

Crawl4AI 和 Firecrawl 是数据采集行业最热门的两款人工智能产品。在本指南中,我们将介绍这两种产品的基本用法和统计数据。
阅读完毕后,您将能够回答以下问题。
- 什么是 Crawl4AI?
- 什么是 Firecrawl?
- 他们各自的闪光点在哪里?
- 他们的不足在哪里?
- 为什么说 Bright Data 是这两者的最佳替代品?
了解这些新工具的比较有助于突出Bright Data 的全面和可扩展解决方案。无论您需要的是一般抓取功能还是全面的数据收集套件,Bright Data 都能提供成熟的技术。
概述和目的
在深入了解具体细节之前,让我们先仔细了解一下这两款产品各自的特点和销售对象。由于它们的用途不同,因此这并不是苹果与苹果之间的比较。这更像是 “工具箱与瑞士军刀 “的比较。
Crawl4AI

Crawl4AI是一个开源 Python 库,它能让人工智能驱动的网络抓取变得更简单、更易用。它主要面向专注于扩展提取管道的开发人员。它完全开源。代码可在其GitHub 页面上免费获取。Crawl4AI 更符合 Bright Data 的传统搜索工具。
Firecrawl
Firecrawl是人工智能驱动的网络抓取领域的企业领导者之一。他们提供语言无关的框架和大量集成选项。Firecrawl 吸引了大多数传统上不从事数据收集或开发的人的兴趣。有了 Firecrawl,那些不一定具备编码技能的人也可以使用网络搜索了。
独特功能
Crawl4AI
Crawl4AI之所以能脱颖而出,是因为它完全开源并使用许可授权。看看 Crawl4AI 哪些功能对开发人员极具吸引力。该工具提供可配置的选项,代码透明,值得信赖。
- 开放源代码:任何人都可以查看代码。社区通常能迅速发现并修复 Bug。透明的代码库意味着不会出现意外情况–如果你知道如何阅读代码的话。
- LLM驱动和无LLM提取:使用 Crawl4AI,您可以选择使用小型本地模型进行提取,也可以插入Deepseek 等外部模型。
- 自由许可:Crawl4AI 背后的许可方式非常灵活和自由。这吸引了业余爱好者和企业开发人员的兴趣。
- Python 库:Crawl4AI 并不是什么订阅服务。它是一个Python库。您可以将其插入到其他东西中,如果您愿意,还可以使用 Crawl4AI 作为后端,构建自己的专属搜索器。
Firecrawl
Firecrawl 是目前最流行的企业级网络抓取工具之一。他们提供了一个语言无关的框架–您可以使用 Python、JavaScript 或他们的图形用户界面网站来执行提取。他们为业余爱好者和企业客户量身定制了各种计划。
- 企业级:Firecrawl 是一款企业级产品。他们确实提供开源选项。不过,他们的主要产品线面向的是目前需要可扩展数据收集的用户。
- 语言无关:Firecrawl 通过网络应用程序提供图形用户界面支持。他们还为Python和JavaScript 提供 SDK 支持。此外,还有Go和Rust的社区驱动 SDK。有了 Firecrawl,你就不局限于 Python 了。甚至不局限于编程环境。
- 自然语言处理(NLP):Firecrawl 面向通过自然语言进行开发和数据收集。您告诉模型要做什么。然后,模型就会执行收集任务。
易用性
Crawl4AI
开始使用 Crawl4AI 相对简单。您可以通过pip安装它,并在 Python 环境中调用它。下面的代码段展示了如何安装和验证安装。
使用下面的命令安装 Crawl4AI。
pip install crawl4ai运行设置程序安装浏览器和工具。
crawl4ai-setup使用doctor命令验证您的安装并找出任何问题。
crawl4ai-doctor下面的代码非常简单。它直接来自此处的 Crawl4AI 文档。将其粘贴到任何 Python 文件中,然后使用python name-of-file.py 运行。实际上,Crawl4AI最好以shell命令的形式运行。直接从 VSCode 或其他集成开发环境中运行往往会导致asyncio问题。
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())Firecrawl
开始使用 Firecrawl 时,只需导航到他们的游乐场,然后输入您的目标 URL 即可。该界面对非开发人员非常友好。
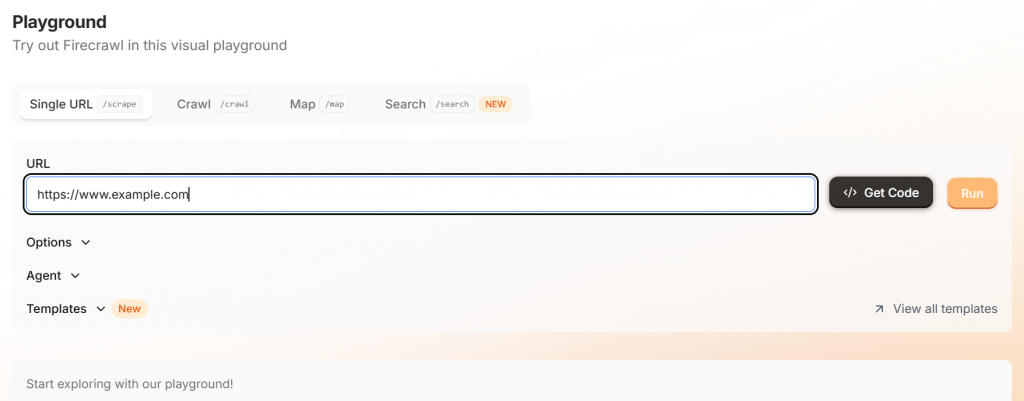
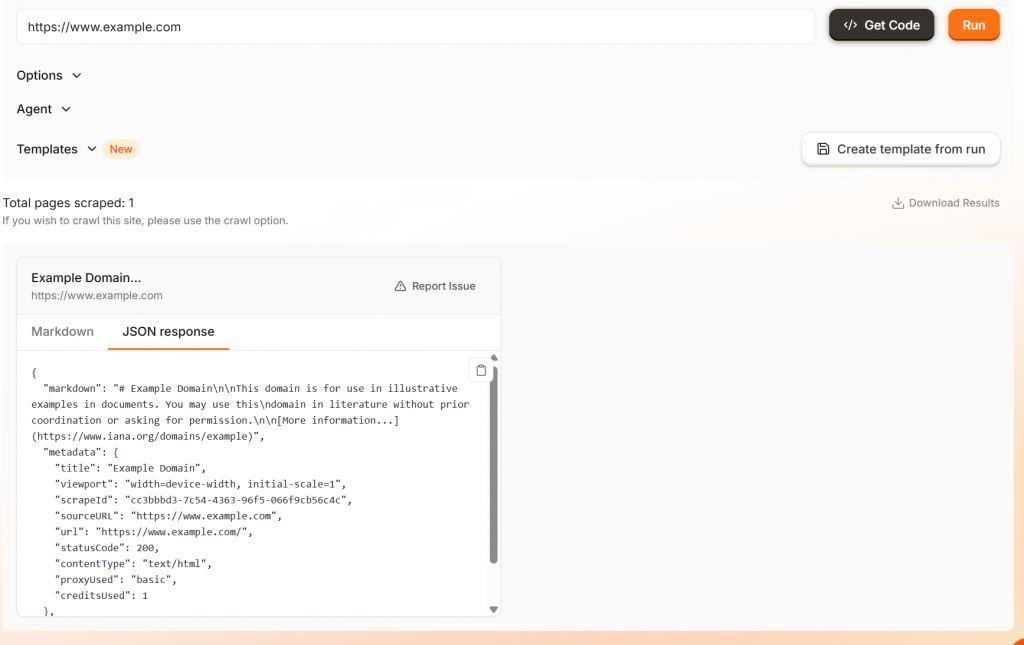
如果点击 “运行 “按钮,你将看到示例输出,可以选择标记符或 JSON。
性能和可扩展性
Crawl4AI
下面的代码段来自你之前看到的示例代码。总的来说,只用了不到两秒钟就完成了示例域的搜索。在不使用 LLM 的情况下,Crawl4AI 的速度非常快。就性能而言,它可以与使用Requests 和 BeautifulSoup进行的手动搜索相媲美。

不过,markdown 抓取和原始 HTML 已经非常干净了。Crawl4AI 确实列出了在不使用 LLM的情况下对JSON 提取的支持,但这种支持是有限的,而且漏洞百出。要提取完整的数据结构,需要在代码中添加 LLM 支持。这是Crawl4AI的隐藏成本,你需要托管或支付外部LLM才能完成真正的解析工作。
在下面的代码中,我们使用 OpenAI 模型来解析从Books 到 Scrape 的页面。如果你决定自己运行,请确保将 API 密钥替换为你自己的密钥。
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
#tell the llm what to scrape and set config
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="Extract all product objects with 'name' and 'price' from the content.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
#build the crawler config
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
#create a browser config if needed
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
#crawl a single page
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
#assume the extracted content is json
data = json.loads(result.extracted_content)
print("Extracted items:", data)
#show usage stats
llm_strategy.show_usage()
else:
print("Error:", result.error_message)
if __name__ == "__main__":
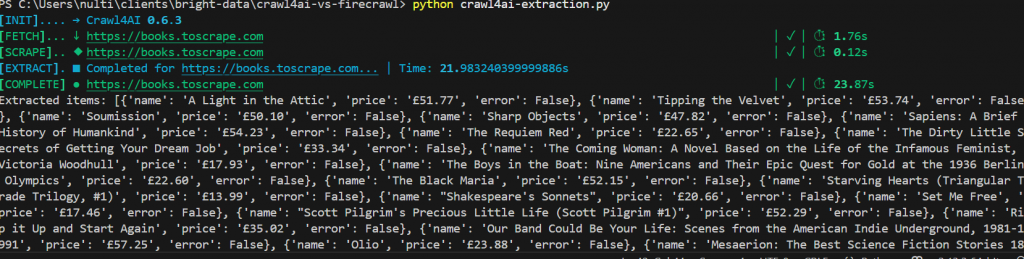
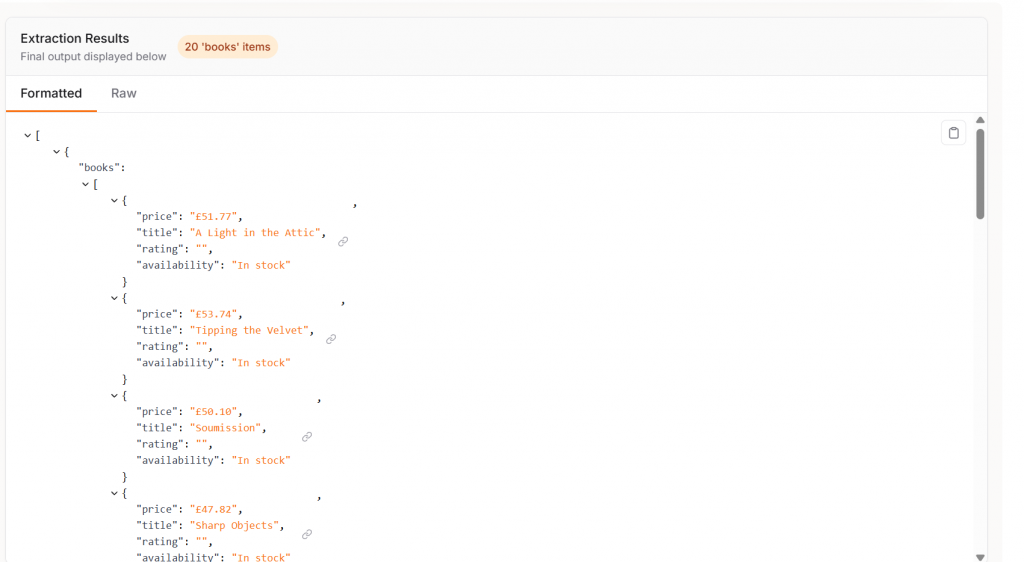
asyncio.run(main())这是我们的输出结果。总共用时不到 25 秒。你还可以看到每本书都以结构清晰的 JSON 对象形式列出了价格。
Firecrawl
Firecrawl 只需让你输入一个 URL,它就会抓取页面。使用默认版本的 Firecrawl 时,它会将页面输出为转储到 JSON 对象中的原始标记符。
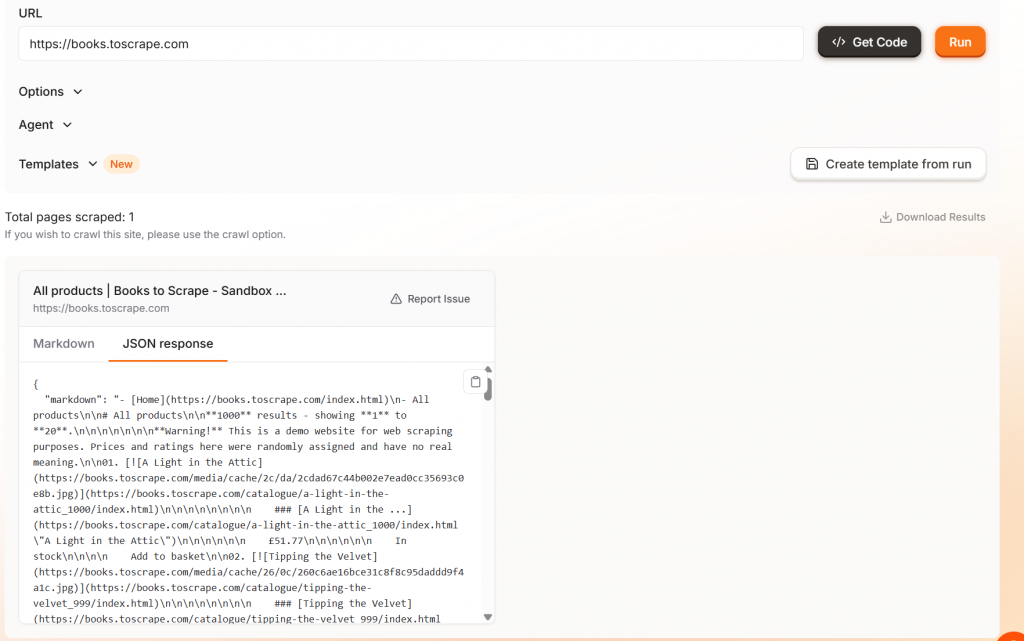
运行代码时,Firecrawl 有一个很酷的功能。当你的抓取程序运行时,你可以看到浏览器渲染页面的过程。
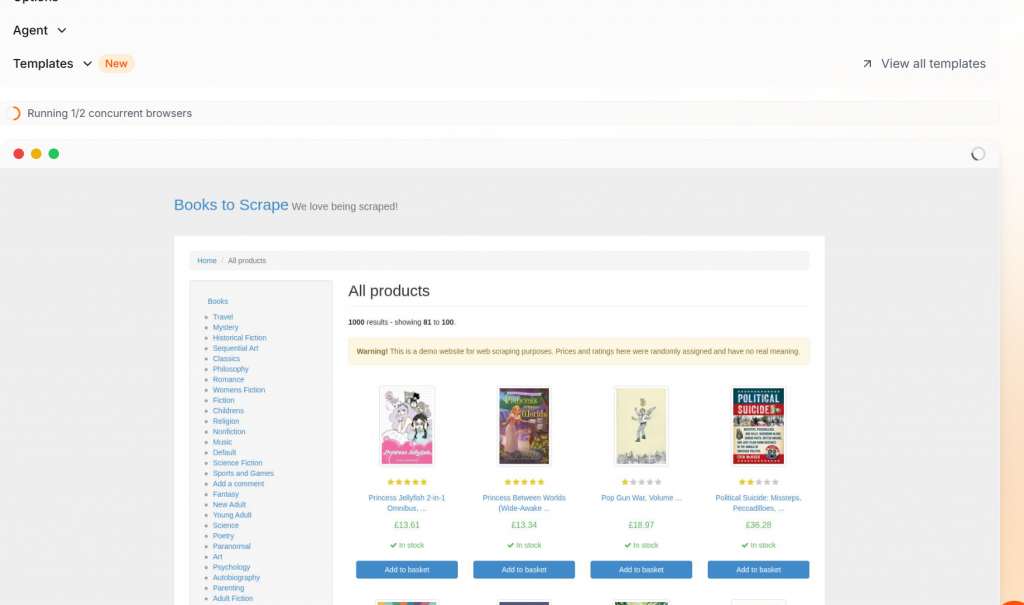
数据质量和准确性
Crawl4AI
与 GPT-4o 连接后,Crawl4AI 的准确率达到了 100%。为了检查物品数量,我们在代码中添加了以下一行。
print("Total products scraped:", len(data))如下所示,Crawl4AI 和 GPT-4o 找到了页面上的所有 20 个项目。

与 LLM 搭配使用时,Crawl4AI 将成为一款功能强大的工具,其准确性令人惊讶。
Firecrawl
Firecrawl 实际上提供两种不同的抓取产品。您可以使用普通的 Firecrawl 进行简单、肮脏的抓取。Firecrawl Extract允许您提取结构化的 JSON 对象。
常规 Firecrawl
这是使用普通 Firecrawl 时的 Books To Scrape 输出结果。如你所见,它很糟糕–真的很糟糕。Firecrawl 将页面转换为 markdown。然后,它将原始 markdown 分割成看似随机的 JSON 字段。这些数据需要使用代码手动进一步清理,或者传入 LLM。
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [Travel](catalogue/category/books/travel_2/index.html)n - [Mystery](catalogue/category/books/mystery_3/index.html)n - [Historical Fiction](catalogue/category/books/historical-fiction_4/index.html)n - [Sequential Art](catalogue/category/books/sequential-art_5/index.html)n - [Classics](catalogue/category/books/classics_6/index.html)n - [Philosophy](catalogue/category/books/philosophy_7/index.html)n - [Romance](catalogue/category/books/romance_8/index.html)n - [Womens Fiction](catalogue/category/books/womens-fiction_9/index.html)n - [Fiction](catalogue/category/books/fiction_10/index.html)n - [Childrens](catalogue/category/books/childrens_11/index.html)n - [Religion](catalogue/category/books/religion_12/index.html)n - [Nonfiction](catalogue/category/books/nonfiction_13/index.html)n - [Music](catalogue/category/books/music_14/index.html)n - [Default](catalogue/category/books/default_15/index.html)n - [Science Fiction](catalogue/category/books/science-fiction_16/index.html)n - [Sports and Games](catalogue/category/books/sports-and-games_17/index.html)n - [Add a comment](catalogue/category/books/add-a-comment_18/index.html)n - [Fantasy](catalogue/category/books/fantasy_19/index.html)n - [New Adult](catalogue/category/books/new-adult_20/index.html)n - [Young Adult](catalogue/category/books/young-adult_21/index.html)n - [Science](catalogue/category/books/science_22/index.html)n - [Poetry](catalogue/category/books/poetry_23/index.html)n - [Paranormal](catalogue/category/books/paranormal_24/index.html)n - [Art](catalogue/category/books/art_25/index.html)n - [Psychology](catalogue/category/books/psychology_26/index.html)n - [Autobiography](catalogue/category/books/autobiography_27/index.html)n - [Parenting](catalogue/category/books/parenting_28/index.html)n - [Adult Fiction](catalogue/category/books/adult-fiction_29/index.html)n - [Humor](catalogue/category/books/humor_30/index.html)n - [Horror](catalogue/category/books/horror_31/index.html)n - [History](catalogue/category/books/history_32/index.html)n - [Food and Drink](catalogue/category/books/food-and-drink_33/index.html)n - [Christian Fiction](catalogue/category/books/christian-fiction_34/index.html)n - [Business](catalogue/category/books/business_35/index.html)n - [Biography](catalogue/category/books/biography_36/index.html)n - [Thriller](catalogue/category/books/thriller_37/index.html)n - [Contemporary](catalogue/category/books/contemporary_38/index.html)n - [Spirituality](catalogue/category/books/spirituality_39/index.html)n - [Academic](catalogue/category/books/academic_40/index.html)n - [Self Help](catalogue/category/books/self-help_41/index.html)n - [Historical](catalogue/category/books/historical_42/index.html)n - [Christian](catalogue/category/books/christian_43/index.html)n - [Suspense](catalogue/category/books/suspense_44/index.html)n - [Short Stories](catalogue/category/books/short-stories_45/index.html)n - [Novels](catalogue/category/books/novels_46/index.html)n - [Health](catalogue/category/books/health_47/index.html)n - [Politics](catalogue/category/books/politics_48/index.html)n - [Cultural](catalogue/category/books/cultural_49/index.html)n - [Erotica](catalogue/category/books/erotica_50/index.html)n - [Crime](catalogue/category/books/crime_51/index.html)nn# All productsnn**1000** results - showing **1** to **20**.nnnnnnn**Warning!** This is a demo website for web scraping purposes. Prices and ratings here were randomly assigned and have no real meaning.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [A Light in the ...](catalogue/a-light-in-the-attic_1000/index.html "A Light in the Attic")nnnnnn £51.77nnnnnn In stocknnnn Add to basketnn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [Tipping the Velvet](catalogue/tipping-the-velvet_999/index.html "Tipping the Velvet")nnnnnn £53.74nnnnnn In stocknnnn Add to basketnn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn In stocknnnn Add to basketnn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn In stocknnnn Add to basketnn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [Sapiens: A Brief History ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "Sapiens: A Brief History of Humankind")nnnnnn £54.23nnnnnn In stocknnnn Add to basketnn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [The Requiem Red](catalogue/the-requiem-red_995/index.html "The Requiem Red")nnnnnn £22.65nnnnnn In stocknnnn Add to basketnn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [The Dirty Little Secrets ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "The Dirty Little Secrets of Getting Your Dream Job")nnnnnn £33.34nnnnnn In stocknnnn Add to basketnn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [The Coming Woman: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull")nnnnnn £17.93nnnnnn In stocknnnn Add to basketnn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [The Boys in the ...](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics")nnnnnn £22.60nnnnnn In stocknnnn Add to basketnn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [The Black Maria](catalogue/the-black-maria_991/index.html "The Black Maria")nnnnnn £52.15nnnnnn In stocknnnn Add to basketnn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [Starving Hearts (Triangular Trade ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "Starving Hearts (Triangular Trade Trilogy, \#1)")nnnnnn £13.99nnnnnn In stocknnnn Add to basketnn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [Shakespeare's Sonnets](catalogue/shakespeares-sonnets_989/index.html "Shakespeare's Sonnets")nnnnnn £20.66nnnnnn In stocknnnn Add to basketnn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn In stocknnnn Add to basketnn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [Scott Pilgrim's Precious Little ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "Scott Pilgrim's Precious Little Life (Scott Pilgrim \#1)")nnnnnn £52.29nnnnnn In stocknnnn Add to basketnn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn In stocknnnn Add to basketnn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [Our Band Could Be ...](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991")nnnnnn £57.25nnnnnn In stocknnnn Add to basketnn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [Olio](catalogue/olio_984/index.html "Olio")nnnnnn £23.88nnnnnn In stocknnnn Add to basketnn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [Mesaerion: The Best Science ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "Mesaerion: The Best Science Fiction Stories 1800-1849")nnnnnn £37.59nnnnnn In stocknnnn Add to basketnn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [Libertarianism for Beginners](catalogue/libertarianism-for-beginners_982/index.html "Libertarianism for Beginners")nnnnnn £51.33nnnnnn In stocknnnn Add to basketnn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [It's Only the Himalayas](catalogue/its-only-the-himalayas_981/index.html "It's Only the Himalayas")nnnnnn £45.17nnnnnn In stocknnnn Add to basketnnn-nPage 1 of 50nnn- [next](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "24th Jun 2016 09:29",
"viewport": "width=device-width",
"title": "n All products | Books to Scrape - Sandboxn",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}普通的 Firecrawl 可以获取页面,但并不能做得更多。你得到的是一个被切成小块的 Markdown 页面,它被压缩成一个大的 JSON 对象。你可以获取页面,但需要大量工作才能将网页转化为可用数据。
防火提取物
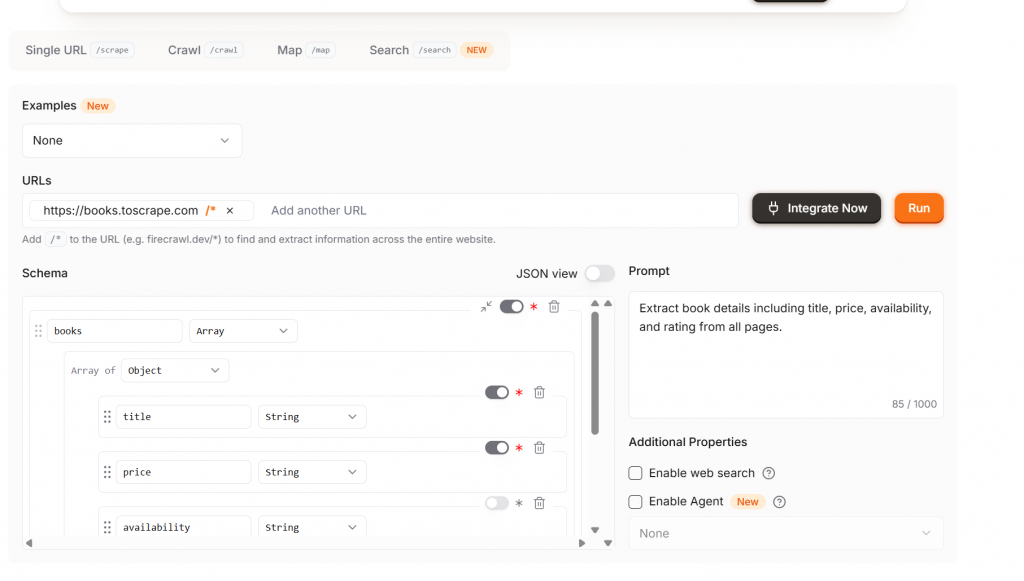
Extract 是下一级产品。有了 Extract,你就能通过 NLP 获得全面的抓取支持。告诉模型要获取哪些数据,它就会从页面中提取出来。如下图所示,我们甚至可以获得包含标题、价格和可用性字段的推荐模式。如果您对模式满意,请点击 “运行 “按钮。
请注意,您的网站附有/*– 这将告诉 Extract 自动抓取整个网站。为节省信用点数,请删除/*。
如果你想抓取单个页面,只需确保更改默认设置 Extract 即可。下图显示了我们对单页抓取的配置。/*操作符很容易被忽视,为了省钱,只在需要时使用。
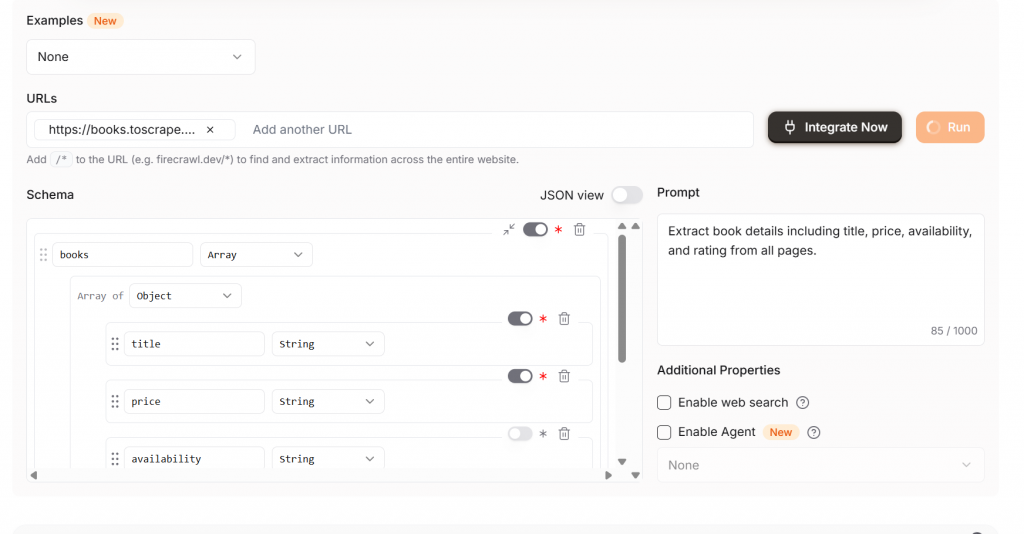
有了 Firecrawl Extract,我们的输出干净整洁,开箱即可使用。如您所见,我们得到的结构化 JSON 对象具有以下特征。
titlepriceratingavailability
安全与合规
Crawl4AI
Crawl4AI软件不提供合规性保证。他们确实提供了一些配置,可以帮助您遵守robots.txt文件等规定。
使用Crawl4AI时,您有责任遵守GDPR和CCPA等法律。Crawl4AI在法律和安全合规方面提供的帮助几乎为零。这意味着在大规模运行项目时,您可能需要聘请额外的帮手来确保您遵循正确的做法。
Firecrawl
根据他们的文档,Firecrawl会将你的信息交给谷歌处理。他们在条款中明确指出,他们遵守 GDPR 和 CCPA,但你必须自己遵守这些政策。任何违反这些行为都是您的责任,他们不对滥用其工具负责。
Firecrawl 确实比 Crawl4AI 提供了更多的责任保护。不过,这仍然不算多。他们的产品不带护栏。您需要遵守规则,如果您不遵守,您将对任何滥用行为负责。欲了解更多信息,请查看完整的Firecrawl服务条款。
定价和许可
Crawl4AI
任何人都可以免费使用Crawl4AI。我们在这里使用的 “免费 “一词比较宽泛。你可能已经注意到,任何真正的提取工作都需要 LLM 集成。你可以自己托管 LLM,也可以接入 OpenAI API 这样的服务。使用 Crawl4AI 时,如果自行托管,仍需支付外部服务或基础设施费用。这些费用都会增加。Crawl4AI不会将您的运营成本降至零。
Crawl4AI根据阿帕奇协议发布。您可以对Crawl4AI进行修改、分发,甚至进行商业销售。如果你有合规方面的帮助,Crawl4AI的许可许可使其成为对开发人员和数据团队极具吸引力的选择。
Firecrawl
常规 Firecrawl
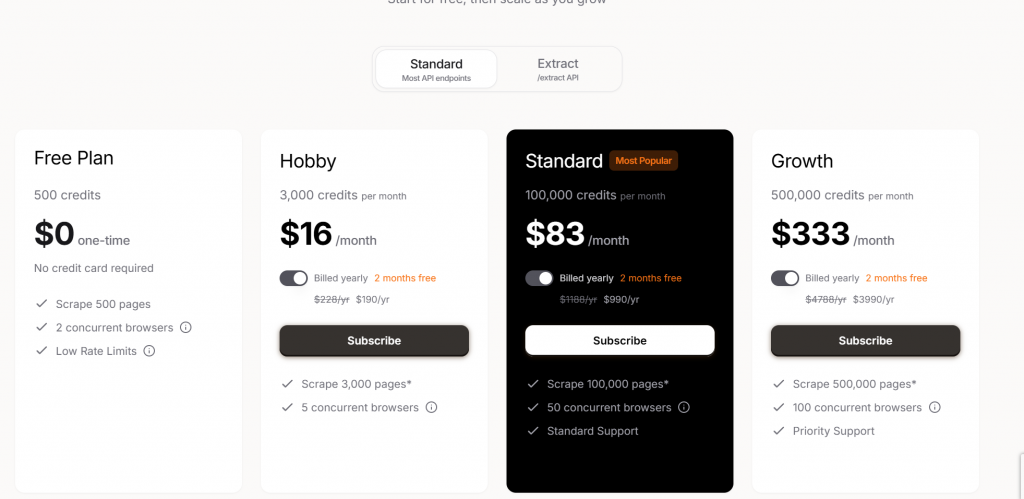
Vanilla Firecrawl 有多种价格等级。您可以尝试他们的免费计划。付费计划从每月 16 美元(3,000 页)到每月 333 美元(500,000 页)不等。
防火提取物
使用 Extract 时,付费计划从每年 18,000,000 个令牌的 89 美元/月到每年 192,000,000 个 API 令牌的 719 美元/月不等。

Firecrawl 许可
Firecrawl 的各种产品使用不同的许可证。你可以在这里查看所有不同的许可证。请注意,Firecrawl是企业级产品,你不能将其代码重新打包为自己的代码。即使是他们的开放源代码也是根据AGPL-3.0许可发布的。就像其他GNU软件协议一样,该协议在企业使用方面也有严格限制。
社区与支持
Crawl4AI
作为一个开放源码项目,Crawl4AI 利用其资源提供了有限的支持。没有服务台或服务水平协议。不过,您可以通过他们的Discord 频道联系开发人员。等待时间可能会有所不同。不要指望有专门的团队跟踪问题并及时解决您的需求。
Firecrawl
Firecrawl在仪表板上为您提供文档、常见问题页面和状态更新等支持选项。您可以通过 “联系支持 “按钮联系他们的支持团队,不过您的优先级会根据您的计划层级而有所不同。您还可以随时加入他们的Discord 频道,获得社区支持。
真实世界使用案例
Crawl4AI
Crawl4AI 为现代开发人员提供了各种实际应用案例。您只受限于您所能构建的内容。
- 后台支持:如果您决定创建自己的数据产品,您可以将 Crawl4AI 与您自己的 LLM 集成,并销售您的产品。
- 人工智能代理:正如我们在本文前面所做的那样,您可以将外部 LLM 直接插入 Crawl4AI,通过自定义数据结构输出(CSV、JSON XML)进行强大的提取操作。
- 业余项目和初创企业:Crawl4AI 等开源工具为实验、概念验证和流水线原型提供了快速访问途径。
Firecrawl
Firecrawl是专为那些需要在很少的内部开发的情况下进行大量抓取的团队而设计的。如果您想不费吹灰之力就能从想法变为实际产品,Firecrawl可以提供帮助。
- 生产级爬行:Firecrawl 专为大规模抓取而设计。其工具默认情况下甚至可以抓取完整的网站。
- 内容监控:对竞争对手进行例行抓取,监控其定价和内容。
- 干净整洁的数据:使用 Extract,您可以直接将数据传递给数据团队,几乎无需清理。
优点和缺点
| Crawl4AI | Firecrawl | |
|---|---|---|
| 优点 | – 完全开源、透明。 – 允许使用 Apache 许可证–可构建、修改、转售。 – 灵活:LLM 驱动或无 LLM 选项。 – 即插即用的 Python 库,可用于自定义管道。 |
– 对于非开发人员来说,它非常简单:图形用户界面、游乐场、NLP 提示。 – 支持多种语言(Python、JS、Go、Rust)。 – 可快速部署,用于一次性或常规搜索。 – 提供企业定价和支持层级。 |
| 缺点 | – 需要单独的 LLM 才能进行真正的结构化提取–增加了隐性成本。 – 有限的内置合规支持–用户必须管理 GDPR/CCPA。 – 异步怪癖–shell 运行效果最好,IDE 可能会破坏它。 |
– 没有 Extract 的基础输出通常比较混乱–原始标记需要更多的工作。 – 没有真正的合规准则–用户仍有责任。 – 闭源核心、AGPL 限制限制了自定义构建。 – 使用成本会随着规模的扩大或通配符抓取的增加而快速增长。 |
为什么要考虑 Bright Data
Crawl4AI 和 Firecrawl 都需要权衡利弊。Crawl4AI 有开发者需求和隐藏的 LLM 成本。而使用 Firecrawl,您将被锁定在使用层级和 Firecrawl 生态系统中。
Bright Data 提供的各种产品可以帮助填补上述两种工具的相同空白。
顶级亮数据工具
- 网页抓取工具 API:随时使用干净、随时可用的数据运行预构建的Scraper。
- 网络解锁器 API:绕过网站拦截,解决验证码问题,以 markdown 的形式抓取,甚至控制你的地理位置。
- 抓取浏览器 API:从编程环境中控制带有集成代理和验证码解决方案的远程浏览器。
- 数据集:访问来自 100 多个领域的庞大历史数据集库,可追溯到多年前。
通过我们的MCP 服务器,您可以访问所有最佳 Bright Data 产品的 LLM 友好软件包。将它插入您的 LLM,编写您的提示,然后让您的系统完成它的工作。
明亮的数据集成选项
我们甚至还提供与当今人工智能和开发行业中一些最佳工具的集成。我们一直在增加新的集成。请查看我们的文档,了解最新列表。
结论
在Bright Data,我们解决的不仅仅是一个抓取问题,而是为您的人工智能堆栈提供一个完整的生态系统。从采集实时数据到利用历史档案进行训练,我们确保您将时间花在洞察力上,而不是基础设施上。
今天就开始免费试用,看看它的与众不同之处。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。




