

本 Puppeteer Stealth 教程将涵盖:
- 什么是机器人检测,以及为什么它对 Puppeteer 来说是一个问题。
- 什么是 Puppeteer Extra。
- 如何使用 Puppeteer Extra Stealth Plugin 来避免封锁。
机器人检测:Puppeteer 最大的敌人
Puppeteer 是最广泛使用的用于浏览器自动化的 JavaScript 库之一。它如此受欢迎,是因为它由 Google 的 Chrome 团队支持。其高级 API 允许你通过 DevTools Protocol 控制无头或有头浏览器,使其成为网页抓取、自动化测试和机器人开发的绝佳工具。
然而,Puppeteer 很容易被机器人检测技术拦截。使用无头模式下的 Chrome/Chromium 时尤其如此。为什么?因为 Puppeteer 会自动设置默认属性和标头,使受控制的浏览器看起来像一个无头实例。例如,它会设置以下 Chrome 设置:navigator.webdriver: true。
反机器人解决方案了解这一点,并分析这些设置来判断当前用户是人类还是机器人。当它们发现一些可疑配置时,就会将用户标记为机器人。
例如,考虑这个无头模式机器人检测测试。如果你在浏览器中打开测试页面,你会看到:
现在,尝试使用原生 Puppeteer 访问该网站,并从中提取测试结果:
import puppeteer from "puppeteer"
(async () => {
// set up the browser and launch it
const browser = await puppeteer.launch()
// open a new blank page
const page = await browser.newPage()
// navigate the page to the target page
await page.goto("https://arh.antoinevastel.com/bots/areyouheadless")
// extract the message of the test result
const resultElement = await page.$("#res")
const message = await resultElement.evaluate(e => e.textContent)
// print the resulting message
console.log(`The result of the test is "%s"`, message);
// close the current browser session
await browser.close()
})()启动上述脚本,你会看到:
The result of the test is "You are Chrome headless"这意味着测试失败了,因为该页面能够检测到自动请求来自无头浏览器。
默认情况下,Puppeteer 是一个有限的工具。为了避免机器人检测,你必须手动调整它并覆盖默认配置。使用 Puppeteer Extra 避免所有这些!
Puppeteer Extra:Puppeteer 的可扩展版本
Puppeteer Extra 是一个围绕 Puppeteer 构建的轻量级包装器,通过插件支持扩展它。换句话说,<a href="https://www.npmjs.com/package/puppeteer-extra" target="_blank" rel="noreferrer noopener nofollow">puppeteer-extra</a> 是 puppeteer 的直接替代品。除了像流行的浏览器自动化库一样工作之外,它还提供 use() 方法来注册插件。
每个插件都会为 Puppeteer 添加额外功能。一些最有用的可用插件包括:
puppeteer-extra-plugin-stealth:使机器人检测技术更难检测到无头浏览器实例。puppeteer-extra-plugin-recaptcha:自动破解 reCAPTCHA 和 hCaptcha。puppeteer-extra-plugin-adblocker:移除广告和跟踪器,从而减少带宽和加载时间。puppeteer-extra-plugin-devtools:通过创建到 DevTools 的安全隧道,使从任何地方进行浏览器调试成为可能。puppeteer-extra-plugin-repl:通过交互式 REPL(Read-Eval-Print-Loop)界面让调试变得有趣。puppeteer-extra-plugin-block-resources:阻止动态页面资源,例如图像、媒体、CSS 和 JS 文件。puppeteer-extra-plugin-anonymize-ua:在页面导航时匿名化 User-Agent 标头。请在我们的用于网页抓取的 User-Agent 指南中了解为什么这很重要。puppeteer-extra-plugin-user-preferences:设置自定义 Chrome/Chromium 用户偏好。
现在让我们更深入地了解 Puppeteer Stealth 插件。
Puppeteer Extra Stealth Plugin 是什么以及它做什么
<a href="https://github.com/berstend/puppeteer-extra/tree/master/packages/puppeteer-extra-plugin-stealth#readme" target="_blank" rel="noreferrer noopener nofollow">puppeteer-extra-plugin-stealth</a> 是 Puppeteer Extra 的一个插件,包含一组用于避免机器人检测的配置。具体来说,Puppeteer Stealth 依赖内置规避模块,这些模块会覆盖 Puppeteer 的泄露信息以及将其暴露为机器人的属性。例如,它会从 User-Agent 标头中移除“HeadlessChrome”,并删除 Puppeteer 默认设置的 navigator.webdriver 属性。
Puppeteer Extra Stealth 插件的目标是让通过 Puppeteer 控制的无头 Chromium 实例通过 sannysoft.com 上的所有机器人检测测试。截至本文撰写时,它实现了这一目标。同时,正如官方文档中所述,仍然有方法可以检测无头 Chromium。这意味着不可能绕过所有机器人检测机制,但该项目的理念是让这个过程尽可能困难。
如何在抓取网页时使用 Puppeteer Stealth 避免机器人检测
是时候看看如何将 Puppeteer Stealth 集成到 puppeteer 爬虫脚本中以避免被封锁了。
请按照以下步骤操作!
第 1 步:安装 Puppeteer Extra 和 Stealth 插件
启动以下命令,将 Puppeteer Extra 和 Puppeteer Stealth 插件添加到你项目的依赖项中:
npm install puppeteer-extra puppeteer-extra-plugin-stealth太好了!你刚刚满足了将 Stealth 插件集成到 Puppeteer 自动化脚本中的先决条件。
第 2 步:设置 Puppeteer Extra 并注册 Stealth 插件
首先,用此指令替换 puppeteer 导入语句:
import puppeteer from "puppeteer-extra"换句话说,确保从 "puppeteer-extra``" 而不是 "puppeteer``" 导入 puppeteer 对象。
然后,从 puppeteer-extra-plugin-stealth 导入 StealthPlugin:
import StealthPlugin from "puppeteer-extra-plugin-stealth"如果你是 CommonJS 用户,则需要:
const puppeteer = require("puppeteer-extra")
const StealthPlugin = require("puppeteer-extra-plugin-stealth")接下来,通过 use() 方法将 Stealth 插件传递给 puppeteer 对象来注册它:
puppeteer.use(StealthPlugin())太棒了!你刚刚将该插件支持的默认规避能力添加到了 Puppeteer。
请注意,StealthPlugin() 构造函数接受一个可选对象,其中包含与要启用的规避项对应的字符串集合:
// enable only a few evasion techniques
puppeteer.use(StealthPlugin({
enabledEvasions: new Set(["chrome.app", "chrome.csi", "defaultArgs", "navigator.plugins"])
}))否则,使用下面的逻辑从 Stealth 插件中动态移除特定的规避策略:
const stealthPlugin = StealthPlugin()
puppeteer.use(stealthPlugin)
// ...
// remove the "user-agent-override" evasion method
pluginStealth.enabledEvasions.delete("user-agent-override")第 3 步:整合到一起
将 Puppeteer Extra 及其 Stealth 插件集成到你在文章开头看到的脚本中:
import puppeteer from "puppeteer-extra"
import StealthPlugin from "puppeteer-extra-plugin-stealth"
(async () => {
// configure the stealth plugin
puppeteer.use(StealthPlugin())
// set up the browser and launch it
const browser = await puppeteer.launch()
// open a new blank page
const page = await browser.newPage()
// navigate the page to the target page
await page.goto("https://arh.antoinevastel.com/bots/areyouheadless")
// extract the message of the test result
const resultElement = await page.$("#res")
const message = await resultElement.evaluate(e => e.textContent)
// print the resulting message
console.log(`The result of the test is "%s"`, message);
// close the current browser session
await browser.close()
})()运行此代码片段,它现在将打印:
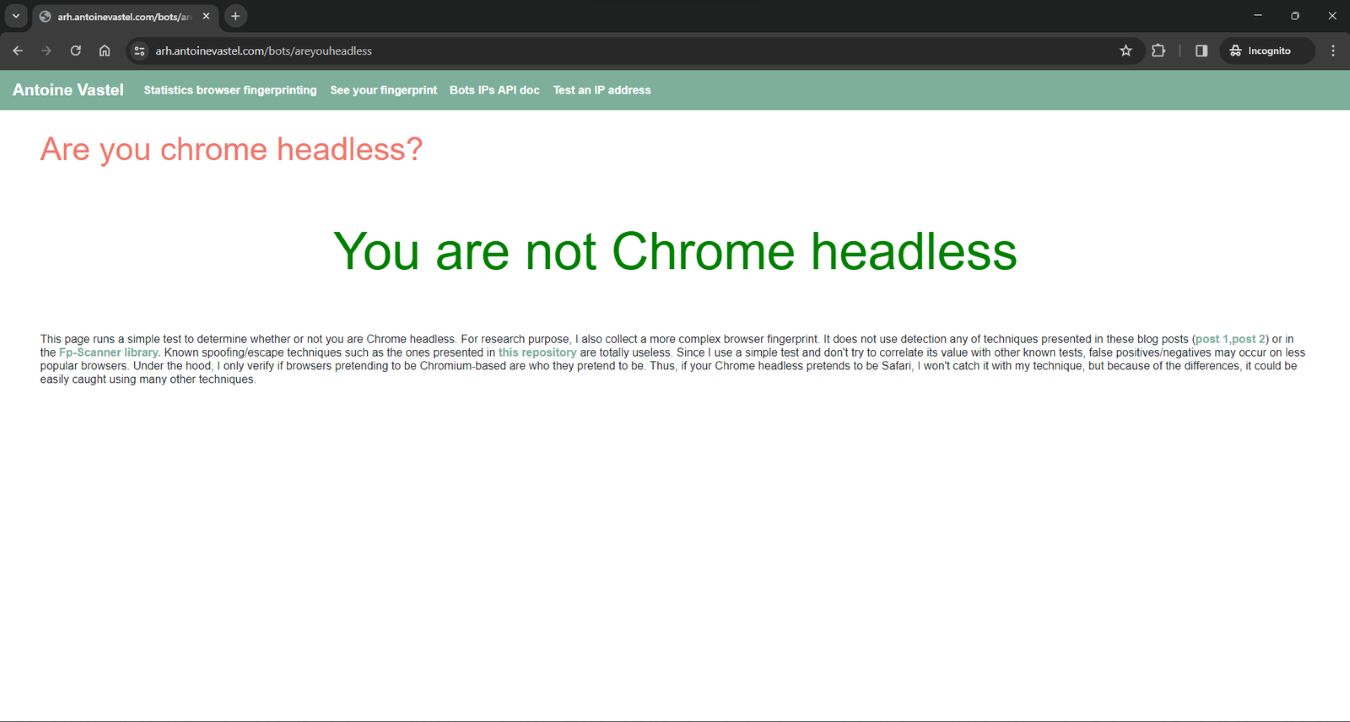
The result of the test is "You are not Chrome headless"Et voilà!所选的具有机器人检测能力的页面不再能够将你的 Puppeteer 自动化脚本标记为机器人。
恭喜!你现在是一名 Puppeteer Stealth 忍者,任何机器人检测技术都不会再吓到你了。
结论
在本文中,你了解了为什么机器人检测对 Puppeteer 来说是一个挑战,以及如何处理它。借助 Puppeteer Extra,你可以通过插件扩展 Puppeteer 的功能。特别是,Stealth 插件是规避机器人检测的强大盟友,在这里你学习了如何使用它。
无论你的 Puppeteer Extra 多么复杂,像 Cloudflare 这样的高级反机器人技术仍然能够发现并阻止你的脚本。你可以选择另一个浏览器自动化包,但检测的原因是浏览器,而不是库。解决方案是一个具有反机器人绕过功能的可扩展浏览器,并且可以与任何浏览器自动化库集成。这样的浏览器确实存在,它叫做抓取浏览器!
Bright Data 的抓取浏览器是一个高度可扩展的云浏览器,可与 Puppeteer、Playwright、Selenium 等一起使用。它会在每个请求时自动轮换出口 IP,并可以为你处理浏览器指纹识别、CAPTCHA 破解和自动重试。这得益于它所依赖的基于代理的解锁功能。
Bright Data 的代理被财富 500 强公司和超过 20,000 名客户使用。这个可靠的全球代理网络包括:



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




