

在本教程中,你将学到:
- 如何通过基于查询扇出与 Google AI Overview(AI 概览)对比的方法提升 GEO 与 SEO。
- 如何通过六个 AI 智能体在高层次上构建该工作流。
- 如何使用 CrewAI 并集成 Gemini 与 Bright Data 实现该 AI 内容优化工作流。
- 进一步增强此工作流的一些思路与建议。
让我们开始吧!
要点速览
想直接获取可用的项目文件?请查看 GitHub 上的项目。
解释查询扇出与 AI 概览对比:助力更佳的 GEO 与 SEO
我们都知道,SEO(Search Engine Optimization)是提升网站在自然搜索结果中可见性的艺术。但世界正在向 GEO(Generative Engine Optimization,生成式引擎优化)转变。
如果你对 GEO 不熟悉,它是一种数字营销策略,旨在让内容在 Google AI Overviews、ChatGPT 等 AI 驱动的搜索引擎中更易被看到。
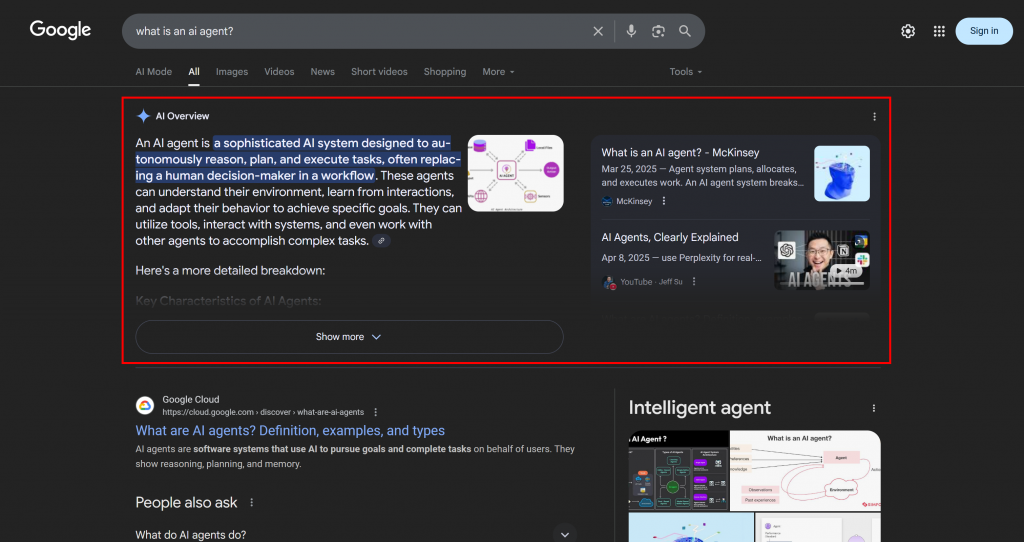
由于大语言模型本质上是黑盒,目前没有直接的方式为 GEO “优化”网页(这与关键词搜索量工具出现前的 SEO 很相似)。
你可以采取经验性的方法:查看目标关键词对应的真实 AI 生成摘要与查询扇出。针对某个搜索词,若某些主题在 AI 结果中反复出现,就应围绕这些主题优化页面内容。
在 Google 的 AI 驱动搜索场景中,查询扇出(query fan-out) 是一种将单个用户查询扩展为一组相关子查询的技术。Google AI 模式不仅仅匹配原始查询与最佳答案,还会进一步生成并同时检索多个相关问题。
如下例所示,Google AI 模式通常会返回约 10 个相关链接,并附带简短摘要,帮助你更深入地探索该主题:
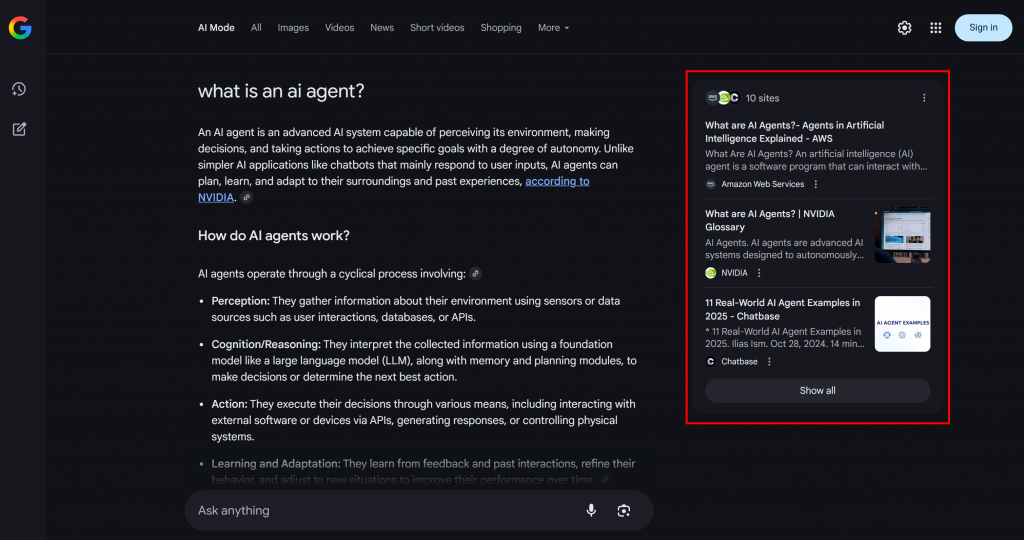
这就是 Google 查询扇出,可以更简单地理解为:基于一次 AI 搜索生成的一组相关子查询集合。
如果某些主题在查询扇出与 AI 概览中反复出现,那么围绕这些主题来组织内容页面就很有意义。一个正向的副作用是,这一方法也有助于传统 SEO,因为像 Google 这样的搜索引擎很可能提升那些在其 AI 驱动搜索中表现良好的页面在 SERP 中的排名。
现在你已了解基础原理,让我们深入 GEO 方法的技术细节!
如何构建多智能体 GEO 优化系统
如你所想,实现一个支持 GEO 内容优化工作流的 AI 智能体并不简单。一种有效方法是基于六个专用智能体的多智能体系统:
- Title Scraper(标题抓取):根据网页 URL,提取页面的主标题或 H1。
- Google Query Fan-Out Researcher(Google 查询扇出研究):使用提取的标题调用 Gemini 中可用的 Google Search 工具,生成查询扇出。
- Google Main Query Extractor(Google 主查询提取):解析查询扇出,识别并提取主要的类 Google 搜索查询。
- Google AI Overview Retriever(Google AI 概览获取):使用主查询执行 Google SERP 搜索,并提取其中的 AI Overview 区域。
- Query Fan-Out Summarizer(查询扇出总结):将通常较长的查询扇出内容压缩为优化的 Markdown 摘要,突出关键主题。
- AI Content Optimizer(AI 内容优化):对比查询扇出摘要与 Google AI 概览,找出模式和反复出现的主题,并生成包含可操作洞察的 Markdown 文档,用于 GEO 内容优化。
上述部分智能体相当通用,可以用多数 LLM 实现(例如 Google Main Query Extractor、Query Fan-Out Summarizer 与 AI Content Optimizer)。但也有智能体需要更专业的能力与特定模型或工具的访问。
例如,Google Main Query Extractor 需要访问 google_search 工具,而它只在 Gemini 模型中可用。类似地,Title Scraper 必须访问网页内容以提取标题。这项任务具有挑战性,因为许多网站具备反 AI 措施。为避免问题,你可以将 Title Scraper 集成到 Web Unlocker 中。该 Bright Data 抓取 API 可返回原始 HTML 或 AI 优化的 Markdown 内容,并为你绕过所有阻断。
同样,Google AI Overview Retriever 需要使用像 Bright Data SERP API 这样的工具来执行搜索查询,并实时抓取 AI Overview。
换言之,借助 Gemini 与 Bright Data 的 AI 基础设施,你可以落地这个 GEO/SEO 用例。接下来,你需要一个AI 智能体构建系统来编排这些智能体,如下图所示:
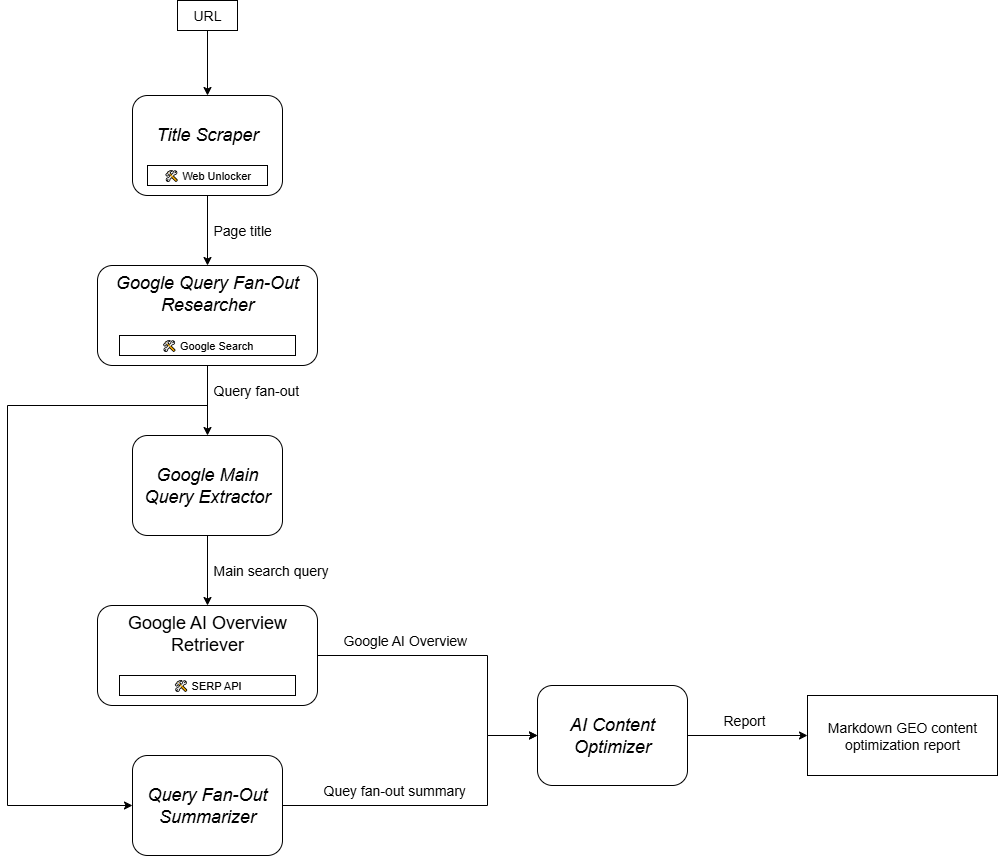
由于 CrewAI 专为编排多智能体系统而设计,它是构建与管理此工作流的理想框架。
使用 CrewAI、Gemini 与 Bright Data 在实战中实现多智能体 GEO 内容优化系统
按照以下步骤,构建一个可复用的多智能体系统,用于为 AI 驱动的搜索引擎优化网页。通过系统化分析查询扇出与 AI 概览,这一方法帮助你发现高优先级主题,并据此结构化内容,从而在 AI 驱动的排名中获得更高位置。
下文代码使用 Python 编写,采用 CrewAI,并集成 Bright Data 与 Gemini,为各智能体提供必要的工具与能力。
前置条件
请确保你已具备:
- 本地安装的 Python 3.10+。
- Gemini API Key(无需额度)。
- 一个 Bright Data 账户。
如果你还没有 Bright Data 账户也没关系。文中会引导你完成注册流程。
此外,理解 CrewAI 的基本工作方式非常重要。开始前,建议先阅读官方文档。
步骤 1:设置 CrewAI 应用
CrewAI 需要使用 uv 进行安装。你可以用如下命令全局安装:
pip install uv或者,按照你操作系统的官方安装指南进行。
接着,在你的系统上全局安装 CrewAI:
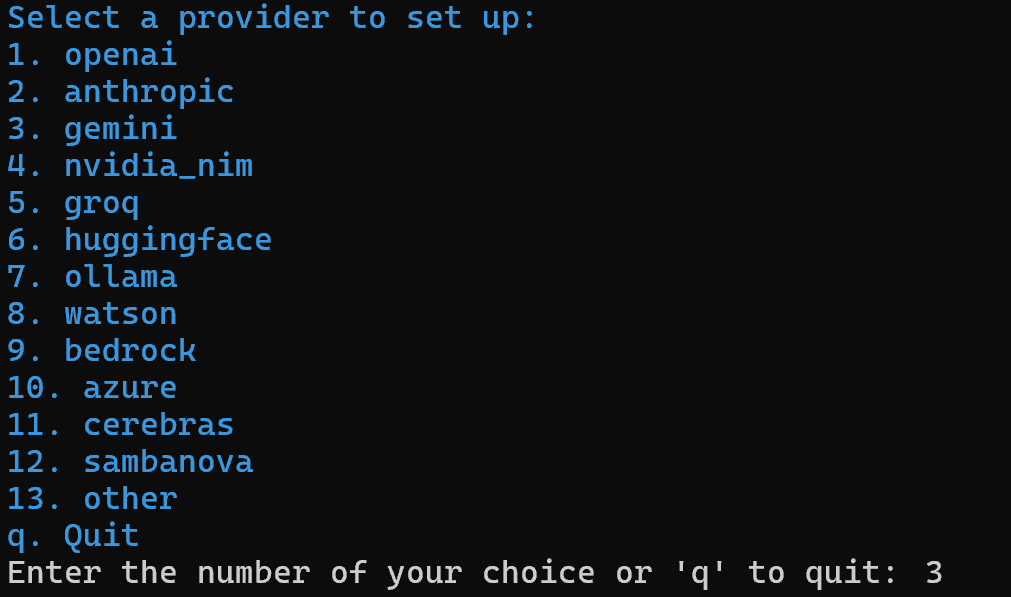
uv tool install crewai 现在,创建一个名为 ai_content_optimization_agent 的 CrewAI 项目:
crewai create crew ai_content_optimization_agent系统会提示你选择一个 AI 提供方。由于当前工作流基于 Gemini,请选择选项 3:
接下来,选择一个 Gemini 模型:
可选择任意可用模型,稍后你会替换它,因此此时并不关键。
继续粘贴你的 Gemini API Key:

完成上述步骤后,ai_content_optimization_agent/ 项目的目录结构如下:
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yaml在你喜欢的 Python IDE 中打开项目并熟悉其结构。查看当前文件,并注意 .env 已包含所选 Gemini 模型与 API Key:
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>如果不熟悉 CrewAI 中各文件或遇到问题,请参考官方安装指南。
在终端中进入项目目录:
cd ai_content_optimization_agent随后,在该目录中初始化一个Python 虚拟环境:
python -m venv .venv 注意:虚拟环境必须命名为 .venv。否则用于启动 CrewAI 工作流的 crewai run 命令会失败。
在 Linux 与 macOS 上,激活虚拟环境:
source .venv/bin/activate在 Windows 上,执行:
.venvScriptsactivate完成!你已建立一个空白的 CrewAI 项目。
步骤 2:集成 Gemini
如前所述,CrewAI 会默认将所选的 Gemini 模型写入 .env 文件。要切换到最新模型,覆盖 .env 中的 MODEL 环境变量:
MODEL=gemini/gemini-2.5-flash这样,你由 CrewAI 编排的 AI 智能体即可连接到 gemini-2.5-flash。撰写本文时,这是最新的 Gemini Flash 模型,且通过 API(如本次 CrewAI 集成)调用的速率限制非常宽松。
在 crew.py 中,从环境中读取 MODEL 名称:
MODEL = os.getenv("MODEL")该变量稍后将用于为智能体设置 LLM。
不要忘记从 Python 标准库中导入 os:
import os很好!Gemini 设置完成。
步骤 3:安装并配置 CrewAI 的 Bright Data 工具
通过 AI 提取网页标题并非易事。多数 LLM 无法直接访问网页内容;即便带有内置网页访问工具,也常因高级的反爬措施(如浏览器指纹与验证码)而失败。实时 SERP 抓取同样面临挑战,因为 Google 会主动阻止自动化抓取。
这正是 Bright Data 发挥关键作用的地方。幸运的是,CrewAI 已官方支持 Bright Data 工具。
首先,注册一个 Bright Data 账户(或如果已有账户请登录)。随后进入你的个人控制台,按照官方指南设置一个 Web Unlocker 区:
确保该区的状态为“Active”:
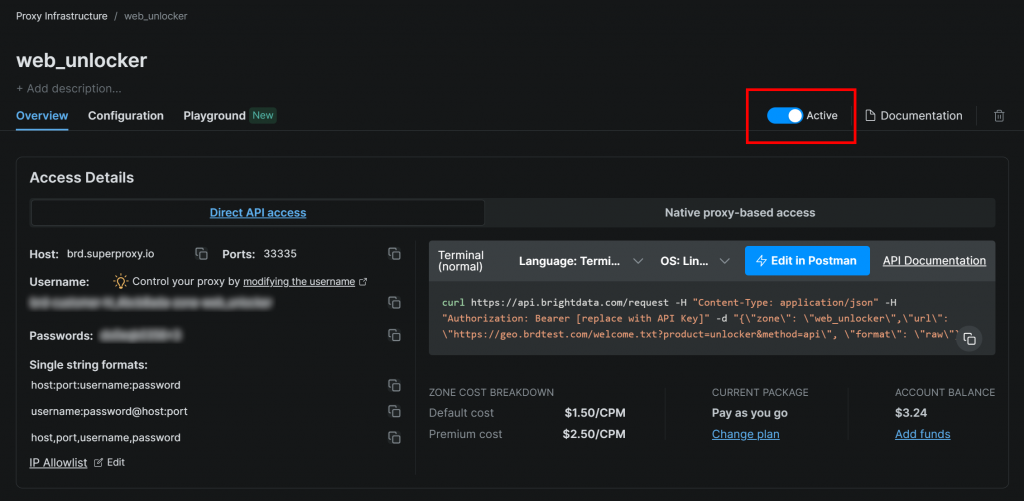
此处的 Web Unlocker 区名称是 "web_unlocker",你也可以自定义其他名称。请记住该名称,稍后将用到。
完成设置后,按照官方指南生成 Bright Data API Key。请妥善保管,后续会用到。
现在,在已激活的虚拟环境中安装 CrewAI Bright Data 工具依赖:
pip install crewai[tools] aiohttp requests为使集成生效,将你的 Bright Data 凭据加入 .env 文件中的两个环境变量:
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"将 <YOUR_BRIGHT_DATA_API_KEY> 与 <YOUR_BRIGHT_DATA_ZONE> 分别替换为你的 Bright Data API Key 与 Web Unlocker 区名称。
接着,在 crew.py 中导入 Bright Data 工具:
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchTool按如下方式初始化:
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()现在,只需将这些工具传入智能体,即可赋予其网页解锁与 SERP 检索能力。太棒了!
步骤 4:构建 Title Scraper 智能体
准备好构建第一个智能体:Title Scraper,负责从网页中提取标题。
获取页面标题主要有两种方式:
- 从 HTML 的
<h1>元素中抓取文本。 - 如果没有
<h1>,则让 AI 从页面内容中推断标题。
别忘了这需要集成 Web Unlocker 工具。在 crew.py 中,按如下方式定义 CrewAI 智能体与任务:
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)由于该任务需要调用第三方工具,建议通过 max_retries 将重试次数设为 3,以避免因为临时网络问题或工具错误导致整个工作流失败。对所有依赖第三方服务(通过工具)或涉及复杂 AI 操作、可能因 LLM 处理错误而失败的任务,都应采用类似的重试策略。
接着,在 agents.yaml 配置文件中按如下方式定义 Title Scraper 智能体:
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."然后在 tasks.yaml 中描述其主要任务:
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."注意该任务通过 {url} 语法从 CrewAI 输入中读取 URL。稍后你将看到如何填充这个输入参数。
很好!Title Scraper 智能体已完成。接下来以类似方式定义其余智能体。
步骤 5:实现 Google Query Fan-Out Researcher 智能体
CrewAI 目前没有内置方式访问 Gemini 模型中的 Google Search 工具。你需要像官方 Gemini CrewAI 集成仓库示例那样,定义一个自定义的 Gemini LLM 集成。
本质上,你需要创建一个继承自 CrewAI 的 LLM 类的类,用于连接 Gemini 并启用 google_search 工具。你可以将该类放在自定义的 llms/ 子目录下的 gemini_google_search_llm.py 中(也可直接写在 crew.py 顶部)。
按如下方式定义自定义 Gemini LLM 集成类:
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)这样就可以在配置的 Gemini 模型中访问 Google Search 工具。
注意:Google Search 工具有免费额度,你可以在应用中使用,无需付费计划。
然后,在 crew.py 中导入 GeminiWithGoogleSearch 类:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearch用它来指定 Query Fan-Out Researcher 智能体:
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)注意 Agent 中使用的 LLM 是自定义的 GeminiWithGoogleSearch 实例。由于查询扇出结果对调试与进一步分析很有价值,建议输出到自定义文件。在此示例中,输出存储在 output/query_fanout.md。
另请注意,当前智能体任务的上下文正是上一个智能体主任务的输出。这样当前智能体即可使用 Title Scraper 产生的结果作为调用 Google Search 工具进行扇出检索的输入。
接着,在 agents.yaml 中添加:
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."在 tasks.yaml 中添加:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."如果你想了解查询扇出的样子,下面是一个真实的 google_search 工具输出片段:
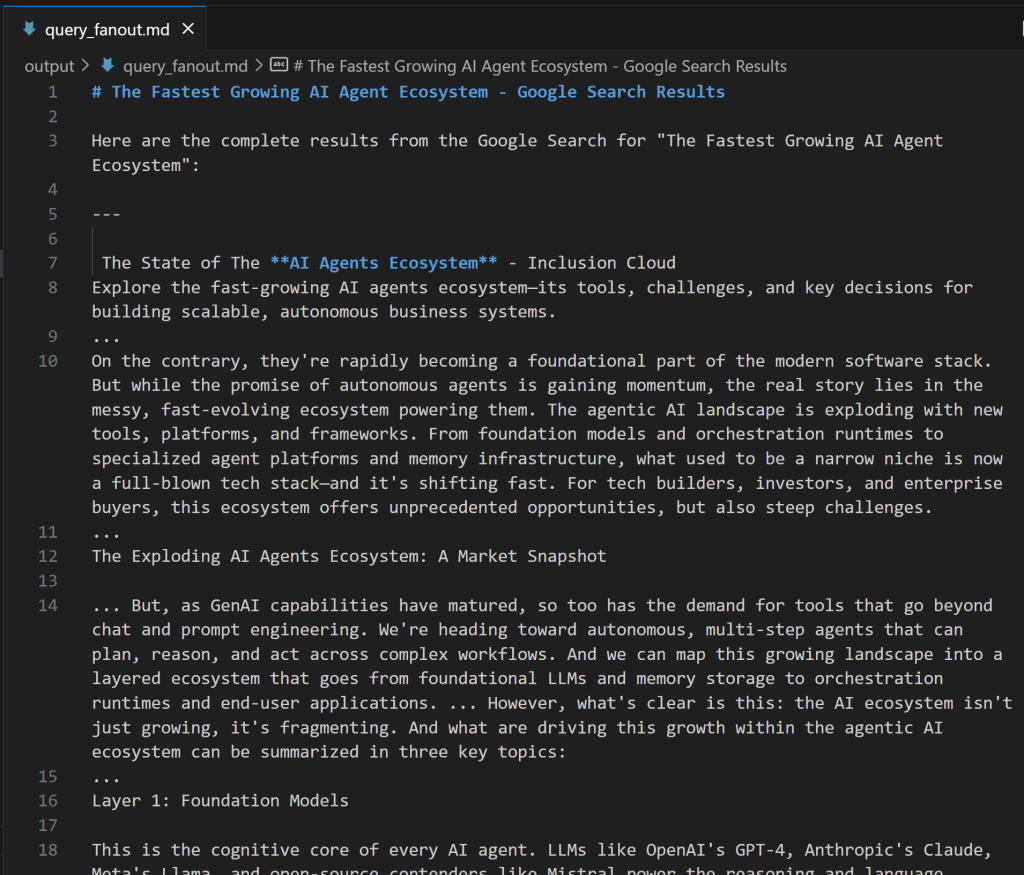
完美!Google Query Fan-Out Researcher 智能体已就绪。
步骤 6:定义其余智能体
像之前一样,在 crew.py 中继续定义其余智能体:
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)以上代码分别定义了:
- Google Main Query Extractor 智能体及其主任务。
- Google AI Overview Retriever 智能体及其主任务。
- Query Fan-Out Summarizer 智能体及其主任务。
- AI Content Optimizer 智能体及其主任务。
在 agents.yaml 中补充:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."以及在 tasks.yaml 中补充:
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.可以看到,ai_overview_extraction_task 的任务包含了在 SERP API 响应中获取 AI 概览的技术规范。详情请参阅官方文档。
太好了!GEO 内容优化工作流中的所有 AI 智能体均已创建完毕。接下来,添加 Crew 以编排它们。
步骤 7:将所有智能体聚合为一个 Crew
在 crew.py 中定义一个新的 Crew 函数,顺序运行智能体:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)很好!crew.py 中的 AiContentOptimizationAgent 类已完成。你只需在 main.py 中调用其 crew() 方法即可启动工作流。
步骤 8:定义运行流程
覆盖 main.py 文件,实现:
- 使用 Python 的
input()从终端读取输入 URL。 - 使用该 URL 构造所需的智能体输入。
- 初始化
AiContentOptimizationAgent并调用其crew()方法,传入包含{url}字段的输入对象。 - 运行 AI 工作流。
在 main.py 中实现如下逻辑:
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")步骤 9:测试你的智能体
在已激活的虚拟环境中,启动智能体前,先安装所需依赖:
crewai install然后启动多智能体 GEO 优化系统:
crewai run系统会提示你输入 URL:

本示例使用 CrewAI 官网的一页作为输入:
https://www.crewai.com/ecosystem
此页面展示了 AI 智能体生态的主要参与者。
对该页面运行智能体,你将看到类似输出:
上面的 GIF 加速播放了,实际上步骤如下:
- Title Scraper 智能体通过 Bright Data Web Unlocker 工具收集页面标题,结果为
"The Fastest Growing AI Agent Ecosystem"(与页面截图一致)。 - Google Query Fan-Out Researcher 通过
google_search工具生成查询扇出,并在output/目录生成query_fanout.md。 - Google Main Query Extractor 从查询扇出中识别出主要类 Google 搜索查询,结果为
"AI agent ecosystem growth"。 - Google AI Overview Retriever 使用 Bright Data SERP API 获取该搜索查询的 AI 概览,并输出到
ai_overview.md。 - Query Fan-Out Summarizer 将查询扇出内容浓缩为详细的 Markdown 摘要,保存为
query_fanout_summary.md。 - AI Content Optimizer 对比查询扇出摘要与 Google AI 概览,生成最终的
report.md文件。
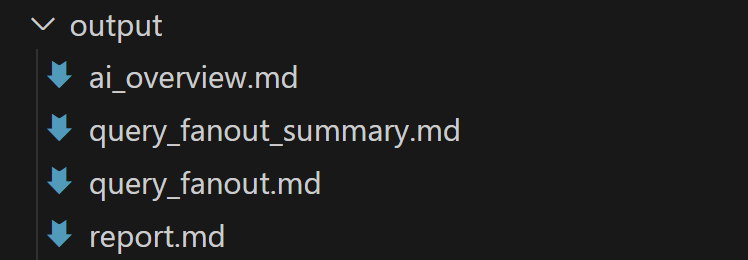
执行结束后,output/ 目录应包含以下四个文件:
在 VS Code 中以预览模式打开 report.md 并滚动查看:
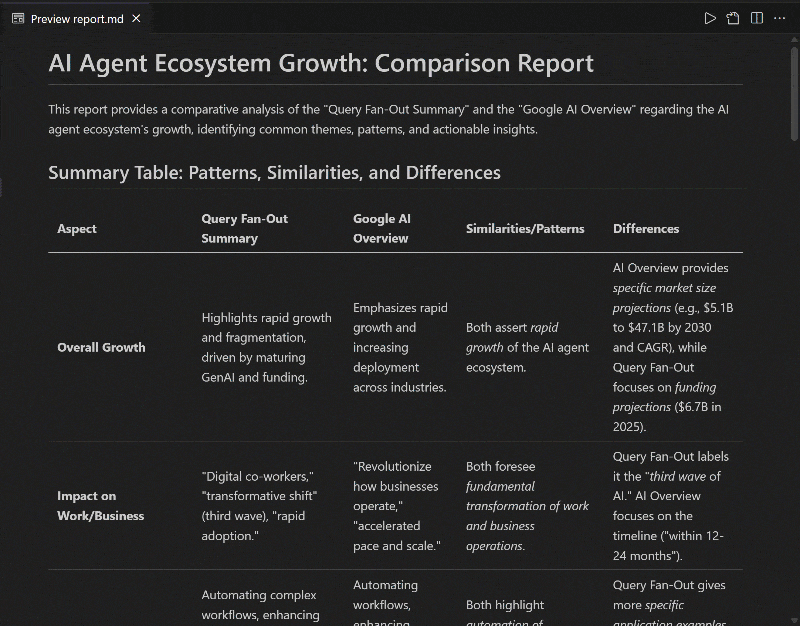
如你所见,报告包含详尽的 Markdown 内容,帮助你基于 GEO(与 SEO)优化输入页面的内容!
现在,将该智能体用于你希望提升 AI 排名的网页 URL,即可增强你的 GEO 与 SEO 表现。
大功告成!
下一步
上述 AI 内容优化智能体已经相当强大,但仍有改进空间。一个思路是在工作流开头增加一个智能体,它以站点地图(可选用正则过滤 URL,例如只选博客文章)作为输入,然后把这些 URL 传给现有工作流,甚至可并行处理,从而同时分析多页的 AI 内容优化。
总体而言,你可以在 agents.yaml 与 tasks.yaml 中调整指令,以便针对你的特定用例微调六个智能体的行为。完成这些调整并不需要高深的技术能力!
结语
本文介绍了如何利用 Bright Data 的 AI 集成能力,在 CrewAI 中构建一个复杂的多智能体工作流,用于 GEO/SEO 优化。
该 AI 工作流非常适合希望以编程化方式同时为传统搜索引擎与 AI 驱动搜索改进网页内容的用户。
如需创建类似的高级工作流,请探索 Bright Data AI 基础设施中用于检索、验证与转换实时网页数据的全套方案。
立即创建一个免费的 Bright Data 账户,开始体验我们的 AI 就绪型网页工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


