

读完本文,你将学会:
- 使用 Bright Data 的 Google AI 模式 Scraper API 服务
- 利用 Skyvern 实现任务自动化
- 将 Bright Data API 服务与 Skyvern 结合以自动化网页任务
- 结合自动化与数据馈送构建电商助理
- 自动获取购物车中的商品详情
让我们开始吧!
充分利用 Bright Data 的 API 服务
浏览器自动化的基础在于应对 CAPTCHA、人机验证、IP 封禁以及动态网页加载等挑战。Bright Data 正是在此方面至关重要。
借助 Bright Data 的 Web Scraper(支持 120+ 个网站/域),浏览器自动化更高效、更可靠。它可应对常见采集难题,包括 IP 封禁、CAPTCHA、Cookie 以及其他各类机器人检测。
开始之前,先注册免费试用,并获取目标域的 API key 和 dataset_id。获得这些之后即可开始。
以下是在任意域(例如 BBC News)获取最新数据的步骤:
- 如果尚未注册,请创建一个Bright Data 账号,支持免费试用。
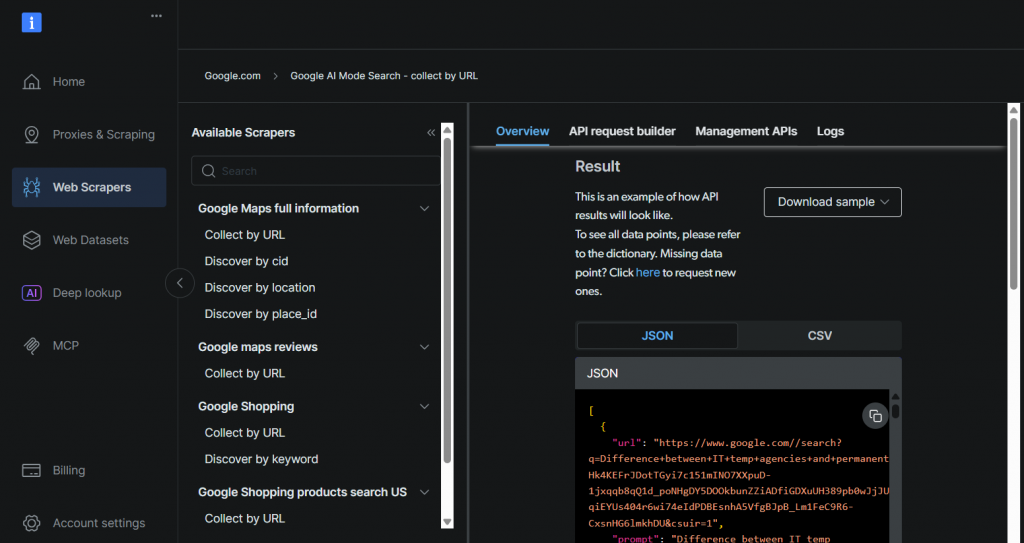
- 进入 Web Scrapers 页面。在 Web Scrapers Library 中浏览可用的爬虫模板。
- 搜索你的目标站点(如 BBC News)并选择它。
- 在BBC News 爬虫列表中,选择“BBC News — 按 URL 采集”。该爬虫无需登录即可获取数据。
- 选择 Scraper API 选项。“No-Code Scraper(无代码爬虫)”可在无需编写代码的情况下获取数据集。
- 点击 API Request Builder,然后复制你的
API key、BBC Dataset URL和dataset_id。 API-key和dataset_id是在工作流中启用自动化功能的必需参数,可让你在编程时直接访问 Bright Data 能力。
什么是 Skyvern
Skyvern 是一款 AI 浏览器自动化工具,利用人工智能在浏览器中自动执行任务。它结合了机器学习、自然语言处理和计算机视觉,以处理复杂的浏览器操作。
与传统的 Selenium、Playwright 等自动化工具相比,Skyvern 的不同之处在于:
- 对 UI 变化的适应性:自愈能力让 Skyvern 能够在 UI 变化时动态适配而不致脚本失效。
- 工作流复杂度:可通过单条提示词,依靠 AI 推理处理多步骤工作流。
- 视觉识别:使用计算机视觉来理解并以可视化方式与 UI 元素交互。
借助这些能力,你可以使用 Skyvern 登录预订网站、填写表单或将商品加入购物车。当与 Bright Data 的网页采集能力结合时,Skyvern 可为多样化的网页自动化需求提供强大的解决方案。
自动化工作流
例如,你想在某家网店购买一款汽车零件,可能希望比较可选项并自动将某一款加入购物车。工作流如下:
- 利用 Bright Data AI 模式的 Scraper API 从指定制造商处获取商品描述和产品详情(如零件号)。
- 你审阅输出并进行选择。Bright Data 提供快速可靠的网页数据获取。
- Skyvern 使用 Bright Data 返回的详情访问 finditparts.com,随后导航网站,将所选商品加入购物车,并输出购物车详情和购物车 URL。
- 直接进入结账与支付。
前置条件
- 具备 Python 编程基础。可在此处下载 Python
- 一个可用的 Bright Data 账号。点击此处注册,并从欢迎邮件中获取你的 API key
- 具备 JSON 与 REST API 的基础知识
项目搭建
步骤 1:设置 Bright Data
按照“充分利用 Bright Data 的强大 API 服务”中针对你的用例的相同步骤,获取 Bright Data 的 API key、dataset ID 和 Google AI 模式 URL。
步骤 2:注册 Skyvern Cloud
- 访问 https://app.skyvern.com/ 并注册,可获得 5 美元免费额度。
- 让 Skyvern 代理(agent)运行一个任务体验效果。例如:导航到 Hacker News 首页并获取排名前 3 的帖子。
- 在历史记录中查看任务进度。状态为 Completed(已完成) 表示任务成功结束。
- 完成后,点击历史中的该任务查看输出、参数及其他详情。
现在 Skyvern 已设置完毕,你可以开始编写代码脚本。
步骤 3:在本机安装 Skyvern
3.1 创建虚拟环境
在目标项目文件夹中使用 Python 创建虚拟环境:
python -m venv .venv
激活虚拟环境:
.venvScriptsactivate
3.2 在任意设备上安装 Skyvern
pip install skyvern
如果安装遇到问题,可在 Windows 上使用 Ubuntu 终端。参考这篇帖子了解如何设置 Ubuntu 终端。
终端运行后,切换到目标目录并执行:
pip install uv创建虚拟环境:
uv venv venv然后安装 Skyvern:
uv pip install skyvern3.3 快速开始 Skyvern
安装完成后运行:
skyvern quickstart- 当提示“Would you like to run Skyvern locally or in the cloud?”时,输入“cloud”。
- 当提示“Enter Skyvern baseURL”时,直接按回车。
- 除 MCP 提示需输入“y”外,其余安装提示均输入“n”。
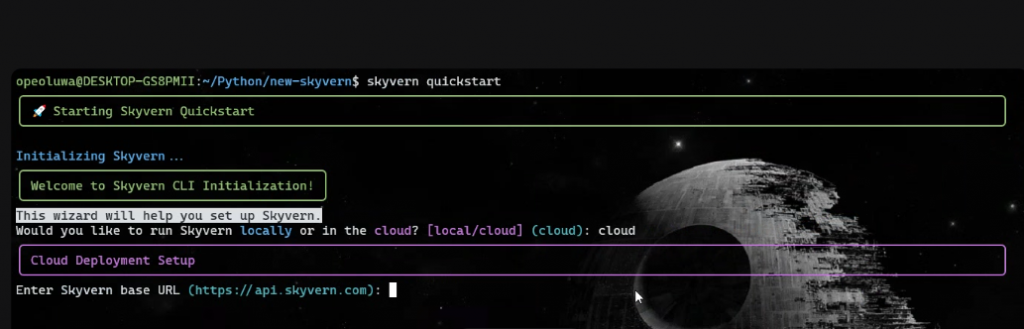
完成设置后,运行:
skyvern init创建一个名为 app.py 的 Python 脚本。
步骤 4:使用 Bright Data 获取产品详情
4.1 在 app.py 中使用以下代码通过 Bright Data 获取零件号:
import asyncio
import requests
import time
import json
def trigger_scraping_job(api_key, data):
"""
Trigger a Bright Data dataset job with a list of dicts containing url, prompt, country.
Returns the snapshot_id if successful.
"""
endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_mcswdt6z2elth3zqr2", # Your dataset ID
"include_errors": "true",
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(endpoint, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json().get("snapshot_id")
print(f"Request successful! Snapshot ID: {snapshot_id}")
return snapshot_id
else:
print(f"Request failed! Status: {response.status_code}")
print(response.text)
return None
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
"""
Poll the Bright Data snapshot endpoint until data is ready.
Save the JSON response to an output file.
"""
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Status: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY" # Your API key
# Match the curl JSON data structure exactly
data = [
{
"url": "https://google.com/aimode",
"prompt": "find the part number of a wheel seal from finditparts.com whose manufacturer is SKF",
"country": ""
}
]
snapshot_id = trigger_scraping_job(BRIGHT_DATA_API_KEY, data)
if snapshot_id:
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "product.json")提示词为:“find the part number of a wheel seal from finditparts.com whose manufacturer is SKF”。
这会生成一个 product.json 文件,其中包含 SKF 品牌的产品描述与零件号。
{
"url": "https://www.finditparts.com/products/16775486/skf-45093xt?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K16775486-L22",
"title": "www.finditparts.com",
"description": "SKF 45093XT Wheel Seal | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
{
"url": "https://www.finditparts.com/products/193780/cr-slash-skf-14115?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K193780-L1464",
"title": "www.finditparts.com",
"description": "SKF 14115 Wheel Seal | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
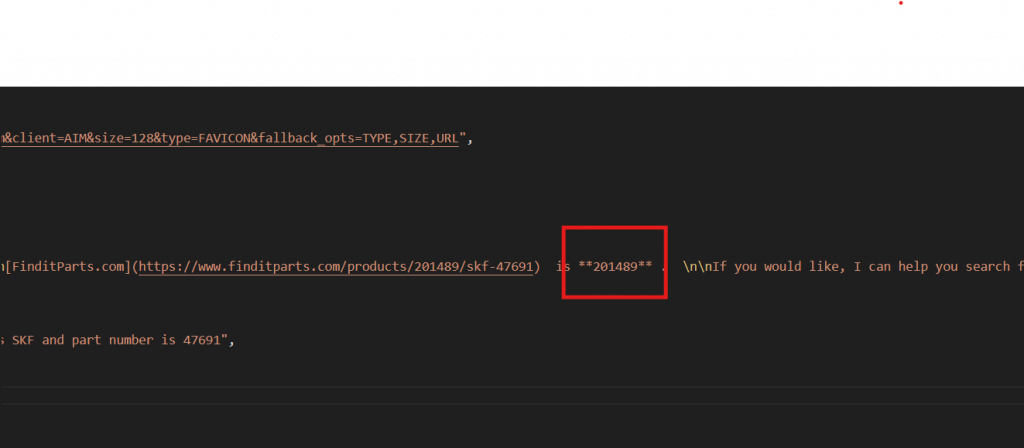
{接下来,选择你想要的零件号(位于 description 中),并使用如下提示词重新运行 Bright Data 代码:“Find the product ID for the SKF wheel seal with part number 47691”
# Match the curl JSON data structure exactly
data = [
{
"url": "https://google.com/aimode",
"prompt": "Find the product ID for the SKF wheel seal with part number 47691",
"country": ""
}
]Skyvern 需要该产品 ID,才能在 finditparts.com(一家汽车零部件电商网站)中将详情添加至购物车。
此过程会生成包含目标产品 ID 的 product.json 文件。
步骤 5:为 Skyvern 下达任务
首先访问 https://app.skyvern.com/tasks/create/finditparts。该 URL 是在 Skyvern 中创建任务的快捷方式。
在 Base Content 部分下点击 Advanced Settings,根据你的用例更新产品 ID 和提示词。
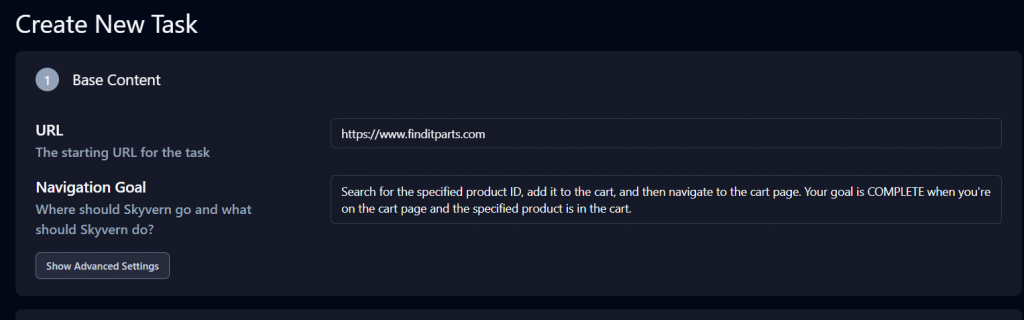
提示词为:“Search for the specified product ID, add it to the cart, and then navigate to the cart page. Your goal is COMPLETE when you’re on the cart page and the specified product is in the cart.”
下方的 Extraction 区域同样重要。将 Data Extraction Goal 修改为:“Extract the cart page URL and all product quantity information from the cart page.”
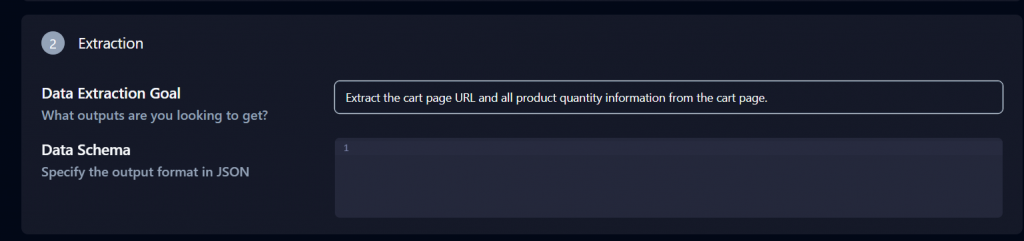
点击页面底部的 Copy API Command,将命令粘贴到终端并按下 Enter。
这样会在终端中生成一个 task_id,并在你的 Skyvern Cloud 中创建该任务实例。你可以在 History 中查看其状态(排队中、运行中或已完成)。
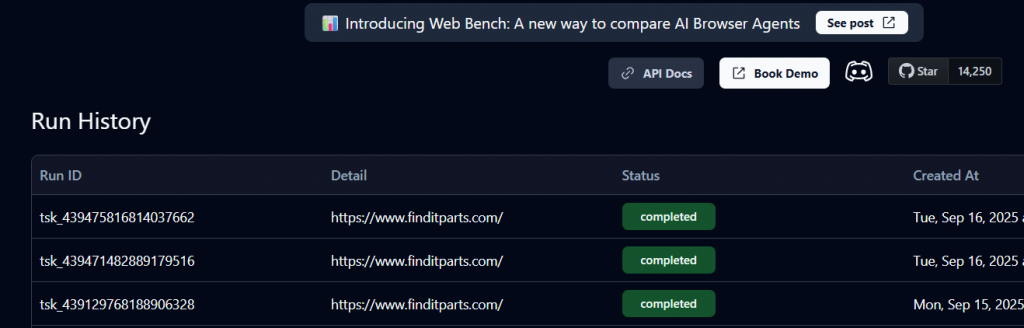
状态为 Completed(已完成) 表示任务结束。现在你可以查看 Skyvern 返回的购物车详情与产品 URL。
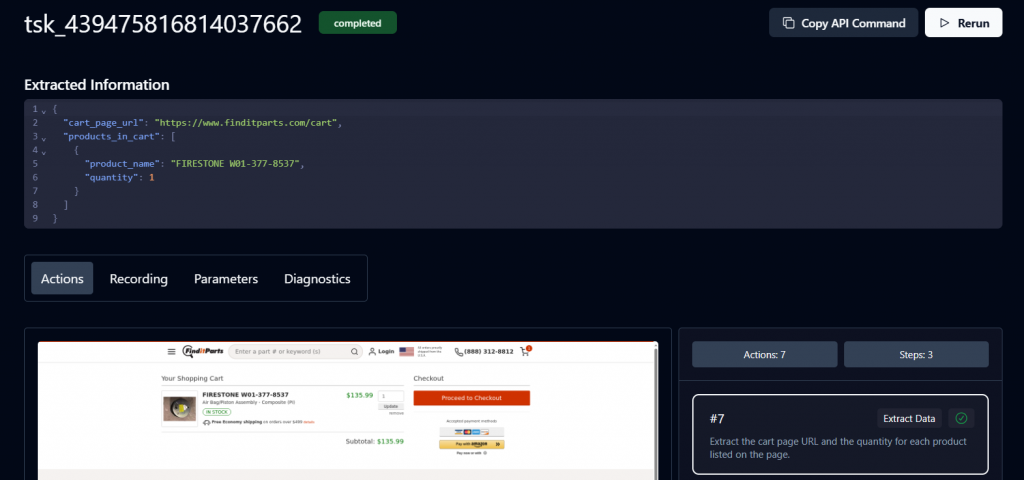
恭喜,你的工作流已完成。点击该 URL 即可继续支付。
Bright Data 将可选商品直接带到你的电脑面前,免去了手动在网上逐一查找的过程。你可以据此选择最佳商品,并借助 Skyvern 自动化完成购买流程。
下一步
你可以扩展此工作流,实现将多个商品加入购物车结账,并生成自然语言处理(NLP)的汇总结果。你还可以将工作流部署到云端进行持续监控,并与 Google 日历集成以跟踪折扣信息。
结论
在本教程中,你学习了如何将 Bright Data 的 Scraper API 与 Skyvern 结合,自动化在线查找与购买产品的流程。除 Scraper API 外,Bright Data 还提供可为你的 AI 代理赋能的其他工具,例如面向电商、社交媒体等场景的即用型数据集,以及用于高级多步自动化并可访问 40+ 专用工具的 Web MCP 服务器。这些产品组合让你能够轻松构建可高效采集、分析并对网页数据采取行动的 AI 驱动工作流。
即刻探索 Bright Data 的完整产品套件,为你的 AI 自动化项目赋能。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。




