

想象一下:你花了数周时间完善你的网络抓取器。CSS 选择器经过微调,数据流畅,然后亚马逊改变了布局。你精心改进的选择器一夜之间就崩溃了。听起来很熟悉吧?
模型上下文协议(MCP)是一种有望改变我们提取网络数据方式的新方法。你不用再编写蹩脚的 CSS 选择器,而只需向人工智能发出简单明了的指令,人工智能就能完成繁重的工作。但这种人工智能驱动的方法真的比久经考验的传统方法更好吗?
让我们深入研究这两种方法,构建一些真实的抓取器,看看哪种方法能在 2026 年获胜。
快速比较:传统扫描与 MCP 扫描
在我们深入探讨细节之前,先来看看这些方法的不同之处:
| 方面 | 传统刮削 | MCP 驱动的扫描 |
|---|---|---|
| 设置时间 | 小时到天数 | 分钟至小时 |
| 维护 | 高 – 因布局变化而中断 | 较低 – 人工智能可适应微小变化 |
| 费用 | 按要求降低 | 按要求提高 |
| 控制 | 完全控制逻辑 | 依赖人工智能解释 |
| 学习曲线 | 陡峭 – 需要编码技能 | 更温和–自然语言提示 |
| 最适合 | 高流量、稳定的站点 | 快速原型设计,不断变化的场地 |
传统网络抓取:基础
几十年来,传统的网络抓取技术一直在为数据提取提供动力。其核心是一个直接的四步流程,让你完全控制数据提取的方式。
传统工作流程
- 发送 HTTP 请求:从 HTTP 客户端开始获取网页。Python 的
请求库可以满足基本需求,但如果需要更高的性能,可以考虑使用它: - 解析 HTML:使用解析器将原始 HTML 转化为可操作的数据。BeautifulSoup仍是首选,通常使用lxml以提高速度。这些解析器擅长静态内容提取。
- 提取数据:使用以下功能锁定特定元素
- CSS 选择器,可直接按类、ID 或属性进行选择
- 用于复杂遍历和文本匹配的 XPath
- 不确定该使用哪个?我们的XPath 与 CSS 选择器指南对此进行了分析
4.处理动态内容:对于 JavaScript 较多的网站,你需要浏览器自动化:
- 硒:支持多种语言的资深选择
- 剧作家现代、快速、可靠
- Puppeteer完美适用于 Node.js 工作流
- Bright Data’s Scraping 浏览器:内置反僵尸保护和代理管理
受欢迎的传统刮削堆栈
静态网站
用于复杂爬行
- PythonScrapy框架
适用于 JavaScript 繁重的网站
- 剧作家 +隐形剧作家
- Puppeteer +puppeteer-extra-plugin-stealth
- 硒基
模型上下文协议:人工智能驱动的搜索
模型上下文协议(MCP)由 Anthropic 于 2024 年 11 月 25 日发布,它是一项开放标准,允许大型语言模型(LLM)像调用函数一样轻松调用外部工具–可以把它想象成人工智能应用程序的 USB-C。
无需硬编码 HTTP 请求或 CSS 选择器,只需描述结果–“从该 URL 抓取产品标题、价格和评级”–LLM 就会在幕后选择合适的工具(如scrape_product())。
对于网络抓取团队来说,这种转变可将脆弱的解析逻辑转变为有弹性、由提示驱动的工作流程。
MCP 如何工作
所有信息都通过JSON-RPC 2.0 传输,使每次调用都与语言无关,并对数据流友好。
- 主机– 启动对话的 LLM 应用程序(如 Claude Desktop
- 客户端– 嵌入主机的协议处理程序
- 服务器– 公开一个或多个工具的服务
- 工具– 返回 JSON 或 CSV 等结构化结果的命名函数
神奇之处在于互动流程:
- 描述任务 “获取这款耐克鞋的历史价格”。
- LLM 选择一个工具。它会将您的请求映射到scrape_product_history(url)。
- 服务器执行。无头浏览、代理轮换和验证码问题的解决取决于工具的配置方式。
- 结构化输出。LLM 接收干净的 JSON 并将其返回或通过管道输送。
💡 请记住:MCP 可管理任何工具调用,而不仅仅是网络提取。它可以协调 SQL 查询、git 操作、文件 I/O 等。但仍需有人编写工具。人工智能无法发明尚未实现的逻辑。
深入了解MCP 如何彻底改变网络搜索工作流程。
官方 MCP SDK
模型上下文协议组织为主要语言提供 SDK:
- TypeScript SDK– 主要实现
- Python SDK– 功能齐全,适用于人工智能/ML 工作流
- Java SDK– 使用 Spring AI 维护
- C# SDK– Microsoft 合作伙伴(预览版)
- Ruby SDK– Shopify 合作
- Rust SDK– 高性能实现
- Kotlin SDK– 基于 JVM,非常适合安卓系统
正面交锋:双管齐下打造亚马逊搜索器
让我们使用这两种方法构建相同的亚马逊产品搜索器。这种实际比较将突出传统抓取器和 MCP 驱动的抓取器之间的真正差异。
传统方法
首先,让我们使用 Playwright 和 BeautifulSoup 创建一个传统的抓取器:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
async def scrape_amazon_product(url):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto(url)
await page.wait_for_selector("#productTitle", timeout=10000)
soup = BeautifulSoup(await page.content(), "html.parser")
await browser.close()
def extract(selector, default="N/A", attr=None, clean=lambda x: x.strip()):
element = soup.select_one(selector)
if not element:
return default
value = element.get(attr) if attr else element.text
return clean(value) if value else default
return {
"title": extract("#productTitle"),
"current_price": extract(".a-price-whole"),
"original_price": extract(".a-price.a-text-price span"),
"rating": extract("#acrPopover", attr="title"),
"reviews": extract("#acrCustomerReviewText"),
"availability": extract(
"#availability span", clean=lambda x: x.strip().split("n")[0].strip()
),
}
async def main():
product = await scrape_amazon_product("https://www.amazon.in/dp/B0BTDDVB67")
print("nProduct Information:")
print("-------------------")
print("n".join(f"{k.replace('_', ' ').title()}: {v}" for k, v in product.items()))
if __name__ == "__main__":
asyncio.run(main())挑战:这些 CSS 选择器(#productTitle、.a-price-whole)都是硬编码。亚马逊一调整 HTML,你的 scraper 就会崩溃。你将花费更多的时间来修复损坏的选择器,而不是分析数据。
需要绕过亚马逊的反僵尸保护?了解我们关于绕过亚马逊验证码的完整指南。
MCP 方法
现在,让我们用 MCP 制作同样的抓取器。
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
from markdownify import markdownify as md
from bs4 import BeautifulSoup
# Initialize FastMCP instance
mcp = FastMCP("Amazon Scraper")
@mcp.tool()
async def scrape_product(url: str) -> str:
"""
Fetch an Amazon product page, extract the main product section,
and return it as Markdown.
"""
browser = None
try:
async with async_playwright() as playwright:
# Launch headless browser
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate and wait for the product title
await page.goto(url, timeout=90000)
await page.wait_for_selector("span#productTitle", timeout=30000)
# Extract HTML and parse
html_content = await page.content()
soup = BeautifulSoup(html_content, "lxml")
product_section = soup.find("div", id="dp") or soup.body
return md(str(product_section)).strip()
except Exception as e:
return f"Error: {e}"
finally:
if browser is not None:
await browser.close()
if __name__ == "__main__":
mcp.run(transport="stdio")差异:注意到缺少了什么吗?没有特定的价格、评级或可用性选择器。MCP 服务器只提供内容,人工智能会根据您的自然语言请求找出需要提取的内容。
使用光标设置 MCP
想亲自尝试一下吗?下面介绍如何将您的 MCP 服务器与 Cursor 集成:
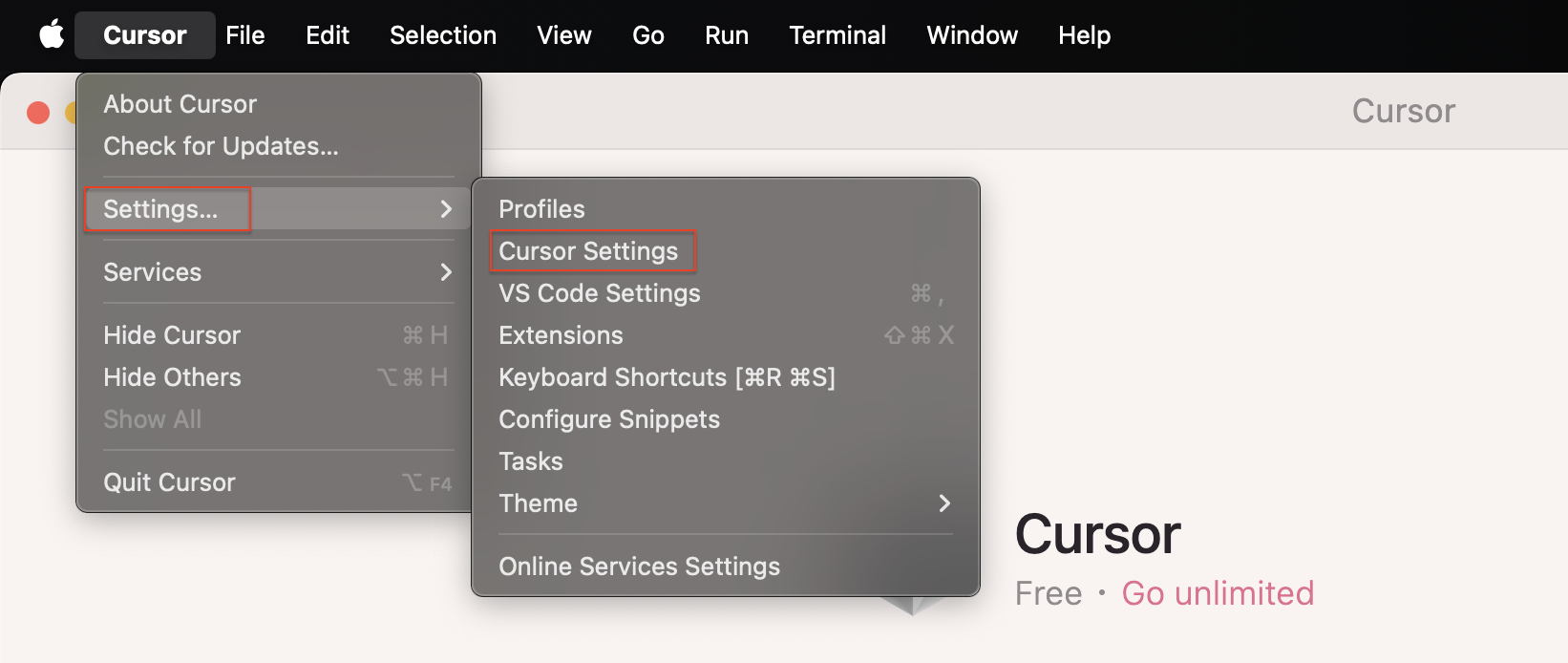
步骤 1:打开光标并导航至设置 → 光标设置
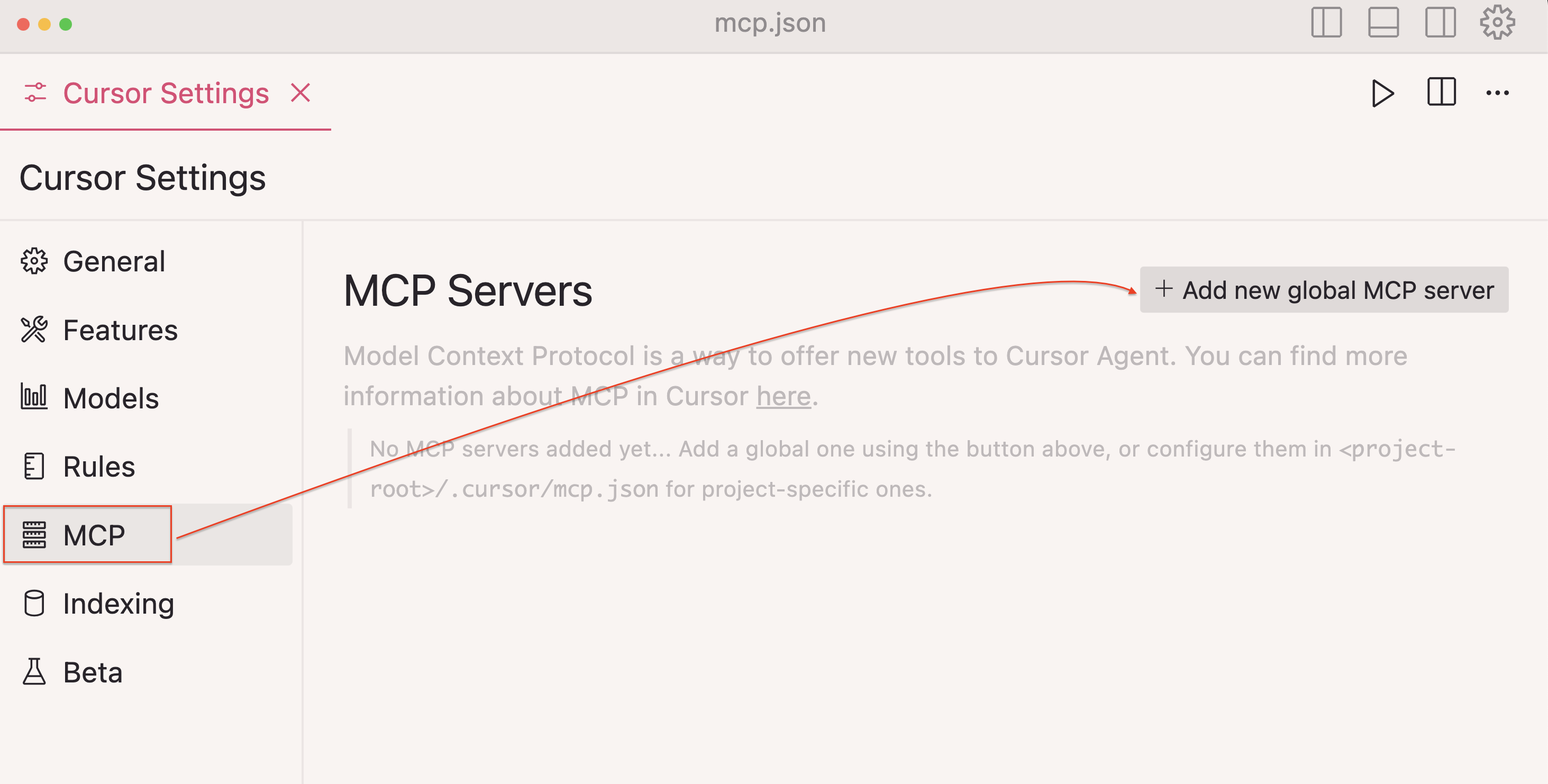
步骤 2:在侧边栏选择MCP
第 3 步:点击+ 添加新的全局 MCP 服务器
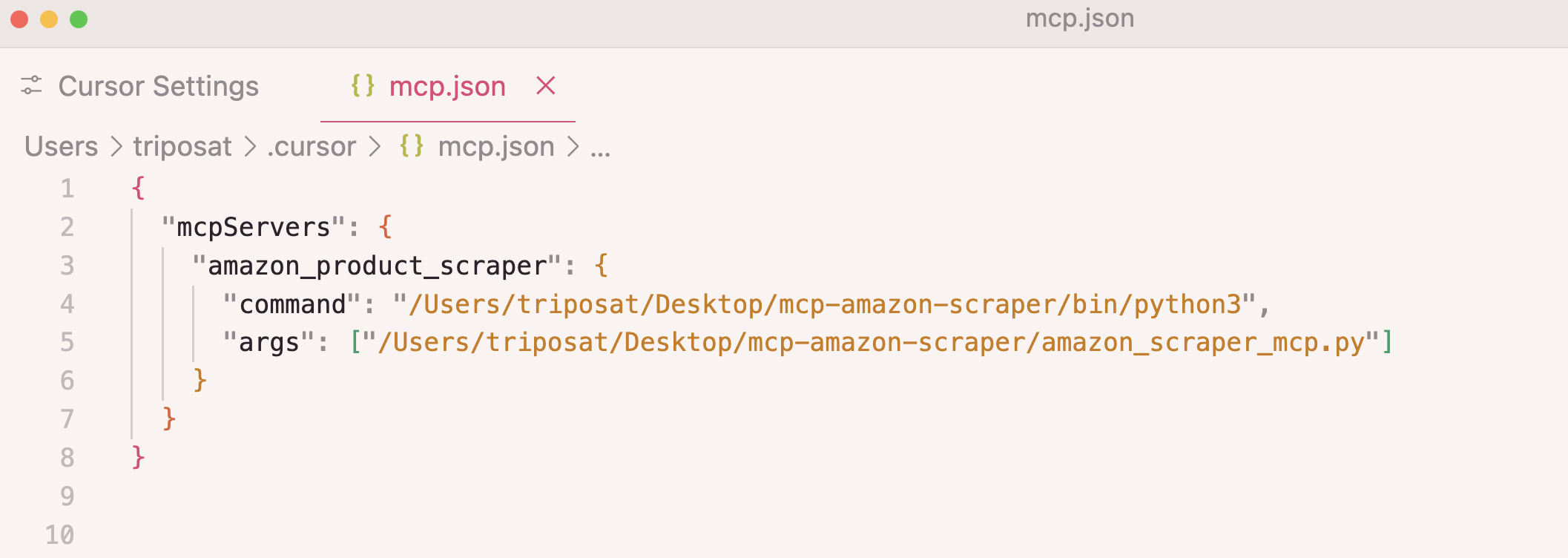
第 4 步:添加服务器配置:
{
"mcpServers": {
"amazon_product_scraper": {
"command": "/path/to/python",
"args": ["/path/to/amazon_scraper_mcp.py"]
}
}
}
步骤 5:保存并验证连接是否显示绿色
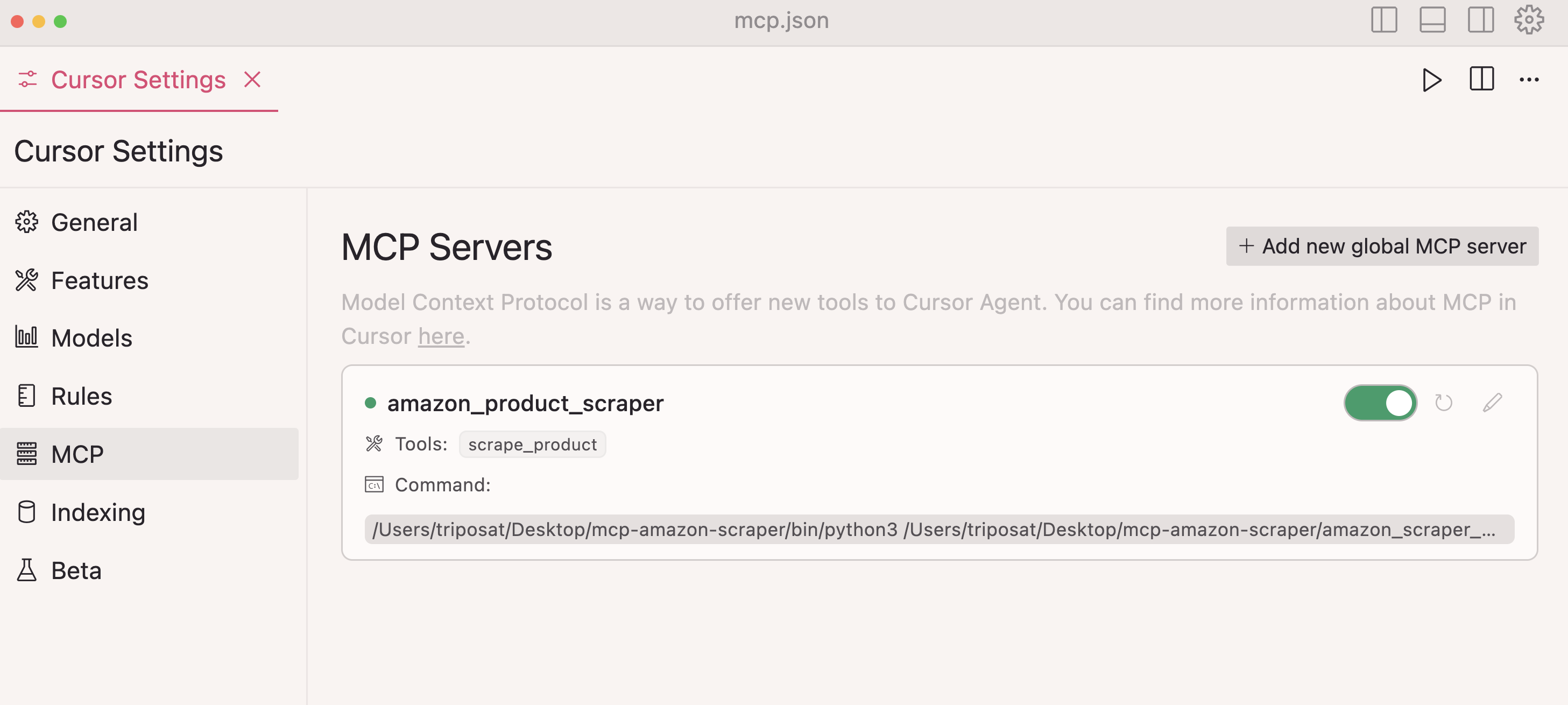
步骤 6:现在,您可以在 Cursor 聊天工具中使用自然语言了:
Extract the product title, current price, original price, star rating, review count, three key features, and availability from https://www.amazon.in/dp/B0BTDDVB67 and return as JSON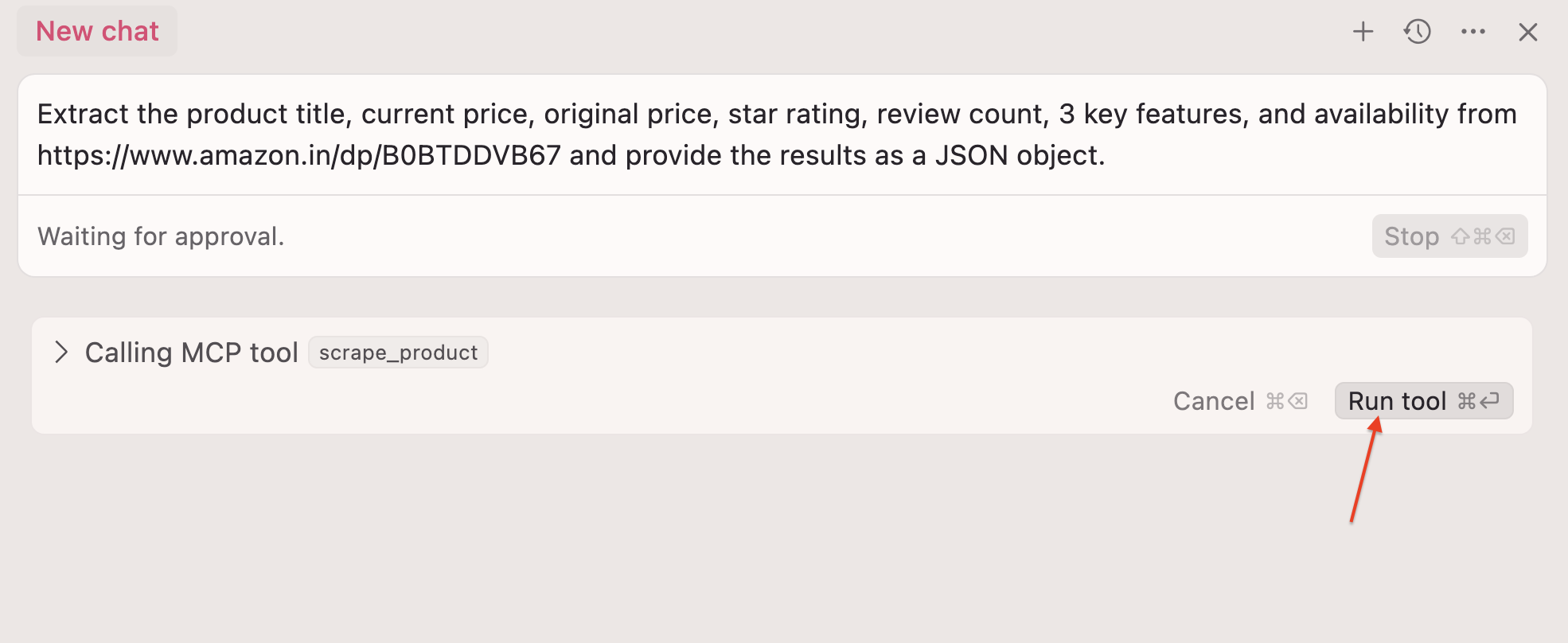
步骤 7:单击运行工具 ⏎
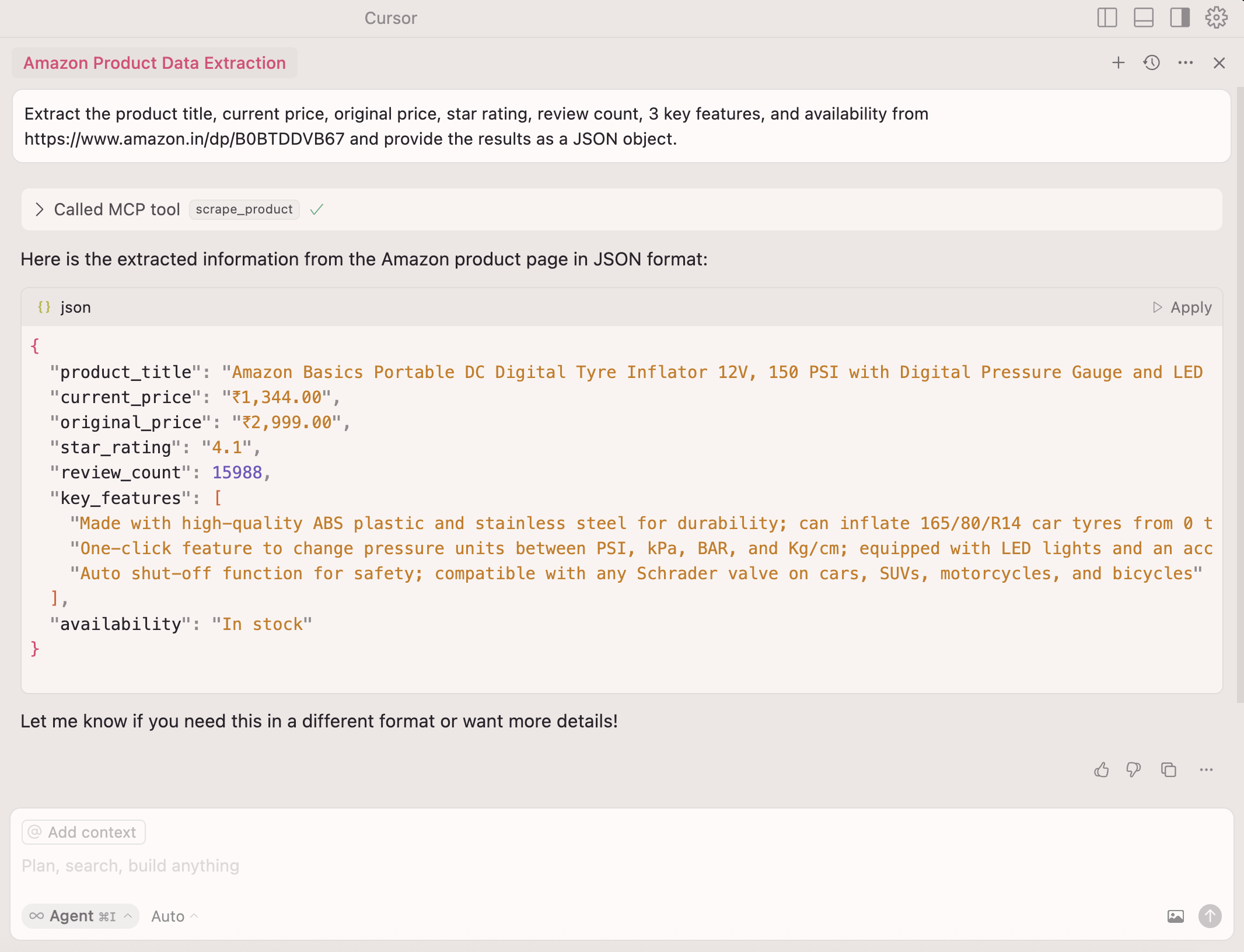
人工智能处理所有提取逻辑,无需选择器!
👉了解如何集成 Bright Data 的 MCP 服务器以访问实时、AI 就绪的网络数据。
何时使用每种方法
在制造出这两种刮削器之后,其中的利弊就一目了然了。
当您需要对每个请求、选择器和代理进行端到端控制时,请选择传统的抓取技术。
- 大批量、可重复的工作
- 定义明确的地点,很少改变
- 每毫秒和依赖关系都很重要的管道
💡 提示:用于传统刮削:
- 探索Bright Data 的代理服务,以处理 IP 轮换和地理限制问题
- 试用Web Scraper API,从 120 多个常用域中提取预建内容
- 浏览数据集市场,获取即用数据
另一方面,如果您的产品已经以 LLM 为中心,或者您希望代理按需获取实时数据,则应采用 MCP 驱动的工作流程。
- 快速原型,编写选择器会拖慢您的速度
- 经常变化或跨域变化的网站
- 技术水平较低的队友可通过提示触发数据收集
- 受益于 LLM 推理的复杂流程(如搜索 → 分页 → 提取
- 可承受额外延迟或工具调用成本的对话式应用程序
💡 提示:用于 MCP 集成:
- 查看社区 MCP 服务器
- 使用官方MCP 参考实现进行实验
- 测试 Bright Data 的 MCP 集成是否具有企业级可靠性。
Bright Data 的 MCP 服务器将Web Unlocker、Crawl API、Browser API 或SERP API封装在一个 JSON-RPC 端点后面。您的代理只需调用search_engine 等可用工具,服务器就会自动处理隐身浏览、验证码解锁和代理轮换。
未来是混合动力
这两种方法都不是灵丹妙药,因此聪明的团队会将两者结合起来。
- 使用 MCP 进行发现。在几分钟内启动由提示驱动的抓取程序,验证新的数据源。
- 使用传统代码优化。目标和模式稳定后,改用手工调整的选择器,以提高速度和成本效益。
- 将成熟的抓取程序作为 MCP 工具公开。将现有的 Python 或 Node.js 爬虫封装在轻量级 MCP 服务器中,这样代理只需调用一个函数即可调用它们。
现代平台已经遵循了这一模式。例如,Bright Data 的 MCP 服务器可让您将人工智能主导的探索与生产级抓取基础设施相结合。
结论
传统的网络抓取技术不会消失–它仍然是大多数大规模数据操作的基础。与此同时,MCP 带来了一层新的灵活性和 LLM 就绪智能。
未来是混合型的–两者都用,根据工作需要切换。
如果您需要可扩展、符合要求的基础架构来进行人工智能驱动的提取,请参阅Bright Data 的人工智能就绪网络数据基础架构–从住宅代理到预建 API 和全面管理的 MCP 服务器。
已经在构建代理工作流?查看将 Google ADK 与 Bright Data MCP 集成的指南。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





