
在本教程中,你将看到:
- 什么是 OpenAI Codex CLI 以及它能做什么。
- 如何通过网页交互与数据抓取能力让 Codex 更有效。
- 如何将 Codex CLI 连接到 Bright Data MCP 服务器,构建下一代 AI 编码代理。
让我们开始吧!
什么是 OpenAI Codex CLI?
OpenAI Codex CLI(简称 Codex 或 Codex CLI)是 OpenAI 开发的一个开源命令行工具。它的目标是将其大语言模型的能力直接带到你的终端中。
它可以帮助开发者完成的主要任务包括:
- 代码生成与修改:理解自然语言指令,生成有效代码,并在你的项目中应用修改。
- 代码理解与解释:帮助理解不熟悉的代码库,或清晰解释特定代码片段。
- 调试与测试:协助定位并修复错误、编写测试,甚至在本地运行这些测试。
- 代码仓库管理:与 Git 等版本控制系统集成,管理文件、设置迁移、更新导入等。
- Shell 命令执行:运行安装依赖、执行测试等任务所需的 Shell 命令。
由此可见,Codex CLI 就像一个轻量级的本地编码助手。该库用 Rust 构建,并以开源的 Node.js 包形式提供。
尽管它仅在 2026 年 5 月中旬发布,但已在 GitHub 上获得超过 3.4 万颗星。这强烈表明其在 IT 社区的采用与受欢迎程度。
为什么要为 Codex CLI 扩展网页交互与数据获取能力?
无论集成到 Codex CLI 的 OpenAI 模型多么先进,它们仍然具有所有大语言模型共有的局限性。
OpenAI 的 LLM 是基于训练用的静态数据集生成回答的,本质上是某个时间点的快照。考虑到开发技术更新极快,这一点尤其成问题。
想象一下,如果你的 Codex CLI 编码助手能够访问最新的教程、文档与指南,并从中学习。同时,它可以像探索本地文件系统一样轻松地浏览动态网站。通过与Bright Data MCP 服务器集成,这一重大功能升级完全可以实现。
Bright Data MCP 服务器提供 60 多个面向 AI 的工具,用于实时网页数据提取与交互。这些工具均由Bright Data 丰富的 AI 数据基础设施驱动。
将 OpenAI CLI 与 Bright Data MCP 相结合,你可以实现如下目标:
- 自动获取搜索引擎结果页,在文本文档中嵌入相关的上下文链接。
- 收集最新教程或文档,吸收信息并生成可运行代码,甚至从零创建项目。
- 从网站提取实时数据并本地存储,用于测试、Mock 或分析。
要查看 Bright Data MCP 服务器可用工具的完整列表,请查阅文档。
来看一看 Bright Data MCP 服务器在 Codex CLI 中的实际表现!
如何将 OpenAI Codex CLI 连接到 Bright Data Web MCP Server
学习如何安装 OpenAI Codex CLI 并将其配置为与 Bright Data MCP 服务器交互。我们将使用得到的增强型编码 CLI 代理来完成以下任务:
- 从某个亚马逊商品页面抓取结构化数据。
- 将数据存入本地文件。
- 编写一个 Node.js 脚本以加载并处理这些数据。
按下面的步骤操作!
前提条件
要跟进本教程,请确保你具备:
- 本地安装了 Node.js 20+(推荐最新 LTS 版本)。
- 一个 OpenAI API Key。
- 一个 Bright Data 账号以及可用的 API Key。
下文步骤会在需要时带你设置 OpenAI 与 Bright Data 的密钥。
OpenAI Codex CLI 的系统要求:
- macOS 12+,或
- Ubuntu 20.04+/Debian 10+,或
- Windows 11(通过 WSL 2,注意需要Windows Subsystem for Linux 版本 2)。
可选但有帮助的背景知识:
步骤一:安装 OpenAI Codex CLI
首先,根据官方指南获取你的 OpenAI API Key。如果你已有密钥,可跳过此步。
拿到 OpenAI API Key 后,打开终端,将其设置为环境变量:
export OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"将 <YOUR_OPENAI_API_KEY> 替换为你的实际 OpenAI API Key。注意,上述命令只在当前终端会话中生效。或者,你也可以通过登录 ChatGPT 方案在终端授权。
然后运行以下命令,通过官方的 @openai/codex 包全局安装 OpenAI Codex CLI:
npm install -g @openai/codex在设置了 OPENAI_API_KEY 的同一个终端会话中,切换到你想要工作的文件夹,启动 Codex CLI:
codex你将被提示授予其对当前目录进行操作的权限:
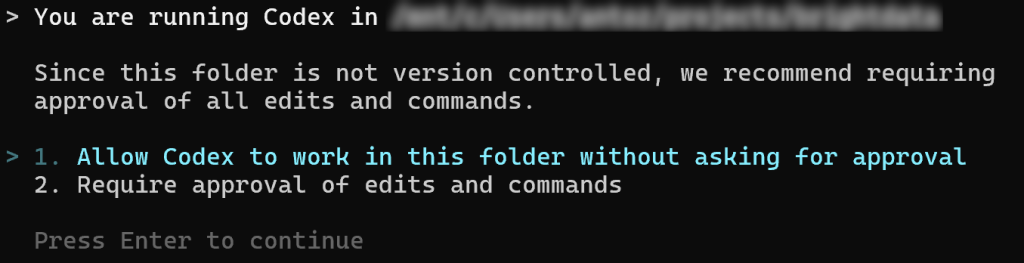
由于只是简单测试,你可以选择选项 1。出于更高的安全性,推荐选择选项 2。
按下 Enter 后,你应该会看到:
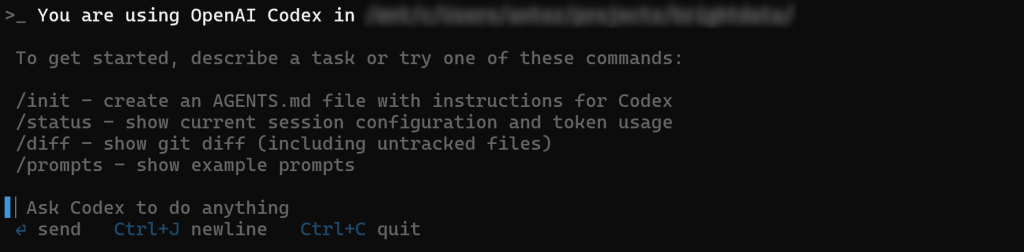
在 “Ask Codex to do anything” 区域中,你现在可以输入你的提示。默认情况下,Codex 将使用GPT-5 模型。如需更换底层 LLM,请参考官方文档。
完成!OpenAI Codex CLI 已安装并可使用。
步骤二:测试 Bright Data Web MCP Server
如果你还没有 Bright Data 账号,请注册 Bright Data。已有账号的直接登录。
接着,按照 Bright Data 官方文档获取你的 API Token。在本指南中,我们假定你使用的是具有 Admin 权限的 Token。
通过官方包 @brightdata/mcp 全局安装 Bright Data MCP 服务器:
npm install -g @brightdata/mcp用以下命令测试安装:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你之前生成的实际 API Token。上述命令会设置所需的 API_TOKEN 环境变量,并在本地启动 Bright Data MCP 服务器。
如果一切正常,你会看到类似这样的日志:

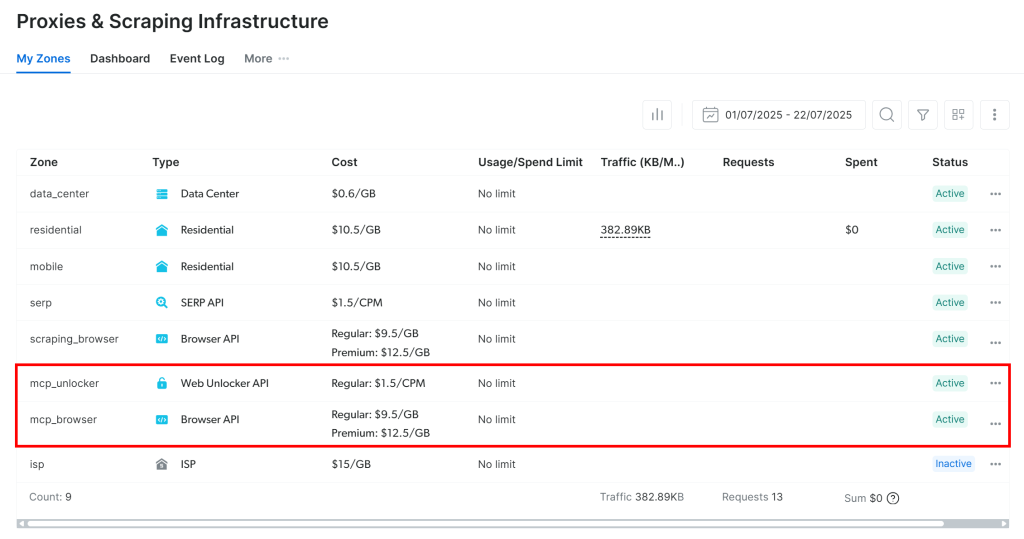
首次启动时,MCP 服务器会在你的 Bright Data 账号下自动创建两个默认代理 Zone:
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
这些 Zone 是 MCP 服务器为其全部工具提供能力所必需的。
要确认这些 Zone 已创建,请登录 Bright Data 控制台,进入“Proxies & Scraping Infrastructure”页面,你应能看到两个以 mcp_* 开头的 Zone:
如果你的 API Token 没有 Admin 权限,这些 Zone 不会自动创建。你需要手动创建,并通过环境变量设置它们的名称,具体可参考官方文档。
注意:默认情况下,MCP 服务器仅暴露 search_engine 与 scrape_as_markdown 工具。若要启用浏览器自动化与结构化数据提取的其他工具,你必须以专业模式运行 MCP 服务器。方法是:在启动前设置环境变量 PRO_MODE=true:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" PRO_MODE="true" npx -y @brightdata/mcp太棒了!你已成功确认 Bright Data MCP 服务器能在你的机器上正常工作。现在先停止该服务器,下一步我们会配置 OpenAI Codex CLI 让其自动启动 MCP 服务器。
步骤三:在 Codex 中配置 Bright Data Web MCP Server 连接
Codex 支持 MCP 集成,通过位于 ~/.codex/config.toml 的配置文件(~ 表示你的用户主目录)。该文件不会在安装时自动创建,因此你需要先创建它。
先创建 .codex 文件夹:
mkdir ~/.codex然后创建并编辑配置文件:
nano ~/.codex/config.toml在 nano 编辑器中,确保 config.toml 文件包含如下 mcp_servers 配置项:
[mcp_servers.brightData]
command = "npx"
args = ["-y", "@brightdata/mcp"]
env = { "API_TOKEN" = "<YOUR_BRIGHT_DATA_API_KEY>", "PRO_MODE" = "true" }按 CTRL + O 然后 Enter 写入文件,再按 CTRL + X 保存并退出(在 macOS 上使用 ⌘ Command 代替 CTRL)。
重要:将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你的实际 Bright Data API Token。
上述配置片段中的 [mcp_servers] 区域告诉 Codex 如何启动 Bright Data MCP 服务器。它明确了参数与环境变量,以生成与你之前测试相同的 npx 启动命令。请记住,启用 PRO_MODE 虽是可选,但推荐开启。
现在,OpenAI Codex CLI 将能够在后台使用该命令自动启动 MCP 服务器并连接到它。
很好!该测试集成的时刻到了。
步骤四:确认 MCP 服务器连接
如果 OpenAI Codex CLI 仍在运行,用 /quit 命令退出,然后重新启动:
codexCodex CLI 现在应能自动连接到 Bright Data MCP 服务器。
截至目前,Codex 尚未提供专门的命令来验证 MCP 服务器集成(不同于提供详细 MCP 连接信息的 Gemini CLI)。
不过,如果 Codex 未能连接到已配置的 MCP 服务器,它会显示类似这样的错误信息:
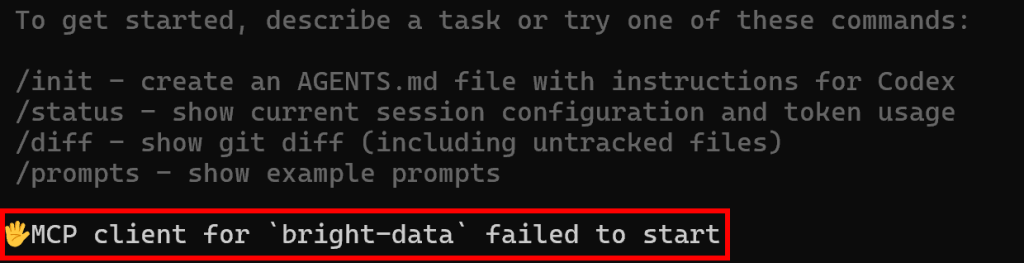
如果你没有看到此错误,即可默认 MCP 集成工作正常。干得好!
步骤五:在 Codex 中运行一个任务
既然 Codex 已连接到 Bright Data MCP 服务器,让我们用一个真实任务来试试。比如,在 OpenAI Codex CLI 中输入以下提示:
从如下亚马逊页面提取数据:"https://www.amazon.com/crocs-Unisex-Classic-Black-Women/dp/B0014BYHJE/"。将得到的 JSON 保存为本地文件 "product.json"。接着,构建一个 Node.js 的 "index.js" 脚本来读取并在控制台打印内容。这模拟了为分析、API Mock 或其他开发任务收集真实世界数据的实际用例。
将提示粘贴到 CLI 并按下 Enter。执行流程应类似于:
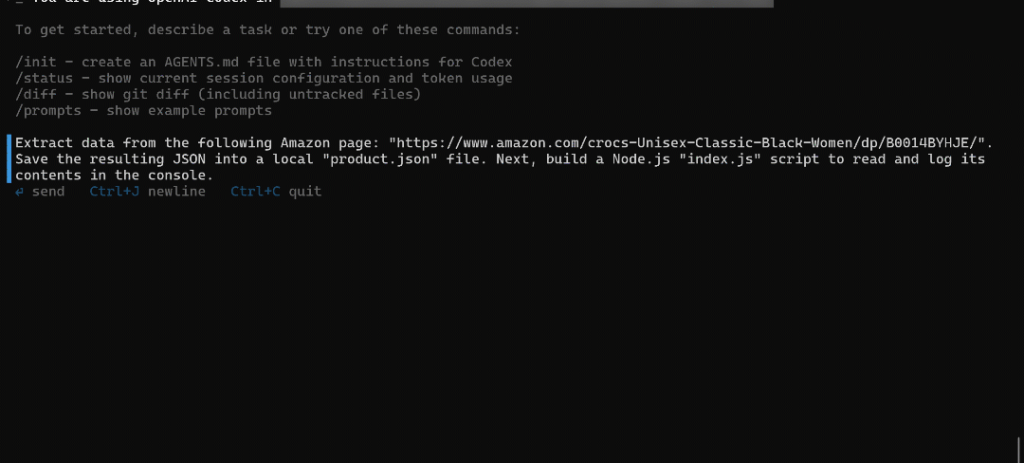
上方的 GIF 加快了速度,但实际过程如下:
- LLM 选择合适的 MCP 工具(本例为
web_data_amazon_product),并通过 MCP 服务器发起亚马逊抓取任务。 - CLI 定期检查抓取任务是否完成以及数据是否就绪。
- 完成后,工具返回的 JSON 格式原始商品数据会被展示。
- Codex 校验 JSON 以确保结构正确。
- 数据被保存到名为
product.json的本地文件。 - 系统会询问你是否添加更多字段到 JSON。回答“否”。
- Codex 生成一个 Node.js 脚本
index.js,用于从product.json加载并打印 JSON 内容。
在运行过程中,你会注意到类似这样的日志条目:

这确认了 CLI 按提示中的亚马逊商品 URL 调用了 Bright Data MCP 服务器的 web_data_amazon_product 工具。你看到的 JSON 是Bright Data 亚马逊爬虫在幕后被该工具调用后返回的结构化结果。
执行结束后,你的工作目录应包含以下两个文件:
├── product.json
└── index.js在 VS Code 中打开 product.json,你会看到:
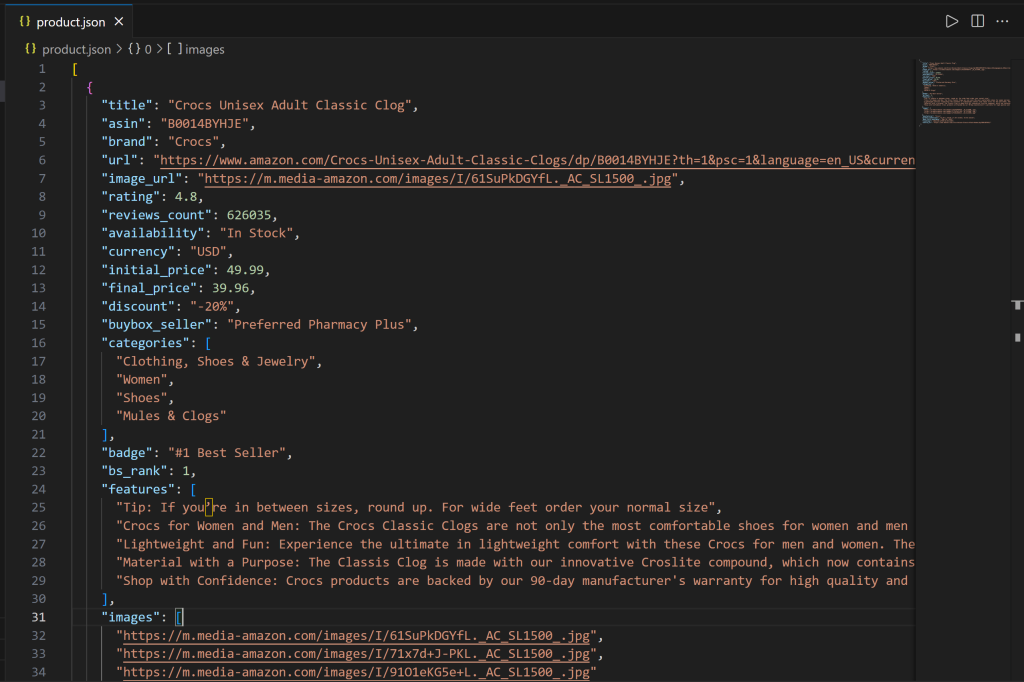
该文件包含通过 Bright Data MCP 集成从亚马逊提取的真实商品数据。
现在,打开 index.js:
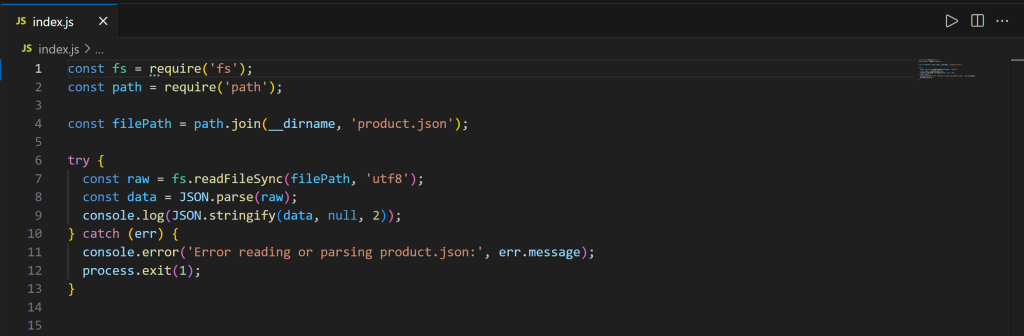
该脚本包含在 Node.js 中加载并打印 product.json 内容的 JavaScript 逻辑。
用以下命令执行 index.js:
node index.js结果应如下所示:
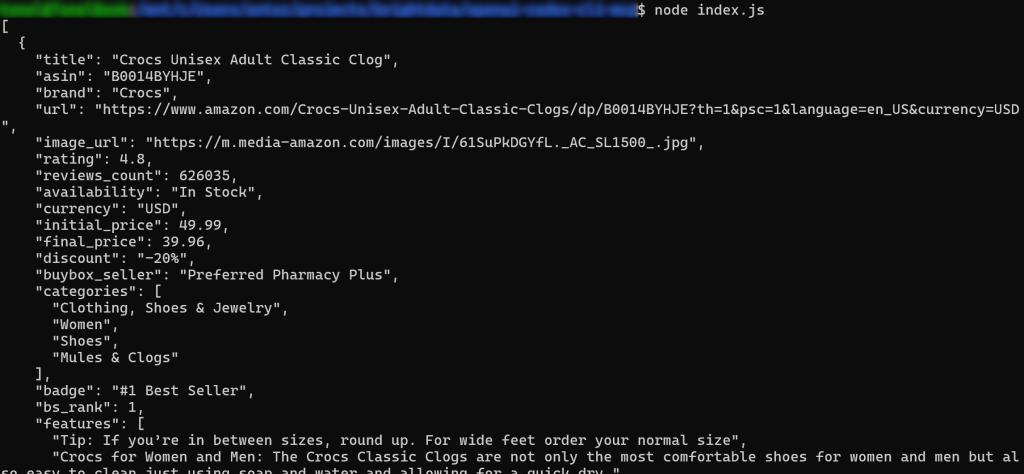
搞定!整个流程顺利完成。
重要:你看到的是实际抓取的数据,而非 AI 编造或幻觉的信息。具体而言,product.json 的内容与原始亚马逊商品页面上的数据一致:
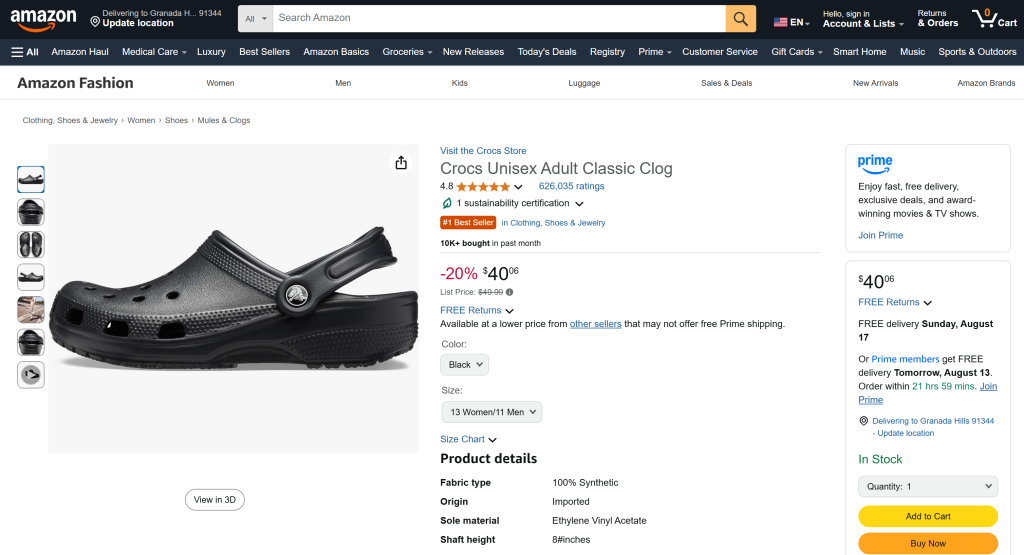
请记住,由于亚马逊的反爬措施(如 Amazon CAPTCHA),抓取亚马逊数据众所周知地困难。普通 LLM 无法直接访问亚马逊数据。这得益于 LLM 通过 MCP 获得的 Bright Data 能力。
由此可见,将 OpenAI Codex CLI 与 Bright Data 的 MCP 服务器相结合非常强大。现在,试试更多提示,探索更多由 LLM 驱动的高级数据工作流吧!
结语
本文介绍了如何将 OpenAI Codex CLI 与Web MCP 服务器集成,最终得到一个能够访问并交互网页的强大 AI 编码代理。
若要开发更复杂的 AI 代理,欢迎探索 Bright Data AI 基础设施的全套服务、产品与能力。这些方案可支持广泛的代理型场景。
创建一个 Bright Data 账号,开始使用 Web MCP,每月免费获得 5,000 次请求!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


