

在本指南中,您将看到:
- 什么是 Pica,以及为什么它是集成外部工具以构建 AI 代理的绝佳选择。
- 为什么 AI 代理需要与第三方解决方案集成以进行数据检索。
- 如何在 Pica 代理中使用内置的 Bright Data 连接器来获取网页数据,从而生成更精确的响应。
让我们开始吧!
什么是 Pica?
Pica 是一个开源平台,旨在快速构建 AI 代理和 SaaS 集成。它提供了对 125+ 第三方 API 的简化访问,无需管理密钥或进行复杂配置。
Pica 的目标是让 AI 模型轻松连接外部工具和服务。借助 Pica,您只需几次点击即可完成集成,然后在代码中轻松调用。这使得 AI 工作流能够处理实时数据检索、复杂自动化等任务。
该项目在 GitHub 上迅速走红,数月内就积累了 1,300 多颗星,彰显了其强大的社区增长和采用度。
为什么 AI 代理需要网页数据集成
任何 AI 代理框架都继承了其背后 LLM 的核心局限性。由于LLM 是在静态数据集上预训练的,它们缺乏实时感知,无法可靠地访问在线内容。
这常常导致回答过时,甚至出现“幻觉”。为克服这些局限,代理(及其所依赖的 LLM)需要访问可信且最新的网页数据。为什么是网页数据?因为网络仍是最全面、最新的信息来源。
因此,合格的 AI 代理必须能够快速、轻松地与第三方网页数据提供方集成。这正是 Pica 大显身手之处!
在 Pica 平台上,您可以发现125+ 可用集成,其中就包括 Bright Data:
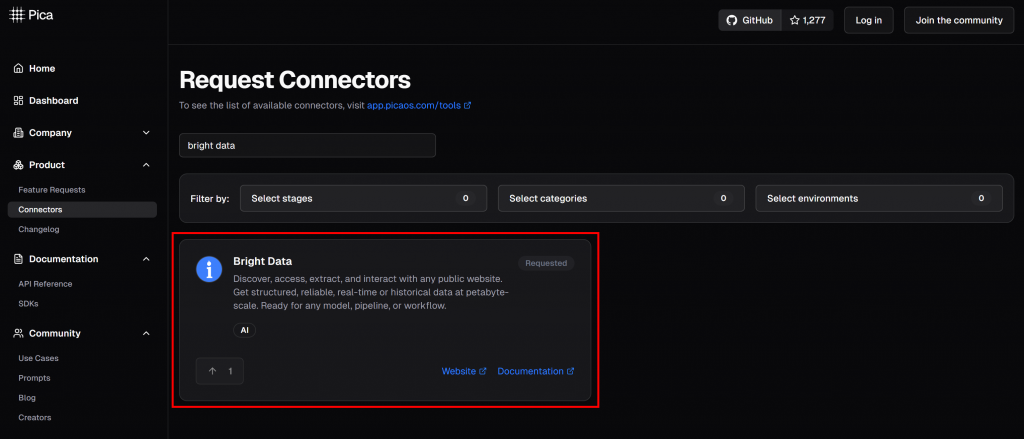
Bright Data 集成使您的 AI 代理和工作流能够无缝连接到:
- Web Unlocker API:一种高级爬虫 API,可绕过反爬虫保护,将任何网页内容以 Markdown 格式返回。
- Web Scraper APIs:针对 Amazon、LinkedIn、Instagram 等 40 多个热门站点的结构化数据提取解决方案。
这些工具让您的 AI 代理、工作流或管道能够实时从相关页面提取可靠的网页数据,为响应提供有力支撑。下一章带您实操演示!
如何使用 Pica 和 Bright Data 构建可从网页检索数据的 AI 代理
在本节中,您将学习如何使用 Pica 构建一个 Python AI 代理,并连接到 Bright Data 集成。这样,您的代理就能从 Amazon 等站点检索结构化网页数据。
请按以下步骤创建您的 Pica + Bright Data AI 代理!
准备工作
要完成本教程,您需要:
- 在本机安装 Python 3.9 或更高版本(推荐最新版本)。
- 一个 Pica 帐户。
- 一个 Bright Data API 密钥。
- 一个 OpenAI API 密钥。
如果您尚未拥有 Bright Data API 密钥或 Pica 帐户,请别担心,接下来的步骤里会教您如何设置。
步骤 1:初始化您的 Python 项目
打开终端并为您的 Pica AI 代理项目创建新目录:
mkdir pica-bright-data-agent该 pica-bright-data-agent 文件夹将包含用于 Pica 代理的 Python 代码,利用 Bright Data 集成进行网页数据检索。
接着,进入项目目录并创建一个 虚拟环境:
cd pica-bright-data-agent
python -m venv venv然后在您喜欢的 Python IDE 中打开该项目。推荐使用Visual Studio Code(Python 插件)或PyCharm Community Edition。
在项目文件夹中创建一个名为 agent.py 的新文件,目录结构应如下:
pica-bright-data-agent/
├── venv/
└── agent.py在终端激活虚拟环境。在 Linux 或 macOS 上运行:
source venv/bin/activate在 Windows 上运行:
venv/Scripts/activate接下来,您将安装所需的 Python 包。如果想一次性安装所有依赖,确保虚拟环境已激活,然后运行:
pip install langchain langchain-openai pica-langchain python-dotenv至此,您的 Python 开发环境已就绪,准备使用 Pica 集成 Bright Data 构建 AI 代理。
步骤 2:设置环境变量读取
您的代理需要连接 Pica、Bright Data 和 OpenAI 等第三方服务。为安全起见,请勿将 API 密钥硬编码到代码中,而是将其存储为环境变量。
使用 python-dotenv 库来简化环境变量加载。在已激活的虚拟环境中安装:
pip install python-dotenv然后,在 agent.py 顶部导入并调用 load_dotenv():
import os
from dotenv import load_dotenv
load_dotenv()此函数会从项目根目录的 .env 文件加载变量。确保在项目根目录创建 .env 文件,目录结构如下:
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.py现在,您可以安全地通过环境变量管理 API 密钥和其他敏感信息了。
步骤 3:配置 Pica
如果尚未注册,请创建免费 Pica 帐户。默认情况下,Pica 会为您生成一个 API 密钥,您可以在 LangChain 或任何支持的集成中使用。
访问“Quick start”页面,选择“LangChain”标签:
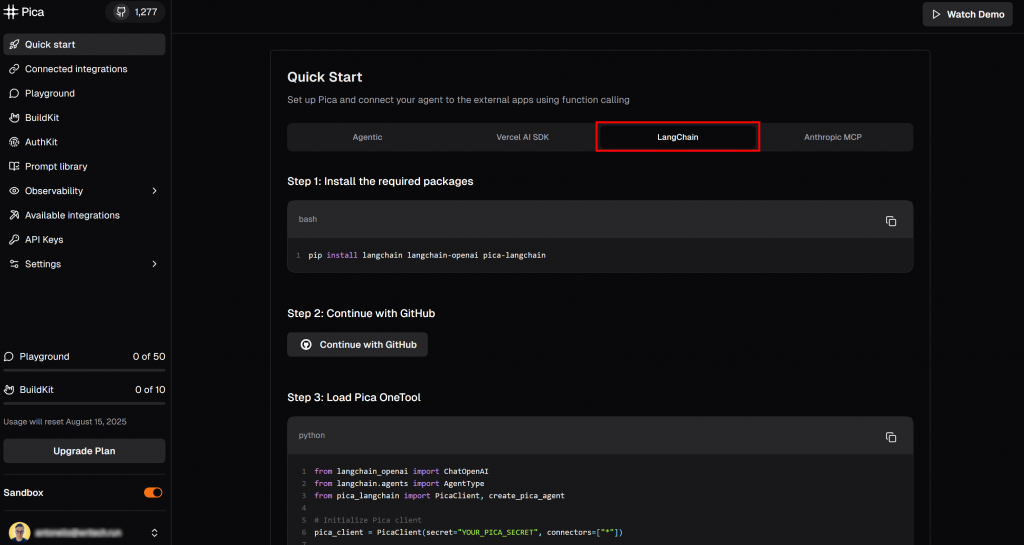
按照那里显示的安装命令,在已激活的虚拟环境中运行:
pip install langchain langchain-openai pica-langchain然后向下滚动到“API Key”部分:
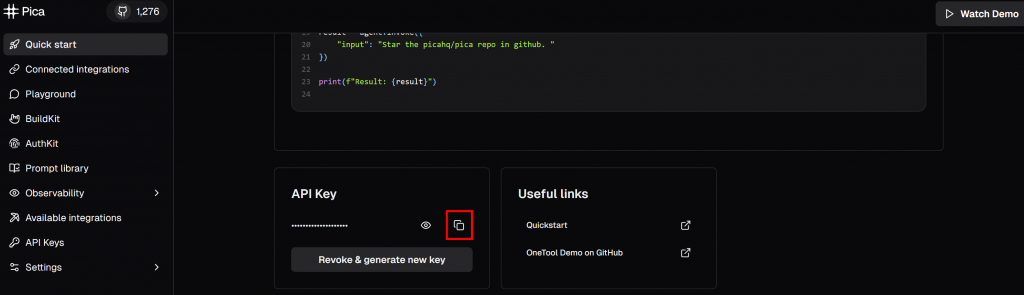
点击“Copy to clipboard”按钮复制您的 Pica API 密钥,并将其粘贴到 .env 文件中,形如:
PICA_API_KEY="<YOUR_PICA_KEY>"请将 <YOUR_PICA_KEY> 替换为刚才复制的实际密钥。
太好了!您的 Pica 帐户现已配置完毕,可在代码中使用。
步骤 4:在 Pica 中集成 Bright Data
首先,请按照官方指南设置 Bright Data API 密钥。此密钥将用于通过 Pica 平台提供的内置集成将代理连接到 Bright Data。
获取密钥后,可在 Pica 中添加 Bright Data 集成。
在 Pica 控制台“LangChain”标签下,滚动到“Recent Integrations”部分,点击“Browse integrations”按钮:
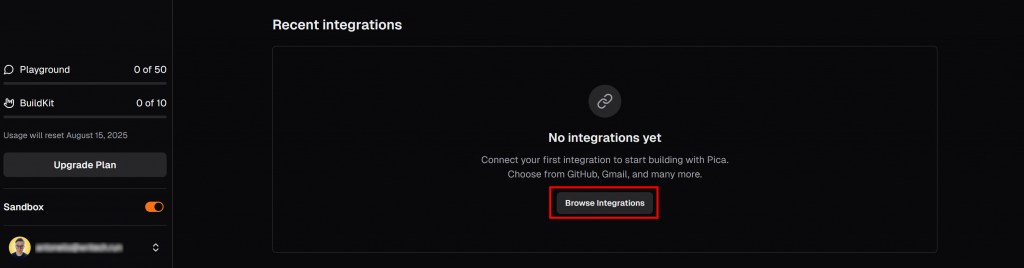
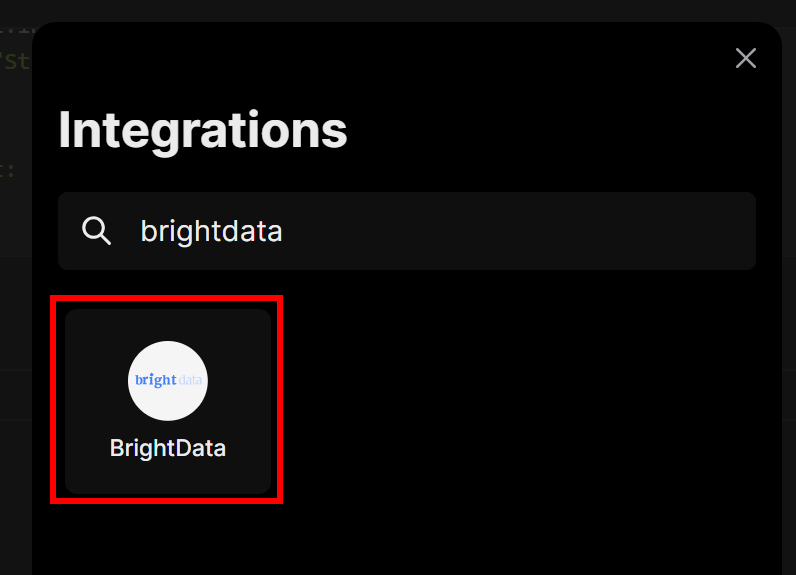
在弹出窗口的搜索栏中输入“brightdata”,然后选择“BrightData”集成:
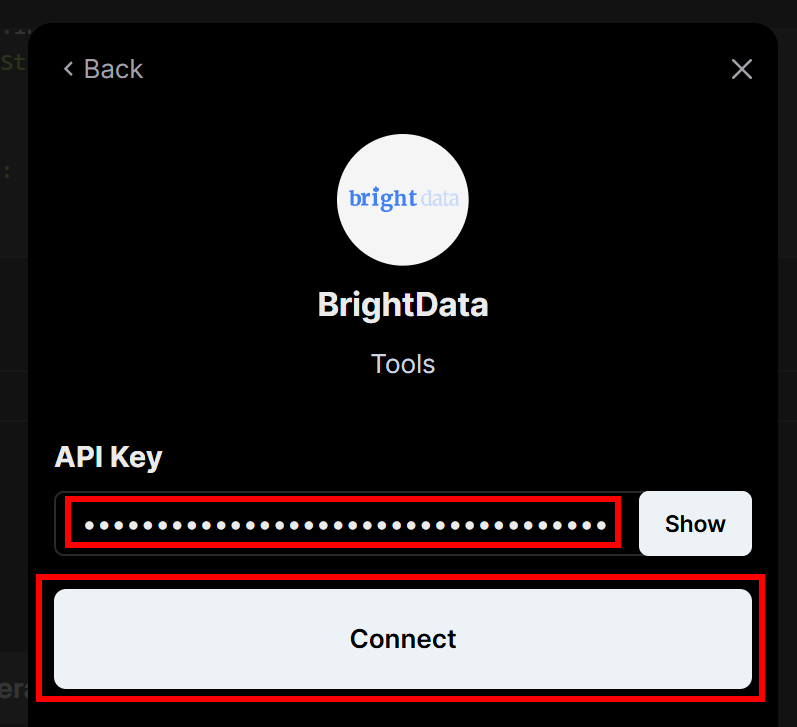
系统会提示您输入此前创建的 Bright Data API 密钥。粘贴后点击“Connect”按钮:
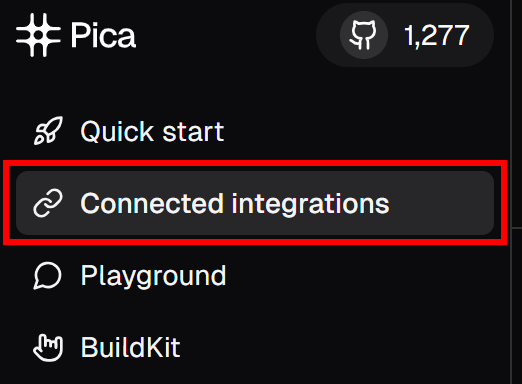
接着,在左侧菜单点击“Connected Integrations”:
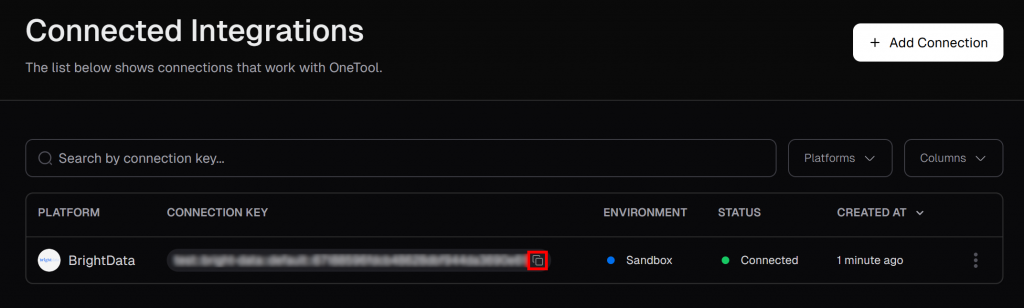
在“Connected Integrations”页面,您应能看到 Bright Data 已列为已连接的集成。从列表中点击“Copy to clipboard”按钮,复制连接密钥:
然后,将其粘贴到 .env 文件中,添加:
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"请将 <YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY> 替换为刚才复制的实际连接密钥。
接下来,您将在代码中使用此密钥初始化 Pica 代理,使其能够加载配置好的 Bright Data 连接。详见下一步!
步骤 5:初始化您的 Pica 客户端
在 agent.py 中,用以下代码初始化 Pica 客户端:
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()上述代码使用从环境变量读取的 PICA_API_KEY 密钥连接至您的 Pica 帐户,并通过 PICA_BRIGHT_DATA_CONNECTION_KEY 指定 Bright Data 集成。
别忘了导入所需类:
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptions太棒了!现在任何由该客户端创建的代理都可以利用 Bright Data 的实时网页数据检索功能。
步骤 6:集成 OpenAI
您的 Pica 代理需要一个 LLM 引擎来解析输入提示,并结合 Bright Data 功能执行任务。
本教程使用 OpenAI 集成,请在 agent.py 中按如下方式定义 LLM:
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)Pica LangChain 文档中的示例均使用 temperature=0,以确保模型确定性——相同输入始终产生相同输出。
请确认已导入:
from langchain_openai import ChatOpenAI此外,ChatOpenAI 会读取名为 OPENAI_API_KEY 的环境变量。请在 .env 中添加:
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>将 <YOUR_OPENAI_API_KEY> 替换为您的 OpenAI API 密钥。
现在,您具备了定义 Pica AI 代理的所有基石。
步骤 7:定义您的 Pica 代理
在 Pica 中,一个 AI 代理由三部分组成:
- Pica 客户端实例
- LLM 引擎
- Pica 代理类型
本示例要构建的代理将调用OpenAI 函数调用(从而借助 Pica 集成调用 Bright Data 网页检索功能)。请按以下方式创建代理:
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)别忘了导入:
from pica_langchain import create_pica_agent
from langchain.agents import AgentType完美!现在只需测试代理的数据检索能力。
步骤 8:调用您的 AI 代理
为验证 Bright Data 集成是否生效,给代理下达它自身无法完成的任务。例如,让它从近期的 Amazon 产品页面(如 Nintendo Switch 2,链接 https://www.amazon.com/dp/B0F3GWXLTS/)获取最新数据。
使用以下代码调用代理:
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})注意:提示词故意写得非常明确,告知代理具体要做什么、要爬取哪个页面以及使用哪个集成,确保 LLM 能调用 Pica 配置的 Bright Data 工具,生成预期结果。
最后,打印输出:
print(f"nAgent Result:n{result}")至此,您的 Pica AI 代理已完成,快来体验它的强大功能吧!
步骤 9:整合所有内容
您的 agent.py 文件应包含:
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")如您所见,不到 50 行代码,您就构建了一个具备强大数据检索能力的 Pica 代理,这得益于 Pica 平台内置的 Bright Data 集成。
运行代理:
python agent.py在终端中,您将看到类似如下日志:
# Omitted for brevity...
2026-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2026-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2026-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2026-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2026-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2026-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2026-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2026-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2026-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2026-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2026-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-data简单来说,您的 Pica 代理完成了:
- 连接到 Pica 并获取配置好的 Bright Data 集成。
- 发现 Bright Data 平台上共有 54 个可用工具。
- 检索了Bright Data 的数据集列表。
- 根据提示选择了“Trigger Synchronous Web Scraping and Retrieve Results”工具,用于爬取指定的 Amazon 产品页面数据;该操作实际调用了Bright Data Amazon Scraper。
- 成功执行爬取操作并返回数据。
您的输出应类似于下图:

将此结果粘贴到Markdown 编辑器中,您会看到格式良好的产品报告:
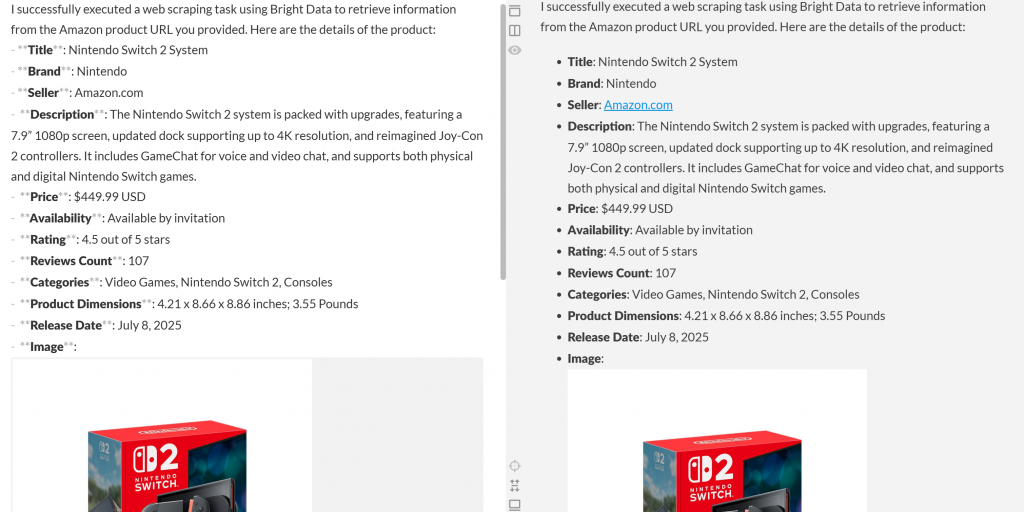
正如您所见,代理已生成一份 Markdown 报告,其中包含来自亚马逊产品页面的有意义且最新的数据。您可以在浏览器中访问目标产品页面来验证其准确性:
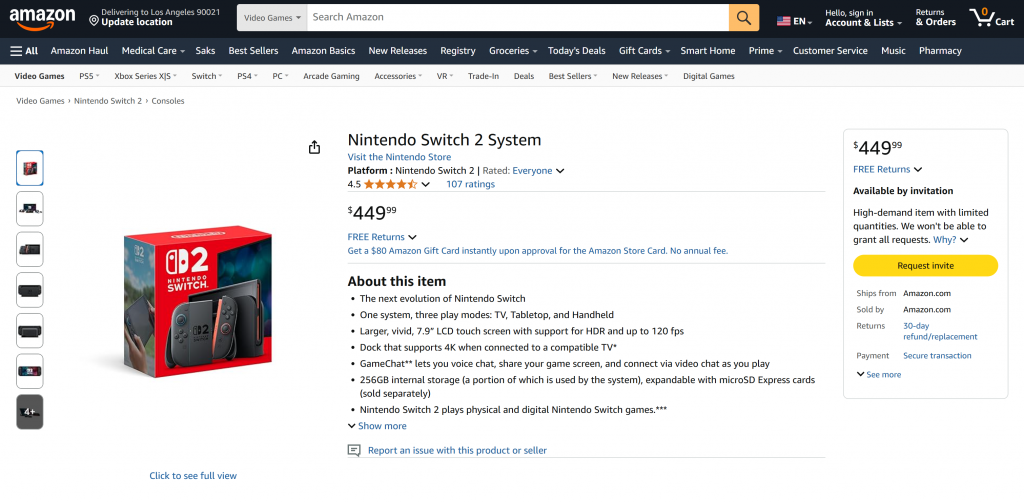
如您所见,代理生成了一份包含 Amazon 页面真实数据的 Markdown 报告,而非 LLM 的“幻觉”产物。这正是通过 Bright Data 工具完成爬取的成果。而这只是开始!
借助 Pica 上丰富的 Bright Data 工具,您的代理现在几乎可以从任何网站检索数据,包括对反爬虫措施严格的复杂目标(如臭名昭著的Amazon CAPTCHA)。
Voilà!您刚刚体验了一次由 Pica AI 代理中 Bright Data 集成驱动的无缝网页爬取。
结论
本文演示了如何使用 Pica 构建 AI 代理,并通过内置的 Bright Data 集成为其响应提供最新网页数据支持。Pica 的 Bright Data 连接器让 AI 能够随时获取任意网页的数据。
请记住,这只是一个简单示例。若要构建更高级的代理,还需强大的解决方案来抓取、验证和转换实时网页数据。这正是您在Bright Data AI 基础设施中能找到的。
立即创建免费 Bright Data 帐户,开始探索我们的 AI 就绪网页数据提取工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




