

在本指南中,您将学习:
- 什么是 Undetected ChromeDriver,以及它为何有用
- 它如何最大程度地降低被反爬虫系统检测
- 如何在 Python 中使用它进行网页爬取
- 进阶用法和方法
- 它的主要局限性和缺点
- 相似技术
让我们开始吧!
什么是 Undetected ChromeDriver?
Undetected ChromeDriver 是一个 Python 库,为 Selenium 的 ChromeDriver 提供了一个优化版本。该版本经过了补丁修改,以尽量避免被类似以下服务的反爬虫系统检测:
- Imperva
- DataDome
- Distil Networks
它也有助于绕过部分 Cloudflare 防护,尽管这更具挑战性。要了解更多,请阅读我们关于 如何绕过 Cloudflare的指南。
如果您曾使用过 Selenium 等浏览器自动化工具,您就会知道它们允许您以编程的方式控制浏览器。为实现这一点,它们会以不同于普通用户的方式配置浏览器。
反爬虫系统会查找这些差异,也就是所谓的“泄露信息”,由此识别自动化的浏览器机器人。Undetected ChromeDriver 对 Chrome 驱动进行补丁处理来最大程度地减少这些特征,从而降低被检测到的可能性。对于有 反爬虫措施的网站来说,这非常理想!
工作原理
Undetected ChromeDriver 通过以下技术减少来自 Cloudflare、Imperva、DataDome 以及类似解决方案的检测:
- 重命名 Selenium 变量,使其更像真实浏览器使用的名称
- 使用真实、合法的 User-Agent 字符串避免被检测
- 允许用户模拟自然的人类交互
- 在访问网站时正确管理 Cookie 和会话
- 启用使用代理服务器来绕过 IP 封锁并防止请求速率限制
这些方法可以使该库所控制的浏览器更有效地绕过各种反爬虫防护。
使用 Undetected ChromeDriver 进行网页爬取:分步指南
大部分网站使用高级反爬虫措施来阻止脚本自动访问页面。这些机制也同样能有效拦截 爬虫机器人。
例如,假设您想从以下 GoDaddy 产品页面中抓取标题和描述:
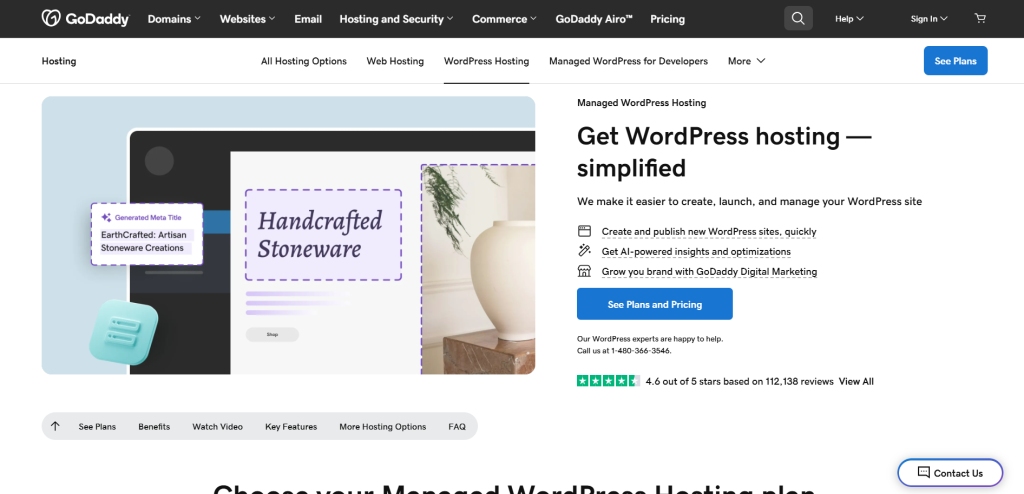
如果使用 Python 中的普通 Selenium,您的爬虫脚本大致如下:
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# configure a Chrome instance to start in headless mode
options = Options()
options.add_argument("--headless")
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service(), options=options)
# connect to the target page
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# scraping logic...
# close the browser
driver.quit()如果您对这段逻辑不熟悉,可以先阅读我们关于 Selenium 爬取网页的指南。
当您运行脚本时,它会因为这条错误页面而失败:
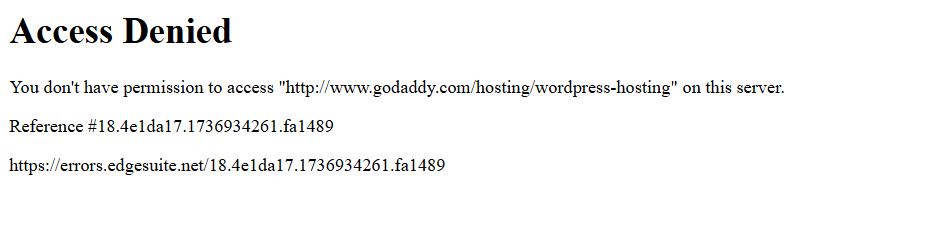
换言之,Selenium 脚本被一个反爬虫(本例中是 Akamai)拦截了。
那么,如何绕过它呢?答案就是 Undetected ChromeDriver!
按照下列步骤学习如何使用 undetected_chromedriver Python 库进行网页爬取。
步骤 #1:环境需求与项目设置
Undetected ChromeDriver 有以下先决条件:
- 最新版 Chrome 浏览器
- Python 3.6+:如果您的机器尚未安装 Python 3.6 或更高版本,请从官方站点下载安装并按照说明执行安装。
注意:该库会自动下载并为您打补丁 Chrome 驱动程序,因此无需手动下载 ChromeDriver。
现在,使用以下命令为您的项目创建一个目录:
mkdir undetected-chromedriver-scraperundetected-chromedriver-scraper 目录将作为 Python 爬虫的项目文件夹。
进入该目录并初始化一个 虚拟环境:
cd undetected-chromedriver-scraper
python -m venv env在您喜欢的 Python IDE 中打开该项目文件夹。建议使用 安装了 Python 插件的 Visual Studio Code或 PyCharm Community Edition。
接下来,在项目文件夹中创建一个 scraper.py 文件,结构如下图所示:
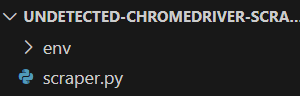
目前,scraper.py 是空的。稍后,我们会在其中添加爬取逻辑。
在 IDE 的终端中激活虚拟环境。Linux 或 macOS 上使用:
./env/bin/activate在 Windows 上则使用:
env/Scripts/activate太好了!现在您有了一个可供浏览器自动化进行网页爬取的 Python 环境。
步骤 #2:安装 Undetected ChromeDriver
在激活的虚拟环境中,通过 undetected_chromedriver pip 包安装 Undetected ChromeDriver:
pip install undetected_chromedriver该库会在后台自动安装 Selenium,因为这是它的依赖项之一。因此不需要单独安装 Selenium。这也意味着您可以默认使用所有 selenium 的导入。
步骤 #3:初始设置
导入 undetected_chromedriver:
import undetected_chromedriver as uc然后可以这样初始化一个 Chrome WebDriver:
driver = uc.Chrome()与 Selenium 一样,这会打开一个您可以用 Selenium API 控制的浏览器窗口。也就是说,driver 对象暴露了所有标准的 Selenium 方法,同时还有一些附加的功能(我们稍后会进一步探讨)。
主要区别在于,这个 Chrome 驱动已经过补丁,从而帮助绕过部分反爬虫解决方案。
要关闭驱动,只需调用 quit() 方法:
driver.quit()下面展示了一个基础的 Undetected ChromeDriver 设置:
import undetected_chromedriver as uc
# Initialize a Chrome instance
driver = uc.Chrome()
# Scraping logic...
# Close the browser and release its resources
driver.quit()很好!您现在可以在浏览器中直接执行网页爬取。
步骤 #4:将其用于网页爬取
警告:本节与标准 Selenium 配置步骤相同。如果您已经熟悉使用 Selenium 进行爬取,可直接跳到下一节查看完整代码。
首先,使用 get() 方法让浏览器访问目标页面:
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")接着,在您的浏览器中以无痕模式打开该页面,并检查您想要爬取的元素:
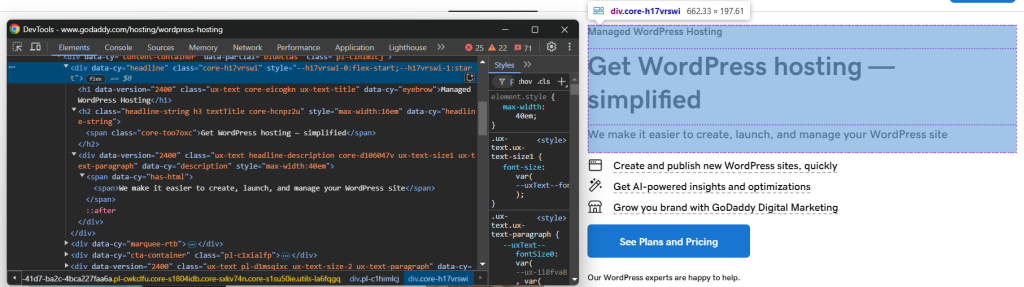
假设您想提取产品标题、标语和描述。
可以使用如下代码进行爬取:
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text为了让上面的代码能运行,需要从 Selenium 中导入 By:
from selenium.webdriver.common.by import By然后,将爬取到的数据存储在一个 Python 字典中:
product = {
"title": title,
"tagline": tagline,
"description": description
}最后,将数据导出为 JSON 文件:
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)记得从 Python 标准库导入 json:
import json好了,这就是一个基础的 Undetected ChromeDriver 网页爬取逻辑。
步骤 #5:整合所有内容
下面是完整的爬取脚本:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Create a Chrome web driver instance
driver = uc.Chrome()
# Connect to the target page
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# Scraping logic
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
# Populate a dictionary with the scraped data
product = {
"title": title,
"tagline": tagline,
"description": description
}
# Export the scraped data to JSON
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
# Close the browser and release its resources
driver.quit() 使用以下命令执行该脚本:
python3 scraper.py或在 Windows 上:
python scraper.py这会打开一个浏览器并显示目标页面,不会像原始的 Selenium 那样出现错误页面:
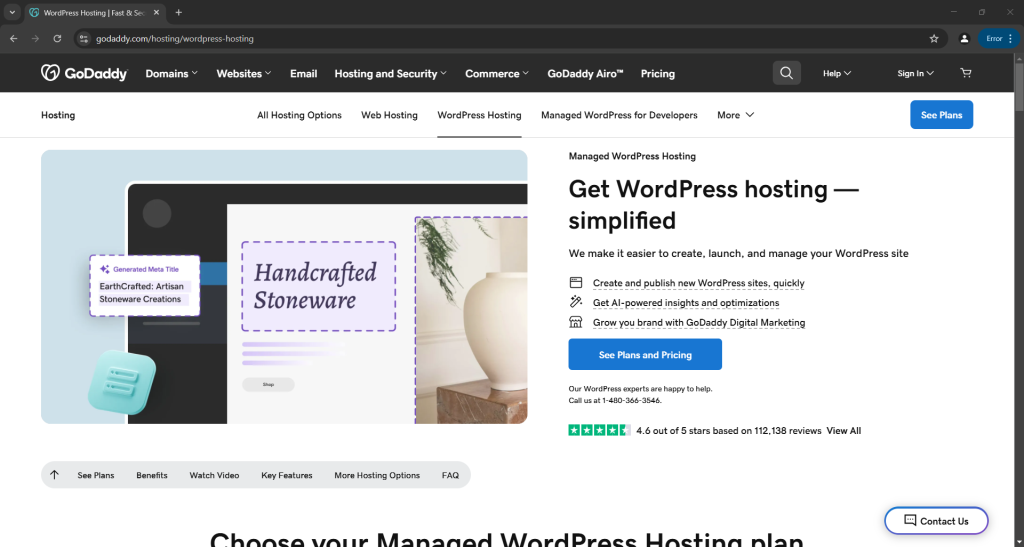
脚本会从页面中提取数据并生成如下的 product.json 文件:
{
"title": "Managed WordPress Hosting",
"tagline": "Get WordPress hosting — simplified",
"description": "We make it easier to create, launch, and manage your WordPress site"
}undetected_chromedriver:进阶用法
现在您已经了解了该库的工作原理,可以继续探索更多高级场景。
选择特定的 Chrome 版本
可以通过设置 version_main 参数来指定要使用的 Chrome 版本:
import undetected_chromedriver as uc
# Specify the target version of Chrome
driver = uc.Chrome(version_main=105)请注意,该库也可在其他基于 Chromium 的浏览器上使用,但需要进行一些额外的调整。
使用 with 语法
如果您不想在使用完驱动后手动调用 quit() 方法,可以使用 with 语法,如下所示:
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("<YOUR_URL>")当 with 代码块中的逻辑执行完后,Python 会自动为您关闭浏览器。
注意:此语法在 3.1.0 版本及以上才受支持。
代理集成
在 Undetected ChromeDriver 中使用代理的方式与普通 Selenium 类似。只需将代理 URL 传给 --proxy-server 参数:
import undetected_chromedriver as uc
proxy_url = "<YOUR_PROXY_URL>"
options = uc.ChromeOptions()
options.add_argument(f"--proxy-server={proxy}")注意:通过 --proxy-server 标志用于 Chrome 的代理不支持身份验证。
扩展的 API
undetected_chromedriver 在常规的 Selenium 功能之上增加了一些方法,包括:
WebElement.click_safe():如果点击链接会触发检测,可试试这个方法。虽然无法保证一定成功,但提供了一个更安全的点击方式。WebElement.children(tag=None, recursive=False):这个方法可帮助您更加轻松地寻找子元素,例如:
# 获取 body 内的第六个子元素(任意标签),然后递归查找所有 <img> 子元素
images = body.children()[6].children("img", True)
undetected_chromedriver Python 库的局限性
尽管 undetected_chromedriver 非常强大,但仍存在一些需要注意的局限性。以下是最重要的几点:
IP 封锁
该库的 GitHub 页面对这一点写得很明确:该包并不会隐藏您的 IP 地址。因此,如果您在数据中心运行脚本,仍然很容易受到检测;同样,如果您的家庭 IP 信誉较差,也可能被封锁!

若要隐藏您的 IP,需要将被控浏览器与代理服务器集成,就像之前演示的那样。
不支持 GUI 手动导航
由于该模块的内部工作原理,您必须通过编程方式使用 get() 方法进行浏览。避免在浏览器中手动输入来导航——使用键盘或鼠标与页面交互会增大被检测的风险!
同理,若需要处理新标签页,也请使用 URL data:,(包括逗号) 来打开一个空白标签页,然后再进行自动化操作。
只有遵守这些要点,才能最大限度减少检测风险,从而更顺利地进行网页爬取。
对无头模式的有限支持
官方并未完全支持 undetected_chromedriver 的无头模式。不过,您可以尝试如下方式:
driver = uc.Chrome(headless=True)该库作者在 3.4.5 版本的更新日志中提到,无头模式应该可以正常工作并提供一定的反检测能力。然而,这个功能仍不十分稳定。使用时需谨慎,并做充分测试以确定能满足您的爬取需求。
稳定性问题
正如该包在 PyPI 上的说明,由于众多因素,结果可能会有所差异。没有任何保证,只能说作者会不断研究并对抗检测算法。
这意味着脚本今天能成功绕过 Distil、Cloudflare、Imperva、DataDome 或 hCaptcha,不代表明天也能成功,因为这些反爬虫系统也会更新:
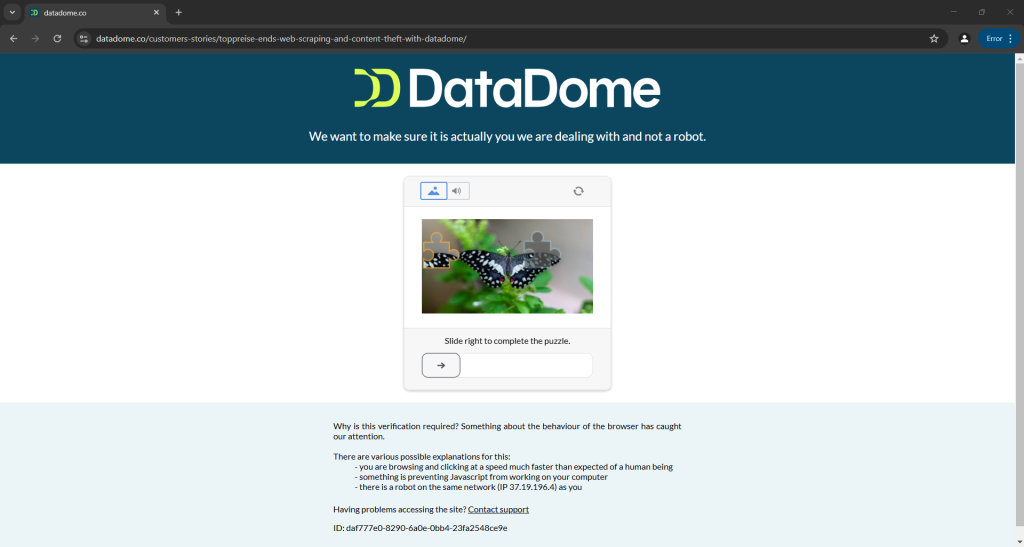
上图是官方文档中出现的脚本运行结果,可见即便是由开发者提供的脚本,也有可能无法按预期工作。具体而言,脚本触发了 CAPTCHA,轻易就会阻止您的自动化流程。
想了解更多,请参阅我们的指南 如何在 Python 中绕过 CAPTCHA。
延伸阅读
Undetected ChromeDriver 并不是唯一一个通过修改浏览器驱动来防止检测的库。如果您想了解相似工具,或想更深入地了解这一主题,可以阅读以下文章:
结论
本文介绍了如何使用 Undetected ChromeDriver 来应对 Selenium 中的反爬虫检测。该库提供了一个打过补丁的 ChromeDriver,用于在网页爬取时尽量不被阻止。
问题在于,像 Cloudflare 这样更先进的反爬虫技术依然可以检测并阻止您的脚本。undetected_chromedriver 等库并不稳定——它今天能工作,但明天可能就不行了。
真正的问题并不在于 Selenium 的 API,而在于浏览器本身的各种配置。这说明更好的方案是一种云端的、实时更新的、可扩容的浏览器,具有内置的反爬虫绕过功能。这款浏览器已经存在,它叫 抓取浏览器!
Bright Data 的 Scraping Browser 是一个高度可扩展的云端浏览器,可与 Selenium、Puppeteer、Playwright 等工具搭配使用。它可以自动处理浏览器指纹、CAPTCHA 识别以及自动重试。此外,它会在每次请求时自动切换出口 IP,这得益于其包含以下类型的全球代理网络:
现在就创建一个免费的 Bright Data 账户,试用我们的 Scraping Browser 或测试我们的代理服务吧。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


