
在本文中,你将了解:
- 什么是 Google Gen AI SDK 以及它提供的核心功能。
- 为何通过 MCP 扩展它是一种制胜选择。
- 如何将 Google Gen AI SDK 与 Bright Data Web MCP 结合,构建一个情感分析 AI 工作流示例。
让我们开始吧!
什么是 Google Gen AI SDK?
Google Gen AI SDK 是一组软件开发工具包,帮助你将 Google 的生成式 AI 模型(如 Gemini)集成到 AI 应用中。这些开源 SDK 支持多种编程语言。
简而言之,它为你通过 Gemini Developer API 和 Vertex AI 上的 Gemini API 与这些模型交互提供了统一接口。具体来说,Google Gen AI SDK 的关键特性包括:
- 多语言支持:SDK 提供 Python、Node.js、Java 和 Go 版本,让你可用偏好的语言构建 AI 功能。
- 访问 Gemini 模型:可访问 Google 的先进生成式 AI 模型,如 Gemini 2.5 系列大模型。
- 统一 API 访问:同时为快速原型的 Gemini Developer API 和面向生产的 Vertex AI 上的 Gemini API 提供一致接口。
- 函数调用能力:支持通过 MCP 等与外部工具和服务交互。
为什么要将 Google Gen AI SDK 与用于网页访问的 MCP 服务器集成
无论你在 Google Gen AI SDK 中配置哪种 Google 生成式 AI 模型,它们都有同一个限制:知识是静态的!
LLM 是在数据上训练的,这些数据只代表某一时刻的快照,容易过时。这是 LLM 的主要局限之一,同时它们也无法直接与实时网站交互。
在大多数情况下,你希望 AI 工作流和应用能访问最新的高质量数据。理想状态下,既然 AI 旨在自动化,工作流应能自动为你获取这些数据。将 Google Gen AI SDK 与 Bright Data 的 Web MCP 集成,正是为了实现这一点。
Web MCP 提供 60 多个 AI 就绪工具的访问,这些工具均由 Bright Data 的 AI 基础设施驱动,以进行网页交互和数据采集。即使在免费版,你也可以给你的 AI 开启其中的两个工具:
| 工具 | 描述 |
|---|---|
scrape_as_markdown |
以高级提取选项抓取单个网页内容,并以 Markdown 返回数据。可绕过机器人检测和验证码。 |
search_engine |
从 Google、Bing 或 Yandex 提取搜索结果。以 JSON 或 Markdown 格式返回 SERP 数据。 |
除此之外,还有约 60 个专用工具,用于在 Amazon、LinkedIn、Yahoo Finance、TikTok 等领域进行网页交互和结构化数据采集。
总之,将 Google Gen AI SDK 与 Web MCP 集成,等于为你的 AI 工作流接入了整个 Web。这有助于在充分利用 Google 生成式模型的同时,从最新数据中生成洞察。
如何使用 Google Gen AI SDK 与 Bright Data 的 Web MCP 构建情感分析 AI 工作流
在本指南部分,你将学习如何在用 Python 编写的 Google Gen AI SDK 工作流中连接 Bright Data 的 Web MCP。具体来说,你将使用此集成来构建一个情感分析 AI 工作流:
- 使用 Bright Data Web MCP 工具抓取一篇 CNN 新闻文章。
- 让 Gemini 模型对内容进行摘要与情感分析。
- 将结果返回给你。
注意:这只是一个示例。通过修改提示词,你可以覆盖许多其他场景。此外,你也可以轻松将下面的 Python 脚本适配到其他支持的编程语言。
我们开始吧!
准备工作
开始之前,请确保你已具备:
- 本地安装 Python 3.9+。
- 本地安装 Node.js(推荐 最新 LTS 版本)。
- Gemini API Key。
- 一个已配置 API Key 的 Bright Data 账户。
无需为 Bright Data 账户的设置而担心,稍后步骤会引导你完成。
步骤 #1:创建你的 Python 项目
打开终端,为你的 Google Gen AI 项目创建一个新目录:
mkdir google-genai-mcp-workflowgoogle-genai-mcp-workflow/ 文件夹将包含你的 Google Gen AI 工作流的 Python 代码。它将连接 Bright Data Web MCP 进行网页数据抓取。
接着,进入项目目录并在其中创建一个虚拟环境:
cd google-genai-mcp-agent
python -m venv .venv现在,在你喜欢的 Python IDE 中打开该项目。我们推荐 装有 Python 扩展的 Visual Studio Code 或 PyCharm 社区版。
在项目文件夹中新建 workflow.py 文件。你的目录结构应如下所示:
google-genai-mcp-workflow/
├── .venv/
└── workflow.py在终端中激活虚拟环境。Linux 或 macOS 下执行:
source .venv/bin/activate在 Windows 下,运行:
.venv/Scripts/activate环境激活后,安装所需依赖:
pip install google-genai mcp python-dotenv这将安装:
google-genai:Google Gen AI 的 Python SDK,用于将 Google 的生成式模型集成到 Python 应用。mcp:MCP(Model Context Protocol)的 Python 实现。python-dotenv:从.env文件加载环境变量。
一切就绪!你已经拥有一个可用于构建带 Bright Data Web MCP 集成的 AI 工作流的 Python 开发环境。
步骤 #2:设置环境变量读取
你的 AI 工作流将连接到第三方组件,如 Gemini AI 模型和 Bright Data Web MCP 服务器。为保证安全,应避免将 API Key 硬编码在 Python 代码中,而应将它们存储为环境变量。
为简化环境变量的加载,可使用 python-dotenv 库。在 workflow.py 文件顶部导入并调用 import os
import os
from dotenv import load_dotenv
load_dotenv()load_dotenv() 函数允许你的脚本从本地 .env 文件读取变量。因此,在项目根目录创建该 .env 文件:
google-genai-mcp-workflow/
├── venv/
├── .env # <-----------
└── workflow.py很好!你现在可以通过环境变量安全地管理 API Key 和其他机密信息。
步骤 #3:测试 Bright Data Web MCP
在你的脚本中配置 Bright Data 的 Web MCP 连接之前,先确保你的机器能运行 MCP 服务器。
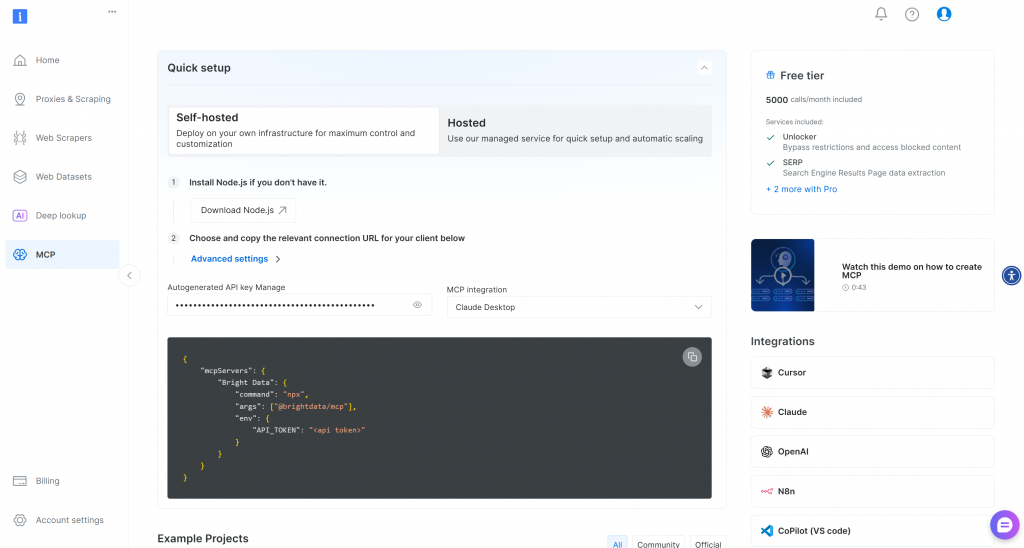
如果你还没有 Bright Data 账户,请创建一个。已有账户的话,直接登录。为了快速设置,前往控制台的 “MCP” 区域并按指引操作:
或者,按以下步骤进行。
首先,生成一个 Bright Data API Key 并妥善保存。本文假设该 API Key 具有 Admin 权限,以简化 Web MCP 的集成流程。
运行以下命令全局安装 Web MCP:
npm install -g @brightdata/mcp然后,通过运行以下命令验证本地 MCP 服务器是否正常:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp或在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你实际的 Bright Data API Token。该命令会设置所需的 API_TOKEN 环境变量,并使用 @brightdata/mcp 包启动 Web MCP。
如果成功,你应能看到类似如下的日志:

首次启动时,该包会在你的 Bright Data 账户中创建两个默认 Zone:
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
这些 Zone 是 Web MCP 驱动其 60 多个工具所必需的。
要确认 Zone 已创建,请登录 Bright Data 控制台。转到“Proxies & Scraping Infrastructure”页面,检查表格中是否出现这两个 Zone:
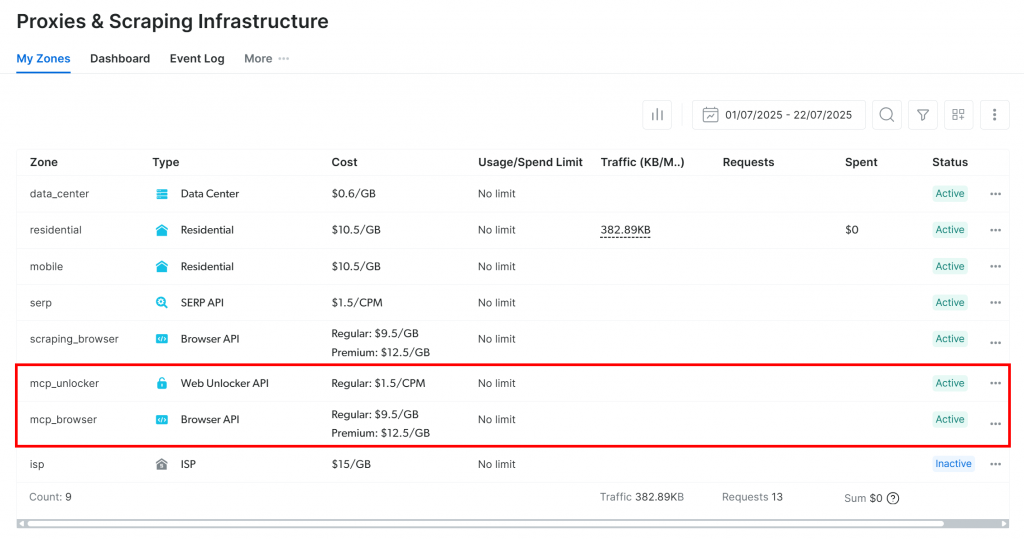
注意:如果你的 API Token 没有 Admin 权限,这些 Zone 不会自动创建。此时需要在控制台手动添加,并通过环境变量配置它们的名称(详见 GitHub 页面)。
默认情况下,MCP 服务器仅暴露 search_engine 和 scrape_as_markdown 工具(及其批量版本)。借助 Web MCP 免费层即可使用它们。
拓展:若要解锁高级工具(例如浏览器自动化与结构化数据源),在启动 MCP 服务器前设置 PRO_MODE="true" 环境变量以启用 专业模式:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp专业模式解锁全部 60 多个工具,不包含在免费层内,可能产生额外费用。
太棒了!你已确认 Web MCP 服务器能在本机运行。现在可以暂时停止该服务器,接下来你会配置 Google Gen AI 脚本以自动启动并连接它。
步骤 #4:定义 MCP 连接配置
在 workflow.py 中,用以下配置表示 Web MCP 的连接逻辑:
from mcp import StdioServerParameters
# Read the Bright Data API key from the env
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Configuration to connect to the Bright Data Web MCP via stdio connection
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
# "PRO_MODE": "true" (optional, to enable access to all 60+ tools)
},
)该配置会生成与之前相同的 npx 命令(并带上正确的环境变量),以在本地启动 Web MCP 服务器并通过 stdio 连接。
注意:PRO_MODE 环境变量是可选的。只有在你想访问全部 60 多个工具时才启用。否则,可继续使用免费层提供的 search_engine 与 scrape_as_markdown(及其批量版本)。
接着,将你的 Bright Data API Key 添加到 .env 文件:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"请务必将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你在前面步骤中生成并测试过的实际 API Key。
很好!你的 AI 工作流现在可以使用该配置,通过 mcp 包连接到本地 Bright Data Web MCP 服务器。
步骤 #5:创建 Google Gen AI SDK 客户端与 MCP 会话
先将你的 Gemini API Key 添加到 .env 文件:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"将 <YOUR_GEMINI_API_KEY> 替换为你的实际 Gemini API Key。
然后,初始化一个 Google Gen AI SDK 客户端,并设置带 MCP 集成的会话:
import asyncio
from mcp import ClientSession
from google import genai
from mcp.client.stdio import stdio_client
# Initialize the Google Gen AI SDK client
client = genai.Client()
async def run():
# Initialize an MCP client context
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the AI SDK client session, with MCP integration
await session.initialize()
# Google Gen AI SDK with MCP integration...
# Start the asyncio event loop and run the main function
asyncio.run(run())会话通过 stdio_client() 启动。得到的 read 与 write 对象随后传入 ClientSession,建立 MCP 连接。稍后该会话将传递给 Google Gen AI SDK 实例,以便在 Gemini 中进行 MCP 集成。
注意:该设置涉及异步操作,因此需要使用 asyncio。
做得好!你现在可以通过客户端向 Gemini 模型发送请求,并在需要时调用 MCP 工具了——正如下文所示。
步骤 #6:验证 MCP 工具集成
验证本地 Bright Data Web MCP 服务器暴露的工具是否可用。为此,列出所有可用工具:
tools = await session.list_tools()然后打印它们:
print(tools)如果你执行脚本(未启用 专业模式),你应看到如下所示:
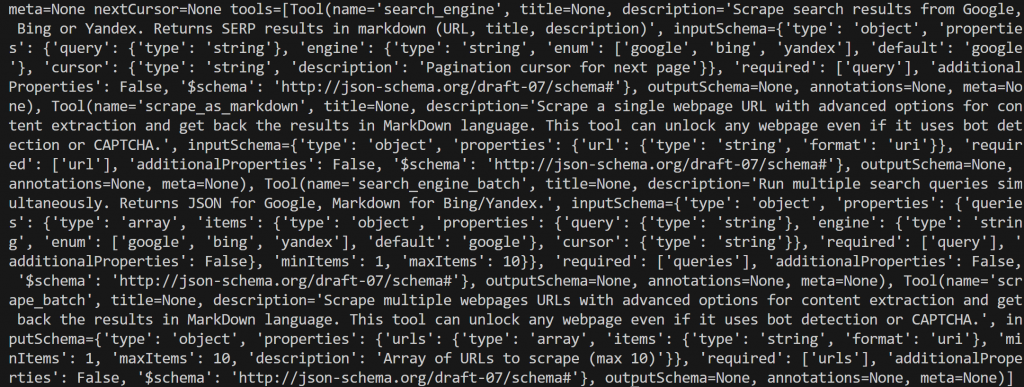
上面的输出有点冗长,但仔细查看你会发现列出了:
search_engine:从 Google、Bing 或 Yandex 抓取搜索结果。以 Markdown 格式返回 SERP(URL、标题、描述)。scrape_as_markdown:以高级选项抓取单个网页,并以 Markdown 返回内容。可在存在机器人检测或验证码时工作。search_engine_batch:同时运行多个搜索查询。Google 返回 JSON,Bing/Yandex 返回 Markdown。scrape_batch:一次抓取多个网页(最多 10 个 URL),提供高级选项,并以 Markdown 返回结果。
这些正是 Web MCP 在免费层中暴露的工具,说明你的集成工作正常!
步骤 #7:执行任务
现在你已具备在 Google Gen AI SDK 工作流中运行任务的全部要素,并可连接到 Bright Data 的 Web MCP。
创建一个引用特定新闻文章(本例为 CNN)的提示词。请一个 Gemini 模型(例如 gemini-2.5-flash)抓取文章内容,并返回摘要和情感分析评述:
prompt = """
Scrape the content from the following news article as Markdown:
https://www.cnn.com/2026/09/15/tech/meta-future-ai-smart-glasses
Then, analyze it and provide:
1. A short summary of around 50 words.
2. A sentiment analysis comment indicating whether the article is positive, negative, or neutral.
"""将提示词传给 client.aio.models.generate_content() 方法,通过 Google Gen AI SDK 询问已配置的 Gemini 模型:
# Send the prompt to the Gemini model
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=genai.types.GenerateContentConfig(
temperature=0, # For more repeatable results
tools=[session], # To allow the automatic calling of the configured MCP tools
),
)
# Print the response from the AI
print(response.text)通过把先前初始化的 MCP 会话传给 tools 参数,Gemini 模型就能自动调用 Web MCP 工具。具体而言,为抓取文章内容,它应使用 scrape_as_markdown。
重要:gemini-2.5-flash 模型的配额相当宽松,同时 Bright Data Web MCP 已按免费层配置。这意味着你不会产生任何费用,该工作流完全免费。
很好!现在只剩下测试你的情感分析 AI 工作流了。
步骤 #8:整合全部
workflow.py 的最终代码如下:
import asyncio
import os
from dotenv import load_dotenv
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
from google import genai
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the env
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Configuration to connect to the Bright Data Web MCP via stdio connection
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
# "PRO_MODE": "true" (optional, to enable access to all 60+ tools)
},
)
# Initialize the Google Gen AI SDK client
client = genai.Client()
async def run():
# Initialize an MCP client context
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the AI SDK client session, with MCP integration
await session.initialize()
# Prompt to get sentiment analysis from a news article
prompt = """
Scrape the content from the following news article as Markdown:
https://www.cnn.com/2026/09/15/tech/meta-future-ai-smart-glasses
Then, analyze it and provide:
1. A short summary of around 50 words.
2. A sentiment analysis comment indicating whether the article is positive, negative, or neutral.
"""
# Send the prompt to the Gemini model
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=genai.types.GenerateContentConfig(
temperature=0, # For more repeatable results
tools=[session], # To allow the automatic calling of the configured MCP tools
),
)
# Print the response from the AI
print(response.text)
# Start the asyncio event loop and run the main function
asyncio.run(run())哇!不到 50 行代码,你就构建了一个情感分析 AI 工作流。如果没有 Bright Data Web MCP 与 Google Gen AI SDK,这是很难实现的。
用以下命令验证脚本是否正常:
python workflow.py脚本执行可能需要一些时间,因为按需抓取网站并用 AI 进行分析需要一定时长。
输出应类似于:
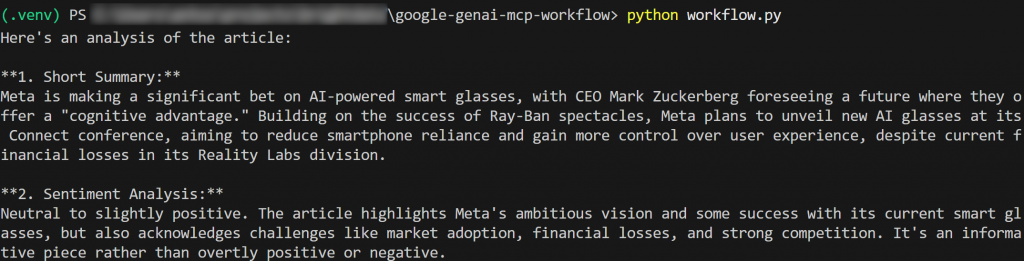
如你在CNN 原文所见,摘要与情感分析结果相当准确。
请注意,新闻网站抓取并不轻松,尤其是像 CNN 这样通常有反爬系统保护的热门网站。这正是 Bright Data Web MCP 发挥作用的地方,它为网页数据获取、交互与搜索提供了一整套 AI 就绪工具。
这只是一个示例。借助 Gen AI SDK 中广泛的 Bright Data 工具,你可以通过调整提示词,构建覆盖多种真实业务用例的工作流。
就是这样!你已经体验了在 Google Gen AI 工作流中集成 Bright Data Web MCP 的强大能力。
结论
在本文中,你看到了如何将 Google Gen AI SDK 连接到 Bright Data 的 Web MCP(现已提供免费层!)。结果是一个增强的 AI 工作流,能够访问多种用于网页数据提取与交互的工具。
若要构建更复杂的 AI 代理,请探索 Bright Data 的 AI 基础设施所提供的完整产品与服务。这些解决方案支持各种 AI 工作流与 Agent 场景。
立即创建免费的 Bright Data 账户,开始试用我们的 AI 就绪型网页数据工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




