

在本文中,你将学到:
- 什么是 Azure AI Foundry 以及它能提供什么。
- 为什么在 Azure AI Foundry 中集成 Bright Data 的 SERP API 是制胜策略。
- 如何构建一个连接到 SERP API 的真实 Azure AI 提示流。
开始吧!
什么是 Azure AI Foundry?
Azure AI Foundry 是一个统一平台,提供一套用于构建、部署和管理 AI 应用、智能体(agents)和流程(flows)的工具与服务。换句话说,它通过标准化 AI 系统的创建流程,充当“AI 工厂”。
其主要目标是帮助你从概念走向生产。这是通过提供来自 Azure OpenAI、Meta、Mistral 等 AI 供应商的广泛模型与能力,以及开发、部署与持续监控工具来实现的。
为何将 Bright Data 的 SERP API 集成到 Azure AI Foundry
Azure AI Foundry 提供了长长的 LLM 名单,但无论你选择哪一个,它们的知识都是静态的。例如,LLM 对今天的股市新闻、昨晚的比赛结果等并不了解,这会导致“陈旧”或“幻觉”式的回答。
为克服这一限制,你可以构建一个系统,用来自互联网的实时数据对 LLM 进行“接地”(grounding)。这种方法在 RAG(检索增强生成)工作流中尤为常见:在生成回答前向 LLM 提供外部信息,确保产出基于最新事实。
Azure AI 自带一个内置接地工具,但其数据来源仅限于 Bing,未必总是理想之选。更专业且灵活的替代方案是 Bright Data 的 SERP API!
SERP API 允许你以编程方式在搜索引擎上运行查询并获取完整的 SERP 内容,为 AI 智能体与 LLM 工作流提供可靠的、可验证、可无缝集成的新鲜数据。可在官方文档中了解其全部能力。
在 Azure AI Foundry 中,第三方 API 集成既可用于智能体(agents),也可用于流程(flows)。本文将重点关注尤其适合 RAG 场景的提示流(prompt flows)。
如何在 Azure AI 提示流中使用 SERP API 获取网页搜索上下文
本节演示如何在 Azure AI 流程中集成 Bright Data 的 SERP API,构建一个新闻分析提示流。该工作流包括四个主要步骤:
- 接收输入:你向工作流提供感兴趣的主题,以检索相关新闻。
- 抓取新闻:一个专门的 Python 节点接收主题并调用 Bright Data 的 SERP API,从 Google 获取新闻。
- 新闻分析:LLM 处理 SERP API 返回的数据,识别值得阅读的新闻。
- 生成输出:输出的 Markdown 报告列出每条新闻、简述以及阅读价值评分。
注意:这只是一个示例,你还可以在许多其他场景与用例中利用 SERP API。
按照以下步骤,在 Azure AI Foundry 中构建一个以 Bright Data 的 SERP API 新鲜数据为基础的 RAG 风格工作流!
先决条件
要跟随本教程,请确保你具备:
- 一个 Microsoft 账户。
- 一个 Azure 订阅(免费试用也可)。
- 一个具备有效 API 密钥(需 Admin 权限)的Bright Data 账户。
按照官方 Bright Data 指南获取你的 API 密钥。请妥善保存,稍后将用到。
步骤 1:创建 Azure AI Hub
Azure AI 提示流只能在Azure AI Hubs 中使用,因此第一步是创建一个 Hub。
为此,登录你的 Azure 账户,打开 Azure AI Foundry 服务(点击图标或在搜索栏搜索):
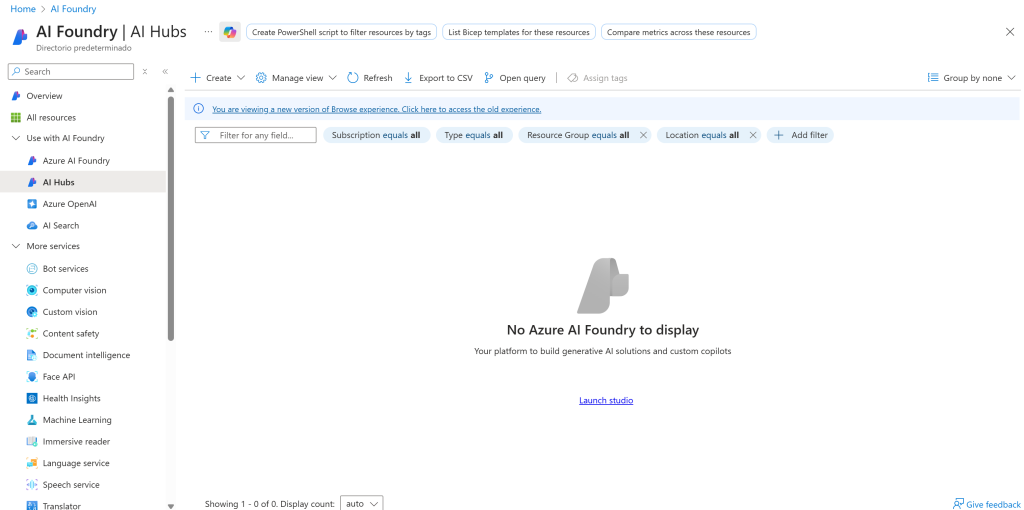
你将进入“AI Foundry”管理页面:
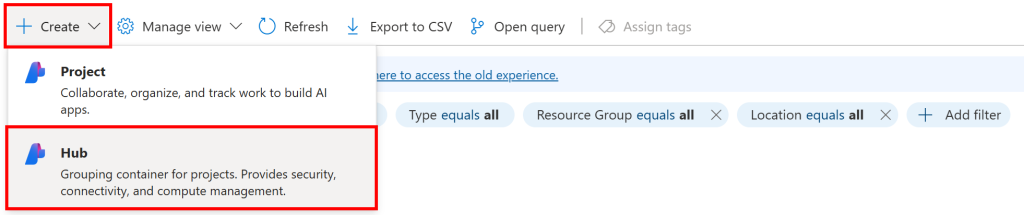
点击“Create(创建)”按钮并选择“Hub(中心)”选项:
然后按下图填写 Azure AI Hub 创建表单:
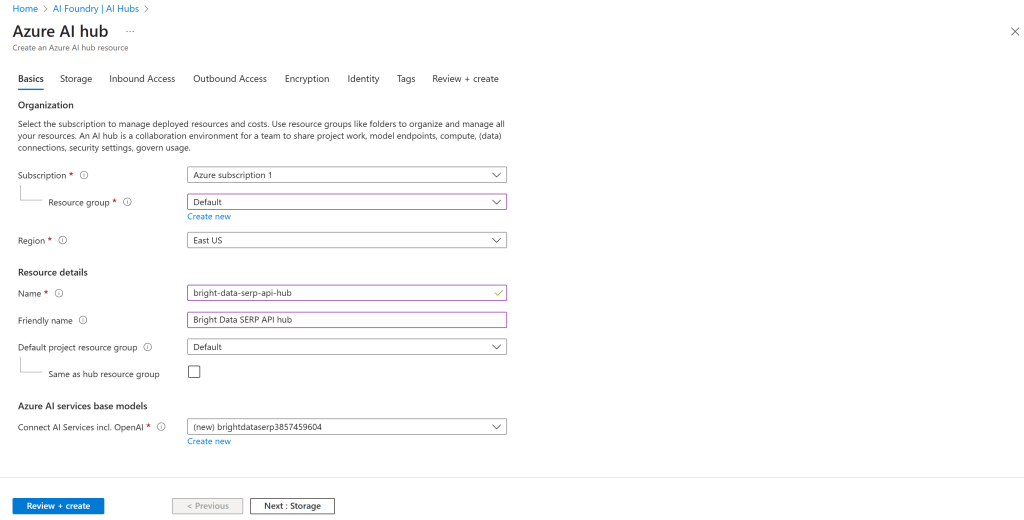
选择区域,选择现有资源组(如有需要也可新建),并为 Hub 命名,例如 bright-data-serp-ai-hub。
接着点击“Review + Create(审核并创建)”。系统将显示摘要:
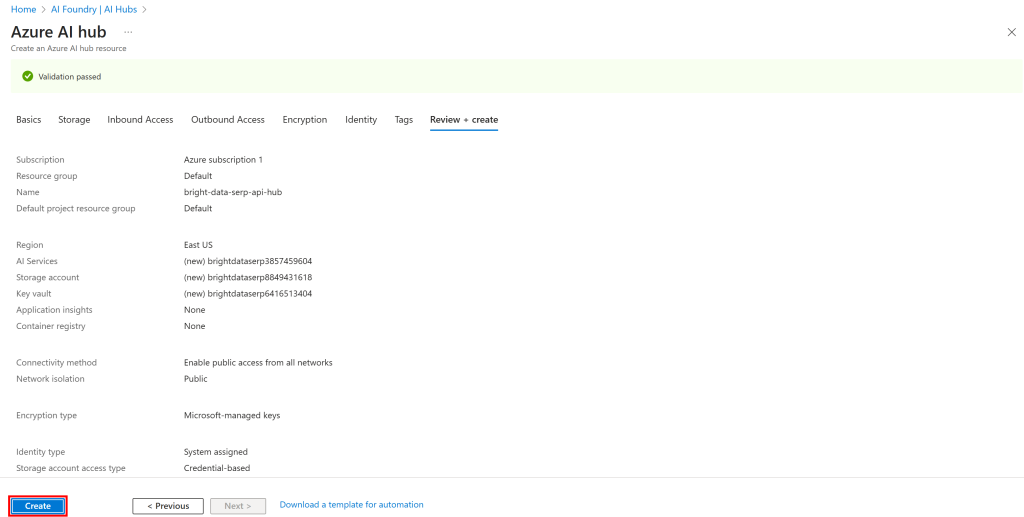
如果一切无误,点击“Create(创建)”开始部署。
初始化过程可能需要几分钟。完成后,你会看到如下确认页面:
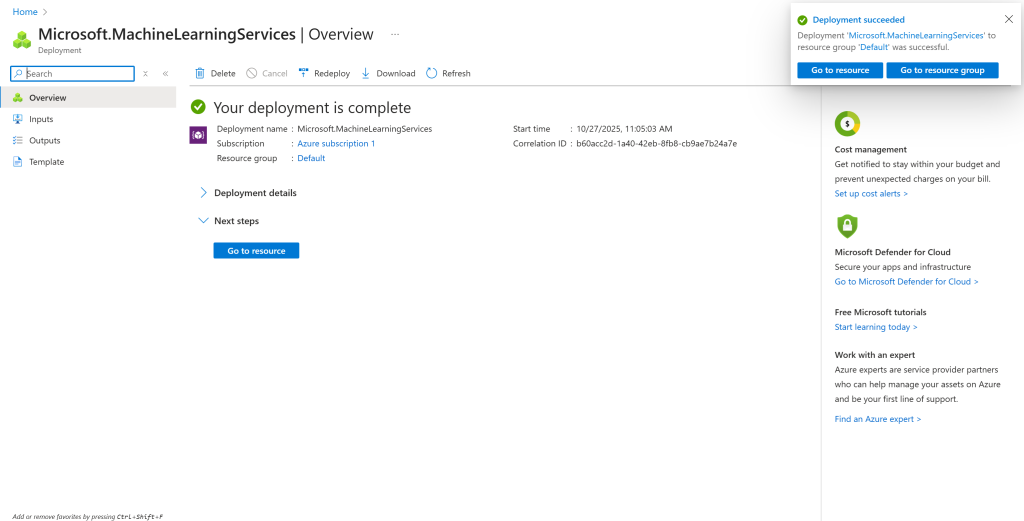
太棒了!你现在拥有一个 Azure AI Hub,可以在其中创建项目并初始化提示流。
步骤 2:在 AI Hub 中创建项目
要管理提示流,你需要先在 AI Hub 中创建一个项目。先点击左侧菜单中的“AI Hubs”选项:
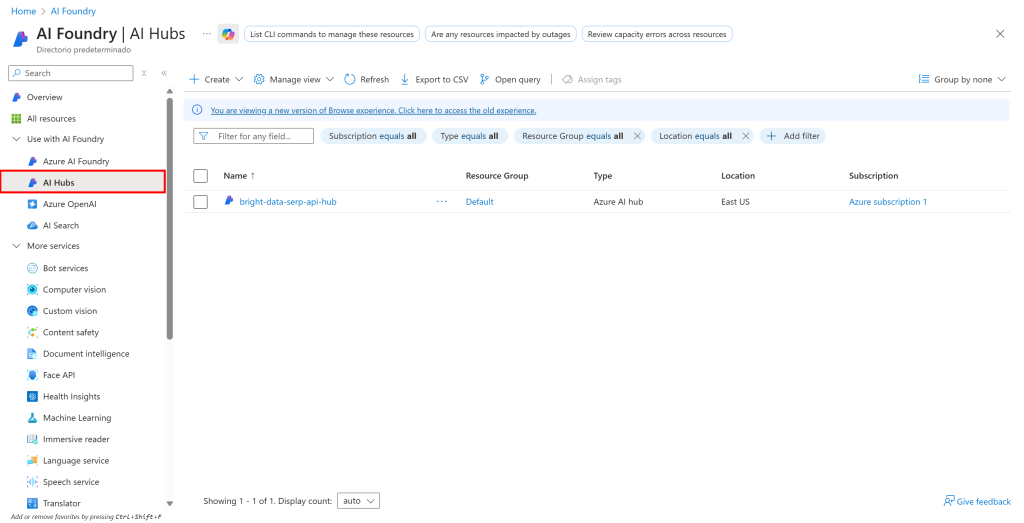
点击你的 Hub 名称,在右侧出现的区域选择“Create project(创建项目)”:
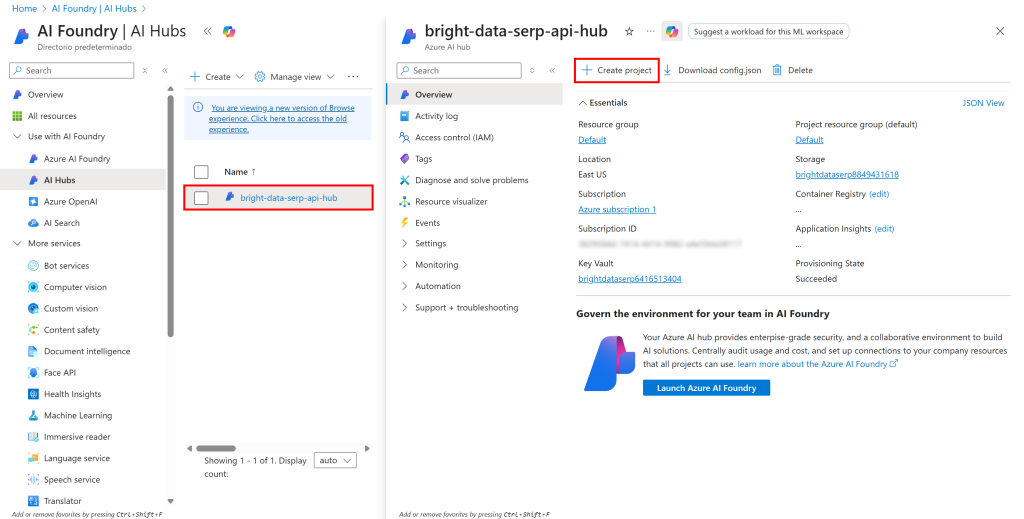
填写项目创建表单。此处可将项目命名为 serp-api-flow:
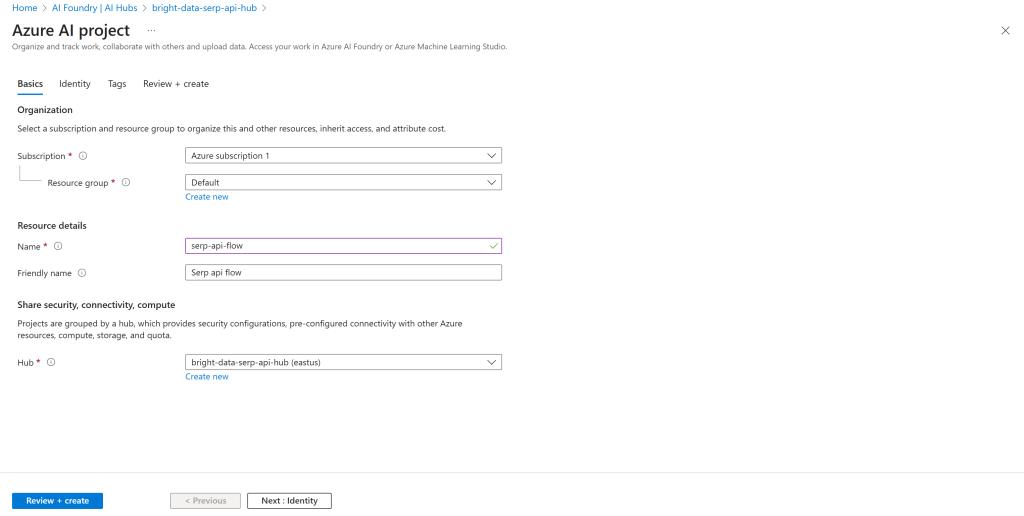
点击“Review + create(审核并创建)”,在摘要中确认无误后点击“Create(创建)”部署项目。
等待片刻以初始化项目。准备就绪后,它会显示在“AI Hubs”页面中。点击它:
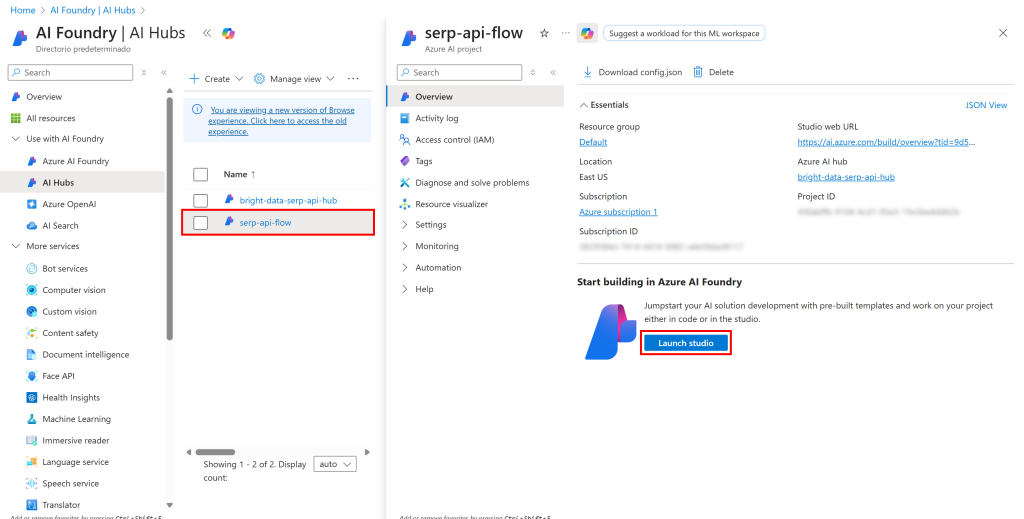
按下“Launch studio(启动 Studio)”在 Azure AI Foundry studio 中打开:
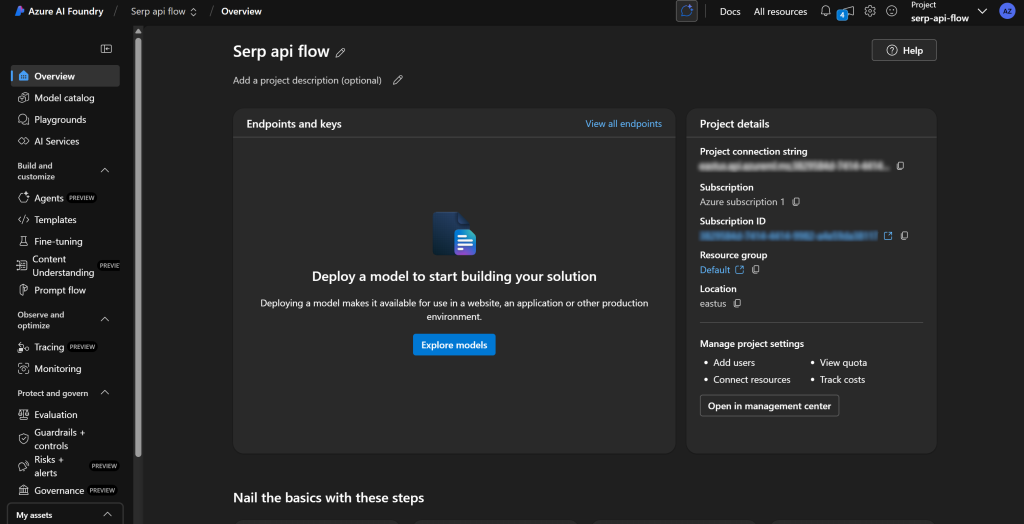
注意顶部显示你当前位于“Serp api flow”项目中。如果不是(例如你有多个项目),请确保选择正确的项目。
很好!准备定义 Azure AI 提示流。
步骤 3:部署 LLM
要在提示流中使用 LLM 节点,Azure 要求你先部署一个可用的 AI 模型。
在左侧菜单选择“Model catalog(模型目录)”。在目录页搜索你要使用的模型。例如假设你想用 gpt-5-mini。
搜索“gpt-5-mini”并选择它:
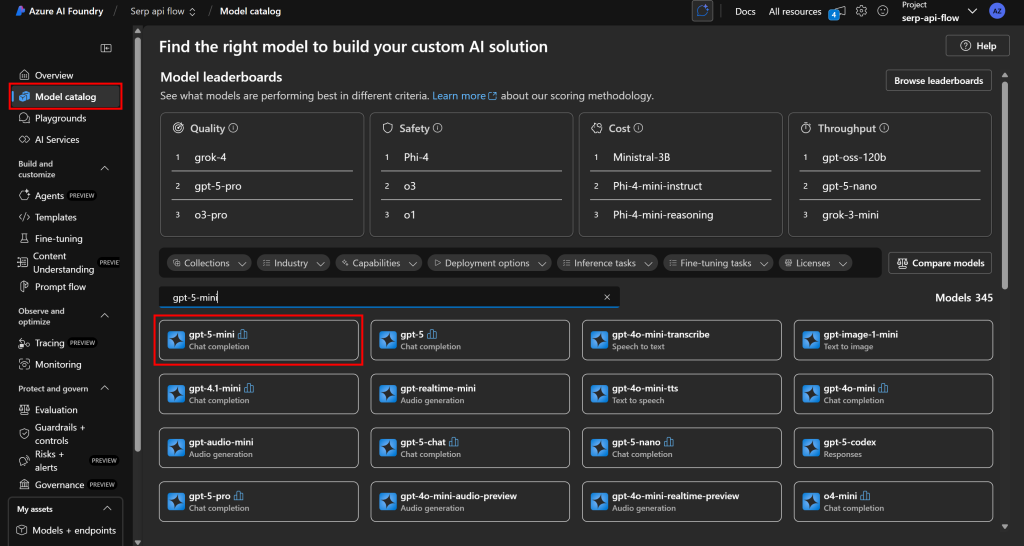
在模型页面点击“Use this model(使用此模型)”:
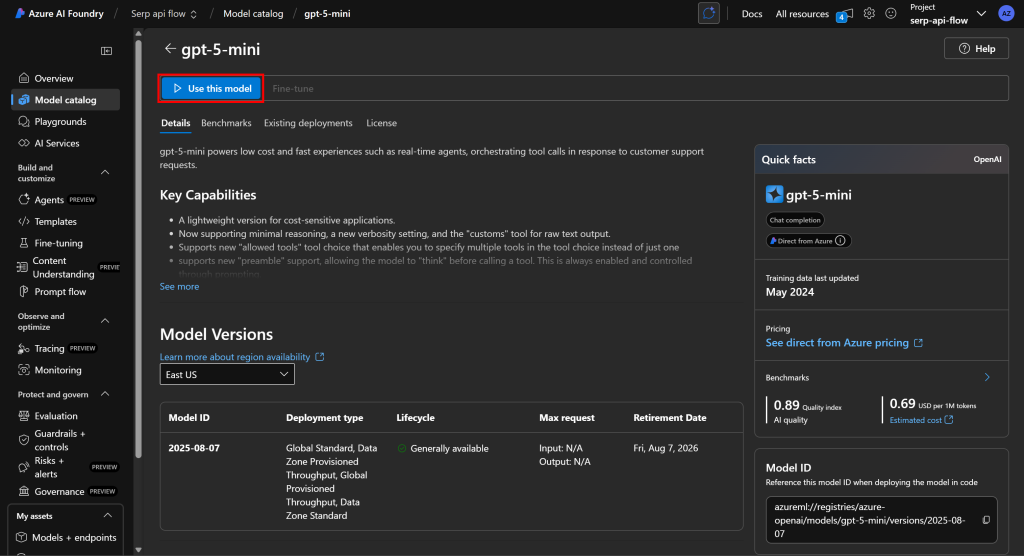
在弹出窗口中点击“Create resource and deploy(创建资源并部署)”,然后等待模型部署完成:
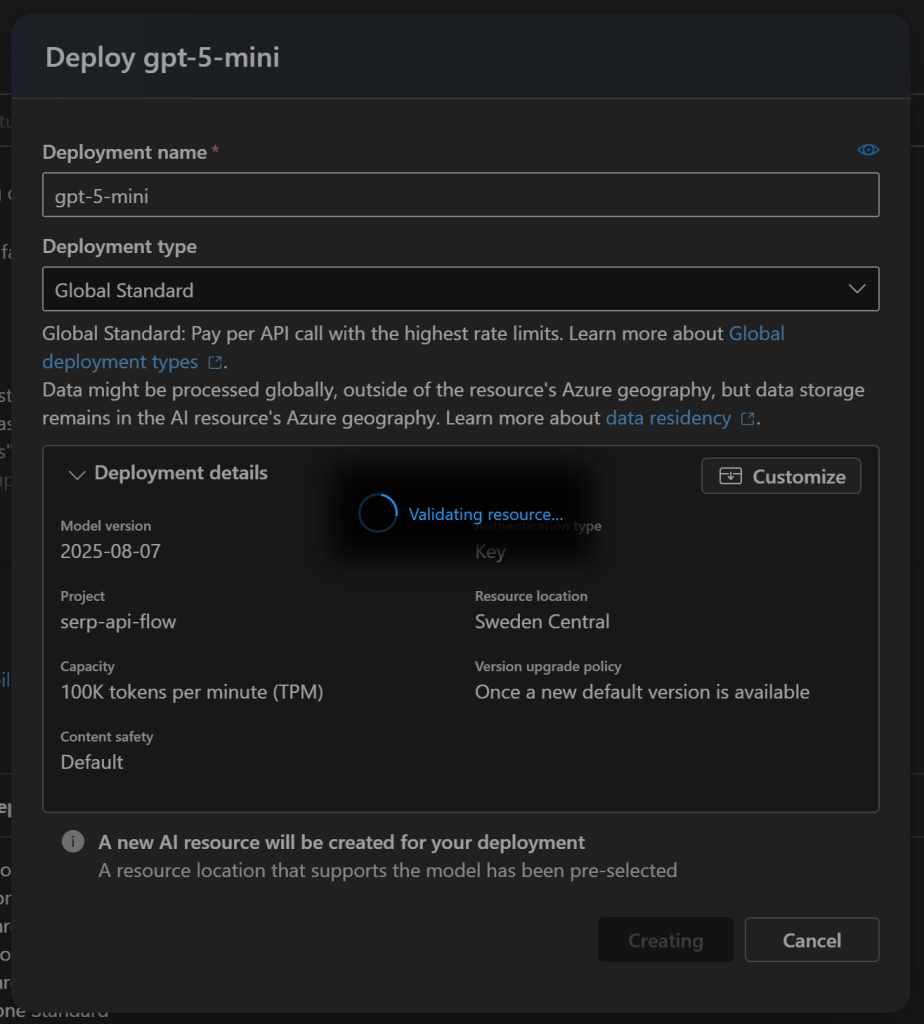
这一过程可能需要几分钟,请耐心等待。部署完成后,你将在 Azure AI 项目中看到该模型如下所示:
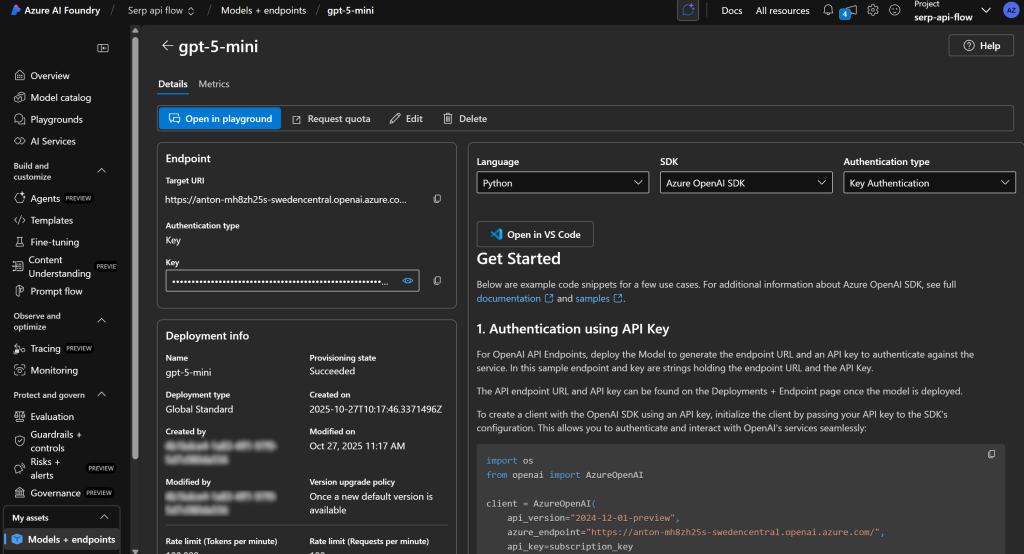
太好了!你现在拥有一个可为提示流提供动力的 LLM 引擎。
步骤 4:创建新的 Prompt Flow
现在可以开始构建提示流了。先在左侧选择“Prompt flow”,然后点击“Create(创建)”按钮:
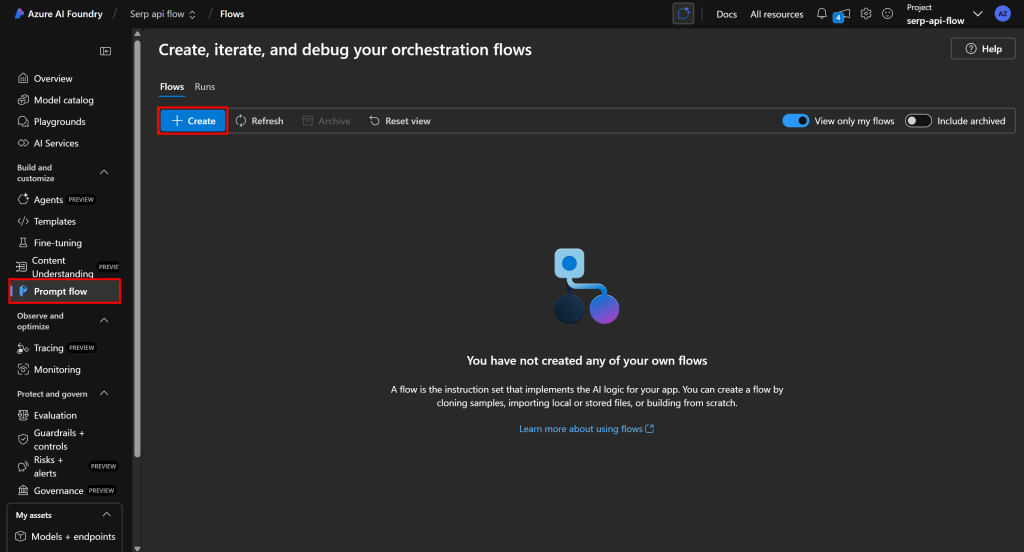
在“Create a new flow(创建新流)”弹窗中,在“Standard flow(标准流程)”卡片上点击“Create(创建)”以新建一个基础提示流:
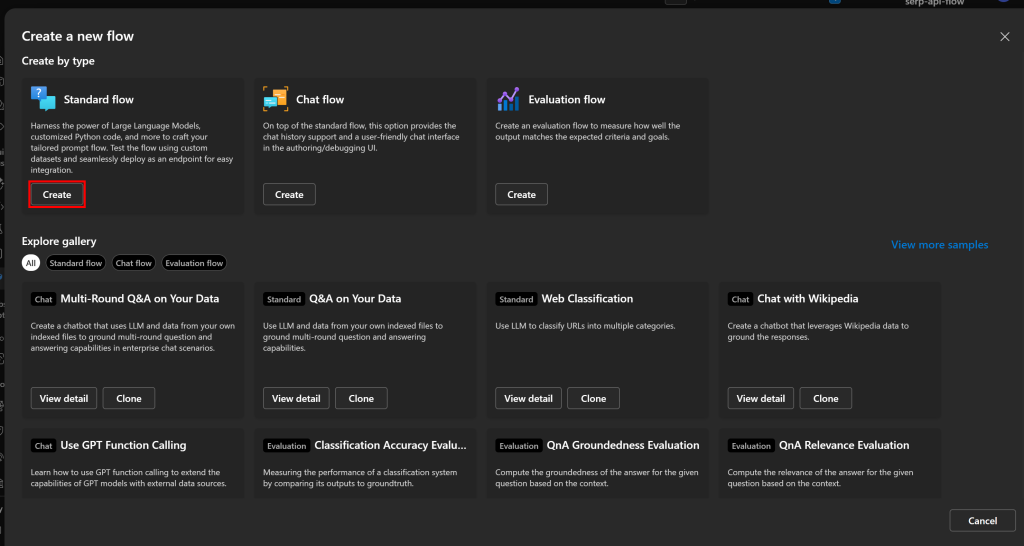
系统会提示输入流名称。可命名为 bright-data-serp-api-flow:
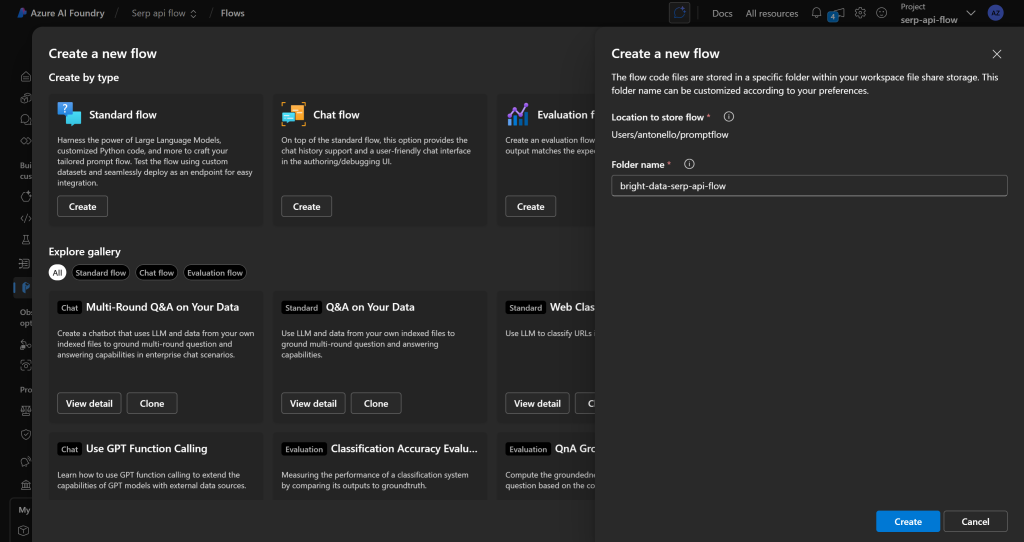
点击“Create(创建)”,等待提示流初始化,你将看到如下界面:
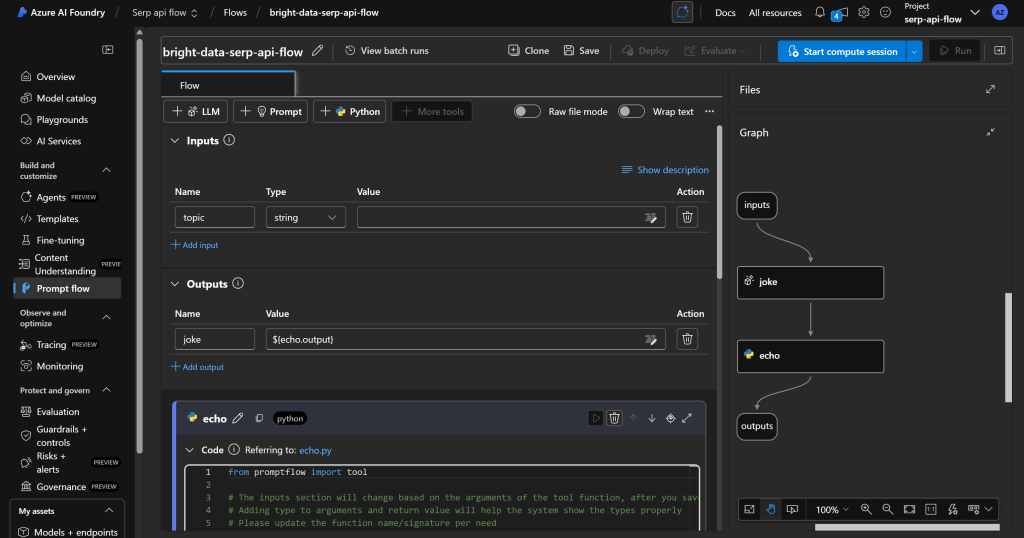
右侧为你的流程的 DAG(有向无环图) 表示;左侧是可视化编辑器,可定义流程节点。左侧的任何更改都会自动反映在右侧 DAG 中。
默认的标准流程包含一个让 AI 讲笑话的简单示例。
请从零开始,删除所有现有节点,并点击“Start compute session(开始计算会话)”以启动流程开发环境:
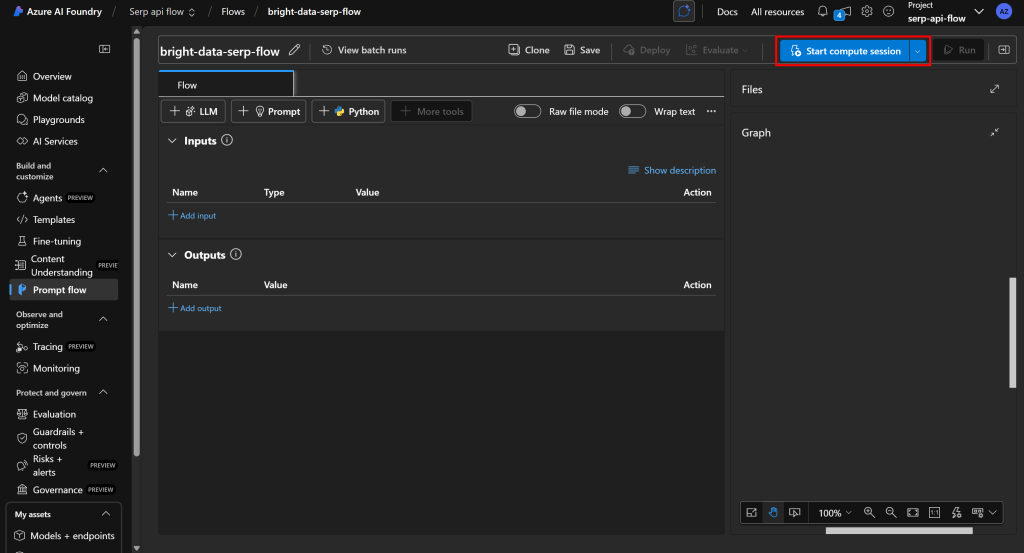
注意:启动计算会话时,Azure 会尝试启动默认计算实例。但分配资源可能需要数分钟甚至数小时。为避免长时间等待,建议使用自定义配置在你自己的计算实例上手动启动会话。
干得好!现在你有了一块空白画布,即将把它变成一个由 Bright Data SERP API 驱动的 Azure AI 提示流。
步骤 5:设计你的提示流
在构建流程前,先清晰定义其中包含的节点。
本例的目标是构建一个新闻检索与评估流程。给定主题后,依靠 Bright Data SERP API 从 Google 获取相关新闻,并将其传递给 LLM 按“阅读价值”进行评估,从而快速识别哪些文章值得读。
为实现该目标,流程将包含四个节点:
- 一个输入节点,用于接收要进行新闻搜索的主题。
- 一个 Python 工具节点,使用提供的主题调用 Bright Data 的 SERP API。
- 一个 LLM 节点,处理 API 返回的 SERP 数据以识别并评估新闻。
- 一个输出节点,展示由 LLM 生成的最终报告。
接下来你将学习如何实现这一 Azure AI 提示流!
步骤 6:添加输入节点
每个流程都必须包含输入和输出节点。因此,这两个节点无法删除,且已预置在流程中。
要配置输入节点,前往流程的“Inputs(输入)”部分并点击“Add input(添加输入)”按钮:
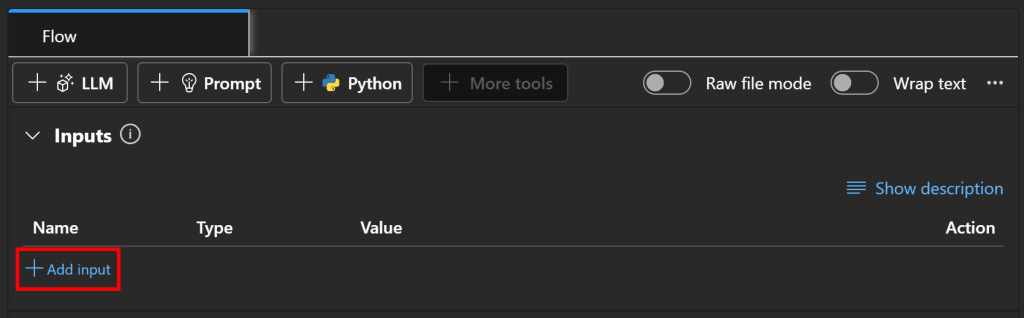
将输入定义为 topic 并将类型设置为字符串(string):
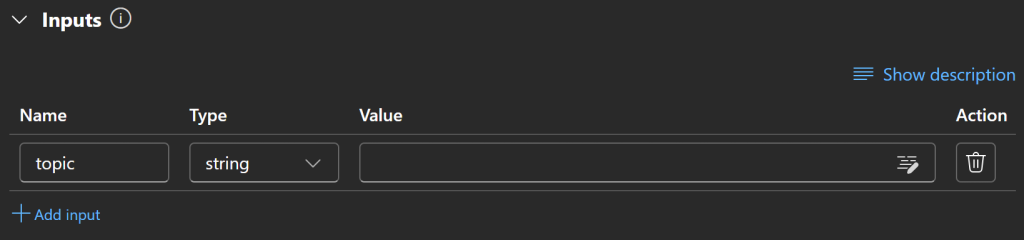
很好!输入节点已配置完成。
步骤 7:准备调用 SERP API
在创建调用 Bright Data SERP API 的自定义 Python 节点之前,需要先进行一些准备工作。这些步骤并非强制,但可以简化集成并提升安全性。
首先,为了更轻松地进行 API 调用,安装 Bright Data Python SDK。该 SDK 提供了与Bright Data 产品(包括 SERP API)交互的便捷方法(无需通过 HTTP 客户端直接调用 API)。更多信息见官方文档。
该 SDK 在 PyPI 上的包名为 brightdata-sdk。要在流程中安装它,点击左侧的“Compute session running(计算会话正在运行)”,然后选择“Install packages from requirements.txt(从 requirements.txt 安装依赖)”:
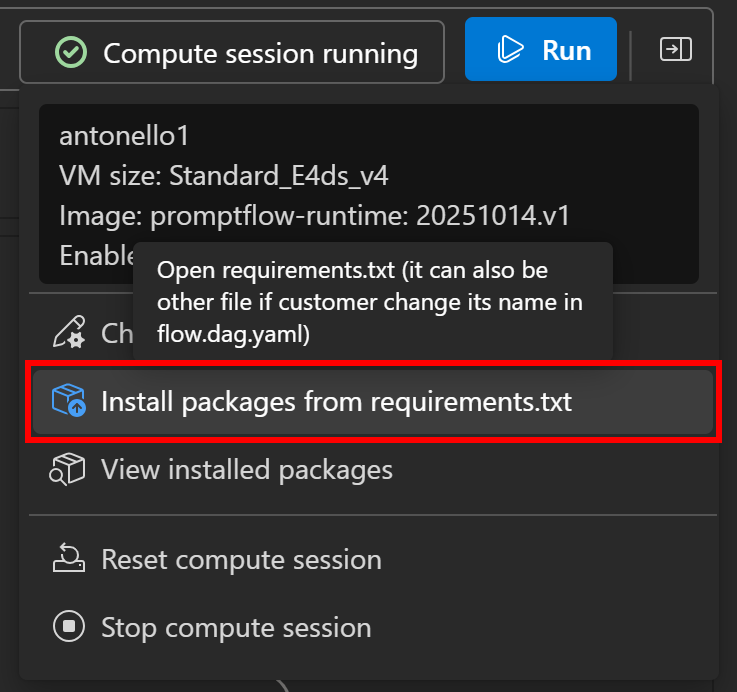
流程定义面板会打开一个 requirements.txt 文件。向其中添加以下一行,然后点击“Save and install(保存并安装)”:

安装完成后,你就可以在自定义 Python 工具节点中使用 Bright Data Python SDK 了。
接下来,由于 SERP API 需要通过 API 密钥进行身份验证——而你并不希望将其硬编码在流程中——建议将其作为机密(secret)安全存储在 Azure 中。为此,从左侧菜单打开“Management center(管理中心)”(通常是最后一个选项):
在项目管理概览中,于“Connected resources(连接的资源)”部分下点击“New connection(新建连接)”:
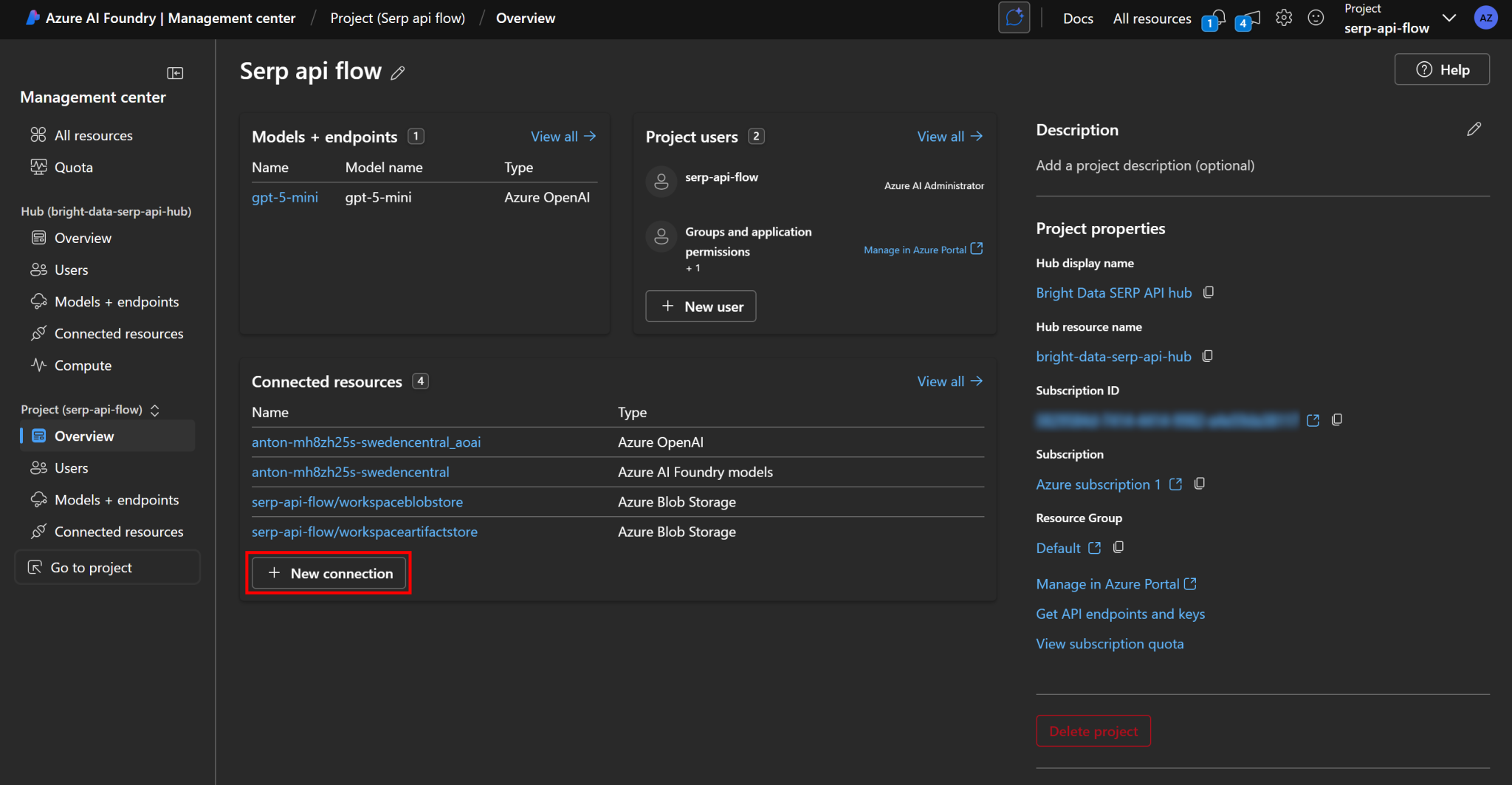
在弹窗中选择“Custom keys(自定义密钥)”选项:
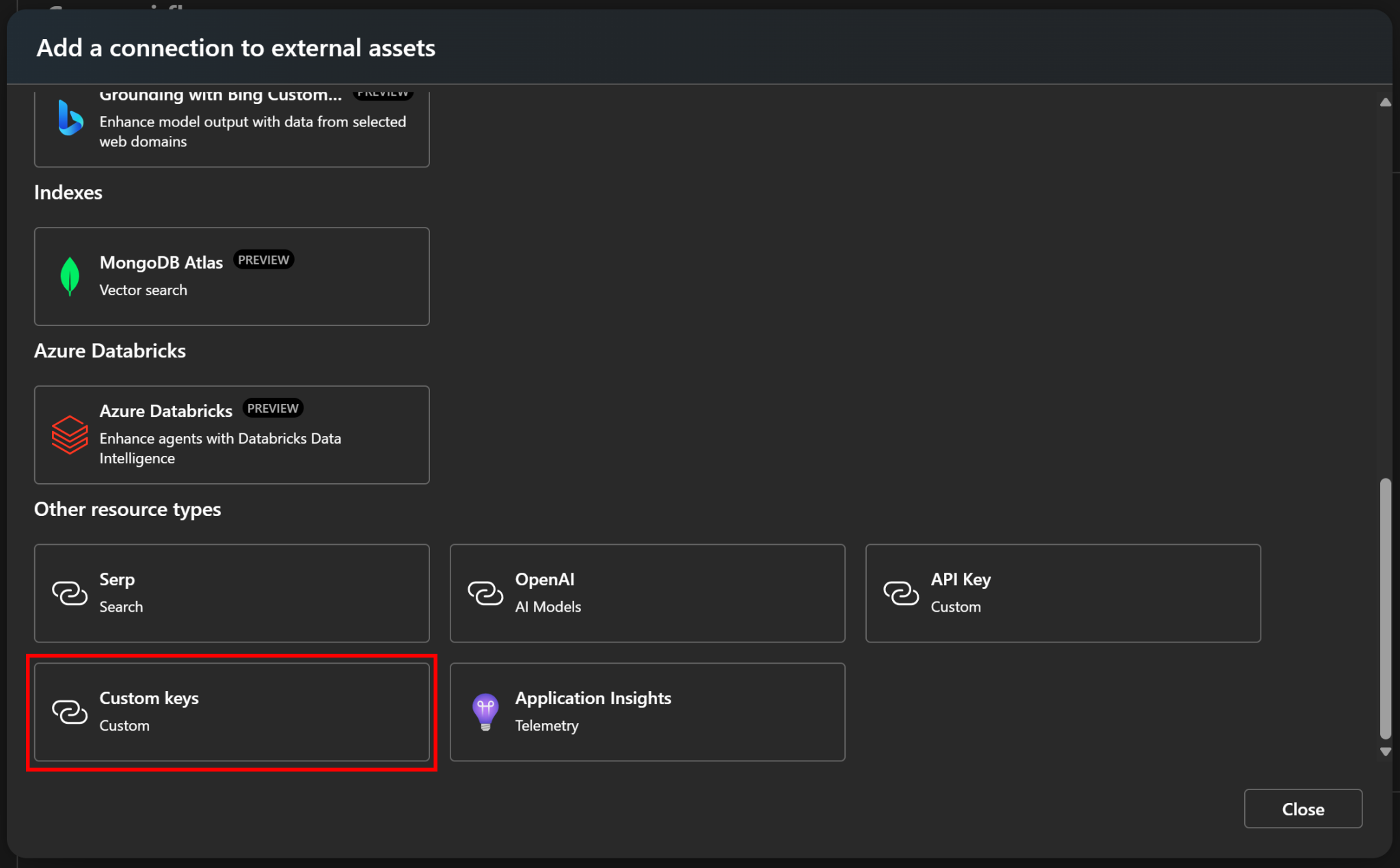
这就是在 Azure AI Foundry 中存储自定义 API 密钥的方式。
现在,新建一个名为 BRIGHT_DATA_API_KEY 的密钥,并将你的 Bright Data API 密钥粘贴到值字段。务必勾选“is secret(为机密)”。然后为连接起一个易识别的名称,例如 bright-data:
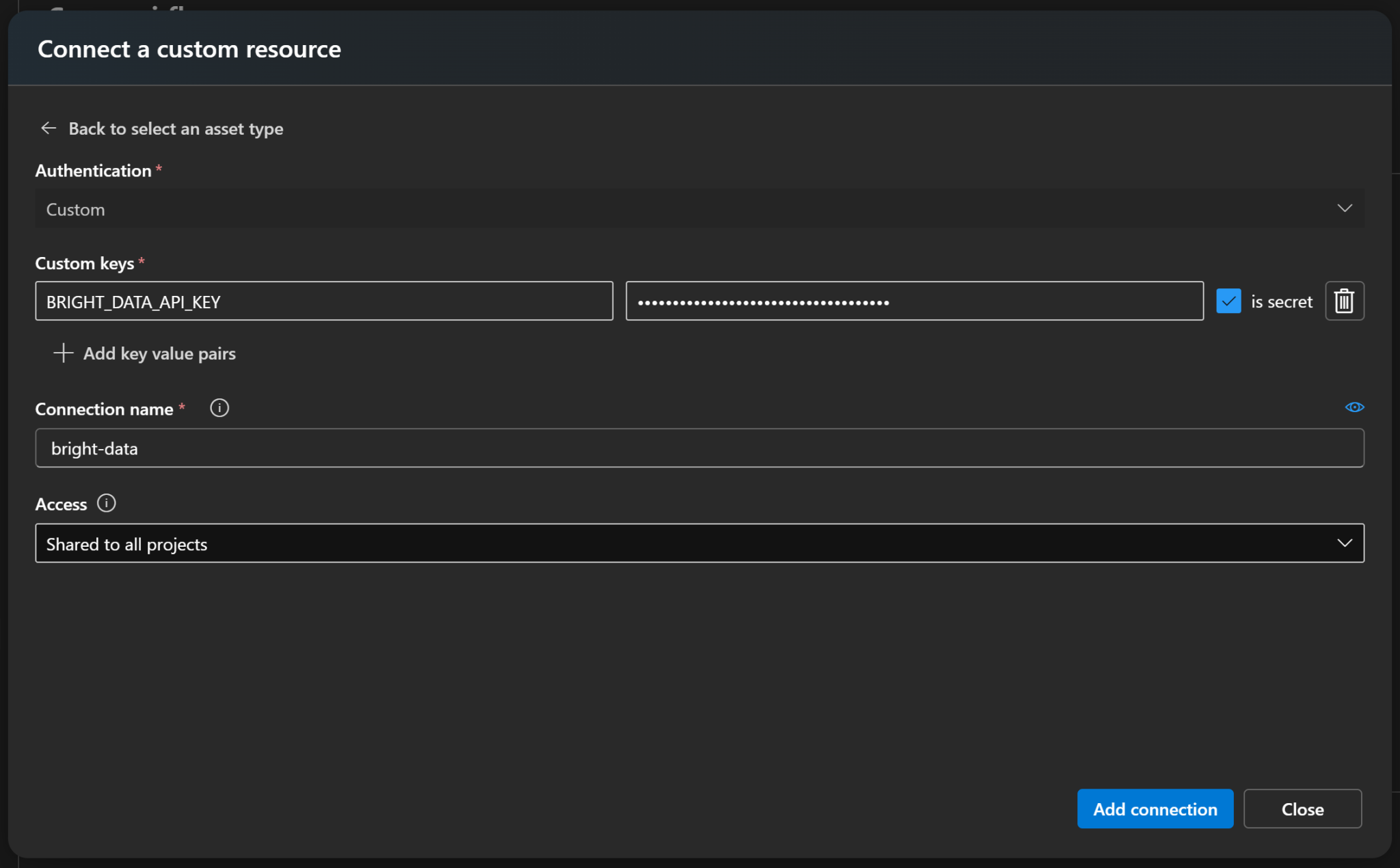
最后点击“Add connection(添加连接)”保存。
很好!返回到你的流程。你将看到如何用少量代码,在 Bright Data Python SDK 与已存储 API 密钥的帮助下调用 SERP API。
步骤 8:定义用于调用 Bright Data SERP API 的自定义 Python 节点
在流程画布中,点击“Python”按钮创建一个新的Python 工具节点:

将节点命名为 serp_api,然后点击“Add(添加)”:

在代码文本区域中添加以下 Python 代码:
from promptflow import tool
from promptflow.connections import CustomConnection
from brightdata import bdclient
@tool
def serp_api(search_input: str, bd_conn: CustomConnection) -> str:
# Initialize the Bright Data SDK client
client = bdclient(api_token=bd_conn.BRIGHT_DATA_API_KEY)
# Retrieve the SERP from Google in Markdown format
serp_page = client.search(
search_input,
data_format="markdown",
country="us"
)
return serp_page在 Azure AI Foundry 中,Python 节点必须将工具定义为使用 @tool 注解的函数。本例中,serp_api() 函数接收搜索输入字符串和自定义连接作为入参。
该函数从自定义连接中读取你先前定义的 BRIGHT_DATA_API_KEY,并用它初始化 Bright Data API 的 Python SDK 客户端。随后通过 search() 方法调用 SERP API,并使用 data_format="markdown" 与 country="US" 选项,从美国版 Google 返回已抓取的 Markdown SERP 页面(非常适合 AI 摄取)。
接着,向下滚动并定义该节点的输入元素。首先点击“Validate and parse input(验证并解析输入)”以使节点识别有效输入。通过如下映射配置输入:
- 将
bd_conn映射为bright-data(先前定义的自定义连接)。 - 将
search_input映射为${input.topic},将输入节点的搜索主题传递给 SERP API。
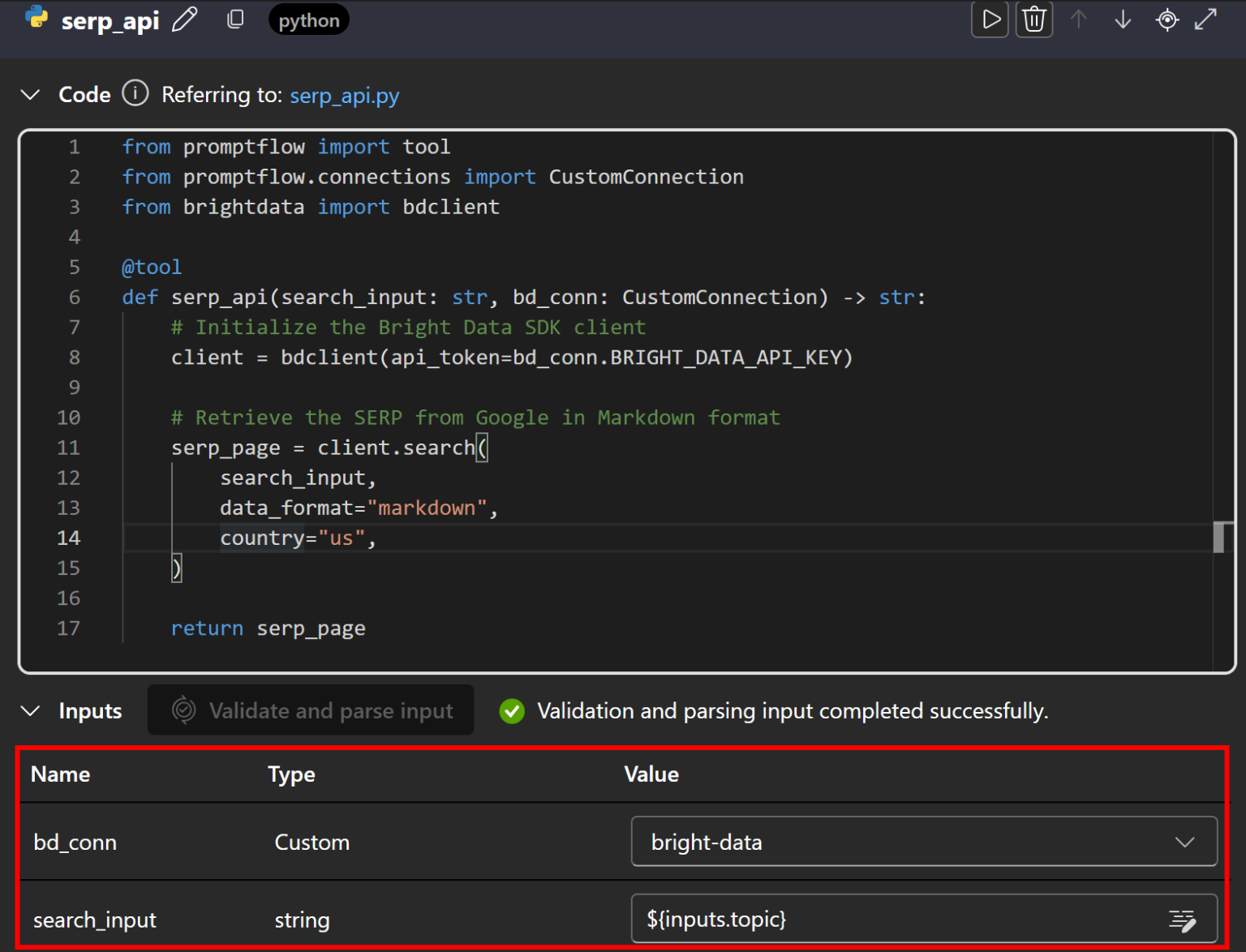
太棒了!已完成在 Azure AI Foundry 中集成 Bright Data SERP API。
步骤 9:指定 LLM 节点
现在你已经获取了与初始搜索主题对应的 SERP 页面,将其输入给 LLM 以进行新闻抽取与评估。点击“Flow(流程)”标签下方的“LLM”按钮添加一个LLM 节点:

将 LLM 节点命名为 llm 并点击“Add(添加)”确认:

该节点将定义你的提示流的核心逻辑。为实现新闻抽取与评估,可使用如下提示:
# system:
You are a news analysis assistant tasked with identifying the most relevant news articles for a given topic.
# user:
Given the SERP page below, extract the most important news items and evaluate each one on a scale of 1 to 5 based on how worth reading it appears.
Return a Markdown-formatted report containing:
* News title
* News URL
* Short description (no more than 20 words)
* Reading worthiness (1–5)
SERP PAGE:
{{serp_page}}# system 部分定义助手的角色与总体行为,而 # user 部分提供具体任务与处理输入的指令。
接下来将 LLM 节点连接到先前部署的 AI 模型(步骤 3):
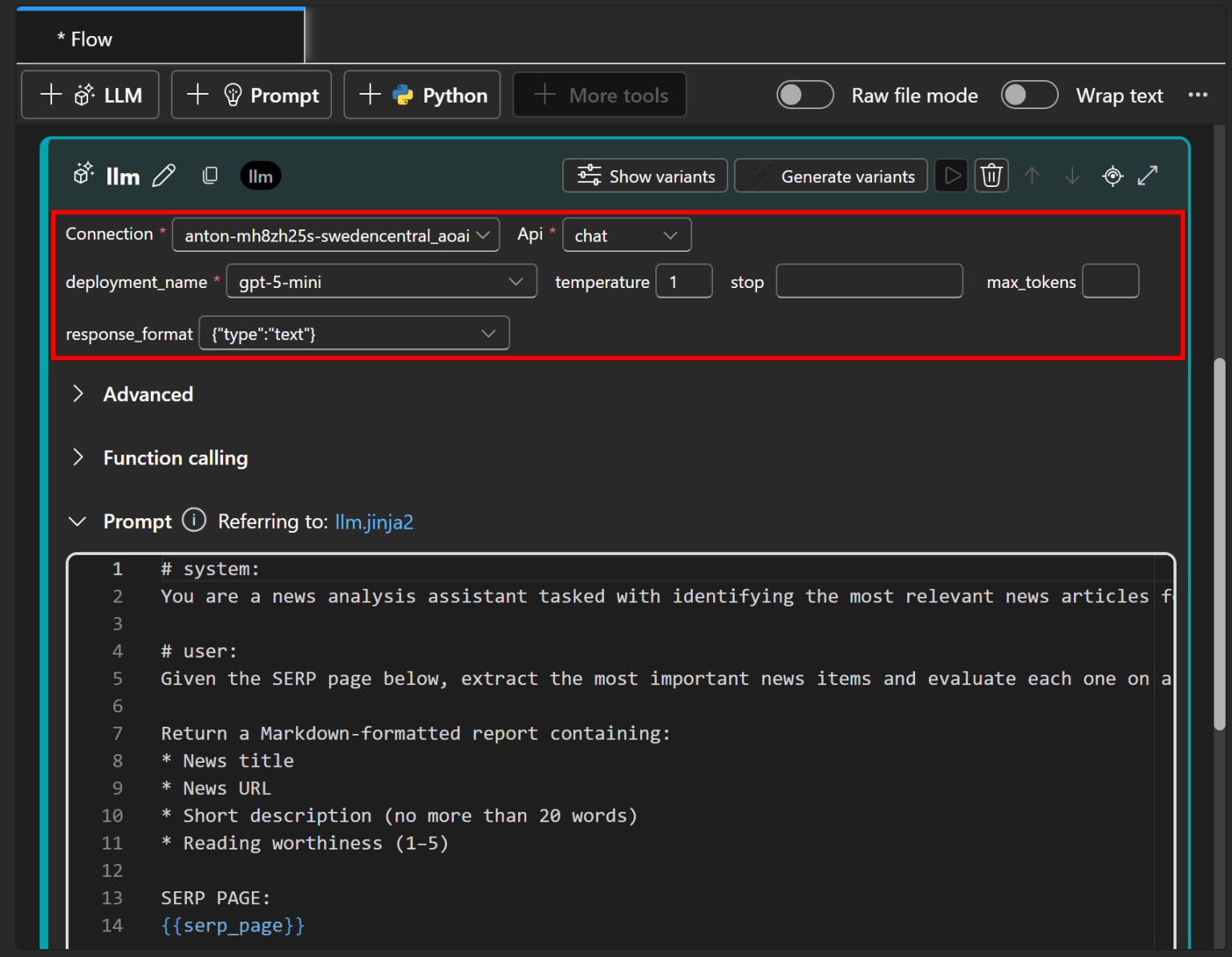
注意提示中包含一个 serp_page 参数,需要将其设置为之前定义的 serp_api 节点的输出。在“Inputs(输入)”部分点击“Validate and parse input(验证并解析输入)”,并将 serp_page 赋值为 ${serp_api.output}:
很好!你的 Azure AI 流程现在拥有一个可处理 SERP 结果并生成新闻评估报告的 LLM “大脑”。
步骤 10:定义输出节点
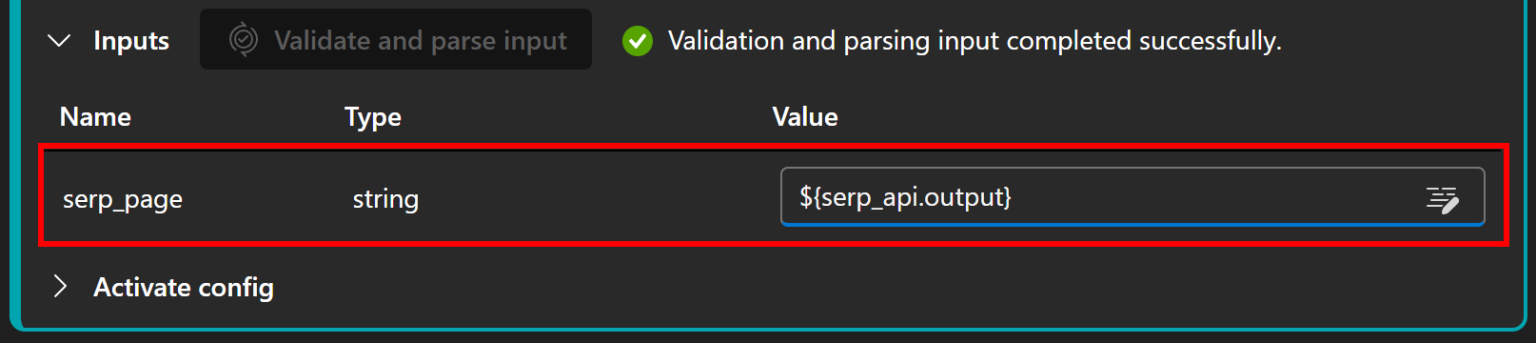
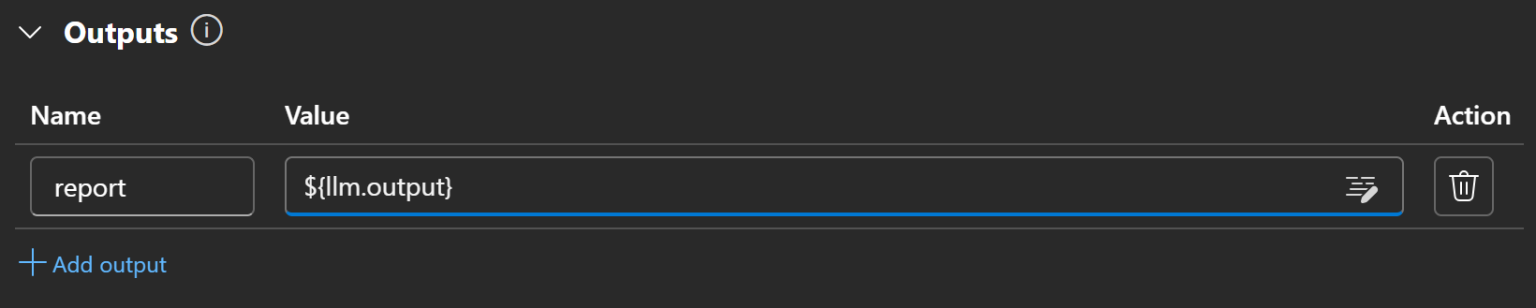
最后一步是配置输出节点。在“Outputs(输出)”部分点击“Add output(添加输出)”:

将输出名称设为 report,并用 ${llm.output} 变量指向 LLM 节点的输出:
完成后点击“Save(保存)”以保存提示流:

恭喜!你的 Azure AI 流程现已全部实现。
步骤 11:整体验证
在流程开发环境的“Graph(图)”部分,你应当看到如下的 DAG:
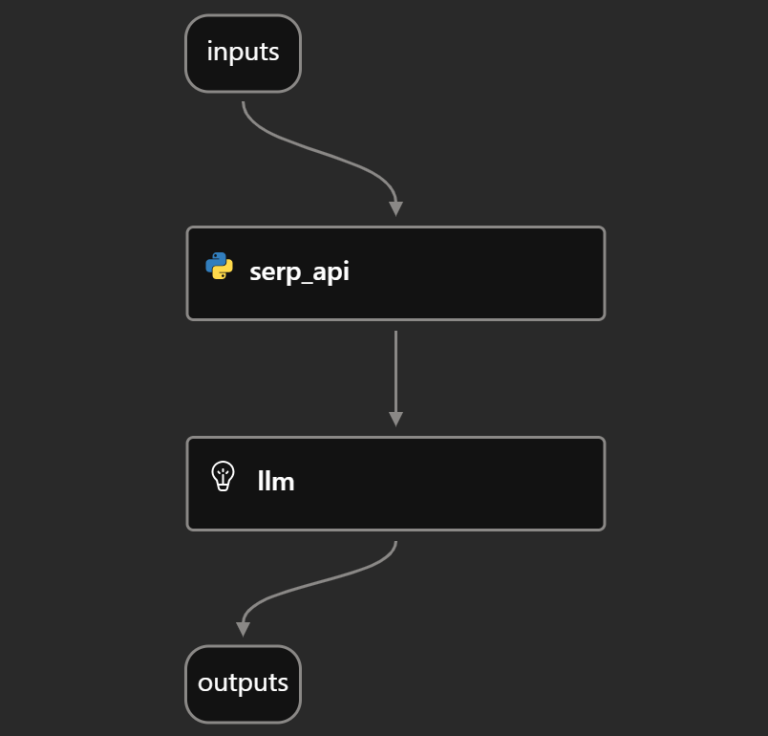
这清晰地展示了步骤 5 中的新闻分析流程:输入、SERP API 调用、LLM 评估与输出如何相互连接。
步骤 12:运行提示流
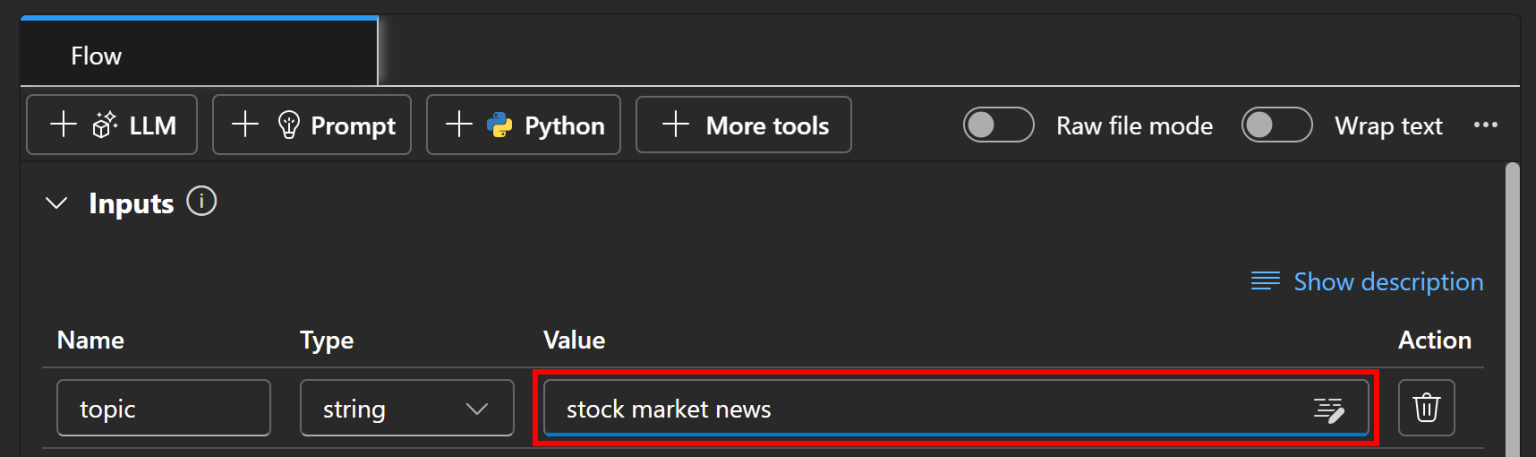
让我们用示例主题“stock market news”测试你的 Azure AI 提示流。在“Inputs(输入)”节点中,将 topic 的“Value(值)”填写为 “stock market news”:
然后点击右上角的“Run(运行)”按钮执行流程:

你会看到数据在流程中传递,每个节点逐渐变为绿色,直至到达“Outputs(输出)”节点:
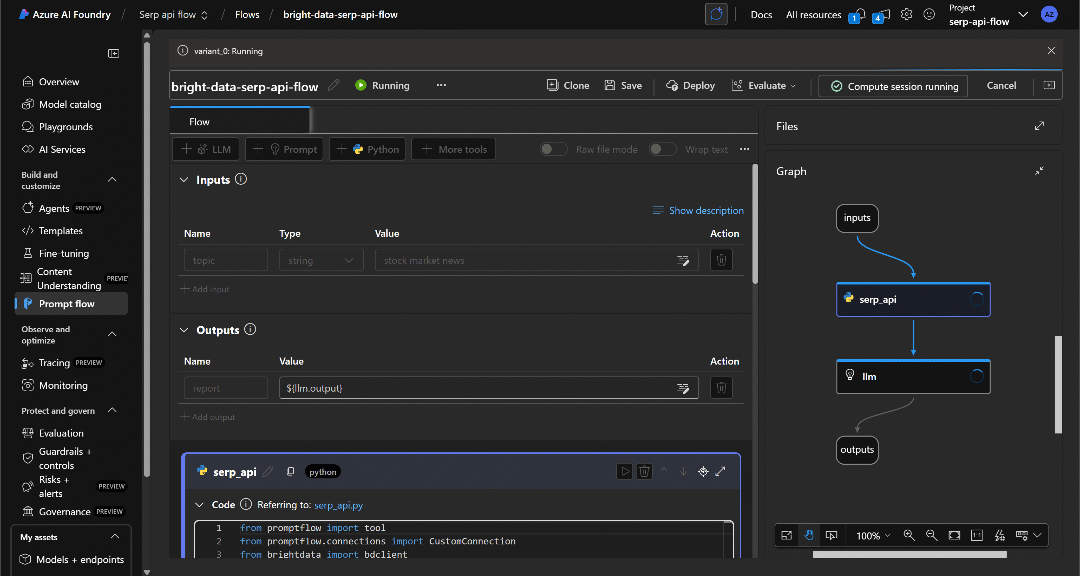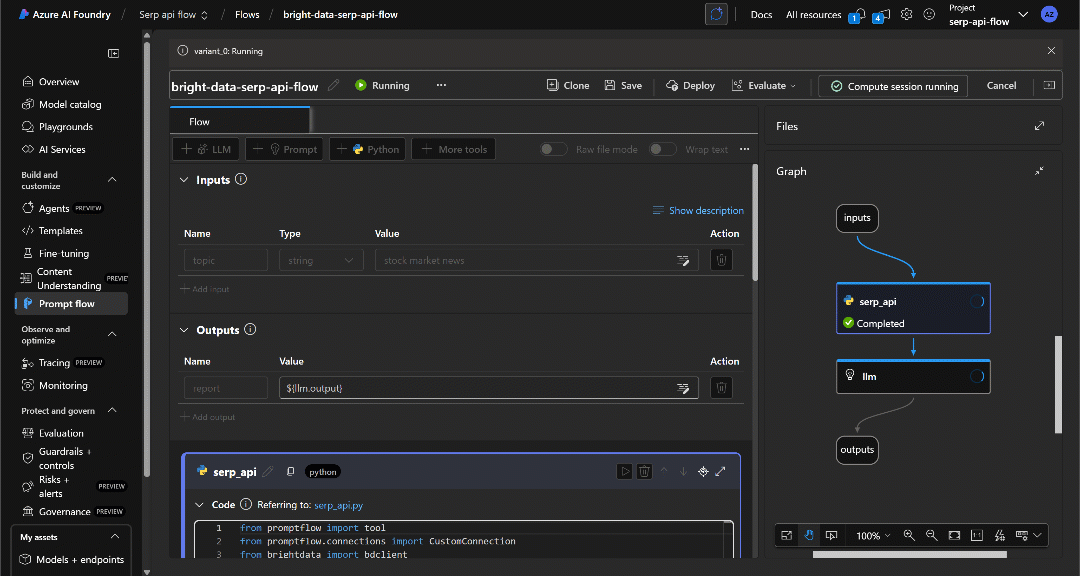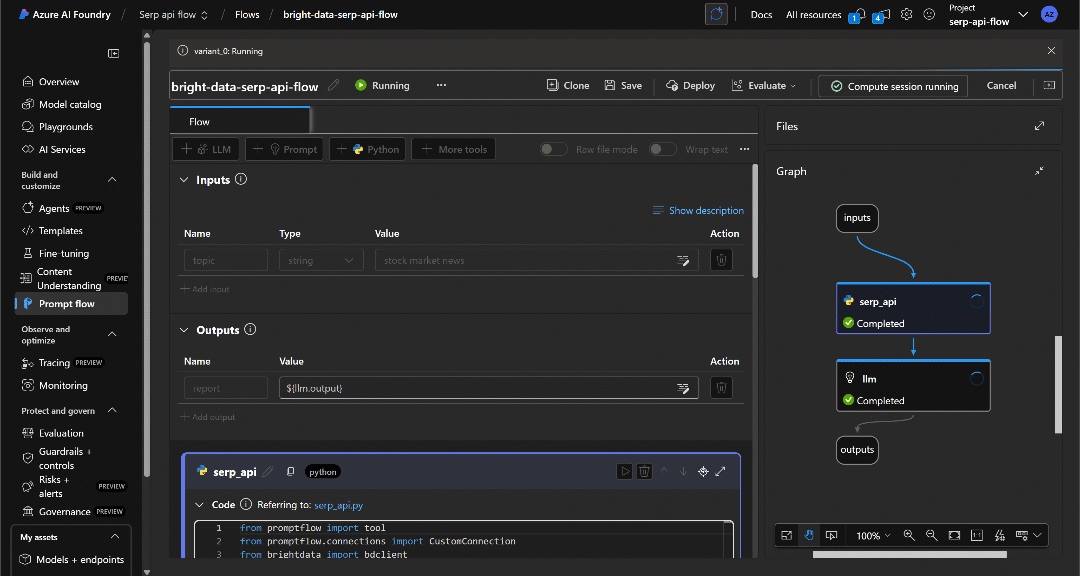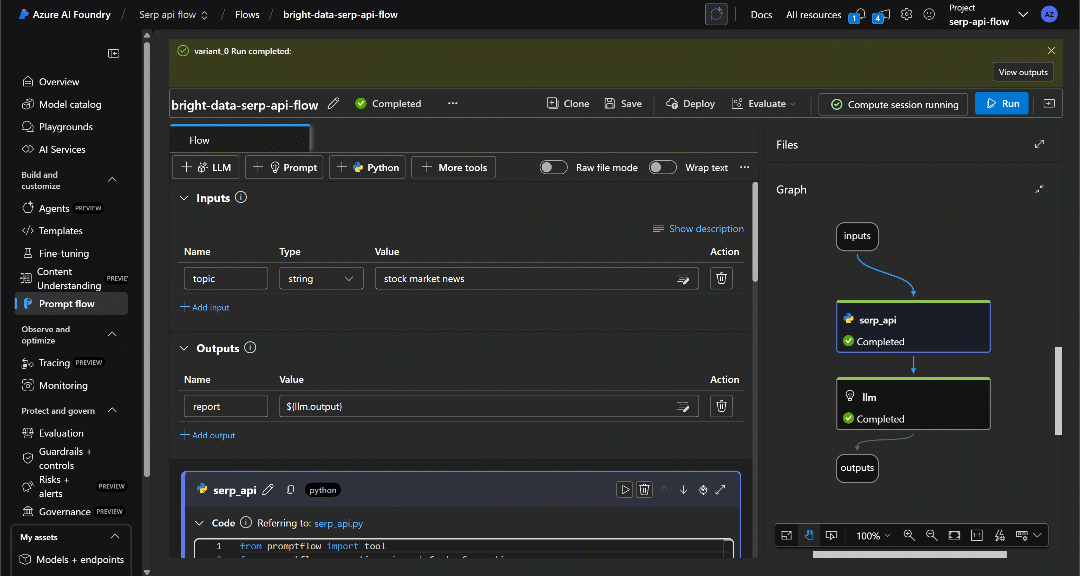
执行完成后,你会收到如下通知:

点击“View outputs(查看输出)”来查看流程结果:
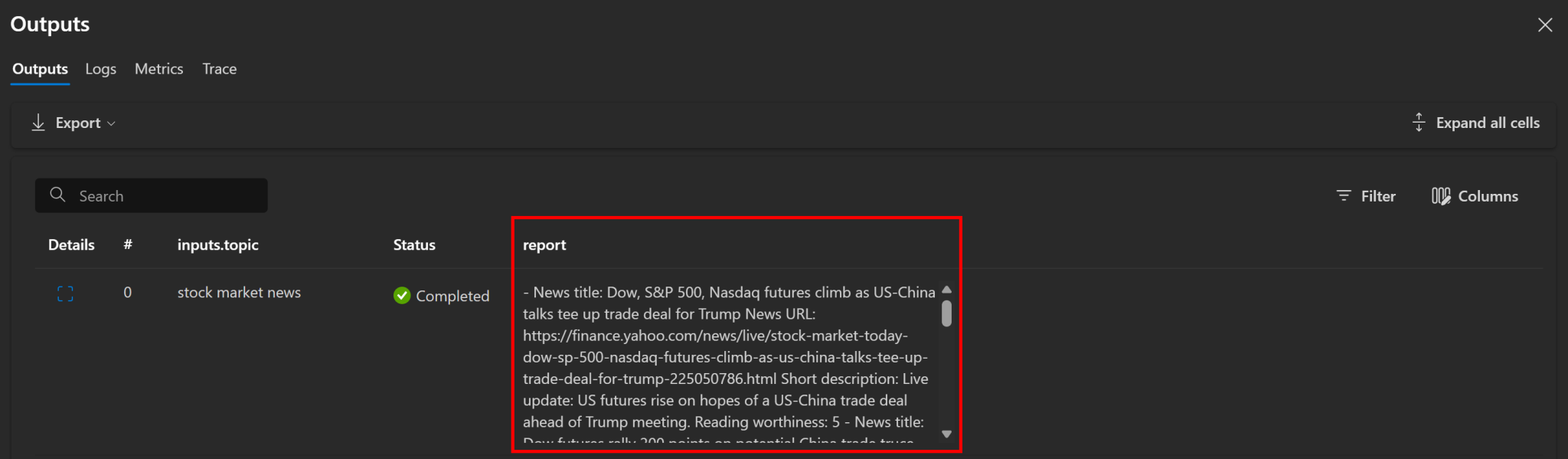
如预期,流程生成了包含新闻条目的 Markdown 报告。示例如下:
- **News title:** Dow, S&P 500, Nasdaq futures climb as US-China talks tee up trade deal for Trump
**News URL:** [Yahoo Finance](https://finance.yahoo.com/news/live/stock-market-today-dow-sp-500-nasdaq-futures-climb-as-us-china-talks-tee-up-trade-deal-for-trump-225050786.html)
**Short description:** Live update: US futures rise on hopes of a US-China trade deal ahead of Trump meeting.
**Reading worthiness:** 5
- **News title:** Stock market today: Dow, S&P 500, Nasdaq futures climb as US-China talks tee up trade deal for Trump
**News URL:** [Yahoo Finance](https://finance.yahoo.com/news/live/stock-market-today-dow-sp-500-nasdaq-futures-climb-as-us-china-talks-tee-up-trade-deal-for-trump-225050786.html)
**Short description:** Markets rise on renewed U.S.–China trade optimism during Trump’s talks.
**Reading worthiness:** 5
# Omitted for brevity...这些结果反映了运行流程时“stock market news”的 SERP 页面:
要确认 SERP 页面是否被正确检索,请查看 serp_api 节点“Outputs(输出)”部分中的“output”标签页:
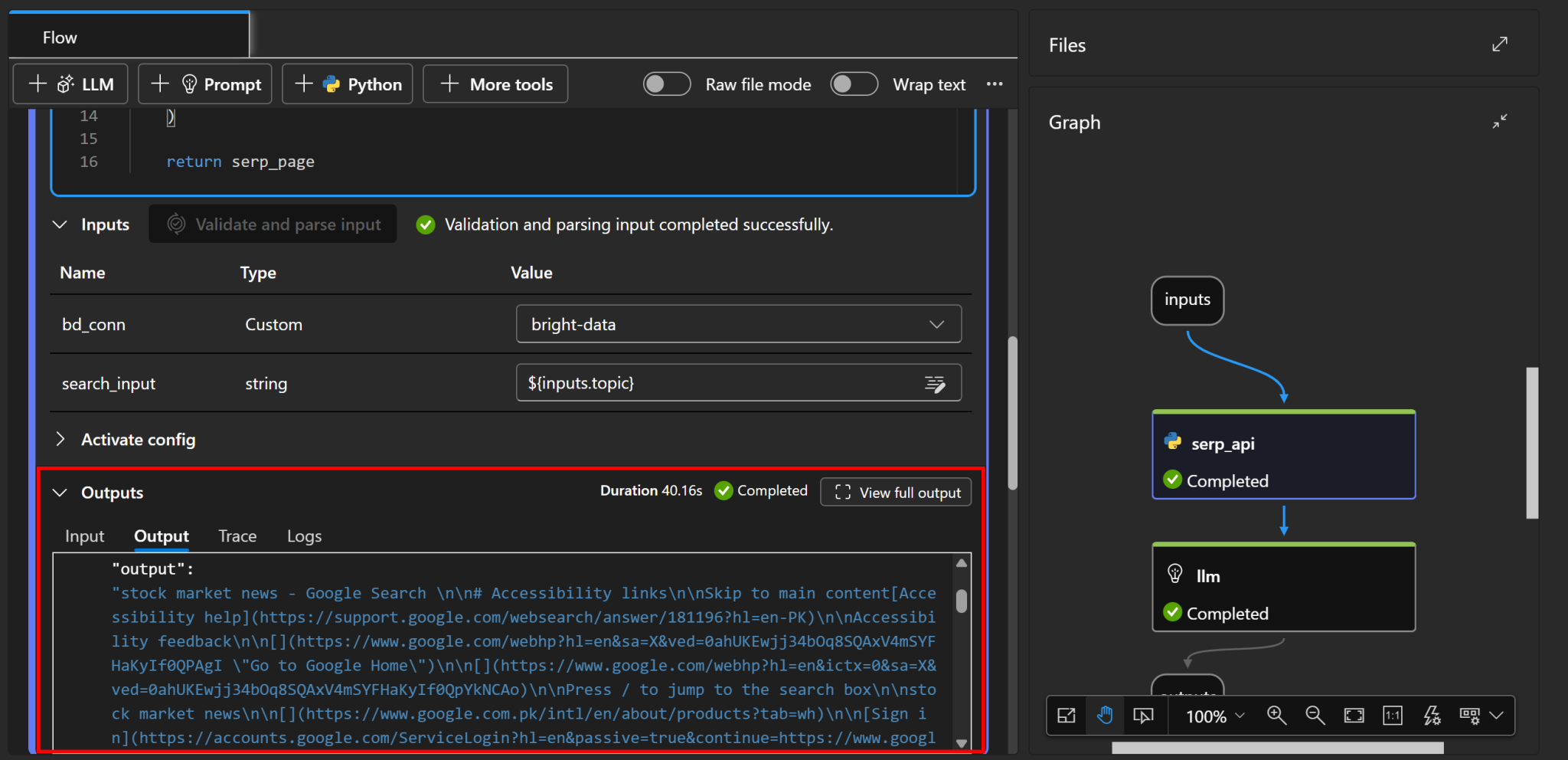
在那里你将看到原始 SERP 的 Markdown 版本。Bright Data 的 SERP API 大显身手!
若要完整查看流程输出,可将 report 输出复制到文件(如 report.md),并在 Visual Studio Code 等 Markdown 查看器中打开:
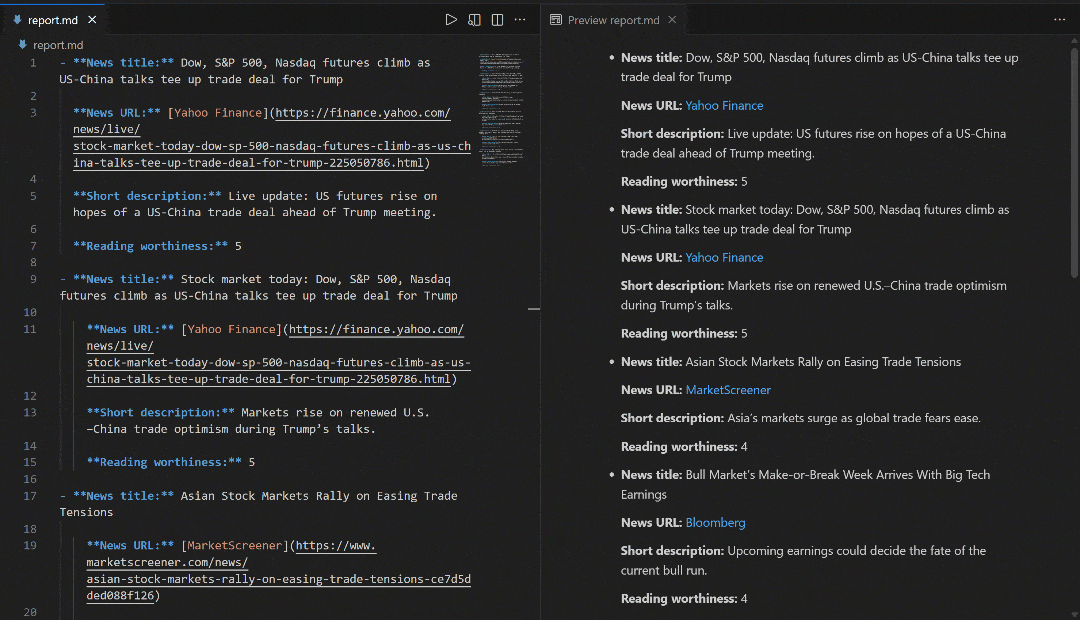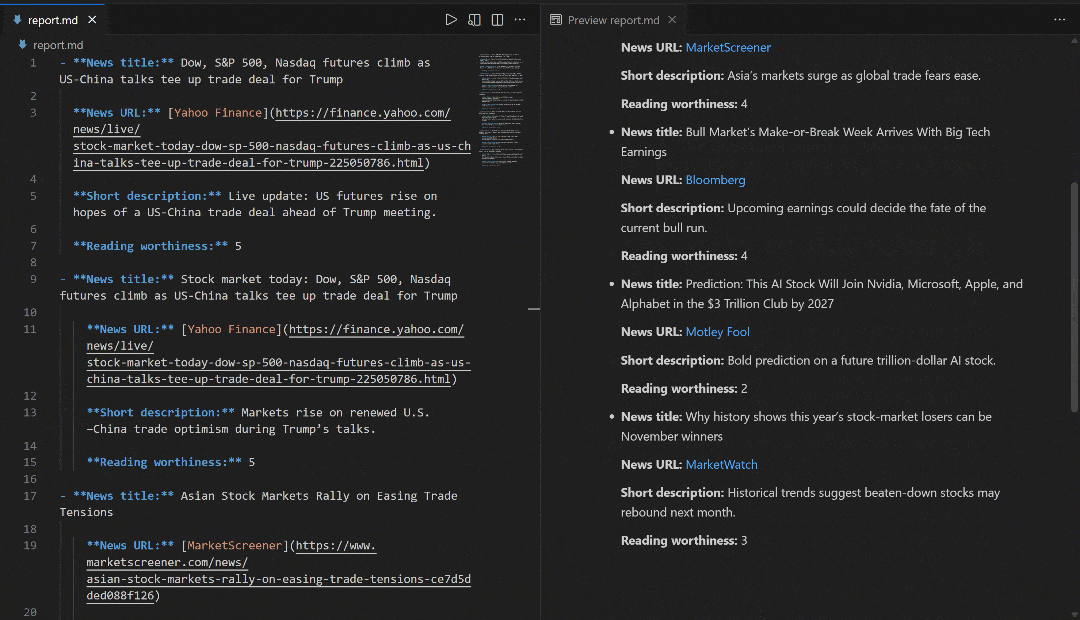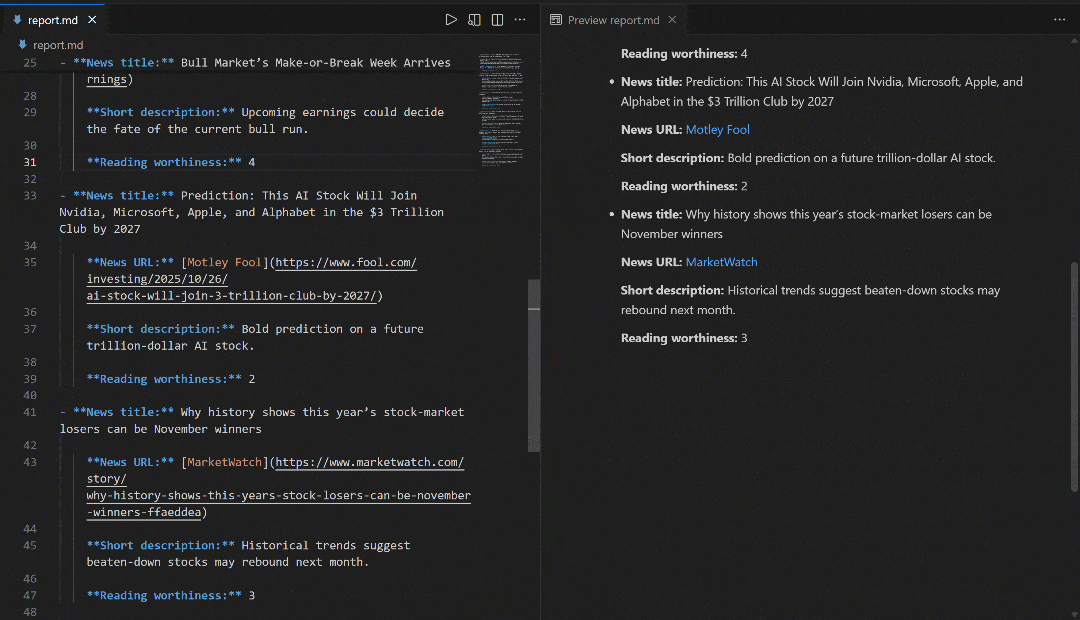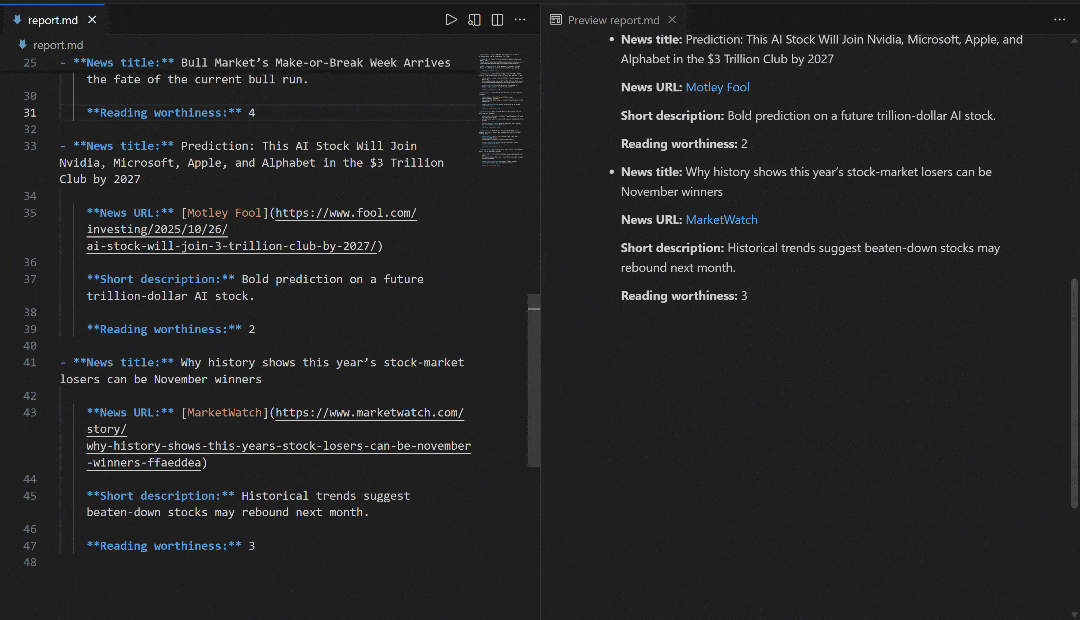
请注意,流程生成的报告与 Google 上“stock market news”的 SERP 新闻相匹配。抓取 Google 搜索结果众所周知非常困难(因反爬措施和速率限制)。借助 SERP API,你可以可靠、轻松地从不同地区获取 Google(或其他受支持搜索引擎)的结果,且以适合 AI 的 Markdown 格式返回,并具备良好可扩展性。
该示例展示了一个简单用例,你可以尝试更复杂的流程、集成其他 Bright Data 产品,或调整 LLM 提示以处理不同任务。还有许多其他用例也同样适用!
就这样!你已经拥有一个 Azure AI Foundry 流程,能够检索网页搜索数据并将其用作 RAG 风格工作流中的上下文。
结论
在本文中,你学习了如何使用 Bright Data 的 SERP API 从 Google 获取最新新闻,并将其集成到 Azure AI 的 RAG 工作流中。
此处演示的 AI 工作流非常适合希望构建新闻助手、过滤内容的人群,让你只阅读与你关心主题相关的新闻。若要创建更高级的 AI 工作流,请探索Bright Data 的全套工具,用于检索、验证与转换实时网页数据。
立即注册免费的 Bright Data 账号,开始体验我们的 AI 就绪网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



