

在本指南中,你将学到:
- LlamaIndex 是什么。
- 为何用 LlamaIndex 构建的 AI 代理应当具备网页搜索功能。
- 如何创建一个具备网页搜索能力的 LlamaIndex AI 代理。
让我们开始吧!
什么是 LlamaIndex?
LlamaIndex 是一个开源 Python 框架,用于构建由大型语言模型(LLM)驱动的应用。它在非结构化数据与 LLM 之间架起桥梁,尤其擅长在多种数据源上编排 LLM 工作流。
借助 LlamaIndex,你可以打造可投入生产的 AI 工作流与代理,进行信息检索、综合洞见、生成报告、执行自动化操作等。
截至撰写本文时,它是 AI 生态中增长最快的库之一,在 GitHub 上已获得超过 42k 颗星。
为何将网页搜索数据集成到 LlamaIndex AI 代理中
与其他 AI 代理框架相比,LlamaIndex 旨在解决 LLM 的一大局限:缺乏最新的现实世界知识。
为解决该问题,LlamaIndex 提供多种数据连接器,可从多来源摄取内容。那么,对 AI 代理来说,最有价值的数据源是什么?
答案可从LLM 的训练数据来源找到。成功的 LLM 绝大部分训练数据来自互联网——这是最大且多样性最高的公共数据源。
若想让你的 LlamaIndex 代理突破静态训练数据的限制,关键能力就是能够搜索网页并从中学习。因此,代理应能从搜索结果页面(“SERP”)提取结构化信息,再进行有意义的处理与学习。
问题在于,Google 近期加强了对简单爬虫脚本的打击,SERP 抓取变得更为困难。因此,你需要一个能与 LlamaIndex 集成并简化此流程的工具——这正是 LlamaIndex 的 Bright Data 集成大显身手的地方!
Bright Data 处理了复杂的 SERP 抓取工作。通过其 search_engine 工具,你的 LlamaIndex 代理可以执行搜索查询,并以 Markdown 或 JSON 格式接收结构化结果。
这正是让 AI 代理随时准备回答问题所必需的能力。下一章节将展示该集成如何运作!
使用 Bright Data 工具构建可搜索网页的 LlamaIndex 代理
本分步指南展示如何通过 Python 与 LlamaIndex 构建一个具备网页搜索能力的 AI 代理。
通过集成 Bright Data,你将让代理访问最新、具上下文且丰富的网页搜索数据。更多详情参见 官方文档。
按照下列步骤,创建由 Bright Data 提供支持的 AI SERP 代理吧!
前置条件
要跟随本教程,你需要:
- 在本机安装 Python 3.9 或更高版本(建议使用最新版本)。
- 一个 Bright Data API 密钥,用于连接 Bright Data 的 SERP API。
- 一个受支持的 LLM API 密钥(本指南示例使用 Gemini,可免费通过 API 集成;你也可使用 LlamaIndex 支持的任何 LLM 提供商)。
如果你还没有 Gemini 或 Bright Data 的 API 密钥,不必担心,下一步将演示如何创建二者。
步骤 #1:初始化 Python 项目
首先打开终端,为 LlamaIndex AI 代理项目创建一个新文件夹:
mkdir llamaindex-bright-data-serp-agentllamaindex-bright-data-serp-agent/ 将存放所有使用 Bright Data 实现网页搜索功能的 AI 代理代码。
接着进入项目目录,并在其中创建一个 Python 虚拟环境:
cd llamaindex-bright-data-serp-agent
python -m venv venv现在,用你喜欢的 Python IDE 打开项目文件夹。推荐使用 Visual Studio Code(安装 Python 扩展)或 PyCharm Community Edition。
在项目根目录创建一个名为 agent.py 的新文件。项目结构应如下所示:
llamaindex-bright-data-serp-agent/
├── venv/
└── agent.py在终端中激活虚拟环境。Linux 或 macOS 上执行:
source venv/bin/activateWindows 上执行:
venv/Scripts/activate接下来将逐步安装所需包;如需一次性安装,可运行:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-google-genai llama-index注意:本教程使用 Gemini 作为 LlamaIndex 的 LLM 提供商,因此安装了 llama-index-llms-google-genai。若使用其他提供商,请安装相应的集成包。
干得好!Python 开发环境已就绪,可以使用 Bright Data 的 SERP 集成构建 AI 代理了。
步骤 #2:集成环境变量读取
你的 LlamaIndex 代理将通过 API 连接 Gemini 与 Bright Data 等外部服务。出于安全考虑,切勿将 API 密钥硬编码在代码中,而应使用环境变量。
在激活的虚拟环境中安装 python-dotenv 以便管理环境变量:
pip install python-dotenv然后在 agent.py 顶部添加以下代码以加载 .env 文件中的变量:
from dotenv import load_dotenv
load_dotenv()load_dotenv() 会在项目根目录查找 .env 并加载其值到环境中。
现在,在 agent.py 同级创建 .env 文件。新的项目结构如下:
llamaindex-bright-data-serp-agent/
├── venv/
├── .env # <-------------
└── agent.py太棒了!你已为第三方服务的敏感凭据配置了安全管理方式。
继续初始化,在 .env 中填入所需环境变量!
步骤 #3:配置 Bright Data
要通过官方集成包在 LlamaIndex 中调用 Bright Data SERP API,你首先需要:
- 在 Bright Data 仪表盘中启用 Web Unlocker 方案。
- 获取你的 Bright Data API 令牌。
按照下列步骤完成设置!
如果你还没有 Bright Data 账户,请先注册;已有账户则直接登录。在仪表盘点击“Get proxy products”按钮:
随后你将进入“Proxies & Scraping Infrastructure”页面:
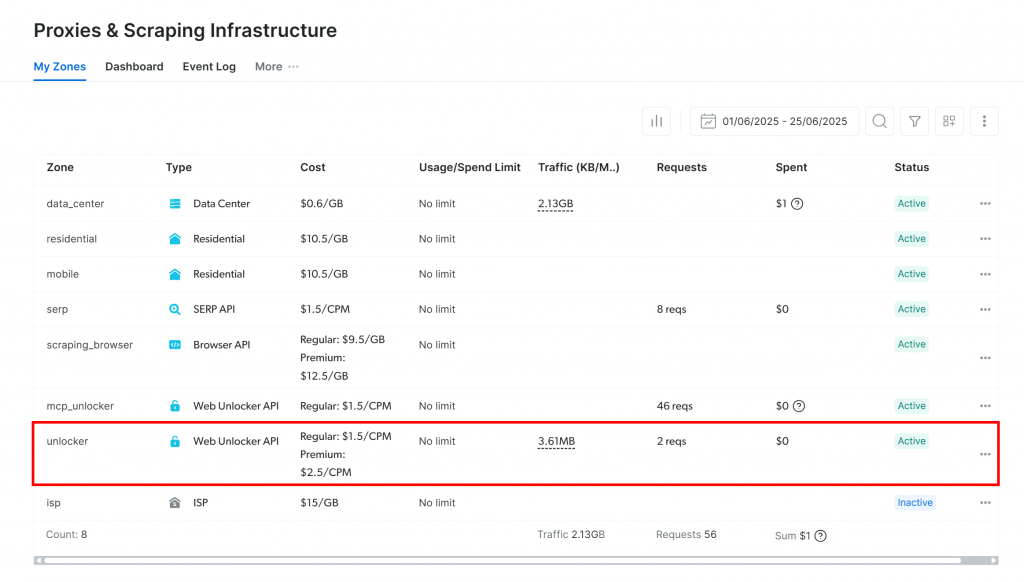
若已看到一个激活状态的 Web Unlocker API 分区(如上图所示),即可使用。记下分区名称(例如 unlocker),稍后代码中将用到。
如果还没有 Web Unlocker 分区,向下滚动到 “Web Unlocker API” 部分,点击 “Create zone” 按钮:
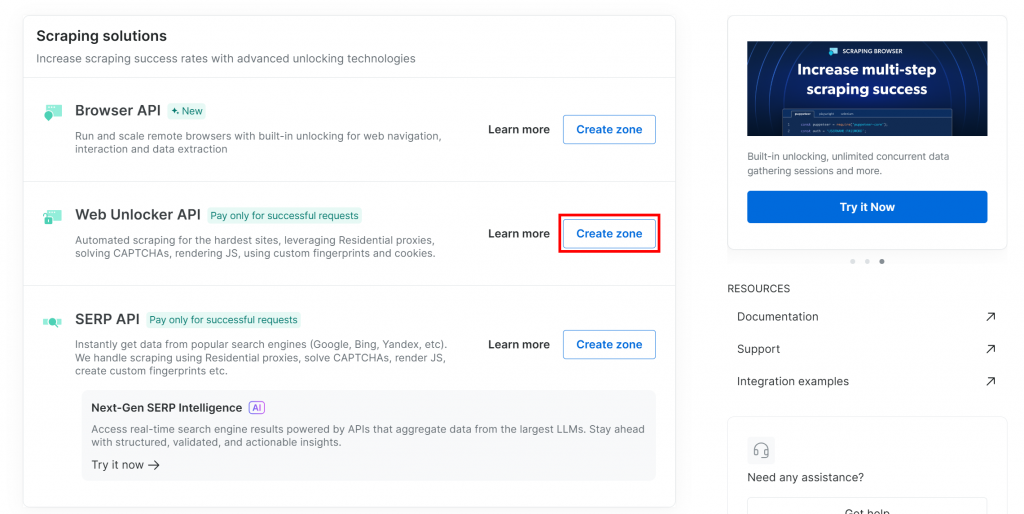
为什么使用 Web Unlocker API 而非专用 SERP API?
LlamaIndex 的 Bright Data SERP 集成通过 Web Unlocker API 运作。正确配置后,Web Unlocker 与专用 SERP API 功能等同。因此,只需创建 Web Unlocker 分区,即自动可用 SERP API。
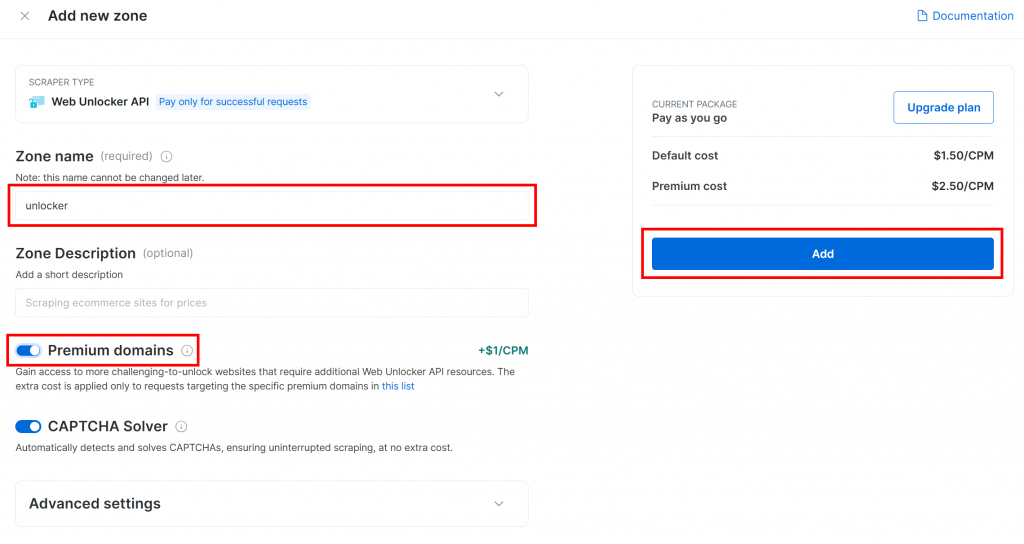
为新分区命名(如 unlocker),可启用高级功能以提升性能,然后点击 “Add”:
创建完成后会跳转到分区配置页:
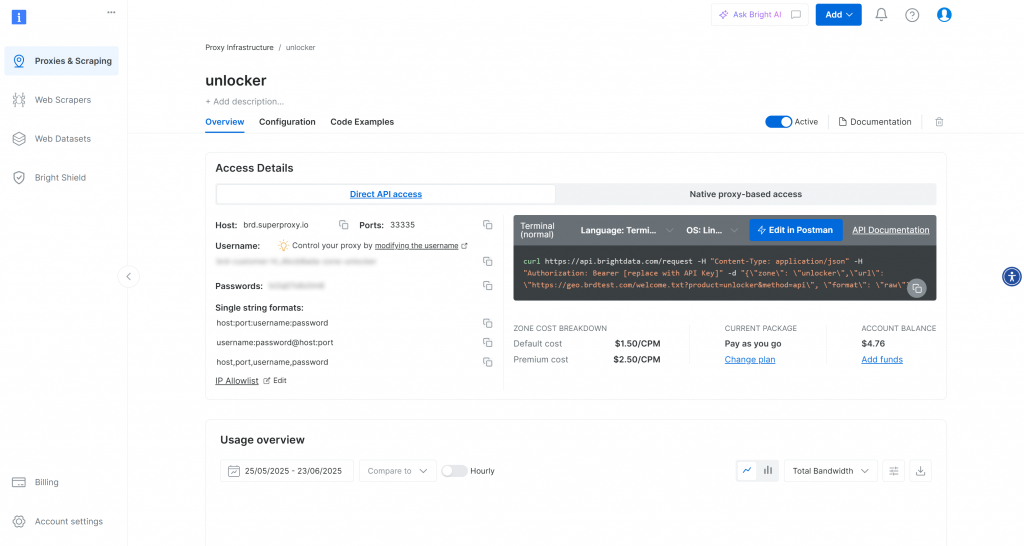
确保激活开关已置为“Active”,表示分区可用。
然后按照 Bright Data 官方文档生成 API key,并在 .env 中安全存储:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"将 <YOUR_BRIGHT_DATA_API_KEY> 替换为真实值。
太好了!接下来在 LlamaIndex 脚本中配置 Bright Data SERP 工具。
步骤 #4:接入 Bright Data LlamaIndex SERP 工具
在 agent.py 中,首先从环境变量读取 Bright Data API key:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")别忘了导入 Python 标准库 os:
import os在激活的虚拟环境中安装 LlamaIndex Bright Data 工具包:
pip install llama-index-tools-brightdata然后在 agent.py 中导入 BrightDataToolSpec:
from llama_index.tools.brightdata import BrightDataToolSpec创建 BrightDataToolSpec 实例,传入 API key 与 Web Unlocker 分区名:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True,
)如果分区名不是 unlocker,请替换为你的实际名称。verbose=True 在开发期间可查看日志。
BrightDataToolSpec 提供多种工具,此处聚焦 search_engine,可查询 Google、Bing、Yandex 等并返回 Markdown 或 JSON 结果。
仅提取该工具:
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])数组参数用于过滤,仅保留名为 search_engine 的工具。
注意:默认情况下,LlamaIndex 会自动选择合适工具,因此过滤并非必需。本教程专注 Bright Data 的 SERP 功能,为清晰起见仅保留该工具。
太好了!Bright Data 已集成完成,接下来为 LLM 建立连接。
步骤 #5:连接 LLM 模型
本步骤示例使用 Gemini 作为 LLM 提供商,其中部分模型 API 可免费使用。
首先安装 Gemini 集成包:
pip install llama-index-llms-google-genai在 agent.py 导入 GoogleGenAI:
from llama_index.llms.google_genai import GoogleGenAI初始化 Gemini LLM:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)此示例使用 gemini-2.5-flash 模型,可根据需要选择其他支持的 Gemini 模型。
GoogleGenAI 默认查找环境变量 GEMINI_API_KEY 并使用其值连接 Gemini API。
在 .env 中添加:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"将占位符替换为真实 key。若尚未获取,请按 官方指南申请。
注意:若使用其他 LLM 提供商,请参见 官方文档完成设置。
完成!核心组件已就位,可继续定义代理。
步骤 #6:定义 LlamaIndex 代理
先安装主包:
pip install llama-index在 agent.py 导入 FunctionAgent:
from llama_index.core.agent.workflow import FunctionAgentFunctionAgent 能与外部工具交互,如先前配置的 Bright Data SERP 工具。
初始化代理:
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)至此,代理可根据用户输入调用 Bright Data SERP 工具实时搜索网页。system_prompt 定义代理角色。
很好!下一步实现交互式 REPL。
步骤 #7:构建 REPL
REPL(Read-Eval-Print Loop)是交互式编程模式。
本场景中的循环:
- 你描述任务。
- 代理执行任务,必要时在线搜索。
- 结果显示在终端。
循环持续,直到输入 "exit"。
在 agent.py 添加异步函数处理 REPL:
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")此 REPL 函数:
- 通过
input()接收来自命令行的用户输入。 - 使用由 Gemini 和 Bright Data 提供支持的 LlamaIndex 代理,通过
agent.run()处理该输入。 - 将响应输出到控制台。
由于 agent.run() 是异步的,REPL 逻辑必须放在 async 函数中。在文件末尾像下面这样运行:
if __name__ == "__main__":
asyncio.run(main())别忘了导入 asyncio:
import asyncio大功告成!带有 SERP 抓取工具的 LlamaIndex AI 代理已就绪。
步骤 #8:整合并运行 AI 代理
agent.py 完整内容应如下:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent.workflow import FunctionAgent
import asyncio
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True, # Useful while developing
)
# Get only the "search_engine" (SERP scraping) tool
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)
# Async REPL loop
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")
if __name__ == "__main__":
asyncio.run(main())用命令运行代理:
python agent.py脚本启动后,你将在终端看到提示:

尝试提问需要最新信息的问题,例如:
Write a short Markdown report on the new AI protocols, including some real-world links for further reading.为完成任务,代理会搜索最新资料。
结果如下:
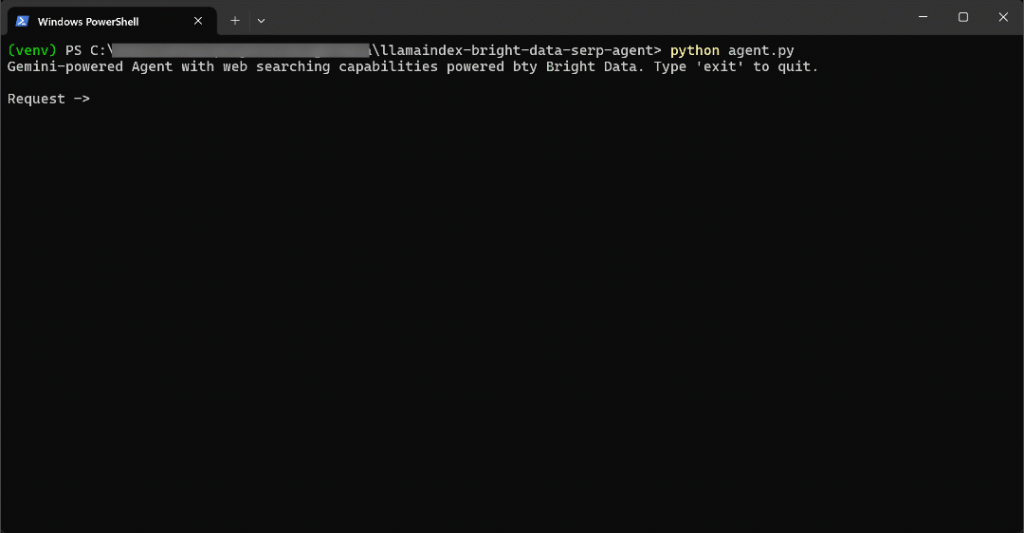
速度相当快,让我们拆解一下发生了什么:
- 代理检测到需要搜索“new AI protocols”,并通过
search_engine工具调用 Bright Data SERP API,使用以下输入 URL:https://www.google.com/search?q=new%20AI%20protocols&num=10&brd_json=1。 - 该工具从 Bright Data 的 Google Search API 异步获取 JSON 格式的 SERP 数据。
- 代理将 JSON 响应传递给 Gemini LLM。
- Gemini 处理最新数据,生成包含相关链接的清晰、准确的 Markdown 报告。
在此示例中,AI 代理返回:
## New AI Protocols: A Brief Report
The rapid advancement of Artificial Intelligence has led to the emergence of new protocols designed to enhance interoperability, communication, and data handling among AI systems and with external data sources. These protocols aim to standardize how AI agents interact, leading to more scalable and integrated AI deployments.
Here are some of the key new AI protocols:
### 1. Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard that facilitates secure, two-way connections between AI-powered tools and various data sources. It fundamentally changes how AI assistants interact with the digital world by allowing them to access and utilize external information more effectively. This protocol is crucial for enabling AI models to communicate with external data sources and for building more capable and context-aware AI applications.
**Further Reading:**
* **Introducing the Model Context Protocol:** [https://www.anthropic.com/news/model-context-protocol](https://www.anthropic.com/news/model-context-protocol)
* **How A Simple Protocol Is Changing Everything About AI:** [https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/](https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/)
* **The New Model Context Protocol for AI Agents:** [https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/](https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/)
* **Model Context Protocol: The New Standard for AI Interoperability:** [https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/](https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/)
* **Hot new protocol glues together AI and apps:** [https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source](https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source)
### 2. Agent2Agent Protocol (A2A)
The Agent2Agent Protocol (A2A) is a cross-platform specification designed to enable AI agents to communicate with each other, securely exchange information, and coordinate actions. This protocol is vital for fostering collaboration among different AI agents, allowing them to work together on complex tasks and delegate responsibilities across various enterprise systems.
**Further Reading:**
* **Announcing the Agent2Agent Protocol (A2A):** [https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
* **What Every AI Engineer Should Know About A2A, MCP & ACP:** [https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742](https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742)
* **What a new AI protocol means for journalists:** [https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193](https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193)
### 3. Agent Communication Protocol (ACP)
The Agent Communication Protocol (ACP) is an open standard specifically for agent-to-agent communication. Its purpose is to transform the current landscape of siloed AI agents into interoperable agentic systems, promoting easier integration and collaboration between them. ACP provides a standardized messaging framework for structured communication.
**Further Reading:**
* **MCP, ACP, and Agent2Agent set standards for scalable AI:** [https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
* **What is Agent Communication Protocol (ACP)?** [https://www.ibm.com/think/topics/agent-communication-protocol](https://www.ibm.com/think/topics/agent-communication-protocol)
* **MCP vs A2A vs ACP: AI Protocols Explained:** [https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/](https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/)
These emerging protocols are crucial steps towards a more interconnected and efficient AI ecosystem, enabling more sophisticated and collaborative AI applications across various industries.请注意,AI 代理的响应包含 Gemini 上次训练之后发布的最新协议和最新链接,这凸显了集成实时网页搜索功能的价值。
更具体地说,响应中的上下文链接与在 Google 上搜索 “new ai protocols” 时得到的结果高度一致:
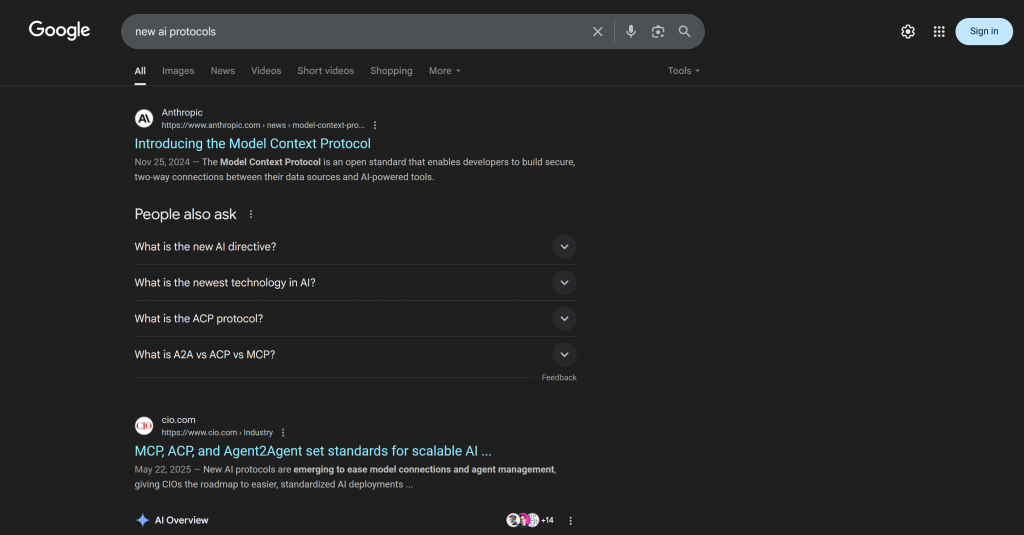
请注意,响应中包含的许多链接与实际 “new AI protocols” SERP(至少在撰写时)中的链接相同。
就这样!你现在拥有一个由 Bright Data 提供搜索引擎抓取能力的 LlamaIndex AI 代理。
步骤 #9:后续步骤
当前的 LlamaIndex SERP AI 代理只是一个简单示例,仅使用了 Bright Data 的 search_engine 工具。
在更高级的场景中,你可能不想将代理限制为单一工具。更好的做法是让代理访问所有可用工具,并编写清晰的系统提示,帮助 LLM 根据目标选择合适的工具。
例如,你可以进一步扩展提示,让代理:
- 执行多个搜索查询。
- 从 SERP 结果中选择排名前 N 的链接。
- 访问这些页面并以 Markdown 格式抓取其内容。
- 学习这些信息,以生成更丰富、更详细的输出。
关于如何整合所有可用工具的更多指导,请参阅我们的教程 使用 LlamaIndex 和 Bright Data 构建 AI 代理。
结论
在本文中,你学习了如何使用 LlamaIndex 构建能够通过 Bright Data 搜索网络的 AI 代理。该集成使你的代理能够在 Google、Bing、Yandex 等主要搜索引擎上执行查询。
请记住,此处展示的示例只是起点。如果你计划开发更高级的代理,就需要强大的工具来检索、验证和转换实时网络数据,而这正是 Bright Data 面向代理的 AI 基础设施 所提供的。
立即创建免费的 Bright Data 账户,开始探索我们的代理式 AI 数据工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



