

在这篇博文中,你将看到:
- 什么是 Crush,以及为什么它深受开发者喜爱,作为 AI 编码助理的命令行应用。
- 如何通过扩展网页交互与数据抽取,让它更高效。
- 如何将 Crush CLI 连接 Bright Data 的 Web MCP 服务器,打造更强大的 AI 编码代理。
让我们开始吧!
什么是 Crush?
Crush 是一个在终端中运行的开源 AI 编码代理。具体来说,Crush CLI 是一个基于 Go 的命令行应用,将 AI 助力带入你的终端环境。它提供一个 TUI(终端用户界面),可与多种大模型互动,辅助编码、调试及其他开发任务。
Crush 的独特之处在于:
- 跨平台:适配 macOS、Linux、Windows(PowerShell 与 WSL)、FreeBSD、OpenBSD、NetBSD 等主流终端。
- 多模型支持:可从广泛的 LLM 中选择,通过兼容 OpenAI/Anthropic 的 API 集成自有后端,或连接本地模型。
- 会话化体验:按项目维护多个工作会话与上下文。
- 高度灵活:支持在会话中切换 LLM,同时保持上下文。
- LSP 就绪:支持 LSP(语言服务器协议),提供额外上下文与智能,如同现代 IDE。
- 可扩展:通过 MCP(HTTP、stdio、SSE)集成第三方功能。
该项目在 GitHub 上已获得 1 万+ Star,并由活跃社区维护,贡献者超过 35 位。
用 Web MCP 弥合 Crush CLI 的 LLM 知识鸿沟
所有 LLM 都面临一个共同挑战:知识截止时间。你在 Crush CLI 中配置的 LLM 也不例外。由于这类模型是基于固定数据集训练,其知识是过去的静态快照,难以及时了解最新事件或进展。
在快速迭代的技术世界中,这是一大弊端。缺乏最新知识的 LLM 可能推荐已弃用的库、过时的实践,或不了解新特性与新工具。
假如你的 Crush AI 编码助理不仅能“回忆”旧知识,还能搜索最新文档、文章和指南,并据此提供更准确的建议,会怎样?
你可以通过给 LLM 赋予网页访问与数据检索能力来实现。这正是Bright Data 的 Web MCP 服务器所提供的功能。该开源服务器(现已提供免费层)内置 60+ 面向 AI 的网页交互与数据采集工具。
Bright Data Web MCP 集成
以下是该 MCP 服务器上的两个主要工具:
search_engine:连接到 SERP API,在 Google、Bing 或 Yandex 上执行搜索,并以 HTML 或 Markdown 返回搜索结果页数据。scrape_as_markdown:使用 Web Unlocker 抓取单页内容。支持高级抽取选项,可绕过反爬系统并自动处理 CAPTCHA。
除此之外,还有 55+ 个专用工具,用于与网页交互(如 scraping_browser_click)以及从亚马逊、领英、TikTok 等多种站点收集结构化数据流。例如,web_data_amazon_product 工具可基于商品 URL 直接拉取亚马逊商品的结构化详情。
基于这些工具,你可以将 Bright Data Web MCP 与 Crush 结合,用于:
- 获取项目所需的最新信息,如雅虎财经的股价或电商商品详情;将数据保存为本地文件用于分析、测试、Mock 等。
- 让 AI 自动获取你所用库/框架的最新文档,确保建议代码不过时、不被弃用。
- 收集上下文相关链接,并将资源整合到 Markdown、文档或其他输出中——无需离开编辑器。
准备好看看 Web MCP 如何增强你的 Crush CLI 代理吧!
如何将 Crush 连接到 Bright Data 的 Web MCP
在本教程中,你将学会在本地安装配置 Crush,并将其与 Bright Data 的 Web MCP 集成。最终,你将得到一个能力增强的 AI 编码代理,可:
- 即时抓取一页亚马逊商品数据;
- 将数据保存到本地 JSON 文件;
- 创建一个 Node.js 脚本来加载并处理这些数据。
按以下步骤操作!
前置条件
开始之前,请确保你已具备:
- 本地安装 Node.js(建议使用最新 LTS)。
- 任一受支持 LLM 提供商的 API Key(本文示例使用 Google Gemini)。
- 一个 Bright Data 账号与可用 API Key(若无别担心,文中会引导你创建)。
此外,以下背景知识虽非必需但有帮助:
- 对MCP 工作机制的基本理解。
- 对 Bright Data Web MCP 服务器及其工具有一定熟悉。
- 了解 CLI 编码代理如何工作以及它们如何与文件系统交互。
步骤一:安装并配置 Crush
通过 @charmland/crush npm 包在系统中全局安装 Crush CLI:
npm install -g @charmland/crush如果你不想通过 npm 安装 CLI,可查看其他安装方式。
现在,启动 Crush:
crush你应当看到如下 LLM 选择界面:
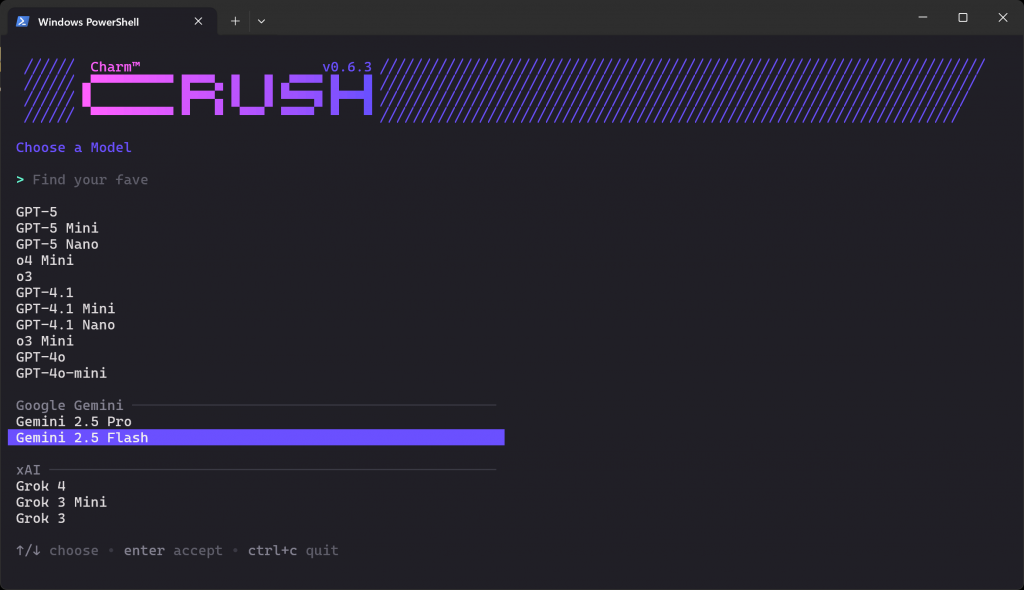
这里有数十家提供商、数百个模型可选。使用方向键在你拥有 API Key 的提供商下找到模型。在本文中,我们选择“Gemini 2.5 Flash”(通过 API 几乎可免费使用)。
接着,系统会要求你输入 API Key。粘贴后按 Enter:
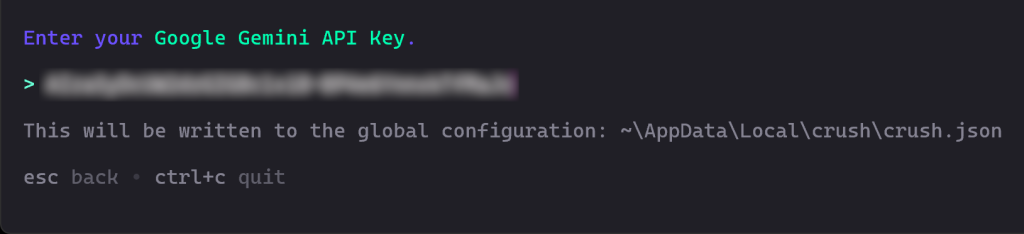
在本例中,粘贴你的 Google Gemini API Key,你可以从 Google AI Studio 免费获取。
Crush 会验证你的 API Key 是否可用。
验证完成后,你应看到类似界面:
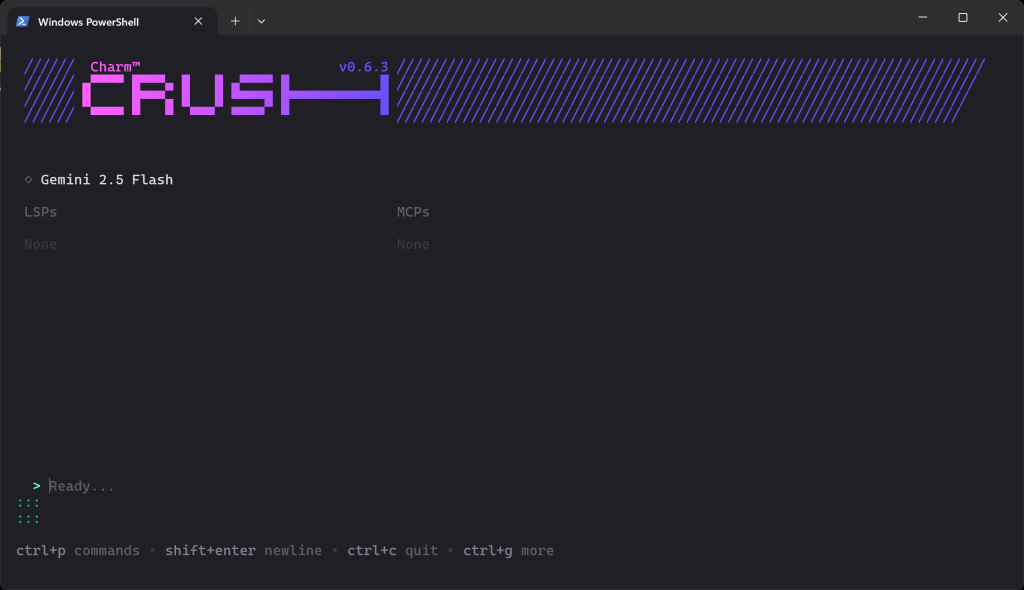
在“Ready…”区域,你现在可以输入提示词了。
注意:再次启动 Crush CLI 时,将不会再次要求设置 LLM 连接。因为你配置的 LLM Key 会自动保存在全局配置 $HOME/.config/crush/crush.json(Windows 为 %USERPROFILE%AppDataLocalcrushcrush.json)。
在 VS Code(或你喜爱的 IDE)中打开全局 crush.json 配置文件查看:
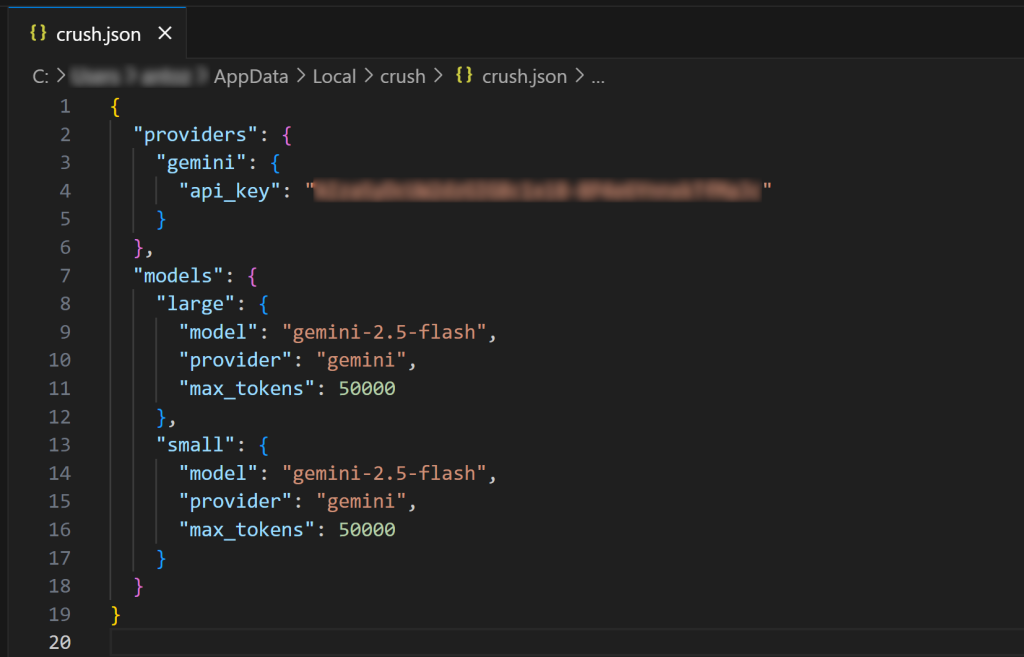
如你所见,crush.json 包含你的 API Key 以及所选模型的配置。这是你在选择 LLM 时由 Crush CLI 自动生成的。你也可编辑此文件配置其他 AI 模型(包括本地模型)。
类似地,你可以在项目目录中创建本地 crush.json 或 .crush.json 来覆盖全局配置。详情参阅官方文档。
很好!Crush CLI 已在你的系统中安装并可用。
步骤二:测试 Bright Data 的 Web MCP
如果你还没有账号,注册一个 Bright Data 账号。已有账号的话,直接登录。
接着,按官方指南生成 Bright Data API Key。妥善保存,后续会用到。为简化示例,我们假设你使用具备 Admin 权限的 API Key。
通过 @brightdata/mcp 包全局安装 Web MCP:
npm install -g @brightdata/mcp然后用下面的 Bash 命令验证服务器可用性:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpWindows PowerShell 等效命令:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你之前生成的实际 API Token。上述命令通过设置必需的 API_TOKEN 环境变量,并用 @brightdata/mcp 启动 MCP 服务器。
若一切正常,你将看到类似日志:

首次启动时,MCP 服务器会在你的 Bright Data 账户内自动创建两个 Zone:
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
这两个 Zone 是使用 MCP 全量工具所必需的。
要确认它们已创建,请登录 Bright Data 仪表盘,前往“Proxies & Scraping Infrastructure”页面。你应能看到这两个 Zone:
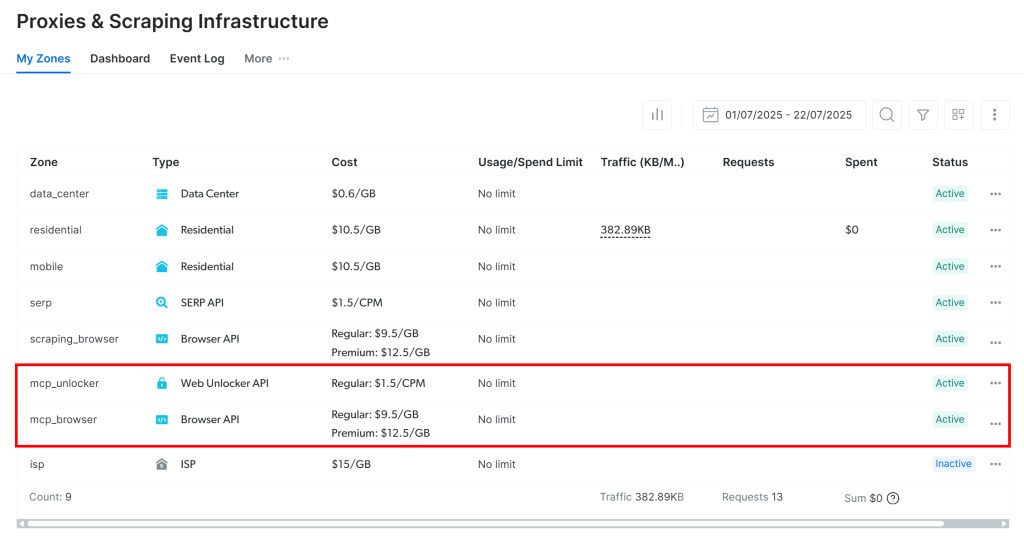
注意:如果你的 API Token 没有 Admin 权限,可能不会自动创建这些 Zone。此时你可以手动创建,并通过环境变量指定它们的名称,详见官方文档。
请记住:默认情况下,MCP 服务器仅暴露 search_engine 与 scrape_as_markdown 两个工具。
若要解锁浏览器自动化和结构化数据源的高级工具,你需要启用 Pro 模式。为此,在启动 MCP 服务器前设置 PRO_MODE=true 环境变量:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpWindows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp重要:启用 Pro 模式后,可使用全部 60+ 工具。但 Pro 模式中的额外工具不在免费层内,使用会产生费用。
在官方文档中了解更多 Bright Data Web MCP 服务器信息。
很好!你已验证 Web MCP 在本机正常运行。先停止服务器,下一步将在 Crush 中配置启动并自动连接 MCP。
步骤三:在 Crush 中配置 Web MCP
Crush 通过配置文件中的 mcp 节支持 MCP 集成(本地或全局 crush.json 皆可)。
本例假设你希望在 Crush CLI 的全局环境中配置 Bright Data 的 Web MCP。请打开全局配置文件:
- Linux/macOS:
$HOME/.config/crush/crush.json - Windows:
%USERPROFILE%AppDataLocalcrushcrush.json
确保包含以下内容:
"mcp": {
"brightData": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}关于该配置:
mcp节告诉 Crush 如何启动外部 MCP 服务器。brightData条目定义了运行 Web MCP 所需的命令与环境变量。(注意:PRO_MODE可选但推荐;将<YOUR_BRIGHT_DATA_API_KEY>替换为你的 Bright Data API Key。)
换言之,该配置新增了名为 brightData 的自定义 MCP 服务器。Crush 会使用文件中设置的环境变量,通过指定的 npx 命令启动服务器(与上一步的命令一致)。简而言之,Crush 现在可以在启动时本地拉起一个 Web MCP 进程并连接。
很好!接下来在 Crush CLI 中测试 MCP 集成。
步骤四:验证 MCP 连接
关闭所有已运行的 Crush 实例,再次启动:
crush若 MCP 连接正常,你会在“MCPs”板块看到 brightData 项:
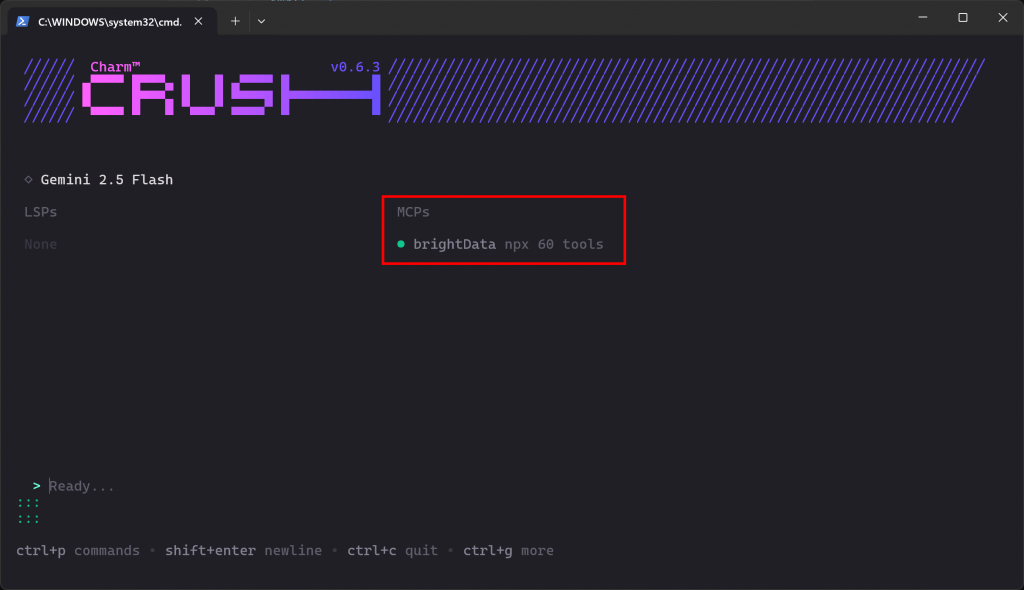
CLI 显示可用 60 个工具。这是因为我们启用了 Pro 模式。否则你只能使用 2 个工具(scrape_as_markdown 与 search_engine)。干得漂亮!
步骤五:在 Crush 中运行任务
为验证你在 Crush CLI 中的新能力,尝试运行如下提示:
Scrape data from "https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/", save it to a local "product.json" file, and define a Node.js "script.js" script to load the file and print its contents in the terminal.这是一条很好的测试用例,因为它需要获取最新商品数据,应通过 Bright Data Web MCP 暴露的工具来完成。同时,它也演示了你在进行 Mock 或数据分析项目时的真实工作流。
将提示粘贴进 Crush 并按 Enter 执行。你应看到类似如下界面:
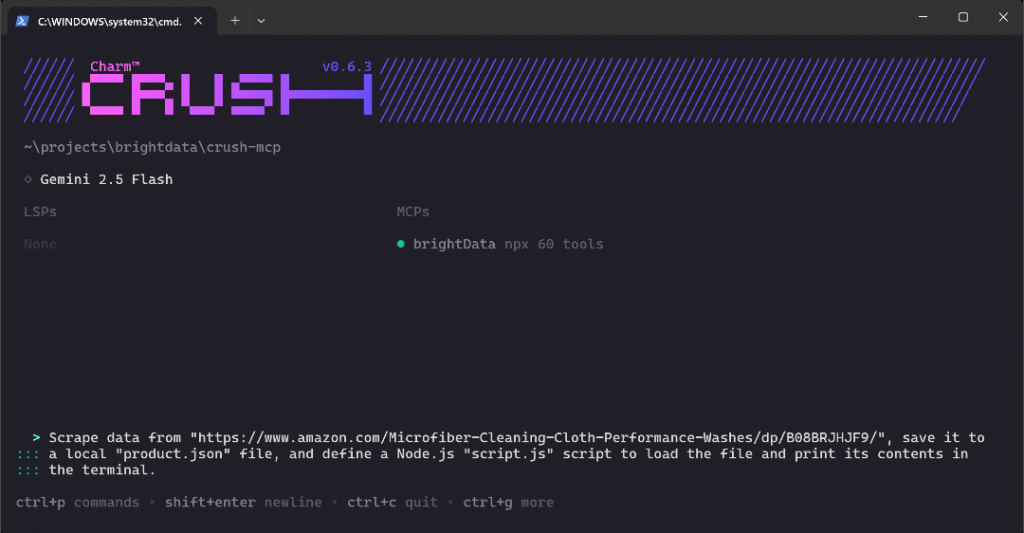
上面的 GIF 做了加速,实际步骤如下:
- Crush 识别到
web_data_amazon_product工具(在 CLI 中显示为mcp_brightData_web_data_amazon_product)是完成该任务的正确选择,并请求你授权运行。 - 获得授权后,抓取任务通过 MCP 集成开始执行。
- 生成的 JSON 商品数据会显示在终端中。
- Crush 询问是否将这些数据保存为名为
product.json的本地文件。 - 批准后,将创建该文件并写入抓取的数据。
- 随后,Crush CLI 生成
script.js的 JavaScript 逻辑,用于加载并打印 JSON 内容。 - 在你批准后,
script.js文件被创建。 - 系统会提示请求权限以执行该 Node.js 脚本。
- 授权后,
script.js被执行,商品数据被打印到终端。
请注意,即使你没有明确要求,CLI 也会请求执行生成的 Node.js 脚本。这是有意为之,便于测试(以及在出错时更容易修复),并为工作流增值。
最终,你的工作目录应包含以下两个文件:
├── prodcut.json
└── script.js在 VS Code 中打开 product.json,你应看到:
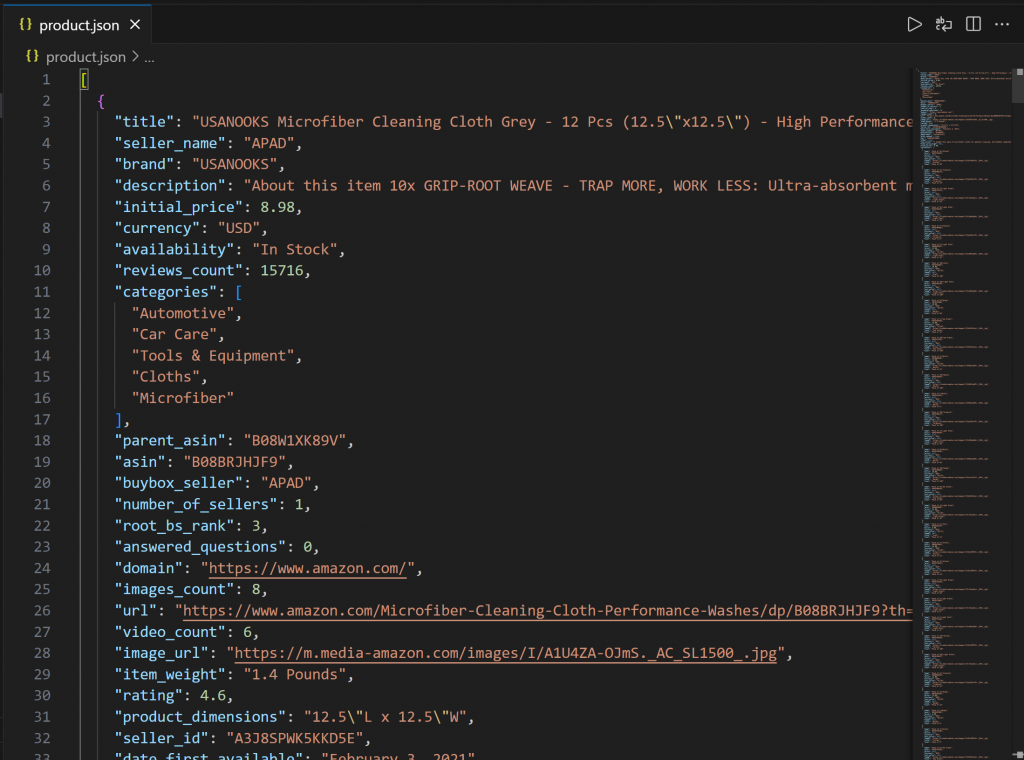
该文件包含通过 Bright Data 的 Web MCP 从亚马逊抓取的真实商品数据。
现在打开 script.js:
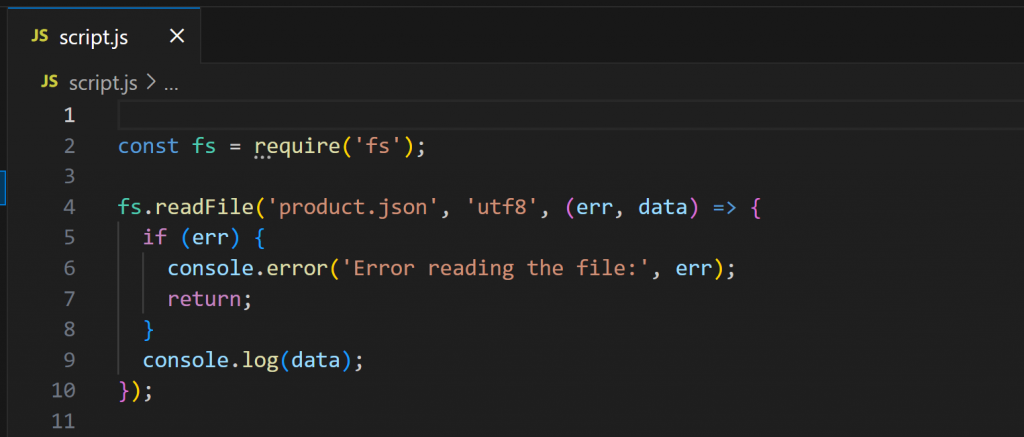
该脚本使用 Node.js 加载并展示 product.json 的内容。运行:
node script.js输出应为:
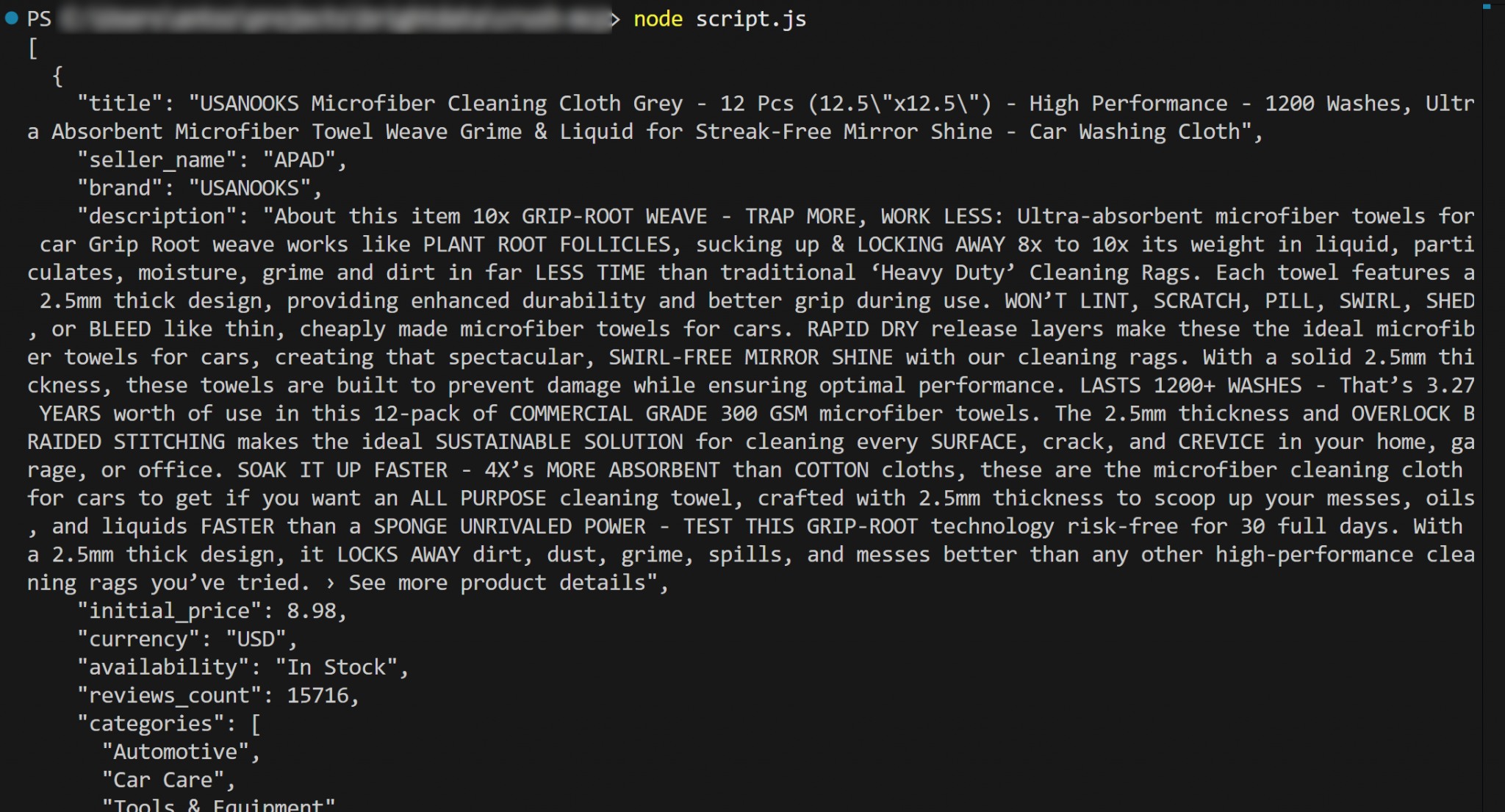
大功告成!工作流运行成功。
更具体地说,终端打印的 product.json 内容应与亚马逊原始商品页中的实际数据一致。
重要:product.json 含有真实抓取的数据——而非 AI 幻觉或编造内容。这一点非常关键,因为抓取亚马逊 notoriously 困难(例如存在亚马逊 CAPTCHA 等高级反爬措施)。仅靠常规 LLM 无法达成这一目标!
该示例展示了将 Crush 与 Bright Data MCP 服务器组合的真正威力。现在试试新的提示词,探索更多可在 CLI 中直接完成的高级、由 LLM 驱动的数据工作流!
结语
在本教程中,你学会了如何将 Crush 连接 Bright Data 的 Web MCP(现已提供免费层)。结果是一个能够访问并与网页交互的强大 CLI 编码代理。这一集成得益于 Crush CLI 对 MCP 服务器的内建支持。
本文的示例任务刻意保持简单。但别忘了,通过该集成,你可以处理更复杂的用例。毕竟,Bright Data Web MCP 工具支持各类智能体场景。
若要打造更高级的代理,请探索 Bright Data AI 基础设施 提供的全套服务。
注册免费 Bright Data 账号,立即开始体验面向 AI 的网页工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



