
在本指南中,您将了解到
- 为什么说 Dify 是构建人工智能代理的强大平台?
- 为什么人工智能代理离不开网络搜索能力?
- 如何在 Dify 中创建一个可以搜索网络的人工智能代理。
让我们深入了解一下!
利用 Dify 实现代理工作流自动化开发
Dify是一个创新的低代码/无代码平台,旨在简化 LLM 应用程序的创建。您可以在云端或开源版本中使用它,它还支持代理工作流。
它提供了一个直观的可视化编辑器,使您能够利用拖放功能轻松构建和管理复杂的人工智能逻辑。Dify 可与从专有到开源的各种 LLM 配合使用,让您可以灵活地选择最适合自己项目的模型。
作为一种 BaaS(Backend-as-a-Service,后端即服务),它可以为您处理人工智能基础设施。此外,它还支持扩展和插件,以进一步提高其功能。这就为您通过第三方集成在人工智能应用程序中扩展功能打开了大门。
为什么人工智能代理应该能够搜索网络?
人工智能代理搜索网络的能力是实现智能和最新响应的基本要求。像 ChatGPT 和 Gemini 这样的 LLM 早期迭代产品往往在提供最新信息或利基信息方面举步维艰。这是因为它们受限于训练数据的静态性质。
正是在他们具备了网络搜索能力之后,他们的准确性才有了重要的飞跃。

这种功能使 LLM 能够按需获取信息,最终目的是扩大知识库,减少幻觉。
同时,法律硕士的内置网络搜索功能通常是付费模式独有的。此外,仅仅 “搜索网络 “是不够的。原因在于,互联网数据的庞大数量和未经核实的性质仍可能导致不准确或不相关的结果。
真正的优势在于可以直接从 Google、Bing、DuckDuckGo 等可靠的搜索引擎获取可信且经过验证的 SERP(搜索引擎结果页面)数据。这些数据由包含严格质量检查的复杂排名算法形成。
因此,SERP 数据为人工智能代理综合信息和生成有理有据的回复提供了更可靠的基础。这就是为什么人工智能的一个常见用例是利用 SERP 数据构建基于 RAG 的聊天机器人。
要为 Dify 人工智能代理工作流程提供 SERP 数据,可以使用Bright Data Dify 插件。在它提供的工具中,有一个叫做 “搜索引擎“。它通过连接Bright Data SERP API,提供来自 Google、Bing、Yandex 和其他主要搜索引擎的实时搜索结果。
有了这种集成,您的无代码人工智能代理就可以利用浩瀚的网络,同时受益于值得信赖的搜索引擎的可信度。
在 Dify 中构建可搜索网络的人工智能代理:逐步教程
在本指导章节中,您将建立一个人工智能代理工作流程,它可以
- 接受关键字作为输入。
- 使用 Bright Data 插件中的 “搜索引擎 “工具,使用该关键词搜索 Google。
- 用 LLM 处理搜索结果。
整个过程完全可视化,无需编码。您将通过一个简单的拖放界面连接每个节点,让您的人工智能代理栩栩如生。
现在,让我们在 Dify 中构建无代码、由 Bright Data 驱动的网络搜索人工智能工作流程!
先决条件
要学习本教程,在 Dify 中构建一个网络搜索人工智能代理,您需要具备以下条件:
- 一个Dify 账户(免费计划即可)。
- 一个Bright Data API 密钥。
如果您还没有这些设备,请使用上面的链接并按照设置说明进行操作。
注:在生产中使用时,您还需要一个 LLM 提供商(如 OpenAI、Anthropic 或 Gemini)提供的 API 密钥。
步骤 #1:在 Dify 中设置 LLM 集成
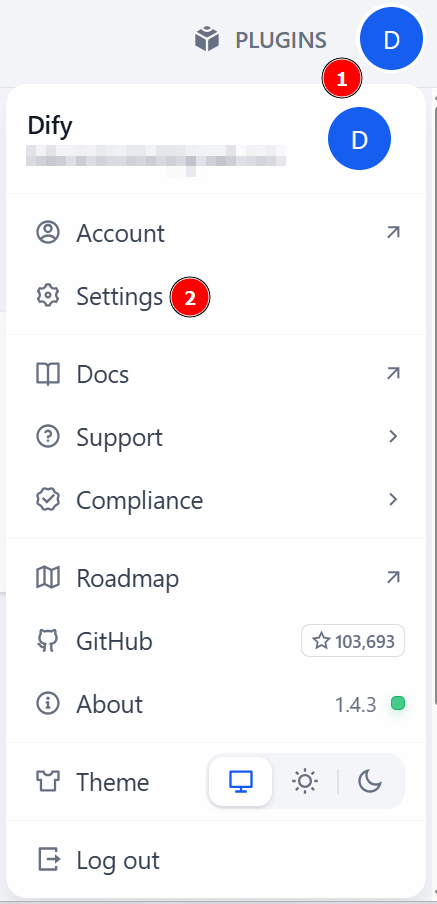
要在 Dify 中使用 LLM,您首先需要设置 LLM 集成。首先点击您的个人资料图像,然后选择 “设置”:
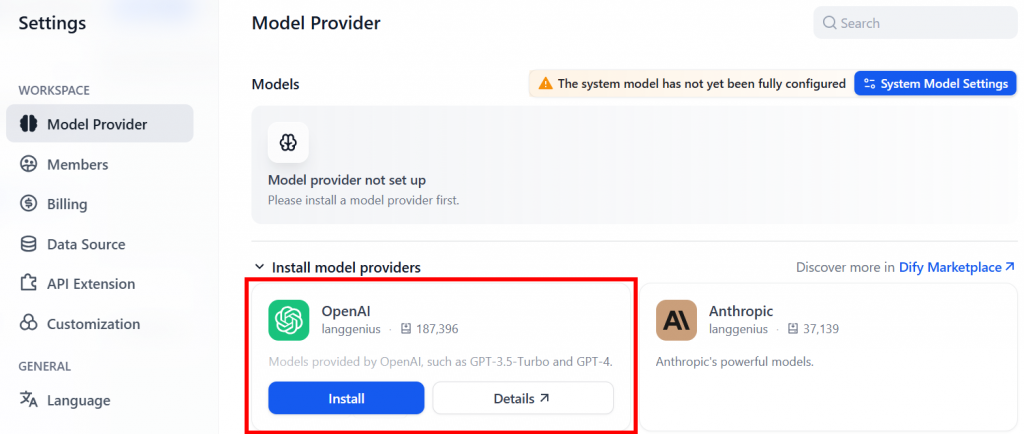
接下来,导航至 “模型提供程序 “页面。例如,您可以在这里安装OpenAI 提供商插件:
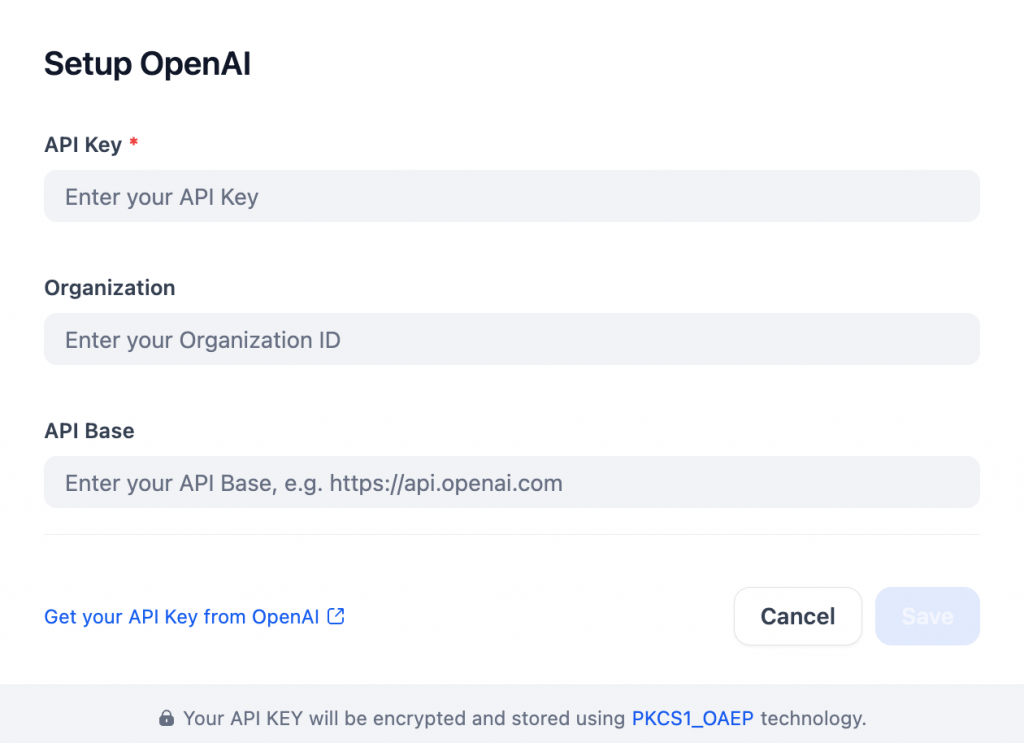
默认情况下,您将获得 200 个免费消息点数。要取消这一限制,请在安装插件后,通过添加 OpenAIAPI 密钥配置OpenAI 设置:
另外,如果想获得免费、永久的 LLM 集成,可以考虑使用 Gemini LLM 提供商。某些 Gemini 模型(如 Flash 2.0)甚至可以通过 API 免费使用。
太好了!您现在可以开始构建具有网络搜索功能的 Dify AI 工作流程了。
步骤 #2:安装 Bright Data 插件
访问GitHub 仓库中的 Bright Data 插件发布页面,下载名为brightdata_plugin.difypkg 的文件。
要在 Dify 中安装,请单击 “PLUGINS(插件)”打开插件市场,然后选择 “从本地软件包文件安装”:
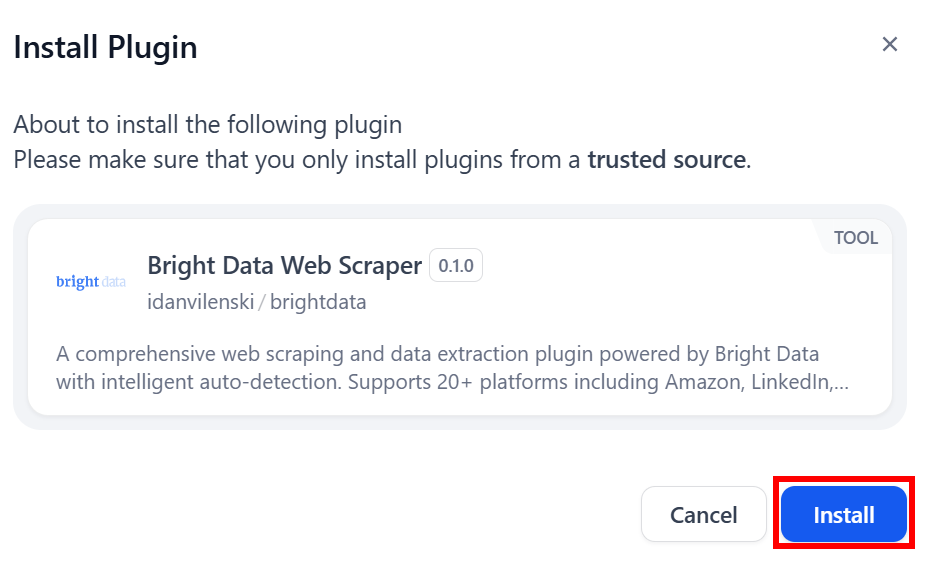
选择之前下载的本地.difypkg文件,然后点击 “安装 “按钮:
就是这样!Bright Data 插件现已成功安装到 Dify 中。
步骤 #3:设计新的 Dify 应用程序
一切准备就绪后,您就可以开始创建人工智能代理了。从 Dify 工作区主页,选择 “从空白创建”,创建一个新应用程序,如下图所示:
然后,选择 “工作流 “作为应用程序类型,为人工智能应用程序命名,并点击 “创建”:
这将生成一个新的、空白的工作流程画布:
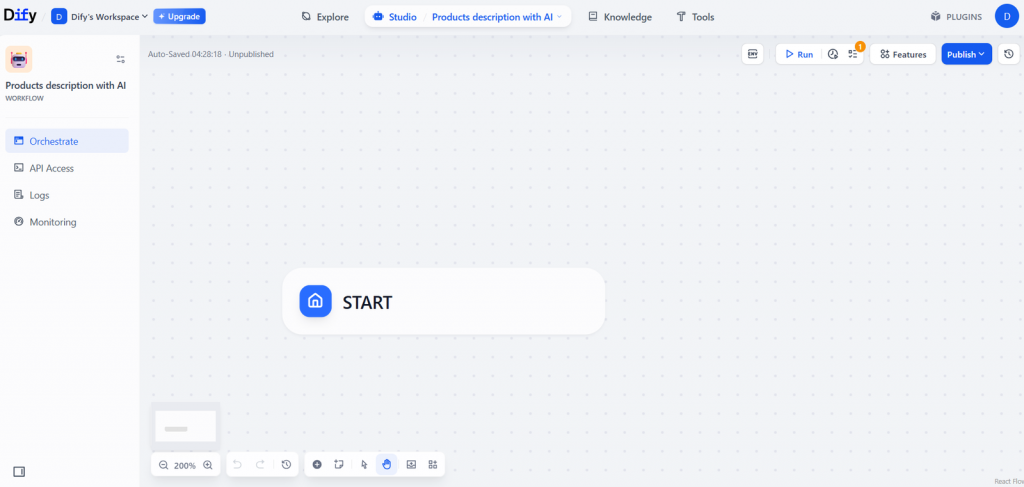
在开始构建无代码人工智能代理之前,请花点时间概述一下代理应该做什么以及需要哪些节点。在本教程中,您可以通过一个简单的四步工作流程来实现目标,其中包括以下节点:
- 一个 “开始 “节点,用于定义输入变量(关键词)。
- 搜索引擎 “节点可使用该关键词进行网络搜索。
- 一个 “LLM “节点,用于分析搜索结果,并使用自定义提示提取有用的见解。
- 一个 “结束 “节点,用于显示人工智能生成的最终报告。
太棒了是时候在 Dify 中实施网络搜索人工智能工作流程了。
步骤 #4:配置 “启动 “节点
首先点击 “开始 “节点,然后选择 “输入字段”:
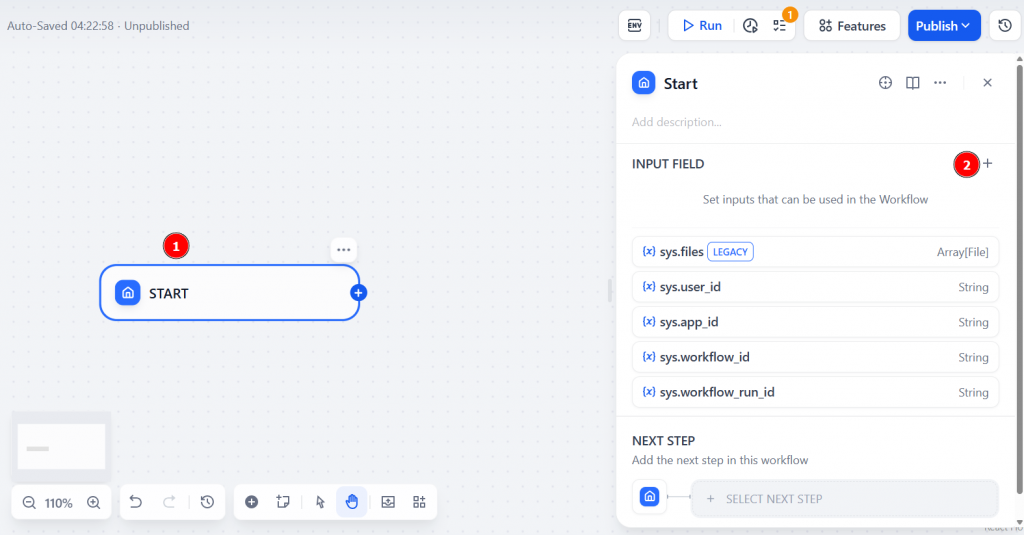
将 “字段类型 “设置为 “短文本”,因为您将输入一个短文本查询作为输入。将输入字段命名为search_topic。这代表人工智能代理将用来执行网络搜索的关键词。
点击 “保存 “确认:
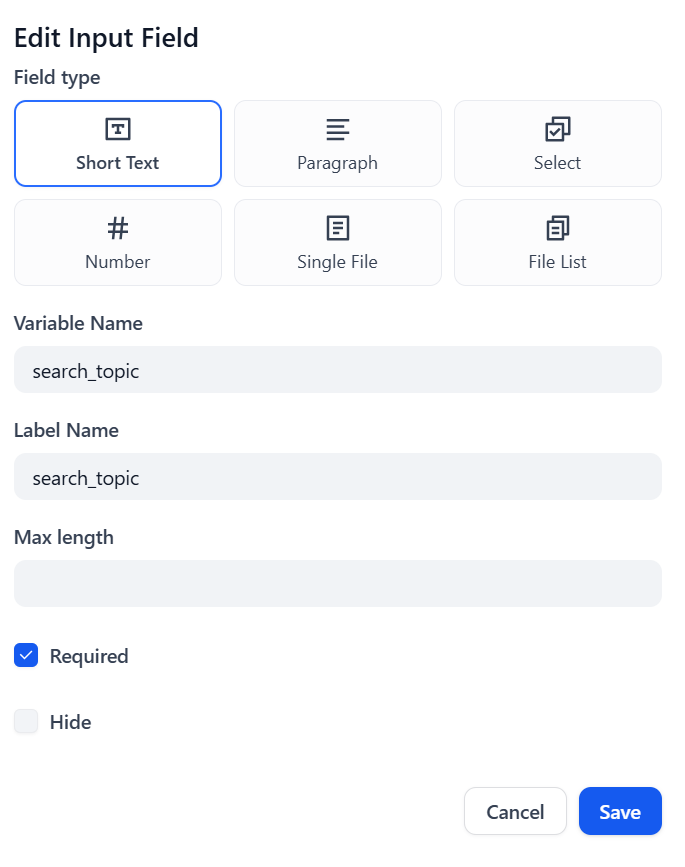
很好!现在,”启动 “节点已正确配置。
步骤 #5:整合 “搜索引擎 “节点
继续点击 “开始 “节点上的 “+”图标。然后转到 “工具” > “Bright Data Web Scraper” > “搜索引擎”:
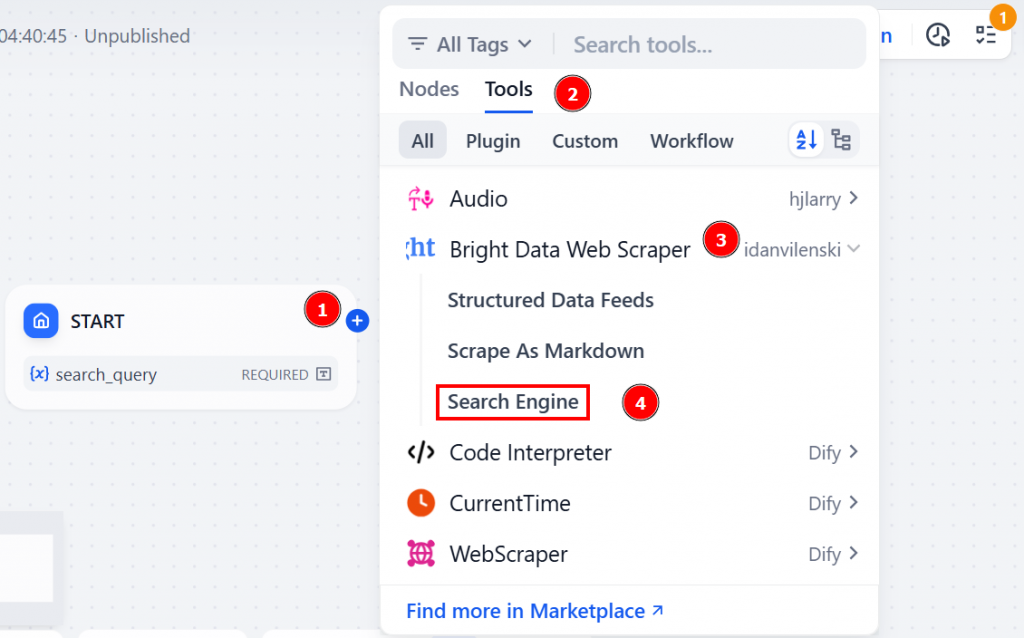
此 Bright Data 插件节点是 Dify 工作流程与Bright Data AI 基础架构之间的桥梁。具体来说,”搜索引擎 “工具可让您的人工智能代理直接从网上检索实时搜索结果。
现在,点击 “授权 “并输入您的 Bright Data API 令牌:
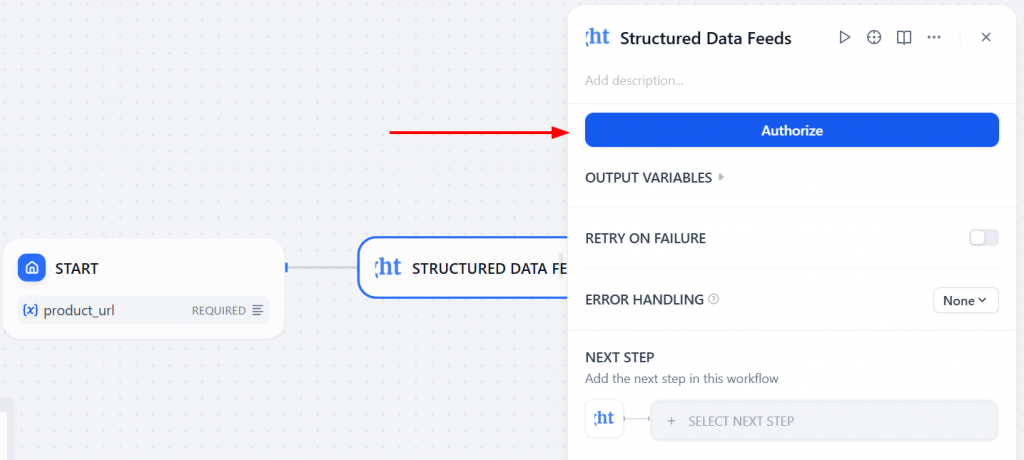
授权后,Bright Data 插件将连接到您的账户。
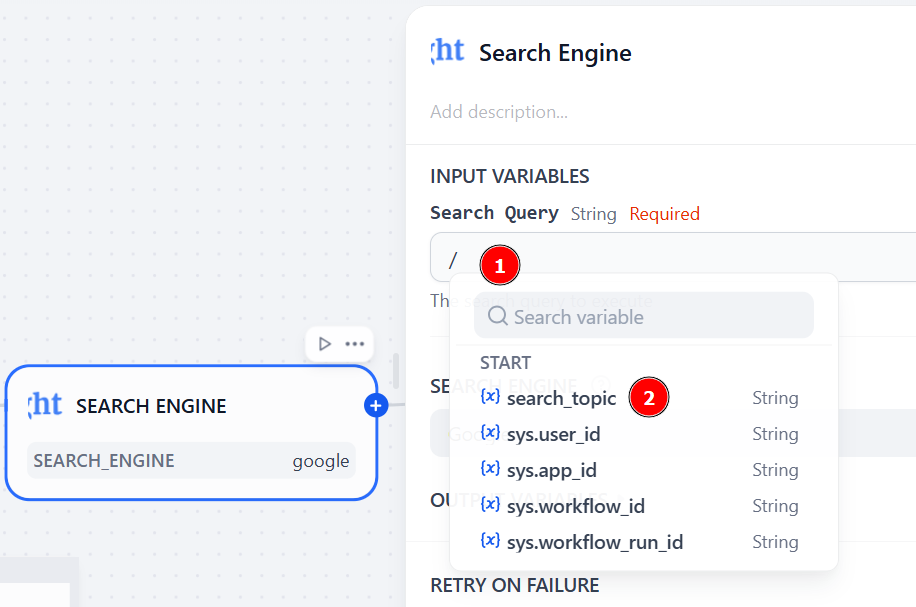
现在,输入之前配置的输入变量。在 “搜索查询 “字段中输入”/”查看可用变量,然后选择search_topic。搜索引擎 “节点将根据用户输入执行实时网络搜索:
最后,在 “SEARCH ENGINE(搜索引擎)”下拉菜单中,选择您想使用的搜索引擎(本教程将使用 Google):
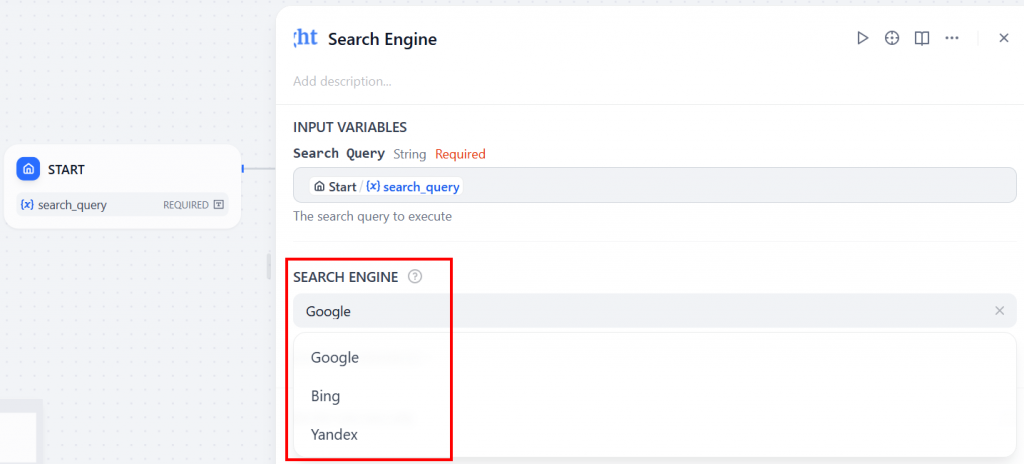
太好了!Bright Data “搜索引擎 “节点现已就位。
步骤 #6:添加 “LLM “节点
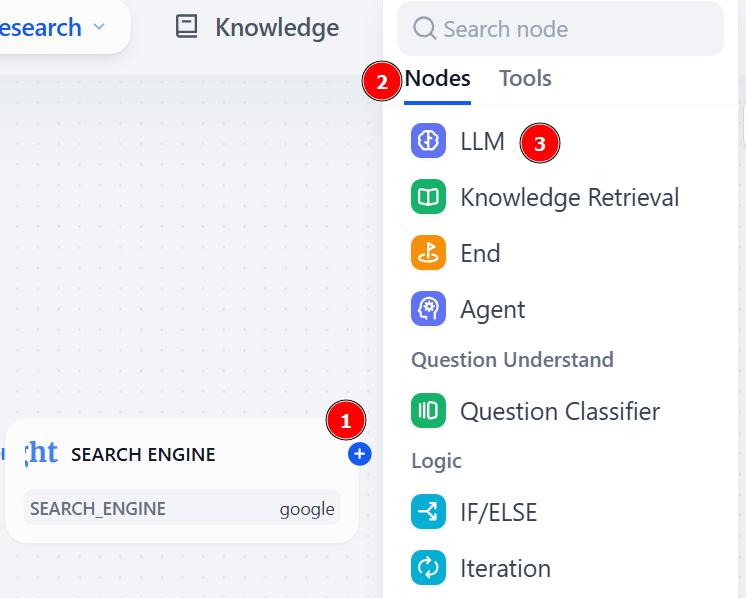
从 “搜索引擎 “节点,点击 “+”图标,选择 “法律硕士 “节点:
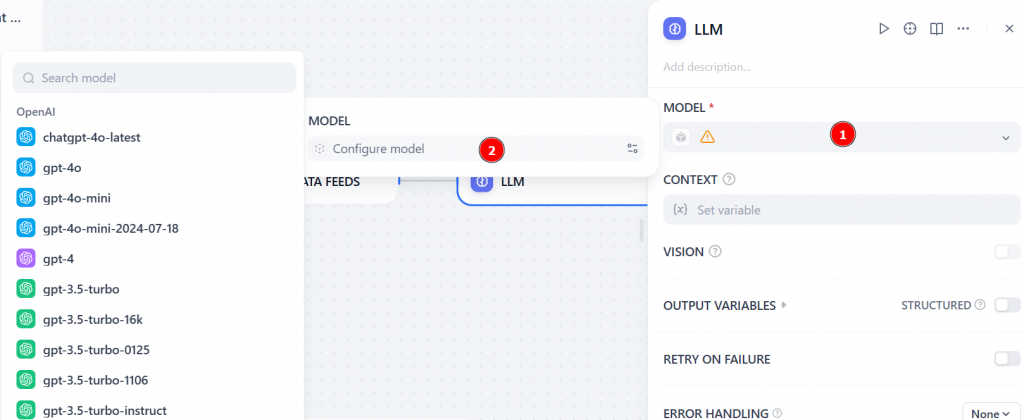
在 “MODEL(模型)”部分,点击 “Configure model(配置模型)”并从列表中选择一个 LLM(例如gpt-4):
在 “SYSTEM “部分,输入类似下面的提示:
You are an expert SEO analyst. You have been given data containing the results from a Google search.
Based on this information, please report on the following:
- Common Talking Points: What are the most common themes and keywords you see repeated in the search result titles and descriptions?
- Dominant Content Types: Based on the titles, what kind of articles seem to be ranking? (e.g., "What is...", "Top 10...", "Beginner's Guide...", "Vs...").
Also, report the URLs.
Search Results Data:
{{Search_engine.text}}该提示指示 LLM 执行以下操作
- 分析 “搜索引擎 “节点返回的搜索结果。
- 提取重复出现的主题、流行的内容格式和相关 URL,充当搜索引擎优化分析师。
注:变量{{Search_engine.text}}将 “搜索引擎 “节点输出的文本直接传入 LLM 提示符。换句话说,LLM 可以访问 “搜索引擎 “节点返回的实时网络搜索数据。
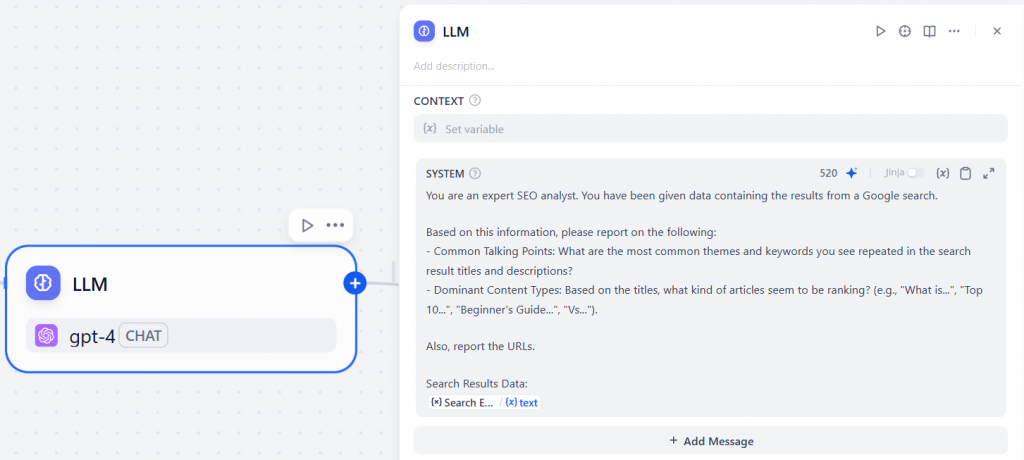
下面是 “LLM “节点配置的外观:
太棒了!现在只剩下在工作流程中添加最后一个节点了。
步骤 #7:通过 “结束 “节点最终完成人工智能工作流程
添加 “结束 “节点,完成工作流程:
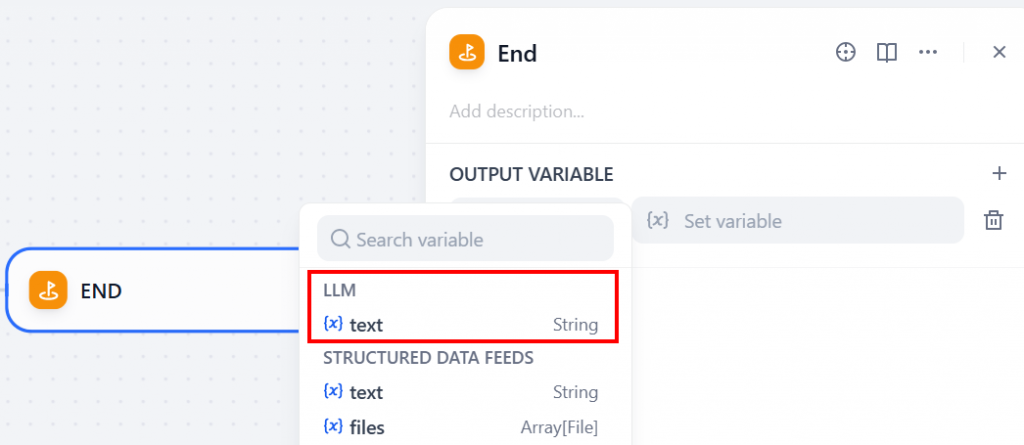
该节点将返回 LLM 生成的最终输出。要配置该行为,请单击 “OUTPUT VARIABLE(输出变量)”部分,然后从 LLM 节点中选择文本变量:
这种设置可确保 LLM 的最终响应(基于实时搜索引擎结果)作为整个工作流程的输出返回。
步骤 #8:运行人工智能网络搜索工作流程
这是 Dify 的最终网络搜索人工智能工作流程,由 Bright Data 的 “搜索引擎 “工具提供支持:
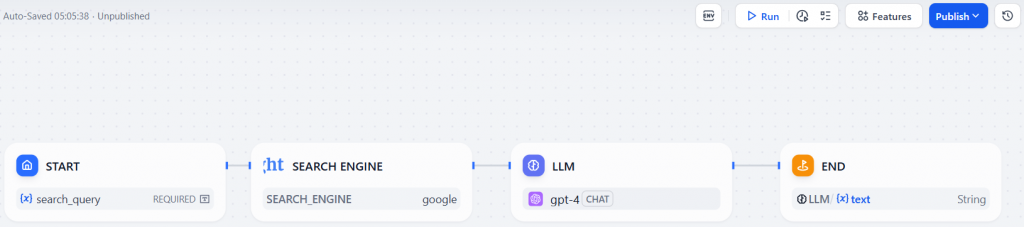
要运行工作流程,请单击 “运行 “按钮。在search_topic 的输入字段中,键入要研究的主题(如“新人工智能协议“)。然后,按 “开始运行 “按钮启动代理:
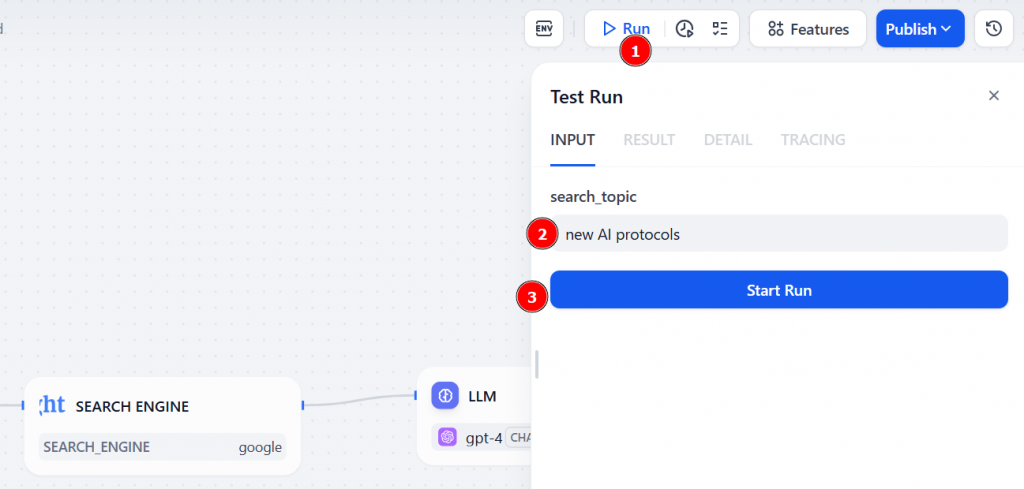
工作流程现在开始。Bright Data 节点将执行实时谷歌搜索,LLM 节点将接收搜索结果并按指示生成摘要。
最终输出结果将显示在 “结果 “选项卡中。它可能看起来像这样
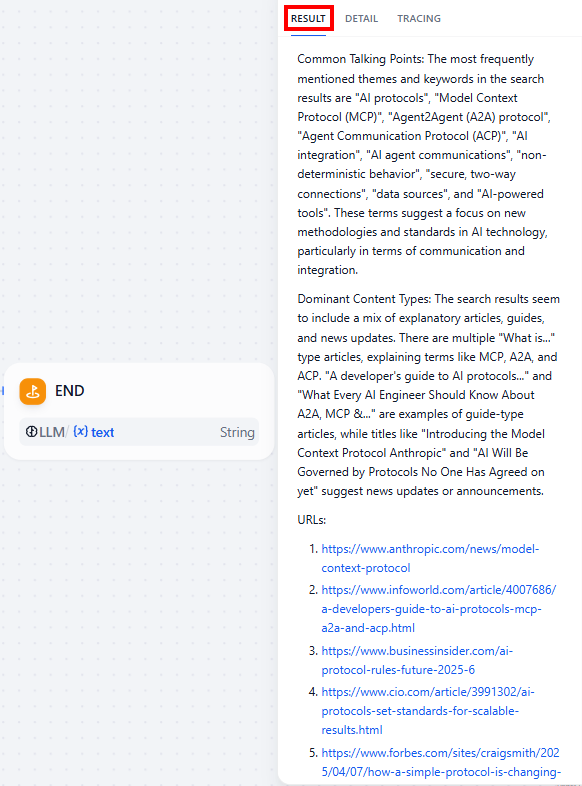
以下是文本结果:
Common Talking Points: The most frequently mentioned themes and keywords in the search results are "AI protocols", "Model Context Protocol (MCP)", "Agent2Agent (A2A) protocol", "Agent Communication Protocol (ACP)", "AI integration", "AI agent communications", "non-deterministic behavior", "secure, two-way connections", "data sources", and "AI-powered tools". These terms suggest a focus on new methodologies and standards in AI technology, particularly in terms of communication and integration.
Dominant Content Types: The search results seem to include a mix of explanatory articles, guides, and news updates. There are multiple "What is..." type articles, explaining terms like MCP, A2A, and ACP. "A developer's guide to AI protocols..." and "What Every AI Engineer Should Know About A2A, MCP &..." are examples of guide-type articles, while titles like "Introducing the Model Context Protocol Anthropic" and "AI Will Be Governed by Protocols No One Has Agreed on yet" suggest news updates or announcements.
URLs:
1. https://www.anthropic.com/news/model-context-protocol
2. https://www.infoworld.com/article/4007686/a-developers-guide-to-ai-protocols-mcp-a2a-and-acp.html
3. https://www.businessinsider.com/ai-protocol-rules-future-2025-6
4. https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html
5. https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/
6. https://hackernoon.com/mcp-a2a-agp-acp-making-sense-of-the-new-ai-protocols
7. https://www.youtube.com/watch?v=rmphqjsc4Po
8. https://www.youtube.com/watch?v=CQywdSdi5iA
9. https://www.youtube.com/watch?v=TQXG4r0U2PQ
10. https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/
11. https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
12. https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source根据指示,LLM 模型按照您的提示报告了结果:
- 确定了 “模型上下文协议 (MCP) “和 “代理对代理 (A2A) 协议 “等共同讨论点。
- 突出主要内容类型,包括开发人员指南和信息文章。
- 列出相关网址,供进一步阅读。
就是这样!您已经成功创建了一个人工智能代理,它可以在网络上搜索实时信息并提供定制的见解。
结论
在本文中,您将学习如何使用 Dify 构建一个能够搜索网络的无代码人工智能工作流。这一功能的实现要归功于Bright Data Dify 插件,它提供了一个 “搜索引擎 “工具,可从主要搜索引擎检索实时 SERP 数据。
虽然这只是一个例子,但许多其他用例都是可能的。无论您的具体人工智能工作流程目标是什么,有效的代理都需要访问用于检索、验证和转换网络数据的工具。这正是Bright Data 的人工智能基础设施所能提供的。
创建一个免费的 Bright Data 账户,现在就开始尝试使用我们的人工智能就绪数据工具!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





