
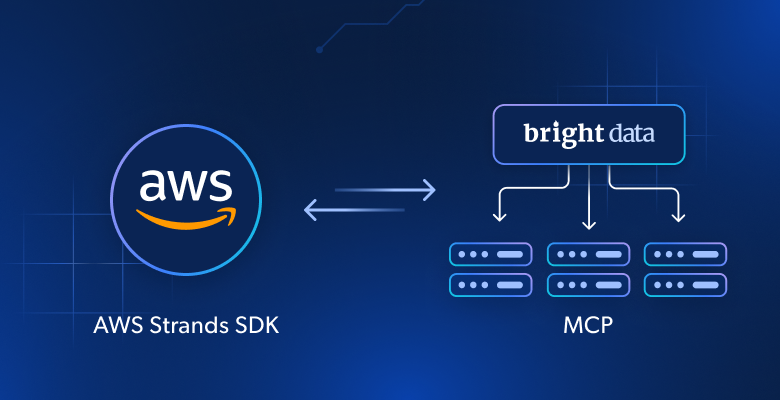
由大语言模型(LLM)驱动的 AI 代理能够进行推理和决策,但受限于其训练数据。要构建真正有用的代理,你需要将其连接到实时网页数据。本文将展示如何将 AWS Strands SDK 与 Bright Data 的 Web MCP 服务器相结合,创建能够访问并分析在线实时网页数据的自主 AI 代理。
在本指南中,你将学到:
- 什么是 AWS Strands SDK,以及它作为 AI 代理构建框架的独特之处
- 为什么 AWS Strands SDK 与 Bright Data 的 Web MCP 服务器是构建具备网页感知能力代理的完美组合
- 如何将 AWS Strands 与 Bright Data 的 Web MCP 集成,创建自主的竞争情报代理
- 如何构建代理,使其能根据目标自主决定使用哪些网页抓取工具
让我们开始吧!
什么是 AWS Strands SDK?
AWS Strands SDK 是 AWS 开发的一款轻量级、代码优先的框架,可用极少的代码构建 AI 代理。它采用模型驱动的方法,让代理能力源自模型的决策,而非硬编码逻辑。
与其他 AI 代理框架相比,AWS Strands SDK 强调简单、灵活和生产可用性。其主要特性包括:
- 模型无关:支持包括 AWS Bedrock、OpenAI、Anthropic 等在内的多家 LLM 提供商
- 原生 MCP 支持:内置与模型上下文协议(MCP)的集成,可访问 1000+ 预构建工具
- 最少代码:仅需几行代码即可构建复杂代理
- 生产就绪:开箱即用的错误处理、重试机制与可观测性
- 代理循环:实现“感知-推理-行动”的循环,用于自主决策
- 多代理支持:提供编排原语以协调多个专用代理
- 状态管理:跨交互的会话与上下文管理
理解 AWS Strands SDK
核心架构
AWS Strands SDK 采用简洁的三组件设计,在不牺牲能力的前提下简化了代理开发。
这种方法让你用极少的代码构建智能代理,否则可能需要成千上万行代码:
- 模型组件:作为“大脑”,可与多个 AI 提供商协作
- 工具集成:通过 MCP 服务器将代理连接到外部系统
- 基于提示的任务:用自然语言而非代码定义代理行为
代理循环实现
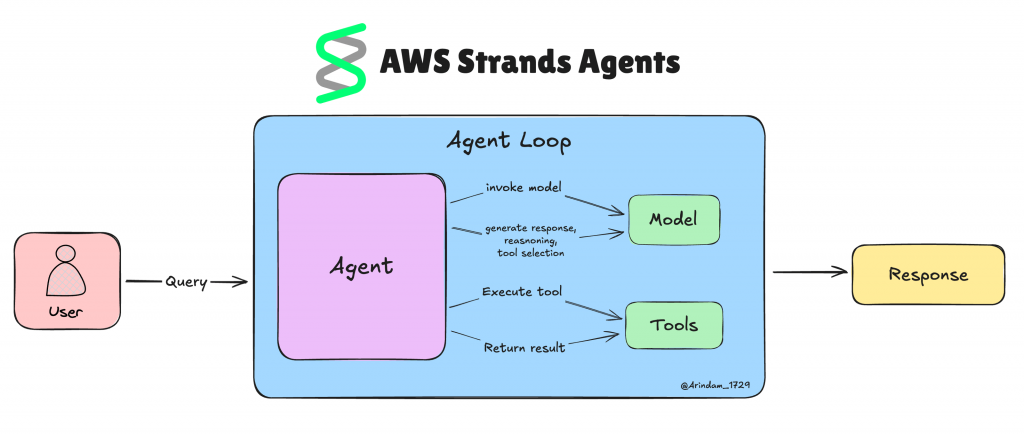
代理循环让 Strands 代理更“聪明”。这是一个持续的循环:代理感知发生了什么、进行思考并采取行动,从而能独立处理复杂任务。
Strands 的改变在于让 AI 模型决定下一步要做什么。无需为每种可能情况写死逻辑,模型会基于当前情境自行判断。
实际流程如下:
- 你的代理收到用户任务。
- 模型查看当前情况以及可用的工具。
- 它决定是使用某个工具、请求澄清,还是直接给出最终答案。
- 若使用工具,Strands 会运行该工具并将结果反馈给模型。
- 这个循环持续,直到任务完成或需要人工协助。
想象构建一个价格监控工具。用传统编码方式,你需要编写用于检查竞争对手网站、处理不同页面布局、管理错误、收集结果、设置告警阈值的逻辑。
使用 Strands,你只需提供网页抓取工具,并告诉代理:“监控这些竞争对手网站,当价格变动超过 5% 时,用摘要提醒我。”模型会自行决定检查哪些网站、如何处理问题、何时发送提醒。
为什么将 AWS Strands SDK 与 MCP 服务器结合用于网页数据获取
用 AWS Strands 构建的 AI 代理会继承其底层 LLM 的局限——尤其是无法访问实时信息。当需要当前数据(如竞争对手价格、市场状况或客户情绪)时,这可能会导致过时或不准确的响应。
这就是 Bright Data 的 Web MCP 服务器发挥作用的地方。该 MCP 服务器基于 Node.js 构建,并与 Bright Data 的一系列面向 AI 的数据获取工具集成。这些工具可以让你的代理:
- 访问任意网站内容,即使有反爬机制
- 查询来自 120+ 热门网站的结构化数据集
- 同时在多个搜索引擎上进行检索
- 实时与动态网页交互
截至目前,该 MCP 服务器包含 40 个专用工具,可借助 Web Scraper API 从 Amazon、LinkedIn、TikTok 等网站收集结构化数据。
现在,让我们看看如何在 AWS Strands SDK 中使用这些 MCP 工具!
如何在 Python 中将 AWS Strands SDK 与 Bright Data MCP 服务器集成
本节你将学习如何使用 AWS Strands SDK 构建一个具备来自 Web MCP 服务器的实时数据抓取与检索能力的 AI 代理。
我们将以构建一个自主的竞争情报代理为例,它可以自主分析市场和竞争对手。代理将基于目标自行决定使用哪些工具,从而展示代理循环的威力。
按照以下分步指南,使用 AWS Strands SDK 构建你的 Claude + Bright Data MCP 加持的 AI 代理!
先决条件
要复现以下代码示例,请确保你具备:
软件要求:
- Python 3.10 或更高版本
- Node.js(建议使用最新 LTS 版本)
- Python IDE(VS Code(含 Python 扩展)或 PyCharm)
账号要求:
- Bright Data 账户(免费层每月提供 5,000 次请求)
- Anthropic 账户,并拥有 Claude API 访问权限与额度
背景知识(有帮助但非必需):
- 对 MCP 工作原理的基本理解
- 熟悉 AI 代理及其能力
- 具备 Python 异步编程的基础知识
步骤一:创建你的 Python 项目
打开终端并为你的项目创建新文件夹:
mkdir strands-mcp-agent
cd strands-mcp-agent创建 Python 虚拟环境:
python -m venv venv激活虚拟环境:
# On Linux/macOS:
source venv/bin/activate
# On Windows:
venvScriptsactivate创建主 Python 文件:
touch agent.py你的文件夹结构应如下所示:
strands-mcp-agent/
├── venv/
└── agent.py一切就绪!你现在已拥有一个可用于构建具备网页数据访问能力的 AI 代理的 Python 环境。
步骤二:安装 AWS Strands SDK
在已激活的虚拟环境中,安装所需包:
pip install strands-agents python-dotenv这将安装:
strands-agents:用于构建 AI 代理的 AWS Strands SDKpython-dotenv:用于安全管理环境变量
接着,在 agent.py 文件中加入以下导入:
from strands import Agent
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.stdio import stdio_client, StdioServerParameters很好!你现在可以使用 AWS Strands SDK 来构建代理了。
步骤三:设置环境变量
在项目文件夹中创建 .env 文件以安全管理 API 密钥:
touch .env将你的 API 密钥添加到 .env 文件:
# Anthropic API for Claude models
ANTHROPIC_API_KEY=your_anthropic_key_here
# Bright Data credentials for web scraping
BRIGHT_DATA_API_KEY=your_bright_data_token_here在 agent.py 中加载环境变量:
import os
from dotenv import load_dotenv
load_dotenv()
# Read API keys
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")搞定!你现在可以从 .env 文件安全加载 API 密钥了。
步骤四:安装并测试 Bright Data MCP 服务器
通过 npm 全局安装 Bright Data Web MCP:
npm install -g @brightdata/mcp用你的 API 密钥测试是否可用:
# On Linux/macOS:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp
# On Windows PowerShell:
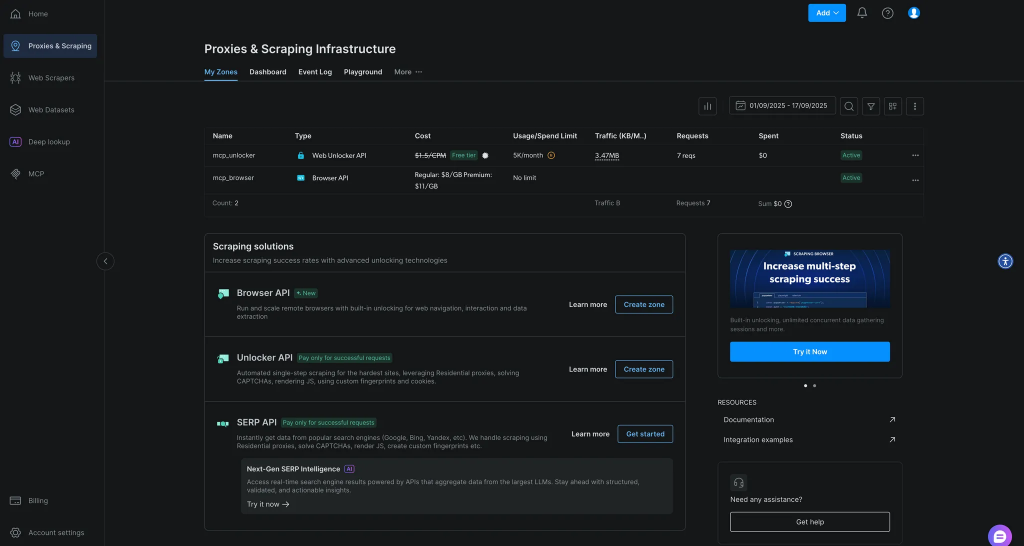
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp如果成功,你将看到 MCP 服务器启动的日志。首次运行会在你的 Bright Data 账户中自动创建两个 Zone:
mcp_unlocker:用于 Web Unlockermcp_browser:用于 Browser API
你可以在 Bright Data 控制台的“Proxies & Scraping Infrastructure”中查看。
太棒了!Web MCP 服务器运行良好。
步骤五:初始化 Strands 模型
在 agent.py 中配置 Anthropic Claude 模型:
# Initialize Anthropic model
model = AnthropicModel(
model_id="claude-3-opus-20240229", # You can also use claude-3-sonnet for lower cost
max_tokens=4096,
params={"temperature": 0.3}
)
# Set the API key
os.environ["ANTHROPIC_API_KEY"] = ANTHROPIC_API_KEY这将把 Claude 配置为你的代理所用的 LLM,并设置合适的参数以获得稳定、聚焦的响应。
步骤六:连接到 Web MCP 服务器
创建 MCP 客户端配置以连接 Bright Data 工具:
import asyncio
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def connect_mcp_tools():
"""Connect to Bright Data MCP server and discover tools"""
logger.info("Connecting to Bright Data MCP...")
# Configure connection to Bright Data hosted MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={"API_TOKEN": BRIGHT_DATA_API_KEY, "PRO_MODE": "true"}
)
# Create MCP client
mcp_client = MCPClient(lambda: stdio_client(server_params))
# Discover available tools
with mcp_client:
tools = mcp_client.list_tools_sync()
logger.info(f"📦 Discovered {len(tools)} MCP tools")
for tool in tools:
logger.info(f" - {tool.tool_name}")
return mcp_client, tools这将建立与 Bright Data MCP 服务器的连接,并发现所有可用的网页抓取工具。
步骤七:定义竞争情报代理
创建一个带有竞争情报专用提示词的代理:
def create_agent(model, tools):
"""Create a competitive intelligence agent with web data access"""
system_prompt = """You are an expert competitive intelligence analyst with access to powerful web data tools through MCP.
## Your Mission
Conduct comprehensive market and competitive analysis using real-time web data.
## Available MCP Tools
You have access to these Bright Data MCP tools:
- search_engine: Scrape search results from Google, Bing or Yandex
- scrape_as_markdown: Extract content from any webpage with CAPTCHA bypass
- search_engine_batch: Run multiple searches simultaneously
- scrape_batch: Scrape multiple webpages in parallel
## Autonomous Analysis Workflow
When given an analysis task, autonomously:
1. Decide which tools to use based on the goal
2. Gather comprehensive data from multiple sources
3. Synthesize findings into actionable insights
4. Provide specific strategic recommendations
Be proactive in tool selection - you have full autonomy to use any combination of tools."""
return Agent(
model=model,
tools=tools,
system_prompt=system_prompt
)这将创建一个专注于竞争情报的代理,并具备自主决策能力。
步骤八:启动你的代理
创建主执行函数来运行你的代理:
async def main():
"""Run the competitive intelligence agent"""
print("🚀 AWS Strands + Bright Data MCP Competitive Intelligence Agent")
print("=" * 70)
try:
# Connect to MCP tools
mcp_client, tools = await connect_mcp_tools()
# Create the agent
agent = create_agent(model, tools)
print("n✅ Agent ready with web data access!")
print("n📊 Starting Analysis...")
print("-" * 40)
# Example: Analyze Tesla's competitive position
prompt = """
Analyze Tesla's competitive position in the electric vehicle market.
Research:
- Current product lineup and pricing strategy
- Main competitors and their offerings
- Recent strategic announcements
- Market share and positioning
Use web scraping tools to gather real-time data from tesla.com and search results.
"""
# Run analysis with MCP context
with mcp_client:
result = await agent.invoke_async(prompt)
print("n📈 Analysis Results:")
print("=" * 50)
print(result.content)
print("n✅ Analysis complete!")
except Exception as e:
logger.error(f"Error: {e}")
print(f"n❌ Error: {e}")
if __name__ == "__main__":
asyncio.run(main())任务完成!你的代理已准备好执行自主的竞争分析。
步骤九:整合全部代码
以下是 agent.py 的完整代码:
import asyncio
import os
import logging
from dotenv import load_dotenv
from strands import Agent
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.stdio import stdio_client, StdioServerParameters
# Load environment variables
load_dotenv()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Read API keys
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Initialize Anthropic model
model = AnthropicModel(
model_id="claude-3-opus-20240229",
max_tokens=4096,
params={"temperature": 0.3}
)
# Set API key
os.environ["ANTHROPIC_API_KEY"] = ANTHROPIC_API_KEY
async def connect_mcp_tools():
"""Connect to Bright Data MCP server and discover tools"""
logger.info("Connecting to Bright Data MCP...")
# Configure connection to Bright Data hosted MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={"API_TOKEN": BRIGHT_DATA_API_KEY, "PRO_MODE": "true"}
)
# Create MCP client
mcp_client = MCPClient(lambda: stdio_client(server_params))
# Discover available tools
with mcp_client:
tools = mcp_client.list_tools_sync()
logger.info(f"📦 Discovered {len(tools)} MCP tools")
for tool in tools:
logger.info(f" - {tool.tool_name}")
return mcp_client, tools
def create_agent(model, tools):
"""Create a competitive intelligence agent with web data access"""
system_prompt = """You are an expert competitive intelligence analyst with access to powerful web data tools through MCP.
## Your Mission
Conduct comprehensive market and competitive analysis using real-time web data.
## Available MCP Tools
You have access to these Bright Data MCP tools:
- search_engine: Scrape search results from Google, Bing or Yandex
- scrape_as_markdown: Extract content from any webpage with CAPTCHA bypass
- search_engine_batch: Run multiple searches simultaneously
- scrape_batch: Scrape multiple webpages in parallel
## Autonomous Analysis Workflow
When given an analysis task, autonomously:
1. Decide which tools to use based on the goal
2. Gather comprehensive data from multiple sources
3. Synthesize findings into actionable insights
4. Provide specific strategic recommendations
Be proactive in tool selection - you have full autonomy to use any combination of tools."""
return Agent(
model=model,
tools=tools,
system_prompt=system_prompt
)
async def main():
"""Run the competitive intelligence agent"""
print("🚀 AWS Strands + Bright Data MCP Competitive Intelligence Agent")
print("=" * 70)
try:
# Connect to MCP tools
mcp_client, tools = await connect_mcp_tools()
# Create the agent
agent = create_agent(model, tools)
print("n✅ Agent ready with web data access!")
print("n📊 Starting Analysis...")
print("-" * 40)
# Example: Analyze Tesla's competitive position
prompt = """
Analyze Tesla's competitive position in the electric vehicle market.
Research:
- Current product lineup and pricing strategy
- Main competitors and their offerings
- Recent strategic announcements
- Market share and positioning
Use web scraping tools to gather real-time data from tesla.com and search results.
"""
# Run analysis with MCP context
with mcp_client:
result = await agent.invoke_async(prompt)
print("n📈 Analysis Results:")
print("=" * 50)
print(result)
print("n✅ Analysis complete!")
except Exception as e:
logger.error(f"Error: {e}")
print(f"n❌ Error: {e}")
if __name__ == "__main__":
asyncio.run(main())用以下命令运行 AI 代理:
python agent.py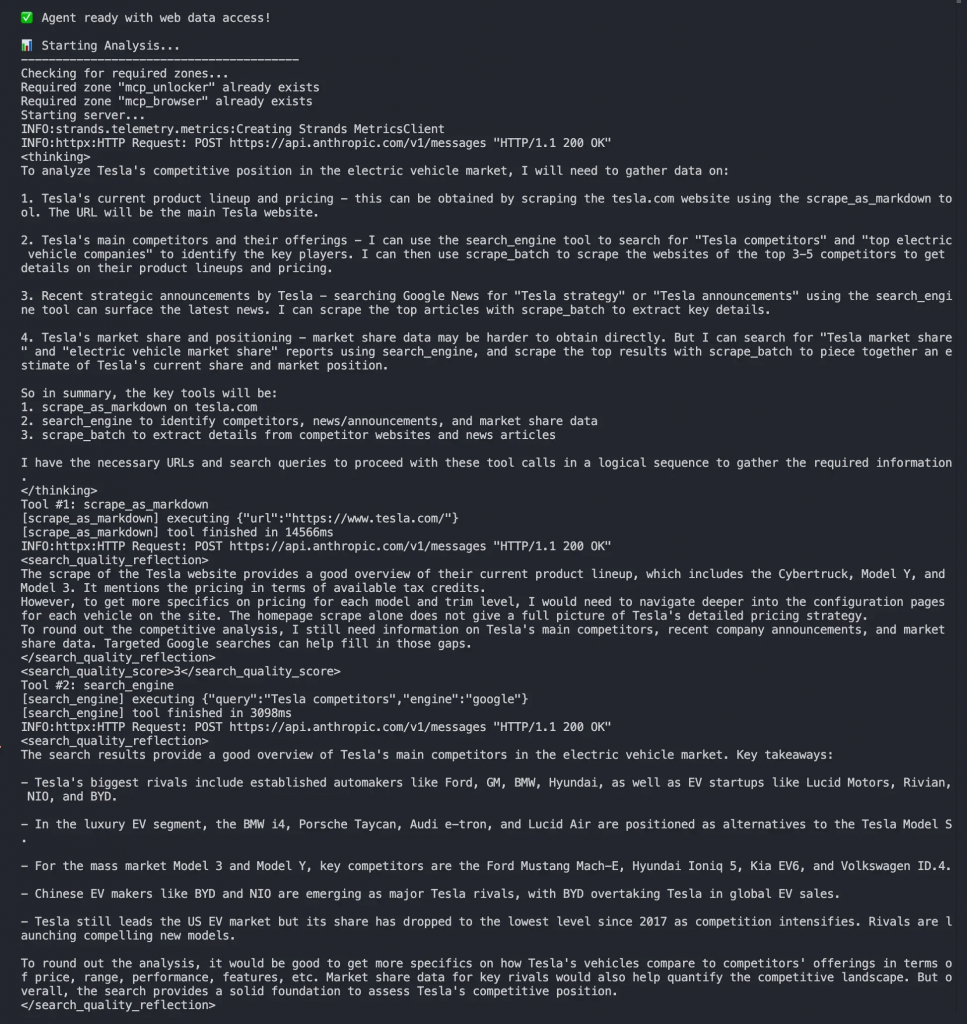
在终端中,你应能看到如下输出:
- MCP 连接建立
- 发现可用的 Bright Data 工具
- 代理自主选择要使用的工具
- 从 tesla.com 和搜索结果收集实时数据
- 基于当前数据生成全面的竞争分析
代理会自主决定:
- 使用
search_engine查找关于特斯拉及其竞争对手的信息 - 使用
scrape_as_markdown从 tesla.com 提取数据 - 整合多个数据源进行全面分析
搞定!你已成功构建出一个能够访问并分析实时网页数据的自主竞争情报代理。
下一步
本文构建的 AI 代理已经可用,但只是一个起点。你可以进一步扩展:
- 构建对话循环:添加 REPL 界面,与代理进行交互式聊天
- 创建专用代理:构建用于价格监控、市场研究或潜在客户获取的代理
- 实现多代理工作流:协调多个专用代理以处理复杂任务
- 添加记忆与状态:使用 AWS Strands 的状态管理实现具备上下文的对话
- 部署到生产:利用 AWS 基础设施实现可扩展的代理部署
- 扩展自定义工具:为特定数据源创建你自己的 MCP 工具
- 增强可观测性:为生产部署实现日志与监控
真实场景用例
AWS Strands 与 Bright Data 的组合可在多种业务场景中构建更先进的 AI 代理:
- 竞争情报代理:实时监控竞争对手的定价、产品特性与营销活动
- 市场研究代理:分析行业趋势、消费者情绪与新兴机会
- 电商优化代理:跟踪竞争对手目录与价格,支持动态定价策略
- 线索挖掘代理:从网络来源识别并筛选潜在客户
- 品牌监控代理:跟踪全网的品牌提及、评价与口碑
- 投研代理:收集财务数据、新闻与市场信号,辅助投资决策
结论
本文介绍了如何将 AWS Strands SDK 与 Bright Data 的 Web MCP 服务器集成,构建能够访问并分析实时网页数据的自主 AI 代理。这一强大的组合让你能够打造既能进行战略性思考又能保持信息实时更新的代理。
该方法的关键优势包括:
- 极少代码:使用约 100 行 Python 即可构建复杂代理
- 自主决策:代理会根据目标自行决定使用哪些工具
- 生产就绪:两个平台都具备内置的错误处理与可扩展能力
- 实时数据访问:借助在线网页数据克服 LLM 的局限
若要构建更复杂的代理,欢迎探索 Bright Data AI 基础设施的全套服务。这些解决方案可以支撑多种代理式应用场景。
立即免费创建 Bright Data 账户,开始体验由 AI 驱动的网页数据工具吧!



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





