

在本世纪的这十年里,代理式AI与生成式AI将成为两大重要的AI范式。随着AI在各领域的快速普及,目前出现了两种独特的体系结构模式——代理式(Agentic)和生成式(Generative)。
阅读完本指南后,你可以回答以下问题:
- 什么是代理式AI?
- 什么是生成式AI?
- 为什么它们都很重要?
- 我应该在何时使用其中之一?
这些技术的简要概述
代理式AI与生成式AI通常共享相同的基础——权重、预训练、微调以及LLM(大型语言模型)。它们的主要区别在于使用方式。这里我会借用音乐的概念来说明区别:
- 代理式AI:演奏由他人创作的乐曲——准确地遵循每一个音符,一丝不苟。
- 生成式AI:同样在演奏,但它是即兴的。生成式AI相当于是作曲者——就像贝多芬或爵士乐手。
代理式AI完成一个复杂任务。生成式AI则是创造全新的事物。
它们的共性
- 权重:权重代表模型真正学到的内容,即模型内部进行模式识别和决策的依据。
- 预训练:模型从海量数据集中学习,并据此调整内部的权重。
- 微调:在完成预训练后,模型会针对特定任务或领域进行微调,从而做出所需的行为。
- 模型:在训练完成后,模型用于实现其目标。对于代理式AI和生成式AI来说,最终结果通常(但不一定总是)由LLM驱动。
它们的差异
- 最终目标:代理式AI旨在完成某项任务;生成式AI旨在创建内容。
- 交互方式:代理式AI通常只需最少的提示,遵循既定流程决定行动;生成式AI则几乎完全依赖提示——模型收到提示后会进行解释并生成内容。
- 自主性:代理式AI往往被赋予较高的自主性,而生成式AI则更多是人在回路(human-in-the-loop)。当你使用ChatGPT抓取LinkedIn时,你用的是代理式AI;当你让ChatGPT生成一张图片时,用的就是生成式AI。
- 输出:代理式AI的输出是某种状态的改变——例如“任务完成”;生成式AI的输出通常是文本、图像或视频。
- 评估标准:代理式AI以任务是否完成来衡量;生成式AI则以输出的质量、相关性及原创性来评估。
代理式AI
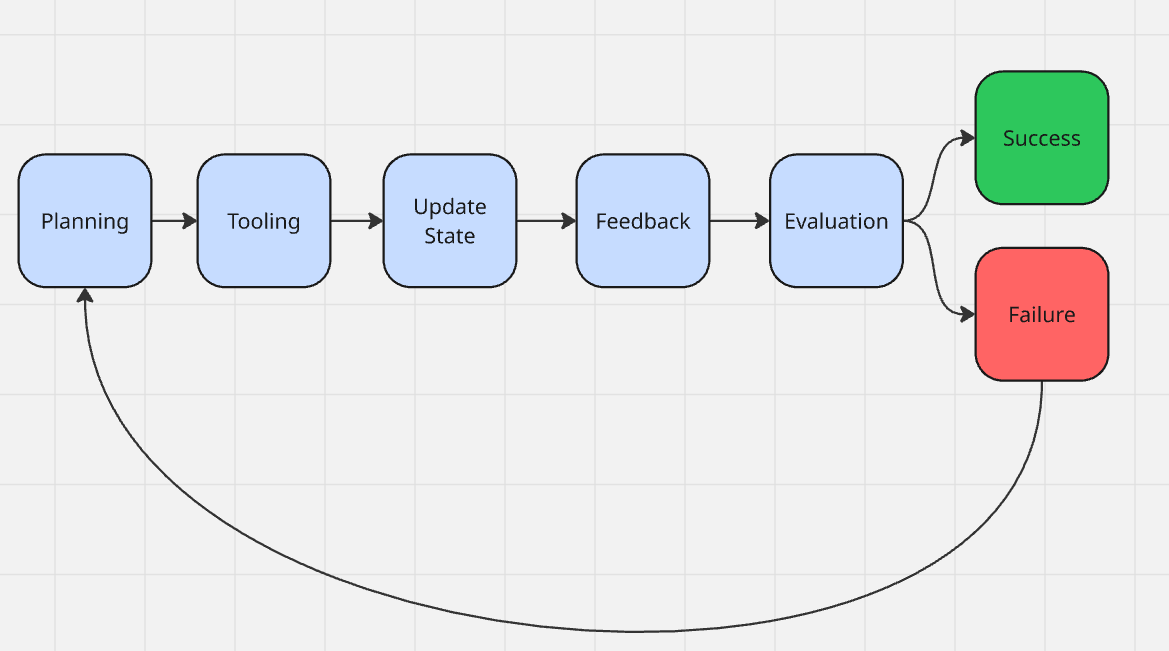
代理式AI围绕如何完成任务而运转。这一点不应与AI代理混为一谈。代理只是代理式AI的一个实际应用场景。当你使用代理式AI构建软件时,你的应用可能需要以下一项或多项功能:
- 决策
- 问题求解
- 自主性
- 交互
- 任务完成
底层原理
- 规划:任何AI代理都需要至少一个粗略的计划。它可以是一个简单的提示,例如:“你是一位乐于助人的爬虫助手,请提取这些产品并输出JSON格式。”
- 工具和函数调用:代理并不是单独行动。根据需要的复杂程度,你可能会给它一个计算器,甚至是一个完整的Playwright环境。你赋予代理访问权限,它自行决定如何以及何时使用这些工具。
- 状态管理:代理需要同时具备短期和长期上下文意识。短期情况下,聊天上下文可能足够,但这并不理想。一个简单的CRUD应用能帮助持久化数据,让代理正确跟踪自己的工作。
- 反馈循环:代理应当在一个循环中持续运行,直到任务完成或因某些条件而停止(例如用户中断)。
- 评估和终止:代理应该知道任务何时完成。如果所有步骤都执行了,但结果不符合要求,代理需要重试。如果任务成功,则退出控制循环。
使用场景
- 客户服务:几乎每个网站的帮助中心都会运行一个聊天机器人。这种情况下,模型可以记录问题、用户情绪,然后通过函数调用来创建工单或将问题标记为已解决。
- 医疗保健:自上世纪90年代起,医疗领域就开始使用代理式AI——远早于“代理式AI”这一名称的出现。代理接收X光、超声波以及病人病历等信息来加速诊断。
- 工作流程:想象一下,你的代理同时能访问浏览器和文件系统。它可以先爬取网页,然后把提取到的数据直接写入存储系统,无论是SQL数据库还是简单的JSON文件。
- 自主机器人:也许代理式AI最广泛的应用就是自主机器人和智能家居。例如特斯拉的自动驾驶、智能家电以及扫地机器人Roomba等,都属于代理式AI的应用。
生成式AI
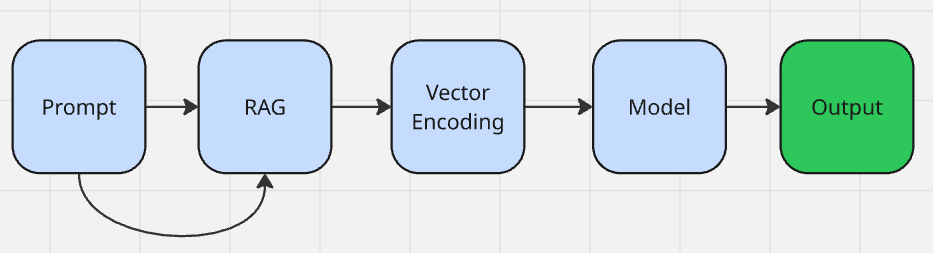
如前文所述,生成式AI更像是作曲家或爵士乐手。它仍然高度依赖预训练(甚至更甚),但会利用这些预训练来创建新的结构化或非结构化数据——关于结构化和非结构化数据的区别,你可以在此处了解更多。生成式AI可以满足以下需求:
- 创造独特的输出
- 数据分析
- 适应性
- 个性化
底层原理
- 预训练的基础模型:生成式AI模型的核心是一个大型神经网络。ChatGPT、Grok、Claude等都使用了transformer架构。训练使得模型具有推理能力,而推理能力允许我们生成新内容。
- 提示界面:这类模型通常设计为与人直接交互。当你给模型一个指令,比如“创建一个表情包”或“总结这段文字”,这个提示会被直接用于生成输出。
- 向量编码:你的提示会先被编码为一个数值向量,该向量会与模型内部的向量嵌入相匹配。想了解更多关于向量和嵌入的知识,可以点击这里。
- 检索增强式生成(RAG):RAG当前仍算可选,但它越来越常见。当模型缺乏某些信息时,会执行检索(retrieval)以找到相关数据,然后使用零样本学习来改进(augment)输出(generation)。
- 输出形式:模型使用与输入相同的向量编码原理,将结果转换为文本token(文本),甚至可以合成图像或视频。根据你的提示需求,你也可以让它输出JSON或CSV等格式的数据。
使用场景
- 对话工具:与帮助中心聊天机器人不同,生成式聊天机器人旨在进行对话并生成独特的内容——它们模拟更深入的对话,而不只是“你确定电源插好了吗?”这类简单查询。Grok、ChatGPT、Claude等大多数基于LLM的网络应用都属于此类。
- 内容创作:只要使用正确的提示,生成式模型可以在数秒内产出高质量内容。无论你需要概念艺术、社交媒体帖文还是长文写作,生成式模型都能应对这些任务。
- 数据分析与生成:将数据集上传给模型进行分析。根据模型的不同,你可能得到详细的报告,或者生成一份新的合成数据集,反映原始数据的模式。
- 个性化助手:生成式AI具有高度的可定制性——它们天生就可以“与众不同”。如果你想要一个具有特定语气的助手,只需提供一些示例,你就能训练出一个自定义的“个性”。
代理式AI与生成式AI的关键对比
| 对比项目 | 代理式AI | 生成式AI |
|---|---|---|
| 主要目的 | ✔️ 任务执行与完成 | ✔️ 内容生成与综合 |
| 目标导向 | ✔️ 是的——有明确的目标 | ❌ 不一定以目标为导向 |
| 对提示的依赖 | ❌ 较少——通常可自动运行 | ✔️ 高——需要提示来启动输出 |
| 输出类型 | ✔️ 状态变化,完成动作 | ✔️ 文本、图像、代码或结构化数据 |
| 工具使用/API访问 | ✔️ 经常会使用工具或函数 | ❌ 很少(除非在代理循环中封装) |
| 内存需求 | ✔️ 需要短期和长期记忆 | ❌ 可选(仅在RAG或定制版本中) |
| 控制流程 | ✔️ 有反馈循环及重试逻辑 | ❌ 一次性生成(默认无循环) |
| 自主性 | ✔️ 可实现高度自主 | ❌ 通常需要人在回路 |
| 评估方式 | ✔️ 成功/失败的二元结果 | ✔️ 主观质量(原创性、语气等) |
| 实际示例 | ✔️ 网页爬虫机器人、自动驾驶汽车 | ✔️ ChatGPT、DALL·E、GitHub Copilot |
结论
代理式AI与生成式AI并非互相竞争,而是各有侧重。它们在很多方面存在很大的重叠,但代理式AI会根据计划行动,而生成式AI则根据一次次提示进行即兴创作。
Bright Data的Model Context Protocol等工具允许你的代理或LLM实时访问真实的网络数据。这极具威力——你的AI能够访问互联网上任何公开网站。对于代理式AI而言,这能提升决策能力;对于生成式AI而言,这能提高内容质量。
代理式AI和生成式AI将主导未来。能够理解并灵活运用这两种范式的开发者和分析师,将在未来具备更强的竞争力。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。



