

在本指南中,您将看到以下内容:
- 什么是 JavaScript 密集型网站
- 挑战和通过浏览器渲染进行抓取的方法。
- AJAX 调用拦截的工作原理及其局限性。
- 抓取 JavaScript 繁重网站的现代解决方案。
让我们深入了解一下!
什么是 JavaScript 密集型网站?
在网络抓取领域,当要收集的数据不在服务器返回的初始 HTML 文档中时,该网站就属于 “重 JavaScript “网站。相反,实际内容是通过 JavaScript 在用户浏览器中动态获取和呈现的。
网站如何使用 JavaScript 会直接影响到提取数据的步骤。通常,基于 JavaScript 的网站遵循以下三种主要模式:
- 单页面应用程序(SPA):SPA是一个网页,它依靠 JavaScript 从服务器更新特定部分的新内容。换句话说,整个网络应用程序只是一个单一的网页,不会在每次用户交互时重新加载。
- 用户驱动交互:只有在执行特定操作后,内容才会出现。例如 “加载更多 “按钮和动态分页。
- 异步数据:许多网站为了提高速度,会先加载基本的页面布局,然后使用AJAX进行后台调用以获取数据。这种机制常用于实时更新,如刷新股票价格而无需重新加载页面。
通过全浏览器渲染技术抓取 JavaScript 繁重网站
浏览器自动化工具可让你编写脚本来启动和控制网络浏览器。这样,它们就能执行完全呈现页面所需的 JavaScript。然后,您就可以使用这些工具提供的 HTML 元素选择和数据提取 API 来获取所需的数据。
这是对 JavaScript 负载较重的网站进行抓取的基本方法,我们将在下文中加以介绍:
- 自动化工具如何工作
- 什么是 “无头 “模式和 “满头 “模式?
- 这种方法的挑战和解决方案。
- 最常用的浏览器自动化工具
自动化工具如何工作
浏览器自动化工具通过使用协议(如CDP或 BiDi)直接向浏览器发送命令。简单地说,这些工具提供了一个完整的应用程序接口,用于发出 “导航到此 URL”、”找到此元素 “和 “点击此按钮 “等命令。
浏览器会在页面上运行这些命令,执行抓取脚本中描述的交互所需的 JavaScript。浏览器自动化工具还可以访问渲染的 DOM(文档对象模型)。这就是您可以找到要抓取的数据的地方。
无头浏览器与 “有头 “浏览器
在自动运行浏览器时,您需要决定其运行方式。通常,您可以在两种模式中进行选择:
- 头头是道:浏览器以完整的图形界面启动,就像人类用户打开浏览器一样。你可以在屏幕上看到浏览器窗口,并实时观看脚本的点击、键入和导航。这有助于直观地确认脚本是否按预期运行。对于反僵尸系统来说,它还能让你的自动化看起来更像真实的用户活动。另一方面,运行带有图形用户界面的浏览器需要耗费大量资源(我们都知道浏览器有多耗费内存),这会减慢网络搜索的速度。
- 无头:浏览器在后台运行,没有可见界面。它使用的系统资源更少,速度更快。这是生产型抓取程序的标准,尤其是在服务器上运行数百个并行实例时。缺点是,如果配置不慎,无图形用户界面浏览器可能会显得可疑。了解市场上最好的无头浏览器。
浏览器渲染的挑战和解决方案
自动运行浏览器只是处理 JavaScript 繁重网站的第一步。在抓取此类网站时,您将不可避免地面临两大类挑战,包括: 1:
- 复杂的导航:扫描脚本必须不仅仅是命令执行器。您需要对它们进行编程,以处理整个用户旅程。这就意味着要编写代码来抓取复杂的导航流,例如等待新内容加载和处理无限滚动。对 JavaScript 繁重的网站进行扫描包括处理多页面表单、下拉菜单等。
- 躲避反僵尸系统:如果应用不当,浏览器自动化就会成为反僵尸系统可以检测到的红旗。要在使用浏览器自动化工具进行抓取的情况下取得成功,您的抓取程序必须通过应对以下挑战,在某种程度上显得像人一样:
- 浏览器指纹识别:反僵尸软件会分析来自客户端浏览器的数百个数据点,从而创建一个独一无二的签名。其中包括用户代理字符串、屏幕分辨率、安装的字体、WebGL 渲染能力等。显然,默认的自动化设置很容易识别。设置非无头 User-Agent 是一个很好的提示。您可能还需要专门的工具,如undetected-chromedriver,它可以修改多个浏览器选项,使其看起来像普通用户的浏览器。
- 行为分析:反僵尸程序还会观察抓取程序是如何与页面交互的。在页面加载 5 毫秒后点击按钮的脚本显然不是人类。如果这种行为被标记为机器人行为,防御系统就会封杀你。
- 验证码 验证码通常是基于浏览器自动化的抓取方法的终极障碍。这是因为标准自动化脚本无法自主解决这些问题。要克服这一问题,需要集成验证码解决服务。
如需更多指导,请参阅我们的动态网站搜索指南。
顶级浏览器自动化框架
浏览器自动化的三大主流框架是
- Playwright:这是微软推出的一款现代框架。它从头开始设计,旨在处理现代网站的复杂性。这使它成为新的抓取项目的首选。它有 JavaScript、Python、C# 和 Java 版本,社区还提供其他语言支持。因此,对于大多数开发人员来说,使用 Playwright 进行网页抓取是一个不错的选择。
- Selenium:它是网络自动化领域的开源巨人。它的最大优势在于其多功能性。特别是,它支持几乎所有的编程语言和浏览器,并拥有一个广泛而成熟的生态系统。这就是Selenium 在很大程度上被用作浏览器自动化工具的原因。
- Puppeteer:这是一个由 Google 开发的库,通过 CDP(Chrome DevTools Protocol,Chrome 开发工具协议)对 Chrome 浏览器和基于 Chromium 的浏览器进行细粒度控制。它现在还支持火狐浏览器。有了这个库,你就可以在受控浏览器中模拟用户行为,以普通用户的身份出现。这使得Puppeteer 广泛应用于网络搜索。
请参阅我们关于最佳浏览器自动化工具的资料库,了解这些解决方案(以及其他解决方案)的比较情况。
替代方法复制 AJAX 调用
与其承担在浏览器中渲染整个可视化网页的成本,还不如采取侦探的方法。取而代之的是识别网站前端对后端的直接 API 调用,并自行复制。
这些 API 调用通常会返回网站随后在页面上渲染的原始数据,因此你可以直接瞄准它们。这种技术依赖于模仿 AJAX 调用,通常被称为API 网络抓取。
让我们看看它是如何工作的!
AJAX 调用复制方法的工作原理
AJAX 复制是一种实用的搜索技术。其核心思想是通过模仿网络应用程序从其后台获取数据的网络请求(通常是 AJAX 调用)来绕过整个页面的渲染。
在高层次上,这涉及两个主要步骤:
- 窥探:打开浏览器的开发工具(通常是启用了 “Fetch/XHR “过滤器的 “网络 “选项卡)并与网站交互。观察新数据加载时后台会调用哪些 API。例如,在无限滚动或点击 “加载更多 “按钮时。
- 重放:确定正确的 API 请求后,记下其 URL、HTTP 方法(GET、POST 等)、标头和有效载荷(如果有)。然后使用类似Python 中的 Requests 这样的 HTTP 客户端在你的抓取脚本中复制这个请求。
这些 API 端点通常以结构化格式(最常见的是 JSON)返回数据。这是一个巨大的优势,因为您可以访问 JSON 数据,而无需解析 HTML 的额外麻烦。
例如,请看一个使用无限滚动来加载更多数据的网站所调用的 API:
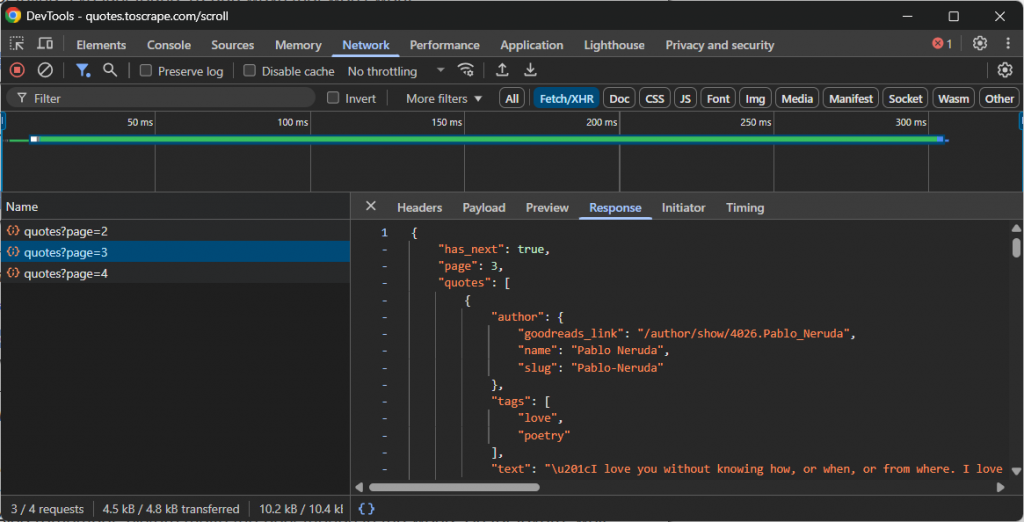
在这种情况下,您可以编写一个简单的抓取脚本,复制上述无限滚动 API 调用,然后访问数据。
拦截 AJAX 调用时的主要挑战
当它发挥作用时,这种方法是快速、有效和简单的。不过,它也有一些挑战:
- 混淆有效载荷:应用程序接口可能需要加密的有效载荷,或者不返回干净、可读的 JSON。可能是特定 JavaScript 函数知道如何解码的加密字符串。这是一种需要逆向工程的反抓取措施。
- 动态端点和标头:应用程序接口端点和调用方式(例如,设置适当的标头、添加正确的有效载荷等)会随着时间的推移而改变。这种解决方案面临的主要挑战是,API 的任何变化都会破坏搜索器。这就需要对代码进行维护以恢复功能,而这是大多数(但不是全部,我们即将看到)网络抓取方法的共同问题。
- TLS 指纹识别:最先进的反僵尸程序会分析 “TLS 握手”,这是程序的数字签名。它们可以轻松区分来自 Chrome 浏览器的请求和来自标准 Python 脚本的请求。要绕过这一点,你需要专门的工具来冒充浏览器的 TLS 签名。
一种扫描 JavaScript 繁重网站的现代方法:人工智能驱动的浏览器抓取代理
迄今为止介绍的方法仍面临重大挑战。要为大量使用 JavaScript 的网站提供更现代化的抓取解决方案,就必须转变模式。我们的想法是从编写命令式命令转向使用人工智能驱动的浏览器代理来定义声明式目标。
代理浏览器是一种集成了 LLM 的浏览器,能够理解页面内容、上下文和可视化布局。这从根本上改变了我们的网络抓取方法,尤其是对于 JavaScript 较多的网站。
这些网站通常需要复杂的用户交互才能加载所需的数据。传统上,您必须在脚本中注入逻辑来复制这些交互。这种方法本身就很脆弱,维护工作也很繁重。问题在于,每次用户流发生变化时,您都需要手动更新自动化逻辑。
有了人工智能驱动的浏览器代理,您就可以避免这一切。即使网站的用户界面或流程发生变化,一个简单的描述性提示也能驱动有效的自动化。这种灵活性是一个巨大的优势,并为许多其他自动化可能性打开了大门,这也是代理人工智能迅速获得认可的原因。
现在,无论你的人工智能浏览器代理库多么强大,你的抓取逻辑仍然依赖于普通浏览器。这意味着您仍然容易受到浏览器指纹和验证码等问题的影响。由于速率限制和 IP 禁止,扩展此类解决方案也变得十分困难。
真正的解决方案是一个基于云的人工智能就绪搜索平台,该平台可与任何代理库集成,并可避免被拦截。这正是Bright Data 的代理浏览器所能提供的。
Agent Browser 可以让你在远程浏览器上运行人工智能驱动的工作流,而且永远不会被阻止。它可无限扩展,支持无头和有头模式,并由全球最可靠的代理网络提供支持。
结论
在本文中,您将了解到什么是 JavaScript 密集型网站,以及从这些网站中抓取数据的常见挑战和解决方案。所述的每种实现方法都有其局限性,但其中最突出的是使用代理浏览器。
如上文所述,Bright Data 的代理浏览器允许您解决所有常见的抓取问题,同时与最流行的代理人工智能库集成。
如果您使用高级人工智能搜索代理,您需要可靠的工具来检索、验证和转换网络内容。要获得所有这些功能以及更多,请探索Bright Data 的人工智能基础架构。
创建Bright Data帐户,试用我们为人工智能代理开发提供的所有产品和服务!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





