

在本指南中,你将看到:
- 入门 DuckDuckGo 抓取所需的一切。
- 抓取 DuckDuckGo 的最流行且有效的方法。
- 如何构建自定义 DuckDuckGo 抓取器。
- 如何使用 DDGS 库抓取 DuckDuckGo。
- 如何通过 Bright Data SERP API 获取搜索引擎结果数据。
- 如何通过 MCP 向 AI 代理提供 DuckDuckGo 搜索数据。
让我们开始吧!
DuckDuckGo 抓取快速上手
DuckDuckGo 是一个提供内置在线跟踪防护的搜索引擎。用户喜欢它的隐私政策,因为它不会跟踪搜索或浏览历史。也正因如此,它区别于主流搜索平台,并且多年来使用率稳步上升。
DuckDuckGo 搜索引擎提供两种版本:
- 动态版本:默认版本,需要 JavaScript,并包含诸如“Search Assist(搜索助手)”之类的功能,可类比 Google 的 AI Overviews。
- 静态版本:简化版本,即使不渲染 JavaScript 也能工作。
根据你选择的版本,所需的抓取方法也不同,概览如下表:
| 特性 | 动态 SERP 版本 | 静态 SERP 版本 |
|---|---|---|
| 是否需要 JavaScript | 是 | 否 |
| URL 格式 | https://duckduckgo.com/?q=<SEARCH_QUERY> |
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY> |
| 动态内容 | 是,包含 AI 摘要和交互元素 | 否 |
| 分页 | 复杂,基于“More Results(更多结果)”按钮 | 简单,传统“Next(下一页)”按钮并重新加载页面 |
| 抓取方式 | 浏览器自动化工具 | HTTP 客户端 + HTML 解析器 |
下面来看看这两种 DuckDuckGo SERP(搜索引擎结果页)版本的抓取影响!
DuckDuckGo:动态 SERP 版本
默认情况下,DuckDuckGo 会加载需要 JavaScript 渲染的动态网页,URL 如下:
https://duckduckgo.com/?q=<SEARCH_QUERY>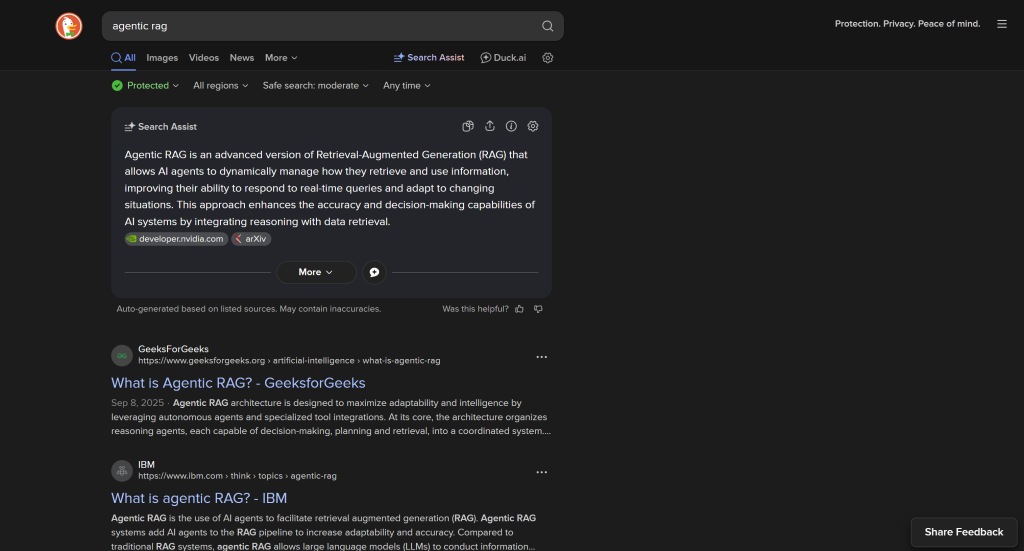
此版本包含复杂的页内用户交互,例如用于动态加载更多结果的“More Results”按钮:
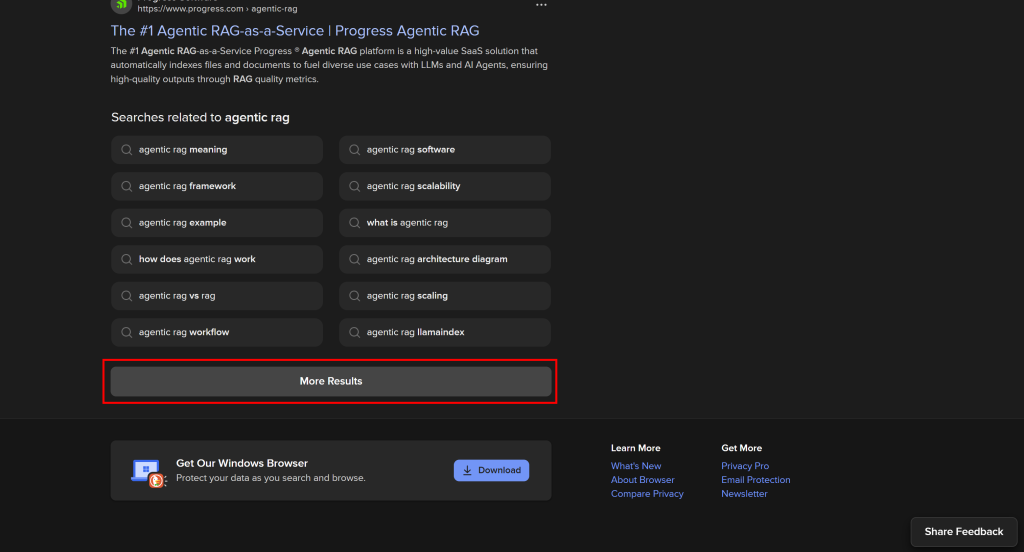
动态 DuckDuckGo SERP 功能更丰富、信息更全面,但抓取时需要浏览器自动化工具。原因是只有浏览器才能渲染依赖 JavaScript 的页面。
问题在于,控制浏览器会引入额外的复杂性和资源消耗。这也是为什么大多数抓取器会依赖站点的静态版本!
DuckDuckGo:静态 SERP 版本
对于不支持 JavaScript 的设备,DuckDuckGo 也提供其 SERP 的静态版本。这些页面遵循如下 URL 格式:
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY>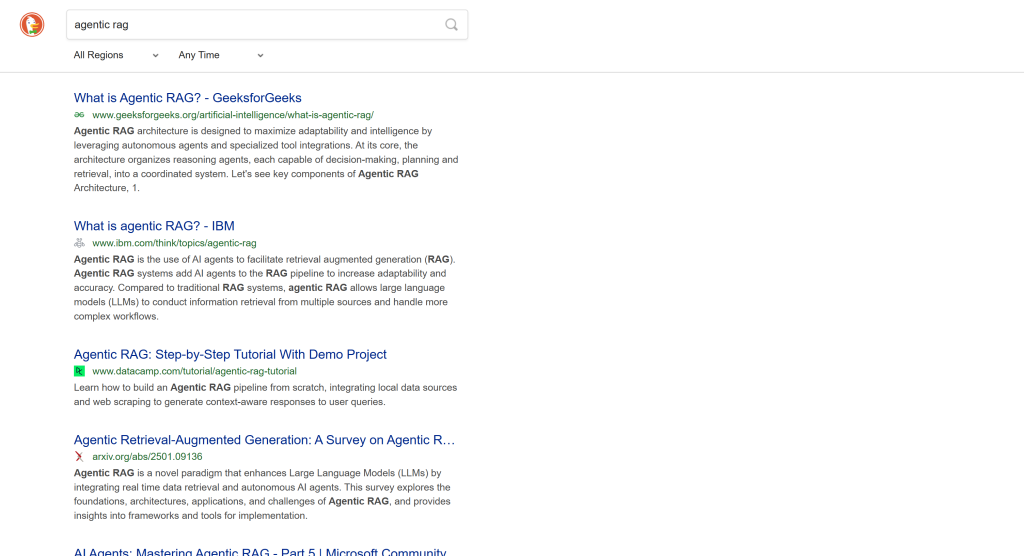
此版本不包含 AI 生成摘要等动态内容。此外,分页采用更传统的“Next(下一页)”按钮实现:
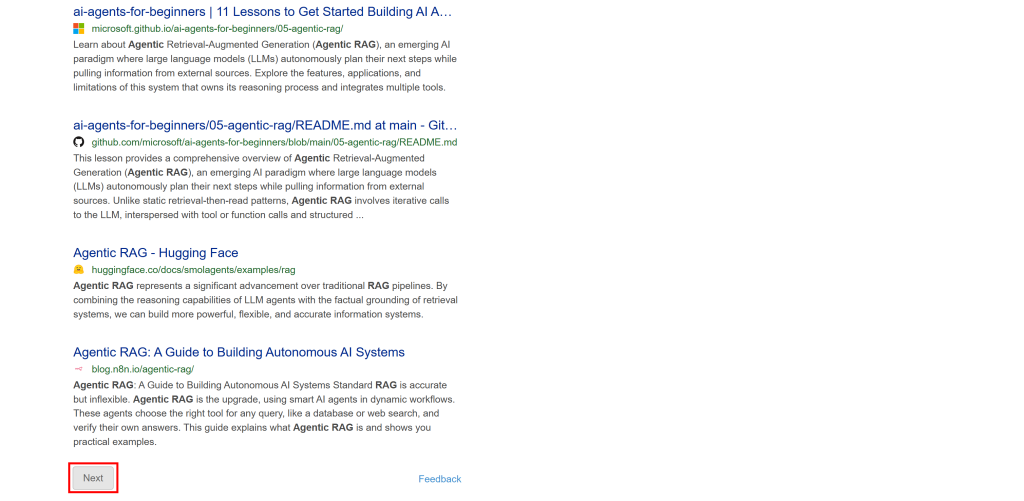
由于该 SERP 是静态的,你可以使用传统的 HTTP 客户端 + HTML 解析器方式进行抓取。该方法更快、更易实现且资源占用更少。
DuckDuckGo 抓取的可选方法
下面是本文将介绍的四种 DuckDuckGo 抓取方法:
| 方法 | 集成复杂度 | 所需条件 | 价格 | 被封禁风险 | 可扩展性 |
|---|---|---|---|---|---|
| 自建定制抓取器 | 中/高 | Python 编程技能 | 免费(为避免封禁可能需要高级代理) | 可能 | 有限 |
| 依赖 DuckDuckGo 抓取库 | 低 | Python 技能 / CLI 使用 | 免费(为避免封禁可能需要高级代理) | 可能 | 有限 |
| 使用 Bright Data 的 SERP API | 低 | 任意 HTTP 客户端 | 付费 | 无 | 无限 |
| 集成 Web MCP 服务器 | 低 | 支持 MCP 的 AI 代理框架/方案 | 提供免费层,之后付费 | 无 | 无限 |
随着教程的推进,你会了解每种方法的细节。
无论采用哪种方法,本文的目标搜索查询为“agentic rag”。也就是说,你将看到如何获取该查询的 DuckDuckGo 搜索结果。
我们假设你已经在本地安装了 Python,并对其有所了解。
方法一:自建定制抓取器
使用浏览器自动化工具,或将 HTTP 客户端与 HTML 解析器结合,从零构建一个 DuckDuckGo 网页抓取机器人。
👍 优点:
- 完全掌控抓取逻辑。
- 可定制以精确提取所需数据。
👎 缺点:
- 需要搭建与编码。
- 规模化抓取时可能遇到 IP 封禁。
方法二:使用 DuckDuckGo 抓取库
使用现成的 DuckDuckGo 抓取库,如 DDGS(Duck Distributed Global Search),无需编写代码即可获得所需功能。
👍 优点:
- 几乎无需配置。
- 通过 Python 代码或简单的 CLI 命令,自动处理搜索引擎抓取任务。
👎 缺点:
- 与自定义抓取器相比灵活性较低,对高级用例的控制有限。
- 仍可能遭遇 IP 封禁。
方法三:使用 Bright Data 的 SERP API
利用高品质的 Bright Data SERP API 端点,可从任意 HTTP 客户端调用。它支持多种搜索引擎(包括 DuckDuckGo),为你处理各种复杂性并提供可扩展的大规模抓取能力。
👍 优点:
- 无限可扩展性。
- 避免 IP 封禁和反机器人措施。
- 可与任何编程语言的 HTTP 客户端集成,也能配合 Postman 等可视化工具使用。
👎 缺点:
- 付费服务。
方法四:集成 Web MCP 服务器
通过 Bright Data Web MCP 免费访问 Bright Data SERP API,为你的 AI 代理提供 DuckDuckGo 抓取能力。
👍 优点:
- 轻松完成 AI 集成。
- 提供免费层。
- 便于在AI 代理与工作流中使用。
👎 缺点:
- 无法完全控制 LLM 行为。
方法一:使用 Python 构建自定义 DuckDuckGo 抓取器
按照以下步骤,学习如何用 Python 构建自定义的 DuckDuckGo 抓取脚本。
注意:为简化与加速数据解析,我们将使用 DuckDuckGo 的静态版本。如果你对收集AI 生成的“Search Assists”感兴趣,可阅读我们关于抓取 Google AI-overview 结果的指南,并据此轻松适配到 DuckDuckGo。
步骤一:设置项目
首先,打开终端并为 DuckDuckGo 抓取器项目创建一个新文件夹:
mkdir duckduckgo-scraperduckduckgo-scraper/ 文件夹将包含你的抓取项目。
接着,进入项目目录,并在其中创建一个Python 虚拟环境:
cd duckduckgo-scraper
python -m venv .venv现在,在你喜欢的 Python IDE 中打开项目文件夹。我们推荐安装 Python 扩展的 Visual Studio Code或PyCharm Community Edition。
在项目根目录创建一个名为 scraper.py 的新文件。项目结构应类似如下:
duckduckgo-scraper/
├── .venv/
└── agent.py在终端中激活虚拟环境。在 Linux 或 macOS 上,运行:
source venv/bin/activate在 Windows 上,执行:
venv/Scripts/activate激活虚拟环境后,安装项目依赖:
pip install requests beautifulsoup4需要的两个库为:
requests:流行的Python HTTP 客户端,用于获取 DuckDuckGo 的静态 SERP。beautifulsoup4:用于解析 HTML 的 Python 库,以便从 DuckDuckGo 结果页中提取数据。
太好了!你的 Python 开发环境已准备就绪,可以开始构建 DuckDuckGo 抓取脚本了。
步骤二:连接目标页面
在 scraper.py 中先导入 requests:
import requests接着,使用 requests.get() 方法,对 DuckDuckGo 静态版本发起模拟浏览器的 GET 请求:
# Base URL of the DuckDuckGo static version
base_url = "https://html.duckduckgo.com/html/"
# Example search query
search_query = "agentic rag"
# To simulate a browser request and avoid 403 errors
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Connect to the target SERP page
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)如果你对这种语法不熟悉,请参阅我们的Python HTTP 请求指南。
上述代码将向 https://html.duckduckgo.com/html/?q=agentic+rag(本教程的目标 SERP)发送 GET 请求,并带上如下 User-Agent 头:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36像上面那样设置一个真实的 User-Agent 对于避免 DuckDuckGo 返回 403 Forbidden 错误非常重要。了解更多关于User-Agent 在网页抓取中的重要性。
服务器会返回 DuckDuckGo 静态页面的 HTML。可通过以下方式获取:
html = response.text打印验证页面内容:
print(html)你应能看到类似如下的 HTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=3.0, user-scalable=1" />
<meta name="referrer" content="origin" />
<meta name="HandheldFriendly" content="true" />
<meta name="robots" content="noindex, nofollow" />
<title>agentic rag at DuckDuckGo</title>
<!-- Omitted for brevity... -->
</head>
<!-- Omitted for brevity... -->
<body>
<div>
<div class="serp__results">
<div id="links" class="results">
<div class="result results_links results_links_deep web-result">
<div class="links_main links_deep result__body">
<h2 class="result__title">
<a rel="nofollow" class="result__a"
href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9">
What is Agentic RAG? - GeeksforGeeks
</a>
</h2>
<!-- Omitted for brevity... -->
</div>
</div>
<!-- Other results ... -->
</div>
</div>
</div>
</body>
</html>很好!该 HTML 包含了你感兴趣的所有 SERP 链接。
步骤三:解析 HTML
在 scraper.py 中引入 BeautifulSoup:
from bs4 import BeautifulSoup然后,用它将之前获取的 HTML 字符串解析为可导航的树结构:
soup = BeautifulSoup(html, "html.parser")这使用 Python 内置的 "html.parser" 进行解析。你也可以配置其他解析器,如 lxml 或 html5lib,详见我们的BeautifulSoup 抓取指南。
干得好!现在你可以使用 BeautifulSoup 的 API 在页面上选择 HTML 元素并提取所需数据。
步骤四:准备抓取所有 SERP 结果
在深入抓取逻辑之前,先熟悉 DuckDuckGo SERP 的页面结构。在浏览器的隐身模式下打开此网页(确保是干净会话):
https://html.duckduckgo.com/html/?q=agentic+rag接着,右键任一 SERP 结果元素,选择“Inspect(检查)”打开浏览器开发者工具:
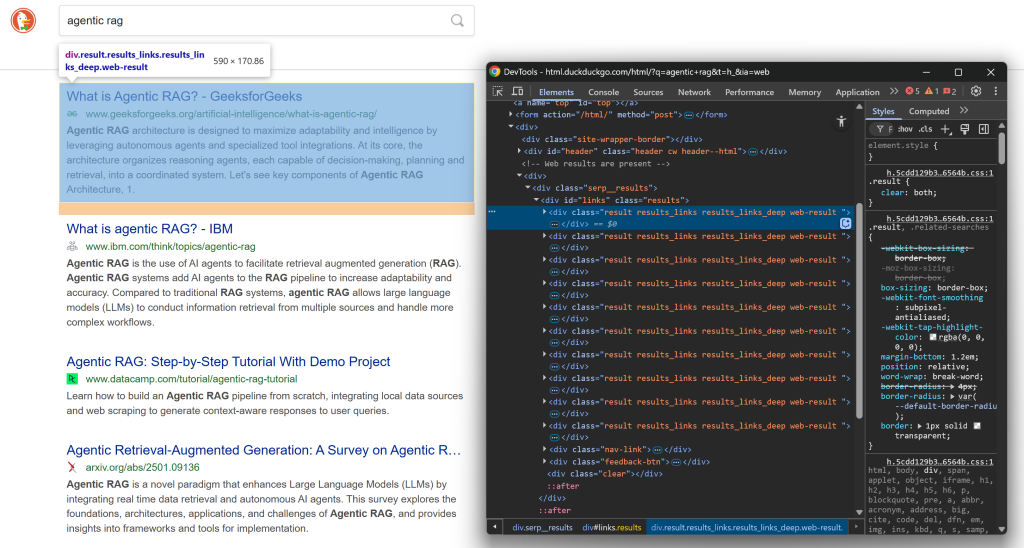
查看 HTML 结构。可以注意到,每个 SERP 元素都有 result 类,并包含在 ID 为 links 的 <div> 中。也就是说,你可以用以下 CSS 选择器选中所有搜索结果元素:
#links .result通过 BeautifulSoup 的 select() 方法对解析后的页面应用该选择器:
result_elements = soup.select("#links .result") 由于页面包含多个 SERP 元素,你需要一个列表来存储抓取的数据。像这样初始化:
serp_results = []最后,遍历每个选中的 HTML 元素。准备应用抓取逻辑来提取 DuckDuckGo 搜索结果,并填充 serp_results 列表:
for result_element in result_elements:
# Data parsing logic...很好!你距离实现 DuckDuckGo 抓取目标又近了一步。
步骤五:抓取结果数据
再次在结果页检查一个 SERP 元素的 HTML 结构:
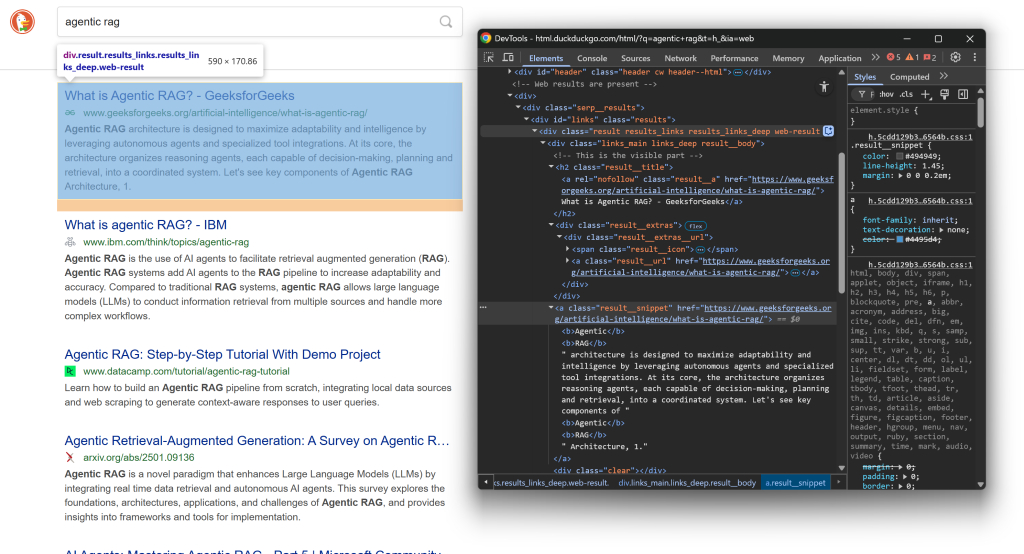
这次关注其内部的嵌套节点。可以看到,你可以从这些元素中抓取:
- 标题:来自
.result__a的文本 - 结果 URL:来自
.result__a的href属性 - 展示 URL:来自
.result__url的文本 - 结果摘要/描述:来自
.result__snippet的文本
使用 BeautifulSoup 的 select_one() 方法选中具体节点,然后用 .get_text() 提取文本,或用 [<attribute_name>] 访问 HTML 属性。
实现抓取逻辑如下:
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)注意:strip=True 可移除提取文本前后的空白字符。
如果你在疑惑为何需要把 "https:" 拼接到 title_element["href"] 前面,那是因为服务器返回的 HTML 与浏览器渲染后的略有不同。你的抓取器实际解析的原始 HTML 中,URL 的格式类似:
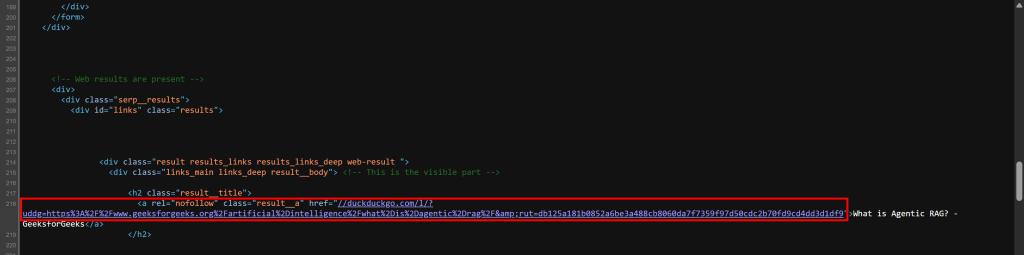
//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9如你所见,URL 以 // 开头,而不是包含协议(https://)。通过在前面加上 "https:",可以确保该 URL 更易于在浏览器外部使用(浏览器也支持这种格式)。
你可以自己验证一下。右键页面并选择“查看页面源代码(View page source)”。这将展示服务器返回的原始 HTML 文档(未应用浏览器渲染)。你会看到 SERP 链接是这种格式:
现在,使用已抓取的数据字段,为每条搜索结果创建一个字典,并将其追加到 serp_results 列表中:
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)完美!你的 DuckDuckGo 网页抓取逻辑已完成。接下来只需导出抓取数据。
步骤六:将抓取数据导出为 CSV
此时,DuckDuckGo 搜索结果已经存储在一个 Python 列表中。为便于其他团队或工具使用,使用 Python 内置的 csv 库将其导出为 CSV 文件:
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Write the header
writer.writeheader()
# Write all data rows
writer.writerows(serp_results)别忘了导入 csv:
import csv这样,你的 DuckDuckGo 抓取器就会生成一个名为 duckduckgo_results.csv 的输出文件,包含所有抓取结果的 CSV 格式数据。任务完成!
步骤七:整合到一起
scraper.py 中的最终代码如下:
import requests
from bs4 import BeautifulSoup
import csv
# Base URL of the DuckDuckGo static version
base_url = "https://html.duckduckgo.com/html/"
# Example search query
search_query = "agentic rag"
# To simulate a browser request and avoid 403 errors
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Connect to the target SERP page
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)
# Retrieve the HTML content from the response
html = response.text
# Parse the HTML
soup = BeautifulSoup(html, "html.parser")
# Find all result containers
result_elements = soup.select("#links .result")
# Where to store the scraped data
serp_results = []
# Iterate over each SERP result and scrape data from it
for result_element in result_elements:
# Data parsing logic
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)
# Populate a new SERP result object and append it to the list
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)
# Export the scraped data to CSV
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Write the header
writer.writeheader()
# Write all data rows
writer.writerows(serp_results)哇!不到 65 行代码,你就构建了一个 DuckDuckGo 数据抓取脚本。
使用以下命令运行:
python scraper.py输出将是一个 duckduckgo_results.csv 文件,会出现在你的项目文件夹中。打开它,你将看到类似如下的抓取数据:

搞定!你已将 DuckDuckGo 网页上的非结构化搜索结果转化为结构化的 CSV 文件。
[加分项] 集成轮换代理以避免封禁
上述抓取器适合小规模运行,但难以大规模扩展。因为当 DuckDuckGo 发现同一 IP 发出过多流量时,就会开始封禁请求。此时服务器会返回 403 Forbidden 错误页面,内容类似:
If this persists, please <a href="mailto:[email protected]?subject=Error getting results">email us</a>.<br />
Our support email address includes an anonymized error code that helps us understand the context of your search.这意味着服务器已识别你的请求为自动化请求并将其阻止,通常是由于速率限制问题。为避免封禁,你需要轮换 IP。
解决方案是通过轮换代理发送请求。若想了解更多原理,请查看我们的如何轮换 IP 地址指南。
Bright Data 提供由超过 1.5 亿 IP 支持的轮换代理。看看如何将其集成到你的 DuckDuckGo 抓取器中以避免封禁!
按照官方代理设置指南操作,最终你将得到一个类似如下的代理连接字符串:
<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335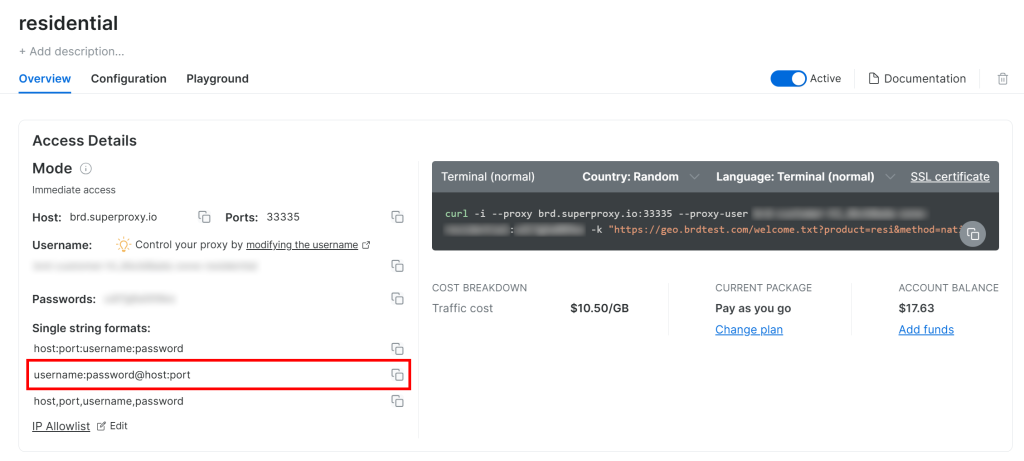
在 Requests 中设置代理,如下:
proxy_url = "http://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
# params and headers definition...
response = requests.get(
base_url,
params=params,
headers=headers,
proxies=proxies, # route the request through the rotating proxy
verify=False,
)注意:verify=False 会禁用 SSL 证书校验。这可以避免与代理证书验证相关的错误,但并不安全。要用于生产环境,请参阅我们关于 SSL 证书验证的文档。
现在,你对 DuckDuckGo 的 GET 请求将通过Bright Data 的 1.5 亿+ 住宅代理网络进行路由,确保每次使用新的 IP,帮助你避免与 IP 相关的封禁。
方法二:使用 DDGS 等 DuckDuckGo 抓取库
本节将学习如何使用 DDGS 库。这个开源项目在 GitHub 上有 1.8k+ Star,先前名为 duckduckgo-search,因为当时主要聚焦 DuckDuckGo。近期由于开始支持其他搜索引擎,已更名为 DDGS(Dux Distributed Global Search)。
这里我们将演示如何在命令行中使用它抓取 DuckDuckGo 搜索结果!
步骤一:安装 DDGS
通过 ddgs PyPI 包在全局或虚拟环境中安装 DDGS:
pip install -U ddgs安装完成后,你可以使用 ddgs 命令行工具。通过以下命令验证安装:
ddgs --help输出应类似如下:
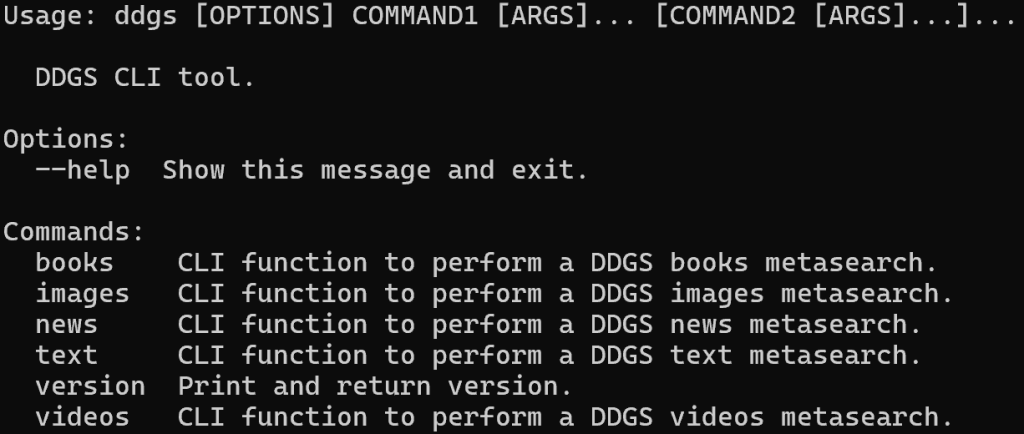
可以看到,该库支持多个用于抓取不同数据类型的命令(如文本、图片、新闻等)。在这里,你将使用针对 SERP 搜索结果的 text 命令。
注意:你也可以在 Python 代码中通过 DDGS API 调用这些命令,详见文档。
步骤二:通过 CLI 使用 DDGS 抓取 DuckDuckGo
首先,运行以下命令熟悉 text 命令:
ddgs text --help这会显示其支持的所有标志与选项:
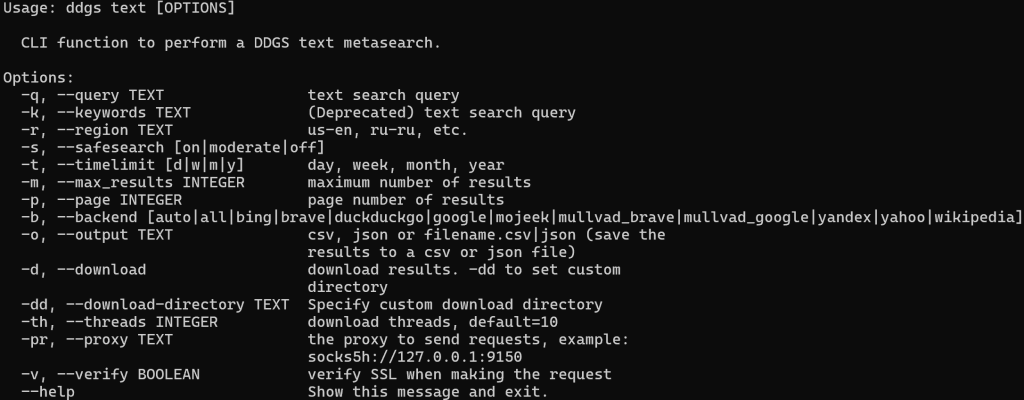
要抓取 "agentic rag" 的 DuckDuckGo 搜索结果并导出为 CSV 文件,运行:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv输出将是一个 duckduckgo_results.csv 文件。打开它,你应能看到类似如下的内容:

太棒了!只用一条 CLI 命令,就获得了与自定义 Python 抓取器相同的搜索结果。
[加分项] 集成轮换代理
如你所见,DDGS 是一个非常强大的SERP 搜索与抓取工具。但它并非万能。在大规模抓取项目中,它仍会面临前述的 IP 封禁与阻断。
要避免这些问题,和之前一样,你需要轮换代理。DDGS 原生支持通过 -pr(或 --proxy)标志集成代理。
获取你的Bright Data 轮换代理 URL,并在 ddgs CLI 命令中这样设置:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv -pr <BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335完成!该库底层发起的网络请求现在会通过 Bright Data 轮换代理网络进行路由,让你不必担心与 IP 相关的封禁问题。
方法三:使用 Bright Data 的 SERP API
本节将学习如何使用 Bright Data 的一体化 SERP API,以编程方式从 DuckDuckGo 的动态版本获取搜索结果。按以下说明开始!
注意:为简化与快速上手,我们假设你已有安装了 requests 库的 Python 项目。
步骤一:设置 Bright Data SERP API Zone
首先,创建一个 Bright Data 账号或登录已有账号。下面将指导你为 DuckDuckGo 抓取配置 SERP API 产品。
若想更快完成设置,也可参考官方 SERP API “快速开始”指南。否则,请继续以下步骤。
登录后,进入你的 Bright Data 账户,点击“Proxies & Scraping”以进入如下页面:
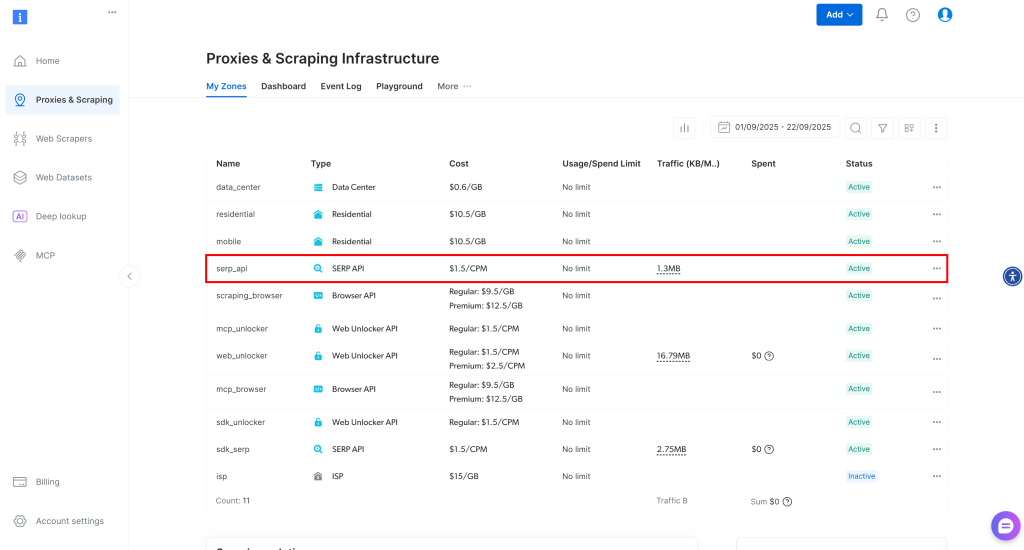
查看“My Zones”表格,其中列出了已配置的 Bright Data 产品。如果已有一个激活的 SERP API Zone,就可以直接使用。只需复制该 Zone 名称(例如 serp_api),后面会用到。
如果尚未创建,向下滚动至“Scraping Solutions”部分,在“SERP API”卡片上点击“Create Zone”按钮:
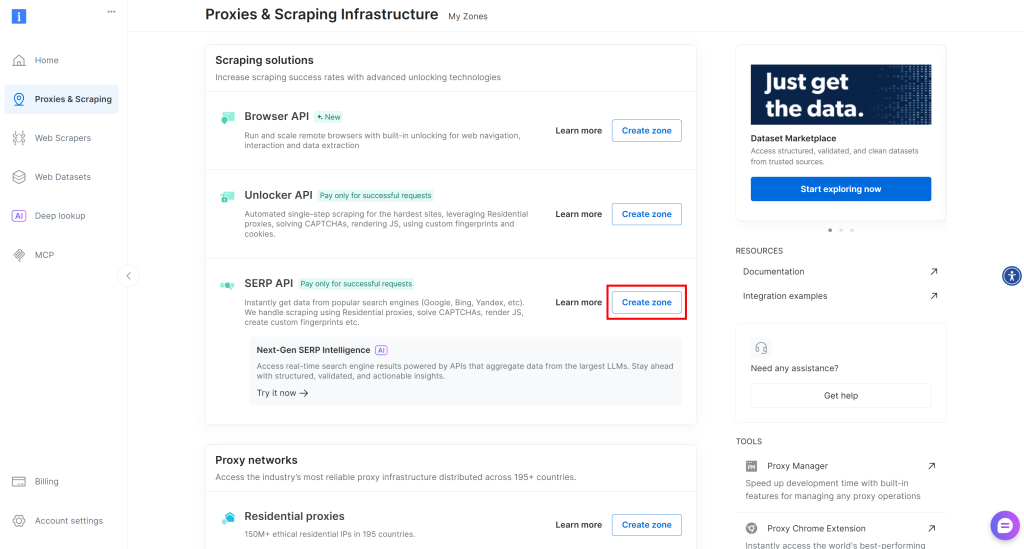
为你的 Zone 命名(例如 serp-api),然后点击“Add”:
接着,进入该 Zone 的产品页面,通过切换开关确保其为“Active(启用)”状态:
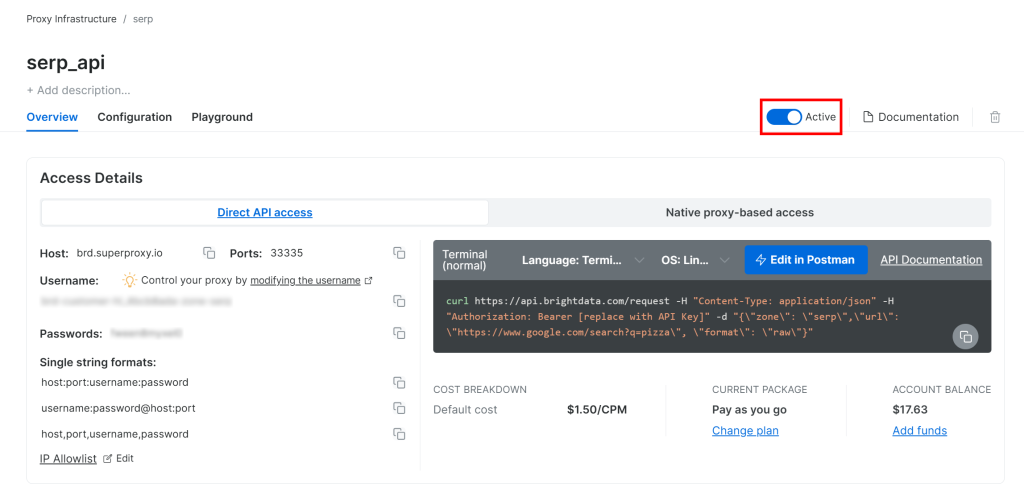
太好了!你已成功配置 Bright Data 的 SERP API。
步骤二:获取 Bright Data API Key
推荐的 SERP API 鉴权方式是使用你的 Bright Data API Key。如果尚未生成,请按照官方指南生成。
向 SERP API 发起 POST 请求时,将 API Key 置于 Authorization 头部中以完成鉴权:
"Authorization: Bearer <BRIGHT_DATA_API_KEY>"很好!现在你已经具备在 Python 脚本(或任何其他 HTTP 客户端)中调用 Bright Data SERP API 的所有基础。
步骤三:调用 SERP API
将上述内容整合,在“agentic rag”的 DuckDuckGo 搜索页上调用 Bright Data SERP API,Python 代码示例如下:
# pip install requests
import requests
# Bright Data credentials (TODO: replace with your values)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"
# Your DuckDuckGo target search page
duckduckgo_page_url = "https://duckduckgo.com/?q=agentic+rag"
# Perform a request to Bright Data's SERP API
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zone": bright_data_serp_api_zone_name,
"url": duckduckgo_page_url,
"format": "raw"
}
)
# Access the rendered HTML from the dynamic version of DuckDuckGo
html = response.text
# Parsing logic...更完整的示例请查看 GitHub 上的“Bright Data SERP API Python Project”。
注意,这一次目标 URL 可以是动态版本(如 https://duckduckgo.com/?q=agentic+rag)。SERP API 会处理 JavaScript 渲染、与 Bright Data 代理网络集成进行 IP 轮换,并管理其他反爬措施(如浏览器指纹和验证码)。因此,抓取动态 SERP 不会有问题。
html 变量将包含 DuckDuckGo 页面完整渲染后的 HTML。通过打印进行验证:
print(html)你会得到类似如下内容:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agentic RAG at DuckDuckGo</title>
<!-- Omitted for brevity ... -->
</head>
<body>
<div class="site-wrapper" style="min-height: 825px;">
<div id="content">
<div id="duckassist-answer" class="answer-container">
<div class="answer-content-block">
<p class="answer-text">
<span class="highlight">Agentic RAG</span> is an advanced version of Retrieval-Augmented Generation (RAG) that allows AI agents to dynamically manage how they retrieve and use information, improving their ability to respond to real-time queries and adapt to changing situations. This approach enhances the accuracy and decision-making capabilities of AI systems by integrating reasoning with data retrieval.
</p>
<!-- Omitted for brevity ... -->
</div>
<!-- Omitted for brevity ... -->
</div>
<ul class="results-list">
<li class="result-item">
<article class="result-card">
<div <!-- Omitted for brevity ... -->
<div class="result-body">
<h2 class="result-title">
<a href="https://www.geeksforgeeks.org/artificial-intelligence/what-is-agentic-rag/" rel="noopener" target="_blank" class="result-link">
<span class="title-text">What is Agentic RAG? - GeeksforGeeks</span>
</a>
</h2>
<div class="result-snippet-container">
<div class="result-snippet">
<div>
<span class="snippet-text">
<span class="snippet-date">Sep 8, 2026</span>
<span>
<b>Agentic RAG</b> architecture is designed to maximize adaptability and intelligence by leveraging autonomous agents and specialized tool integrations. At its core, the architecture organizes reasoning agents, each capable of decision-making, planning, and retrieval, into a coordinated system. Let's see key components of <b>Agentic RAG</b> Architecture, 1.
</span>
</span>
</div>
</div>
</div>
</div>
</article>
</li>
<!-- Other search results ... -->
</ul>
<!-- Omitted for brevity ... -->
</div>
<!-- Omitted for brevity ... -->
</div>
</body>
</html>注意:由于你在处理页面的动态版本,输出 HTML 也可能包含“Search Assist”AI 生成摘要。
现在,按方法一所示解析该 HTML,从而访问所需的 DuckDuckGo 数据!
方法四:通过 MCP 将 DuckDuckGo 抓取工具集成进 AI 代理
请记住,SERP API 产品也通过 Bright Data Web MCP 中提供的 search_engine 工具进行暴露。
该开源 MCP 服务器为 AI 提供访问 Bright Data 网页数据检索方案的能力,包括 DuckDuckGo 抓取。具体来说,search_engine 工具包含在 Web MCP 免费层中,因此你可以无成本地将其集成到 AI 代理或工作流中。
要将 Web MCP 集成到你的 AI 方案,一般需要在本地安装 Node.js,并准备如下配置文件:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}例如,该配置适用于 Claude Code。在文档中了解更多集成方式。
得益于该集成,你将能够以自然语言检索 SERP 数据,并将其用于你的AI 驱动的工作流或代理。
结论
在本教程中,你看到了四种抓取 DuckDuckGo 的推荐方法:
- 自定义抓取器
- 使用 DDGS
- 使用 DuckDuckGo Search API
- 借助 Web MCP
如本文所示,想要在大规模抓取 DuckDuckGo 的同时避免封禁,可靠的方法是使用具备强大反爬绕过技术与大型代理网络的结构化抓取方案,例如 Bright Data。
立即创建免费的 Bright Data 账号,开始探索我们的抓取解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




