
在本文中,你将学到:
- 什么是 smolagents,以及它为何迅速流行。
- 其代理如何依赖工具执行,以及如何通过 Bright Data 的 Web MCP 获取工具。
- 如何将 Web MCP 工具集成进 smolagents 来构建代码式 AI 代理。
开始吧!
什么是 smolagents?
smolagents 是一个轻量级 Python 库,可用极少代码构建强大的 AI 代理。其独特之处在于 CodeAgent,它会将执行提示所需的动作写成可执行的 Python 代码片段(而不仅仅返回文本回复)。
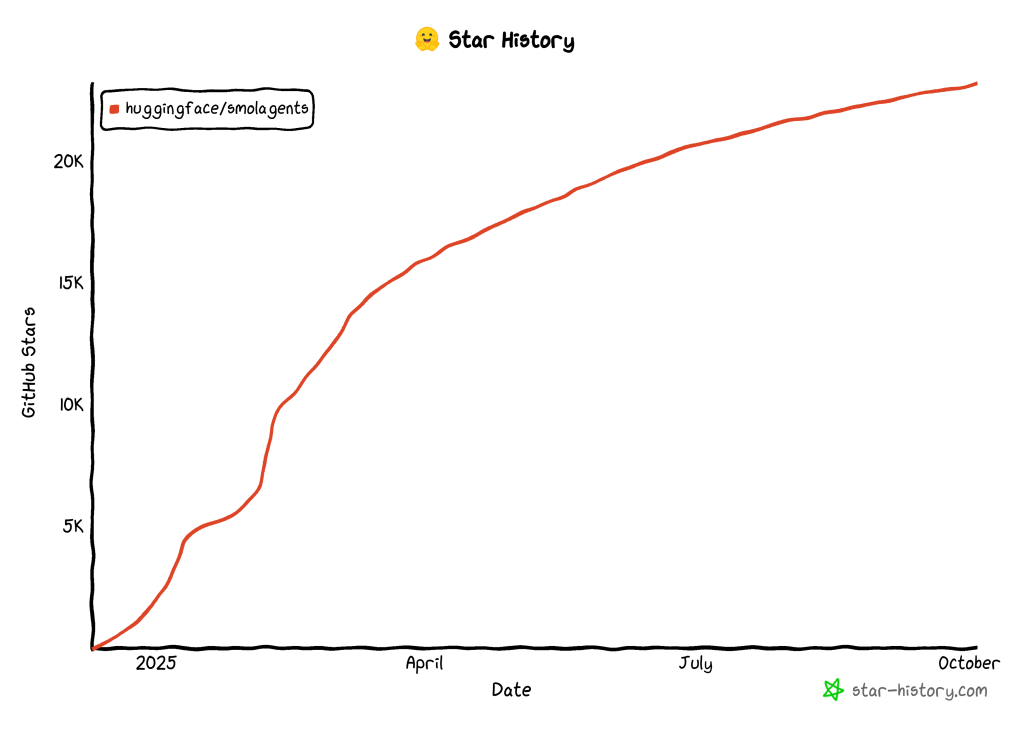
这种方式提高了效率,减少了 LLM 调用次数,并且通过沙箱化执行,让代理可以安全地直接与工具和环境交互。社区已广泛接受这种构建 AI 代理的新方法,仅数月内该库就在 GitHub 上收获了23k 颗星:
请记住,smolagents 具有以下特性:
- 模型无关:支持 OpenAI、Anthropic、本地 transformers,或 Hugging Face Hub 上的任何 LLM。
- 模态无关:支持文本、视觉、音频和视频。
- 工具无关:支持来自 MCP 服务器、LangChain 或 Hub Spaces 的工具。
可在Hugging Face 博客的公告文章中了解该库背后的理念。
为何 smolagents 强调使用工具
LLM 受限于其训练数据。它们能基于这些知识生成回复、内容、代码或多媒体,这很强大,但也构成了当前 AI 的主要限制之一。
smolagents 通过围绕工具构建代理来解决这个问题。重要到何种程度?库中的每个代理类都将工具列表作为必填参数。得益于工具调用,你的 AI 模型可以与环境交互,执行超越内容生成的任务。
尤其是,smolagents 可以连接 MCP 服务器、LangChain,甚至 Hub Space 的工具。它还支持标准的 JSON/文本式工具调用。
那么,当下典型 AI 缺少的是什么?准确、最新的数据以及像人类一样与网页交互的能力。这正是Bright Data 的 Web MCP 工具所提供的!
Web MCP 是一个开源服务器,提供60+ 个适配 AI 的工具,全部由 Bright Data 的网页交互与数据采集基础设施驱动。即使在免费层,你也能使用两款改变游戏规则的工具:
| 工具 | 描述 |
|---|---|
search_engine |
以 JSON 或 Markdown 形式获取来自 Google、Bing 或 Yandex 的搜索结果。 |
scrape_as_markdown |
将任意网页抓取为干净的 Markdown 格式,绕过机器人检测和验证码。 |
除此之外,Web MCP 还提供云端浏览器交互工具,以及数十种在 YouTube、Amazon、LinkedIn、TikTok、Yahoo Finance 等平台上进行结构化数据采集的专业工具。更多信息请参见官方 GitHub 页面。
看看 Web MCP 与 smolagents 的实际效果吧!
如何用 Web MCP 工具扩展 smolagents 代码式 AI 代理
在本教程中,你将学习如何构建一个与 Bright Data Web MCP 集成的 smolagents AI 代理。具体来说,该代理将使用 MCP 服务器暴露的工具即时获取网页数据并对其进行情感分析。
注意:这只是一个示例,你可以通过更改输入提示轻松适配其他用例。
按以下步骤操作!
先决条件
要跟随本教程,请确保你已具备:
- 本地安装了Python 3.10+。
- 机器上安装了 Node.js(建议使用最新 LTS 版本)以运行 Web MCP。
- 一个Gemini API 密钥(或任一其他受支持模型的 API 密钥)。
你还需要一个带有 API 密钥的 Bright Data 账户。无需担心,本文稍后会引导你完成。对MCP 的工作原理以及Web MCP 提供的工具有基本了解也会有帮助。
步骤 1:项目初始化
打开终端,为你的 smolagents 项目创建新文件夹:
mkdir smolagents-mcp-agentsmolagents-mcp-agent/ 将包含通过 Web MCP 工具扩展的 AI 代理的 Python 代码。
然后,进入项目目录并在其中初始化虚拟环境:
cd smolagents-mcp-agent
python -m venv .venv新增一个名为 agent.py 的文件。此时你的项目结构应如下:
smolagents-mcp-agent/
├── .venv/
└── agent.pyagent.py 将作为主 Python 文件,包含 AI 代理的定义。
在你喜欢的 Python IDE 中打开该项目文件夹。推荐使用装有 Python 扩展的 Visual Studio Code或PyCharm 社区版。
现在激活先前创建的虚拟环境。在 Linux 或 macOS 上,执行:
source .venv/bin/activate在 Windows 上,执行:
.venv/Scripts/activate激活虚拟环境后,安装所需 PyPI 库:
pip install "smolagents[mcp,openai]" python-dotenv依赖如下:
"smolagents[mcp,openai]":smolagents包,并扩展了 MCP 集成以及连接任何提供 OpenAI 兼容 API 的供应商的能力。python-dotenv:用于从本地.env文件读取环境变量。
完成!现在你已具备使用 smolagents 进行 AI 代理开发的 Python 环境。
步骤 2:配置环境变量读取
你的代理会连接到 Gemini 和 Bright Data 等第三方服务。为这些连接进行身份验证,你需要设置一些 API 密钥。将它们硬编码在 agent.py 中会带来安全问题。因此,应配置脚本从环境变量中读取密钥。
这正是我们安装 python-dotenv 的原因。在 agent.py 中引入该库并调用 load_dotenv() 以加载环境变量:
from dotenv import load_dotenv
load_dotenv()你的脚本现在可以从本地 .env 文件访问环境变量。
在项目目录添加一个 .env 文件:
smolagents-mcp-agent/
├── .venv/
├── .env # <------
└── agent.py然后在代码中通过以下方式访问环境变量:
import os
os.getenv("ENV_NAME")很好!你的脚本现在可以安全地从环境变量加载第三方集成所需的密钥。
步骤 3:本地测试 Bright Data 的 Web MCP
在配置与 Bright Data Web MCP 的连接之前,请先确保你的机器可以运行该服务器。因为你将让 smolagents 在本地启动 Web MCP,随后代理会通过STDIO 与之连接。
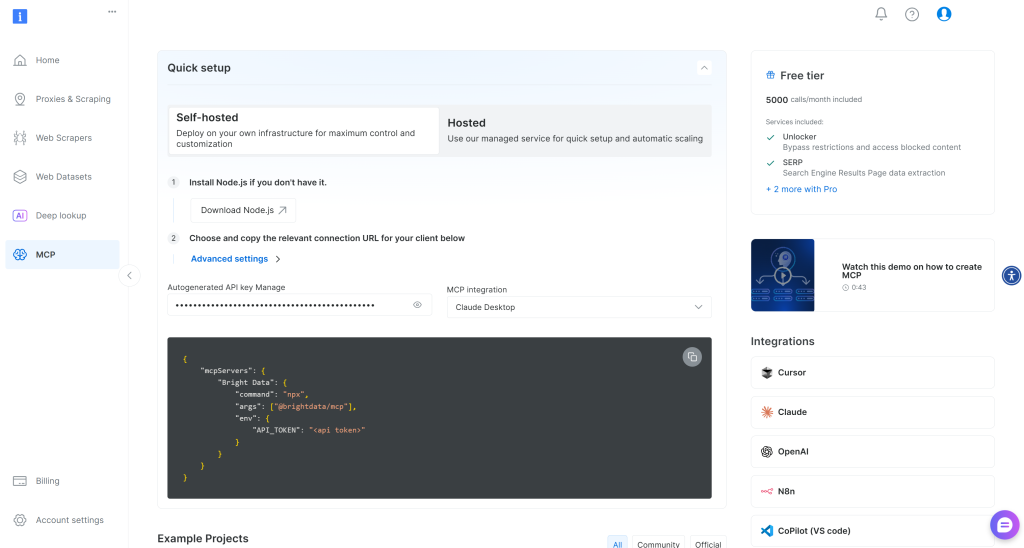
如果你还没有 Bright Data 账户,请创建一个新账户。已有账户的话,直接登录。快速设置可按你账户中的“MCP”部分提示进行:
若你需要更多引导,请按照下述步骤操作。
首先,生成一个 Bright Data API 密钥。妥善保存,稍后会用到。这里我们假设你的 API 密钥具备 Admin 权限,因为这会简化 Web MCP 集成流程。
接着,通过安装 @brightdata/mcp 包,将 Web MCP 全局安装到你的机器:
npm install -g @brightdata/mcp然后,通过启动本地 MCP 服务器来检查其是否正常工作:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp或在 PowerShell 中:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你的 Bright Data API 令牌。上述命令会设置必需的 API_TOKEN 环境变量,并通过执行其 npm 包在本地启动 Web MCP。
若成功,你会看到类似如下的日志:

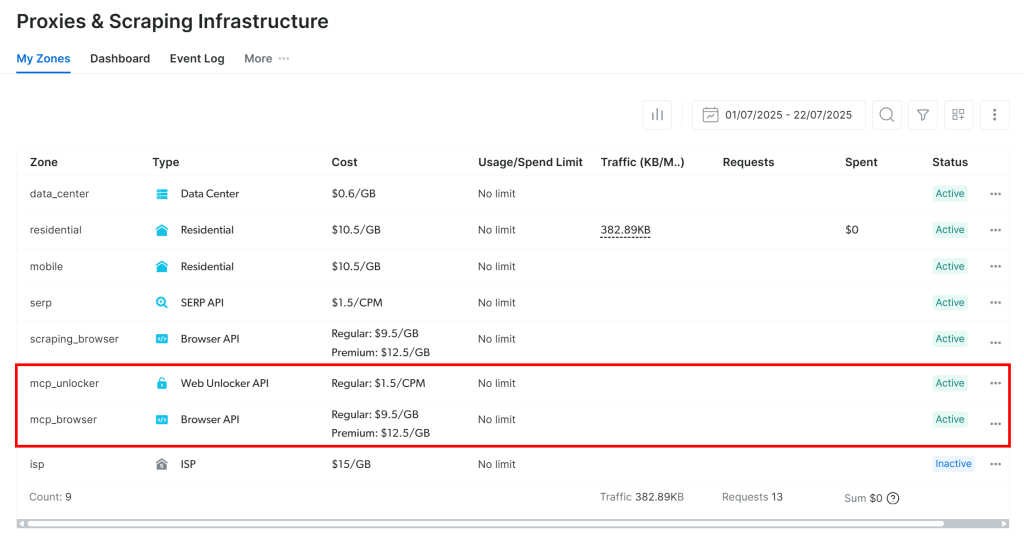
首次启动时,Web MCP 会在你的 Bright Data 账户中自动创建两个默认 Zone:
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
Web MCP 的 60+ 个工具依赖这两款 Bright Data 产品来提供能力。
若要验证这些 Zone 是否创建成功,登录 Bright Data 仪表盘,进入“Proxies & Scraping Infrastructure”页面,你应能在表格中看到它们:
注意:如果你的 API 令牌没有 Admin 权限,这两个 Zone 不会被自动创建。在这种情况下,你需要手动创建并通过环境变量配置它们的名称,具体见GitHub 上的说明。
默认情况下,MCP 服务器只暴露 search_engine 和 scrape_as_markdown 工具(及其批处理版本)。这些工具包含在Web MCP 免费层中,你可以免费使用它们。
若要解锁高级工具(如浏览器自动化与结构化数据源工具),你需要启用 Pro 模式。为此,请在启动 Web MCP 前设置 PRO_MODE="true" 环境变量:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpPro 模式会解锁所有 60+ 工具,但不包含在免费层中,会产生额外费用。
太棒了!你已经确认 Web MCP 服务器可以在你的系统上正常运行。现在结束 MCP 进程,接下来将配置脚本以启动并连接它。
步骤 4:连接 Web MCP
让你的 Python 脚本通过 STDIO 连接到 Web MCP 服务器。
先将之前获取的 Bright Data API 密钥添加到 .env 文件:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你的真实密钥。
在 agent.py 中加载该 API 密钥:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")然后,定义一个 StdioServerParameters 对象以配置 STDIO 连接:
from mcp import StdioServerParameters
server_parameters = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true", # Optional
},
)该设置与之前的 npx 命令一致,使用环境变量传递 API 令牌。注意 API_TOKEN 为必填,PRO_MODE 为可选。
使用一个 MCPClient 实例应用上述连接设置,并检索服务器暴露的工具列表:
from smolagents import MCPClient
with MCPClient(server_parameters, structured_output=True) as tools:你的 agent.py 脚本现在会启动一个 Web MCP 进程并通过 STDIO 连接。结果是一组工具,可传递给任意 smolagents AI 代理。
通过打印可用工具来验证连接:
for bright_data_tool in bright_data_tools:
print(f"TOOL: {bright_data_tool.name} - {bright_data_tool.description}n")如果在禁用 Pro 模式下运行脚本,你将看到数量受限的工具:
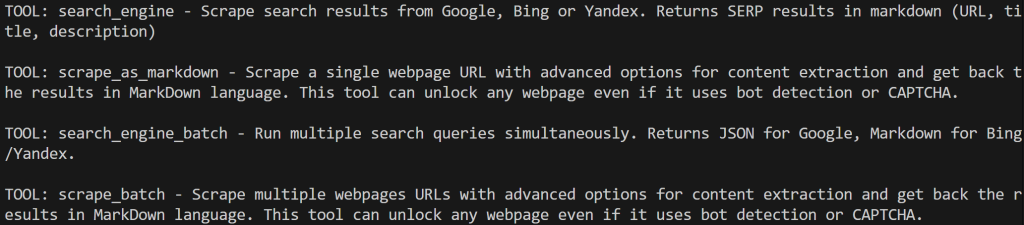
启用 Pro 模式后,将显示全部 60+ 工具:
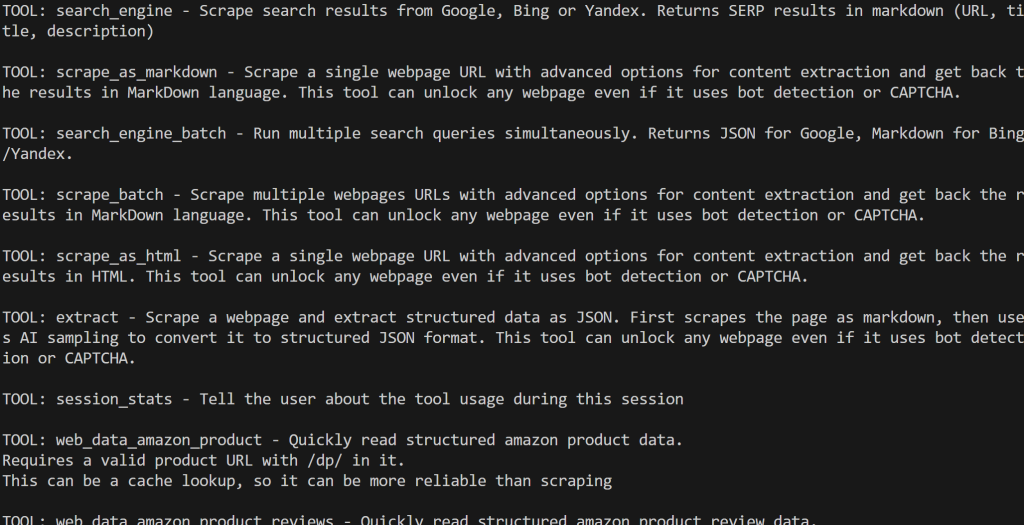
很好!这表明你的 Web MCP 集成工作正常。
步骤 5:定义 LLM 集成
你的脚本现在已经可以访问这些工具,但代理还需要“大脑”。这意味着是时候配置与 LLM 服务的连接了。
先将 Gemini API 密钥添加到 .env 文件:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"然后在 agent.py 中加载:
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")接下来,定义一个 OpenAIServerModel 实例以连接 Gemini API:
from smolagents import OpenAIServerModel
model = OpenAIServerModel(
model_id="gemini-2.5-flash",
# Google Gemini OpenAI-compatible API base URL
api_base="https://generativelanguage.googleapis.com/v1beta/openai/",
api_key=GEMINI_API_KEY,
)即便使用的是面向 OpenAI 的模型类,这也能正常工作。这要归功于你设置的特定 api_base,它提供了 Gemini 的 OpenAI 兼容端点。很酷!
步骤 6:使用 Web MCP 工具创建 AI 代理
你现在已具备创建 smolagents 代码式 AI 代理的所有构件。使用 Web MCP 工具与 LLM 引擎来定义一个代理:
from smolagents import CodeAgent
agent = CodeAgent(
model=model,
tools=tools,
stream_outputs=True,
)CodeAgent 是 smolagents 的主力 AI 代理类型。它会生成 Python 代码片段来执行动作并解决任务。其优缺点如下:
优点:
- 表达力强:可处理复杂逻辑、控制流,并组合多个工具;支持循环、变换、推理等。
- 灵活:无需预定义每个动作,可动态生成新动作与工具。
- 涌现式推理:适合多步问题或动态决策场景。
缺点:
- 易出错:可能生成 Python 语法错误或异常,需要处理。
- 不可预测性更强:输出可能出乎意料或不安全。
- 需要安全环境:必须在安全的执行环境中运行。
剩下的就是运行你的代理,让它执行任务了!
步骤 7:在代理中执行一个任务
为了测试代理的网页数据获取能力,你需要编写一个合适的提示。例如,假设你想分析某个 YouTube 视频评论的情感。
Web MCP 工具将检索评论,而由 CodeAgent 生成的 Python 脚本会执行情感分析。最后执行该代码。查看生成的 Python 代码也有助于理解流程并便于未来扩展。
在你的代理中运行如下提示即可实现:
prompt = """
Retrieve the top 10 comments from the following YouTube video:
https://www.youtube.com/watch?v=9txkGBj_trg
Provide a concise report that includes sentiment analysis, along with excerpts from the actual comments
"""
# Execute the prompt in the agent
agent.run(prompt)输入视频是《黑色行动 7》预告片,这款游戏并未获得社区的良好反馈。
由于大多数评论相当偏负面,预计情感分析将显示以负面反应为主的结果。
步骤 8:整合到一起
此时你的 agent.py 文件应包含:
# pip install "smolagents[mcp,openai]" python-dotenv
from dotenv import load_dotenv
import os
from smolagents import OpenAIServerModel, MCPClient, CodeAgent, ToolCallingAgent
from mcp import StdioServerParameters
# Load environment variables from the .env file
load_dotenv()
# Read the API keys from the envs
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
server_parameters = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true", # Optional
},
)
# Initialize the connection to Gemini
model = OpenAIServerModel(
model_id="gemini-2.5-flash",
# Google Gemini OpenAI-compatible API base URL
api_base="https://generativelanguage.googleapis.com/v1beta/openai/",
api_key=GEMINI_API_KEY,
)
# Initialize the MCP client and retrieve the tools
with MCPClient(server_parameters, structured_output=True) as tools:
# Define the AI agent, extended with the MCP tools
agent = CodeAgent(
model=model,
tools=tools,
stream_outputs=True,
)
prompt = """
Retrieve the top 10 comments from the following YouTube video:
https://www.youtube.com/watch?v=9txkGBj_trg
Provide a concise report that includes sentiment analysis, along with excerpts from the actual comments
"""
# Execute the prompt in the agent
agent.run(prompt)如约,smolagents 表现不俗,让你在不到 50 行代码内构建一个带有 MCP 集成的完整 AI 代理。
通过执行以下命令进行测试:
python agent.py假设你在启用 Web MCP 的 Pro 模式下运行,将看到如下多步输出:
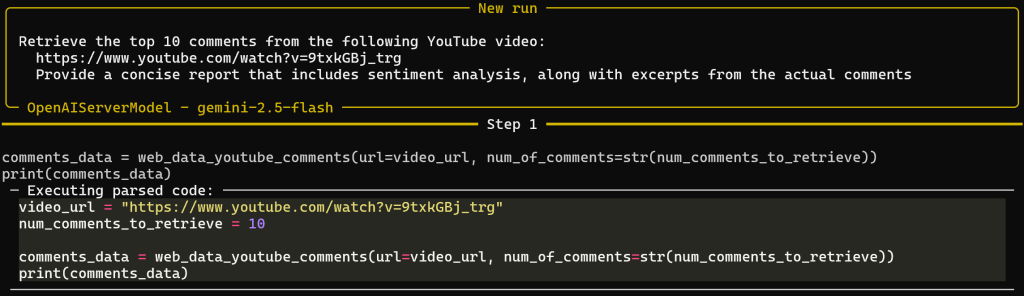
请注意,基于提示,代理成功选择了 web_data_youtube_comments 这一 Web MCP 工具,并以正确的参数进行调用以达成目标。该工具的描述是:“快速读取结构化的 YouTube 评论数据。需要有效的 YouTube 视频 URL。这可能是一次缓存查找,因此比抓取更可靠。”可见决策非常合理!
在工具返回评论数据后,进入用于生成报告的第 2 步:
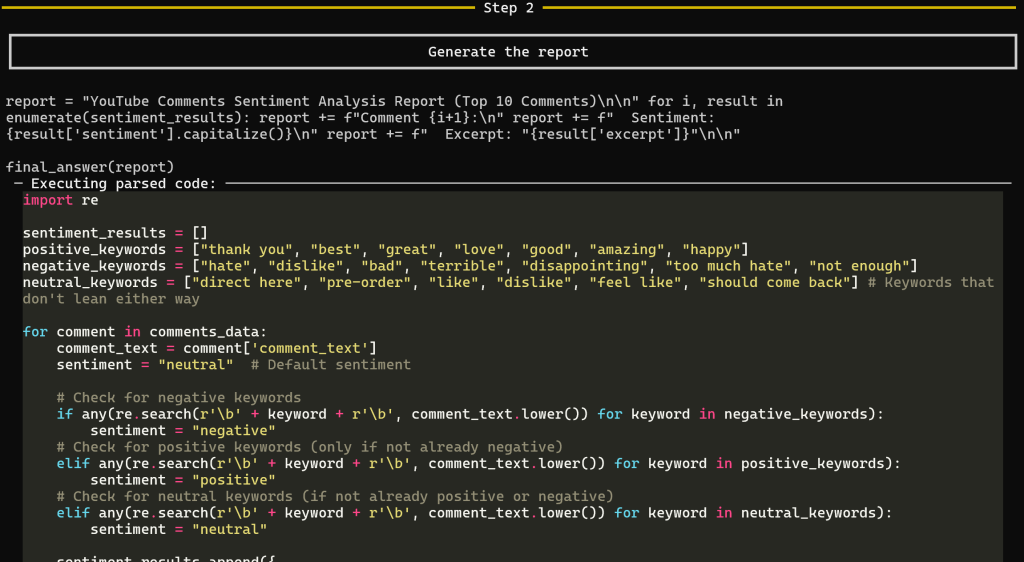
此步骤生成最终的情感分析报告。具体而言,CodeAgent 会生成用于产出报告的全部 Python 代码,并在 web_data_youtube_comments 获取的数据上执行。
这种方式让你清楚地了解 AI 产出结果的过程,在很大程度上消除了 LLM 的“黑箱”感。
结果大致如下所示:
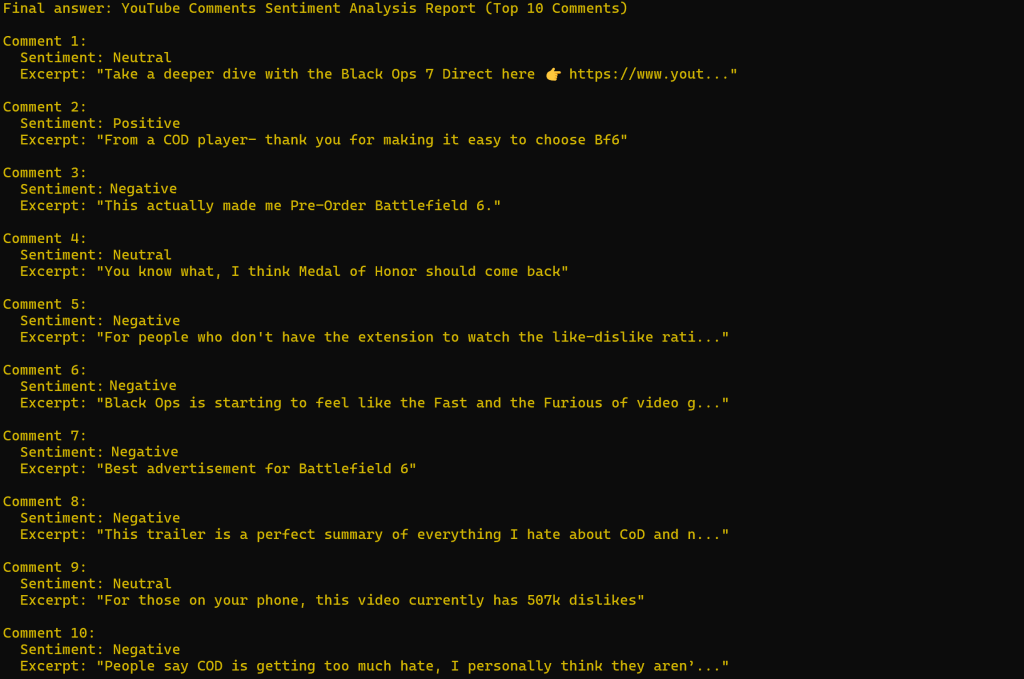
不出所料,情感分析结果以负面为主。
注意,报告中引用的评论与你在该 YouTube 视频页面上看到的内容完全一致:
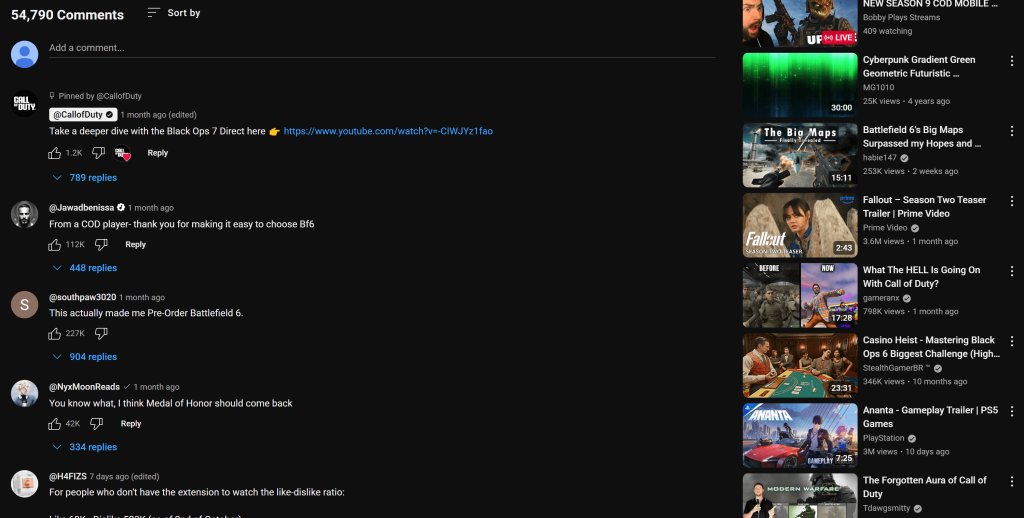
如果你尝试过抓取 YouTube,就会知道这有多困难:既有反爬保护,又需要用户交互。传统 LLM 无法处理这些,这也展示了将 Bright Data 的 Web MCP 集成到 smolagents AI 代理中的强大与高效。
欢迎尝试不同的输入提示。借助 Bright Data Web MCP 丰富的工具,你可以应对各种真实世界的用例。
大功告成!你已经见识到在 Python 中将 Bright Data 的 Web MCP 与 smolagents 代码式 AI 代理相结合的强大威力。
结语
本文介绍了如何使用 smolagents 构建基于代码的 AI 代理,并展示了如何通过 Bright Data 的 Web MCP 工具进行增强,其中还提供免费层。
此集成为你的代理赋予网页搜索、结构化数据抽取、访问实时网页数据源、自动化网页交互等能力。若想构建更复杂的 AI 代理,请探索 Bright Data 生态中更广泛的 AI 就绪产品和服务。
立即创建 Bright Data 账户,开始体验我们的网页数据工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



