

在本文中,你将了解:
- Pica MCP 服务器是什么,以及它暴露的工具。
- 它与其他可用的 MCP 服务器有何不同。
- 如何在 Claude Desktop 中将其作为工具供 AI 代理使用,以访问 Bright Data 服务。
一起开始吧!
什么是 Pica MCP?
Pica 最近宣布发布专用的 MCP 服务器。如果你还不熟悉该方案,请阅读我们关于如何在 Pica AI 代理中集成 Bright Data的文章,以更好地理解它是什么、能做什么以及如何工作。
具体而言,Pica MCP Server 通过标准化接口,打开了与众多第三方服务无缝交互的大门。它提供对平台集成、动作、执行能力以及强大的代码生成特性的直接访问。
截至撰文时,开源 Pica MCP 服务器暴露的可用工具包括:
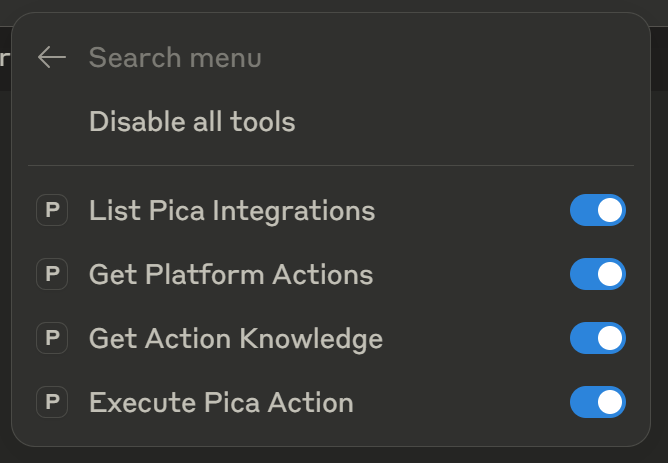
list_pica_integrations:列出所有可用平台以及你已激活的连接。get_pica_platform_actions:获取某个平台可用的动作列表。get_pica_action_knowledge:提供某个动作的详细文档,包括参数和用法。execute_pica_action:以完整参数支持执行 API 动作。
Pica MCP 的独特之处
与其他 MCP 服务器相比,Pica MCP 的优势来自其平台本身的特性。通常,如果你希望 AI 代理通过 MCP 连接到不同供应商的工具,你需要分别在本地安装并配置每个 MCP 服务器,或远程连接它们。这个过程既繁琐又耗时。
而 Pica MCP 为你集中处理了一切。得益于 Pica 的集成能力,你可以通过自己的 Pica 账户连接 100+ 平台(包括 Bright Data),然后通过 MCP 服务器将这些连接暴露给你的代理。
这意味着单个 Pica MCP 服务器就能为每个代理提供多个第三方工具连接。此外,一旦你在代理中配置好 MCP,就可以直接通过 Pica 控制台管理你的集成和工具,无需改动代码。这些集成会通过 Pica MCP 自动对底层代理可用。
另一个优势是你只需在 MCP 配置中暴露 Pica API 密钥。所有其他机密和凭据都安全地存储并由 Pica 平台管理。
现在,你可以了解如何通过 Pica MCP 在 AI 代理中使用 Bright Data 的网页搜索、抓取和交互能力。
如何通过 Pica MCP 将 Bright Data 连接到 Claude Desktop
按照以下步骤将 Bright Data 集成到 Pica 中。接着,设置 Pica MCP,并将已配置的能力暴露给 Claude Desktop 中的 AI 代理。
注意:这里使用 Claude Desktop 做演示。但一旦 Pica MCP 设置完成,你就可以将其连接到任何支持 MCP 集成的其他方案,例如 OpenAI Codex CLI、Qwen-Agent、Google ADK、Crush CLI、Roo Code、LlamaIndex、Amazon Q Developer CLI、Gemini CLI、opencode、CrewAI、Pydantic AI、Claude Code、Cline 等。
前置条件
在开始本教程前,请确保你已具备:
- 一个已配置 API 密钥的 Bright Data 账户。
- 一个已就绪可用的 Pica 账户。
- 用于在 Claude Desktop 中连接的 Anthropic 账户。
按照官方指南获取你的 Bright Data API 密钥。
第一步:在 Pica 中配置 Bright Data
登录你的 Pica 账户,进入“Integrations > Connected Integrations(集成 > 已连接集成)”:
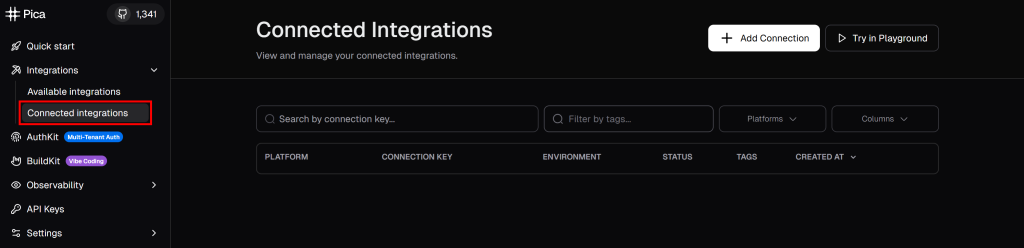
点击右上角的“+ Add Connection”,并搜索“brightdata”:
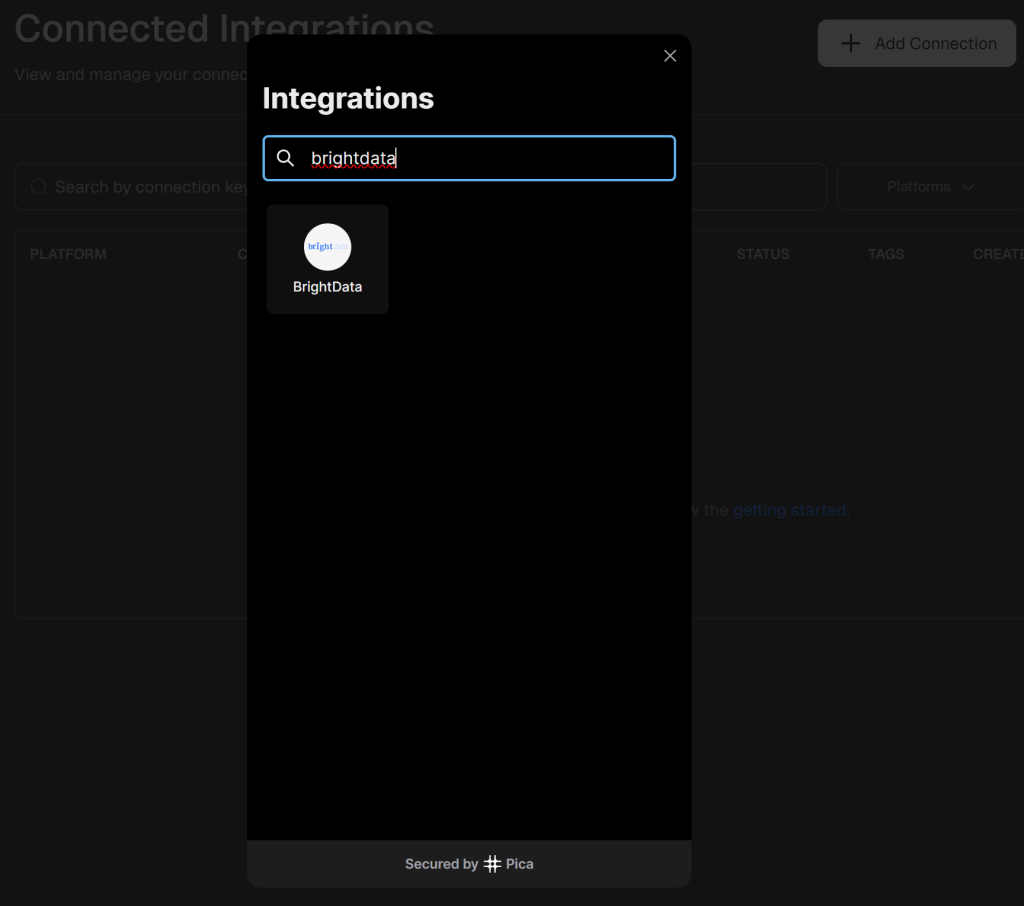
选择“BrightData”集成选项:
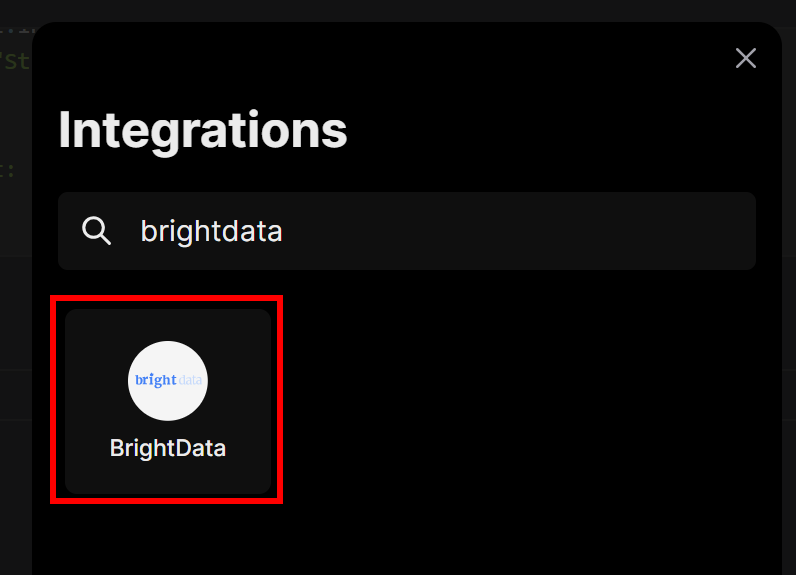
系统会提示你输入Bright Data API 密钥。粘贴后点击“Connect(连接)”:
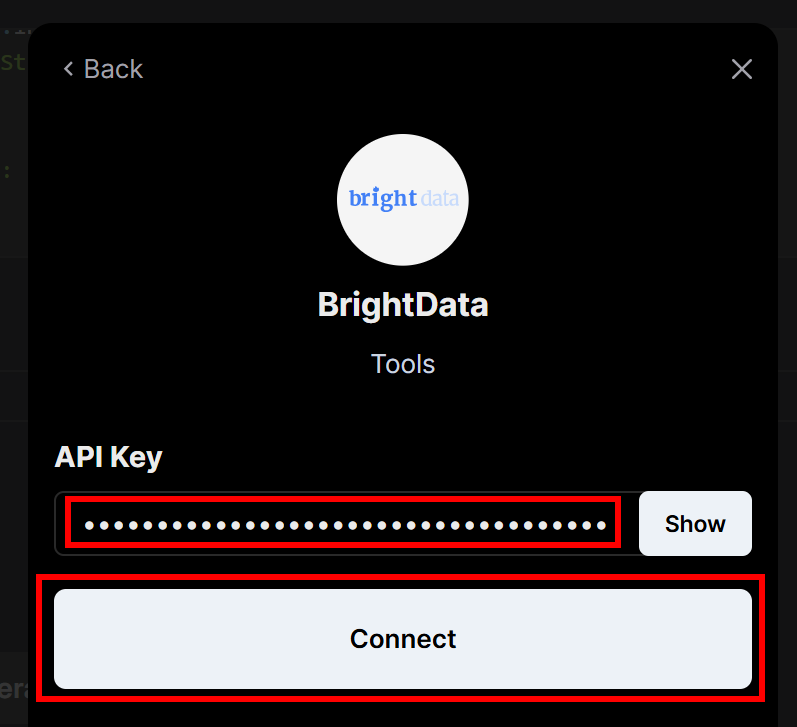
现在你应能看到“BrightData”已显示为活动连接:
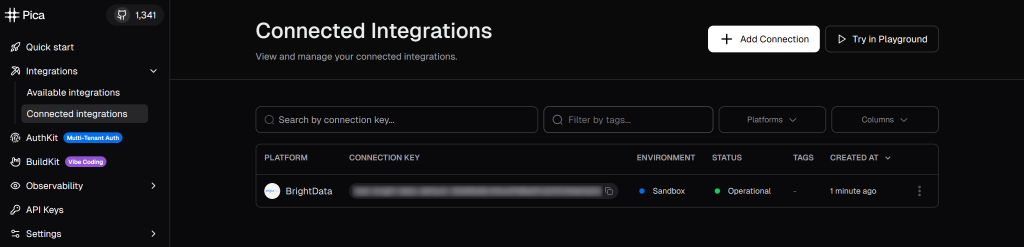
太棒了!你已在 Pica 账户中成功配置 Bright Data 集成。
第二步:安装并测试 Pica MCP
如需引导式设置,请访问“Quick start(快速开始)”页面,在“MCP”标签中按照说明操作:
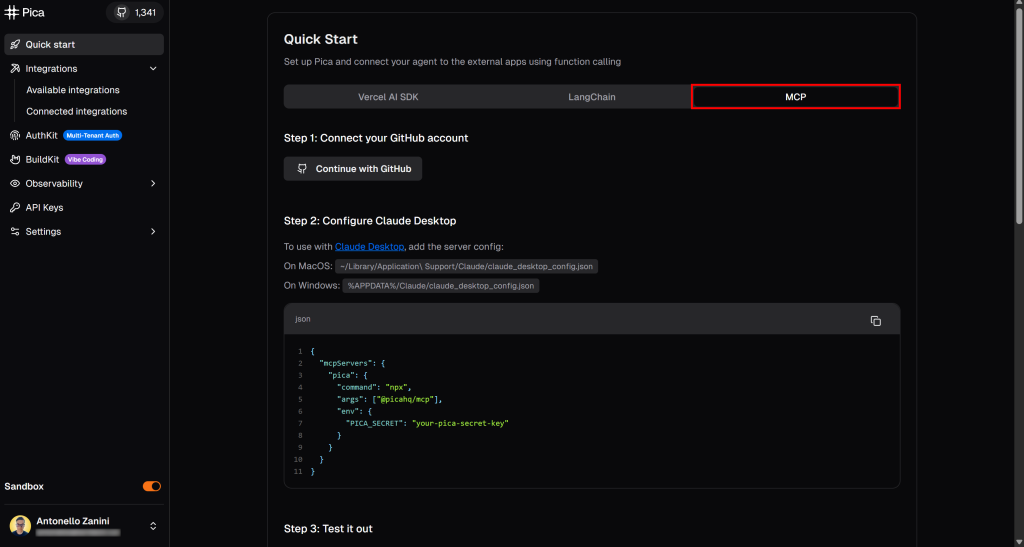
或按以下步骤操作。在你的机器上打开终端,通过 @picahq/mcp 包全局安装 Pica MCP:
npm install -g @picahq/mcp这可能需要一点时间,请耐心等待。
现在,用你的 API 密钥运行 Pica MCP 服务器:
PICA_SECRET="<YOUR_PICA_API_KEY>" npx @picahq/mcp或在 PowerShell 中等效地执行:
$Env:PICA_SECRET="<YOUR_PICA_API_KEY>"; npx @picahq/mcp以上两条命令都会将 PICA_SECRET 环境变量设置为你的 Pica API 密钥(用于认证),然后通过 @picahq/mcp 启动 Pica MCP 服务器。
在 Pica 账户的“API Keys”部分获取你的 Pica API 密钥:
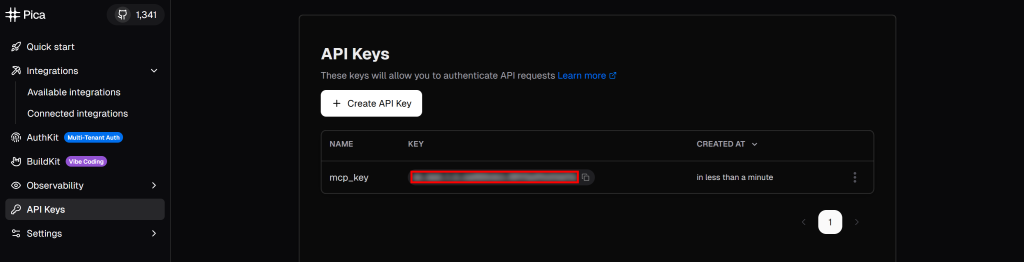
服务器成功启动时不会有输出。确认不要出现如下错误:
PICA_SECRET environment variable is required此外,当使用 Ctrl + c 关闭服务器时,你应看到:
Shutting down server...很好!你已经验证了 Pica MCP 服务器在本地机器上可以正常工作。
第三步:将 Claude Desktop 连接到 Pica MCP
如果尚未安装,请下载并安装 Claude Desktop。更多细节可参考官方的 Pica MCP 与 Claude Desktop 集成指南。
接下来,在 Claude Desktop 中通过编辑 claude_desktop_config.json 文件来配置 Pica MCP 服务器(macOS:~/Library/Application Support/Claude/claude_desktop_config.json;Windows:%APPDATA%/Claude/claude_desktop_config.json)。
确保文件包含以下配置:
{
"mcpServers": {
"pica": {
"command": "npx",
"args": ["-y", "@picahq/mcp"],
"env": {
"PICA_SECRET": "<YOUR_PICA_API_KEY>"
}
}
}
}其中:
mcpServers条目用于告诉 Claude Desktop 要连接哪些 MCP 服务器。pica条目定义了运行 Pica MCP 所需的命令(npx)、参数和环境变量。PICA_SECRET环境变量提供了你的 Pica API 密钥。
重启 Claude Desktop 后,它会根据上述配置将 Pica MCP 作为子进程启动并自动连接。
完成!Claude Desktop 现已配置为连接到你的本地 Pica MCP 服务器。
第四步:在 Claude Desktop 中验证 Pica MCP 可用
打开 Claude Desktop 并使用你的 Anthropic 账户登录。然后选择“Tools(工具)”,确认“pica” MCP(先前配置)可用且已启用:
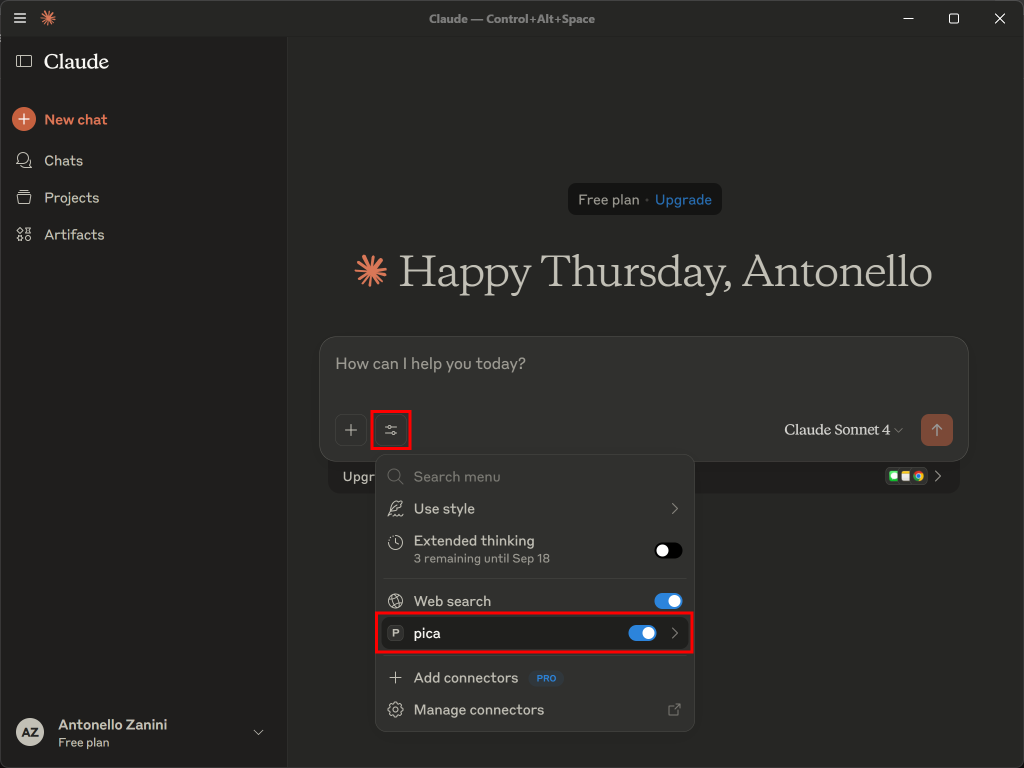
点击后,应显示本文开头提到的 4 个工具:
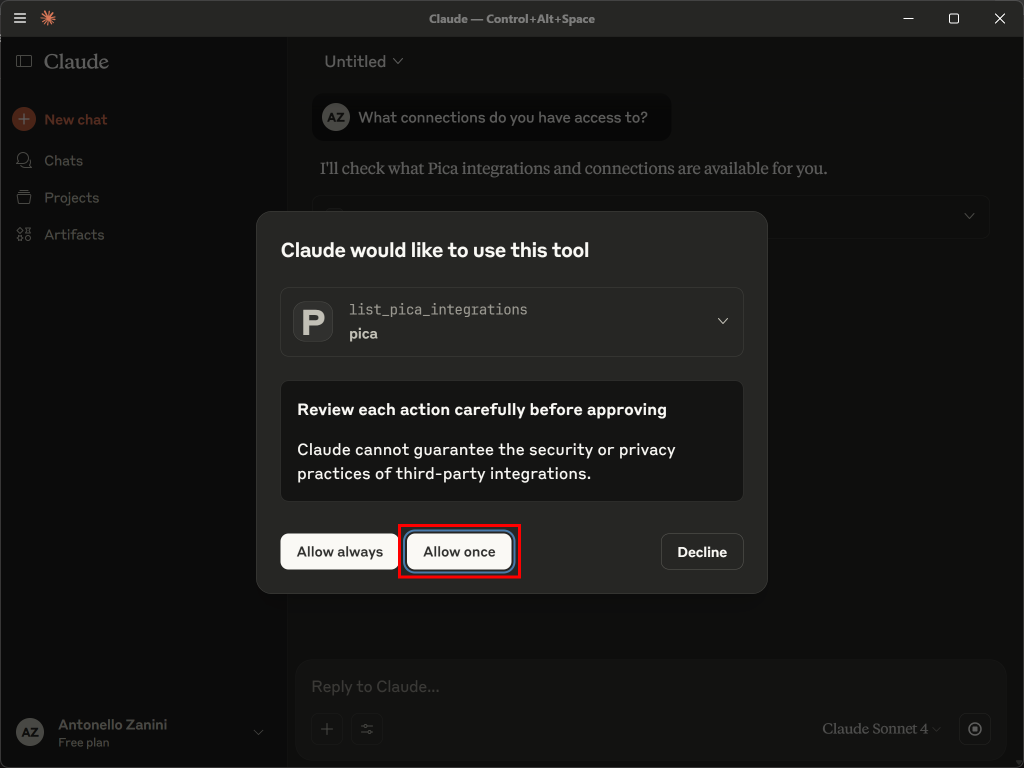
接着,验证 Pica MCP 服务器已连接到你的账户(你已在其中配置了 Bright Data 连接)。输入类似如下提示进行测试:
"What connections do you have access to?"接受 Pica 工具的执行:
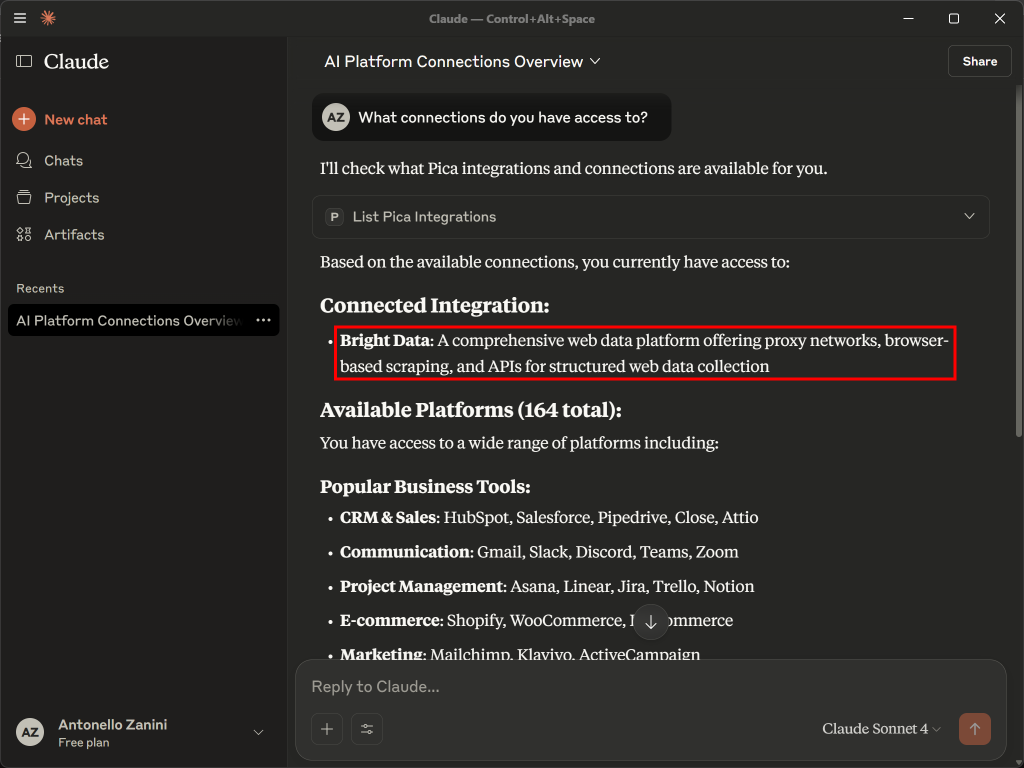
如你所见,Claude 选择了正确的“List Pica Integrations(列出 Pica 集成)”工具。这会返回你 Pica 账户中可用的集成列表。在输出中,你应能看到先前配置的 Bright Data 连接:
如需更多细节,可继续输入如下提示:
Show which actions are available for the Bright Data connection这会执行“Get Platform Actions(获取平台动作)”工具。允许工具执行后,输出应为:
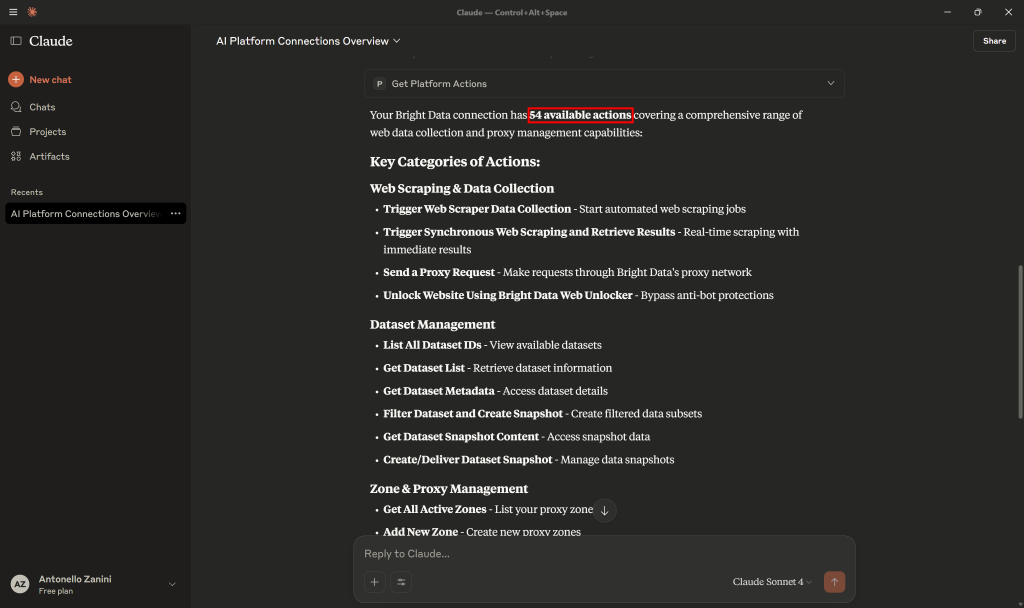
向下滚动,你应能看到通过 Bright Data 集成提供的全部 54 个工具。
做得好!Pica MCP 现在像一座桥梁一样,在 Claude Desktop 中暴露了 Bright Data 的能力。
第五步:在 Claude Desktop 中测试 Bright Data 的网页获取能力
检查 Claude Desktop 是否已能通过 Pica MCP 交互调用 Bright Data 的网页搜索、数据获取与交互功能。为测试这一点,尝试如下提示:
Use the most appropriate Bright Data action to perform a web scraping task on "https://github.com/picahq/pica". Wait for the snaphsot to be ready and process it to then return the most interesting stats and information about this repository.这足以验证 Claude Desktop 可以使用 MCP 集成从网络(尤其是 GitHub)抓取信息。
执行该提示:
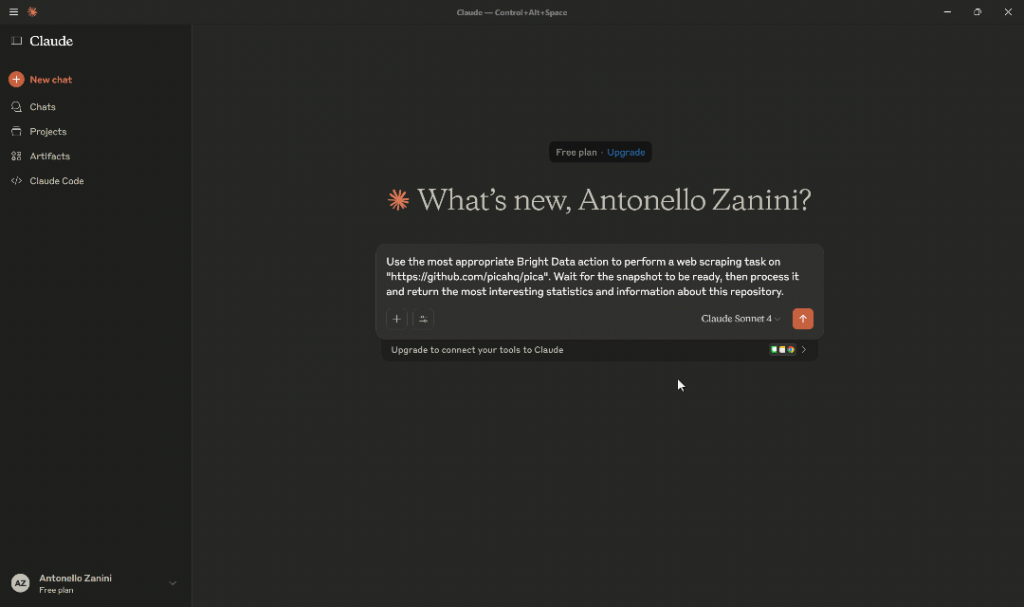
接下来将发生的关键步骤如下:
- Claude Desktop 调用工具以获取所有 Pica 集成。
- 识别所需的 Bright Data 集成并执行工具以获取其可用的动作。
- 检查各个动作,并将“Trigger Synchronous Web Scraping and Retrieve Results(触发同步网页抓取并获取结果)”识别为正确选项(对应调用 Bright Data 的Web Scraper API 同步模式)。
- 调用其他 Bright Data 动作以获取所有抓取器 ID(称为“dataset list”)。
- 识别正确的数据集 ID(
gd_lyrexgxc24b3d4imjt),它对应于 Bright Data GitHub Scraper。 - 将该 ID 与 GitHub URL 一同传递给“Trigger Synchronous Web Scraping and Retrieve Results”,以检索该仓库的信息。
- 处理快照,并给出包含该仓库最相关信息的摘要。
输出包含对所给仓库的关键信息与统计的报告。
这只是一个简单示例,但它清晰展示了通过 Pica MCP 集成 Bright Data 后,你的 Claude 代理所具备的强大能力。结合不同的提示与 Pica 中的连接器集成,你可以将其拓展到更多智能体用例。
搞定!任务完成。
结论
在本文中,你了解了如何安装和配置 Pica MCP Server,以将 Bright Data 的网页能力扩展到 Claude Code 中的 AI 代理。借助 Pica 的 Bright Data 连接器,你的 AI 代理可通过 MCP 访问 54 个用于网页数据获取、搜索、交互等的工具。
如果你希望构建更高级的代理,你需要可靠的解决方案来获取、验证和转换实时网页数据。这正是Bright Data 的 AI 基础设施所提供的。
也可以探索 Bright Data 支持的所有其他集成。
立即创建一个免费的 Bright Data 账户,开始体验我们面向 AI 的网页工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




