
将本地采集从 1,000 页扩展到 100,000 页,通常意味着更多服务器、代理与运维工作。目标站点会变得更难抓取。基础设施成本上升。团队花在修修补补爬虫上的时间,往往多于交付功能的时间。规模一旦上来,采集就不再只是脚本,而是基础设施。
在本地与云端采集之间做选择,会影响三件事:成本、可靠性和交付速度。
TL;DR
- 本地采集运行在你自己的机器上。你拥有完全控制权,但需要手动维护。
- 云端采集运行在远程基础设施上,具备自动扩缩容与内置的IP 轮换。
- 当你采集<1,000 页或数据受监管、仅可在内网使用时,选择本地采集。
- 当你采集10,000+ 页、目标站点容易封禁,或需要7×24 监控时,选择云端采集。
- IP 封禁是第一大瓶颈,68% 的团队将其视为主要挑战。
- 在大规模场景下,云端采集可通过消除 DevOps 开销将总成本最多降低 70%。
- Bright Data提供1.5 亿+ 住宅 IP、99.9% 在线率与零维护执行。
什么是本地采集?
本地采集意味着你拥有整个技术栈——代码、IP、浏览器,同时也要承担失败与宕机。你在自有基础设施上运行采集脚本,并自行管理全链路流程。
没有托管的基础设施层,因此一旦出问题,就需要你来修复。
本地采集如何工作
本地采集遵循一个简单的执行循环:脚本发送请求、接收响应,并从 HTML 或渲染后的页面中提取数据。
请求来源是你自己的 IP 地址,或你配置的代理。当站点封禁流量时,你需要手动轮换 IP 并重试请求。
静态页面用一个简单的 HTTP 客户端就足够,但对于JavaScript 很重的网站,你需要在本地运行无头浏览器先渲染内容,再进行提取。
除此之外,本地采集中你通常还需要手动处理验证码(CAPTCHA)以及其他反爬措施。
小规模时这套方式可行,但随着数据量增长,你最初的简单脚本会很快演变为复杂的基础设施系统,需要你持续运营与维护。
本地采集的优势
由于执行完全发生在你的环境内,本地采集适合你需要:
- 完全的执行控制:你可以管理请求时序、请求头、解析逻辑与存储。
- 不依赖第三方:无需外部基础设施或供应商即可运行采集。
- 保护敏感数据:数据留在你的网络内。
- 学习价值高:可以直接处理请求头、Cookie、限速与失败情况。
- 小任务启动成本低:在低量采集、且站点无强防护时,一段脚本加一台笔记本就够了。
本地采集的局限
随着数据量与可靠性要求提升,本地采集会越来越难以持续:
- 扩展性差:更高的吞吐需要购买更多服务器与带宽。
- IP 封禁:站点封禁流量后,你必须自行获取、轮换并替换代理。
- 验证码中断:手动解验证码会破坏自动化;自动解码服务会增加成本与延迟。
- JavaScript 重站点的浏览器执行:需要本地浏览器渲染,消耗大量 CPU 与内存。
- 持续维护:站点改版与检测策略更新会导致频繁修代码与重新部署。
- 可靠性脆弱:一旦失败,数据采集会停止,直到你介入处理。
示例:Python 本地采集
这是使用 Python 进行小规模本地采集的样子:
import requests
from bs4 import BeautifulSoup
def scrape_products(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
return [
{
"name": item.find("h3").text.strip(),
"price": item.find("span", class_="price").text.strip(),
}
for item in soup.select(".product-card")
]
products = scrape_products("https://example.com/products")这个脚本在本地运行,并使用你的真实 IP 地址。在没有防护的站点上,它可以轻松处理几百个页面。
但注意缺了什么——没有代理轮换、验证码处理、重试逻辑或监控。把这些能力补齐很容易让脚本膨胀,变得难以运行与维护。
什么是云端采集?
云端采集将执行移出你的应用边界。你向供应商的 API 发送请求,然后在响应中收到提取后的数据。供应商负责代理网络的运行以及所需的采集基础设施。
像 Bright Data 这样的平台会以生产级规模运营这套基础设施。
云端采集如何工作
云端采集遵循“请求—执行—响应”模型:
- 你通过供应商 API 提交采集请求。
- 供应商在远程基础设施上(而不是你的机器上)通过其代理网络转发请求。
- 当站点需要 JavaScript 时,请求会在托管浏览器中执行,渲染后的页面会在数据提取前被处理。
- 失败请求会按供应商定义的逻辑触发重试。
- 验证码挑战会在执行层被检测并解决。
- 你收到提取后的数据作为响应。
下面是云端采集工作方式的简化概览: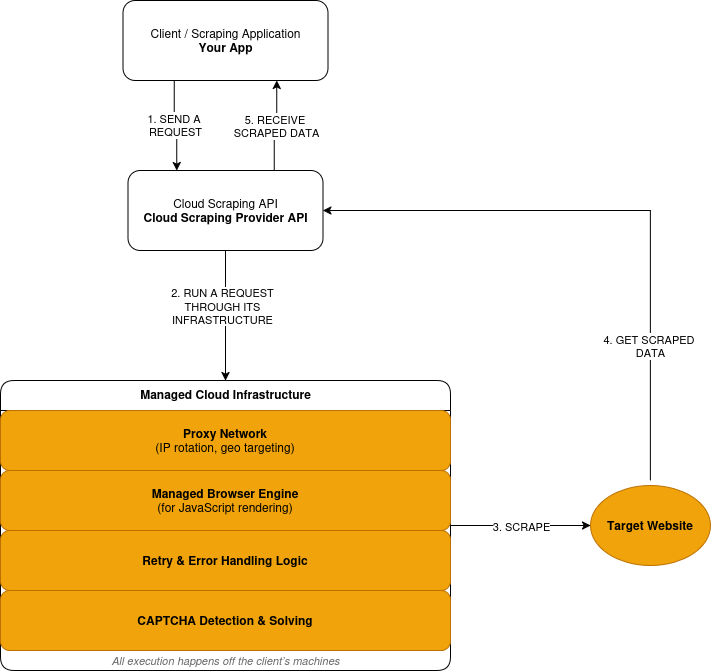
云端采集的优势
云端采集更偏向规模、可靠性与降低运维负担:
- 托管执行:请求在供应商运营的基础设施上运行。
- 内置可扩展性:规模增长无需你采购新服务器。
- 集成反爬处理:IP 轮换与重试自动发生。
- 包含浏览器基础设施:供应商负责 JavaScript 渲染。
- 维护范围更小:站点变化不再需要你频繁重部署。
- 按用量计费:价格与请求量相关。
云端采集的权衡
云端采集降低了运维负担,但引入外部依赖,一部分控制权移出你的应用边界。
- 底层控制减少:请求时序、IP 选择与重试策略遵循供应商逻辑。
- 第三方依赖:可用性与执行在你的系统之外。
- 成本随使用量增长:高并发/高规模会增加支出。
- 外部调试:失败排查需要供应商侧可见性与支持。
- 合规限制:某些数据不能离开受控环境。
示例:使用 Bright Data Web Unlocker 进行高并发采集
这是同一个采集任务通过云端执行层运行的示例。
import requests
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer API_KEY',
}
payload = {
'zone': 'web_unlocker1',
'url': 'https://example.com/products',
'format': 'json'
}乍看之下,它与本地采集示例类似:仍然是一次 HTTP 请求。区别在于请求在哪里执行。
使用 Bright Data Web Unlocker API 时,请求在托管基础设施上运行。IP 轮换、封禁检测与重试发生在你的应用之外。
云端采集 vs 本地采集:正面对比
下面对比本地与云端采集在真正影响项目的关键因素上的差异。
| 因素 | 本地采集 | 云端采集 | Bright Data 优势 |
|---|---|---|---|
| 基础设施 | 自建(DIY) | 完全托管 | 覆盖 195 个国家的全球网络 |
| 扩展性 | 有限 | 自动扩展至每月数十亿级 | 每月数十亿请求规模 |
| IP 封禁 | 高风险 | 自动轮换 | 1.5 亿+ 住宅 IP |
| 维护 | 手动 | 供应商托管 | 7×24 监控 |
| 成本模型 | 固定成本 + 隐性成本 | 按需付费 | 最高可降 70% 成本 |
| 反爬对抗 | 自建 | 内置 | 99.9% 验证码成功率 |
| 合规 | 自建 | 因供应商而异 | SOC2、GDPR、CCPA |
成本拆分:本地 vs 云端采集
本地采集看起来便宜,直到你把维持运行所需的一切都算进去。这里最大的成本不是服务器,而是工程师把时间花在维护采集系统上,而不是交付产品功能。
云端采集则把这些成本转移到按请求计费的价格里。
本地采集的成本构成
本地采集存在随时间累积的固定成本。
- 服务器:虚拟机、带宽、存储。
- 代理:住宅订阅。
- 验证码解答:第三方解码服务。
- 维护:修复与更新所需的工程时间。
- 宕机:失败期间丢失的数据。
无论你当月是否抓取,这些成本都存在。
云端采集的成本构成
云端采集采用与使用量绑定的可变计费。
- 请求:按请求或按页面计费。
- 渲染:执行 JavaScript 的成本更高。
- 数据传输:按带宽计费。
基础设施、代理与维护均已包含在内。
成本对比
| 成本因素 | 本地采集 | 云端采集 | Bright Data |
|---|---|---|---|
| 服务器容量 | 固定月成本 | 包含 | 包含 |
| 代理基础设施 | 单独订阅 | 包含 | 1.5 亿+ IP 池 |
| 验证码解答 | 单独服务 | 包含 | 包含 |
| 维护投入 | 持续工程时间 | 供应商托管 | 零维护 |
| 宕机影响 | 由你的团队承担 | 由供应商降低 | 99.9% 在线率 SLA |
真实世界成本示例
假设每月从有防护的网站采集500,000 页。
本地方案:
- 服务器与带宽:$300/月
- 住宅代理:$1,250/月
- 验证码解答:$150/月
- 工程维护:\$3,000/月
- 合计:$4,700/月
云端方案:
- 带渲染的请求:$1,500/月
- 数据传输:\$50/月
- 合计:$1,550/月
在该规模下,云端方案将月成本降低约 70%。
盈亏平衡点
- 低于5,000 页/月:本地通常更划算
- 在5,000–10,000 页之间:成本趋于接近
- 高于10,000 页:云端通常更便宜
超过这个点后,本地成本会线性上升;云端成本则随用量更可预测地扩展。
何时使用本地采集
当以下条件都成立时,本地采集是正确选择:
- 每次运行采集少于 1,000 页
- 目标站点反爬防护很弱
- 数据不能离开你的环境
- 你接受手动维护
- 采集不是业务关键
超出这些条件后,成本与风险会快速上升。
何时使用云端采集
当满足以下任一条件时,云端采集更合适:
- 月采集量超过10,000 页
- 站点部署了强硬的反爬保护
- 需要 JavaScript 渲染
- 数据需要持续更新
- 可靠性比执行控制更重要
到了这个阶段,基础设施自建会变成负担。
Bright Data 如何简化云端采集
Bright Data 定义了采集在哪里运行,以及你不再需要运营哪些层。它处理让采集“昂贵且难维护”的基础设施部分:
- 网络访问:通过托管代理基础设施进行请求路由
- 浏览器执行:为 JavaScript 重站点提供远程浏览器。
- 反爬缓解:IP 轮换、封禁检测与重试。
- 失败处理:执行控制与重试逻辑。
- 维护:随着站点与防护变化持续更新。
- 会话控制:跨请求保持粘性会话。
- 地理精度:可定位国家、城市、运营商或 ASN。
- 指纹管理:通过浏览器级指纹降低被检测概率。
- 流量控制:安全地限速、突发或分布式分摊负载。
执行路径与工具
Bright Data 根据你的需求,通过不同工具对外提供这些基础设施能力。
Scraping Browser API
当站点需要 JavaScript 渲染或类似用户的交互时,使用Scraping Browser。你现有的Selenium或Playwright逻辑将运行在 Bright Data 托管的浏览器上,而不是本地实例。
Bright Data 替代本地浏览器集群、生命周期管理与资源调优。
Web Unlocker API
当你需要对受保护站点进行基于 HTTP 的采集时,使用Web Unlocker。Bright Data 通过自适应代理基础设施路由请求,并应用内置的封禁处理。
这让你无需自行获取代理、轮换 IP 或在代码中编写重试逻辑。
Web Scraper APIs(预构建数据集)
当目标是标准化平台(如Amazon、Google、LinkedIn等)时,使用Web Scraper APIs。它提供150+ 预构建采集器,覆盖主要电商与社交媒体平台。
Bright Data 返回结构化数据,无需浏览器自动化或自定义解析器,从而消除常见数据源的站点特定维护。
从你的技术栈中消失的部分
使用 Bright Data 后,你不再需要运营:
- 代理池或 IP 轮换逻辑
- 本地或自管的浏览器集群
- 验证码解答服务
- 自定义重试与封禁检测代码
- 针对站点与检测变化的持续修复
这些运维成本在本地与 DIY 云方案里会快速累积。
Bright Data vs 其他云端采集工具
云端采集平台并非可互换。正确选择取决于采集量、目标站点防护强度,以及你愿意承担多少基础设施运营工作。
正面对比
| 供应商 | 规模 | IP 池 | 合规 | 最适合 |
|---|---|---|---|---|
| Bright Data | 企业级(数十亿级) | 1.5 亿+ | SOC2、GDPR、CCPA | 大规模生产环境 |
| ScrapingBee | 小–中 | 有限 | 部分 | 简单项目 |
| Octoparse | GUI 图形化 | 小规模池 | 有限 | 非技术用户 |
Bright Data 的适配场景
Bright Data 适用于采集持续运行且在运维上很重要的工作负载。
包括以下情况:
- 月采集量超过10,000 页
- 目标采用现代反爬防御
- 需要 JavaScript 渲染
- 数据要供下游系统或分析使用
- 采集失败会造成业务影响
在这些情况下,基础设施自建带来的成本与风险往往比 API 简洁性更关键。
何时其他工具已足够
更轻量的云工具在约束更低时可满足需求。
API 类服务适合:
- 小规模或周期性采集任务
- 防护较弱的网站
- 可以接受偶发失败的工作负载
GUI 工具适合:
- 非技术用户
- 一次性或手动数据采集
- 探索性或临时任务
这些工具降低了配置门槛,但在大规模场景下无法消除运维限制。
如何选择
决策逻辑与前面的成本与用量阈值一致:
- 如果采集规模小、不频繁或不关键,更简单的工具通常就够了
- 如果采集持续进行、目标站点强防护或业务关键,托管基础设施更重要
结论
从本地采集开始学习。在自己的机器上运行爬虫能帮助你理解请求、解析与失败机制。对于少于 1,000 页的小任务,这种方式通常足够。
当规模或防护改变了成本方程时,就该转向云端采集。一旦量超过每月 10,000 页、目标启用现代反爬防御,或数据需要持续更新,基础设施自建就会成为瓶颈。
本地采集带来控制权,也带来责任。云端采集用一部分控制权换取可预测执行、更低运维风险与可扩展成本。
对于生产级工作负载,云端采集就是基础设施。你不会在大规模情况下自建 CDN 或邮件服务器;采集基础设施也遵循同样逻辑。
如果你的用例符合这个画像,像Bright Data这样的平台可以让你保留提取逻辑,同时把执行与维护移出你的技术栈。
常见问题:云端采集 vs 本地采集
什么是本地采集?
本地采集运行在你可控的机器上。你需要自己管理请求、代理、浏览器、重试与失败处理。它最适合在防护较弱的网站上执行小规模、低频任务。
什么是云端采集?
云端采集运行在第三方运营的基础设施上。你向 API 发送请求并在响应中获得提取数据。采集服务商负责执行、扩展、IP 轮换、验证码解答、绕过反爬措施等更多能力。
我应该何时从本地切换到云端采集?
当出现以下任一情况时就该切换:
- 在较小请求量后就出现 IP 封禁
- 验证码打断自动化
- 月采集量超过10,000 页
- 开始必须做 JavaScript 渲染
- 采集失败影响下游系统
此时,基础设施自建会变成负担。
云端采集比本地采集更贵吗?
本地方案会累积服务器、代理、维护与宕机等成本。云端按用量计费,并移除固定基础设施开销。
- 小规模时,本地采集通常更便宜
- 规模上来后,云端采集通常更省
云端采集能处理 JavaScript 很重的网站吗?
可以。云平台会运营托管浏览器,在远程执行 JavaScript。
本地采集则需要你自己运行无头浏览器,这会限制并发并增加维护成本。
云端采集如何降低 IP 封禁?
云端供应商运营大型代理网络并管理请求路由。IP 轮换与重试逻辑在基础设施层完成。
云端采集适合敏感或受监管数据吗?
不一定。有些工作负载因政策或监管要求,数据不能离开受控环境。但 Bright Data 提供完全SOC2、GDPR 和 CCPA 合规的采集解决方案。
我可以混合使用本地与云端采集吗?
可以,但复杂度会增加。
一些团队会在本地开发与测试爬虫,然后在云端跑生产任务。这需要维护两套执行环境,并处理它们之间的差异。
大多数团队会基于核心约束选择一种主要方案。
哪些团队最适合使用 Bright Data 这类云端采集平台?
把采集作为持续运行或业务关键系统的团队。包括高规模、目标强防护、需要 JavaScript 渲染,或工程带宽有限的工作负载。







