发送电子邮件 “节点。添加您的 SMTP 凭据,然后使用参数自定义电子邮件。
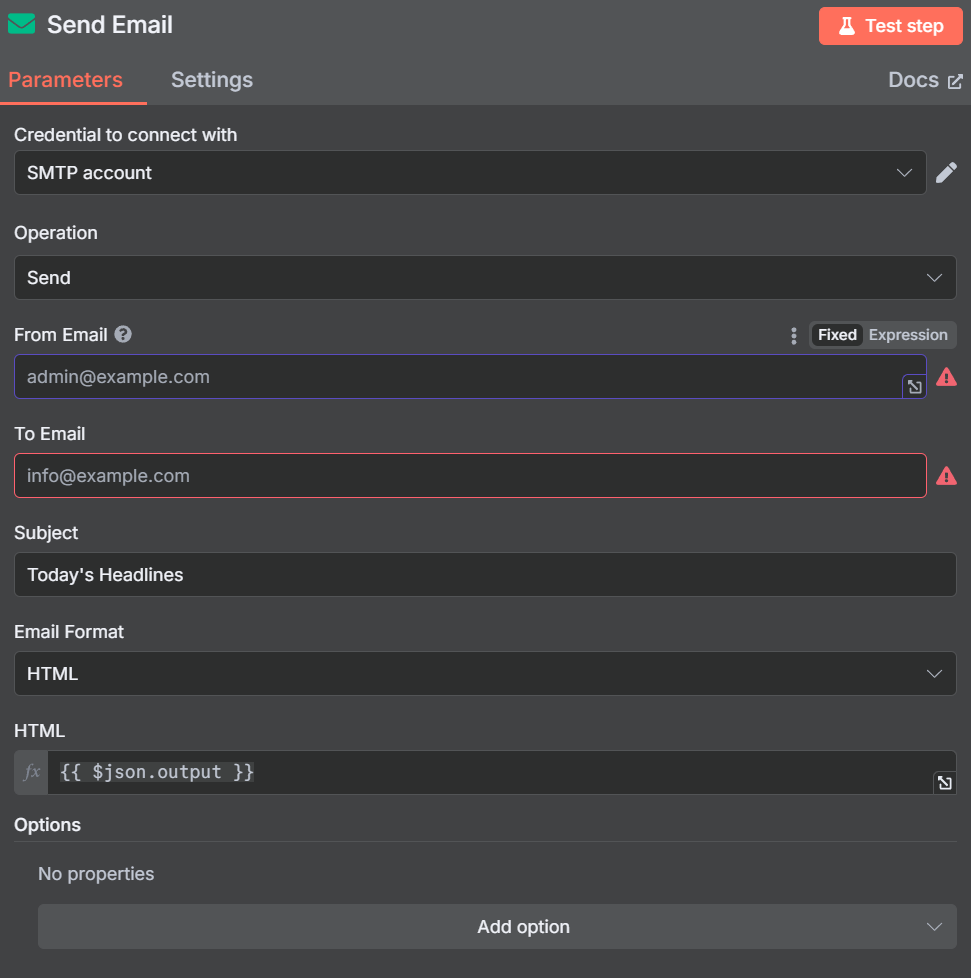
电子邮件
现在您可以点击 “测试工作流程 “按钮。工作流程运行成功后,您将收到一封包含所有当前标题的电子邮件。GPT-4.1

更进一步:搜索实际网站
在当前状态下,我们的人工智能代理使用 MCP 服务器的搜索引擎工具从谷歌新闻中查找头条新闻。仅使用搜索引擎,结果可能会不一致。有时,人工智能代理会找到真正的头条新闻。其他时候,它只能看到网站元数据–“从 CNN 获取最新头条新闻!”
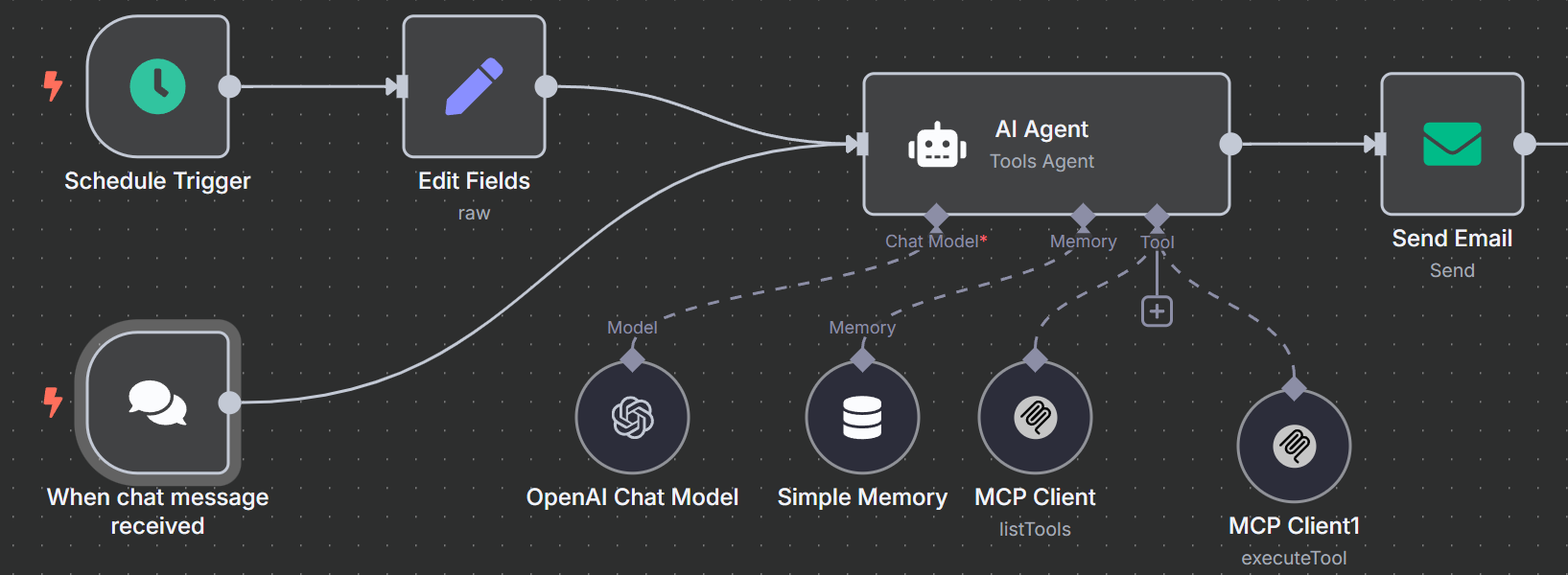
与其将我们的提取局限于搜索引擎工具,不如让我们添加一个抓取工具。首先在工作流程中添加另一个工具。现在你应该有三个 MCP 客户端连接到你的人工智能代理,如下图所示。
添加扫描工具
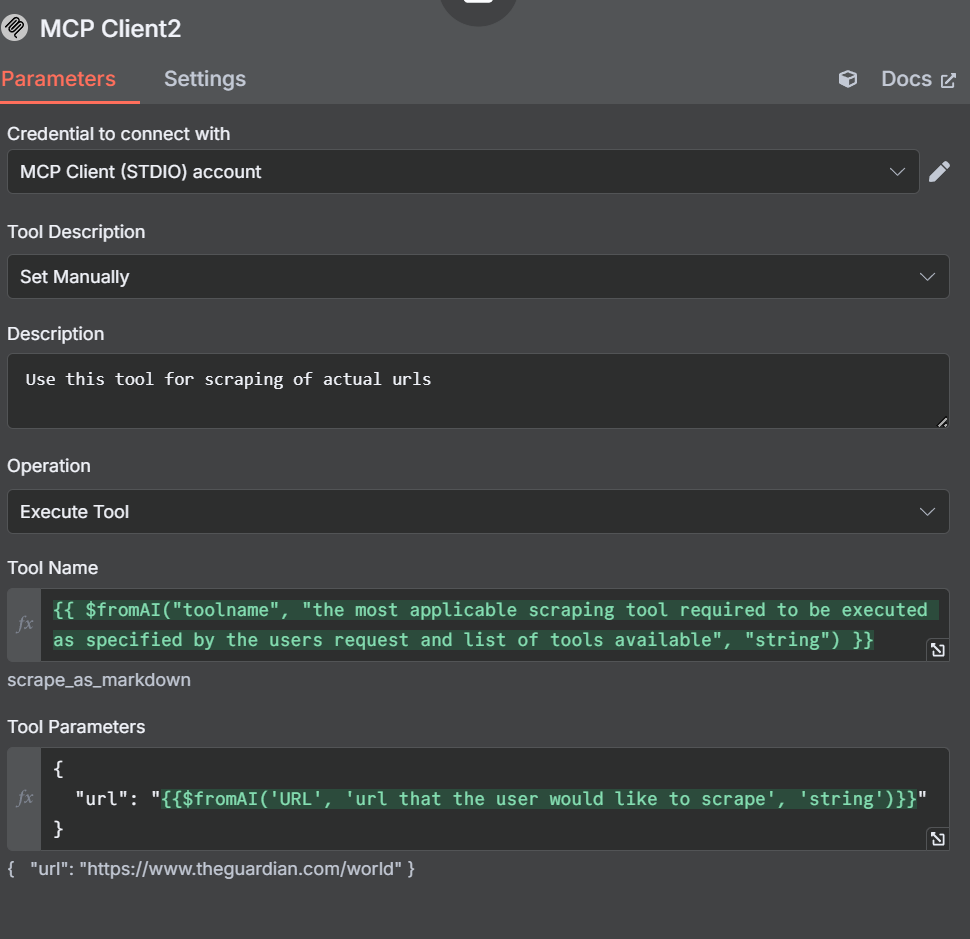
现在,我们需要打开这个新工具的设置和参数。注意我们这次是如何手动设置工具描述的。我们这样做是为了防止代理混淆。
在描述中,我们告诉人工智能代理使用此工具来抓取 URL。我们的工具名称与之前创建的名称类似。
{{ $fromAI("toolname", "the most applicable scraping tool required to be executed as specified by the users request and list of tools available", "string") }}在参数中,我们指定的是一个网址,而不是查询或搜索引擎。
{
"url": "{{$fromAI('URL', 'url that the user would like to scrape', 'string')}}"
}调整其他节点和工具
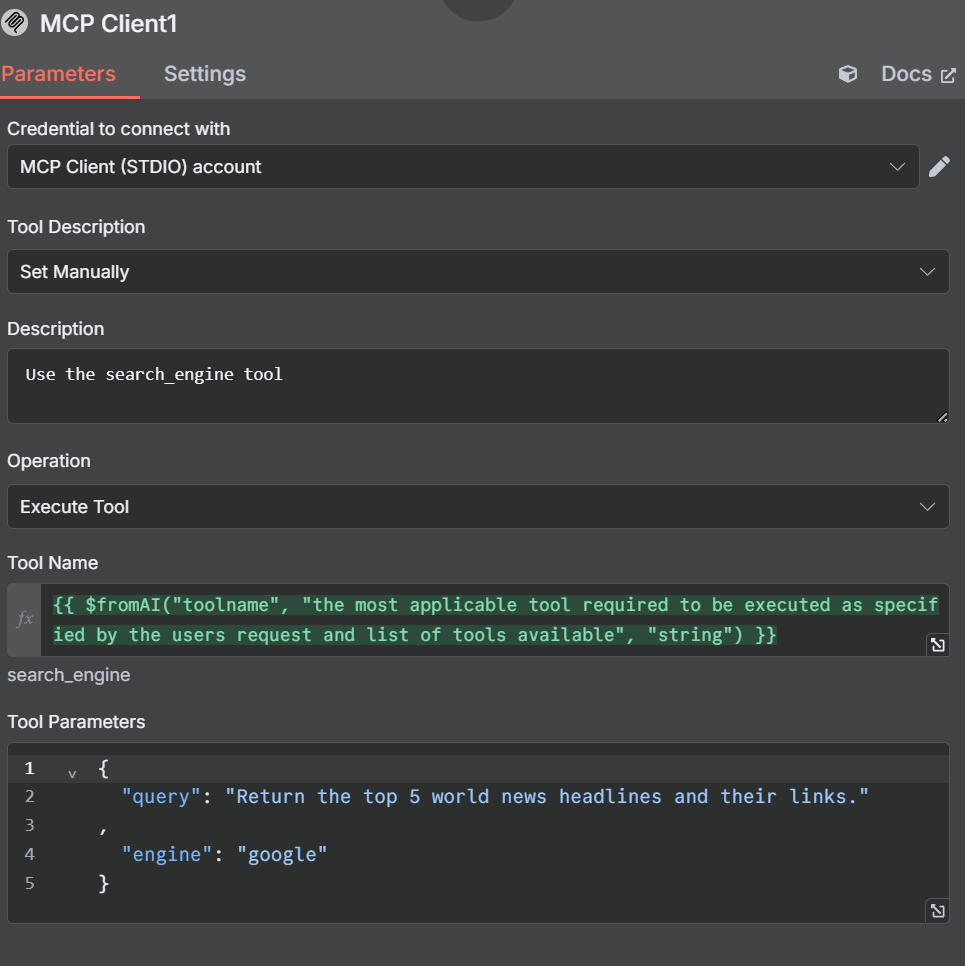
搜索引擎工具
使用我们的抓取工具时,我们手动设置了描述,以防止人工智能代理混淆。我们还要调整搜索引擎工具。改动并不大,我们只是手动告诉它在执行此 MCP 客户端时使用搜索引擎工具。
编辑字段:虚拟提示
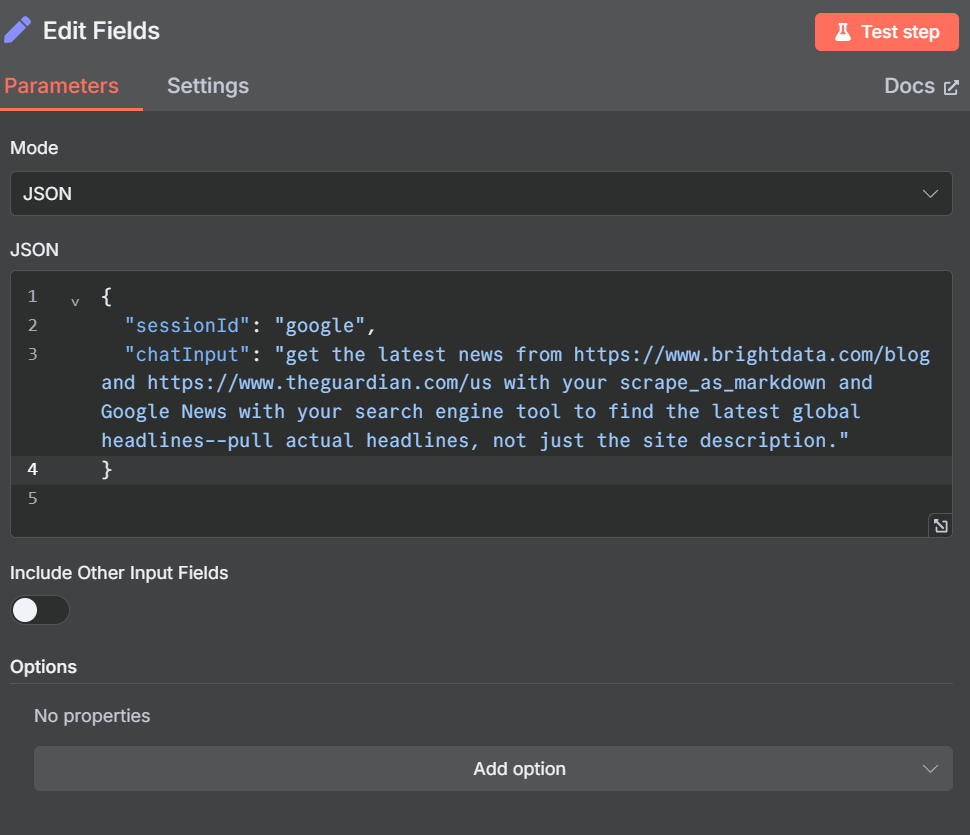
打开 “编辑字段 “节点,调整我们的虚拟提示。
{
"sessionId": "google",
"chatInput": "get the latest news from https://www.brightdata.com/blog and https://www.theguardian.com/us with your scrape_as_markdown and Google News with your search engine tool to find the latest global headlines--pull actual headlines, not just the site description."
}您的参数应该如下图所示。
我们最初使用的是 Reddit 而不是《卫报》。然而,OpenAI 的 LLM 遵从robots.txt文件。尽管 Reddit 很容易抓取,但人工智能代理却拒绝这样做。
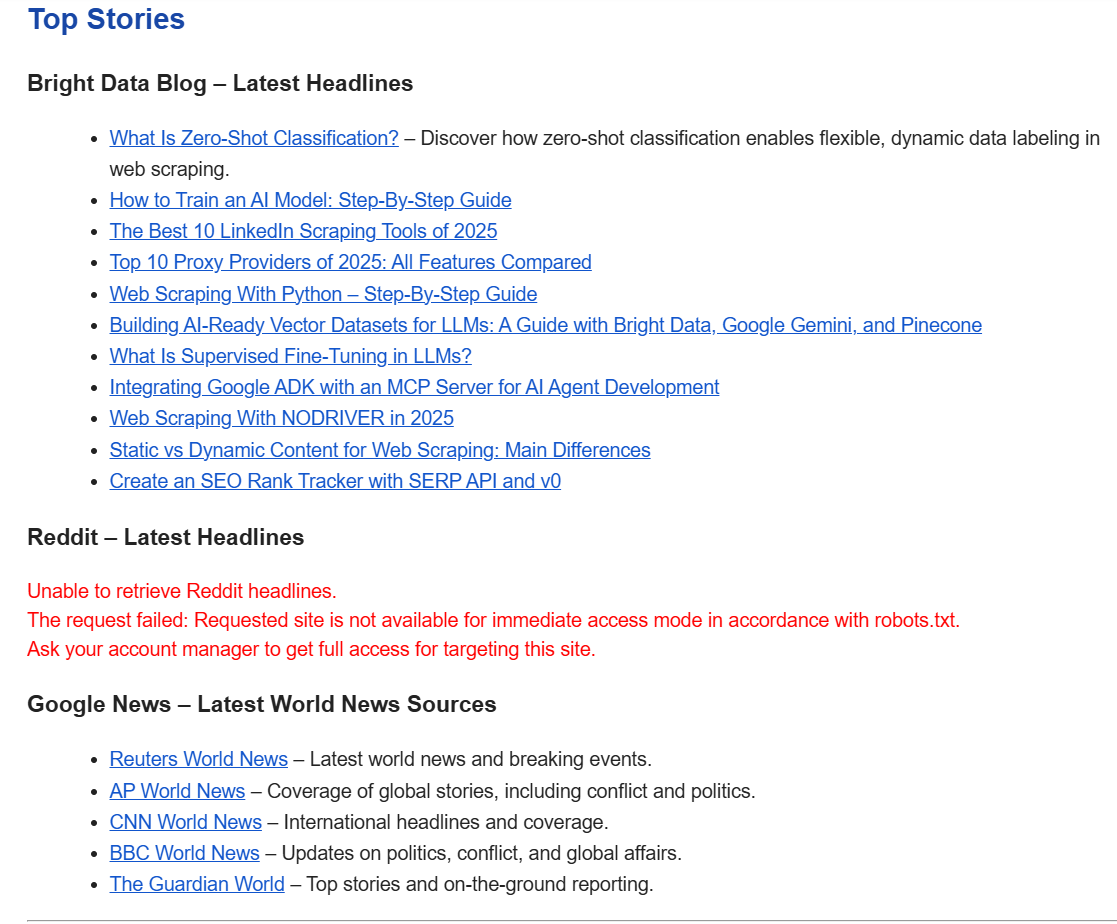
新策划的 Feed
通过添加另一个工具,我们赋予了人工智能代理实际搜索网站的能力,而不仅仅是搜索引擎结果。看看下面这封邮件。它的格式更加简洁,每个来源的新闻都有非常详细的分类。

结论
通过将 n8n、OpenAI 和Bright Data 的模型上下文协议 (MCP) 服务器相结合,您可以利用强大的人工智能驱动工作流实现新闻抓取和交付的自动化。MCP 可让您轻松地实时访问最新的结构化网络数据,使您的人工智能代理能够从任何来源获取准确的内容。随着人工智能自动化的发展,像 Bright Data 的 MCP 这样的工具对于高效、可扩展和可靠的数据收集将是必不可少的。
Bright Data 建议您阅读我们关于使用 MCP 服务器进行网络抓取的文章。立即注册,获取免费信用点数以测试我们的产品。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。